
![]()
Flying a modern commercial airliner has never been easier than it is today. Essentially, all a pilot has to do is enter a start point and an end point, get the plane in the air, and let the plane fly itself for the rest of the flight. Should conditions necessitate it, the plane can even land itself. Despite these facts, commercial pilots undergo a massive amount of training before they are allowed to take off with passengers on board. They have to study not only the specifics of the type of plane they want to fly but also the basics of aeronautics. In addition to the education they must receive, they also need to log a large number of hours of actual flying time before they can get a commercial license.
On a good day, little of this knowledge will need to be put to use. But in the case something does go wrong, a pilot needs to be able to draw from this vast array of education and experience in order to solve any potential problem. Without an intimate knowledge of both the principles of aeronautics and the specifics of the aircraft, this is simply not possible.
Similarly, to truly understand how to build secure APEX applications, you have to understand the underlying infrastructure and technologies that make up APEX. That is what this chapter sets out to do: familiarize you with the architecture and building blocks of APEX. It starts out with a high-level overview of the different modules of APEX, from the instance administration console to what a workspace is and how many of them to create. It also briefly covers the application development environment components, namely, the Application Builder, SQL Workshop, Team Development, and Websheets. It then shifts gears a bit and discusses the metadata-based architecture of APEX and how that relates to building applications. Next, it covers the three schemas that make up APEX and how they are managed and secured. The chapter concludes with a detailed overview of how APEX transactions work.
Overview of APEX
What is Oracle Application Express (APEX)? In a sentence, APEX is a web-based development and deployment platform designed in and for the Oracle Database. All that is required to design or use an APEX application is a modern web browser. APEX applications can be as simple as a single page or contain multiple pages and interface with external systems via web services. Figure 3-1 shows the sample database application, which highlights the features of APEX. In fact, the APEX developer tools—Application Builder, SQL Workshop, and Team Development—are actually APEX applications.

Figure 3-1 . The sample database application
APEX is built on a declarative architecture. Thus, when pages or reports are created, no additional code is generated. Rather, rows that describe the corresponding components are inserted into APEX’s tables. When an application is run, APEX will render the page and its components by combining this metadata with its own internal procedures. This approach is quite scalable, because the same procedures are executed over and over in the database, with the only difference being the data that is used. The Oracle Database can read and write records quite efficiently, which yields extremely fast performance for most APEX application environments.
The APEX environment contains a number of commonly used foundation components integrated directly into the tool. Features such as session state management, user and role management, validations, user interface, and integration via web services are all out-of-the-box features that are ready to use. APEX 4.2 also ships with a number of packaged applications, which are prebuilt applications that solve basic business problems. Examples include a project tracker, incident tracker, art catalog, and bug tracker. Once installed, these packaged applications are ready to use just as they are. Alternatively, they can be easily modified to suit a particular requirement or need.
All components and actions within APEX are accessed via nothing more than a modern web browser. At a high level, APEX is split into two major parts: the instance administration console and the Application Builder. The instance administration console is where all workspaces, developers, and instance settings are managed. Access to the instance administration console should be restricted to either the DBA or system administrator, since users with access to it can perform low-level system administration functions, such as creating new schemas, developers, and workspaces. The instance administration console is discussed in detail in Chapter 4.
The application development environment—which includes the Application Builder, SQL Workshop, Team Development, and Websheets—is where all development takes place. Developers who log in to the application development environment can create applications, pages, reports, charts, and so on. They can also use the SQL Workshop to create and manage database objects and can use Team Development to manage their projects. Chapters 6 and 7 cover using the application development environment, specifically the Application Builder, in much more depth.
Administration Console
The APEX administration console is a web-based interface used by APEX administrators to manage an instance of APEX. From the administration console, an administrator can manage requests, manage the instance settings, create and manage workspaces, and monitor all workspace activity. Upon installation, only a single user—ADMIN—has access to the administration console. The typical APEX developer will never need access to the administration console. If such a case does arise, it is best to have the APEX administrator perform the task on behalf of the developer, rather than grant the developer access.
The APEX administrator is a powerful role; it should be closely guarded and given out only to trusted individuals. While it is often compared to SYS, it does not have the ability to manage and control the Oracle Database; its functionality is limited to only the APEX workspaces and their associated applications and users. However, the APEX administrator can access nearly any schema in the database simply by creating a workspace and associating it to a schema. Thus, the APEX administrator can view any data in the database that does not have any other safeguards.
From a personnel point of view, the APEX administrator is rarely a full-time position. It requires a commitment of only a few hours a month, sometimes even less than that. In most cases, the APEX administrator is also the DBA. This makes sense from a compliance and control point of view in that having access to the APEX administrator is a lesser set of privileges than that of a DBA.
The administration console home page provides a dashboard that summarizes the settings of the instance of APEX, as shown in Figure 3-2.
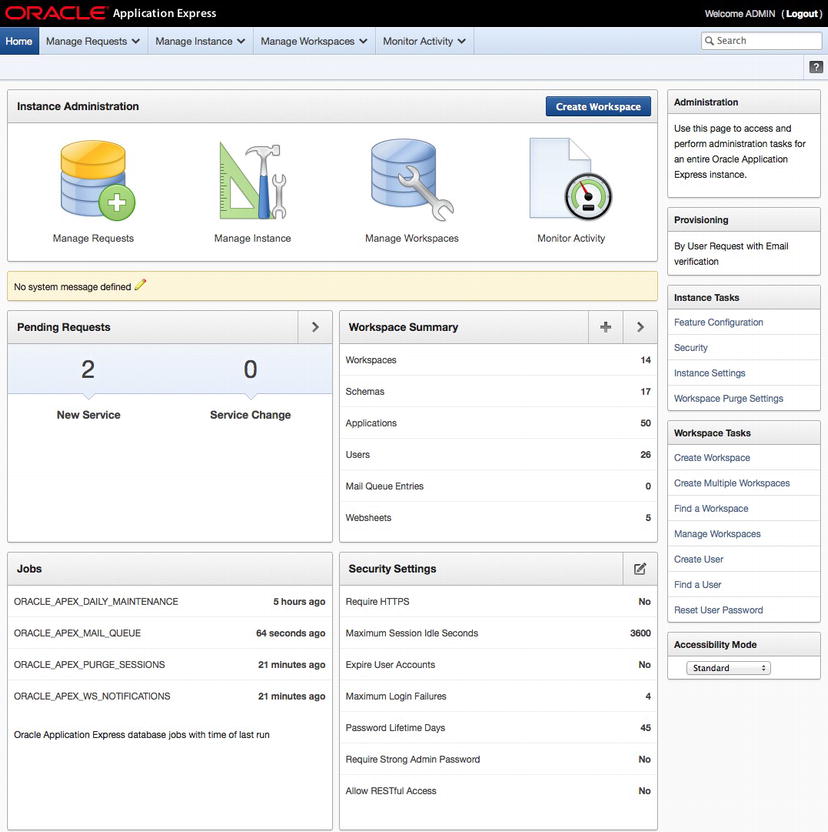
Figure 3-2 . The APEX adminsitration console home page
On this page, a number of metrics and settings are displayed, broken out into four categories. It is important to note that this is not a conclusive list of attributes, particularly in the Security Settings region. Quite a few additional attributes are critical for the security of an instance of APEX. Recommended secure settings for an instance of APEX are discussed thoroughly in Chapter 4.
