


GDPS Virtual Appliance
This appendix discusses the Geographically Dispersed Parallel Sysplex (GDPS) Virtual Appliance.
|
Statement of Direction1: In the first half of 2015, IBM intends to deliver a GDPS/Peer-to-Peer Remote Copy (GDPS/PPRC) multiplatform resiliency capability for customers who do not run the z/OS operating system in their environment. This solution is intended to provide IBM z Systems customers who run z/VM and their associated guests, for instance, Linux on z Systems, with similar high availability and disaster recovery benefits to those who run on z/OS. This solution will be applicable for any IBM z Systems announced after and including the zBC12 and zEC12.
|
1 All statements regarding IBM plans, directions, and intent are subject to change or withdrawal without notice. Any reliance on these statements of general direction is at the relying party’s sole risk and will not create liability or obligation for IBM.
D.1 GDPS overview
GDPS is a collection of offerings, each addressing a different set of IT resiliency goals that can be tailored to meet the recovery point objective (RPO) and RTO for your business. Each offering uses a combination of server and storage hardware or software-based replication, automation, and clustering software technologies. In addition to the infrastructure that makes up a GDPS solution, IBM also includes services, particularly for the first installation of GDPS and optionally for subsequent installations to ensure that the solution meets and fulfills your business objectives.
|
Definitions:
•Recovery Point Objective (RPO) defines the amount of data that you can afford to re-create during a recovery, by determining the most recent point in time for data recovery.
•Recovery Time Objective (RTO) is the time needed to recover from a disaster or how long the business can survive without the systems.
|
Figure D-1 illustrates some of the GDPS offerings.

Figure D-1 GDPS offerings
For a complete description of GDPS solution and terminology, see GDPS Family: An Introduction to Concepts and Capabilities, SG24-6374.
It is typical to deploy IT environments based on IBM z Systems that are running only Linux on z Systems. The GDPS Virtual Appliance is a building block of High Availability and Disaster Recover solutions for those environments that do not have nor require z/OS skills.
The following are the major drivers behind implementing a High Availability and Disaster Recovery (HA/DR) architecture:
•Regulatory compliance for business continuity (99.999% or higher availability)
•Avoid financial loss
•Maintaining reputation (which translates also in customer satisfaction, and thus money)
There are also various levels of and HA/DR implementation:
•High availability (HA): The attribute of a system to provide service during defined periods, at agreed upon levels by masking unplanned outages from users It employs component duplication (HW and SW), automated failure detection, retry, bypass, and reconfiguration.
•Continuous operations (CO): Attribute of a system to continuously operate and mask planned outages from users. and by providing the means to minimize planned downtime during maintenance windows. It employs nondisruptive hardware and software changes, nondisruptive configuration, and software coexistence.
•Continuous availability (CA): Attribute of a system to deliver non-disruptive service to the user 7 days a week, 24 hours a day (there are no planned or unplanned outages).
There are different reasons for a system outage. Outages can be categorized as either planned or unplanned.
Planned outages can be caused by the following situations:
•Backups
•Operating System installation and maintenance
•Application software maintenance
•Hardware and software upgrades
Unplanned outages can be caused by the following situations:
•Non-disaster events such as:
– Application failure
– Operator errors (human error)
– Power outages
– Network failure
– Hardware and software failures
•Disaster events such as:
– Outages that are caused by natural disasters or other catastrophes that damage the production facilities beyond usability (for example, fire, flood, earthquake, or bombing)
– Failure of a regional power grid
– Outages that require a recovery procedure at an off-site location
Automation is key when implementing a HA/DR solution. The major benefits of an automated solution are as follows:
•Provides reliable, consistent recovery time objective (RTO)
•Provides consistent and predictive recovery time as the environment scales
•Reduces infrastructure management cost and staff skills
•Reduces or eliminates human intervention, and therefore the probability of human error
•Facilitates regular testing for repeatable and reliable results of business continuity procedures
•Helps maintain recovery readiness by managing/monitoring servers, data replication, workload, and network with the notification of events that occur within the environment
D.2 Overview of GDPS Virtual Appliance
To reduce IT costs and complexity, many enterprises are consolidating independent servers into Linux images (guests) running on z Systems servers. Linux on z Systems can be implemented either as guests running under z/VM or native Linux LPARs on z Systems. Workloads with an application server running on Linux on z Systems and a database server running on z/OS are common. Two examples are as follows:
•WebSphere Application Server running on Linux and CICS, DB2 running under z/OS
•SAP application servers running on Linux and database servers running on z/OS
With a multi-tiered architecture, there is a need to provide a coordinated near-continuous availability and disaster recovery solution for both z/OS and Linux on z Systems.
