
Trading Sheep in Sumer
Emily is confused. She knows that the systems she uses every day exist to ‘capture’ data, but why? What is this wild beast that needs to be captured? Why are the data entry screens filled with so many data fields, and is all of it necessary? Does anyone use it? For what purpose? Is some data more important than other data?
Transactions create data
At the heart of every transaction lies data that needs to be managed. Transactions cause the updating of data of some sort or another. In this chapter we explain why it is vital to be aware of the data involved in a transaction and to manage that data appropriately.

Figure 2-1 A map of the ancient Middle East showing Sumer 2
The farmers of ancient Sumer understood data. 10,000 years ago, when agriculture developed, Sumerian farmers needed a way to record their animals and goods. A plainly shaped clay token was developed to represent an animal or a container of grain.
Around 6,000 years ago, clay tokens became more sophisticated and varied in shape. As the production of goods increased, their exchange became more commonplace, and a more efficient way of recording exchanges was necessary. Traders began to place several tokens within a baked clay envelope called a ‘bulla’. Impressions were made on the outside of the bulla so that people knew what was inside.

Figure 2-2 Sumerian bulla and contents3
Embossed seals represented the parties to the transaction. A bulla had to be broken to alter the information inside, and so, an intact bulla held irrefutable evidence of the facts of a transaction should a dispute arise. Thus, the information contained in a bulla was a permanent record of a transaction of goods between parties. To Sumerian traders, data mattered.
Recording nouns
These ancient transactional records consisted of tokens that represented a thing – that is, the tokens were like nouns, the names of things. Over time, tokens representing counts of things were developed to reduce the need to make an individual token for each separate thing. With this development, the transaction for a trade of five sheep, for example, could now be represented by only two tokens rather than the five tokens previously needed – one token was required for the noun ‘sheep’ and one for the count of five, thus making a complete noun + numeral phrase.
In this way, the concept of data was born. Nothing much has changed – today we continue to record transactions using nouns and counts.
There are no verbs in this accounting ‘language’ and so the Sumerian bulla left no record of the processes the traders used to conduct their exchanges. We may lament this absence that so limits our understanding of the Sumerian trading culture; however, it is likely that trading involved only a few simple actions or processes – handing over the tokens in exchange for goods, storing the tokens inside a bulla, handing the bulla to a third party as security, and, potentially, breaking open the bulla.
Even today, our smartphones contain mostly nouns – ‘Contacts’ and ‘Photos’, for example. Actions such as turning, touching, and swiping are the processes of the phone but are not stored as data like contacts and photos. Yet using these simple actions that humans have always been able to perform, we can turn over the phone to accept a call, touch another phone and exchange contacts, swipe and delete an email. Despite their staggering technical complexity under the covers, the universal ability to use a modern phone mimics the simplicity of these early recording systems, with a series of verbs or actions that are used to process nouns or data.
Cuneiform
Records of transactions evolved into larger clay tablets inscribed with pictograms in the shape of the earlier tokens. Clay tablets rapidly replaced tokens and bulla, as tablets were much cheaper to make. Over subsequent millennia, we have developed ever more efficient methods of recording data about transactions, culminating of course in modern-day digital data.
Around 3700 BC, Sumerian people discovered that pictograms could represent sounds as well as objects or things. This significant advance, known as the Rebus Principle, enabled people to record words that were difficult to represent as pictures. Suddenly it became possible to record verbs.
By about 2500 BC, pictograms became more abstract in the form of simple wedge-shaped marks arranged in patterns. This script, known as cuneiform, was simpler and cheaper than pictograms for recording transactions as it required less space and therefore fewer materials. Over the next few centuries, writing complex sentences became possible using cuneiform – even stories and poetry began to be recorded.

Figure 2-3 Cuneiform tablet4
Cuneiform script was so useful that it was adopted by multiple cultures and languages in the Middle and Near East, and used for two and a half thousand years until the first century AD. The famous Rosetta Stone, dated at 500 BC, relates a story in three languages, all written using cuneiform script. Despite its continuous use over such a long time, cuneiform script retained its patterns of simple wedge-shaped impressions, and is remarkably reminiscent of the ones and zeros of digital data.