APEX developers can request additional tablespaces, schemas, workspaces, or workspace termination from within APEX. All of these requests need to be approved by an APEX administrator and are done so through the Manage Requests section of the administration console. It is important to point out that schema management can be done outside of APEX as well by the DBA, just as it would for any other database schema. This embedded feature was created namely for APEX in a multitenant, hosted environment where access to SYS is not required. In most on-premises environments, the DBA manages the creation of all schemas for any application, and this feature is simply not utilized.
From a security perspective, there is little risk here by allowing developers to make such requests, because they will all need to be approved by the APEX instance administrator. However, the Provisioning Status setting in the instance settings should be set to Manual. This will prevent anyone from signing up for a workspace without approval and require the APEX instance administrator to create all workspaces.
The Manage Instance section is where most instance-level settings of APEX are configured. These settings typically impact every workspace and application on the instance. In some cases, a workspace administrator can override some of these settings at the workspace level. Many of these settings have to do directly with the overall security of the instance of APEX, particularly most of those in the Instance Settings region. The bulk of the remainder of the settings have little direct impact on the overall security of an instance and are there purely for instance management purposes.
Aside from initially configuring APEX, little time will need to be spent in this section on an ongoing basis. Most management of an APEX instance is done at the workspace level, either by creating new workspaces or by managing the associated workspace users. Chapter 4 is dedicated to configuring an instance of APEX with secure best practices in mind and highlights any instance setting that pertains to security.
From its earliest days, APEX was intended to be a multitenant, hosted environment. Multiple users from completely different organizations would be able to securely share an instance of APEX that would be hosted on the public Internet. A real-world example of this is Oracle’s publicly hosted instance of APEX, at http://apex.oracle.com. Oracle provides this instance free of charge to anyone who wants to try APEX without having to download and install it locally. This instance regularly plays host to more than 10,000 workspaces, or virtual private slices of the APEX environment.
An APEX workspace contains both developers and applications and is typically associated with one or more database schemas. All development activity occurs within a workspace. Each workspace is completely segregated and isolated from all others, thus ensuring that different groups can build and deploy their applications on a single instance of Oracle and APEX. However, most organizations that have adopted APEX have chosen to deploy it on-premise, installing it as close to their production databases as possible. Given APEX’s ease of management and installation, this is not a surprise.
The Manage Workspace section provides a set of tools for creating, modifying, and removing workspaces. It also provides a facility for moving a workspace from one instance of APEX to another. Lastly, a few reports summarize the attributes of all workspaces within an instance of APEX.
Details about what makes up a workspace and its associated components can be found in the “Workspaces” section of this chapter. You can find information on how to ensure that workspaces are properly configured and secured in Chapter 5.
The last component of the administration console is Monitor Activity. From here, an APEX instance administrator can keep an eye on all page views that occur within any workspace, including the application development environment. A combination of reports, charts, and even calendars are provided to display the data. Summary data is automatically archived by APEX and displayed here as well.
While APEX does collect a lot of details about itself, the data here has a relatively default short life span of about two weeks. This APEX instance administrator can increase this value up to about a year, which may still not be enough in some cases. Thus, it is recommended that if data retention periods need to be longer, a custom archival procedure be implemented. Archived data is stored only as summary data; discrete details are not archived automatically by APEX.
As previously mentioned, workspaces are virtual private slices of an instance of APEX where developers build and deploy their applications. Each workspace will have a number of users associated with it. Users can be one of three types: workspace administrators, developers, or end users.
Workspaces also have at least one schema associated with them that the different modules can interact with or parse as. Any system privilege granted to that schema will be available to any developer or workspace administrator in the workspace it’s associated with. For example, if a schema were created without the CREATE TABLE privilege, then there is no way that any type of APEX user would be able to create a table within that schema from APEX, even though a user would still be able to run the Create Table Wizard. This concept extends to any system privilege.
Depending on how the instance administrator configured it, a workspace will provide access to all or some of the different modules that make up the application development environment. This ability to limit access to modules can even be extended to individual users, if needed.
APEX users are specific and unique to a workspace. Their credentials are managed internally by APEX and cannot currently be moved elsewhere. If a single person needs access to three workspaces, then three APEX users need to be created—one in each respective workspace. These three accounts are seen as completely separate accounts by APEX and contain no integration or association with one another. Changing the password on one account does not impact the other two at all. Future releases of APEX may support moving these users to an external authentication repository, but as of APEX 4.2, that is not possible.
There are three classifications or types of APEX user: workspace administrator, developer, and end user. The end user is simply a set of credentials that can be used in applications that are developed with APEX. End users can access only the Team Development module. They will not even see the Application Builder or SQL Workshop when they log in to the application development environment, as shown in Figure 3-3. Even though there is a link to the Administration section of the workspace, no functions or actions are available on the corresponding page for APEX end users.

Figure 3-3 . An end user’s view of the application development environment
Using the APEX end-user type of user is acceptable for testing, training, or even applications with a small, static user community. However, because APEX users cannot be used across applications in different workspaces and cannot be easily integrated with external authentication repositories, it is not recommended they be used for most applications.
Most developers within a workspace should be classified as just that—developers. APEX developers can create and build applications, access the associated database objects via the SQL Workshop, use Team Development, and access some of the functionality of the Administration report. Developers can also be limited as to which module or modules they have access to. For instance, a developer could be created who had access only to SQL Workshop but not the Application Builder or Team Development.
It is important to understand that a developer who has access to the Application Builder but not the SQL Workshop can still perform almost any function in the SQL Workshop, including performing any DML or DDL on any schema associated with the workspace. All they would have to do would be to create a simple application that either embeds the desired functionality via PL/SQL processes or allows them to execute any SQL statement passed in via a page item.
The last level of APEX user is the workspace administrator. The workspace administrator can do anything that a developer can as well as manage the workspace. Workspace administrators have full access to all modules within a workspace, and it is not possible to alter this.
In most organizations, workspace management tasks will fall on the shoulders of the workspace administrator as opposed to the instance administrator. Things such as adding or removing a developer, unlocking a locked account, and setting the workspace preferences are all common tasks given to the workspace administrator. The time required to perform these tasks is usually just a few minutes per month.
While the workspace administrator can manage only their specific workspace, it is important to limit who actually gets this role. Developers who spend their time building applications and their associated schema objects do not need to be created as workspace administrators, but rather simply as developers. The workspace administrator role should be reserved for either the development manager or a DBA. This way, there can be more accountability for administrative tasks performed within a workspace.
Workspace users and roles are disused in more detail in Chapter 5.
When a workspace is created, it must have at least one schema associated with it. This schema can be an existing one or be created automatically as part of the workspace creation process. This schema will be used to store all database objects and data used in user-developed applications. The metadata that APEX creates as developers build applications is not stored in this schema, but rather in the APEX_040200 schema.
