
CHAPTER 5
PRIORITIZING WORK AND MANAGING SUPPLIERS
5 Prioritizing work and managing suppliers
5.1 Why do we need to prioritize work?
Queues occur wherever the demand for work exceeds the capacity to complete it within the expected timeframe. In an ideal situation, an organization would have no variation in demand and would have the appropriate quality and quantity of resources needed to satisfy it. However, organizations often need to contend with having a fixed capacity but a varying demand for services. This imbalance creates queues or backlogs in which work items need to be prioritized.
Prioritization is an activity commonly associated with support and software development work (e.g. prioritizing incident records or prioritizing a sprint backlog), but its use is universal.
5.1.1 Managing work as tickets
A ticket is a record of work. Before the widespread adoption of digital systems, paper forms were a common communication medium, sitting at the centre of the workflow process. These tickets were often constructed with a ruler, pen, and typewriter and would be photocopied, manually completed, and placed in the physical in-tray of the next employee in the documented process. Although the data might have been entered into an electronic system at some point, the physical ticket itself was the vehicle through which the data (and the response to that data) evolved.
The emergence of business IT systems and the normalization of computer-based work meant a fundamental shift in the media used for information capture and transmission, but it did not change the underlying ticket process. The data fields on paper forms became database tables controlled by software applications. Those tables were shown to users as on-screen forms, each typically composed of a collection of fields arranged in a familiar way. In other words, the software user interface echoed the paper form.
Digital forms were an extraordinary improvement over physical ticket systems for many reasons. Data transmission was instantaneous, replacing the time-consuming movement of internal office envelopes through physical company postal systems. Data could be made more consistent through the control of the nature of what could be entered into the given fields. Buttons and other controls improved automation and provided better guidance to the user. The main driver for the design, however, was arguably the data itself: user experience was not the primary consideration.
For some time, customer service industries, including IT service management, have designed support structures and workflow practices around data manipulation on ticket forms and the transfer of those tickets from one assignment list to another. Negative impacts are common and include, for example:
• hotel check-in procedures involving lengthy typing by a front-desk employee
• telephone support agents having to pause the conversation while they complete on-screen forms
• customers being asked to enter the same details on consecutive forms because their specific requirements necessitate several tickets.
Just as paper tickets used to amass in physical in-trays, electronic tickets often accumulate in assignment lists. A core principle of Lean manufacturing, the industrial philosophy which underpins Agile and DevOps, is that work queues represent interruptions to the flow of work. Lean, Agile, and DevOps focus heavily on the reduction of accumulated work-in-progress. Consequently, many IT professionals have a negative opinion of queues.
It is important to recognize that the ticket represents a discrete unit of work and its current state within its expected lifespan. A busy service provider performs many tasks and activities simultaneously, so it is vital that they have the means to record and track their work. Without this, the risk of chaos, data and information loss, and a lack of accountability is high; all of these have significant consequences for the risk management and overall governance of the organization.
Hence, tickets are important. They enable prioritization, communicate the current state of any given task to anyone who should know it, and enable high-value behaviours. Even after the work has been completed, the archive of recorded tickets continues to provide value as a source of data for management reporting and analytics.
Nevertheless, the user experience and behaviours that have accumulated around tickets can cause problems. Tickets do not cause queues to happen: queues are not a fundamental property of a ticket. Rather, queues are the result of the way the organization allocates people and other resources to manage the tickets.
Recently, service providers have differentiated themselves by moving away from the digital equivalents of forms to polished interfaces that obscure the record-keeping experience. These new interfaces significantly enhance user experience because the interface is a more human representation of the work and context, although the system still performs data entry and record keeping.
Effective service design does not require the avoidance or elimination of tickets, but it does require that they are not the dominant influence on the user’s experience. Design-thinking principles are crucial, encouraging the service designer to focus on the specific challenges of stakeholders and identify user-focused solutions.
5.1.2 Prioritization and demand management
The prioritization of work to create, deliver, and support services is necessary for co-creating value while minimizing the costs and risks that arise from unfulfilled demand and idle capacity (Figure 5.1). Prioritization is thus a technique within an organization’s risk management practice.

