
Chapter 27. Testing Asynchronous Code
I can spell banana but I never know when to stop.
—Johnny Mercer (songwriter)
Introduction
Some tests must cope with asynchronous behavior—whether they’re end-to-end tests probing a system from the outside or, as we’ve just seen, unit tests exercising multithreaded code. These tests trigger some activity within the system to run concurrently with the test’s thread. The critical difference from “normal” tests, where there is no concurrency, is that control returns to the test before the tested activity is complete—returning from the call to the target code does not mean that it’s ready to be checked.
For example, this test assumes that a Set has finished adding an element when the add() method returns. Asserting that set has a size of one verifies that it did not store duplicate elements.

By contrast, this system test is asynchronous. The holdingOfStock() method synchronously downloads a stock report by HTTP, but the send() method sends an asynchronous message to a server that updates its records of stocks held.
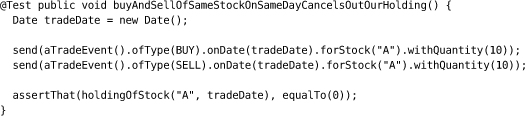
The transmission and processing of a trade message happens concurrently with the test, so the server might not have received or processed the messages yet when the test makes its assertion. The value of the stock holding that the assertion checks will depend on timings: how long the messages take to reach the server, how long the server takes to update its database, and how long the test takes to run. The test might fire the assertion after both messages have been processed (passing correctly), after one message (failing incorrectly), or before either message (passing, but testing nothing at all).
As you can see from this small example, with an asynchronous test we have to be careful about its coordination with the system it’s testing. Otherwise, it can become unreliable, failing intermittently when the system is working or, worse, passing when the system is broken.
Current testing frameworks provide little support for dealing with asynchrony. They mostly assume that the tests run in a single thread of control, leaving the programmer to build the scaffolding needed to test concurrent behavior. In this chapter we describe some practices for writing reliable, responsive tests for asynchronous code.
Sampling or Listening
The fundamental difficulty with testing asynchronous code is that a test triggers activity that runs concurrently with the test and therefore cannot immediately check the outcome of the activity. The test will not block until the activity has finished. If the activity fails, it will not throw an exception back into the test, so the test cannot recognize if the activity is still running or has failed. The test therefore has to wait for the activity to complete successfully and fail if this doesn’t happen within a given timeout period.
This implies that every tested activity must have an observable effect: a test must affect the system so that its observable state becomes different. This sounds obvious but it drives how we think about writing asynchronous tests. If an activity has no observable effect, there is nothing the test can wait for, and therefore no way for the test to synchronize with the system it is testing.
There are two ways a test can observe the system: by sampling its observable state or by listening for events that it sends out. Of these, sampling is often the only option because many systems don’t send any monitoring events. It’s quite common for a test to include both techniques to interact with different “ends” of its system. For example, the Auction Sniper end-to-end tests sample the user interface for display changes, through the WindowLicker framework, but listen for chat events in the fake auction server.
Beware of Flickering Tests
![]()
A test can fail intermittently if its timeout is too close to the time the tested behavior normally takes to run, or if it doesn’t synchronize correctly with the system. On a small system, an occasional flickering test might not cause problems—the test will most likely pass during the next build—but it’s risky. As the test suite grows, it becomes increasingly difficult to get a test run in which none of the flickering tests fail.
Flickering tests can mask real defects. If the system itself occasionally fails, the tests that accurately detect those failures will seem to be flickering. If the suite contains unreliable tests, intermittent failures detected by reliable tests can easily be ignored. We need to make sure we understand what the real problem is before we ignore flickering tests.
Allowing flickering tests is bad for the team. It breaks the culture of quality where things should “just work,” and even a few flickering tests can make a team stop paying attention to broken builds. It also breaks the habit of feedback. We should be paying attention to why the tests are flickering and whether that means we should improve the design of both the tests and code. Of course, there might be times when we have to compromise and decide to live with a flickering test for the moment, but this should be done reluctantly and include a plan for when it will be fixed.
As we saw in the last chapter, synchronizing by simply making each test wait for a fixed time is not practical. The test suite for a system of any size will take too long to run. We know we’ll have to wait for failing tests to time out, but succeeding tests should be able to finish as soon as there’s a response from the code.
Succeed Fast
![]()
Make asynchronous tests detect success as quickly as possible so that they provide rapid feedback.
Of the two observation strategies we outlined in the previous section, listening for events is the quickest. The test thread can block, waiting for an event from the system. It will wake up and check the result as soon as it receives an event.
The alternative—sampling—means repeatedly polling the target system for a state change, with a short delay between polls. The frequency of this polling has to be tuned to the system under test, to balance the need for a fast response against the load it imposes on the target system. In the worst case, fast polling might slow the system enough to make the tests unreliable.
Put the Timeout Values in One Place
![]()
Both observation strategies use a timeout to detect that the system has failed. Again, there’s a balance to be struck between a timeout that’s too short, which will make the tests unreliable, and one that’s too long, which will make failing tests too slow. This balance can be different in different environments, and will change as the system grows over time.
When the timeout duration is defined in one place, it’s easy to find and change. The team can adjust its value to find the right balance between speed and reliability as the system develops.
Two Implementations
Scattering ad hoc sleeps and timeouts throughout the tests makes them difficult to understand, because it leaves too much implementation detail in the tests themselves. Synchronization and assertion is just the sort of behavior that’s suitable for factoring out into subordinate objects because it usually turns into a bad case of duplication if we don’t. It’s also just the sort of tricky code that we want to get right once and not have to change again.
In this section, we’ll show an example implementation of each observation strategy.
Capturing Notifications
An event-based assertion waits for an event by blocking on a monitor until it gets notified or times out. When the monitor is notified, the test thread wakes up and continues if it finds that the expected event has arrived, or blocks again. If the test times out, then it raises a failure.
NotificationTrace is an example of how to record and test notifications sent by the system. The setup of the test will arrange for the tested code to call append() when the event happens, for example by plugging in an event listener that will call the method when triggered. In the body of the test, the test thread calls containsNotification() to wait for the expected notification or fail if it times out. For example:
trace.containsNotification(startsWith("WANTED"));
will wait for a notification string that starts with WANTED.
Within NotificationTrace, incoming notifications are stored in a list trace, which is protected by a lock traceLock. The class is generic, so we don’t specify the type of these notifications, except to say that the matchers we pass into containsNotification() must be compatible with that type. The implementation uses Timeout and NotificationStream classes that we’ll describe later.

