
A Job to Do

Emily has been given a huge business process diagram by a business analyst, who explains that the diagram maps the sequence of work activities that Emily’s department supposedly performs. The map is a plotter-sized roll of paper with many boxes joined by branching and intersecting lines. There are lots of confusing symbols that refer to specific actions and conditions, so the business analyst has given her another sheet of paper that attempts to explain what each of the symbols means. Emily finds the definitions of the symbols just as confusing, but after looking at the map for an hour or so she begins to understand it.16
The business process map includes several different transactions and information services, all joined together in a complex end-to-end process. Emily finds the activities that seem to match the work involved in the transaction that she is presently working on. The map seems to be a complex and confusing way to represent a business process, which Emily had always thought of as fairly straightforward.
Part of the problem is that there is no standardization of the terms used to describe each activity on the map. For example, activities that involve some sort of validation are given a mixture of verbs such as ‘validate’, ‘verify’, ‘confirm’, and ‘accept’. Wouldn’t it be less confusing if the process map picked one of these words and used it for all those activities?
It also occurs to Emily that one kind of validation task consists of similar work to another kind of validation – the variation is only the specific data fields that need to be validated in the different validation tasks. Similarly, a task labeled ‘Approve awarding of grant’ sounds like it might be a very similar task to ‘License approval’, it is only what is being approved that changes. In both cases decision tasks need to be performed by a properly authorized person and the result of the task is that it is either approved or not.
Emily begins to think that there must be a simpler way to structure the business process, but she is not sure how.
Getting down to work
So far in this book, we have seen how a transaction will change its status as it progresses through the request and response parts of the processing. A transaction progresses by work being performed on it, such as validating the data or sending the response to the customer. We use the generic term task for the work activities that are performed to process a transaction. In this chapter, we will discover how the tasks performed in each phase of a transaction can be standardized and added to our generic Transaction Pattern.
Tasks performed by people (or by machines) move a transaction from one status to another, as shown in Figure 6-1. These tasks are arranged in a predefined sequence so that the work happens in a sensible and efficient order every time. An efficient business performs the same tasks in the same order, with variations only for exceptions that cause the transaction to take a different path from the normal one.

While the transaction has a specific status, only certain types of work can be performed on it – that is, the status controls what work can be performed. Some tasks are not applicable when the transaction is in a particular status. To take some obvious examples: an application cannot be evaluated before it has been submitted; an order cannot be fulfilled before it has been received and validated.
The tasks that are performed, and the sequence of those tasks, conform to a pattern that is similar for most types of request-and-response transactions. The Transaction Pattern names these tasks using generic labels. For example, the task in which the customer completes a web form is labeled ‘Preparation’, meaning ‘preparation of the customer’s request’. The same label can be applied to the equivalent task in a different transaction, such as when items are added to a shopping cart at an online retailer. ‘Preparation’ is also a good generic label for the task when a customer fills in the details of a transfer of funds that they want to carry out on their bank’s website.
The automated digitized activity that validates the information on a web form before the customer submits it is named the ‘Pre-submission Validation’ task. Following submission of the customer’s request, further validation may be needed that cannot be automated – this task is named ‘Post-submission Validation’.
While a transaction has the Initiated status, only tasks such as entering data on a form, or adding items to an order, can be performed. Because the transaction has not yet reached the Submitted status, tasks that the business performs in the back office are not relevant at this stage. Back-office tasks include assessing the customer’s request, making a decision, and notifying the customer of the decision.
The tasks that the back-office staff perform are also governed by the status of the transaction. For instance, the decision-making task – ‘Approval’ – can only be performed when the transaction has the Accepted status. The Transaction Pattern contains a small number of generic tasks in each phase of a request-and-response transaction. These basic rules, about what tasks can be performed when the transaction has each possible status, are illustrated in Figure 6-2, which shows all the possible tasks in every phase of the transaction.
Note that there is an implied top-down sequence of tasks within each of the five phases. The task sequencing shown is not rigid, however. There may be legitimate reasons to sequence the tasks differently in a specific transaction.

In the following sections we delve into the details of the tasks in each phase of the generic Transaction Pattern. Readers may want to refer to Figure 6-2 often throughout this chapter.
Initiate phase
The first major part of the transaction – the request – occurs in the front office of the business. In a physical front office, the Request Stage is where the customer tells the clerk at the counter what they want, for example by filling in a form or explaining their need verbally. The online channel has a virtual equivalent of this physical activity, such as a web form that is completed and submitted without any direct interaction with a clerk. There is a contemporary trend towards supporting online transactions using automated ‘chatbots’ and human-driven instant ‘chat’ features.
