
4.2 Top-down Parsing
We shall now discuss some Top-down parsing in some detail. A sub-class of CFG, known as LL(k) grammars, can be parsed deterministically, i.e. without backtracking, by LL(k) methods. The nomenclature LL(k) has the following significance:
We cannot have a grammar with left recursion for Top-down parsing. Consider a production
T –> T * a
Because Top-down parsing involves leftmost derivation, we shall always replace the T on the RHS by “T * a” and thus we shall have an infinite loop. We shall have to rewrite any left-recursive grammar as either right recursive or right iterative. How do we do this conversion? The general rules are as follows:
Here, β ∈ (VN ∪ VT)* not starting with A.
Within the class LL(k) there are sub-classes, with certain restrictions on the kind of production rules allowed, which will allow us to use simpler methods for parsing. LL(k) has the following most used sub-classes:
- Recursive-descent parser (RDP),
- Simple LL(1),
- LL(1) without ε-rules,
- LL(1) with ε-rules,
with progressively more complex grammar rules.
4.2.1 Recursive-descent Parser (RDP)
RDP has no left-recursive rule, either right-recursive or iterative rules (extended BNF) only. The extended BNF can be thought of as a set of rules whose RHS are generalized form of regular expressions. We have already encountered such parsers in Chapters 1 and 2.
Generally, we require a recognizer more powerful than FSM, a push-down automata (PDA) (an FSM with a separate stack) to parse sentences generated by a CFG (Fig. 4.4).
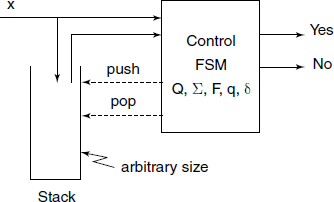
In case of RDP, an explicit stack is not present, rather we use the return-stack normally available as a hidden stack in an HLL like C (or even in most of the modern CPU hardware). Thus, the information that would have been stored normally on the stack of the PDA gets stored on this hidden stack, which stores the Activation Record (see Section 7.1.3 in Chapter 7). The local variables within a function and function called arguments are part of the activation record and thus automatically get stacked and unstacked on the hidden stack.
There is a function for each symbol X ∈ VT U VN. This function is named pX(), designed to recognize any string derivable from X.
If X ∈ VT : px () simply reads the input symbol and checks that it is really X, otherwise raises an error.
If X ∈ VN : within pX () we take action depending upon the next (look-ahead) symbol and call pX1(), pX2(), etc. depending upon its value.
Example
Consider the arithmetic expression grammar ![]() given previously. We have to rewrite it in an extended BNF, which is a right-iterative form, using the technique given previously as follows:
given previously. We have to rewrite it in an extended BNF, which is a right-iterative form, using the technique given previously as follows:
E –> T { + T }
T –> F { * F }
F –> ( E ) | a
A skeleton code for the corresponding RDP is:
int nextsym(){ /* look-ahead next input symbol */}
int symbol(){ /* get next input symbol */}
int error(){/* report error and exit */}
pE(){ pT(); while(nextsym() == “+”){pplus(); pT();} }
pT(){ pF(); while(nextsym() == “*”){past(); pF();} }
pF(){ switch(nextsym())
case “(”: plp(); pE(); prp(); break;
case “a”: pa();
}
pa(){ if(symbol() != “a”} error(); }
p1p(){ if(symbol() != “(”} error(); }
prp(){ if(symbol() != “)”} error(); }
pplus(){ if(symbol() != “+”} error(); }
past(){ if(symbol() != “*”} error(); }
RDP vs. A Parser Generator
We have seen that many real-life compiler writing projects use a parser generator like yacc. Looking at the simplicity of an RDP, how does development of a compiler using RDP compare with development using a parser generator?
- Probably more work involved in developing an RDP.
- Less risk of a disaster – you can almost always make a recursive-descent parser work.
- May have easier time dealing with resulting code: you need not learn the meta-language of the parser generator, no need to deal with potentially buggy parser generator, no integration issues with automatically generated code.
- If your parser development time is small compared to the rest of project, or you have a really complicated language, use hand-coded recursive-descent parser.