![]() We store notifications in a list so that they’re available to us for other queries and so that we can include them in a description if the test fails (we don’t show how the description is constructed).
We store notifications in a list so that they’re available to us for other queries and so that we can include them in a description if the test fails (we don’t show how the description is constructed).
![]() The
The append() method, called from a worker thread, appends a new notification to the trace, and then tells any threads waiting on traceLock to wake up because there’s been a change. This is called by the test infrastructure when triggered by an event in the system.
![]() The
The containsNotification() method, called from the test thread, searches through all the notifications it has received so far. If it finds a notification that matches the given criteria, it returns. Otherwise, it waits until more notifications arrive and checks again. If it times out while waiting, then it fails the test.
The nested NotificationStream class searches the unexamined elements in its list for one that matches the given criteria. It allows the list to grow between calls to hasMatched() and picks up after the last element it looked at.
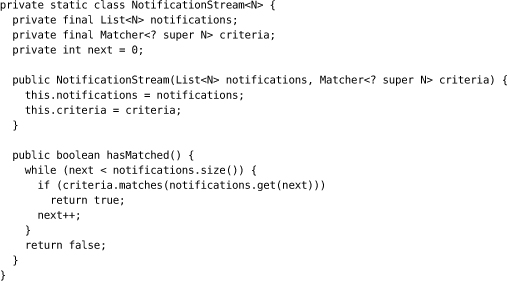
NotificationTrace is one example of a simple coordination class between test and worker threads. It uses a simple approach, although it does avoid a possible race condition where a background thread delivers a notification before the test thread has started waiting. Another implementation, for example, might have containsNotification() only search messages received after the previous call. What is appropriate depends on the context of the test.
Polling for Changes
A sample-based assertion repeatedly samples some visible effect of the system through a “probe,” waiting for the probe to detect that the system has entered an expected state. There are two aspects to the process of sampling: polling the system and failure reporting, and probing the system for a given state. Separating the two helps us think clearly about the behavior, and different tests can reuse the polling with different probes.
Poller is an example of how to poll a system. It repeatedly calls its probe, with a short delay between samples, until the system is ready or the poller times out. The poller drives a probe that actually checks the target system, which we’ve abstracted behind a Probe interface.
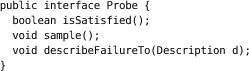
The probe’s sample() method takes a snapshot of the system state that the test is interested in. The isSatisfied() method returns true if that state meets the test’s acceptance criteria. To simplify the poller logic, we allow isSatisfied() to be called before sample().
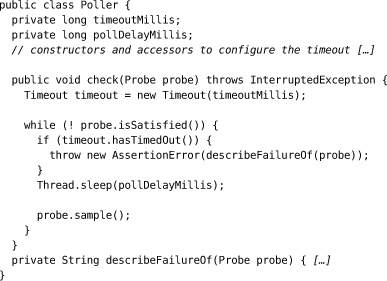
This simple implementation delegates synchronization with the system to the probe. A more sophisticated version might implement synchronization in the poller, so it could be shared between probes. The similarity to NotificationTrace is obvious, and we could have pulled out a common abstract structure, but we wanted to keep the designs clear for now.
To poll, for example, for the length of a file, we would write this line in a test:
assertEventually(fileLength("data.txt", is(greaterThan(2000))));
This wraps up the construction of our sampling code in a more expressive assertion. The helper methods to implement this are:
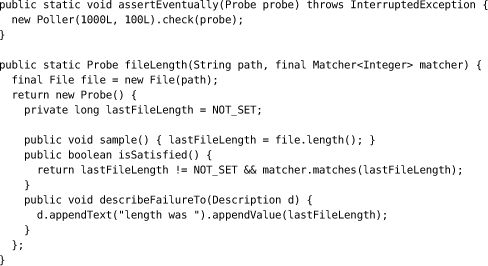
Separating the act of sampling from checking whether the sample is satisfactory makes the structure of the probe clearer. We can hold on to the sample result to report the unsatisfactory result we found if there’s a failure.
Timing Out
Finally we show the Timeout class that the two example assertion classes use. It packages up time checking and synchronization:

Retrofitting a Probe
We can now rewrite the test from the introduction. Instead of making an assertion about the current holding of a stock, the test must wait for the holding of the stock to reach the expected level within an acceptable time limit.

Previously, the holdingOfStock() method returned a value to be compared. Now it returns a Probe that samples the system’s holding and returns if it meets the acceptance criteria defined by a Hamcrest matcher—in this case equalTo(0).
Runaway Tests
Unfortunately, the new version of the test is still unreliable, even though we’re now sampling for a result. The assertion is waiting for the holding to become zero, which is what we started out with, so it’s possible for the test to pass before the system has even begun processing. This test can run ahead of the system without actually testing anything.
The worst aspect of runaway tests is that they give false positive results, so broken code looks like it’s working. We don’t often review tests that pass, so it’s easy to miss this kind of failure until something breaks down the line. Even more tricky, the code might have worked when we first wrote it, as the tests happened to synchronize correctly during development, but now it’s broken and we can’t tell.
Beware of Tests That Return the System to the Same State
![]()
Be careful when an asynchronous test asserts that the system returns to a previous state. Unless it also asserts that the system enters an intermediate state before asserting the initial state, the test will run ahead of the system.
To stop the test running ahead of the system, we must add assertions that wait for the system to enter an intermediate state. Here, for example, we make sure that the first trade event has been processed before asserting the effect of the second event:

Similarly, in Chapter 14, we check all the displayed states in the acceptance tests for the Auction Sniper user interface:

We want to make sure that the sniper has responded to each message before continuing on to the next one.
Lost Updates
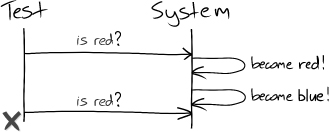
A significant difference between tests that sample and those that listen for events is that polling can miss state changes that are later overwritten, Figure 27.1.
Figure 27.1 A test that polls can miss changes in the system under test
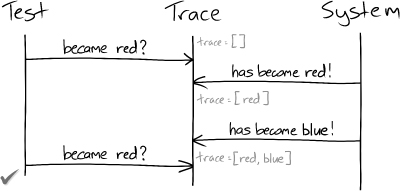
If the test can record notifications from the system, it can look through its records to find significant notifications.
Figure 27.2 A test that records notifications will not lose updates
To be reliable, a sampling test must make sure that its system is stable before triggering any further interactions. Sampling tests need to be structured as a series of phases, as shown in Figure 27.3. In each phase, the test sends a stimulus to prompt a change in the observable state of the system, and then waits until that change becomes visible or times out.
Figure 27.3 Phases of a sampling test
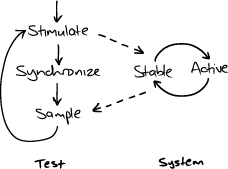
This shows the limits of how precise we can be with a sampling test. All the test can do between “stimulate” and “sample” is wait. We can write more reliable tests by not confusing the different steps in the loop and only triggering further changes once we’ve detected that the system is stable by observing a change in its sampled state.
Testing That an Action Has No Effect
Asynchronous tests look for changes in a system, so to test that something has not changed takes a little ingenuity. Synchronous tests don’t have this problem because they completely control the execution of the tested code. After invoking the target object, synchronous tests can query its state or check that it hasn’t made any unexpected calls to its neighbors.
If an asynchronous test waits for something not to happen, it cannot even be sure that the system has started before it checks the result. For example, if we want to show that trades in another region are not counted in the stock holding, then this test:

cannot tell whether the system has correctly ignored the trade or just not received it yet. The most obvious workaround is for the test to wait for a fixed period of time and then check that the unwanted event did not occur. Unfortunately, this makes the test run slowly even when successful, and so breaks our rule of “succeed fast.”
Instead, the test should trigger a behavior that is detectable and use that to detect that the system has stabilized. The skill here is in picking a behavior that will not interfere with the test’s assertions and that will complete after the tested behavior. For example, we could add another trade event to the regions example. This shows that the out-of-region event is excluded because its quantity is not included in the total holding.

Of course, this test assumes that trade events are processed in sequence, not in parallel, so that the second event cannot overtake the first and give a false positive. That’s why such tests are not completely “black box” but have to make assumptions about the structure of the system. This might make these tests brittle—they would misreport if the system changes the assumptions they’ve been built on. One response is to add a test to confirm those expectations—in this case, perhaps a stress test to confirm event processing order and alert the team if circumstances change. That said, there should already be other tests that confirm those assumptions, so it may be enough just to associate these tests, for example by grouping them in the same test package.
Distinguish Synchronizations and Assertions
We have one mechanism for synchronizing a test with its system and for making assertions about that system—wait for an observable condition and time out if it doesn’t happen. The only difference between the two activities is our interpretation of what they mean. As always, we want to make our intentions explicit, but it’s especially important here because there’s a risk that someone may look at the test later and remove what looks like a duplicate assertion, accidentally introducing a race condition.
We often adopt a naming scheme to distinguish between synchronizations and assertions. For example, we might have waitUntil() and assertEventually() methods to express the purpose of different checks that share an underlying implementation.
Alternatively, we might reserve the term “assert” for synchronous tests and use a different naming conventions in asynchronous tests, as we did in the Auction Sniper example.
Externalize Event Sources
Some systems trigger their own events internally. The most common example is using a timer to schedule activities. This might include repeated actions that run frequently, such as bundling up emails for forwarding, or follow-up actions that run days or even weeks in the future, such as confirming a delivery date.
Hidden timers are very difficult to work with because they make it hard to tell when the system is in a stable state for a test to make its assertions. Waiting for a repeated action to run is too slow to “succeed fast,” to say nothing of an action scheduled a month from now. We also don’t want tests to break unpredictably because of interference from a scheduled activity that’s just kicked in. Trying to test a system by coinciding timers is just too brittle.
The only solution is to make the system deterministic by decoupling it from its own scheduling. We can pull event generation out into a shared service that is driven externally. For example, in one project we implemented the system’s scheduler as a web service. System components scheduled activities by making HTTP requests to the scheduler, which triggered activities by making HTTP “postbacks.” In another project, the scheduler published notifications onto a message bus topic that the components listened to.
With this separation in place, tests can step the system through its behavior by posing as the scheduler and generating events deterministically. Now we can run system tests quickly and reliably. This is a nice example of a testing requirement leading to a better design. We’ve been forced to abstract out scheduling, which means we won’t have multiple implementations hidden in the system. Usually, introducing such an event infrastructure turns out to be useful for monitoring and administration.
There’s a trade-off too, of course. Our tests are no longer exercising the entire system. We’ve prioritized test speed and reliability over fidelity. We compensate by keeping the scheduler’s API as simple as possible and testing it rigorously (another advantage). We would probably also write a few slow tests, running in a separate build, that exercise the whole system together including the real scheduler.