
Chapter 4. Kick-Starting the Test-Driven Cycle
We should be taught not to wait for inspiration to start a thing. Action always generates inspiration. Inspiration seldom generates action.
—Frank Tibolt
Introduction
The TDD process we described in Chapter 1 assumes that we can grow the system by just slotting the tests for new features into an existing infrastructure. But what about the very first feature, before we have this infrastructure? As an acceptance test, it must run end-to-end to give us the feedback we need about the system’s external interfaces, which means we must have implemented a whole automated build, deploy, and test cycle. This is a lot of work to do before we can even see our first test fail.
Deploying and testing right from the start of a project forces the team to understand how their system fits into the world. It flushes out the “unknown unknown” technical and organizational risks so they can be addressed while there’s still time. Attempting to deploy also helps the team understand who they need to liaise with, such as system administrators or external vendors, and start to build those relationships.
Starting with “build, deploy, and test” on a nonexistent system sounds odd, but we think it’s essential. The risks of leaving it to later are just too high. We have seen projects canceled after months of development because they could not reliably deploy their system. We have seen systems discarded because new features required months of manual regression testing and even then the error rates were too high. As always, we view feedback as a fundamental tool, and we want to know as early as possible whether we’re moving in the right direction. Then, once we have our first test in place, subsequent tests will be much quicker to write.
First, Test a Walking Skeleton
The quandary in writing and passing the first acceptance test is that it’s hard to build both the tooling and the feature it’s testing at the same time. Changes in one disrupt any progress made with the other, and tracking down failures is tricky when the architecture, the tests, and the production code are all moving. One of the symptoms of an unstable development environment is that there’s no obvious first place to look when something fails.
We can cut through this “first-feature paradox” by splitting it into two smaller problems. First, work out how to build, deploy, and test a “walking skeleton,” then use that infrastructure to write the acceptance tests for the first meaningful feature. After that, everything will be in place for test-driven development of the rest of the system.
A “walking skeleton” is an implementation of the thinnest possible slice of real functionality that we can automatically build, deploy, and test end-to-end [Cockburn04]. It should include just enough of the automation, the major components, and communication mechanisms to allow us to start working on the first feature. We keep the skeleton’s application functionality so simple that it’s obvious and uninteresting, leaving us free to concentrate on the infrastructure. For example, for a database-backed web application, a skeleton would show a flat web page with fields from the database. In Chapter 10, we’ll show an example that displays a single value in the user interface and sends just a handshake message to the server.
It’s also important to realize that the “end” in “end-to-end” refers to the process, as well as the system. We want our test to start from scratch, build a deployable system, deploy it into a production-like environment, and then run the tests through the deployed system. Including the deployment step in the testing process is critical for two reasons. First, this is the sort of error-prone activity that should not be done by hand, so we want our scripts to have been thoroughly exercised by the time we have to deploy for real. One lesson that we’ve learned repeatedly is that nothing forces us to understand a process better than trying to automate it. Second, this is often the moment where the development team bumps into the rest of the organization and has to learn how it operates. If it’s going to take six weeks and four signatures to set up a database, we want to know now, not two weeks before delivery.
In practice, of course, real end-to-end testing may be so hard to achieve that we have to start with infrastructure that implements our current understanding of what the real system will do and what its environment is. We keep in mind, however, that this is a stop-gap, a temporary patch until we can finish the job, and that unknown risks remain until our tests really run end-to-end. One of the weaknesses of our Auction Sniper example (Part III) is that the tests run against a dummy server, not the real site. At some point before going live, we would have had to test against Southabee’s On-Line; the earlier we can do that, the easier it will be for us to respond to any surprises that turn up.
Whilst building the “walking skeleton,” we concentrate on the structure and don’t worry too much about cleaning up the test to be beautifully expressive. The walking skeleton and its supporting infrastructure are there to help us work out how to start test-driven development. It’s only the first step toward a complete end-to-end acceptance-testing solution. When we write the test for the first feature, then we need to “write the test you want to read” (page 42) to make sure that it’s a clear expression of the behavior of the system.
Deciding the Shape of the Walking Skeleton
The development of a “walking skeleton” is the moment when we start to make choices about the high-level structure of our application. We can’t automate the build, deploy, and test cycle without some idea of the overall structure. We don’t need much detail yet, just a broad-brush picture of what major system components will be needed to support the first planned release and how they will communicate. Our rule of thumb is that we should be able to draw the design for the “walking skeleton” in a few minutes on a whiteboard.
Mappa Mundi
![]()
We find that maintaining a public drawing of the structure of the system, for example on the wall in the team’s work area as in Figure 4.1, helps the team stay oriented when working on the code.