When a schema is associated with a workspace, any developer who has access to that workspace can perform any task that the schema has privileges for. The developer can also see any data stored in the schema, provided it has not been obfuscated by an external mechanism. This is a critical factor when considering which developers have access to which workspace, because any developer will be able to see all objects in any parse-as schema associated with a workspace.
In most workspaces, only a single schema is associated with a workspace. However, if requirements dictate that different applications parse as different schemas, then multiple schemas may be associated to a single workspace. It is also possible for a single schema to be associated with multiple workspaces. Regardless of how many schemas are associated to a workspace, an application can parse only as a single schema, and a developer can change this association only during design time.
The top-level sections of the application development environment consist of four major components: Application Builder, SQL Workshop, Team Development, and Administration. Depending on a user’s role and privileges, the user may see one, two, or all of the associated components. Furthermore, some sections will be only partially enabled based on role. For example, a developer will see the Administration tab, but only a subset of the functionality is available to a developer.
An instance or workspace administrator can limit which modules users have access to on a per-workspace or per-user basis, as illustrated in Figure 3-4.

Figure 3-4 . Limiting which modules an individual user has access to
Under the covers, each module is actually a separate APEX application. Take notice of the URL the next time you log into the application development environment, and you’ll see that each module has its own unique application ID. This design was done to facilitate security, as well as make each module more manageable so that a bug or design change in one module will not impact the other modules.
The Application Builder is where developers will spend the bulk of their time when using the tool. Here, applications can be built by creating pages, reports, charts, calendars, and a number of other types of components. Users with either the developer or the workspace manager privilege can access the Application Builder.
As mentioned, each application must be associated with one and only one schema. The developer must make that determination when creating the application and is free to choose any schema that is associated with the workspace. The schema assignment can be changed at any time, but only by a developer at design time. All SQL and PL/SQL within that application will parse as if connected directly to that schema. Applications can also perform any DDL commands that the corresponding schema has access to, if so programmed by the developer.
Application Builder secure development best practices are discussed in detail in Chapters 6 and 7.
The SQL Workshop is a web-based interface used to interact with database objects and data. It is by no means a replacement for a desktop-based IDE; rather, it’s an alternative that developers can use when a full IDE is not required or not available. The SQL Workshop is further split up into five subsections: Object Browser, SQL Commands, SQL Scripts, Utilities, and RESTful Services, as illustrated in Figure 3-5.

Figure 3-5 . The SQL Workshop home page
From a security perspective, there is not much that can be configured to limit or restrict access to the SQL Workshop. Either developers have access to it or they don’t. And if they don’t, they can easily build an application that allows them to perform similar functionality. Thus, when any developer has access to either the Application Builder or the SQL Workshop, they have full access to any schema associated with it. They will be able to run any SQL statement they want, create or drop any type of object the schema has permissions to, view any table or view, and execute any script they can upload. If this level is access is not appropriate for a developer, then the only sure way to limit it is to not make them a developer in that workspace.
Despite there being little control as to what a developer can access within the SQL Workshop, there are a couple of sections that do focus on security, and they are worth mentioning here.
- Methods on Tables: Found in the Utilities subsection of the SQL Workshop, the Methods on Tables Wizard automates the creation of a package to manage all DML transactions on a table or group of tables. Using this wizard to create what are called table APIs creates a single entry point into inserting, updating, and deleting data for a table. This entry point can be augmented with any number of business rules and additional security checks to ensure that only valid transactions occur.
- Chapter 13 discusses an approach that use a limited privilege schema and table APIs to mitigate a number of threats. The theory behind this approach is that if the parse-as schema that an application is associated with has little to no system privileges, then any successful attack on that schema will also be limited as to what it can impact. The Methods on Tables Wizard is used as part of this approach, and samples are provided as well.
- Object Reports: The Object Reports section is broken down into five subsections. Of particular interest here is the Security Reports subsection. There are four security reports: Object Grants, Column Privileges, Role Privileges, and System Privileges. Each of these reports displays information from the corresponding data dictionary views. While this data is not unique to APEX and can be obtained a number of ways, it is convenient that it is included in the SQL Workshop.
Team Development was introduced with APEX 4.0. Essentially, it is a project management utility that is integrated with the Application Builder. A development team can use Team Development to plan their milestones, features, and to-dos, as well as manage bugs and feedback reported by end users.
Any type of user—workspace administrator, developer, or end user—can be configured to have access to Team Development. This flexibility works well for nondevelopers such as project managers because they can be created as an end-user account and only be able to use Team Development.
Team Development is, of course, an APEX application, designed by the Oracle APEX team. It functions like any other APEX application and may or may not have potential security vulnerabilities. Unfortunately, if there are any vulnerabilities, there is little that can be done aside from waiting for a patch from Oracle to address them. This fact should not discourage the use of Team Development, though, because it is a supported component of the application development environment and will be patched should a vulnerability be discovered.
Introduced in APEX 4.0, Websheets are a feature of APEX aimed at the common business user. More of an online spreadsheet feature than full-blown application development environment, Websheets do not have traditional developers, but rather end-users who can also make changes to the application. The approach works well in some scenarios, as business users can quickly and easily modify both data and its underlying structure without the assistance from a developer, or knowledge of SQL or PL/SQL.
Most Websheets applications are designed with the assumption that any authorized user can see and modify any record. This is often a decision made by necessity, as most of the security controls available in a database application are absent in Websheets. For example, there is no easy way to prevent URL tampering with a Websheet.
Unfortunately, there is no simple upgrade path from a Websheet to a traditional database application. All pages and their associated content will need to be re-created. In fact, Websheets applications will lose some functionality when migrated to a traditional database application, as they allow for updatable interactive reports and database applications do not. Data will also need to be migrated to traditional Oracle tables, since Websheets use a single table to store any and all data.
Thus, when choosing between a Websheet and a traditional database application, these limitations and shortcomings need to be kept in mind. Often times with just a little more work, a database application can be quickly created in place of a Websheet, ensuring the application’s longevity as the business and requirements grow.
HOW MANY WORKSPACES?
One of the questions to arise when starting with APEX is this: how many workspaces do I need to create for my organization? Ideally, the answer to this question would be simple: one. A single workspace could be associated with as many schemas as needed, and all developers could be created there as well.
There are a couple of technical benefits of using a single workspace. First, APEX subscriptions work only within a single workspace. Subscriptions allow developers to create master copies of some components and then subscribe to those components across different applications—as long as those applications are in the same workspace. Using this mechanism, a developer could make a change to a component and then publish that change to all subscribers, regardless of which application they are located in. This centralization increases the manageability of an application greatly because changes need to happen in only a single location vs. multiple places.
Second, applications within a single workspace can be configured so that when a user authenticates to one, the user is authenticated to all of them. Configuring an application to behave this way is as simple as setting the cookie name in the authentication scheme to the same value across multiple applications. Details of this approach are discussed in Chapter 8.
While these two benefits may seem compelling, there are also some drawbacks to using a single workspace that may negate the benefits. First, if there is concern that only specific developers should be able to access specific schemas, then a single workspace approach will not work. Since there is no way to restrict which schema a specific developer has access to (aside from the SQL Workshop), multiple workspaces may be required where this requirement is in place.