Data matters
As the ancient Sumerians knew, data matters far more than the processes that created it. Data ends up in a business’s financial statements, its annual reports, and its communications with customers and other stakeholders. Data fuels management decisions, both strategic and operational. Data is the critical asset that remembers your customers, your product catalogue, your financial accounts, and so on. That is, your data remembers your business.
Whether it is stored in Sumerian clay tokens, bulla, tablets, ledger books, or computer databases, data is created by transactions between stakeholders. In other words, business transactions generate the data that later can be recalled and used, not only as proof of past dealings, but also for many additional purposes, such as to summarize the last month’s or year’s transactions, to produce ‘how are we doing’ reports, and to provide the raw material for the business’s tax returns.
When a customer transacts with a business, a small shift occurs in the state of the business. An exchange of information occurs – also, perhaps, money and/or goods exchange hands. This shift in the business’s state is recorded in the business’s data. When a new customer opens a bank account, a new customer record and account record are added to the bank’s data. When the customer moves to a new house and notifies their bank, the address on the record for the customer is updated so that the customer’s account statements will be sent to the correct address.
Computer systems were primarily designed to manage these data changes. In the early days of using computers to make businesses more efficient, they were known as ‘electronic data processing systems‘. Systems were used for processing orders, processing sales, processing employees’ pay, and processing invoices. The term ‘data processing’ was – and still is – appropriate for such systems because this is essentially what computerized business systems do – they process changes to data.
As we have seen so far in this chapter, from ancient Sumer to the present day, there is nothing new about the need to record and process data. Businesses have always needed to update their records when a transaction occurs. For centuries, clay tablets and pen-and-paper provided the technology to do this important task. Data processing systems simply turned pen-and-paper ledger books, order books, and card-based stock inventories into digital bits and bytes. In the next section, we look at the different kinds of data that are managed by computers today.
Data is at the heart of a business
Data is represented in the nouns of your business. You will discover references to these data ‘nouns’ not only in data models, but throughout documents containing business processes and procedures, reports and statistics, functional structure and job titles, business systems and applications. We can refer to these nouns as ‘data subjects’, meaning the things that we keep data about.
For example, a business process named ‘Customer pays premium for insurance policy’ contains three nouns – customer, premium, and policy. (Note that insurance is a noun too, but it is special because it is behaving like an adjective, signifying a type of policy.) These nouns reflect the data that is involved in the business process, because when an insurance premium is paid, a record needs to be made of the payment, who made it, and for what purpose. That is, the premium payment data is linked to a customer record and to a policy record. Identifying the data subjects in your business is a matter of looking for the nouns.
Of course, most businesses use different words to mean the same thing – customer, client, stakeholder, buyer, purchaser, participant, etc. A wise business will define these terms carefully, including any allowed synonyms, and encourage consistent use of the terms. Many terms have clear-cut meanings, but others will always be problematic.
Take ‘student’, for example, a term that pervades the education industry. ‘Student’ can mean many different things depending on your point of view or role in the industry. To an admissions officer, ‘student’ may be a person who has been admitted to a course of study; to a teacher, ‘student’ may be a person who is enrolled in a unit they are teaching in the current semester; to an administrator, ‘student’ may be any person who has ever enrolled whether studying now or not; to the alumni association, ‘student’ means someone who has graduated and completed a course of study; to the marketing department, ‘student’ could be a person who is considering studying; and so on. This situation is fertile ground for confusion and misunderstanding.
