
A Task Shared is a Task Halved

Emily has noticed that one team does their letters to customers slightly differently than another team. The customers probably don’t notice this variation, as they get letters from us so infrequently and the differences are fairly cosmetic. But the methods that are used to generate and dispatch the letters are different across all the teams within Emily’s department. Not only are the processing methods different, but they use different technology tools. One team creates each letter individually in Microsoft Word®, copying a letter previously sent to another customer, and inserting the correct customer’s name and address into the document – this is labor intensive and needs several people. Another team has a collection of templates that provide a ‘fill-in-the-blanks’ starting point, while another team that sends a high volume of letters uses a software tool that inserts customer-specific data into a predeveloped template.
Emily is puzzled why the teams have not done something about this. She thinks it would be quicker and easier if everyone produced letters using the same method and technology. The department could also centralize the letter creation team and give them the opportunity to find a way to produce letters as accurately and efficiently as they can.
Emily realizes that the task of sending a letter19 is used several times across the business processes. Of course, we notify a customer of our decision concerning the transaction they initiated with us. But also, we send an acknowledgement that we have received their request after they have submitted it. And we sometimes send letters requesting further information from the submitter. When a renewal action is nearly due, we send a letter to the customer as a reminder that we have commenced the renewal process and they will need to provide some information. Despite the variety of these uses, in the end, they are all just letters. The only variations are the standard text relating to the context of the transaction in hand, the customer’s details, and other specific details of the transaction. If we had a common way to feed these inputs into a centralized team, they should be able to generate letters quickly and cheaply.
It seems to Emily that the varied uses of letters are covered by a handful of tasks in the generic pattern, namely the Acknowledgement, Acceptance, Request for Further Information, Notification, and Commencement tasks. We could implement those five tasks by creating a single work queue (maybe called the Correspondence queue) and by creating a central team whose staff would all be members of the Correspondence queue. When a transaction needs to send a letter, the workflow would assign all the five task types listed above to the single Correspondence queue. When all types of transactions do this, the teams responsible for each transaction will not need to implement correspondence capabilities for themselves but will simply reuse the standard shared task.
Emily thinks this would be a lot more efficient as well as ensuring that letters are done properly and consistently every time.
What tasks can be shared across transactions?
As Emily has realized, some tasks are undertaken in much the same way by most transactions – or at least, they could be. For example, correspondence is generated not only by several notification tasks in the Transaction Pattern, but also by most types of transactions. All these correspondence-related tasks could be implemented into business processes and computer systems once only; and designed in such a way that the tasks know what correspondence to generate, what channel to use, and what customer and address data to feed in. A further step up in efficiency and effectiveness would occur if the tasks were all carried out by a centralized correspondence team.
The generation of letters and other correspondence is a rather obvious example of a task that could be shared, but there are several other shareable tasks that we can identify in the Transaction Pattern. These include Identification, Approval, Payment, and Future Activity Scheduling. Later in this chapter we will look in detail at why and how these tasks can be performed in the same way for most types of transactions.
The infrastructure to implement shared tasks can be built once and made available to all types of transactions. However, some tasks will always remain specifically designed for a single type of transaction. We refer to these non-shared tasks as ‘transaction-specific tasks’. For example, the design of an Evaluation task is always specific to the type of transaction, as there will be different data to be evaluated and added to, different business rules to be applied and so on. This means that the Evaluation task needs to be designed and built uniquely for each transactional service. In contrast, the Approval task is very simple – the approver makes a simple choice between approve or not-approve, and the information system records that simple choice. Of course, the approver must have access to the data of the transaction, but this can be presented to the approver as a link, rather than a new screen or report. This simplicity means that an Approval module can be built once and deployed to every type of transaction.
Arrange the pattern diagram differently
Figure 7-1 rearranges the layout of the pattern that we introduced earlier to draw out the commonality more clearly. In this version, the potentially shared tasks are shown with dashed lines. The left-to-right sequencing of the tasks through the Request and Response stages is still present in this new layout, but you will notice that the shared and transaction-specific tasks alternate. We can now remove the transaction-specific tasks from the diagram, leaving the shared tasks behind, as shown in Figure 7-2.
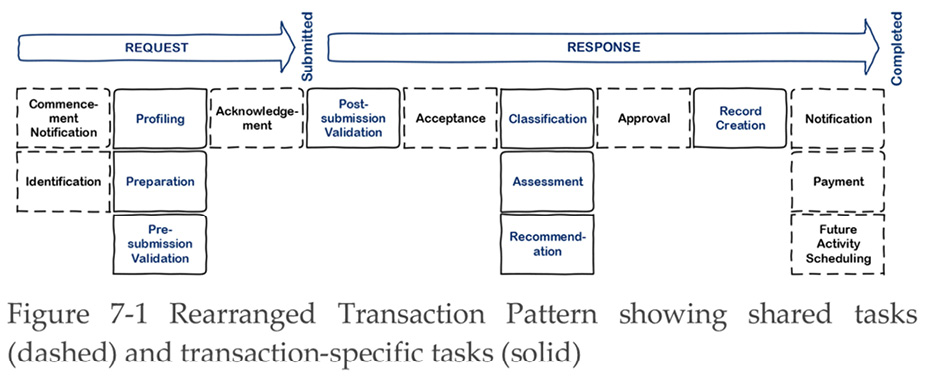

