
Diffing
Introduction
Diffing, the comparison of a program, library, or other file before and after some action, is one of the simplest hacking techniques. It is used frequently during security research, often to the point that it is not thought of as a separate step. Diffing can be done at the disk, file, and database levels. At the disk level, you can discover which files have been modified. At the file level, you can discover which bytes have been changed. At the database level, you can discover which records are different. By doing so, you can discover how to manipulate the data outside of the application for which it is intended.
What Is Diffing?
The diff utility predates many of the modern UNIX and UNIX-clone operating systems, appearing originally in the UNIX implementation distributed by AT&T and currently available in many variations on the original. The name diff is shorthand for difference, derived from getting a list of the differences between two files.
The term diffing can therefore be defined as the use of the diff utility (or similar program) to compare two files. From this comparison, we can gather information for such purposes as determining what has changed from one revision of the software to the next; whether or not a binary is different from another claiming to be the same; or how a data file used by a program has changed from one operation to another.
Examine the source code of the program shown in Figure 5.1.


As mentioned in the header, this program contains a buffer overflow. (We saw this program originally in Chapter 4, in the “Buffer Overflows” section.) Now examine the next program, shown in Figure 5.2.


This program is presented as a fixed version of Figure 5.1. As we can see, the two programs have the same structure, use most of the same functions, and use the same variable names.
Using the diff program on a UNIX system, we can see the exact differences between these two programs (Figure 5.3).


As we can see in the beginning of the output, data in scpybufo.c is indicated by the < symbol, and the data in sncpyfix.c is indicated by the < symbol. The beginning of this diff is consumed by the header of both files.
Beginning at context number 25a24, we can see that the differences in the actual code begin. A size_t variable appears in sncpyfix.c that is not in scpybufo.c. At context number 27c26, we see the change of the strcpy function to the strncpy function. Though it is impractical to diff files as small as these, the usefulness of this utility becomes much more apparent when files containing more lines of code are compared. We discuss the reasons for diffing source code next.
Why Diff?
Why is it useful to be able to see the differences in a file or memory before and after a particular action? One reason is to determine the portion of the file or the memory location of the item of interest. For example, if a hacker has a file that he thinks contains a form of a password to an application, but the file appears to be in a binary format, he might like to know what part of the file represents the password.
To make this determination, the hacker would have to save a copy of the file for comparison, change the password, and then compare the two files. One of the differences between the two files (since there could be several) represents the password. This information is useful when a hacker want to make changes to the file directly, without going through the application. We look at an example of this scenario in this chapter. For cases like this, the goal is to be able to make changes to the storage directly.
In other cases, a hacker might be interested largely in decoding information rather than changing it. The steps are the same, causing actions while monitoring for changes. The difference is that rather than trying to gain the ability to make changes directly, the hacker wants to be able to determine when a change occurs and possibly infer the action that caused it.
Another reason is the security research discovery process. In the days of full disclosure, it is still common for vendors to release a fix without detailing the problems when the vulnerability is announced. Several major software vendors, such as Microsoft, Hewlett-Packard, and Caldera, are guilty of this practice. Vendors such as Linux companies (with the exception of Caldera) are the exception, whereas companies such as Cisco are on the fence, going back and forth between both sides of the information disclosure debate.
The use of diffing can expose a vulnerability when a software vendor has released a vague announcement concerning a security fix. A diff of the source code of two programs can yield the flaw and thus the severity of the issue. It can also be used to detect problems that have been quietly fixed from one revision of a software package to another.
Looking to the Source Code
Let’s go back to our discussion about diffing source code. In Figures 5.1 and 5.2, we showed the source code of two programs. The two are the same program, just different revisions. The first program contained a buffer overflow in strcpy, the second one a fixed version using strncpy.
From the output of a diff between the two source files (shown in Figure 5.3), we were able to determine two changes in the source code. The first change added a size_t variable in the sncpyfix.c program. The second change made a strcpy function in scpybufo.c into a strncpy function in sncpyfix.c.
Discovering problems in open source software is relatively easy. Often, problems in open source software are disclosed through files distributed to fix them. This is demonstrated through patch files produced by UNIX clone vendors such as Linux and the BSDs. Observe the patch in Figure 5.4, distributed in response to FreeBSD Security Advisory FreeBSD-SA-02:02.