The most common first step when initiating a new transaction is to identify the customer who is making the request. This task is called Identification. This task seeks answers to questions such as:
- Who are you?
- Are you allowed to conduct this transaction?
- Do we know anything special about you already?
In some instances, such as making a complaint about a third party, the business may allow the customer to remain anonymous. In that case, a task for identifying the customer is not required. Another type of transaction may allow the customer making the request to be a representative of another person or organization. The latter party is the subject of the transaction. For example, a person lodging a tax return may be the agent for the person or organization whose tax return it is. Both the subject and the submitter of the transaction would usually be identified. We describe these so-called ‘roles’ later in this chapter.
In services that are made available online, a typical mechanism for identifying the submitter is to ask them to login before any processing occurs. This enables the business to retrieve the customer’s details from its database and to make use of that data during the transaction, such as pre-filling a form or customizing the experience to the known preferences of the customer.
Identifying that a known customer is commencing the transaction enables the business to apply a profile to the customer, through a task called Profiling. Perhaps this customer is good for repeat business and we want to give them special care and privileges. Perhaps the customer is a known credit risk or is under investigation for fraud – in either case, different actions may be taken during the transaction to protect the business from risk.
Sometimes, a transaction is started by a scheduled calendar event or initiated by the business rather than the customer. An example of this kind of transaction is a social welfare body that periodically reviews their clients’ continuing need to receive support. A task named Commencement Notification sends a correspondence to the customer notifying them to report for an interview or to submit a form with their latest details.
Once the tasks of the Initiate phase are completed – Identification, Profiling, and Commencement Notification – our transaction moves into the Initiated status, and it is ready to commence the Submit phase.
Submit phase
The key activity of the Submit phase of a transaction is collecting the information that is needed to process the customer’s request. This task is called Preparation and it is where the customer states what they want and provides the information the business requires. A common mechanism for this is a paper form or its online equivalent – for example, a form to open a new bank account, an order form, a driver’s license application form, a birth registration form, and so on.
Frequently, form designers seize the opportunity to collect additional information on the form that is not actually needed to process the transaction. It is tempting to do this, as the data ‘might be useful to have’. Often, this additional data is not used, or the quality of the data is paid little attention. The result is that the business collects extra data pointlessly and wastes the customer’s time. Emily keeps a watchful eye out for people asking for extra data fields when they are unsure how the data will be used.
Once the customer’s request has been prepared, some checks need to be performed to ensure that the data in the request is valid. We call this task Pre-submission Validation. See Validating before processing below for more details on validations. The final task in the Submit phase is Acknowledgement. This is where a notification is sent to the submitter acknowledging the receipt of a submission and typically also informing them of what happens next.
Once the tasks of the Submit phase are completed – Preparation, Pre-submission Validation, and Acknowledgement – the transaction moves into the Submitted state. This completes the customer’s request and they now take a back seat in the transaction while the business responds to their request. The change to the Submitted status serves as a clear marker that separates the Request Stage of the transaction from the Response Stage.
Validating before processing
Before allowing the transaction to move from the Request stage into the Response stage, validations are performed on the contents of the Request. The submitted data might be validated either before or after submission occurs, or perhaps both. The change of status from Initiated to Submitted occurs between these two validation activities.
Validation of the collected information prior to allowing the customer to submit their request is important for correcting any data quality issues at the source, rather than allowing poor quality data to penetrate the business. For example, this validation check is what happens when a website asks you to enter some information twice, such as your email address, twice. A similar validation occurs when a website requires you to enter only part of an address and you select the correct complete address from a list. Prior to submission, there is an opportunity to ask the customer to correct any invalid or incomplete data, and to check that the information they have entered is correct. If a customer is allowed to proceed without this validation step, data quality issues can result in inefficiencies (through the need to seek further information from the customer) and ineffective evaluation and fulfilment of the request.
This Pre-submission Validation activity can take two forms:
- asking the customer to review the information before finalizing the submission, and
- using business rules to validate data such as addresses and dates, and to ensure that the data presented is complete and internally consistent.
When a paper form is submitted in person, this validation activity is performed by a clerk at the front desk checking the form while the customer is present. With computerized submission systems, automated rules are built into the system to perform the necessary checks and the submitter is alerted to errors and given the opportunity to correct the data before trying again to submit the request. When the customer’s request is successfully lodged with no failed validation checks, the transaction flips from the Initiated status into the Submitted status.
Validate phase
The next activity that usually occurs is to perform any further validation checks that could not be performed prior to submission. An example of Post-submission Validation is where an attachment is required as part of the customer’s request (e.g. a birth certificate in support of a passport application). Pre-submission Validation checks can only ensure that a document is attached, but after submission the content of the attachment needs to be viewed by a person to ensure it is the correct document. (In the in-person channel, this check would be performed by the front office clerk receiving the submission. If the service is online, the validation occurs in the back office after submission.) Post-submission validations typically require a human to do something and consequently the validation rules are difficult to automate.
