
CHAPTER 3
USING INFORMATION AND TECHNOLOGY TO CREATE, DELIVER, AND SUPPORT SERVICES
3 Using information and technology to create, deliver, and support services
3.1 Integration and data sharing
Service design frequently relies upon integration between multiple systems, and in such cases it is important to understand the different levels at which integration may be modelled. For example:
• Application Applications are made to interact with each other.
• Enterprise Integrated applications are aligned to provide value.
• Business Existing business services are aligned.
A number of integration methodologies have evolved over time, each having specific goals which are important to the success of the integration. Selection of an integration methodology requires the consideration of multiple factors, including reliability, fault tolerance, cost, complexity, expected evolution, security, and observability.
Good integration enables and reinforces the processes which underpin the delivery of value. For integration to be effective, it must be based on a clear understanding of the stakeholders affected by the integration, and designed to support their work methods and needs.
The nature of integration varies. Some situations simply require a one-time hand-off from one system to another; for example, a one-time call to a control system to change a parameter. Others require an ongoing, two-way process of alignment between two systems; for example, where a support agent might collaborate with an external supplier’s representative when each uses a separate ticketing system.
When data is passed from one system to another, it is important to ensure that compliance is maintained with regulatory obligations, such as privacy, security, and confidentiality.
Integration design requires an understanding and consideration of the different topographical approaches to integrating multiple systems. There are two generally accepted topologies: point-to-point and publish–subscribe.
Point-to-point integration involves directly linking pairs of systems. This may be suitable for simple services with a small number of integrated systems. There are, however, drawbacks with this approach:
• The number of connections grows quickly in proportion to the number of integrated systems, requiring n(n–1) integrations to be implemented. A bi-directional integration effectively counts as two separate integrations.
• The number of different integration protocols and methods may be high, which increases the complexity.
Publish–subscribe is an alternative topology in which messages are published by systems to an event broker, which forwards the message to the systems that have been designated as its recipients. This approach offers better scalability, and the looser coupling reduces the complexity of implementation (the publishing system does not even need to be aware of the subscriber). Reliability, though, may be a challenge, particularly when the publisher is unaware that a subscriber has not received a message.
The broker architecture may be in the form of a bus, in which the transformation and routing is done by adapters local to each integrated system (or hub and spoke), where it is centralized. The bus model is not constrained by the limits of a single hub and as such is more scalable.
Where a service implementation is dependent on multiple integrations, it is important to consider the delivery approach for those integrations. Three approaches are outlined in Table 3.1.
Table 3.1 Delivery approaches
Big bang |
A ‘big bang’ approach involves the delivery of every integration at once. This has potential benefits for testing because the entire system is in place prior to a live roll-out. However, as with software development, integration projects delivered using this approach can become excessively large and complex, which can lead to issues with, for example, troubleshooting. As a result, the approach is suited to simple service implementations with fewer integrated systems and simpler, lower-risk integration. |
Incremental delivery |
Incremental delivery is a more Agile approach for the integration of multiple components in which new integrations are introduced separately in a pre-defined order. It reduces the scale of each individual delivery into production, thus enabling troubleshooting and resolution of post-deployment issues. This approach can be used in most circumstances. Nevertheless, because the overall service remains incomplete until each integration is in place, service testing may require extensive simulation to account for undelivered elements. There may also be a heavy regression test burden. |
Direct integration with the (value) stream |
Direct integration allows individual integrations to be deployed as soon as they are ready, in no predetermined order. This provides greater agility and enables rapid initial progress, as with incremental delivery. The approach may necessitate significant simulation to facilitate adequate testing. Global tests of the entire service, and even of the subsets of functional chains within it, can only be run late in the service implementation. |
The ITIL story: Integration and data sharing
|
Reni: Initially, the pilot of our bike hire service will have minimal functionality, which we will enhance over time in consultation with our customers. |
|
Solmaz: If the new service proves popular, our strategy is to deploy the bike hire service at other branches in the Axle chain. It is important to choose technology, information models, and software development methods that are scalable and compatible with the existing Axle infrastructure and systems. |
|
Henri: We can use integration and data sharing for this service. Many data stores and systems will need to be integrated if the bike hire service is to be successful, and scaled as necessary: • At the application integration level, we need one customer booking system, capable of booking both cars and bikes. • At the enterprise integration level, we need one financial transaction system, which is centrally managed and capable of being deployed across all branches. • At the business integration level, we would like to offer bike hire to car renters, and vice versa. Giving our customers the chance to combine these will improve the value of the services we provide. |
3.2 Reporting and advanced analytics
Advanced analytics is the autonomous or semi-autonomous examination of data or content using high-level techniques and tools. These go beyond traditional business intelligence to discover new or deep insights, make predictions, or generate recommendations.
Some advanced analytic techniques are:
• complex event processing
• data/text mining
•forecasting
• graph analysis
• machine learning
• multivariate statistics
• network and cluster analysis
• neural networks
• pattern matching
• semantic analysis
• sentiment analysis
•simulation
•visualization.
Data science, predictive analytics, and big data are growing areas of interest among researchers and businesses.
In many organizations, there is a vast amount of raw data but very little useful information. Data on its own is useless; but information can provide answers. Information is data that has been transformed into meaningful insight, statistics, reports, forecasts, and recommendations. For example, daily sales figures per product/service sold and customers invoiced are data; sales trends, customer purchasing preferences by location, industry sector, and overall ranking of products/services by profitability are information.