To illustrate how confusing this can get, let’s look at the contrast between two versions of the same diagram. The first, shown in Figure 2-4, is the anarchic result of business silos using their own terms and working in isolation. Different nouns are used for the same real-world thing. The second diagram (Figure 2-5), in which common terms are used, shows a much more joined-together business that has a better prospect of delivering consistent services to students. A standardized definition of a term enables it to be used for many different purposes. As shown in Figure 2-5, the standardized term ‘Student’ is used in the college’s statement of its business objectives, the names of its services, its business processes, and the subject areas that it holds information about. This is especially valuable in the case of business design documentation, such as process maps, procedures, customer journey maps, and information models.


Just as the architect of a building will communicate both with their client and with the engineer and builder using standardized language (everyone knows what ‘door’ or ‘beam’ means), a business architect or service designer uses the defined nouns throughout documents and diagrams that present views of the business. The nouns are defined in a business glossary, a data dictionary, or a high-level data model. Each noun will almost invariably relate to a category of data that is captured and used by the business.

There is even a problem with using the term ‘student’. ‘Student’ is a perfectly legitimate unifying concept to use when describing the business situation of an educational institution (and certainly far better than using a mixture of ‘student’, ‘learner’, ‘prospect’, ‘graduate’, and ‘resident’). When it comes to designing and building information systems, however, there is a need for greater precision in our use of terms. A person is admitted to a course of study – this makes them a student. The person and the student are the same thing. If they withdraw from the course, they are no longer a current student – but the person still exists. Their historic admission to the course is knowledge that we don’t want to lose. Therefore, ‘student’ is actually a term for the relationship between a person and a course.
So, the only nouns we need when describing the data are Person and Course – ‘student’ is superfluous. Person and Course are much easier to define clearly – that is, Person and Course are stable and distinct real-world concepts. As we saw above, student is not a stable concept. And since it is so ambiguous and unnecessary, ‘student’ can be eliminated entirely.
Therefore ‘student’ is not a data subject, it expresses a type of a relationship a person has with another data subject – actually, several relationships (which is why it is such an ambiguous term). The student relationships may include:
- Person is admitted to Course;
- Person is enrolled in Unit;
- Person lodges in Residence;
- Person has Assessment for Unit;
- Person is awarded Qualification;
- Person is granted Scholarship.
The capitalized nouns in the above list are all data subjects, also known as data concepts or business objects. We can draw a simple map of the data subjects outlined in the above list of relationships, as shown in Figure 2-6. This type of diagram is called a ‘data model’ – it models some or all of the relevant data subjects, the nouns of the business.

There are many more relationships that a person may have with other education-related subjects, such as a teacher of a unit, as an administrator, and as a prospect for a course of study. A person can – all at the same time – be admitted to a course, be enrolled in units, have already been awarded a qualification, be employed by the university as a tutor, and have a scholarship. All these roles are simply relationships between the person and other subjects. The word ‘student’ is not necessary to describe these data subjects and relationships.
So, should the word ‘student’ be eliminated from our vocabulary? Good luck with that. ‘Student’ is such a widespread term that it will survive no matter what data specialists think about it. However, this discussion is not suggesting the word needs to be excised from the language; our opinion is that ‘student’ is not precise enough a term to use in relation to data about students. It is good data design to excise ‘student’ from the model of the organization’s data. Nevertheless, it remains a useful word – a kind of shorthand for ‘a person who is enrolled, or has ever been enrolled, in a course’. As this example shows, data can get complicated very quickly, but we can keep control of the complexity by doing two things:
- clearly defining our nouns, and
- distinguishing nouns that are placeholders for a relationship between data subjects.
It takes time and experience to analyze your business’s data subjects skillfully, so seek the assistance of an experienced data modeler.
Six kinds of data
All data is not created equal. Some data forms the most important records of a business – we term this type of data ‘master data’. Master data is the precious payload of our transactions. However, the payload is but a fraction of the data that a business operation needs to process the transaction, and others like it, smoothly and efficiently.
As the transaction is initiated and progresses through submission and decision-making steps, data is created so that operational staff can monitor the transaction’s progress. This kind of data is termed ‘transaction data’. The accumulating transaction data informs staff what work needs to be done next. With good quality transaction data at hand, a manager can control their team’s workload and rebalance the workload when staff are absent.