If these post-submission validations fail, then the customer can be contacted to obtain further information. Otherwise, another notification may be sent to the customer to confirm that the submission has been accepted and has commenced processing. This task is called Acceptance and the transaction can move onto the evaluation and decision tasks of the Decide Phase – i.e. the transaction moves from the Submitted to the Accepted status.
Decide phase
Once the customer’s request has been accepted, it needs to be classified so that the transaction can be directed to the appropriate teams and personnel to carry out the work of processing it. This task is called Classification. Classification may be automated if suitable tools are available; otherwise, a person will be tasked with performing this job.
A simple example is an insurance company, where motor vehicle claims are directed to the motor vehicle claim team, while life claims are directed to the life claim team. Applying a refinement on this work management regime could, for example, distinguish among motor vehicle claims further, allowing them to be classified as either low-value or high-value. A high-value claim presents a greater risk to the insurer, so more attention – or attention from a more senior officer – is given to it. A low-value claim could be assessed by junior staff or even approved automatically by systems equipped with business rules and loss calculators. To perform this traffic-directing job, the Classification task creates the required work tasks of the Decide and Complete Phases and assigns each one to the correct team.
The next task in the Decide Phase is called Evaluation. Prior to making a decision on the customer’s request, it may be necessary to assess the customer’s submitted information against predetermined criteria. The Evaluation task is often where most of the work is done in processing a transaction. Some types of transactions require only a short and simple evaluation, while others may be far more complex and involve multiple people, such as an application for a home loan which is assessed (by different teams) for credit-worthiness, property value, and risk. Although such an evaluation is complex, it is helpful from a requirements perspective to think of each part as a sub-task of the Evaluation task. This ensures that the designers and implementers don’t confuse evaluation activities with decision-making activities.
After Evaluation, the decision-maker performs the Approval task, sometimes preceded by a Recommendation task. These three tasks are separate because the decision-maker may be a different person to the one performing the Evaluation task, and there may need to be a third person involved who checks the work done in the Evaluation task. The assessor makes their evaluation, then the recommender may recommend a decision to the decision-maker. This is an often-used mechanism to separate the duties of different workers in higher-risk processes, to maintain integrity and honesty. For example, this technique is used in banks when assessing the risk and suitability of a home loan application. In the public sector and larger corporations, where decisions are always attributed to the chief executive, this mechanism is employed to constrain the number of people holding the delegation to act on behalf of the chief executive, and to ensure that someone is accountable for all decisions made. Therefore, there are often two distinct roles performing the Evaluation and Approval tasks (and a third role if a separate Recommendation task is required) and these work tasks must be assigned to different teams or individuals.
In the Approval task, the authorized decision-maker usually has two options: they make a decision based on the recommendation, or they reject it and return it for further evaluation work. In the latter case, the tasks of the Decide phase are repeated until the approver has enough information to decide. The approver’s decision finishes the tasks of the Decide phase – Classification, Evaluation, Recommendation, and Approval. The transaction changes its status to Decided and moves into the Complete Phase. (Note that we use the status ‘Decided’ so that the transaction status is clearly distinct from the outcome of the approver’s decision – the outcome should be a separate data item.)
Complete phase
This is the point of no return – now that the decision has been made, the business must carry out all the tasks in the Complete phase that ‘wrap up’ the processing of the transaction. The Complete phase puts the decision into effect and we should not be able to halt these actions. If this were permitted, the effect of the decision would be incomplete. For example, there should be no choice about whether to send a letter notifying a customer that their application for a license has been approved or declined. Likewise, once an insurance claim has been approved, there is no choice about making a payment to the claimant: it must happen.
The tasks within the Complete phase often include sending a letter or other notification to the customer notifying them of the decision, a task called Notification. Some examples of post-decision notifications are:
- an email confirming that an order has been fulfilled and shipped;
- a letter of offer for a new home loan with the terms of the loan attached;
- a letter rejecting an insurance claim containing an explanation of the reasons for the adverse decision and any recourse that is now available to the customer if they are dissatisfied.
Since most transactions will cause a change to occur in the master data (as discussed in Chapter 2), activities in the Complete Phase usually include committing any changes of master data to the database. This task is called Record Creation. A decision to award a license will create a permanent record of the new license, linked to the customer’s master record. A decision to change the bank account that will receive government payments, will cause the new bank account to be recorded and linked to the customer’s payment schedule. A decision to approve the assessment of an insurance loss will cause the payment amount to be calculated and recorded.