Also, for organizations with a large number of applications, it may simply be easier to split up the applications into multiple workspaces for organizational sake, at least on the development side. It is possible to develop applications in multiple workspaces and then deploy them to a single workspace on the production instance. While the subscription feature will not work using this approach, the shared authentication will.
While there is no single correct number of workspaces for an organization, a good guideline is that the fewer workspaces that exist, the easier an instance of APEX will be to manage and secure.
The architecture of APEX is simple yet extensible at the same time. APEX is a metadata-based environment, meaning that most options specified by developers are stored as data rather than PL/SQL procedures. This approach allows APEX to scale quite well because all of APEX’s procedural code is finely tuned and does not change as applications are developed.
As far as languages go, APEX consists of two languages: PL/SQL and JavaScript. While the heavy lifting and all page rendering and processing tasks are done in PL/SQL, all of the client-side interaction and validation code is written in JavaScript using the open source jQuery library. At its core, APEX is a database application and thus makes extensive use of database objects such as tables, views, indexes, triggers, functions, procedures, packages, and so on. Much of APEX’s code is written in PL/SQL and called from the interface itself.
jQuery allows for more efficient, cross-browser, client-side interactions and has been integrated with APEX since version 4.0. It provides a set of rich-UI client-side components, such as modal dialog boxes, calendar tools, and tabs, that can easily and quickly be integrated into any web development platform.
![]() Note There is no Java code anywhere within the tool whatsoever, although it is possible to use Java within any developed APEX application by calling it from PL/SQL.
Note There is no Java code anywhere within the tool whatsoever, although it is possible to use Java within any developed APEX application by calling it from PL/SQL.
Metadata-Based Architecture
APEX is a declarative development environment, meaning that every object in an APEX application is actually stored as metadata in a set of database tables. When a page is rendered, APEX will call a set of its own PL/SQL procedures that will, in turn, read the corresponding metadata and use that to generate whatever components live on the page. Thus, when a new APEX page, report, form, chart, calendar, or even process is created, no new objects in the database are created. Rather, the information about that component is stored as metadata by APEX and recalled as an end user renders that page.
Historically, metadata-based tools have been limited as to the level of complexity that they are capable of supporting. If only a finite number of options can be defined, than only a finite number of results are possible. While APEX is also constrained by the number of options that are defined for a given component, it is quite extensible beyond the traditional limitations of a metadata-based architecture. APEX can evaluate and execute PL/SQL at almost any point during the rendering or processing of a page, whether it’s a named PL/SQL procedure or an anonymous block. This level of extensibility provides the developer with a limitless palette of options when designing applications.
All of the APEX metadata is exposed through a set of views simply called the APEX views. These views provide a view into all of the metadata that makes up everything within an APEX environment—from the workspace itself all the way down to a column in a report. Because a good portion of APEX is metadata-based, it is possible to use an automated process or tool, such as Enkitec eSERT, to inspect the vales of many of the attributes and determine whether they are set to the most secure setting. You can find a list of all APEX views on the application utilities page, as shown in Figure 3-6.
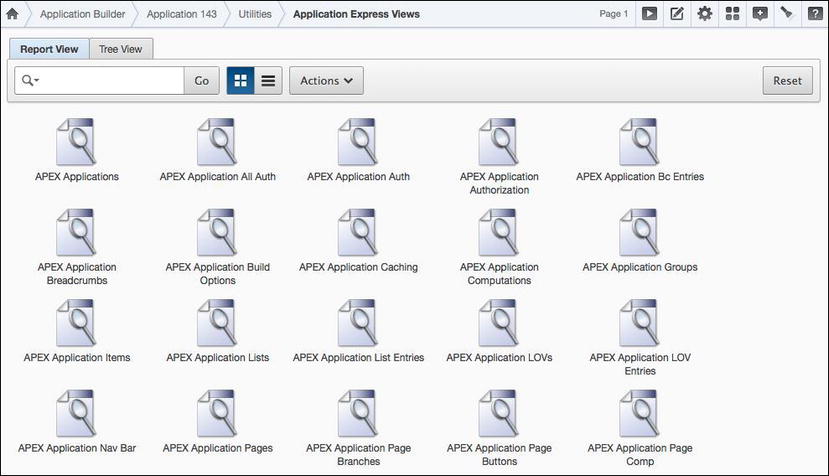
Figure 3-6 . The APEX views report, highlighting some of the APEX views available
APEX views can be accessed from any schema within the database but will return data only if the views are queried either from a schema that is mapped to a workspace or from SYS and SYSTEM. They can be accessed from any tools that can connect directly to the database, not just APEX itself.
Starting in version 4.1, APEX includes a new database role called APEX_ADMINISTRATOR_ROLE that, when granted to a schema, gives that schema two things: the ability to call the APEX_INSTANCE_ADMIN APIs in order to manage the instance of APEX and the ability to allow that schema to view applications from any workspace when querying any APEX view. This role should be granted with care because any schema it is granted to essentially becomes the equivalent of an instance administrator.
Schemas
Not counting any parse-as schema associated with a workspace, APEX itself consists of three schemas: APEX_040200, FLOWS_FILES, and APEX_PUBLIC_USER. These schemas are created and populated upon the installation of APEX. APEX_040200 is where all of the APEX database objects and metadata are stored. The 040200 portion of the schema name represents the version of APEX. Thus, your installation of APEX may be based on a previous version, depending on the value embedded in the schema name. FLOWS_FILES is a schema dedicated to storing uploaded files, either permanently or temporarily. And lastly, APEX_PUBLIC_USER is the only schema that APEX will directly connect to. All applications—including the application development environment—connect to the database using APEX_PUBLIC_USER and nothing else.
When created, two of these schemas—APEX_040200 and FLOW_FILES—will be locked and should remain that way. There is no reason for any developer to access these schemas directly, especially in a production environment. In fact, if the APEX_040200 schema is accessed and data is manipulated directly there, it could corrupt an application or potentially the entire instance of APEX. The third schema—APEX_PUBLIC_USER—is unlocked because it is the sole schema that APEX uses to connect directly to the database.
By default, all three of these schemas are secured with a single password that is supplied when installing APEX. Given that two of these schemas are locked, the fact that three schemas have the same password is not as critical if they were all unlocked. However, since the installation script does not enforce any password strength policies, it is possible to install APEX and set all three schemas’ passwords to something easy to crack, such as oracle.
It is recommended that the passwords of all three schemas immediately be set to a more secure password and that all three schemas use a different password. These passwords should be changed regularly and also adhere to any organizational password policies. Changing the password of APEX_040200 and FLOW_FILES will have no impact on the instance of APEX whatsoever, because nothing directly connects to those schemas. However, changing the password of APEX_PUBLIC_USER will impact APEX, because the password stored with the web server will also have to be updated accordingly, if either the Oracle HTTP Server or APEX Listener is being used.
APEX_PUBLIC_USER
The APEX_PUBLIC_USER schema is the single “gateway” schema that will be used for all APEX transactions in any APEX application, including the application development environment itself. This schema itself is extremely limited as to what it has access to. It is created with only a single system privilege—CREATE SESSION—and with no role or object privileges, as illustrated in Listing 3-1. It also does not own any objects.