In order to transform raw data into valuable information, it is important to follow a process. This process is known as data analytics.

Definition: Data
Information that has been translated into a form that is efficient for movement or processing.
Data analytics is the method of examining data sets, often using specialized software, in order to draw conclusions about the information they contain. Data-analytics technology and techniques are widely used in industry. For example, they enable organizations to make informed business decisions and help scientists and researchers to verify or disprove scientific models, theories, and hypotheses.
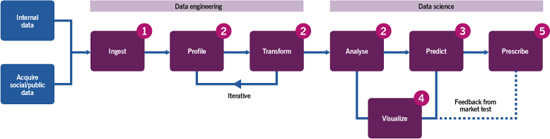
Figure 3.1 Data analytics
In data analytics, there is a typical path that organizations follow in order to get the most from their data (see Figure 3.1):
• Data engineering Data is processed using programming languages (e.g. Python, R, Java, SQL, or Hadoop) and made ready for analysis.
• Data science Data is analysed and insight gained by using tools such as R, Azure ML, or Power BI.
Big data is a term that describes large volumes of structured, semi-structured, and unstructured data. To extract meaningful information from big data requires processing power, analytics capabilities, and skill.
Analysis of data sets can discover correlations within the data. For example, it can unearth business trends, pinpoint health issues, and prevent fraud. Scientists, business executives, doctors, and governments often find large data sets overwhelming, but big data can help to create new knowledge once field experts have brought their expertise to the process.
The cost of running their own big data servers has encouraged many system administrators to seek more scalable, cost-effective solutions. However, it has been found that the cloud can be used for storage and processing of big data. Cloud storage involves digital data being stored in logical pools. The physical storage spans multiple servers, and the physical environment is typically owned and managed by a hosting company. These cloud storage providers are responsible for ensuring the data is available and accessible and that the physical environment is protected and operational (see the infrastructure and platform management practice guide for more information).
The more complex the data, the bigger the challenge of finding value within it. Understanding and assessing the complexity of data is important when deciding whether a particular solution is appropriate and for mapping out the best approach.
The following criteria can be used to assess the complexity of an organization’s data:
• Data size Gigabytes, terabytes, petabytes, or exabytes. Volume is not the only consideration, as data should also be organized into thousands or millions of rows, columns, and other dimensions.
• Data structure Data relating to the same subject but from different sources may be provided in different structures.
• Data type Structured data, like the entries in a customer order database, may vary by alphabetical, numerical, or other data type. Unstructured data can exist in many forms, including freeform text, conversations on social media, graphics, and video and audio recordings.
• Query language Database systems use query languages for requesting data from the database.
• Data sources The greater the number of data sources, the higher the probability of differences in internal data structures and formats. Occasionally, data may be submitted with no specific format. Data from different sources must be harmonized to in order to be accurately compared.
• Data growth rate The data may increase in volume and variety over time.
There are four steps to generating useful dashboards and reports:
• Connection to the various data sources Data may be stored in different databases, in a data centre, in the cloud, etc. A connection must be made to the platform used to store the data.
• Data extraction, transformation, and loading (ETL) The goal is to create one storage space complete with the compatible and valid version of the data from each data source.
• Querying the centralized data User queries must be performed rapidly and efficiently.
• Data visualization The results of the queries run on the ETL data from the different data sources are displayed in a format that users can consume according to their needs and preferences.
The ITIL story: Reporting and advanced analytics
|
Henri: Axle’s data stores contain information about vehicle hire, customer preferences, and patterns of use. We use this information when making decisions about changes to our services. The data we collect and store for analysis is managed in accordance with local and international laws and regulations, with the explicit approval of our customers. |
|
Solmaz: At each stage of its development, we must ensure that the electric bike hire service gathers the appropriate data that will allow us to perform data analytics. We use techniques such as forecasting, visualization, pattern matching, and sentiment analysis to inform customer requirements. |
|
Reni: Analysing data for the pilot will be easy as the service is new and fairly simple. When the service is fully functioning and integrated into Axle’s portfolio, it will be more difficult to find patterns and trends. We need to consider what data would be most valuable at every stage to help us understand our customers. |
3.3 Collaboration and workflow
The ever-increasing adoption of an Agile approach to managing work, particularly within software development, has triggered a related uptake in the use of tools and methods that support it. These are outlined in Table 3.2.