4.2.2 Exercises
- Implement the RDP fully for arithmetic expression grammar, including ‘ − ‘ and ‘/’ operations also. Your implementation should display how the parsing is being done by showing the steps taken. You may have to add an extra initial production like S –> E # and corresponding function, for ease of handling the input string.
- We have simply terminated the RDP on an error detection. Implement error handling at three levels – detection, report position and recovery from error.
4.2.3 Parser for Simple LL(1) Grammars
A simple LL(1) grammar is a CFG without ε-rules and have rules of the form
where αi ∈VT and αi∈(VT ∪ VN)*, A ∈VN. That means, for a particular NT, each alternative rule starts with different Terminal symbols. (In fact, BASIC was designed like this.)
Example
Given a grammar with productions:
P = { 0. S –> E#
1. E –> a
2. E –> (E)
3. E –> bA
4. A –> +E
5. A –> *E
}
Consider an input string “b + b * a#”.
We assume an explicit stack in the PDA. The PDA stacks the unmatched portion of the sentential form, while developing the syntax tree (Fig. 4.5).
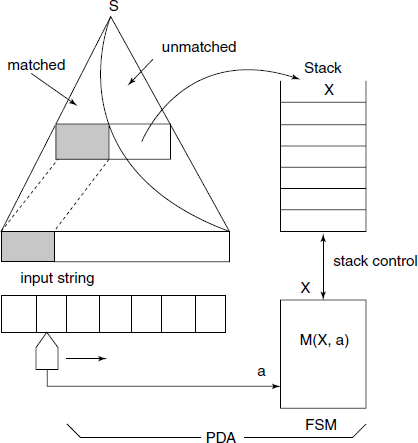
We use a parsing function, which is the specification of the FSM, in the form of a table:
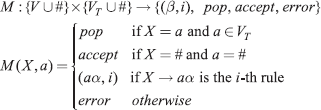
For the example grammar, the parsing function is given in Fig. 4.6. Empty entries denote “error” action. The stack contents are usually shown horizontally.
a–> a b + * ( ) #
X---------------------------------------------------
S 0 0 0
E 1 3 2
A 4 5
a pop
b pop
+ pop
* pop
( pop
) pop
# accept
-----------------------------------------------------------
Fig. 4.6 Parsing function M(X, a) for simple LL(1) grammar
The action of the simple LL(1) parser is shown for the example string shown in Table 4.3.
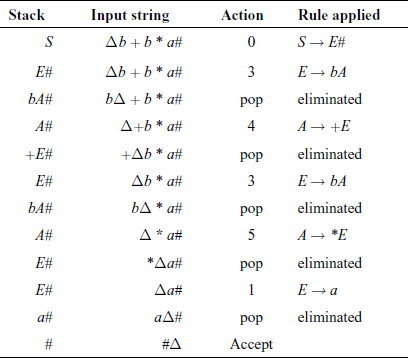
Note: Δ denotes the scan pointer.
4.2.4 LL(1) Grammar Without ε-rules
We extend the simple LL(1) parser, by removing the restriction that the first symbol on the RHS be in Vt. Surprisingly, such grammars are as much powerful, no more no less, as the Simple LL(1) grammars.
Example
Given a grammar with productions:
P = { 0. S’–> S#
1. S –> ABe
2. A –> dB
3. A –> aS
4. A –> c
5. B –> AS
6. B –> b
}
Consider input string adbbeccbee#. How could we have generated this sentence using the given grammar?
S′ => S# rule 0: only rule
=> ABe# rule 1: only rule, but no error, as A leads to a,c,d
=> aSBe# rule 3 selected: as we want “a” in front
=> aABeBe# rule 1: only rule, but no error, as A leads to a,c,d
=> adBBeBe# rule 2 selected: as we want “d” in front
=> adbBeBe# rule 5 rejected: as it would have placed A in front,
which would have lead to a,c,d, but we want “b”
rule 6 selected: gives us “b”
=> adbbeBe# rule 6 selected: gives us “b”
=> adbbeASe# rule 5 selected: rejecting rule 6
=> adbbecSe# rule 4 selected: we want “c” in front
=> adbbecABee# rule 1: only rule, but no error
=> adbbeccBee# rule 4 selected: we want “c” in front
=> adbbeccbeYe# rule 6 selected: gives us “b”
How can we parse this string? We try as shown in Table 4.4.