Figure 5.1 Demand variations and their effect on capacity
At a high level, if demand is created when idle capacity exists, then there is no need to prioritize the work; the work can start immediately. However, when demand exceeds capacity, organizations have the option of managing the demand in order to minimize the queue and thus avoid the need to prioritize the work. Examples of this include:
• reducing variations in demand for value by:
• using pricing mechanisms based on volume of work (e.g. the first ten requests for a service are charged at a lower rate than the next ten)
• using pricing mechanisms based on when demand occurs (e.g. a restaurant offering a discount on week-night service)
• using pricing mechanisms based on quality (e.g. a business class plane ticket costing three times more than an economy class plane ticket)
• altering customer expectations about the length of time needed to complete work (e.g. requests made after 11am will be completed the following working day)
• reducing variation in how much demand is taken into a value stream or step (e.g. employees only being allowed to submit one request per quarter to change their benefits)
• increasing how much demand can be satisfied within a given period of time; for example, by:
• using automation to accelerate the processing of toil (common and repetitive tasks that scale in a linear fashion)
• increasing the size of teams or the number of teams so that more work can be done in parallel
• reducing the cost of increasing or decreasing capacity; for example, by:
• using elastic cloud platforms to swiftly increase or decrease available computing power
• outsourcing staffing requirements to professional services organizations
• using shift-left techniques to deflect demand or prevent demand from being created; for example, by:
• using a self-service knowledge base that enables users to troubleshoot common issues without the need for specialist skills
• using automated testing, integrated with development tools, to reduce the demand for separate testing and validation resources prior to deployment.
The above list highlights common methods for managing demand but, depending on context and complexity, other methods might be more appropriate.
The prioritization of work can occur at various levels of granularity, with a variety of implications for the wider system, and with various levels of impact on user or customer experience. For example:
• Prioritization conducted at a value-stream level increases the need to manage user or customer expectations in order to keep them engaged and to provide regular status updates. This is because, from their perspective, the realization of value is being delayed.
• Prioritization conducted at a value-stream step, action, or task level can result in a constraint in the flow of work. Resources that are waiting to be utilized later in the value stream may remain idle, or a build-up of work (a queue or a backlog) may form earlier in the value stream. This phenomenon is commonly referred to as ‘creating a bottleneck’ or ‘creating a constraint’.10
As much as possible, prioritization should be data driven, rather than emotionally driven, and it should consider all available information that affects the demand and workflow.
There are many different techniques for prioritizing work to minimize queues and wait times. These techniques can be broadly categorized as follows:
• Resource availability or quality Prioritization is determined by the availability of resources to complete the work. For example, if an infrastructure support team has one networking specialist to whom every network support case is assigned, then the team should prioritize non-network-related cases whenever the network specialist is occupied.
• Current workload Prioritization is determined by the current workload of the resource, provided there are no differences in quality between resources or variations in the sizes of work items. For example, support centre automation might assign incoming calls or chats to support agents who are not currently engaged with a user, or to agents with smaller workloads.
• Age Prioritization is determined by the age of work items; for example:
• First-in, first-out The oldest waiting item is actioned.
• Last-in, first-out The newest waiting item is actioned.
• Duration Prioritization is determined by the time required to complete work items; for example, by:
• Shortest item first The item that can be completed the quickest is actioned next
• Longest item first The item that requires the most time to complete is actioned next.
• Economic or financial factors Prioritization is determined by the monetary benefits and costs of work items. For example, an organization that has the capacity to process just one work item is likely to prioritize the item that has the highest economic benefit, such as that which earns most revenue, has the highest financial impact, or has the highest return on investment.
• Economic penalties Prioritization is of work items subject to economic penalty, such as a compliance feature that will reduce a regulatory fine.
• Source or type of demand Prioritization is of work items that are entitled to more immediate attention, such as a request from the CIO of an organization. Commonly, organizations create levels of entitlement (and set prices accordingly); for example, technology vendors and support service providers may implement a tier-based system in which silver-tier customers are prioritized over bronze-tier customers.