If the business is required to make a payment as a result of the decision, this work is performed by the Payment task. The amount of the payment may or may not have been calculated prior to approval by the decision-maker. If not, the payment amount is calculated in the Payment task, followed by execution of the payment, perhaps through sending a message to the Accounts Payable function or creating an invoice directly in the finance system through an automated interface.
Another common action that must be performed after the decision is made is scheduling an activity that will need to occur in the future. This task is called Future Activity Scheduling. In the case of issuing a new license, which typically will have an expiration date, a future action will be placed in the calendar to send a reminder to the licensee one month prior to the expiration date. This Future Activity Scheduling task is the final step of the transaction. When the reminder is sent on the scheduled date, it triggers a new transaction, perhaps called Renew License.
The activities that occur during the Complete phase – Notification, Record Creation, Payment, and Future Activity Scheduling – bring the transaction to a close. The transaction moves to the Completed status and no further action occurs.
Like transactions, tasks also have a status
When creating and managing a work task, the team (and the workflow management system if there is one) need to know the status of the task, since the current status will determine what can or should be done with the task. Therefore, a task must always have a valid status.
The Transaction Pattern constrains task statuses to a small, well-defined set of values which must be the same for all tasks across all transactions. This approach considerably simplifies the implementation of workflow control systems and the day-to-day management of operations. The following table lists the suggested set of valid statuses for tasks. At any point in time, a task must have one of the statuses listed in Table 6-1.
Using this set of task statuses, a task moves through a prescribed sequence of statuses. There needs to be some rules about the direction of the sequence of statuses and what task status can follow another task status. For example, a task cannot reach the In Progress status without first being Assigned, and it can only move to the Done status from the In Progress status.
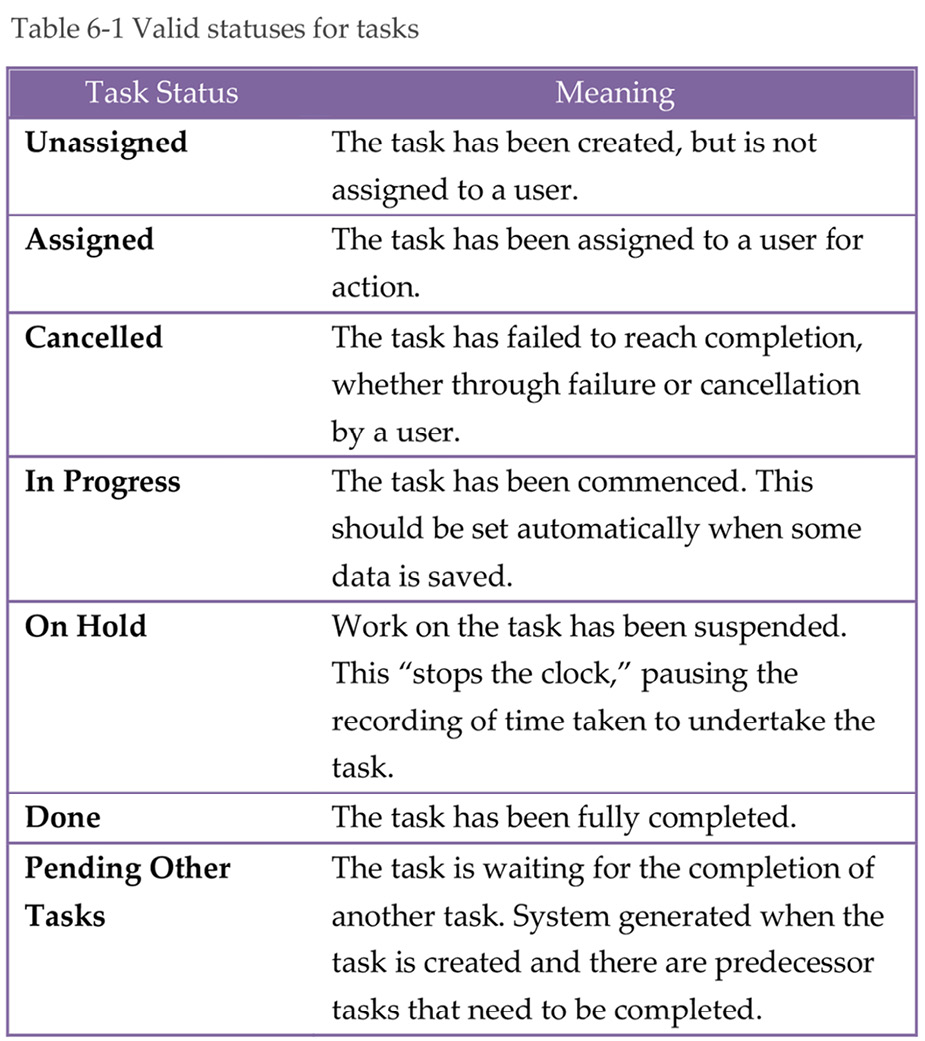
Figure 6-3 shows an example of how a task may transition from one status to another; the lines represent the allowable transitions from one status to another. The dashed lines show the possible paths by which a task may be cancelled – obviously, a task cannot be cancelled if it is already done.