This patch appears in unified diff format. Although the advisory released by FreeBSD contained all the pertinent information, including a detailed description of the problem, examination of this file reveals the nature of the problem. This patch is applied to the pwupd.c source file in the usr.sbin/pw/ source directory, as specified in the first lines of the patch.
The pw program included with FreeBSD is used to add, remove, or modify users and groups on a system. The problem with the program is that when an action is performed with the pw utility, a temporary file is created with world-readable permissions, as denoted in the line beginning with the single minus (–). This could allow a local user to gain access to encrypted passwords on the system.
Had the problem not been disclosed by the FreeBSD security team, we could have performed an audit on the source ourselves. After obtaining the two source files (pwupd.c prior to the change, pwupd.c after the change) and diffing the two files, we can see the alterations to the source code, shown in Figure 5.5.
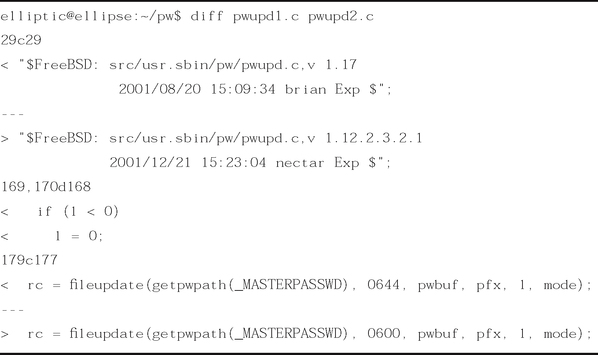
Between the older version and the most current revision of the pwupd.c files, we can see the same changes that were in the patch file shown in Figure 5.4.
Going for the Gold: A Gaming Example
I first ran across the idea of directly manipulating data files in order to affect an application when I was about 13 years old. At the time, I had an Apple][+ computer and enjoyed games quite a bit. By that point, I had completed somewhere between one and two years of junior high programming classes. One of my favorite games was Ultima 2. Ultima is a fantasy role-playing game that puts you in the typical role of hero, with a variety of weapons, monsters to kill, and gold to be had. As is typical of games of this genre, the goal is to gain experience and gold and solve the occasional quest. The more experience you have, the more efficiently you can kill monsters; the more gold you have, the better weapons and armor you can buy.
I wanted to cheat. I was tired of getting killed by daemons, and at that age, I had little concept of the way that cheating could spoil my game. The obvious cheat would be to give my character a lot more gold. I knew the information was written to a diskette each time I saved my game, and it occurred to me that if I could find where on the diskette the amount of gold I had was stored, I might be able to change it.
The technique I used at that time is a little different from what we present in this chapter, largely because the tools I had at my disposal were much more primitive. What I did was to note how much gold I had, save my game, and exit. I had available to me some sort of sector editor, which is a program used to edit individual disk sectors straight on the disk, usually in hexadecimal format. The sector editor had a search feature, so I had it search the disk for the name of my character to give me an approximate location on the disk to examine in detail. In short order, I found a pair of numbers that corresponded to the amount of gold I had when I saved my game. I made an increase and saved the changes to the sector. When I loaded my game back up, I had much more gold. Eureka! My first hack. Little did I know at the time that I had stumbled onto a technique that would serve me for many years to come.
I was able to expand my small bit of research and built myself an Ultima 2 character editor that would allow me to modify most of the character attributes, such as strength, intelligence, number of each type of weapons, armor, and the like. Of course, that was more years ago than I care to admit. (To give you an idea, Ultima IX was recently released, and the manufacturer makes a new version only every couple of years, on average.) Today, I play different games, such as Heroes of Might and Magic II. It is a fantasy role-playing game in which you play a character who tries to gather gold and experience through killing monsters … you get the idea. Figure 5.6 shows the start of a typical game.
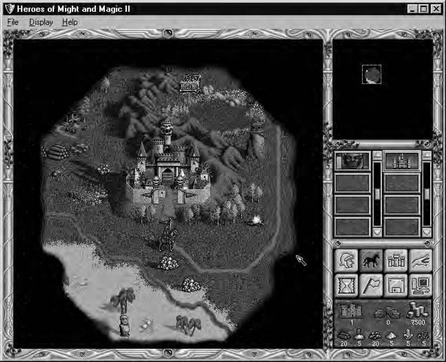
In particular, notice the amount of gold I have: 7500 pieces. The first thing I do is save the game, calling it hack1. Next I make a change to the amount of gold I have. The easiest way is to buy something; in my case, I went to the castle and bought one skeleton, one of the lowest-priced things to buy. It’s important to have the change(s) be as small as possible, which we’ll discuss shortly. After the purchase of the skeleton, I now have 7425 gold pieces. I save the game again, calling it hack2. I drop to a DOS prompt and run the file compare (fc) command, as shown in Figure 5.7.

The fc command compares two files, byte for byte, if you give it the /b switch, and reports the differences in hex. So, my next stop is the Windows calculator (calc.exe) to see what 7500 and 7425 are in hex. If you pick Scientific under the View menu in the calculator, you are presented with some conversion options, including decimal to hex, which is what we want. With Dec selected, punch in 7500 and then click Hex. You’ll get 1D4C. Repeat the process for 7425, and you’ll get 1D01.
Now, looking at the results of the fc command, the difference at address 368 (hex) looks promising. It was 4C and is now 01, which matches our calculations exactly. We can also probably infer what some of the other numbers mean as well. There were eight skeletons available in our castle, and we bought one, leaving seven. That would seem to indicate the byte at 3AE4. The byte at 3AD3 might indicate one skeleton in our garrison at the castle, where there were none before.
For now, though, we’re only interested in the gold amount. So, I fire up a hex editor (similar to a sector editor but intended to be used on files rather than a raw disk) and load hack2.gm1. I go to offset 368, and there are our values 01 1D. Notice that they appear to be reversed, as we Latin-language-based humans see them. That’s most likely because Intel processors store the least significant byte first (in the lower memory location). There’s only one way to find out if we have the right byte: change it. I change the 1D (the most significant byte, because I want the biggest effect) to FF (the biggest value that fits in one byte, expressed in hex). Figure 5.8 shows the result of loading hack2.gm1 into the game.