Listing 3-1. The System, Role, and Object Privileges for APEX_PUBLIC_USER
SQL> SELECT * FROM dba_sys_privs
WHERE grantee = 'APEX_PUBLIC_USER';
GRANTEE PRIVILEGE ADM
--------------------- --------------------- ----
APEX_PUBLIC_USER CREATE SESSION NO
SQL> SELECT * FROM dba_role_privs
WHERE grantee = 'APEX_PUBLIC_USER';
no rows selected
SQL> SELECT * FROM user_tab_privs
WHERE grantee = 'APEX_PUBLIC_USER';
no rows selected
SQL> SELECT * FROM all_objects
WHERE owner = 'APEX_PUBLIC_USER';
no rows selected
No developer should ever have to connect directly to this schema for any reason, and it should not be modified in any way. It is also not locked by default, because the web server must connect directly to it in order for APEX to run. If the APEX_PUBLIC_USER account is compromised and accessed, there is little damage that can be done, because all of the APIs and views that APEX_PUBLIC_USER makes use of have embedded security controls within them that can’t be circumvented without access to a more privileged schema.
For an authenticated APEX session, the APEX engine will allow APEX_PUBLIC_USER to alter the current schema in which it parses based on the schema associated with the current application using DBMS_SYS_SQL.PARSE_AS_USER. Once this switch occurs, all SQL and PL/SQL code executed is actually being executed as if APEX were directly connected to the database as the parse-as schema. This “switch” is built into APEX and cannot be disabled or altered in any way.
![]() Note One gotcha to keep in mind is that any database role associated with the parse-as schema will not work. Many developers coming from an Oracle Forms environment have come to rely on database roles and may be perplexed as to why they will not work anymore in APEX.
Note One gotcha to keep in mind is that any database role associated with the parse-as schema will not work. Many developers coming from an Oracle Forms environment have come to rely on database roles and may be perplexed as to why they will not work anymore in APEX.
Since all APEX applications connect via APEX_PUBLIC_USER, it is impossible to distinguish which APEX session is mapped to which database session by using the USERNAME column alone in V$SESSION. In APEX 4.2, more thorough information about which APEX session maps to which database session has been added to the MODULE, CLIENT_INFO, and CLIENT_IDENTIFIER columns of V$SESSION.
The MODULE column now contains three values delimited by colons: the parsing schema followed by /APEX, APP followed by the APEX application ID, and the APEX page ID. The CLIENT_INFO column contains two values delimited by colons: the APEX-authenticated user name and the workspace ID. Lastly, the CLIENT_IDENTIFIER column contains two values delimited by colons: the APEX-authenticated user name and the session ID. Listing 3-2 shows an example of this.
Listing 3-2. The MODULE, CLIENT_ID, and CLIENT_IDENTIFIER Columns from V$SESSION for APEX_PUBLIC_USER
SQL> SELECT module, client_info, client_identifier
FROM v$session WHERE username = 'APEX_PUBLIC_USER';
MODULE CLIENT_INFO CLIENT_IDENTIFIER
--------------------- -------------------- -----------------
SAMPLE/APEX:APP 123:6 DEV:3010820895725282 DEV:931284638673
Despite this enhancement, the information stored in these three columns in V$SESSION represents the initial values set when that database session is created by APEX. A single database session may and almost always maps to a number of different APEX applications across different workspaces. Since APEX makes heavy reuse of database sessions, the values in these columns may not represent the current values of the session using them.
One last point to make about APEX_PUBLIC_USER is that if the Embedded PL/SQL Gateway is being used as the web server, the APEX_PUBLIC_USER may not exist in the database. Instead, APEX will use the ANONYMOUS user to connect to the database.
APEX_040200
The APEX_040200 schema is where all APEX database objects and metadata reside. The name of this schema will vary slightly based on the version of APEX. In earlier releases of APEX, the name of this schema substituted the word FLOWS for APEX. This was merely a cosmetic change that reflected the original name for APEX, Oracle Flows.
This schema ships as locked and should remain that way. Developers do not need direct access to this schema, especially in a production environment. However, the APEX_040200 schema contains a number of fascinating and interesting constructs that any curious developer would love to explore. For that type of activity, it is recommended—and even encouraged—for a developer to install APEX on a local virtual machine, unlock the APEX_040200 schema, and do their exploration there. This way, no harm can come to any shared systems. Any damage done will be limited to the virtual machine on the developer’s workstation and not impact anyone else.
The password for this schema is also set upon installation and is the same password used for the other two schemas, as well as the APEX instance administrator account. Because of this commonality, the password should be immediately changed to something more secure and different from the other APEX schemas. Unlike the APEX_PUBLIC_USER schema, there is much sensitive information in the APEX_040200 schema, and adequate precautions should be taken to protect it. Changing the password of APEX_040200 will not impact any part of the APEX environment and any associated web server in the least.
When browsing the APEX_040200 schema, it’s almost impossible to miss the fact that most objects contain a prefix of WWV_FLOW. The origin of this prefix is twofold. First, the WWV is the three-letter product abbreviation given to APEX when it was first conceived as an idea. Second, FLOW refers to the original name of APEX, Oracle Flows. The prefix has survived numerous product name changes and, from the looks of it, is here to stay.
As APEX’s name evolved from Oracle Flows to Oracle HTML DB to Oracle APEX, so did the name of the synonyms APEX used for its own APIs. Fortunately, all of the legacy synonym names have been preserved so that any references to either the FLOW or HTMLDB prefix-based ones will continue to function. For example, the table WWV_FLOW actually has three public synonyms that refer to it, as illustrated in Figure 3-7.

Figure 3-7 . Three synonyms for the same APEX table
Many of APEX_040200’s objects are accessible to PUBLIC, which on the surface seems like a really bad idea. However, all of the objects that can be accessed publicly do have the proper security controls embedded within them, making them useless outside of a properly authenticated APEX context. Listing 3-3 shows the breakdown of what types of privileges are granted to APEX_040200’s objects.
Listing 3-3. Privileges by Type Granted to APEX_040200’s Objects
SQL> SELECT privilege, count(*)
FROM user_tab_privs
WHERE grantee = 'PUBLIC'
GROUP BY privilege
ORDER BY 2 DESC
PRIVILEGE COUNT(*)
----------------------------------- --------
SELECT 164
EXECUTE 81
DELETE 3
UPDATE 1
INSERT 1
Each of the 81 packages accessible by PUBIC is secured with code that first validates that it is being called from a valid APEX session. If any attempt is made to execute them from outside of a valid session, they simply won’t work because the embedded security code will prevent them from doing so.
Of the 164 tables and views that can be accessed from PUBLIC, most of them are APEX views, which are secured in the WHERE clause to restrict who gets to see what data, based on schema-to-workspace mappings or the grant of the APEX_ADMINISTRATOR_ROLE. The remaining tables are either placeholder tables—such as WWV_FLOW_DUAL100, a table with 100 fixed rows—or global temporary tables used internally by APEX.
That leaves the remaining five privileges: an UPDATE, an INSERT, and three DELETEs. Listing 3-4 shows the specific objects these five privileges are granted on.