These two types of data – master data and transaction data – are the bread-and-butter of computerized business systems, ever since they came into the commercial business world as ‘electronic data processing‘ machines. In addition, there are four other types of data, illustrated in Figure 2-7 below. The diagram shows six types of data in all. Each type of data has a different purpose; therefore each type has either more or less strategic importance. Increasingly, computer systems store all types of data, but this was not always the case.
The lower layers of Figure 2-7 – transaction data and audit data – form the more mundane data that records the business’s day-to-day operations. Transaction data is critical on the day it is created and immediately afterwards, but quickly loses its usefulness. Transaction data is commonly aggregated to produce statistics on operational throughput and service level achievement. Once aggregated in this way, data about transactions has little enduring value beyond resolving specific issues that may arise with specific transactions. In contrast, the master data that is created or changed by transactions is of significant enduring interest to the business.

Figure 2-7 The Six Kinds of Data5
For an online retailer or a wholesaler, it is critical to the business’s survival that a customer’s order is processed and fulfilled quickly, without losing the information about what the customer purchased. The correct price needs to be charged and the inventory needs to be updated so that a replacement product can be ordered when the stock level reaches the minimum – this is master data. A year later, there is little value to the business in recalling the details about how they processed that sale, or perhaps even which salesperson made the sale – this is transaction data.
The layers in the middle of Figure 2-7 comprise data that has a longer life because the data is about the structure of the business, who the customers are and what products and services the business offers. These are the master data and structure data layers. Structure data holds information about the structure of the business itself, while master data holds the critical records of the outside world and its current relationship with the business.

The day-to-day activities of the business are captured in the transaction data layer. These activities cause changes to occur in the records held in the master data layer. For example, when a customer notifies the business that they have moved, the business updates the address held on the customer’s master record. When a product sale occurs, the business will adjust the stock inventory master record and create an invoice master record.
The lowest data layer is audit data, which is detailed information captured when an action occurs in a system. Audit data is created by business systems in large log files. We do not need to examine audit data very often; we should be thankful for that, because it is very difficult to interpret as it is stored in a compressed technical format. Audit data becomes useful, however, when a technical defect needs to be traced to its source, or when the user who performed an action needs to be identified. The latter is particularly important when evidence must be produced in the case of a dispute with a customer or regulatory authority.
The highest layers of Figure 2-7 are reference data and metadata. Reference data comprises things that you ‘look up’, such as lists of countries, list of permitted values of certain data fields (the allowed values that describe a person’s gender, to take a common example), datasets of all the physical addresses in a country. Most businesses have many such reference data lists and sets. By centralizing these reference lists, we raise our data quality by ensuring that the same set of values constrains all occurrences of a data item.
The top layer is metadata. Commonly described as ‘data about data’, metadata defines the meaning of the nouns that we use in our systems and processes. Accordingly, metadata is often called the ‘data dictionary’. Well-documented and universally applied metadata ensures that staff can readily discover the meaning and proper usage of any data item in the business’s databases.
The differences between the six kinds of data can be difficult to grasp at first – an illustrative example may help your understanding.
When a new driver applies for a license, they must pass all the prescribed tests. When the test results satisfy the criteria, the motor registry must approve a new license to be issued. The registry creates an enduring record of the license that can be retrieved when needed any time in the future. A few years later, the license record is critical to ensuring that infringements of traffic law can be enforced effectively. Also, the license record is useful for demanding a new license fee when the expiration date is reached. Therefore, the license is master data, having a long life. But at the time of a traffic offence or license renewal, it is much less likely that the registry would want to recall who the testing officer was, the date and place of the test, or what the initial license fee was. The data that concerns the license application process is transaction data, not master data.
While the transaction of granting a driver’s license is in progress, the motor registry needs to keep track of the driver’s application and the many tasks involved in receiving, qualifying, testing, approving, issuing, and recording the license. They do this by creating data about the transaction, and then using that data to manage and monitor the operational processing of the license application transaction. So, transaction data has a very important role to play, even though its relevance is short-lived compared to master data.
