
5
Future Outcomes Cover a Range of Possibilities: We Can Describe Uncertainties in Real Estate Using Probability Distributions of Possible Future Outcomes
Let’s now begin to face the reality of the uncertainties that we inevitably encounter in real estate investment and development. Demand rises and falls; prices and rents do likewise; and governments change taxes, zoning, and other regulations. In short, the future is uncertain. The “forecast is always wrong” in that what actually occurs almost always differs in some way from the pro forma projection.
This reality, this uncertainty, underlies the value of flexibility, the value of the manager’s ability to adapt plans to actual circumstances. While a quiet, uneventful life has its attractions, secure, unvarying returns, on average, yield the lowest returns, the risk‐free rate. The uncertainty and variability in the market provides the opportunities for higher returns. Skill in understanding and managing change provides the means to take advantage of change. We need to understand and describe the uncertainties in a quantitative manner, so that we can quantify the value of such flexibility. This chapter provides a common understanding of the important ways to describe and quantify uncertainties in real estate.
5.1 Distribution of Future Outcomes
A “distribution” of future possibilities describes the probability, the likelihood, of some situational circumstance. For example, is the market for office space up or down? Will the profit from this investment exceed $10M? In general, some future situations are more likely to happen than others.
The probability distribution of a future variable describes the probability of its possible outcomes over a range—that is, the relative likelihood of occurrence of some value or particular outcome. In a sample or simulation, the relative frequency of the occurrence reflects the probability distribution. The “range” (also known as a “domain”) describes all the possible future outcomes or values. The frequency (or “density”) indicates the relative likelihood of each possible value on the range. Summing (or integrating) the probability density across the range, by definition, produces a value of unity (1.00). This is because we measure probabilities in relative terms, and the range describes all of the possible outcomes (that is, something must happen, which implies the cumulative probability of 1.00).
We often represent probability distributions by graphs. The horizontal axis defines the possible events that can happen, and the vertical axis gives the probability of each such outcome. The distributions can be either continuous or discrete, either curves or bar charts (histograms). We often refer to the “shape of the distribution” as shorthand for more technical names. Two common types of distributions are bell‐shaped and skewed, as Box 5.1 illustrates.
The shape of the probability distribution can have important implications both for the value of a project or investment, and for the strategies and decisions we might use to implement or operate the project. For example, for start‐up ventures with high chances of failure but great upside potential, we want both the flexibility to exit at low cost if things turn sour, and the ability to cash in fully if the project is a great success. It is therefore important to think about the possible shape of the distributions we might encounter.
The general rule is that we need to work with the entire range of possible outcomes, and not just the most likely cases. For example, consider the skewed probability distribution for the event of fires in any building. It is most likely that the building will not have any fires, somewhat possible for it to have some incidents, and only slightly possible to suffer a total loss from fire. However, we would be unwise in designing a project to focus on the most likely prospects and neglect the possibility of fire. We need to consider the whole distribution of possibilities and act accordingly.
5.2 Quantifying Input Distributions
We need to quantify the probability distributions of future possibilities in order to have the information we need to carry out a quantitative analysis. For investment analysis, this may include variables such as prices, costs, demand, growth rates, yields, etc. There are three ways to obtain information about quantifying the probability distributions of future variables. We can:
- Consult experts for their judgment;
- Base forecasts on perceived trends; and,
- Analyze empirical data statistically for trends and variability.
We often rely on the opinion of persons who are well informed on a subject. Consider the example in the previous chapter that dealt with two possible scenarios: either an attractive development went forward nearby and boosted the prospective rents, or the development did not occur and rents decreased. Just to demonstrate the analysis, we assumed that each scenario was equally possible, had a 50:50 chance of occurring. In practice, however, we can expect that a developer has access to better, maybe inside, knowledge about the scenarios. In that case, we might accept a developer’s judgment that the likelihood of the scenarios was, say, 70:30. We could use this data in the analysis and obtain a more informed, thus better, value of the project. At least, that’s what we think!
We need to be careful with expert opinions. It is human to bias one’s beliefs toward what one wishes were true; what one is familiar with; or one’s own vested interests. Experts in many fields often believe they “know” what will happen regardless of persistent evidence to the contrary. Cognitive psychologists refer to this tendency as anchoring: people tend to fixate on their original estimates, and do not use new information to update their original views as much they should. Box 5.2 gives one of many possible examples. Moreover, extensive experiments document cases in which experts are routinely overconfident. Being sure of their knowledge, experts often minimize the range of possible eventualities and estimate probability distributions much too narrowly.
Another way we can obtain information about quantifying the probability of future inputs is by looking at perceived trends. Following trends is a common, instinctive way to forecast the future. Developers perceive that certain markets are “hot” (the ones that have been growing steadily at a good rate), and developers plan and act as if this pattern will continue. We see this all the time in practice. Sometimes the forecasts explicitly refer to a trend: “tourist traffic has been increasing at X percent annually … and will continue to do so.” Sometimes the forecasts are dressed up in a statistical analysis that simply extends the historical trend.