Take a look at the amount of gold, which is now 65281. A quick check with calc.exe confirms that 65281 in decimal is FF01 in hex. We now have a significant advantage in the game and can crush our simulated enemies with ease. Should we have wanted even more gold, which is entirely possible to gain in this game, we could have tried increasing the next byte to the right of the 1D as well, which was 0 when I looked at it. At worst, a couple tries at the adjacent bytes in the file with the hex editor will reveal which byte is needed to hand yourself millions of gold pieces.
Of course, the purpose of this book isn’t really to teach you how to cheat at games; there are more efficient means to do so than we’ve outlined here. For this game in particular, someone has written a saved-game editor, likely starting with the exact same technique we’ve outlined here. There are also a few cheat codes you can just punch directly into the game, keeping you from having to exit at all. A quick Web search reveals either, if you’re really interested.
If you’re familiar with this game, you might be wondering why our example wasn’t done in Heroes of Might and Magic III, which is the current version. The reason is discussed later in the chapter.
Exploring Diff Tools
Before we move on to other, more interesting examples, let’s take a moment to discuss some of the tools needed to perform this sort of work. In the previous section, we discussed the use of the fc utility and showed a brief example of the utility in action. We also talked about the use of hex editors, sector editors, and calc.exe for our purposes. Here we take a closer, more detailed look at the use and functionality of diff utilities.
Using File-Comparison Tools
The first step in diffing files is to determine the differences between two files. To do this, we’ll need some file-comparison tools. Let’s examine a couple of them.
Using the fc Tool
Thefc utility, which has been included in DOS (and later, Windows) for many years, is the first tool we will take a look at in more depth. If you’ve got a Windows 9x machine, fc can be found in c:windowscommand or whatever your Windows directory is if it’s not c:windows. By default, c:windows command is in the path, so you can simply type fc when you need it. These are the options available in fc:

There’s the /b switch that was mentioned. If you’re comparing binary files without that, the comparison will stop if it hits an end-of-file character or a zero byte. With this particular command, the command-line switches aren’t case sensitive, as evidenced by the fact that the help shows /B, while we’ve demonstrated that /b works fine. There are a number of text options that you can explore on your own. As we’ll see next, there’s a much better utility for comparing text files, but if you find yourself working on someone else’s machine that doesn’t have it, fc is almost always there (on Windows machines) and it will do in a pinch.
Using the diff Command
The diff command originates on the UNIX platform. It has limited binary comparison capabilities but is useful primarily for text file comparison. In fact, its text comparison features are exceptional. The complete list of capabilities for diff is much too large to include here; check the UNIX man pages or equivalent for the full list.
To give you an idea of what diff can do if you’ve not heard of it before, we’ll list a few of the most commonly used features. Using a simple-minded text-comparison tool, if you were to take a copy of a file and insert a line somewhere in the middle, it would probably flag everything after the added lines as a mismatch. Diff is smart enough to understand that a line has been added or removed:

The two files in question (decode.c and decode2.c) are identical except for a line that has been added to decode2.c that reads #include <newinclude.h>. In the first example, decode.c is the first argument to the diff command, and decode2.c is the second. The output indicates that a line has been added in the second file, after line 14 and going through line 15, and then lists the contents. If you reverse the arguments, the difference becomes a delete instead of an add (note the a in the first output and the d in the second).
This output is called diff output or a diff file and has the property that if you have the diff file and the original file being compared, you can use the diff file to produce the second file. For this reason, when someone wants to send someone else a small change to a text file, especially for source code, they often send a diff file. When someone posts a vulnerability to a mailing list regarding a piece of open source software, it’s not uncommon for the poster to include diff output that will patch the source to fix the output. The program that patches files by using diff output is called patch.
The diff program, depending on which version you have, can also produce other scripts as its difference output, such as for ed or Revision Control System (RCS). It can accept regular expressions for some of its processing, understands C program files to a degree, and can produce as part of its output the function in which the changes appear.
A Windows version of diff (as well as many other UNIX programs) is available from the Cygwin project. The Cygwin project is a porting project that is intended to bring a number of the GNU and other UNIX-based tools to the Windows platform. All GNU software is covered under some form of the GNU Public License (GPL), making the tools free. This work (including a package containing the Windows version of diff) can be found at http://sourceware.cygnus.com/cygwin.
Microsoft also includes a utility called Windiff in the Windows NT and Windows 98 resource kits. It’s a graphical version of a diff-style utility that displays changes in different colors and has a graph representation of where things have been inserted or deleted.
Working with Hex Editors
We mentioned in passing about using a hex editor to make a change to a binary file. A hex editor is a tool that allows the user to directly access a binary file without having to use the application program to which that type of file belongs. I say “binary” file, which is, of course, a superset of text files as well; however, most people have a number of programs on their computer that allow editing of text files, so a hex editor is a bit of overkill and cumbersome for editing text files.
In general, a hex editor does not understand the format of the file it is used to edit. Some hex editors have powerful features, such as search functions, numeric base converters, cut and paste, and others. However, at the base level, they are still simply working on a list of byte values. It’s up to the user of the hex editor to infer or deduce which bytes you need to edit to accomplish your task, as we did in our game example earlier in the chapter.
A large number of other hex editors are available. These range all over the spectrum in terms of costs (from freeware to commercial), quality, and functionality. For most people, the “best” editor is very much a matter of personal preference. It might be worth your time to try a number of different editors until you find the one you like.
The three that we look at briefly here—Hackman, [N] Curses Hexedit, and Hex Workshop—are not necessarily representative of hex editors in general, nor should they be considered an adequate cross-section of what’s out there. They merely represent three that I have found interesting.
Hackman
Hackman is a free Windows-based hex editor. It has a long list of features, including searching, cutting, pasting, a hex calculator, a disassembler, and many others. The graphical user interface (GUI) is somewhat sparse, as you can see in Figure 5.9.
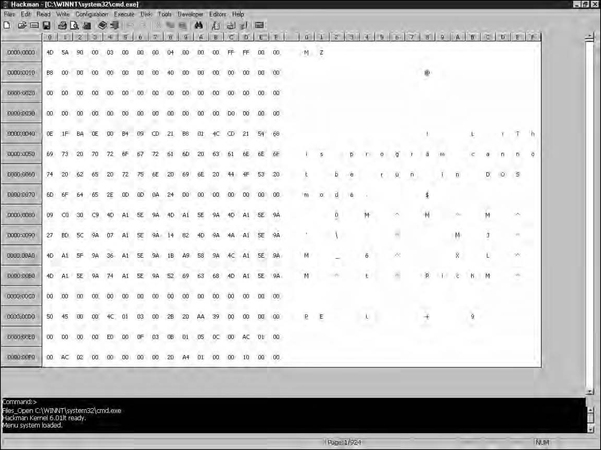
Hackman even includes command-line functionality, visible at the bottom of Figure 5.9. In the figure, we can see Hackman being used to hex-edit cmd.exe. Hackman is easy to use and offers the functionality you need from a basic hex editor, with the added benefit of a nice user interface. It is reliable and user-friendly and has benefited from recent development efforts. Hackman can be found at www.technologismiki.com/hackman.
[N] Curses Hexedit
Another free program (in fact, some might consider it more free, since it’s available under the GPL) is [N] Curses Hexedit. As mentioned, it’s GPL software, so the source is available should you want to make enhancements. There are versions available for all the major UNIX-like OSs as well as DOS.
If you think the Hackman interface is plain, this one is downright Spartan, as shown in Figure 5.10.
Functionality is also fairly basic. There is a search function, a simple binary calculator (converter), and the usual scrolling and editing keys. The whole list can be seen in Figure 5.11.
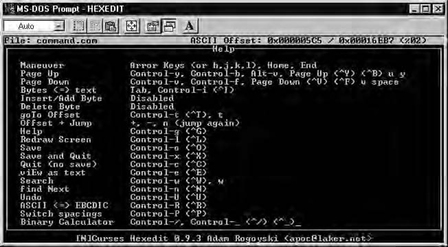
If this tool is a little light on features, it makes up for it in simplicity, light resource usage, and cross-platform support. The current version is 0.9.7, which, according to the changelog, has been the current version since August 8, 1999. This should not necessarily be taken to mean that the project will undergo no future development, but rather that it likely works the way the author wants it to. Possibly, if the author decides that he wants to add something or if someone points out a bug, he’ll release an update. It’s also possible that if you write an enhancement and send it to him, he’ll include it in a new official release.
[N] Curses Hexedit can be obtained at http://ccwf.cc.utexas.edu/˜apoc/programs/c/hexedit.
Hex Workshop
Finally, we take a look at a commercial hex editor, Hex Workshop from BreakPoint Software. This is a relatively inexpensive package (US$49.95 at the time of this writing) for the Windows platform. A 30-day free trial is available. The interface on this program is nicely done, as shown in Figure 5.12, and it seems very full-featured.