GDPS Virtual Appliance is a Fully integrated Continuous Availability and Disaster Recovery solution for Linux on z Systems customers that include these components:
•An operating system image
•The application components
•An appliance management layer, which makes the image self-containing
•APIs and UIs for customization, administration, and operation tailored for the appliance function.
•It is designed to improve both consumability and time-to-value for customers.
Figure D-2 shows different solutions and how to position the GDPS Virtual Appliance.
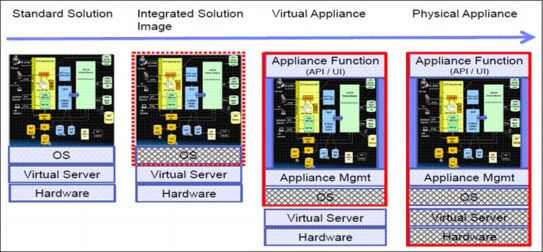
Figure D-2 Positioning a virtual appliance
A virtual appliance is a fully integrated software solution that has been targeted and optimized for a specific business problem:
•Targeted for a specific deployment platform reducing potential configuration complexity while using any underlying capabilities of the platform
•Purposed for a specific, high-level business context or IT architecture – Installing particular applications and hardening then before delivery
•Optimized choosing the appropriate configuration, knowing all elements of the system and removing unnecessary attributes
The GDPS Virtual Appliance solution implements the GDPS/PPRC Multiplatform Resilience for z Systems, also known as xDR. xDR coordinates near-continuous availability and DR solution by:
•Disk error detection
•Heartbeat for sanity checks
•IPL in place again
•Coordinated site takeover
•Coordinated HyperSwap
•Single point of control
The GDPS Virtual Appliance requirements are as follows:
•Hardware
– Any supported hardware: zEC12, zBC12, and z13
– 1 LPAR with one logical CP
– 1 GB Memory
– 3 ECKD direct access storage device (DASD) (one for appliance image initial Installation, and two for upgrade scenario)
– One or two OSA attachments (dependent on the network setup and the wanted network resilience).
•System
– z/VM Version 5 Release 4 or higher, or z/VM 6.2 or higher. Note that z/VM 5.4 is not supported on z13
– The disks being used by z/VM and Linux to be mirrored must be extended count key data (ECKD) disks
– A supported distribution of Linux on z Systems with the latest recommended fix pack
– IBM Tivoli System Automation for Multiplatforms with the latest recommended fix pack. The separately priced xDR for Linux feature is required (one Linux guest as xDR proxy).
|
Note: To get the latest information about Tivoli System Automation for Multiplatforms, see:
|
Figure D-3 shows an overview of GDPS Virtual Appliance implementation.
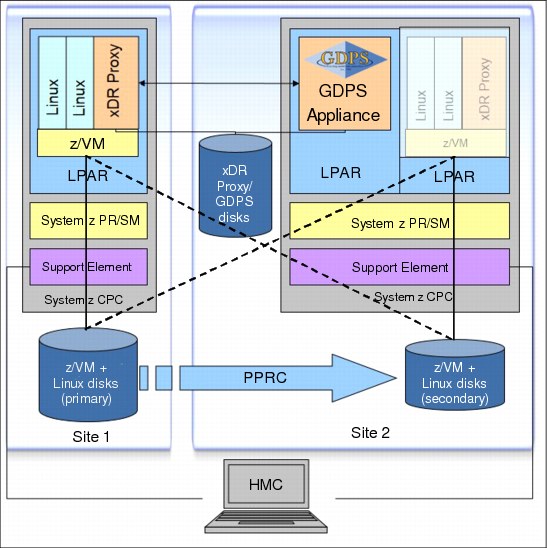
Figure D-3 GDPS virtual appliance architecture overview
Keep in mind the following considerations for GDPS Virtual Appliance architecture:
•PPRC ensures that the remote copy is identical to the primary data. The synchronization takes place at the time of I/O operation.