Defining the task statuses that are going to be allowed, and how tasks may transition from one status to another, are important steps to create uniformity in how work is managed. This approach will also simplify the management of work, so that work is never lost or forgotten.
The flow of work tasks through the workplace
So far in this chapter we have discussed how each phase of the Transaction Pattern consists of a pre-defined set of generic work tasks, such as the Post-submission Validation and Acceptance tasks in the Validate phase, and how each task must have a current status so it can be tracked. Now, Emily wonders how these tasks can be distributed to the correct people to do the work. After all, she would not want an Evaluation task to be assigned to a junior staff member whose skills are limited to validating the customer’s submission, not evaluating it.
Within the internal process journey, the work that team members need to perform is usually organized and routed in an orderly and repeatable way. Once one task has been completed, the transaction is passed onto another person to perform the next task. This system is commonly referred to as workflow. Sophisticated organizations with high volumes of operational processing often automate the business rules that control the flow of work around the teams. Sometimes a machine performs a task, but it, too, needs to be told when to do something.
The central concepts in managing work are tasks, users, and queues. A task is a discrete piece of work that is usually undertaken by a single person. Since, in digitized services at least, the customer or a third-party supplier may perform some tasks (as we described above in the section on submitting the customer’s request), we use the general term user to refer to the people both inside and outside the business who perform tasks. Users have certain characteristics determined by their job role, their experience and competence level, and their authority to perform certain duties.
A task queue is a practical mechanism to link tasks with users. Queues ensure that users receive the tasks that are relevant to them. Tasks, when ready to be undertaken, are distributed to the appropriate queue to await their turn for attention, just like a queue of people at a store.
A queue is simply a list of tasks in priority order. The default order is usually ‘first-in-first-out’. Priorities can be changed for any number of reasons, however, such as when a task reaches its overdue date, or the customer has requested increased urgency.
Users are attached to – made members of – one or more queues, as required by the duties of their jobs. When a user becomes a member of a queue, they can receive any tasks that have been assigned to that queue. It is common to assign responsibility for the supervision of a queue to a manager. A queue may be managed in three ways:
- A team leader responsible for managing the tasks in the queue may assign a task to a specific user in their team – this is known as Task Assignment.
- A user within the team may ‘pick’ a task they would like to perform from the team’s queue – this is called Task Picking.
- Automated queue manager software prioritizes tasks in a queue, then a member of the queue uses a ‘Get Next Task’ feature that allocates the highest priority task to them – this is called Task Allocation.
These mechanisms result in a task being allocated to, or ‘owned by’, an individual user. The queue performs an intermediary function that avoids the need to assign tasks directly to individual users. Without queues, there is a high risk that tasks may be left ‘hanging’ when a user is absent from work or has been given a high workload. Whereas when queues are employed, the tasks will be picked up by whichever members of the queue are at work that day and available for new work.
Tasks, queues, users, and workflow are supported by work management capabilities built into business systems. Workflow specifies the sequencing of tasks and the skill or authorizations required to perform the task. Work management tools facilitate the movement of tasks to the most appropriate queues in the correct order, creating what is known as a ‘sequence of operations’. For this discussion, it is helpful to think of a workflow or a sequence of operations as the same thing as a business process. Tasks, queues and sequenced workflow are effectively an implemented business process.
The desired workflow is designed and configured in the work management system. In operational use, a task, once created and ready to be undertaken, is routed to the appropriate queue at the appropriate time by the workflow tool. The completion of a task triggers the routing of the next task in the transaction to its appropriate queue, in the sequence prescribed by the workflow.
A task that must be performed by a specific business role, such as someone who holds a decision-making authorization, would be assigned to the specific role rather than to a queue. We could think of this case as a queue that has only one member. A person is usually assigned to an authorized role in the Human Resources system for the period they occupy the role. It is common in larger organizations to find people occupying roles temporarily. The queue management software will look up the current occupant of the role and allocate the task to them. This mechanism abstracts the role away from the actual occupant, so the business rules in the queue manager don’t need to change when the occupant changes – only the data in the Human Resources system.