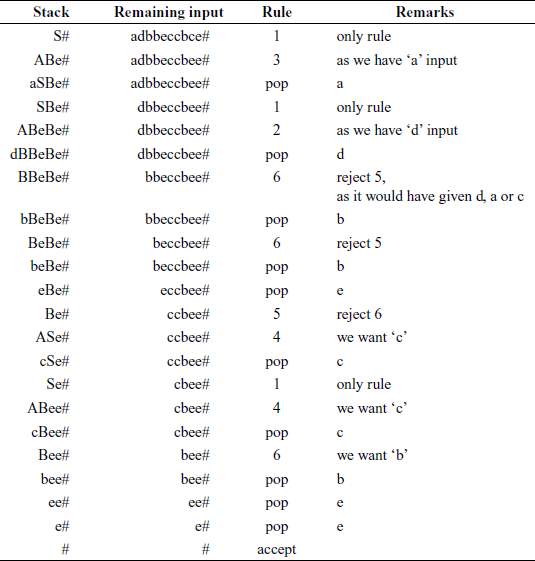
The critical decision was made when we encountered B for the first time; we rejected rule 5 and accepted rule 6, in view of given us {d, a, c}, but we have a ‘b’ on the top-of-stack (TOS) to match. Our experimenting with generation of a sentence guided us in parsing the sentence. We had to check what will be the front symbol ultimately get inserted when we replace a NT by another.
Armed with this experience, we now formalize the approach.
A function which tells us what symbol can get inserted in front is called the FIRST(β) for some string β. First, we give a working definition for the present, and later we shall have a more thorough definition.
Given some string α ∈ G (VT ε VN)*, the set of Terminal symbols which can be leftmost derived from α:
Using the notation,
T is a Terminal symbol,
N is a non-terminal,
X is a Terminal or non-terminal,
β is a sequence of Terminals or non-terminals,
t ∈ FIRST(β) if t can appear as the first symbol in a derivation starting from β. Recursive definition of FIRST(β) is given below:
- t ∈ FIRST (t)
- FIRST (X) ⊆ FIRST (Xβ)
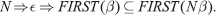
- N → Xb ⇒ FIRST (Xβ) ⊆ FIRST (N).
Note that rule (3) refers to empty string ε and is given here in anticipation of the next case of grammar.
For the example grammar: FIRST(A) = {d, a, c}, FIRST(B) = {d, a, c, b}, FIRST(ABe) = {a, c, d}, etc. Note that the following three – FIRST(dB) = {d}, FIRST(aS) = {a} and FIRST(c) = {c} – are the disjoint sets for productions from A. Similarly, FIRST(AS) = {d, a, c} and FIRST(b) = {b} are disjoint sets for productions from B.
Definition 4.2.1 (A LL(1) grammar without ε-rules) A CFG without ε-rules is a LL(1) grammar if for all production rules of the form: A → (α1)/ (α2)/ … / (αn) the sets FIRST(α1),FIRST(α2), …, FIRST(αn), are pair-wise disjoint, i.e. FIRST(αi) ∩ FIRST(αj) = ɸ, for i ≠ j.
We need to use a modified parsing function:
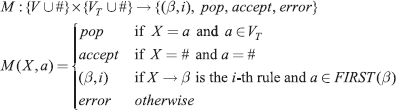
The parsing table for the example grammar is given in Fig. 4.7.
a-> a b c d e #
X ----------------------------------------------------------
S (ABe,1) (ABe,1) (ABe,1)
A (AS,3) (c,4) (dB,2)
B (AS,5) (b,6) (AS,5) (AS,5)
a pop
b pop
c pop
d pop
e pop
# accept
-----------------------------------------------------------
Fig. 4.7 Parsing function M(X, a) for LL(1) grammar w/o ε-rules
4.2.5 LL(1) Grammars with ε-rules
The definition of the FIRST(α) set is to be extended to include zero length strings:
Example
Consider the following grammar:
0. S′ -> A#
1. A -> iB = e
2. B -> SB
3. B -> <empty>
4. S -> [eC]
5. S -> .i
6. C -> eC
7. C -> <empty>
Here, we have the following FIRST() functions:
FIRST(A#) = {i} FIRST(<empty>) = {<empty>}
FIRST(iB = e) = {i} FIRST(eC) = {e} FIRST(.i) = {.}
FIRST(SB) = {[.} FIRST([eC]) = {[}
Note that in this grammar we have two nullable non-terminals – B and C. We use a name VNε for the set of Nullable-NT and say that B, C ∈ VNε.