Hex Workshop includes arithmetic functions, a base converter, a calculator, a checksum calculator, and numerous other features. If your hands are accustomed to the standard Windows control keys (for example, Ctrl-F brings up the Find dialog box), you’ll probably be at home here.
If you’re a Windows user and you end up doing a lot of hex editing, you might want to treat yourself to this package. Hex Workshop can be obtained at www.bpsoft.com.
Utilizing File System Monitoring Tools
The third class of tools we will look at are called file system monitoring tools. These are distinct from tools that work on individual files; they work on a group of files, such as a partition, drive letter, or directory. These tools also span a wider range of functionality, since they often have different purposes. In some cases, we will be taking advantage of a side effect.
Before you can work on an individual file, you often need to determine which file it is you’re interested in. Sometimes this can be done by trial and error or by making an educated guess. However, you will often want tools available to make the process easier.
For example, after you’ve caused your program to perform some action, you will want to know what was changed. In most cases, your action will have changed a file on the disk, but which one? If the filenames offer no clue, how do you determine which files are being modified?
One obvious way is to take a copy of every file in the directory of interest and then compare them one by one with the modified set to see which individual files have been changed (and don’t forget to check for new files). However, that process is very cumbersome and might be more work than is necessary. Let’s examine a few methods that can be used to make this job easier.
Doing It The Hard Way: Manual Comparison
Naturally, you have the option of doing things manually, the hard way. That is, as we mentioned, you can take a complete copy of everything that might possibly be changed (say, all the files in a directory, or the whole hard drive), make the change, and then do a file-by-file comparison.
Obviously, this technique will work, but it takes a lot more storage and time than other methods. In some special cases, though, it might still be the best choice. For example, when you’re working with the Windows Registry, tools to monitor specific portions of the Registry might be unavailable on the machine you’re working on. Regedit is nearly always available, and it allows you export the whole Registry to a text file. In other cases, if there aren’t many files, and you’ve got lots of extra files, diffing the whole hard drive might be fine the first time to locate the file you’re interested in. Brute force can sometimes be faster than subtlety, especially if it will take you some time to prepare to be subtle.
Comparing File Attributes
One of the ways to avoid copying all the files is to take advantage of the file attributes built into the file system. File attributes are things like dates, times, size, and permissions. Several of these attributes can be of use to us in determining which files have just been modified.
Here’s the relevant section of code from the file ext2_fs.h on a Red Hat 6.2 Linux install:

Most UNIX file systems have something very similar to this code as their base set of file attributes. There’s an owner, the size, several time fields, group, number of links to this file, number of disk blocks used, and the file flags (the standard Read Write eXecute permissions).
So which attributes will be of use to us? In most cases, it will be one of the time values or the size. Either of these can be spotted by redirecting the output of an ls –al command to a file before and after and then diffing the two files, as shown in the following example:

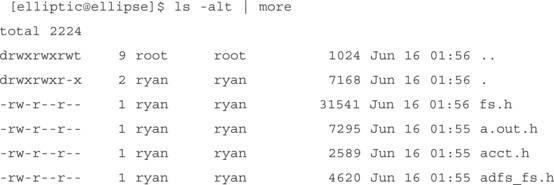
From the example, it’s apparent that the fs.h file changed. This method (comparing the directory contents) will catch a change in any of the attributes. A quick way to simply look for a time change is to use ls –alt, shown in the following example piped through the more command:
… and so on. The newest files are displayed at the top. Under DOS/Windows, the command to sort by date is dir /o:d, as shown in the following example:


Using the Archive Attribute
Here’s a cute little trick available to DOS/Windows users: The File Allocation Table (FAT) file system includes a file attribute called the archive bit. The original purpose of the bit was to determine if a file had been modified since the last backup and therefore needed to be backed up again. Of course, since we’re after modified files, this method serves our purposes, too. Take a look at a typical directory with the attrib command in the following example:

Notice the A at the front of each line. That indicates that the archive bit is set (meaning it needs to be backed up). If we use the attrib command again to clear it, we get the results shown in the following example:

Now, if a file or two out of the group is modified, it gets its archive bit back, as shown in the following example:

That’s the output of attrib again, after HEX-EDIT.EXE has been changed. The nice thing about the attrib command is that it has a /s switch to process subdirectories as well, so you can use it to sweep through a whole directory structure. Then, you can use the dir /a:a command (directory of files with the archive attribute set) to see which files have been changed.
Examining Checksums and Hashes
There’s one central problem with relying on file attributes to determine if the files have been changed: File attributes are easy to fake. It’s dead simple to set the file to any size, date, and time you want. Most applications won’t bother to do this, but sometimes viruses, Trojans, or root kits do something like this to hide. One way around this trick is to use checksums or cryptographic hash algorithms on the files and store the results.
Checksums, such as a cyclic redundancy check (CRC), are also pretty easy to fake if the attacker or attacking program knows which checksum algorithm is being used to check files, so it is recommended that you use a cryptographically strong hash algorithm instead. The essential property of a hash algorithm that we’re interested in is that the chances of two files hashing to the same value are impossibly small. Therefore, it isn’t possible for an attacker to produce a different file that hashes to the same value. Hash values are typically 128 or 160 bits long, so are much smaller than the typical file.
For our purposes, we can use hashes to determine when files have changed, even if they are trying to hide the fact. We run though the files we’re interested in and take a hash value for each. We make our change. We then compute the hash values again and look for differences. The file attributes may match, but if the hash value is different, the file is different.
Obviously, this method also has a lot of use in keeping a system secure. To be correct, I need to partially retract my statement that hashes can spot changes by a root kit; they can spot changes by a naïve root kit. A really good root kit assumes that hashes are being watched and causes the system to serve up different files at different times. For example, when a file is being read (say, by the hashing program), the modified operating system hands over the real, original file. When it’s asked to execute the file, it produces the modified one.
For an example of this technique, look for “EXE Redirection” on the rootkit.com site. This site is dedicated to the open source development of a root kit for NT: www.rootkit.com.
Finding Other Tools
Ultimately, a hacker’s goal is probably to cause the change that she’s been monitoring to occur at will. In other words, if she’s been trying to give herself more gold in her game, she wants to be able to do so without having to go through the whole diffing process. Perhaps she doesn’t mind using a hex editor each time, or perhaps she does. If she does mind, she’ll probably want some additional tools at her disposal.
If the hacker has ever tackled any programming, she’ll want some sort of programming tool or language. Like editors, programming tools are very personal and subjective. Any full-featured programming language that allows arbitrary file and memory access is probably just fine. If the attacker is after some sort of special file access (say, the Windows Registry), it might be nice to have a programming language with libraries that hook into the Application Programming Interface (API) for that special file. In the case of the Windows Registry, it can be done from C compilers with the appropriate libraries; it can also be done from ActiveState Perl for Windows, and probably many, many more. If you’re curious, ActiveState Perl can be found at www.activestate.com/Products/ActivePerl/index.html.
Way back when DOS ruled the gaming market, a program called Game Wizard 32 was created. This program was essentially a diffing program for live, running games. It would install in memory-resident mode, and you would then launch your game. Once your game was running, you’d record some value (hit points, gold, energy, etc.) and tell Game Wizard 32 to look for it. It would record a list of matches. Then you’d make a change and go back to the list and see which one now matched the new value. You could then edit it and resume your game, usually with the new value in effect. This program also had many more features for the gamer, but that’s the one relevant to this discussion.
Nowadays, most gamers call that type of program a trainer or memory editor. The concept is exactly the same as the one we presented for files. A wide range of these types of programs (including Game Wizard 32) can be found at http://gamesdomain.telepac.pt/directd/pc/dos/tools/gwiz32.html.
Another couple of tools I have found invaluable when working on Windows machines are File Monitor (FileMon) and Registry Monitor (RegMon), both from Sysinternals. If you’re using NT, you should also check out HandleEx, which provides similar information but with more detail. Their site can be found at www.sysinternals.com. This site has a large number of truly useful utilities, many of which they will give you for free, along with source code.
FileMon is a tool that enables you to monitor programs that are accessing files, what they are doing to them (reading, writing, modifying attributes, etc.), and at what file offset, as shown in Figure 5.13.
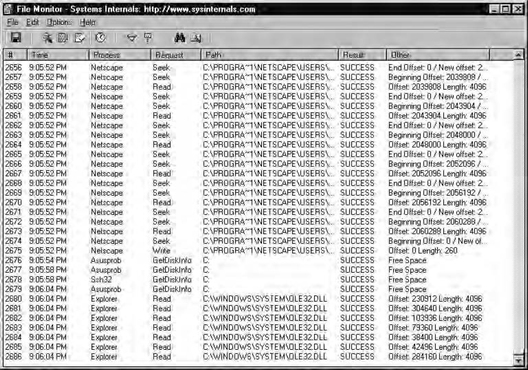
Filtering can be applied, so you can watch what only certain programs do, to reduce the amount of information you have to wade through. Note that FileMon records the offset and length when reading files. This can sometimes be of help when trying to determine where in a file a particular bit of information lives. FileMon is another good way to shorten your list of files to look at.
The other tool from Sysinternals is RegMon. As you might expect, it does much the same thing as FileMon but for the Registry, as shown in Figure 5.14.
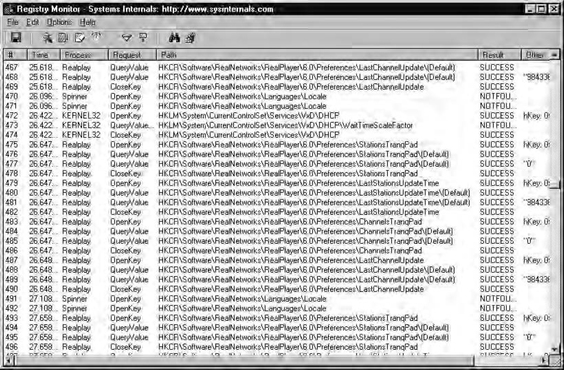
While I was preparing this sample, I was listening to the Spinner application from spinner.com, which uses Real Audio to deliver its music. As you can see, Real Audio keeps itself busy while it’s running. You can also see a Dynamic Host Configuration Protocol (DHCP) action at line 472. This tool can be especially useful if you suspect an application is storing something interesting in the Registry in a subtle place or if you’re trying to determine what some Trojan horse program is up to. It sure beats copying and comparing the whole Registry.