The interesting feature of this diagram is that the shared tasks occur throughout the entire Transaction Pattern. This means that every phase of processing a transaction can benefit from making use of tasks that have already been defined and possibly implemented. The system components that support the shared tasks are also designed, built, tested, and deployed once only. Technology experts call this approach ‘service-oriented architecture’. The idea is that a technology capability that performs a specific, tightly-defined function is built once and called on by other services and systems when needed.
We can see now that all the business tasks that deal with correspondence could not only be centralized through a single work queue but would also call on a single technology capability, called Correspondence Production. This would resolve the variations in practice that Emily detected not only in letter preparation, but also in technology use.
Shared tasks interlock with transaction-specific tasks
As we have seen, the shared tasks and related system components can be designed and built once and then used wherever a transaction needs to call on them. For example, when the designers of a transaction want to send an acknowledgement of the customer’s submission at the end of the request phase, the workflow will be designed to make use of the shared Acknowledgement task, rather than requiring a special task to be designed just for that transaction.
The business expert does not need to be concerned with the internal workings of the shared Acknowledgement task. They simply need to specify the data and content required for the acknowledgement letter, and which work queue the task should be sent to. This reduces the work involved in specifying the business requirements. (If the sending of outbound notifications is a centralized function, then there need only be one work queue making the job of the designer even easier.)
A similar simplification applies to all the shared tasks, including Identification, Approval, Payment, etc. We can regard each as a ‘black box’, the internal workings of which are invisible to the business requirements analyst. The analyst needs to understand only what the ‘black box’ will produce, and provide the inputs it requires.
You will note that specifying the inputs for each shared task is considerably less work than specifying the entire workings of every task. Making use of this commonality delivers a gain in productivity for the development team. There is a trade-off, however, and this is that the analyst and the business experts must be happy to accept the shared tasks as designed and built. When a business team begins to think that they have a special need that is slightly different to the built shared task, then the gain in faster implementation will be lost, and investment will have to be spent on implementing the special needs. Often, a perceived ‘special’ need is only a reflection of how things are done now, and perhaps an unwillingness to change. The benefits of sharing a task will usually be seen to outweigh the loss of a special requirement. A genuine special need should be designed into the shared task, so that other services can use it if they need, rather than keeping the task separate and unique to one transaction. So far, we have seen that shared tasks can reduce the work of specifying business requirements for some tasks. This means that service designers and business analysts can spend more of their limited time on specifying the tasks that are specific to the transaction they are designing. When designed within this framework of shared tasks, the transaction-specific requirements will slot in between the existing design of the shared tasks, like a key in a lock as illustrated in Figure 7-3.