Table 3.2 Tools and methods that support an Agile approach
Tool or method |
Explanation |
Making work visible |
The use of physical boards and maps, colour, and graphics to visualize the work on hand, display how the team plans to handle it, and plot and record its journey through the work stream. Although many IT work management systems contain large quantities of data, very little can be easily viewed or consumed. Bottlenecks may not be noticed until it is too late to resolve them. Work or issues that are hidden from view may be delayed or left unresolved either because no one is aware of them, they fall outside allotted areas of responsibility, or few individuals possess the knowledge or have the availability to fix them. |
Working in topic-based forums |
Although email still predominates in the workplace for the management of work, its characteristics of personal folders, duplicated messages, and lost attachments hidden within vast, nested email chains mean time is frequently wasted in the search for important information. Good collaboration tools utilize a forum approach, where individuals and teams can take part in direct discussion. They facilitate topic-based areas, mini projects and campaigns, etc., which are available only to the individuals involved in the discussion. This helps to improve efficiency and avoids wasting time by searching for documents. |
Mapping workflows |
Teams and projects utilize a model in which their work is presented and used in a visible format. Work packages, timescales, people, and outputs are shown as tangible and easily accessible elements. The work is made available for others in the organization to see. This transparency can lead to greater communication and collaboration across teams, averting a common challenge within big organizations. Issues and problems do not follow the typical reporting lines of organizations, so there is a constant need to improve collaboration by checking for gaps, omissions, or potential blockages that can go unnoticed between or across teams. |
Working in small teams and sprints |
This is a key element in Agile and DevOps, where small integrated teams work on discrete packages of work as end-to-end value streams. Tools and cross-team methods should dynamically reflect the nature of these teams, which are often in operation for a finite period of time as part of a matrix resourcing model or due to flexible ways of managing issues, such as swarming. The relevant teams may only require light documentation, approval processes, and stages in order to achieve their goals. |
Using simple feedback mechanisms |
Communication does not need to be overly formal or complicated. In fact, there is usually a greater chance that the communication will be noticed, read, and actioned if it is simple and easy to comprehend. The collection of customer and employee feedback should be instantaneous and intuitive. |
Collaboration and ‘social media’ features |
Certain social media features are being adopted by work-based tools. Many individuals are already used to features such as ‘like’, ‘retweet’, or ‘share’, and these can be used in the work environment to provide useful data. Furthermore, emojis can also be used to represent feedback responses. |
Many of the tools used for collaboration are designed to resemble interfaces that the user is familiar with from social media, including:
• Communications wall A feature of many social media platforms, particularly those dedicated to communication. A wall can be used as a central area for general communication.
• Topic-based forums and folders These can relate to specific topics with relevance to a varying number of users, from a single specialist up to a large team or topic-based area, projects, operational areas, lifecycle areas, or special interest groups.
• Event surveys Support software usually provides the capability to gather instantaneous customer feedback via a survey. The response to these is often low, although it can be improved through thoughtful survey design that emphasizes brevity and simplicity.
• Portals Actionable portals for requesting services or reporting issues are becoming more prevalent, reducing the inefficient use of email. Good design and user experience is important for successful adoption.
• Self-help Knowledge bases that provide solutions directly to the user can be useful for simple and low-risk issues.
• Social media functions Collaboration tools that provide simple and effective means for users to respond and provide feedback.
3.3.3 Workflow in IT and service management tools
A recent development and improvement in many IT and service management tools is the capability to build, map, and manage process workflows dynamically within the products. This is frequently delivered via a locked-down development interface, whereby changes to workflow elements can be made without the need for scripts or coding, meaning they can be delivered by less-technical frontline individuals.
The interfaces for these administration tools are usually designed in familiar process-mapping formats with swim lanes and action boxes, decision points, parallel streams, and dependencies. These support collaboration, because they reduce lead times for changes as well as presenting the workflows in simple graphical formats.
The ITIL story: Collaboration and workflow
|
Reni: At first, the team working on the pilot will be small, our practices will be visible, feedback will be informal, and we will collaborate closely. If the pilot is successful, we will need to adapt our practices to retain those qualities in order to deliver efficient and effective services as we scale the offering to all our branches. We hope to include familiar social media features, such as commenting forums and chatrooms, as part of the service offering to enable two-way communication between customers and Axle staff. |
3.4 Robotic process automation
Robotic process automation (RPA) is a potential way for organizations to streamline business operations, lower staffing costs, and reduce errors. Through the use of software robots (bots), repetitive and mundane tasks can be automated, allowing resources to be deployed on higher-value activities elsewhere.
Robots can be used to simulate activities that humans perform via screens or applications in order to capture, interpret, and process transactions. This can trigger responses, creating and manipulating data in a consistent and predictable way.
Robots are typically low cost and easy to implement. They do not require the redevelopment of existing systems or involve complex integration within existing systems. The potential benefits are clear, as RPA allows for consistent, reliable, and predictable processes to be implemented in a cost-efficient way. This consistency can lead to fewer errors in key processes, increases in revenue, and better customer service, which leads to greater customer retention.
The types of process where RPA can yield the most benefit tend to be high volume, error prone, and sensitive to faults. Processes that are rules-based and which do not require complex decision-making are open to this kind of automation.
More sophisticated RPA tools incorporate machine learning and artificial intelligence (AI). These tools replace a rote-based approach with one that can adapt and react to a variety of inputs.
Deploying robots can seem deceptively simple, but RPA can be fragile. Even simple changes to the applications that RPA interacts with can have unexpected consequences. A small amendment may appear simple to a human, but an RPA may not tolerate it. If a change causes failure, it may affect performance or corrupt the data.
The design and development of RPA plays a part in how robust it is when dealing with change. Nonetheless, there are limits. The development of RPA often requires configuration and scripts to define the required inputs and outputs. Although these scripts are straightforward to construct, requiring little in the way of technical expertise, they should be treated as software assets and managed similarly. Testing, configuration management, and change management apply as much to RPA as they do to any other software.
Generally, there are three types of RPA technology:
• Process automation This focuses on automating tasks that depend on structured data (e.g. spreadsheets).
• Enhanced and intelligent process automation This works with unstructured data (e.g. email and documents). This type of automation can learn from experience and applies the knowledge it gathers to other situations.
• Cognitive platforms These understand customers’ queries and can perform tasks which previously required human intervention.