The Transaction Pattern encourages a disciplined approach to designing and implementing workflows, through its pre-defined task structure. The pattern defines the task that is due to be performed once a transaction has reached a certain status. For example, when a transaction moves into a Submitted state, the next task that should be performed is called Post-submission Validation (if applicable for that type of transaction). The specific work that needs to be carried out by the worker is specified by the requirements of the transaction – e.g. the business rules that must be checked to validate the contents of the customer’s submitted request. All that is required to be defined in the workflow is the queue to which the Post-submission Validation task is to be sent.
If the submission passes the validation rules, then the Transaction Pattern indicates that the next action is the Acceptance task. This is a written communication sent to the submitter, if required, acknowledging that the request has been received and accepted for processing. The workflow design that needs to be specified is the queue that the Acceptance task is sent to, or – even better – the computer service that will automatically generate and dispatch the notification. (The exact wording and layout of the notification are specified in the requirements document. Chapter 9 suggests techniques and formats for constructing the transaction requirements document.)
In this way, the structure provided by the Transaction Pattern simplifies the specification of workflow requirements. The documentation of the workflow requirements will also simplify the development of test cases for testing that the workflow mechanism performs correctly once implemented.
The data about transactions and tasks can be generalized
So far in this chapter, we have learned how transactions are processed by a generic pattern of work tasks and how those tasks are directed to the right teams. Now, we return to the matter of data, which we explored in Chapter 2. Emily remembers that master data and data about transactions are fundamentally different. Master data waits to be used or amended by a transaction – master data never changes unless a transaction does something to it. On the other hand, transaction data changes frequently while a transaction is active but then does not change at all. After a time, transaction data may have little value to the business and can be archived.
Emily understands clearly now what master data is, but she is still hazy about what information is stored in transaction data and for what kinds of things it might be used. In this chapter we have seen that a transaction generates work tasks for an operations team. So, transaction data keeps track of the processing that has occurred, and still needs to occur, during the life of the transaction. While a transaction is in progress, the users (and the systems that perform automated tasks) need to know what tasks have been done so far and what should be done next. This section describes a generic structure for holding data about transactions and the tasks that are associated with them.
There is nothing too complex about storing transaction data; therefore it can be managed in a generic structure that suits all kinds of transactions. A transaction has a status, a set of roles that various internal and external parties play during the transaction, and a collection of business tasks that do the work of processing the transaction. Transactions may optionally have one or more documents that are attached to them: the attachments could include, for example, documentary evidence supporting the customer’s request (such as a birth certificate) and documents produced by the business for internal operational reasons or for notifying the customer of a decision. A model of these straightforward data concepts is shown in Figure 6-4.

First, let’s explain the notation that we use for the diagrams in this section.17 Figure 6-4 is called a ‘business data model’ and it shows the key data subjects (i.e. the ‘things’ about which data is stored) and how they relate to each other.18 Data subjects help us to distinguish apples and oranges in our minds, so to speak. It is a convention to capitalize the nouns in a data model, and when you refer to the data subject in text it is also capitalized.
Each data subject is shown as a box. The lines joining the boxes indicate relationships between data subjects; relationships are labeled using a verb. When you combine the nouns in the boxes and the label of a relationship line, reading from the side closest to the relationship label, you have a complete sentence. For example, the line from Transaction Status to Transaction is read as: ‘A Transaction Status holds the status of a Transaction’. The ends of lines indicate how many of the things at that end are allowed, as in: ‘A Transaction is processed by at least one Task’. The dashed line indicates an optional relationship, as in: ‘An Attachment may be attached to a Transaction’.
Now that we understand how to read a business data model, Figure 6-4 should be read as follows:
- A Transaction Status holds the current status of a Transaction – i.e. a Transaction will have different statuses at different times, but only one at a time;
- There may be several Parties (people or organizations) that have a role in a Transaction, and a Party may have a role in more than one Transaction (more on roles later in this chapter);
- One or more Attachments may be attached to a Transaction;
- A Transaction is processed by one or more Tasks.
Figure 6-4 shows that multiple Tasks may occur during the processing of a Transaction. Tasks also have some other data associated with them, which we illustrate in the business data model in Figure 6-5. Like transaction data, data about tasks is also fairly simple data.
A Task is described by a few data elements, including its type and status (e.g. not started, in-progress, completed), the work queue the task is assigned to, and the actual person who performed the task. The structure of task data is completely generic, since all tasks are essentially the same, just as all apples are essentially the same and can be described by a few descriptors such as color, size, and variety. It is only the content – what task, who does it – that varies between tasks.