For the grammar without ε-rules, we selected productions based on some a ∈ FIRST(β), where there was a production B →β. Here, in a grammar with ε-rules, we have B → A … and A → ε. Then our test should be modified – we should check which symbol follows A in some production B → AG, …. A → ε. Then to find M(B, a) we should see if G →a …. That means we should define a FOLLOW(A) set.
For a Nullable-NT A, we define
Thus for our example grammar, FOLLOW(C) = {]} (see rule (4) below) and FOLLOW(B) = {=}. Suppose the input string is i[e]=e#. Its leftmost derivation is
A# => iB = e# => iSB = e# => i[eC]B = e# => i[e]B = e# => i[e] = e#
This gives us a hint about how to define the FOLLOW() set table.
Finding FIRST(α) Set
A more complete, recursive, formal definition of FIRST() function, useful for developing algorithms is given below:
- FIRST(a) = {a}, if a ∈ (VT ∪ {ε}).
- If there is a production A → aα, where a ∈ VT and α ∈ V*, then a ∈ FIRST(A).
- If there is a production A → Bα, where B ∈ VN and α ∈ V*, then ∀b ∈ FIRST(B), b ∈ FIRST(A), i.e. FIRST(B) ∩ FIRST(A).
- Generalization of rule (3): If there is a production A → β Xα, where
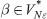 (i.e. contains Nullable-NT only), X ∈ (VN ∪ VT) and α ∈ V*, then FIRST(A) includes FIRST(X) ∪ FIRST(β)
(i.e. contains Nullable-NT only), X ∈ (VN ∪ VT) and α ∈ V*, then FIRST(A) includes FIRST(X) ∪ FIRST(β)
Note that that ε ∈ FIRST(B) if B ∈ VNε.
Finding FOLLOW(a) Set
A recursive definition of FOLLOW() set is:
- If S is the starting symbol, then # ∈ FOLLOW(S).
- If there is a production of the form A → … BX …, where B ∈ VN and X ∈ V, then FIRST(X) ⊆ FOLLOW{B).
- Generalization of rule (2): If there is a production of the form A → … BβX…, where B ∈ VN , and X ∈ V, then FOLLOW(B) includes FIRST(X) ∪ FIRST(β).
- If there is a production of the form A → … B, where B ∈ VN „ then ∀a ∈ FOLLOW(A), a ∈ FOLLOW(B), i.e. FOLLOW(A) ⊆ FOLLOW(B).
- Generalization of rule (4): If there is a production of the form A → … Bβ, where B ∈ VN and , then FOLLOW(A) ⊆ FOLLOW(B), FIRST(β) ⊆ FOLLOW(B).
There is one exception to be noted: consider a production of the form A → … AB. Here, FIRST(B) ≠ FOLLOW(A) and rule (4) says FOLLOW(A) ≠ FOLLOW(B). Then FIRST(B) ≠ FOLLOW(B). In this case, such FIRST(B) should be subtracted from FOLLOW(B) while testing for LL(1) property.
Table 4.5 shows parsing of the sentence i[e] = e#.
![Parsing of example sentence i[e] = e](http://imgdetail.ebookreading.net/software_development/52/9789332510463/9789332510463__compilers-principles-and__9789332510463__images__pg88_img01.png)
Definition 4.2.2 (LL(1) grammar) A CFG is LL(1) if for each pair of rules for some non-terminal A, A → α and A → β,
FIRST(α FOLLOW(A)) ∩ FIRST(β FOLLOW(A)) = Ø
or, or all rules A → α1 | α2 | … | αn
- FIRST(αi) ∩ FIRST(αj) = Ø for I ≠j, and further, if
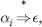 then
then - FIRST(αj) ∩ FOLLOW(A) = Ø, ∀j ≠ i.
The parsing function M is now defined as