Enterprises are beginning to employ RPA, together with cognitive technologies, such as speech recognition, natural language processing, and machine learning, to automate perception-based and judgement-based tasks that were traditionally assigned to humans. The integration of cognitive technologies and RPA is extending automation to new areas, which can help organizations to become more efficient and Agile as they adopt digital transformation (see Figure 3.2).
RPA software and hardware automates repetitive, rules-based processes that were usually performed by humans sitting in front of a computer. Robots can open email attachments, complete forms, record data, and perform other tasks to mimic human action. They can be viewed as a virtual workforce assigned to middle- and back-office processing centres.

Figure 3.2 Manual vs robotic process automation
After Schatsky et al. (2016)3
The integration of cognitive technologies with RPA makes it possible to extend automation to processes that require perception or judgement. The addition of natural language processing, chatbot technology, speech recognition, and computer-vision technology allows robots to extract and structure information from speech, text, or images and pass it to the next step of the process.
There are several benefits of a successful RPA programme, including:
• Lower labour cost After the robots are deployed, the only costs are related to servicing and maintaining the software.
• Increased throughput As robots can do manual tasks hundreds of times faster than a human, including developing, testing, and deployment of software, the time to market for new products can be reduced, which speeds up return on investment (ROI). Robots are also constantly available throughout the year.
• Increased accuracy Robots are able to achieve near-perfect accuracy, which increases excellence throughout the value streams, value chain, and SVS. This provides a more consistent experience with a standard level of output, deeper insights into business/IT performance and customer experience, and a reduction in the level of human error.
The implications of application and environment change for RPA should not be underestimated. Without strategic thinking, governance, control, and judicious application to support an overall strategy, RPA risks becoming the legacy application of the future.
RPA implementation should be approached with the same caution as would any service or tool. It needs proper planning, analysis, design, and governance processes, including the following considerations:
• Garbage in, garbage out The use of robots to run key processes is a challenge if there are no standard processes to follow.
• ITIL guiding principles For example, optimize and automate and keep it simple and practical. Identify areas which have the most potential for automation and prioritize automation accordingly.
• Develop the right skills in the right people For example, how to arrange and use RPA efficiently and effectively.
• Determine realistic ROI expectations Design a sound business case and explain costs, risks, and benefits to the board of directors.
• Enable strong collaboration between the business and IT Special consideration should be given to RPA project owners and IT, as neither business area can work independently.
• Execute automation Treat automation as a roadmap with short iterations.
The ITIL story: Robotic process automation
|
Indu: Over time, the processes and practices of the new bike rental service will coalesce and become standardized. At that stage, we will look to automate repetitive work, such as data entry of details of our customers and bikes, using low-cost, easy-to-implement software robotics, which will facilitate consistency, reliability, and predictability. |
Cognitive technology is increasingly being used to provide more automation in each phase of the service lifecycle and to enhance the service experience for both the consumers and the people involved in serving them. It is also increasingly prevalent in related and supporting domains, such as software development and operations.
Although AI technologies have existed for decades, a new generation of cloud-based tools has resulted in a significant increase in focus and usage. A number of AI tools are now provided as public cloud services, with a range of options available from both specialist AI providers and major broad-offering cloud vendors. This has significantly improved the accessibility of AI tools, with solutions which might previously have required complex technology and significant financial outlay now available on demand at comparatively low cost via simple API (application processing interface) calls.
There is a huge amount of marketing hype and misapprehension in this area, so it is vital to have a clear understanding of the business goals and desired outcomes from adopting AI and the key components, capabilities, and constraints of any potential solution.
3.5.1 Architectural considerations
The implementation of AI technology tends to require significant investment in hardware, software, and expertise. In the past, expense and complexity limited its uptake, but it has become much more mainstream since the emergence of a new generation of cloud-based services.
AI technology is increasingly available from major vendors, consumed as public cloud services, and all major cloud service providers (CSPs) now offer a range of services to address many different priorities or ‘use cases’. These services place leading AI offerings at the end of API calls, and hence many organizations are now consuming them to underpin the digital services they deliver to their users.
Additionally, some service management tool vendors now provide AI-driven features as part of their offering, such as conversational tools for end-users and support agents, automated classification or routing, and language tools, such as translation and sentiment analysis.
One benefit of these services is that they are typically designed and configured specifically for service management use cases. This can enable them to deliver more immediate value than a generalized AI tool, which may require additional work to align to the required use cases. The services may either be underpinned by the vendor’s own AI software or harness the technology of specialist AI vendors.
However, an on-site AI implementation may still have significant advantages. AI requires a significant amount of computing power and processing time to function. This may lead to high charges from public cloud vendors who bill on this basis. Hence, particularly at scale or over time, it may be more economical to use dedicated on-site hardware. Indeed, a number of vendors now provide servers and software dedicated to AI.
It is also important to consider portability and the risk of vendor lock-in. If your digital service is dependent on specific AI services provided by a third party, it may be challenging in future to switch to a different provider.
AI technology offers a broad set of new tools to the service designer, and it is possible to anticipate many new innovations in the application of AI in service management. Some examples of common applications of AI in service design and delivery include:
• Process and decision automation The use of AI to determine the appropriate process branch to follow, based on analysis of the known facts.
• Natural language processing Interpretation of unstructured text for purposes such as translation, summarization, or sentiment analysis.
• Conversational interfaces Enabling customers or service agents to interact with the service management tooling using normal written or spoken language, a common example being chatbots for automated self-service.