This slotting together means that when the business offers two or more transactional services to the market (most businesses offer several services) they can focus design efforts on the transaction-specific tasks for each service. Once the shared tasks have been designed and built, the design team for a new or redesigned transaction specifies the requirements for the transaction-specific tasks, knowing they will slot nicely together with the existing shared tasks. For example, in the case of an insurance company, the ‘Buy Insurance Policy’ transaction and the ‘Claim for a Loss’ transaction will make use of the same set of shared tasks. Despite the two transactions being vastly different in the data and the processing required, they can share tasks such as the Approval and Notification tasks. This is illustrated in Figure 7-4.

Now that we understand the advantages of designing and building shared tasks that can be used by multiple transactional services, in the next section we will look at the features that are typically encountered in the shared tasks.
Specification of requirements for shared tasks
This section discusses each of the shared tasks that we have identified above in more detail.
Figure 7-5 gives an overview of the typical inputs required by each of the shared tasks. This figure is followed by the details of each shared task, its function, key features, and data inputs and outputs.

The inputs and outputs are used by the business analyst involved in designing a specific transaction. The analyst needs to specify the data inputs for a shared task that will instruct the shared task to behave in a certain way or provide data that is used by the shared task to produce the outputs. The outputs of a shared task are the data and artifacts produced by the task. This information is used by the analyst to ensure that the outputs are stored or utilized by the transaction-specific tasks. Here is how to use the tables of Data Inputs and Outputs that are included in the details about each shared task:
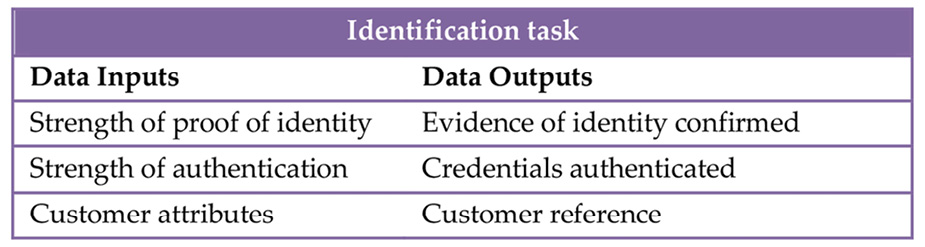
- Data Inputs – lists the items that you should specify when you are documenting the business requirements for a specific transaction. Each data input will be either a fixed value (e.g. in the Identification task, the required strength of proof of identity is ‘Level 4’), or a data item that has been collected earlier in the transaction or linked to it (e.g. for a Notification task, the addressee and their address is retrieved from the customer master data.)
- Data Outputs – lists the data items that are produced by the shared task and are available to later tasks in the transaction. You need to specify what is to be done with each of these data outputs. The data outputs may be stored somewhere or fed directly into the subsequent task in the transaction.
Identification
It is necessary to identify the customer at the commencement of just about any transaction – you always need to know who you are dealing with. This occurs in the Identification task in the generic Transaction Pattern. There are two aspects to identification, one concerning the evidence that proves that someone is who they say they are. We are familiar with providing a certified copy of our passport or birth certificate as evidence of our identity. This is widely referred to as ‘proof of identity’.
The second aspect of identification is the ongoing need to know who is interacting with the business, whether online, in-person, or by phone, on each occasion that an interaction occurs. “Could you tell me your full name and date of birth please?” is a familiar question when we interact with a business by phone. Usernames and passwords fulfil the same function in the online channel. At the business’s front counter, another approach is to ask to see your driver’s license or some other photo ID. The technical term for this second aspect of the Identification task is ‘authentication’.
Proof of identity and authentication are commonplace and are familiar to most of us as users of various services across our dealings with businesses and government agencies. The underlying details, however, can be quite complex. There are many different forms and levels of identification, and these need to be appropriate for the type of transaction and the level of risk associated with it.
Whilst an online retailer might not care whether a purchaser gives their correct name or not, they will be more interested in whether the payment card is being used legitimately, and if the customer has supplied the correct address to which the goods will be sent. A bank, on the other hand, will take considerable care to authenticate an online user or a person presenting at a branch counter, before allowing them to conduct transactions using a customer’s account. Government agencies and many other businesses need to identify their customer confidently to ensure that entitlements, permits, and especially payments are not claimed fraudulently. Privacy law in many jurisdictions now requires businesses to guard access to people’s personal information; this requires a robust yet efficient process for identifying a customer at every service interaction point.
Identification, when supported by robust technical capabilities, can be fully automated for online interactions, and partially automated for phone and in-person interactions. Given this ability to automate, Identification is an obvious candidate to be shared across many services. It would be silly for a company to provide separate mechanisms for validating an online user’s identity for every different transactional service. That would drive the customers mad with frustration as they grapple with the varying user experience.