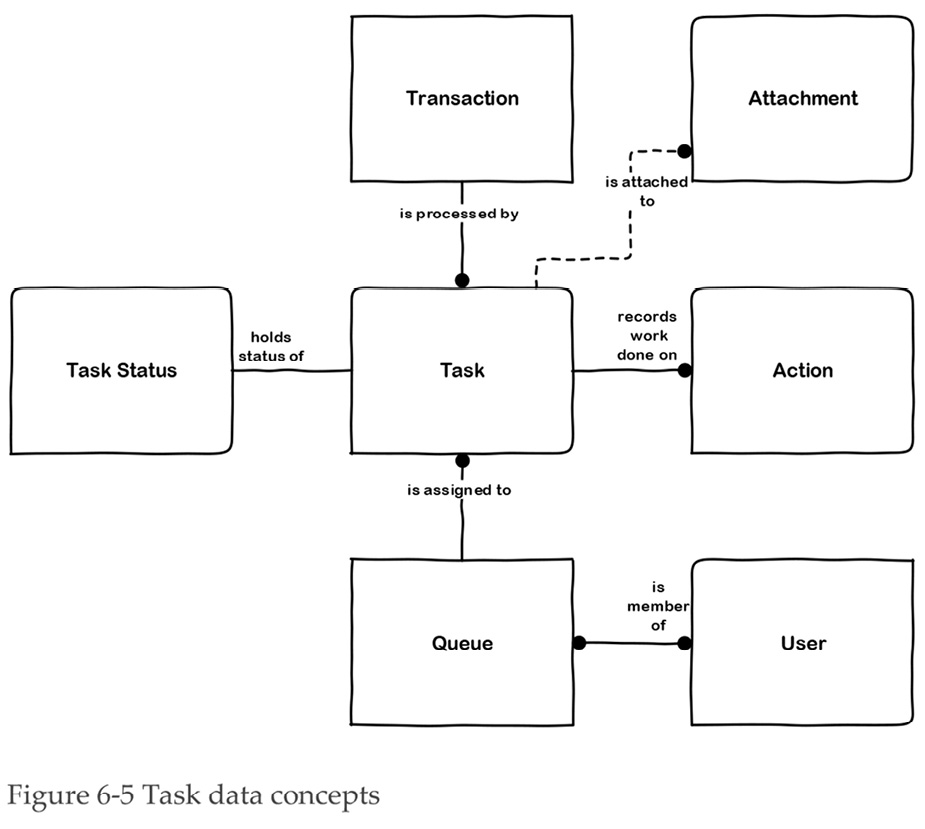
Task data stores the following information:
- When was the task carried out and who carried it out
- What was the result
- Which subsequent task was triggered
- What artifacts were produced
- What structured data was created
- What documents were attached to the task
The business data model in Figure 6-5 shows that each Task has its own Task Status. An Action holds information about what a User did during the completion of a Task; for example, when the User makes notes in the system about why they did something. Queues contain lists of Tasks, while Users are members of one or more Queues. A Task may also have one or more Attachments.
The task data will hold a reference to the relevant Transaction and this will give the User quick access to the information they need to do their Task. Once the Task has been completed, the User will mark the Task as ‘Done’. The Transaction holds information about the next planned Task in the sequence. When the Task is marked as ‘Done’, the next Task can be released to the appropriate Queue to get the next piece of work underway. In this way, the data about Transactions and Tasks can control the workflow.
You will note that Transaction and Task occur in both Figure 6-4 and Figure 6-5. The figures could have been combined into a single business data model, but we have separated them for easier explanation. Figure 6-6 shows the complete business data model for Transaction and Task data. The generic data structure described here can be built or configured into most databases and off-the-shelf business systems. If your project achieves this, the structure will facilitate easier and more accurate operational management reports.
Bringing all these ideas together
By now, Emily is feeling confused about all the ideas we have discussed in this chapter and in Part I. She needs to see how the ideas relate to each other and how, all together, they comprise an easy-to-use framework.

Figure 6-7 illustrates how the ideas that we have described so far hang together. To understand this diagram, read the text on the left from the top down, glancing at the graphics on the right as you go. The flow down the page reads like this:
- a customer initiates a transaction,
- a transaction creates tasks,
- tasks are allocated to queues,
- users in teams perform queued tasks,
- when each task is completed, the workflow moves along and the transaction’s status progresses,
- until the transaction has been completed.

All kinds of transactions conform to the pattern shown in Figure 6-7. Efficient operations teams organize the back office along these lines, using work tasks, queues, teams, users, and status tracking. The Transaction Pattern points to a generic way in which work can be organized and – importantly – inserts two new ideas:
- Status tracking can be made uniform across all transactions and tasks, and
- The customer also performs tasks.