• Predictive analysis Projection of the future state of a metric or situation, enabling proactive decision-making.
• Discovery Identification of useful insights from large collections of information, such as log files, knowledge bases, or previously recorded tickets.
Another emerging technology that will change the way IT services are managed in the future is AIOps and the emergence of AIOps platforms. These platforms were first described by Gartner in 2016,4 referring to the practice of combining big data, analytics, and machine learning in the field of IT operations. The term AIOps was originally derived from Algorithmic IT Operations, although it is frequently synonymously assumed to mean artificial intelligence for IT operations, which, conveniently, is a clearer description of the subject.
Instead of siloed teams monitoring their own parts of the infrastructure, the idea is to collect all the important monitoring data in one place and then use machine learning to identify patterns and detect abnormalities. This can help IT operations to identify and resolve high-severity incidents faster and even help them to detect potential problems before they happen. It can also be used to automate routine tasks so that IT operation teams can focus on more strategic work.
AIOps aims to bring AI to IT operations, addressing the challenges posed by modern trends in the ongoing evolution of infrastructure, such as the growth of software-defined systems. The implications of these new technologies, such as the increase in the rate at which infrastructure is reconfigured and reshaped, necessitates more automated and dynamic management technologies, which may have a significant impact on an organization’s digital services.
AIOps harnesses data platforms and machine learning, collecting observational data (e.g. events, log files, operating metrics) and engagement data (e.g. customer request and service desk tickets), and drawing insights by applying cognitive or algorithmic processing to it.
These insights may be used to drive some or all of a range of common outputs, such as:
• Issue detection and prediction Helping the service organization to respond more quickly to incidents.
• Proactive system maintenance and tuning Reducing human effort and potential errors.
• Threshold analysis Enabling a more accurate picture of the normal range of operation of a system.
Some organizations have also started to use AIOps beyond IT operations to provide business managers with real-time insights of the impact of IT on business. This keeps them informed and enables them to make decisions based on real-time, relevant data.
The ITIL story: Artificial intelligence
|
Indu: We may consider using chatbots to enable customers to interact with our booking system, or use natural language processing for the purpose of translation, to allow customers to book a vehicle in their own language. These could be combined with process and decision automation, predictive analysis, and discovery. |
Machine learning is an applied form of AI. It is based on the principle of systems responding to data, and, as they are continually exposed to more of it, adapting their actions and outputs accordingly. Where machine learning is used to underpin services, this essentially means that it becomes the basis for decision-making in place of paths which are defined by instructions created by human service designers.
As the complexity of a task increases, it becomes harder to map machine learning to that task. Machine learning is typically best suited to solving specific problems. For example, it can be used effectively to make decisions about data classification on support records, which may subsequently drive additional decisions, such as assignment routing.
3.6.1 Supervised and unsupervised learning
Supervised learning is the most commonly encountered machine-learning approach. It is used where both the starting points (inputs) and expected ending points (outputs) are well defined. Supervised learning can be represented as a simple equation:
Y = f(X)
In this equation, X represents inputs, and Y outputs. The job of the machine is to learn how to turn X into Y, effectively building the function defined here by f.
As part of this learning process, a supervisor needs to determine:
• the learning algorithm to be used
• the sample data set used to train the machine. In the context of an IT service this may, for example, be rows of structured data from the system of record (e.g. an IT and service management toolset), each of which covers a ‘known good’ previous decision regarding the outputs made by a human, based on a range of inputs.
A supervised learning system may initially use existing data to train a system. When the results which the system produces have reached a required level of accuracy, the system is considered adequately trained. Any required manual corrections are then made, and ongoing training can continue to improve the reliability of the outputs, reducing the need for continual supervision.
Supervised learning is well suited to both classification problems (e.g. identifying emails that are spam) and regression problems (e.g. analysing when a variable metric is likely to reach a specific threshold).
Unsupervised learning also requires input data, but this approach does not use existing output data from previous decisions and there is no supervisor. Instead, the machine learns from the input data alone.
Unsupervised learning is well suited to ‘clustering analysis’ (the identification of inherent groupings in data) and ‘dynamic baselining’, which is the prediction of future behaviours of a metric based on its past behaviour. In the context of a digital service, unsupervised learning may, for example, be able to detect previously unknown correlations between causes and effects, such as a likelihood that failure Y will occur when failure X occurs.
3.6.2 Benefits and limitations of machine learning
One of the key advantages of machine learning, in the context of IT services, is its ability to derive valuable results from quantities of data (in terms of breadth, depth, frequency of update, or a combination of the three) which would be difficult for humans to process. This can enable improvements in the efficiency or accuracy of decision-making and may enable the automation of entirely new data-driven decisions, which would not have been practical for humans to evaluate (for example, because of the number of data points being too high).
However, the performance of a machine-learning system is entirely dependent on its data, the algorithms used within it, and, for supervised systems, the quality of training. If the input data contains inherent bias, this can directly distort results. This issue has led to some high-profile media coverage, such as when machine-learning systems have exposed and propagated racial bias in source data.
Selecting and implementing the correct algorithm is important and requires a good knowledge of data-science principles and the nature of the data set itself, including such aspects as its outliers. Training a supervised system requires the supervisor to have a clear understanding of which results are actually correct.
Another significant challenge faced by machine-learning systems is the potential for a lack of transparency in the processing of data. In contrast to deterministic algorithmic systems, where the behaviours are defined by humans and can be investigated, the behaviours of a machine-learning system may be difficult to account for, particularly where there are many input parameters.