The motor registry stores master data about the actual licenses they have issued to drivers, while a new driver’s application for a license creates transaction data. A license application transaction creates a new driver master record and a newly issued license record. When the transaction has been completed (that is, once the driver has been tested and approved), the transaction data holds links to the new master data about the driver and the issued license. This is illustrated in Figure 2-8.
The transaction data also holds the type of license that the driver applied for (e.g., car, motorcycle, or truck). Separately, the motor registry stores a complete and definitive list of the types of driver licenses it offers – this list is reference data. The reference list of all types of licenses that can be granted to drivers is very stable over long periods of time. In fact, the kinds of driver licenses are usually enshrined in the government legislation that authorized the registrar to issue licenses. If the legislation is amended to remove or add a new license type, then the reference data must be updated so it continues to match the legislation.

The master data for drivers and issued licenses are kept separate because they relate to two distinct objects – a driver and a license. The importance of this separation becomes clear when you consider that a driver may hold more than one class of license – if they drive a car and a truck, for example. If the driver’s details are mixed in with the license information, then when the second license is issued the driver’s details would be duplicated in two license master records. This makes it more difficult to update the driver’s details when they change their name or address. Inevitably, this leads to poor quality data that will come back to haunt the registry at some point, such as during enforcement of driving infringements.
When the driver license expires, a new transaction occurs, involving the payment of a renewal fee and a vision test. The driver license master record is updated with the new expiration date, a new photo of the driver, and any change to the driver’s address or name. This data is printed onto a fresh license card, which is given to the driver. The relationships between the master records and the renewal transaction are shown in Figure 2-9.
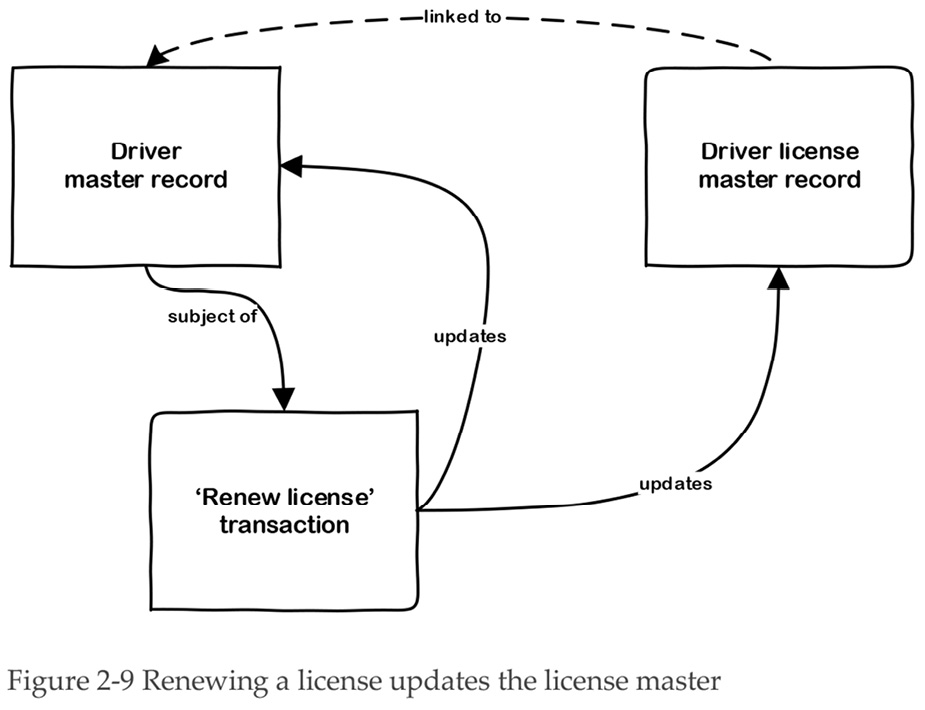
The details about the renewal transaction lose their importance once the payment has been processed and the master record has been updated. Of course, the business may choose to keep it for a few weeks or months in case there are any problems, or for management reporting purposes. But the value of the transaction data diminishes rapidly. However, it is critical that the registry retains the updated license master record, or they – and the police – will not be able to do their jobs in enforcing road laws.