Websites usually have a login facility that enables the online user to say who they are. However, it is easy to pretend to be someone else in the online world. All you need is another person’s login details – the website won’t know if the user actually is the person whose login details are being used. Since it could be anyone – or anything – logging into the site, most websites that require authentication will link the user’s login to a master record of an actual person.
Websites offering low-risk transactions usually place the onus of keeping the login details secure onto the customer. However, sites that provide higher-risk transactions (such as high-value payments or lodging a tax return) will employ an extra layer of protection to provide greater confidence that the online user is who they say they are. This extra layer may consist of a mechanism like sending a verification code to a mobile phone number; only the person who has the mobile phone can obtain the special code.20
Public sector agencies are increasingly relying on national governments to provide a common platform for identity services, through which people and organizations can identify themselves and use legally binding digital signatures. For example, the government in Australia is developing a digital identity service so that citizens and businesses can prove who they are once only, then use that digital identity whenever they request a government service. Furthermore, the digital identity service will be ‘federated’, meaning that customers are free to choose between identifying themselves with the government identity provider or with a private sector provider such as a bank.21 The Indian government has a long-running program to put in place a similar identity system on a much greater scale.22
The online authentication described above is fully automated and computers can do it reliably if the right security protections are in place. The same principle of ‘build it once’ applies to proof of identity processes that may require some human interaction and manual verification. For example, a government agency delivering welfare benefits to citizens in need must ensure that the person claiming a benefit is fully identified. This will enable the agency to ensure that the customer cannot claim the benefit more than once and to obtain information about the customer from third parties. Irrespective of the type of benefit being claimed, the agency will require the customer to provide evidence of their identity to a suitable standard.
Sometimes a person wants to transact business with you on behalf of someone else. This can occur, for example, when a parent applies for access to a government program on behalf of their child with disability. This also occurs when a clerk transacts on behalf of their organization. In this case, you may want to identify the submitter as well as the person (or organization) that is the subject of the transaction and ensure the submitter is properly authorized to act on behalf of the subject.
Call centers engage in a scripted conversation with a caller, with the aim of confirming (or at least reducing the risk) that the caller is who they say they are. Questions such as “Could you tell me your full name and date of birth please?” and “Can you confirm your address please?” are familiar to most of us who have ever contacted a call center. What the call center operator is completing is the Identification task. In most call centers, the script for confirming the identity of the caller is identical for every type of transaction that the caller may wish to do. That is, the call center has implemented the Identification task so that it can be shared by all transaction types.
Every new transaction and interaction with the customer may require a new Identification task – i.e. the identification script or the online user authentication is repeated. Thus, Identification is truly a shared task, built and implemented once and reused in many places.
A common variation that occurs between identification processes is the ‘strength’ of the authentication or proof of identity that is most appropriate for the current transaction. Some types of transactions require the business to be more certain of the customer’s identity than others. The strength of identification that is required modifies how the Identification task is performed. Typically, the business will implement methods for two or three levels of identification strength, and choose which strength is appropriate for each of the transactional services they offer and for each type of customer interaction.
Identification is largely a self-contained function that does not require the designer to specify inputs. The only factor the designer must consider is the required strength of the identification. The required strength is relevant to both once-off proof of identity and to ongoing authentication.
Notification tasks
Notifications are written correspondence from the business to a customer. Notifications may be sent to any of the parties who have a role in the transaction. These include:
- The subject of the transaction
- The submitter
- The responsible party (if there is one)
- An internal business unit that has flagged an interest in being informed of any instances when a particular customer transacts (e.g. an internal investigation team that is gathering evidence of suspected fraud).
Correspondence with a customer is created by several tasks: Acknowledgement, Acceptance, Notification, and Commencement Notification. As noted previously, these tasks can all rely on a single implementation of a correspondence function that contains comprehensive features to deal with all channels and correspondence types.
An outbound notification could be sent via mail, email, or web channels, according to the customer’s preference. It could also take the form of an on-screen confirmation that an action has been successfully completed, with an option to print the confirmation or have it emailed.