Deep learning is a subset of machine learning based on artificial neural networks. This learning can be supervised, semi-supervised, or unsupervised, and it relies on computing systems modelled on the biological neural networks found in animal brains. These systems learn by considering examples, gradually tuning the weighting factors driving their processing in each instance.
The ITIL story: Machine learning
|
Indu: Machine learning is a practical application of AI. In this project, machine learning could be used to understand which cycle routes are out of range of the current battery capacity of our electric bikes by mapping data about: • the locations where the battery charge was exhausted • routes taken by customers. An outcome of this may be to encourage future customers to choose routes that are scenic and interesting, yet within the range of the batteries on our electric bikes. Alternatively, we might find ways to recharge batteries on the popular routes which are out of battery range; for example, by liaising with service stations near local landmarks where customers can leave their bikes to recharge. |
3.7 Continuous integration, continuous delivery, and continuous deployment
Continuous integration, continuous delivery, and continuous deployment (CI/CD) are descriptive terms for a collection of practices primarily associated with software engineering, which are central to the philosophy of Lean and Agile software development. The adoption of these practices has grown rapidly, and it is important to understand the defining characteristics of CI/CD and the wider context of evolving system development practices when implementing services that are underpinned by software development.
Definitions
• Continuous integration An approach to integrating, building, and testing code within the software development environment.
• Continuous delivery An approach to software development in which software can be released to production at any time. Frequent deployments are possible, but deployment decisions are taken case by case, usually because organizations prefer a slower rate of deployment.
• Continuous deployment An approach to software development in which changes go through the pipeline and are automatically put into the production environment, enabling multiple production deployments per day. Continuous deployment relies on continuous delivery.
These approaches are supported by the software development and management, service validation and testing, deployment management, infrastructure and platform management, and release management practices. These practices involve specific skills, processes, procedures, automation tools, and agreements with third parties. They enable the continuous pipeline for integration, delivery, and deployment, which would also affect the design of other practices, such as service configuration management, monitoring and event management, incident management, and others.
CI/CD is, effectively, a practical methodology for delivering software in an Agile manner, consistent with the set of principles defined in the Agile Manifesto:
• Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
• Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage.
• Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
• Business people and developers must work together daily throughout the project.
• Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
• The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
• Working software is the primary measure of progress.
• Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
• Continuous attention to technical excellence and good design enhances agility.
• Simplicity – the art of maximizing the amount of work not done – is essential.
• The best architectures, requirements, and designs emerge from self-organizing teams.
• At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behaviour accordingly.
CI/CD, and the broader principles followed by the Agile movement, are commonly regarded as being the complete opposite of the waterfall approach to service development, which defines the process of system development/implementation as a linear series of phases, with each phase only commenced once the previous step has been completed.
CI/CD is sometimes conflated or confused with DevOps, but this is a simplistic viewpoint. Although the establishment of CI/CD is inherent to its adoption, DevOps has a much broader context, encompassing team organization and culture in addition to any specific mechanics for system delivery.
3.7.1 Goals and value measurements
CI/CD has a primary goal of enabling smaller, high-frequency deployments of changes to systems. This is intended to reduce risk (by making each deployment less complex) while simultaneously increasing the velocity of value co-creation (by enabling useful changes to be delivered more quickly to consumers). Small changes are easier to comprehend, consume, test, troubleshoot and (where necessary) roll back.
The Agile movement is founded on a rejection of large, complex projects that have extensive payloads delivered on an infrequent basis. Such projects are seen as ineffective, primarily because:
• the complexity of large production deployments increases the risk of introducing new issues and makes troubleshooting more difficult
• long periods between releases reduce the opportunity to deliver value quickly. This leads to opportunity costs and reduces an organization’s ability to adapt its services to new, emergent conditions
• linear development frameworks reduce the opportunity to interact on a regular basis with consumers, increasing the chances that a solution will be delivered that is sub-optimal for the consumer’s needs.
CI/CD teams often define their success by their ability to deliver code changes to production systems quickly, efficiently, and reliably. When designing services which are underpinned by the work of software developers practising CI/CD, it is important to be aware of these goals.
A fundamental part of CI/CD is the optimization of the flow of changes from development to production. CI/CD teams also typically have a strong focus on the identification and removal of bottlenecks that reduce the speed of delivery. This often results in a strong focus on automating aspects of delivery which would otherwise require significant manual effort.
Although maintaining a high velocity of deployments is important to CI/CD, teams must also ensure that each change maintains an appropriate level of quality. Validation and testing of each change remain critical, but because they need to be completed quickly, these processes are often automated.
A key component of the implementation of CI/CD is the pipeline. This term defines the set of tools, integrations, practices, and guardrails which allow a continuous and substantially automated flow of changes, from their initial design and development through to deployment into production.
This flow is typically broken up into three different stages:
• Build automation (the CI phase) This stage encompasses coding practices, such as version control, and the merging of multiple developers’ changes into one branch.
• Test automation In this stage, each change is automatically tested and validated as part of the flow chain from development.
• Deployment automation This stage involves the automation of the actual process of moving code from pre-production environments to the production service.
A significant focus for organizations or teams implementing CI/CD is the reduction of pieces of work requiring manual effort. (If left unchanged, these would impede the flow of the CI/CD pipeline without delivering a proportional amount of specific value.) This kind of work is sometimes referred to as ‘toil’. Google’s Site Reliability Engineering5 defines toil as work which exhibits some or all of a certain set of characteristics:
• Manual Work which requires hands-on time from humans.