•One dedicated Linux guest is configured as XDR Proxy for GDPS, which is used for tasks that have z/VM scope (HyperSwap, shut down z/VM, IPL z/VM guest).
•The remote copy environment is managed using HyperSwap function, and data is kept available and consistent for operating systems and applications.
•Disaster detection ensures successful and faster recovery using automated processes.
•A single point of control is implemented from the GDPS Virtual Appliance. There is no need for involvement of all experts (for example, storage team, hardware team, OS team, application team, and so on).
The GDPS Virtual Appliance implements the following functions:
•Awareness of a failure in a Linux on z Systems node or cluster by monitoring (heartbeats) all nodes or cluster master nodes. If a node or cluster fails, it can be set up to automatically IPL the node or all the nodes in the cluster again.
•Shutting down a Linux on z Systems node or cluster for service (planned maintenance).
•Initiation of z/VM Live Guest Relocation to move active guests from one member of a z/VM SSI cluster to another
•Graceful shutdown/startup of the Linux on z Systems cluster, nodes in the cluster, and the z/VM host. Graceful shutdown/startup of z/VM systems includes any z/VSE guests.
•Use of HyperSwap to non-disruptively swap z/VM and its guests from the primary to secondary PPRC devices, for both planned disk subsystem maintenance and unplanned disk subsystem failure.
D.3 GDPS Virtual Appliance recovery scenarios
This section presents the following recovery scenarios using GDPS Virtual Appliance:
D.3.1 Planned disk outage
In a planned disk outage, the HyperSwap provides the ability to non-disruptively swap from using the primary volume of a mirrored pair to using the secondary volume. A planned HyperSwap is invoked manually by operator action using GDPS facilities. One example of a planned HyperSwap is where a HyperSwap operation is initiated in advance of a planned disruptive maintenance of a disk subsystem.
Figure D-4 shows the operation principle of disk failover operation using HyperSwap.
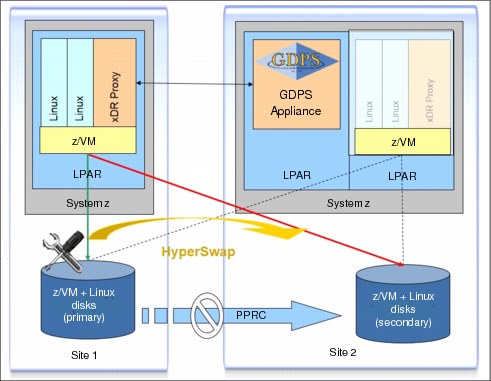
Figure D-4 GDPS Storage failover
Without HyperSwap, the procedure to change the primary disk to the secondary can take up to 2 hours, or even more, depending on the installation size. The procedures include shutting down the systems, removing systems from clusters, and when applicable, reversing PPRC (that is, suspending PPRC), and restarting the systems.
When using HyperSwap, disk swap takes seconds (for example 6 seconds for 14 systems and 10,000 volume pairs), and the systems remain active.
D.3.2 Unplanned disk outage
An unplanned HyperSwap is invoked automatically by GDPS, triggered by events that indicate the failure of a primary disk device. HyperSwap events can include the following events:
•Hard failure triggers
– I/O errors
– Boxed devices
– Control unit failures
– Loss of all channel paths
•Soft failures, such as I/O response time triggers
Again, without HyperSwap, this process can take more than an hour even when done properly. The systems are quiesced, removed from the cluster, and restarted on the other side. With HyperSwap, the same operation can take seconds.
D.3.3 Disaster recovery
In a site disaster, GDPS Appliance will immediately issue a freeze for all applicable primary devices. This is done to protect the integrity of the secondary data. GDPS cluster will Reset Site 1 and Site 2 systems and update all the IPL information to point to the secondary devices, and IPL all the production systems in LPARs in Site 2 again. The GDPS Appliance scripting capability is key to recovering the systems in the shortest possible time following a disaster. All recovery operations are carried out without operator intervention.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.