Listing 3-4. Specific Objects from the APEX_040200 Schema That Are Accessible by PUBLIC
SQL> SELECT grantee, owner, table_name, privilege
FROM user_tab_privs
WHERE privilege NOT IN ('SELECT','EXECUTE')
AND grantee = 'PUBLIC';
GRANTEE OWNER TABLE_NAME PRIVILEGE
------- ----------- ------------------------------ ---------
PUBLIC APEX_040200 WWV_FLOW_FILES DELETE
PUBLIC APEX_040200 WWV_FLOW_FILES INSERT
PUBLIC APEX_040200 WWV_FLOW_FILES UPDATE
PUBLIC APEX_040200 WWV_FLOW_USER_MAIL_ATTACHMENTS DELETE
PUBLIC APEX_040200 WWV_FLOW_USER_MAIL_QUEUE DELETE
All of the objects are actually also secured views, so without a valid APEX context set, no records will be returned, thus ensuring that the data remains protected.
FLOWS_FILES
The third and final schema in the APEX triumvirate is called FLOWS_FILES. This schema exists for the sole purpose of providing an initial repository to upload files. Nothing is ever supposed to connect to this schema, so it is also locked by default. In fact, it goes one step further because FLOWS_FILES even lacks the CREATE SESSION system privilege. The password of FLOWS_FILES can also be changed without impacting any part of the APEX environment.
FLOWS_FILES contains only 11 database objects: a single table, a trigger, and some synonyms and indexes. Listing 3-5 shows a full listing of its objects.
Listing 3-5. FLOWS_FILES Database Objects
SQL> SELECT object_name, object_type
FROM all_objects
WHERE owner = 'FLOWS_FILES';
OBJECT_NAME OBJECT_TYPE
------------------------------ -------------------
SYS_C004026 INDEX
WWV_FLOW_FILES_FILE_IDX INDEX
WWV_FLOW_FILES_USER_IDX INDEX
WWV_FLOW_FILE_OBJ_PK INDEX
WWV_FLOW SYNONYM
WWV_FLOW_FILE_API SYNONYM
WWV_FLOW_FILE_OBJECT_ID SYNONYM
WWV_FLOW_ID SYNONYM
WWV_FLOW_SECURITY SYNONYM
WWV_FLOW_FILE_OBJECTS$ TABLE
WWV_BIU_FLOW_FILE_OBJECTS TRIGGER
11 rows selected.
When any file is uploaded via an APEX application, it initially ends up in the WWV_FLOW_FILE_OBJECTS$ table. Whether it stays there permanently is, in some cases, up to the developer. If the file is uploaded from the application development environment, it will remain in the WWV_FLOW_FILE_OBJECTS$ table until it is either purged by a job or deleted manually. The view from which this table is accessed in the application development environment is augmented with security to segregate data based on the underlying workspace.
As a developer, there is the option to move uploaded files to the parse-as schema as part of the File Browse item type. This approach is highly recommended for a number of reasons. First, by moving the file to the parse-as schema, it can be linked via a foreign key to another record. Oracle Text can also easily index it in when it is moved to the parse-as schema. Lastly, by keeping the uploaded files in the parse-as schema, all of the application’s data exists in a single schema, making it more portable and manageable.
Transactions
One of the benefits of a metadata-based environment is that all transactions consist of the same components. It doesn’t matter how simple or complex, fast or slow, or well-designed or ugly an APEX application is—the fundamental way the APEX engine renders and processes pages is the same. Thus, it doesn’t matter who developed the application or how good or bad the SQL is. The underlying infrastructure functions the same, making it a lot easier to both understand how APEX works and take advantage of the architecture.
Like every other web application, APEX uses two HTML methods to facilitate page views and process input: GET and POST, respectively. On a high level, a GET is used to fetch data from the web server, whereas a POST is used to send data to the web server to be processed. In the Application Builder, APEX has its own nomenclature for each of these methods: page rendering and page processing. Any component defined in the page-rendering column can be mapped to the HTML GET method, whereas any component in the page-processing column can be mapped to the HTML POST method. Shared components, which make up the third column, can be called during either phase, depending on their type.
Understanding when APEX uses the GET and POST methods is one of the most critical and fundamental steps to becoming a skilled and security-conscious APEX developer. Almost every facet of the tool itself can be traced back to either a page-rendering or page-processing event, and being able to clearly delineate between the two of them is critical.
Under the covers, each of these two phases can be mapped to different PL/SQL procedures. All page rendering is handled by wwv_flow.show, whereas all page processing is handled by wwv_flow.accept. Experienced APEX users will recognize at least wwv_flow.accept because it is often referenced in error messages when a page or component can’t be found.
The f Procedure and WWV_FLOW.SHOW
APEX applications have a unique URL syntax that is easily identifiable. Basically, it starts with an f?p= and contains a string of colon-delimited values, as illustrated in Listing 3-6.
Listing 3-6. An Example of the APEX URL Syntax
http://server/apex/f?p=142:1:3514168517778::NO::P1_ITEM:123
As with any other web URL standards, the portion to the left of the ? represents the procedure or function to be called, and the portion to the right of the ? represents the value and attribute pairs that are passed to that procedure. When navigating from page to page via the URL, APEX typically uses a procedure called f and passes a colon-delimited string to a parameter called p. The f procedure actually has a number of additional parameters, as shown in Listing 3-7.
Listing 3-7. The f Procedure Used by APEX Pages via the URL
SQL> desc f
PROCEDURE f
Argument Name Type In/Out Default?
-------------------- -------------------- ------ --------
P VARCHAR2 IN DEFAULT
P_SEP VARCHAR2 IN DEFAULT
P_TRACE VARCHAR2 IN DEFAULT
C VARCHAR2 IN DEFAULT
PG_MIN_ROW VARCHAR2 IN DEFAULT
PG_MAX_ROWS VARCHAR2 IN DEFAULT
PG_ROWS_FETCHED VARCHAR2 IN DEFAULT
FSP_REGION_ID VARCHAR2 IN DEFAULT
SUCCESS_MSG VARCHAR2 IN DEFAULT
NOTIFICATION_MSG VARCHAR2 IN DEFAULT
CS VARCHAR2 IN DEFAULT
S VARCHAR2 IN DEFAULT
TZ VARCHAR2 IN DEFAULT
P_LANG VARCHAR2 IN DEFAULT
P_TERRITORY VARCHAR2 IN DEFAULT
In the example URL, when this page is rendered, the value 142:1:3514168517778::NO::P1_ITEM:123 will be passed to the p parameter of the f procedure. The f procedure will then take that string and decompose it into its discrete values. Once decomposed and after performing some basic security and globalization checks, the f procedure will in turn call wwv_flow.show and pass the discrete values to their corresponding parameters where they will be processed, and in turn, the page will be rendered.
Some of the additional parameters that can be passed to the f procedure may be recognizable. For example, passing the value YES to p_trace will cause APEX to generate a SQL trace file. The TZ parameter is used to set the corresponding time zone for a user. Others, however, are not as commonly used and undocumented, and passing values to them may cause erroneous results.
When run, wwv_flow.show will loop through all the components of a particular page and either execute or render them, depending on the component type. It will use a combination of execution/display point and component sequence to determine the order in which the components are rendered. This way, a computation that occurs before the header is rendered will be set so the computed value can be used in a report that is generated as part of the page body. Some components, such as computations and processes, will not have any output, whereas others, particularly almost any region type, will produce output. This process is repeated for each APEX page that is rendered or asynchronous process that is executed.