As shown in Figure 2-10, master data and transaction data remain useful for different timespans. Due to the differing longevity of the data, master data has different management needs to the data about transactions. Master data forms the heart of the business – it holds critical and enduring information about our products, customers, customer accounts, etc. On the other hand, data about transactions is critical whilst the transaction is in progress, but quickly fades in significance once the transaction has completed. We do not need to hang onto it forever.
Since our uses for master data and for transaction data are fundamentally different, they can be separated in our databases and managed differently. Nevertheless, there is benefit to be gained from unifying the way in which we manage transaction data across all the transactional services.
So far, of the six layers of data, this example has covered three: master data, transaction data, and reference data. Now we will look at the remaining three layers, structure data, metadata, and audit data.
The registry’s organizational structure shows the team structures and supervisory reporting lines. This is structure data. Structure data holds information about the business itself. As the name suggests, structure data is structural rather than transactional. For example, storing data about the organizational structure enables the registry’s managers to report the performance of the teams for which they are responsible. Performance data from individual teams can be aggregated at the different levels represented by the organizational structure. If there were three teams of driver testers, for example, each tester will belong to one of the teams in the organizational structure. The performance of the three teams can be compared.
The uppermost layer – metadata – defines the meaning of objects such as ‘driver’ and ‘license’. The metadata for these objects also stores information about the attributes of the object, such as ‘name’ and ‘address’ for the ‘driver’ object. These definitions help to govern the organization’s data assets by providing a framework to guide what data may be stored in which objects. Having a dictionary or business glossary of well-defined data objects is the first step towards improving and maintaining data quality.
The final data layer is audit data, which is a log of actions that occur in a system. The kinds of actions that are captured in audit data might include when a driver master record is updated, for example. The audit log will retain a snapshot of the old record before it was amended, or at least of the individual data fields that were changed. If the driver’s surname was changed, then the audit log would capture the old and new values of the surname, the user who changed it, and the date and time it was changed. The driver licensing example is summarized in Figure 2-11.
How to tell master data from transaction data
This book is focused on transactions and the effect that transactions have on master data. So, of the six kinds of data, we are mainly interested in the master data and transaction data layers. How do we distinguish between master data and data about the transactions that update the master data? Master data forms an enduring record. The business needs master data to fulfil many purposes over time, and you never know when you are going to need it. On the other hand, we use the term ‘transaction data’ to mean the data about the activities that occur during a transaction. Every transaction generates a set of transaction data about itself.

Launching the payload
A metaphor may serve to illustrate the difference between master data and transaction data. The satellites and deep space probes that humans have launched in the last six decades or so are the pinnacle of technological achievement. Our ability to obtain high-resolution photographs of Pluto, or to steer a probe safely through the rings of Saturn despite a delay of 84 minutes in signal transmission between the craft to Earth, are astonishing achievements. The spacecraft that perform these extraordinary feats are freed from Earth’s gravity and set on their path by huge and complex rockets.
Having set the craft on its journey, the rocket has done its job, and – apart from admiring the film footage of the launch – people quickly forget about the rocket and focus their attention on the spacecraft itself – the rocket’s so-called ‘payload’. The rocket has no purpose other than to set the payload on its proper course into space. However, sitting on the launchpad as the countdown progresses, the tiny payload is literally just the tip of the huge rocket iceberg.
During the launch process, a carefully timed sequence of operations is performed. Meanwhile, onboard sensors monitor every aspect of the machine in case any problems occur. Large amounts of data are generated by these sensors and computers examine the data, watching for unexpected anomalies that might indicate a problem that could jeopardize the mission. The launch team can suspend the pre-launch sequence if serious problems are detected; critical components can be replaced, or other adjustments performed; and the countdown then resumed when it is safe.