Troubleshooting
A couple of things can present challenges to trying to directly edit data files. These problems can become frustrating, since their focus is on meticulous details. In short, the focus is on modifying part of an important file while not confusing it with or becoming distracted by a less important, dependent file.
Problems with Checksums and Hashes
The first type of problem you might encounter is that of a checksum or hash being stored with the file. These are small values that represent a block of data—in this case, a part of the file. When writing out the file in question, the program performs a calculation on some portion of the file and comes up with a value. Typically, this value is somewhere in the 4- to 20-byte range. This value gets stored with the file.
When it comes time to read the file, the program reads the data and the checksum/hash and performs the calculation on the data again. If the new hash matches the old one, the program assumes that the file is as it left it and proceeds. If the hashes don’t match, the program will probably report an error, saying something to the effect of “File corrupt.”
For a variety of reasons, an application developer might apply such a mechanism to his data files. One reason is to detect accidental file corruption. Some applications might not operate properly if the data is corrupted. Another reason is that the developer wanted to prevent the exact thing we’re trying to do. This might range from trying to prevent us from cheating at games to modifying password files.
Of course, there is no actual security in this type of method. All you have to do is figure out what checksum or hash algorithm is used and perform the same operation as the program does. Where the hash lives in the file won’t be any secret; as you’re looking for changed bytes, trying to find your value you changed, you’ll also find some other set of bytes that changes every time, too. One of these other sets of bytes is the checksum.
Unless you’ve got some clue as to what algorithm is used, the tricky part is figuring out how to calculate the checksum. Even with the algorithm, you still need to know which range of bytes is covered by the checksum, but that can be discovered experimentally. If you’re not sure if a particular section of the files is covered under the checksum, change one of the bytes and try it. If it reports a corrupted file, it (probably) is.
Short of looking at the machine code or some external clue (such as the program reporting a CRC32 error), you’ll have to make guesses about the algorithm from the number of bytes in the hash value. CRC32, which is the most common, produces a 32-bit (4-byte) output. This is the checksum that is used in a number of networking technologies. Code examples can be found all over the place—just do a Web search, or you can find an example at www.faqs.org/faqs/compression-faq/part1/section-26.html.
MD4 and MD5 produce 128-bit (16-byte) output (MD stands for Message Digest). The Secure Hash Algorithm (SHA) produces 160-bit (20-byte) output.
Problems with Compression and Encryption
This topic is essentially the same problem as the hash, with a little extra twist. If the file has been compressed or encrypted, you won’t be able to determine which part of the file you want to ultimately modify until after you’ve worked around the encryption or compression.
When you go to diff a data file that has been compressed or encrypted (if the algorithm is any good), most of the file will show up as changed. At the beginning of the chapter I mentioned that I used Heroes of Might and Magic II for my example, even though Heroes of Might and Magic III has been out for some time. That’s because Heroes of Might and Magic III appears to compress its data files. I make this assumption based on the facts that the file is unintelligible (I don’t see any English words in it); nearly the whole file changes every save, even if I do nothing in the game between saves; and the file size changes slightly from time to time. Since compressed file size is usually dependent on file contents, whereas encrypted files tend to stay the same size each time if you encrypt the same number of bytes, I assume I’m seeing compression instead of encryption.
For compressed files, the number of ways a file might be compressed is relatively limited. A number of compression libraries are available, and most people or businesses wouldn’t write their own compression routines. Again, in the worst case, you’ll have to use some sort of debugger or call trace tool to figure out where the compression routines live.
Encryption is about the same, with the exception that chances are much higher that developers will attempt to roll their own “encryption” code. I put the term in quotes because most folks can’t produce decent encryption code (not that I can, either). So, if they make their own, it will probably be very crackable. If they use some real cryptography … well, we can still crack it. Since the program needs to decrypt the files too, everything you need is in there somewhere. See Chapter 6 for more information on encryption.
Summary
Diffing is the comparison of a program, library, or other file before and after some action. Diffing can be performed at the disk level, file level, or database level. In this chapter, we examined the difference between two revisions of the same file and showed how diff can give us details of the modifications between them.
Reasons for diffing include discovering the location of password storage in applications or a vulnerability that has been fixed but not disclosed. We looked at an example of a patch created in unified diff format and then examined diff output between two source files to see that it was the same as the diff.
Various tools are used in diffing, such as the fc utility included with Windows operating systems, and the diff command used with UNIX. Hex editing programs for various platforms are also worth exploring, such as Hackman for Windows. File system monitoring tools work on a broad group of files, a partition, or a drive letter. In this chapter, we discussed monitoring file systems the hard way—by copying the entire file system and doing a file-by-file comparison. By examining the structure of an ext2 file system discussed in this chapter, you can discover the means by which you can identify files that have changed through the modification time using ls. It is possible to perform a similar search using the MS-DOS dir command and looking for the file at the bottom; you can also search FAT file systems for changes with the archive attribute. Checksums can be used to monitor files for changes by creating a list of the checksums, then comparing them later. Note that some programs such as root kits may circumvent checksums.