Notification tasks employ several customer interaction capabilities to deliver a notification. These are examined in detail in Chapter 8.
A shared, generalized Notification task can be employed for all outgoing correspondence, whether there is a centralized correspondence team or not. To cater to a distributed correspondence function, work queues will need to be set up for each team, so that a team’s work is not mixed up with the work of other teams.
Payment
An outgoing payment is required for some types of transactions, such as processing a received invoice and issuing the payment of a grant or benefit. Payments are easy to standardize and are often centralized in a function called ‘accounts payable’. Also, payments can be easily automated, through electronic funds transfer and computerized interfaces to the banking system. These systems have been well-established for many years and perform reliably, processing huge volumes of financial transactions every minute.
The Payment task needs to be fed precise data about the payee, the bank account, the amount to be paid, the date to be paid, and the accounting details for posting the payment to the correct place in the financial ledger. When supplied with these few data fields, the Payment task can do its job very efficiently, usually with no human intervention.

The function of taking inbound payments, which includes, for example, taking a credit card payment when placing an order online and bill payments, is likewise implemented once only and then used across all transaction types. Such card payment and EFT payment functions are often outsourced to a third-party payment provider. In the Transaction Pattern, we regard inbound payments as a part of the Preparation task.
Approval
The Approval task is the action in which someone who has the proper authority decides the outcome of the transaction. For some transaction types, Approval is a very simple task that can be implemented in automated business rules. In this case, the Approval task is carried out by a machine. On the other hand, the decision may require a person to exercise good judgement, in which case the task is assigned to a special work queue or perhaps to a specific individual. Some decisions, especially in government organizations, must be made by a person who has been delegated decision-making powers. For example, an application for a government grant may be assessed by one team, passed to another team for review and recommendation, and finally to a delegate to make the decision. This separation of duties is a key reason why the Approval task should be regarded as a different task than the Evaluation task.
In the Approval task, the approver makes a simple choice between approved and not-approved and the information system records that choice. This simplicity enables decisions for every type of transactional service to be stored in one place, through a shared approvals module. A link to the data of the transaction needs to be provided as input to the shared Approval task, so that the decision-maker can view the data, especially the data created by the Evaluation and Recommendation tasks.

Future activity scheduling
The final shared task, Future Activity Scheduling, creates an entry in a calendar for some future date. The purpose is to remind the business to do something that is related to the current transaction. For example, a review or a renewal may be required at a specific date. When the date of the calendar entry arrives, the business will usually send a notification to advise the customer that they are commencing a new transaction and the customer is required to do something – e.g. “your insurance is due for renewal.” A central calendar of future events could easily be shared between different types of transactions. Having a shared calendar makes it simpler for the Future Activity Scheduling task to be built once and shared.

Customer interactions
Interactions between the customer and the business can occur throughout a transaction. While not a designated task in the Transaction Pattern, interactions are another well of commonality that should be drawn on. There are several types of interaction that vary according to the channel being used.
In the next chapter, we explore customer interactions and how we can standardize them across all transaction types.
Three key points from this chapter
- Eight of the sixteen tasks in the Transaction Pattern can be shared by all types of transactions.
- Transaction-specific tasks slot neatly within a framework of previously-built shared tasks.
- Each shared task has a set of requirements that can be readily specified using the Transaction Pattern framework.