The WWV_FLOW.ACCEPT Procedure
Once a page is requested by the user and then rendered, the user can interact with it as they see fit—entering, selecting, and changing values, and so on. As soon as the user submits the page by clicking a button or other item that causes the page to be submitted, all the information on the page is sent back to the APEX engine for processing. The procedure that handles all page processing or POSTs in APEX is called wwv_flow.accept. Inspecting any APEX page will reveal an HTML form that looks similar to the example in Listing 3-8 that makes reference to wwv_flow.accept.
Listing 3-8. The HTML Form Definition from Any APEX Page
<form action="wwv_flow.accept" method="post" name="wwv_flow" id="wwvFlowForm">
Thus, when a page is submitted, all items on the page are passed in as parameters to the wwv_flow.accept procedure, as if it were being called from another PL/SQL procedure. Both items that are visible and hidden are passed back to the APEX engine. Each APEX page will contain a number of hidden items that are generated by APEX. These items store values for the application, page, session, page instance, and any checksums associated with the page.
One way to see all the items on the page is to view the HTML source. All modern browsers support this capability, typically by allowing the user to right-click anywhere on the page and select the corresponding function. The downside to this function is that the HTML document may be quite large and difficult to sift through to locate a specific element, especially in its raw form. A better alternative is to use a free add-on called Web Developer. Web Developer, written by Chris Pederick, will work with both Firefox and Chrome and can be downloaded from http://chrispederick.com/work/web-developer/.
After installing Web Developer, an additional menu bar will be visible in the browser, typically immediately below the bookmark bar, as highlighted in Figure 3-8.
![]()
Figure 3-8 . The Web Developer toolbar in Firefox
Selecting Display Form Details from the Forms menu will display all item details inline with items on the page. In addition to that, it will also display details for any hidden items, as illustrated in Figure 3-9.

Figure 3-9 . An APEX page with Display Form Details enabled
In APEX 4.2, the wwv_flow.accept procedure contains 510 parameters! Of these, 470 parameters are designed to accept input from APEX pages and asynchronous processes: 200 for items, 200 for arrays, 50 for tabular form columns, and 20 for items used in AJAX transactions. The remaining 40 parameters are used to specify other options such as application, page, session, and instance.
Since the names of the parameters in wwv_flow.accept are fixed and APEX item names can be anything the developer chooses, there has to be some sort of mapping that is done so that the APEX engine knows which item is which. This is what the p_arg_names items are used for. For each item on the page, there will always be a corresponding p_arg_names item as well. The p_arg_names items are always hidden and contain a relatively long numeric value, as shown in Figure 3-10.

Figure 3-10 . An APEX form, highlighting the p_arg_names hidden items
The value stored in p_arg_names is not arbitrary in the least. It actually refers to the primary key of the item that immediately precedes it in the form. By querying the source table for all APEX items—WWV_FLOW_STEP_ITEMS—the values in the ID column clearly correspond to the values set in p_arg_names, as shown in Figure 3-11.

Figure 3-11 . Item details from the WWV_FLOW_STEP_ITEMS table
For example, the item P6_PRODUCT_ID has an ID value of 7138049521757271892. In the HTML, the value of p_arg_names that immediately precedes P6_PRODUCT_ID also has a value of 7138049521757271892. Based on the fact that they have the same value, these two elements are clearly related.
When this form is submitted to the APEX engine, the value for P6_PRODUCT_ID will be passed to the parameter p_t01 in the wwv_flow.accept procedure. All of the p_arg_names will be passed as an array to the p_arg_names parameter in wwv_flow.accept. The APEX engine will then begin to map array values with parameters by looping through all of them. The first array value—7138049521757271892—will be used to look up the corresponding page item, which is of course P6_PRODUCT_ID. Once that association is made, APEX will set the session state of P6_PRODUCT_ID to the value that was passed into p_t01. It will repeat this process for each item passed to a parameter in wwv_flow.accept, setting each value in session state.
Tools like Web Developer are invaluable assets that make web development a lot easier and faster. Unfortunately, they can also be used for evil, because when the details of a form are displayed, they can be edited. Thus, it would be simple for a malicious user to change the value of P6_PRODUCT_ID from 7 to 6 and submit the form, causing the wrong record to be updated.
Fortunately, there are features in the Application Builder that will prevent such an alteration from occurring. Session state protection is an APEX feature that detects when the value of a specific item or items have been altered and prevents the resulting page submission from executing. You can find more information on how session state protection works and how to implement it in Chapters 6 and 7.
Session State
A traditional Oracle database session established via SQL*Plus or Oracle Forms is similar to a phone call. In both scenarios, each party—the client and the server—need to invest resources in order to create a connection. For that connection to be maintained, a fixed number of resources need to be reserved, even if little or no data is being transferred. A fixed number of connections can be established and maintained, depending on the server resources. Once that limit is reached or exceeded, all connections will suffer degradation in performance and potentially be dropped.
An APEX session is more similar to a text message than a phone call. Rather than establishing a dedicated connection to the database server, an APEX session is merely a short request for data followed immediately by a short reply. While both parties still need to dedicate resources for this exchange to occur, the amount needed is far less than a dedicated database connection. In fact, multiple APEX sessions can and almost always do share a single database connection because they are logically and physically distinct from a database session.
Since HTTP is a stateless protocol and does not maintain a persistent connection to the server, APEX contains its own robust session state management infrastructure. APEX’s session state management is enabled by default and does not require any additional code or configuration. It functions the same, regardless of which authentication scheme an application uses. In fact, it even works for unauthenticated users.
APEX uses a unique session ID to segregate its sessions from one another. That session ID is included in almost every APEX URL, as shown in Figure 3-12. In this example, the session ID is 9546423770164.
![]()
Figure 3-12 . The APEX session ID in a typical APEX URL
The session ID is not the only component that is required to validate a session. When a user accesses an APEX site, a cookie is sent to the user’s local computer. That cookie contains a value that, when combined with the session ID, proves that the user is an authenticated APEX user. Therefore, simply copying the URL from one computer to another will not result in successfully hijacking a session, because the corresponding cookie will not be present.
After logging into Application 123, a new cookie is sent to the client. Using the Web Developer toolbar, the cookie that APEX sends to the client can be viewed, as shown in Figure 3-13.

Figure 3-13 . The APEX session cookie, as viewed with Web Developer
Like most other web technologies, it uses client-side cookies to identify which client has authenticated as which user. The name of the cookie contains both the workspace ID and the application ID. The value of the cookie contains a string that corresponds to a hash of the session ID. In this example, the value is 174B4CB2999CA03560905978D172ABBA.
Internally, APEX maps the session ID (ID) to the hashed session ID (SESSION_ID_HASHED) value in the WWV_FLOW_SESSION$ table, as illustrated in Figure 3-14.

Figure 3-14 . The WWV_FLOW_SESSIONS$ table
When validating a session, APEX uses this combination of session ID and hashed session ID. If there is a match and the corresponding session ID has not been otherwise invalidated or expired, then the session is deemed valid. Access to this table is obviously restricted to the APEX engine only and cannot be otherwise used by APEX developers.