Other types of tools include ActiveState Perl, for writing your own tools; FileMon, a utility for monitoring the files that programs are accessing on a Microsoft Windows system; and RegMon, a utility for monitoring entries to the Windows Registry on a Windows system (both the latter tools are from Sysinternals).
We closed the chapter with a discussion about problems we might encounter. We can circumvent checksums and hashes by discovering the location of the checksums and their method of generation. We also mentioned the problem with encryption and compression and how locating a checksum in a file that has been compressed or encrypted is impossible until the protecting mechanism has been circumvented.
Solutions Fast Track
What Is Diffing?
![]() Diffing is the process of comparing an object before and after an operation.
Diffing is the process of comparing an object before and after an operation.
![]() Diffing can be used to discover changes to files by execution of a program or to uncover vulnerabilities that have been fixed but not disclosed.
Diffing can be used to discover changes to files by execution of a program or to uncover vulnerabilities that have been fixed but not disclosed.
![]() An entire directory can be examined via the diff program to compare all like files within the directory.
An entire directory can be examined via the diff program to compare all like files within the directory.
![]() Diff-style research can be applied to source code and binaries.
Diff-style research can be applied to source code and binaries.
Exploring Diff Tools
![]() Most UNIX operating systems include the program diff for diffing; Microsoft operating systems include the fc utility, which offers similar features.
Most UNIX operating systems include the program diff for diffing; Microsoft operating systems include the fc utility, which offers similar features.
![]() When someone posts a vulnerability to a mailing list regarding a piece of open source software, it’s not uncommon for the poster to include diff output that will patch the source to fix the output.
When someone posts a vulnerability to a mailing list regarding a piece of open source software, it’s not uncommon for the poster to include diff output that will patch the source to fix the output.
![]() A hex editor is a tool that allows you to make direct access to a binary file without having to use the application program to which that type of file belongs. Hex editors are available for many platforms, such as Hackman for Windows or hexedit for UNIX.
A hex editor is a tool that allows you to make direct access to a binary file without having to use the application program to which that type of file belongs. Hex editors are available for many platforms, such as Hackman for Windows or hexedit for UNIX.
![]() Because file attributes are easy to fake, you should not rely on them to determine if the files have been changed, because they could be hiding viruses, Trojans, or root kits. One way around this problem is to use checksums or cryptographic hash algorithms on the files and store the results.
Because file attributes are easy to fake, you should not rely on them to determine if the files have been changed, because they could be hiding viruses, Trojans, or root kits. One way around this problem is to use checksums or cryptographic hash algorithms on the files and store the results.
![]() Utilities for Windows monitoring include RegMon and FileMon.
Utilities for Windows monitoring include RegMon and FileMon.
Troubleshooting
![]() Checksums, hashes, compression, and encryption are used to protect files.
Checksums, hashes, compression, and encryption are used to protect files.
![]() Checksums and hashes can be circumvented by locating the value and discovering how it is generated. The tricky part is figuring out how to calculate the checksum; even with the algorithm, you still need to know which range of bytes is covered by the checksum.
Checksums and hashes can be circumvented by locating the value and discovering how it is generated. The tricky part is figuring out how to calculate the checksum; even with the algorithm, you still need to know which range of bytes is covered by the checksum.
![]() Encryption and compression must first be circumvented prior to altering hashes and checksums. The number of ways a file might be compressed is relatively limited, and the encryption, too, will be crackable; since the program needs to decrypt the files, too, everything you need is in there somewhere.
Encryption and compression must first be circumvented prior to altering hashes and checksums. The number of ways a file might be compressed is relatively limited, and the encryption, too, will be crackable; since the program needs to decrypt the files, too, everything you need is in there somewhere.
Frequently Asked Questions
The following Frequently Asked Questions, answered by the authors of this book, are designed to both measure your understanding of the concepts presented in this chapter and to assist you with real-life implementation of these concepts. To have your questions about this chapter answered by the author, browse to www.syngress.com/solutions and click on the “Ask the Author” form.
Q: Is diff available for Windows?
A: Diff can be attained from the Cygwin distribution, available from Cygnus Solutions.
Q: Will I always have to diff fixes to discover vulnerabilities?
A: Yes and no. Many vendors of free or GPL operating systems make this information available. Commercial vendors are not as eager to release this information. Although I can’t tell you which operating system to use, I can say I prefer having the information, and therefore I use free and open source operating systems.
Q: Can I get grep with the recursive function built in?
A: Yes. Versions of grep that support the recursive (-r) flag are available from the Free Software Foundation at www.gnu.org.
Q: What if I want to use C instead of Perl to create my tools?
A: More power to you. Most free UNIX-like operating systems include a C compiler. For Windows, DJGPP can be used; it’s available at www.delorie.com/djgpp.
Q: Where can I find other free utilities?
A: Sourceforge.net has a large repository of free software. Additionally, Freshmeat.net is a freely available software search engine.