• Repetitive Work in which the same tasks are repeated over and over again.
• Automatable Work which does not require specific human judgement and so could be achieved by a machine instead.
• Tactical Work which is interrupt-driven and reactive rather than strategy-driven and proactive.
• Devoid of enduring value Work which does not make any permanent improvement in the service, leaving it in the same state after the task has finished.
• Linearly scaling Work which scales up in proportion to the service size, traffic volume, or user count.
When designing and implementing a service which relies on the effective operation of CI/CD practices, it is important to either eliminate or avoid toil. Failing to do so can limit the scalability of the service, and unnecessarily increase the cost of delivering it, particularly as the service grows.
3.7.3 Aligning CI/CD with ITIL
The core aspects of Agile software development and, by extension, CI/CD are closely aligned with each of the ITIL guiding principles:
• Focus on value Agile development is intended to deliver early and continuous value to the customer.
• Start where you are Agile is built on the concept of continuous, incremental development rather than large releases after lengthy development cycles.
• Progress iteratively with feedback Agile advocates continuous feedback loops.
• Collaborate and promote visibility Good Agile product delivery requires effective visualization of work to all delivery participants, as well as constant interaction with the consumer of the delivered service.
• Think and work holistically Agile development focuses on the big picture of the business and the goals the consumer expects to achieve.
• Keep it simple and practical Agile development is founded on Lean principles. As such, non-productive, low-value activities are regarded as waste and are eliminated.
• Optimize and automate Continuous feedback loops and reduction of toil are fundamental to good Agile practices.
When working with CI/CD processes and the teams responsible for them, individuals and teams should actively seek opportunities to enhance their success.
For instance, rather than starting with the presumption that changes progressing through the CI/CD pipeline need to be controlled, it could be worth considering whether there might be better ways to enable those changes.
Some examples of how this might be achieved could include:
• Taking work away from the development teams and centralizing it in the change function in a way which reduces overall toil (e.g. if development is taking place in a regulated environment, are there checkpoint tasks currently undertaken by developers which could be centralized in the change team?).
• Bringing broader business context to risk assessment, helping to better quantify the risk of specific changes, and, ideally, to find changes that are lower risk and that may have a smoother path through the CI/CD pipeline.
• Relaxing pre-defined controls in favour of ‘guardrails’, thereby allowing individual teams more flexibility to innovate and establish their own change procedures, while still maintaining confidence in the overall safety of the CI/CD process.
3.7.4 CI/CD does not suit every situation
Agile approaches, such as CI/CD, are well suited to situations where there is high uncertainty about present and future requirements for a service, and where risks associated with errors or failure are of relatively low impact or can be managed quickly. In these cases, the iterative nature of CI/CD enables the ongoing development of the service to respond to, and drive, an increasing understanding of the customer’s demands and the best way to deliver value to them.
However, plan-based approaches, such as the waterfall method, may still be more suitable in some situations; for example, where there is high certainty about the requirements of the service, or where safety demands the use of large-batch deployments which are not well suited to the Agile approach. In practice, particularly in larger and more complex organizations, a service will often depend on multiple elements which are delivered using different approaches.
The ITIL story: Continuous integration, continuous delivery, and continuous deployment
|
Indu: If this project is successful, the continuous integration and deployment of improvements or new service offerings for our bike customers will be the difference between an expanding or declining service. To accommodate the required changes, we will need to sustainably and continually deliver working software, and adjust our patterns of work to better accommodate change. This will mean that each change is less of a risk and will allow us to respond iteratively to feedback should one of the changes not work as intended. |
3.8 The value of an effective information model
As digital transformation progresses, organizations’ business operations continually become more closely aligned with, and dependent on, their technology systems and services. As this happens, information can increasingly become a constraint on the effective delivery of services. Several factors can contribute to this issue:
• The organization may distribute information inconsistently and sporadically across multiple IT systems and beyond (some, for instance, may be kept in physical media, while other critical data and knowledge may only exist in people’s heads).
• The quality of the information may be overestimated or unclear.
• Multiple systems, increasingly running on multiple infrastructure types, may be critical to the operation of the organization’s services, but exactly how critical they are may not be clear.
• Inconsistent terminology may be used across different parts of the organization.
To combat this type of challenge, organizations are increasingly using an information model with the aim of developing a shared understanding of their information, terminology, systems, and structure.
The value of such a model is multifaceted. It can be a key enablement tool for transforming processes and practices, integrating technologies, gaining an accurate overview of strengths and weaknesses in the service framework, and driving informed decisions at multiple levels in the organization.
Successful results-based measurement requires a clear understanding of the expected outcomes and results, not only for individual systems but for the organization as a whole. Goals must therefore be aligned with those of the organization. They must be agreed, understood, and documented; as must the methods by which their achievement will be measured. Results-based measurements also provide information on the effectiveness and efficiency of the services.
3.8.1 Anatomy of an information model
There is no single definition of an information model, but an effective one will typically consist of several core elements including:
• definitions of key facts, terminology, activities, and practices within the organization
• structural representations of key components of the organization’s technology and business services, and the relationships between them.
The ideal level of detail held within a model will vary, not just between organizations but within them. Areas of business which are undergoing more rapid change or more significant investment, for example, will warrant more detail in an information model than areas which are relatively static.