Figure 4.1 A broad-brush architecture diagram drawn on the wall of a team’s work area

To design this initial structure, we have to have some understanding of the purpose of the system, otherwise the whole exercise risks being meaningless. We need a high-level view of the client’s requirements, both functional and nonfunctional, to guide our choices. This preparatory work is part of the chartering of the project, which we must leave as outside the scope of this book.
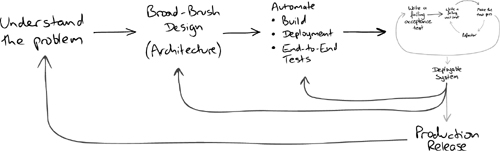
The point of the “walking skeleton” is to use the writing of the first test to draw out the context of the project, to help the team map out the landscape of their solution—the essential decisions that they must take before they can write any code; Figure 4.2 shows how the TDD process we drew in Figure 1.2 fits into this context.
Figure 4.2 The context of the first test

Please don’t confuse this with doing “Big Design Up Front” (BDUF) which has such a bad reputation in the Agile Development community. We’re not trying to elaborate the whole design down to classes and algorithms before we start coding. Any ideas we have now are likely to be wrong, so we prefer to discover those details as we grow the system. We’re making the smallest number of decisions we can to kick-start the TDD cycle, to allow us to start learning and improving from real feedback.
Build Sources of Feedback
We have no guarantees that the decisions we’ve taken about the design of our application, or the assumptions on which they’re based, are right. We do the best we can, but the only thing we can rely on is validating them as soon as possible by building feedback into our process. The tools we build to implement the “walking skeleton” are there to support this learning process. Of course, these tools too will not be perfect, and we expect we will improve them incrementally as we learn how well they support the team.
Our ideal situation is where the team releases regularly to a real production system, as in Figure 4.3. This allows the system’s stakeholders to respond to how well the system meets their needs, at the same time allowing us to judge its implementation.
Figure 4.3 Requirements feedback
We use the automation of building and testing to give us feedback on qualities of the system, such as how easily we can cut a version and deploy, how well the design works, and how good the code is. The automated deployment helps us release frequently to real users, which gives us feedback on how well we have understood the domain and whether seeing the system in practice has changed our customer’s priorities.
The great benefit is that we will be able to make changes in response to whatever we learn, because writing everything test-first means that we will have a thorough set of regression tests. No tests are perfect, of course, but in practice we’ve found that a substantial test suite allows us to make major changes safely.
Expose Uncertainty Early
All this effort means that teams are frequently surprised by the time it takes to get a “walking skeleton” working, considering that it does hardly anything. That’s because this first step involves establishing a lot of infrastructure and asking (and answering) many awkward questions. The time to implement the first few features will be unpredictable as the team discovers more about its requirements and target environment. For a new team, this will be compounded by the social stresses of learning how to work together.
Fred Tingey, a colleague, once observed that incremental development can be disconcerting for teams and management who aren’t used to it because it front-loads the stress in a project. Projects with late integration start calmly but generally turn difficult towards the end as the team tries to pull the system together for the first time. Late integration is unpredictable because the team has to assemble a great many moving parts with limited time and budget to fix any failures. The result is that experienced stakeholders react badly to the instability at the start of an incremental project because they expect that the end of the project will be much worse.
Our experience is that a well-run incremental development runs in the opposite direction. It starts unsettled but then, after a few features have been implemented and the project automation has been built up, settles in to a routine. As a project approaches delivery, the end-game should be a steady production of functionality, perhaps with a burst of activity before the first release. All the mundane but brittle tasks, such as deployment and upgrades, will have been automated so that they “just work.” The contrast looks rather like Figure 4.4.
Figure 4.4 Visible uncertainty in test-first and test-later projects
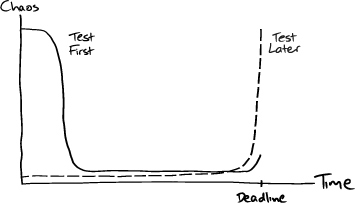
This aspect of test-driven development, like others, may appear counterintuitive, but we’ve always found it worth taking enough time to structure and automate the basics of the system—or at least a first cut. Of course, we don’t want to spend the whole project setting up a perfect “walking skeleton,” so we limit ourselves to whiteboard-level decisions and reserve the right to change our mind when we have to. But the most important thing is to have a sense of direction and a concrete implementation to test our assumptions.
A “walking skeleton” will flush out issues early in the project when there’s still time, budget, and goodwill to address them.