Once a valid session has been established, APEX will then be able to associate any session state values to that unique session ID. Session state values will always be stored in the database and never in a cookie on the client PC. This is good for a number of reasons. First, it is much more secure to keep those values in the database, where they cannot easily be obtained. Second, since most processing in APEX occurs in the database, it is more efficient to store values there, because the server will not have to fetch them from the client when they are needed. Third, if the database is bounced, users can continue using their applications as if nothing happened. Having database-based sessions is also what makes APEX a RAC-friendly development tool. No code changes or special considerations are required for developing APEX applications deployed on Oracle RAC (real application clusters).
The lifetime of an APEX session will vary and can be terminated by one of a number of events. First, as soon as the user logs out, the session will be terminated, and all associated values in session state will be purged. If a user completely closes all windows of the browser, the session cookie will expire, thus terminating the session. Closing just the browser tab, or even the browser window if multiple windows are open, is not enough because the session cookie may still be valid, meaning that if the session ID were retrievable via the back button, the user may be able to rejoin the existing session. An APEX administrator can proactively terminate APEX sessions based on their duration.
Each application also has a session duration and session idle time attribute. If either of these values is exceeded, the session will also be terminated. If the user attempts to modify the session ID in the URL, APEX will not only allow that user to hijack another session but also immediately expire the current session, should one exist. Lastly, by default, there is a scheduled job that will automatically purge any session—valid or otherwise—that is older than 24 hours old. This job runs every eight hours unless altered to run more or less frequently.
Infrastructure
A key part of the architecture of APEX is the underlying web server. While all the code business rules and security processes are managed in the database via PL/SQL, APEX is, after all, an HTML-based application and needs a delivery mechanism in order to present pages and interact with users.
Since APEX’s middle tier resides in PL/SQL, it does not require a traditional middle-tier application server. It does, however, require at least an HTTP server and component that will allow it to communicate with the database. There are currently three supported options that work with APEX: the Embedded PL/SQL Gateway, the Oracle HTTP Server and mod_plsql, and the APEX Listener.
While the details on how to implement and secure the different web servers that work with APEX is out of scope for this book, it is worth at least briefly calling attention to each of them in this section.
Embedded PL/SQL Gateway
Oracle Database 11g contains a built-in web server called the Embedded PL/SQL Gateway (EPG). The EPG runs in the XML DB HTTP server, as shown in Figure 3-15. It provides the same core features as mod_plsql does. All of the supporting files required for APEX—images, Cascading Style Sheets files, and JavaScript libraries—are stored in the database when using the EPG.
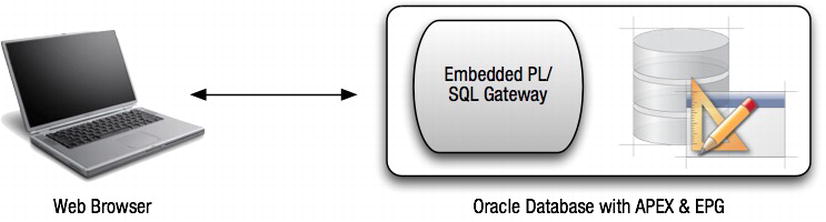
Figure 3-15 . The Oracle Embedded PL/SQL Gateway architecture
Because of its close proximity to the database, Oracle recommends not using the EPG when deploying applications on the Internet. That recommendation should be extended to any production system for the same reasoning. If not used, the EPG should be disabled immediately so that it cannot be illicitly accessed. To disable it, run the commands in Listing 3-9 as the SYS user.
Listing 3-9. Commands to Run As SYS to Disable the Embedded PL/SQL Gateway
EXEC DBMS_XDB.SETHTTPPORT(0);
EXEC DBMS_XDB.SETFTPPORT(0);
To verify that it has been disabled, either try to connect to APEX via the port previously configured by the EPG or run the script at @?/rdbms/admin/epgstat to get the status of the EPG.
Oracle HTTP Server and mod_plsql
The oldest and most mature web server in use with APEX is the Oracle HTTP Server and mod_plsql. The Oracle HTTP Server is a for-cost version of Apache that Oracle made some specific changes to. It is a fully supported product that is compatible with most other Apache modules, such as mod_rewrite or mod_security, and offers the most flexibility when it comes to configuration and management.
The Oracle HTTP Server can be installed on the same server as the database, on a separate tier entirely, or in conjunction with a load balancer for additional fault tolerance. Figure 3-16 illustrates the Oracle HTTP Server installed on its own server, providing a layer of additional separation between the web browser and database server. Firewalls can also be added between each and any of the tiers to restrict network traffic.

Figure 3-16 . The Oracle HTTP Server with mod_plsql architecture
For even more security, a second Apache server and reverse proxy architecture can be used to create what’s called a demilitarized zone (DMZ). If a hacker is successful in breaching the most outward-facing Apache server, they will still be outside of the internal network, or in the DMZ, where the damage they can inflict will be greatly mitigated.
APEX Listener
The third and newest option for serving up APEX pages is the APEX Listener. Introduced around the same time as APEX 4.0, the APEX Listener is a Java application that was designed from the ground up to work with APEX, as illustrated in Figure 3-17. Currently in its second major release, the APEX Listener can run in any J2EE-compliant application server. However, Oracle will provide support only for the following three: OC4J, Oracle Glassfish, and Oracle WebLogic. That is not to say that it won’t run in other J2EE application servers such as JBoss and Tomcat, for example; it’s just that if an issue arises with the APEX Listener, it will need to be verified with one of the three supported servers before Oracle will take action.
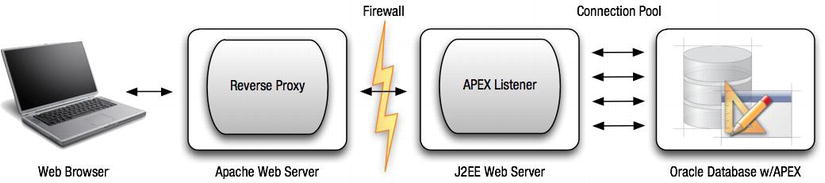
Figure 3-17 . The APEX Listener architecture
Oracle seems to be moving in the direction of increased support of the APEX Listener, because there have been a number of released and additional functionalities over the past couple of years. The most recent release added the ability for a single listener to service multiple database, added integration with ICAP servers for virus scanning, added the ability to manage the APEX listener via either a command line or the SQL Workshop, and added better support for RESTful web services.
Summary
The underlying architecture of APEX is both simple and sophisticated at the same time, which makes it quite unique. Its simplicity makes it easier to understand, install, and ultimately secure because there are fewer moving parts than most applications. Yet its sophistication allows for a number of different configurations, from the simple and basic to the sophisticated and complex. An APEX implementation can start small with as few as a server or two and expand as the organization requirements do.
Understanding some of the underlying technologies and specifics of APEX ultimately leads to a better and more security-conscious APEX developer. A deeper level of understanding provides developers with a more robust view of the technology, giving them the skills that let them anticipate potential issues and design their systems around them from the start.