The whole process of launching a spacecraft involves hundreds of technical specialists and supporting staff. None of this myriad activity affects the precious payload, other than to keep it safe. The launch team’s job is to successfully complete the ‘transaction’ of freeing the payload from Earth-bound gravity. Once their job is done, the launch team can relax. The transaction of launching the payload is finished.
Many components of the rocket’s machinery and supporting equipment work together with many specialist launch teams. The craft to be launched into space is the sole reason for the entire exercise – the payload is like a business’s master data. A business transaction is like the rocket, requiring a complex sequence of work, timing, and good error detection, but the only thing that is really carried on into the future is the ‘payload’ of master data. Without the payload, the transaction is pointless, like a rocket with no spacecraft in the nose cone. The rocket itself is like transaction data, storing data about the activities that occur during a business transaction.
Managing transaction data better
Transaction data is comprised of the information that a business needs to capture, temporarily at least, about the activities that occur to move a business transaction along and to keep track of the transaction’s status. The business operations teams use this data to manage the transaction through the various tasks they need to do to fulfil what the customer wanted.
For example, an order that needs to be fulfilled is a transaction. Historically, the order might come to the business on a handwritten or typed order form. The business might stamp it with the date received, add it to the stack of new orders, tick off the ordered items as they are picked from the stacks, and again as they are packed for shipment. In other words, in these manual systems, transaction data is recorded right on the paper order. The workers processing the order would have manual systems and procedures to ensure they did not misplace an order form, or neglect to pass the completed order form onto the billing team.
As we know, computer systems have changed the old ways of doing things. Nowadays, the customer might submit the order online, comprising a set of data about the order and the desired items. The business has processes – which may or may not be automated – to receive the order and relate it to a customer record, then to transfer the data to the warehouse for picking, packing, and shipping. The shipped order might be then passed over to the billing team for creation of an invoice which is sent to the customer.
The order record is transaction data. The order data contains information about who or what triggered the transaction, what the customer wanted, the status of the transaction, and so on. Typically, the business will use the order record itself to track the tasks that need to be undertaken, changing the status of the record as it progresses through the business process.
Some data about a transaction is specific to the type of transaction involved. An order for books will look quite different to an application for a driver’s license. However, there is other transaction data that looks remarkably similar in structure no matter what type of transaction is being processed. Such generic transaction data holds information about the time and date on which the transaction was started and finished, the type of transaction it is, the tasks that have been performed on it, and the tasks that are yet to be started.
Some transaction data is not generic but is specific to the type of transaction being performed. In the case of an order transaction, the transaction-specific data includes the order form and the packing slip.
Now Emily realizes that data is important, and systems exist primarily to store and process data. Thinking about data needs should come before considering how best to sequence the business process. She understands that master data is data about important things like customers and products, and that master data has strategic importance to a business. Data about transactions is important in the short term, but eventually the business can forget about it – transaction data is important operationally, but not strategically. But Emily thinks that it is in the design of transaction processing where the efficiency and productivity of the business operation are determined. How can the design of transactions be simplified?
In Chapter 3 we will look deeper into transactions and their generic structure, while later in Chapter 6 we describe the generic data structures used to record the work activities involved in processing transactions.
Three key points from this chapter
- Data lies at the heart of every business.
- Structuring your data well is the critical first step towards better systems and processes.
- The six kinds of data should be separated in your databases.
Further reading
Carey, Craig. (2015) The Origin of Writing. Retrieved from: https://bit.ly/2Pdxetn (includes photos of tokens, bulla, tablets and cuneiform).
Davies, Lyn. (2006) “A is for Ox – A short history of the alphabet”. Folio Society.
Hoberman, Burbank, and Bradley. (2009) “Data Modeling for the Business – A handbook for aligning the business with IT using high-level data models”. Technics Publications.