Although some organizations may choose to create an information model from scratch, others may decide to adopt (at least initially) one of a number of established models that focus on technology and operations in large organizations. Two examples of this are:
• Common Information Model (managed by DMTF) A set of open standards setting out a common (and growing) definition of management information across a wide range of IT infrastructure, including modern cloud and virtualization technologies.
• Frameworx A set of ‘best practices and standards that, when adopted, enable a service-oriented, highly automated, and efficient approach to business operations’. Particularly focused on telecommunications and managed by TM Forum, it is a widely used framework in that industry.
The ITIL story: The value of an effective information model
|
Henri: I have worked to develop a shared understanding of Axle’s structure, terminology, information, and systems. The information model used by the bike rental pilot will mirror that of the wider organization. |
|
Reni: ITIL provides a common language that service managers can utilize to facilitate communication. Adopting ITIL practices from the beginning of the pilot will improve the project’s scalability as it expands. |
3.9 Automation of service management
3.9.1 Integrated service management toolsets
Some vendors have been offering integrated toolsets for service management since the 1990s. These toolsets automate records and workflow management and act as engagement and communication tools, with many aiming to support a holistic information model for service management. The majority of these toolsets are designed to automate the service management practices recommended by ITIL, and they are constantly evolving to adopt new technologies.
The most-used functionalities of these toolsets are the systems of record and systems of engagement. These are used to raise, classify, prioritize, escalate, and resolve issues, requests, and changes for items and areas of business and technology infrastructure (including people, IT, departments, services, and functional areas). This includes real-time management of expectations for delivery and fulfilment, approval, escalation, and consumption, as well as other administrative functions around inventory, finance, and lifecycle management.
The value of these toolsets is in the real-time dynamic ability to manage volumes of work, which range from small and simple to complex and large, and to provide reporting and business analytics on performance, trends, improvements, costs, and risks. In addition, the toolsets offer accountability and audit trails on the delivery of work and management of ‘service’ assets and resources.
Organizations of various size and reputation use these toolsets in some form or another to optimize routine record keeping and demonstrate some levels of accountability, consistency, and control. However, most organizations have only made use of the basic functions in the toolsets (incident management, SLM, inventory management) and ignored the opportunities for multi-functional integration across processes. As such, the opportunity of end-to-end value stream integration that the toolsets provide has rarely been exploited. However, as new challenges and opportunities arise, there is a greater requirement to make use of this functionality and integration.
3.9.2 Service management toolset expectations
Service management toolsets are expected to provide:
• effective automation of workflows, including:
• combining standardized pre-defined models and flexibility to allow for customization
• seamless integration of workflows between different practices, value chain activities, and organizations to enable end-to-end value stream management
• end-to-end automation of product and service lifecycles, covering all stages
• effective inventory, monitoring, and event management, including intelligent discovery, change and event detection, capacity monitoring, consumption, and transactions monitoring for technology solutions used both in-house and by third parties
• effective integration with:
• other organizations’ toolsets
• other information systems used in the organization
• other information systems used for service management
• social networks and communication channels used by the organization and its service consumers, suppliers, and partners
• a high level of service warranty, including:
• information security
• availability
• performance
• capacity
• compliance
• continuity
• accessibility
• conformance to evolving architectural and technical requirements and standards
• advanced analytics and reporting.
The ITIL story: Automation of service management
|
Solmaz: There are many different types of work carried out at Axle, and numerous tools for automating it, but first we must make sure that automation is applied across the four dimensions of service management. For example, we must find the best way to automate how we work with our local electric bike breakdown service, or manage the tools we use to create our electric bike software. Some systems are provided by the team in Seattle; for example, our human resources and finance systems. But we need to invest specifically in the tools for managing our electric bike hire business in Montreux. |
|
Reni: We must select the best tools to help automate the work where needed. We must also ensure that we have the capability for human intervention should things start to go wrong. Some years ago, our customers were frustrated by how long it took us to resolve their incidents. When we investigated the matter, we discovered that the tools we were using required our support agents to classify incidents, which they often did incorrectly as the incidents were being logged. This resulted in support work being sent to the wrong groups, causing incidents to bounce from team to team. We have since changed the way in which we log incidents, but we are always looking for opportunities to improve further. |
|
Henri: Some tools, like our IT and service management toolset, are used by all teams globally for consistency in reporting and management information, which facilitates better decision-making by my team of senior managers. However, I also recognize the need to allow teams to work in the way that they think is best, which may include investing in niche, best-of-breed tools that can help solve specific issues. |
|
Solmaz: A guiding principle of ITIL is ‘optimize and automate’. This recommends that we find the best approach, often through iterative trial and error, before we start automating work. That’s how we expect our teams to work, and the data shows that this approach produces better results than jumping headfirst into automation without taking the time to properly work out what needs to be changed and optimized. |
In this age of consumer and enterprise automation, investments in IT are critical for the delivery of valuable products and services. The technology landscape is changing rapidly and diversifying into niche domains.
To help navigate this complex ecosystem, organizations are now actively investing in tools to: facilitate the flow of work across multiple functional domains; promote collaboration; aid in advanced analytics and decision-making; and progress the automation of repetitive low-skilled work. This in turn frees organizations to invest in advanced service management capabilities that add value to diverse stakeholders.
The use of multiple tools and platforms drives the need for a common information and data model across the organization, as well as the need for effective integration.