Either way, trend forecasts neglect the fact that trends regularly break. “Trend‐breaking” events routinely occur. For example, oil prices drop, the economy of Houston falters, and real estate prices collapse. Or, a real estate boom becomes a “bubble” that bursts. And so on. It can be dangerous to assume that current trends will continue throughout the life of a project. Good analysis needs to make provision for “trend‐breaking” events. We need to understand more deeply the dynamics that matter—not just the long‐run average trend, but also random volatility as well as tendencies toward, or susceptibility to, cyclicality, mean‐reversion, inertia, and “surprise” events or disruptions.
A third way to obtain information about the future is to analyze relevant empirical data. Statistical analysis of historical data on market dynamics is generally the preferable way to obtain the probability distributions for investment analysis, when sufficient data exists. Fortunately, detailed historical data on real estate prices over time are increasingly available in major markets. These enable us to estimate the probability distributions of future real estate prices and rents using statistical analysis. Although history does not repeat, it tends to “rhyme,” as the cliché goes.
Statistical analysis can help us understand important dynamic characteristics of the local real estate market. These include such items as the magnitude of:
- Volatility (how much outcomes evolve randomly);
- Cyclicality (the tendency of the market to have “boom” and “bust” periods); and
- Mean‐reversion (the tendency of extreme observations to be followed by observations closer to the mean), and so forth.
Absent a good reason otherwise, it is usually best to assume that future market prices will tend to reflect dynamic characteristics similar to those that occurred in the past. Quantifying these features in past empirical data can help us understand how flexible management can obtain the greatest value from projects, and thus get the best, most informed project valuations.
For our present purpose, let’s simply accept that, when we have good readings on past performance, we can obtain reasonable characterizations of the relevant probability distributions for the parameters used in an investment analysis. Even where we don’t have empirical data for a specific local market, we can apply analogy and common sense to develop plausible input probability distributions for many typical projects.
5.3 Distributions of Outcomes Differ from Distributions of Inputs
We are ultimately interested in the results of the analysis, the quantitative outcomes depicted in the simulation of future scenarios. We use models of the outcomes that depend on inputs about the relevant probability distributions. For example, in the simple illustration in Chapter 4, the input probability distribution was that there was a 50/50 chance of either the optimistic or pessimistic scenario occurring. The outcome was that, with resale timing flexibility, the present value would be either $1294 with a 10‐year hold, or $872 with a Year 1 resale. When we work with distributions of possible inputs (as we should!), we will get corresponding distributions of possible outcomes. How should we understand and work with outcome distributions?
As a rule, the probability distributions of outcomes from a simulation model will not look the same as the distributions of the inputs. The example in the previous chapter provides a very simple illustration of this possibility. Table 5.1 repeats and extends the key information from that case. Note that the input probability distribution is symmetric: cash flows differ from the projection by an equal amount above or below. However, once we model the manager’s decision flexibility on resale timing, the outcomes are not symmetric. Because the investor has the flexibility to time the resale of the property, the value of the property is either above by 29%, or below by 13%, as compared to the pro forma projection.
Table 5.1 Outcome and input distributions differ.

This fact—that outcome distributions differ from input distributions—is a most important point. Intelligent management will make use of its flexibility to react to circumstances as they develop. Good managers will act to maximize upside opportunities and minimize downside losses. Of course, various physical and other constraints may limit the owners’ ability to react to circumstances (for example, to expand their development). But, in general, the shape of the distribution of outcomes from a simulation analysis will not be the same as the shape of the distribution of inputs. For example, it is wrong to assume that a ±10% range in future prices will lead to a ±10% range in profits. The range may be greater or smaller, and it may be asymmetric; as in Table 5.1, it might be +29% and −13%.
5.4 Flaw of Averages
The “flaw of averages” refers to the idea that we should not base decisions only on the average values of the input parameters. If we do that, we may miss important opportunities or major risks that average values mask. We presented a simple but quantitatively explicit example of this point in Chapter 4. The flaw of averages in general consists of failing to look beyond average conditions, failing to consider scenarios, and thus failing to value options. In the context of DCF valuation, the flaw of averages resides in excessive dependence on the traditional, single‐stream cash flow pro forma.
The term “flaw of averages” is a clever pun. It combines the notion of a flaw, that is, a mistake, with the concept of the “law of averages,” which is the notion that future events will balance out toward an average. The name thus emphasizes that using average input values to estimate future expected outcome values is a mistake.
The flaw of averages is a generalized extension of the fact that the outcome and input probability distributions typically differ. A particular case of this idea occurs with the mathematical rule called “Jensen’s Inequality,” which states that, unless a mathematical model (or equation) is linear (that is, only consists of simple additions), the:
A simple example demonstrates this reality. Suppose the mathematical model is
And that x is equally likely to be 1, 3, or 5, and thus has an average value of 3. Then:
But this does not equal the:
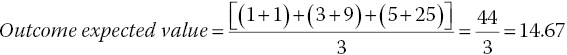
The overall point is very simple: Unless we recognize and work with the entire distribution of possibilities, we get the wrong answers—and miss hidden opportunities to improve outcomes.
5.5 Conclusion
This chapter discussed probability distributions, setting the stage for the chapters that follow. The chapter’s takeaway concepts include the following:
- There are several ways to estimate the probability of inputs to DCF analyses.
- Probabilities for outcomes usually differ from those of inputs: what comes out does not look like what goes in!
- The flaw of averages phenomenon indicates that we get wrong answers if we do not consider the range of inputs.