Emily ‘gets’ how these ideas are linked together to form a coherent framework. There is one final idea that we need to address in this chapter – the roles that people and organizations play in a transaction.
Roles people play
We have discussed how two stakeholders always participate in a transaction. These stakeholders might be a customer and a business, or a business and another business, or a person and another person. As well as the two key stakeholders, several individuals may be involved in submitting and processing a transaction. These people perform the tasks that move a transaction through its sequence of states, from Initiated to Completed.
During the Request stage of the transaction, a person performs the tasks of initiating the transaction and completing the information required. In the case of the online shop example, the shopper is creating and submitting the order. However, they may be doing this on behalf of another person who will pay for the items and own them. We could call these roles ‘the buyer’ and ‘the payer’.
When registering the birth of a child, a parent is informing the registrar about the birth of a third party, the baby. The parent is playing an active role in the transaction. The child – who is the subject of the transaction – has a role as well, albeit a passive one. In some circumstances, a person who is not the child’s parent may register the birth. Since this is possible, it would create difficulty if we labeled the role as ‘the parent’. A more generic way to name the roles of the parent and the child is as ‘the informant’ and ‘the subject’ respectively. In this way, the child, the parent and the informant can all be different people.
When applying for a permit to operate a restaurant, the person providing the information for the application might be one of the operators of the restaurant, or an employee, or an agent of the owner. We might label these roles generically as ‘the submitter’ and ‘the applicant’. If the application is successful, the permit will be granted to the operator – ‘the applicant’ – not to the individual who lodged the application – ‘the submitter’. Therefore, it is important that the transaction carries information about both the applicant and the person that presented the application.
As these examples demonstrate, there is a wide variety of labels that we could use to name the roles that people and organizations play during a transaction. However, this variety can create problems for us when we want to look across different transactional services. For example, ‘the parent’ of a birth, ‘the celebrant’ of a marriage, and ‘the funeral director’ of a death are all doing something similar – that is, submitting information about a life event to the registrar of births, deaths, and marriages. If we wanted to unify our systems and processes so that they handled all three of these events, we would need to use a more generic label for the roles, such as ‘the informant’ or ‘the submitter’.
However, a role name such as ‘the informant’ may not be generic enough for other transactions for which the term ‘the informant’ is inappropriate. For example, when a person requests a copy of their birth certificate, their role is not ‘the informant’, since they are not providing information to the registrar. They are submitting a request for a certified copy of information already held by the registrar.
We can generalize the names for these roles even further, so that they can be applied to any type of transaction. The generic role names that we use in the Transaction Pattern are:
- the subject (meaning the party who the transaction is about)
- the submitter (meaning the person that initiated and lodged the transaction)
- the responsible party (meaning the person or organization who carries responsibility for the affairs of the subject, if applicable).
When ordering goods from an online shop, the submitter is likely to be the same person as the subject. When registering a birth, the submitter might be a midwife, the parent is the responsible party, while the subject is the new baby. In registering a new company, the subject is the company itself, while the submitter might be a director or an office assistant. When applying for a disability pension, the subject is the person with disability, the submitter is whoever submits the application (possibly the person’s parent, caregiver, or legal guardian), and the responsible party would be the subject’s parent or legal guardian, if the subject cannot manage their own affairs.
A final role to consider is called the approver. It is often important to record the name of the person that performed the Approval task. The reasons for recording the approver’s name include a desire to show accountability for decisions. The person assigned the approver role must hold the decision-making power associated with this type of transaction. For example, if the transaction concerns the payment of money, the person who holds the approver role needs to have the appropriate level of spending delegation.
The names of the subject, the submitter, the responsible party (if applicable), and the approver are held in the data about the transaction. These four names are Parties that have a role in the transaction and therefore – recalling the business data model we saw in Figure 6-6 – a Transaction may have four Parties associated with it.
Three key points from this chapter
- The Transaction Pattern includes sixteen generic work tasks which are undertaken during the five phases of a transaction.
- The key concepts in managing work are Tasks, Users, and Queues. A task is placed on a queue, at which point a user can be allocated to the task because they are a member of the queue. The queue is an intermediary that avoids the need to assign tasks directly to people. Orchestrated workflows control the movement and assignment of tasks to queues.
- The essential roles associated with most transactions are Subject, Submitter, Responsible Party, and Approver – these roles are always named individuals or organizations.
Further reading
Ambler, Scott, (2018) “Data Modelling 101”. Retrieved from: https://bit.ly/2KNUVYG.
Simsion, Graeme & Graham Witt. (2006) “Data Modeling Essentials”, 3rd Edition. Morgan Kaufmann.
Workflow, in Wikipedia. Retrieved from https://bit.ly/2fnUeGK.