• Triage Prioritization is determined by urgency, based upon an assessment of the impact a delay may cause. For example, a doctor would prioritize treating a broken bone over a cold. Less urgent needs are only considered when more urgent needs have been addressed. Organizations should supplement this technique with procedures to ensure that low-priority work is not left unattended. For example, support organizations often increase the priority of open support issues when certain deadlines or thresholds approach.
It is important to note that prioritization techniques are context-specific. A technique that works for one environment or type of work might not work for another. At the same time, it is useful to align the prioritization of all types of work against a simple set of common objectives. For example, the prioritization of:
• Continual improvement opportunities These can be determined in the same way as other projects, such as using ROI estimates.
• Incidents These can be determined in the same way as items in a development backlog (e.g. using economic benefit/penalty estimates).
It is also common to find several prioritization techniques working together. For example:
• In the Cost of Delay11 method, prioritization considers the economic impact or penalty over time.
• In the Weighted Shortest Job First (WSJF)12 method, prioritization considers the Cost of Delay and the duration of the work.
A common technique for prioritizing incidents is to consider both impact (an economic factor) and urgency (a time factor). Work prioritization should be revised periodically or as more work enters the system; this allows for the dynamic reallocation of resources to manage queues.
Swarming13 is a method of managing work in which a variety of specialist resources or stakeholders work on an item until it becomes apparent who is best placed to continue with the work, at which point the others are freed up to move on to other work items.14
Swarming is an alternative to hierarchical organizations of specialist resources, where work escalates until it reaches the right level of competency and authority. The disadvantages of a hierarchical structure, which swarming addresses, include:
• Each tier has its own queue of work items, which affects:
• the total work in progress
• the time taken to find the right specialist to complete the work.
• Work can be reassigned between tiers, either from a lower tier to a higher tier, or vice versa. A team that escalates work, by definition, does not have the right skills to complete the work. This might also mean that the escalating team might not have collected or might have misunderstood the information necessary to complete the work, which might result in work items being sent back or escalated to the wrong group. For example, a service desk agent might presume that a user complaint about the failure to print a document was a printer issue, when the issue might actually be a network outage.
• Easily solved cases may be escalated to higher tiers, leading to overloaded specialists who should be focusing on more difficult cases.
Swarming seeks to address these disadvantages by:
• creating a single cross-functional and self-organizing team with a dynamic and flexible structure, which reacts to the work that comes in
• relying heavily on good communication and collaboration, both within the team and with external stakeholders
• focusing on avoiding queues
• sharing and encouraging the development of skills and experience across all team members.
Organizations typically utilize a mixture of swarming techniques alongside ones that are appropriate for tiered structures. For example:
• assigning a person to own a work item until it is completed, even though the work could be completed by someone else in the swarm
• using swarming within specialist hierarchical groups to reduce negative behaviours within each tier.
Because of the self-organizing nature of swarming, there are no definitive categories or types of swarms. However, some examples from real organizations include:
• Dispatch swarms These meet frequently throughout the day to review incoming work, select quick-to-complete items, and validate that the correct information has been recorded for work which requires onward assignment.
• Backlog swarms These convene on a regular or ad-hoc basis at the request of product or service specialists who need input from members of other specialist groups, thereby avoiding delays as work items get reassigned between teams and queues.
• Drop-in swarms Experts are either made continuously available or they continuously monitor the activity of other teams in order to decide if and when to get involved.
The adoption of swarming can be challenging and may require a review and realignment of many of the organization’s practices to support new ways of working. The organizational change management practice can help to smooth the transition and ensure that lasting benefits are achieved by managing the human aspects of the change. Commonly encountered challenges include:
• justifying a perceived increase in the cost of work, which may occur if higher-skilled staff are involved earlier in the work stream
• switching from a performance review model based on individual contribution (which is often difficult to describe or quantify in a dynamic and self-organizing team) to team contribution, which can be monitored at the output or outcome level
• accepting the fluidity and high degree of collaboration required to form successful swarms
• ensuring that individual contributors do not disrupt discussion or dominate decision-making processes
• securing executive support to loosen or suspend adherence to rigid or prescriptive processes, funding, and policies.
These concerns may be reduced if the measurement and reporting of work (and workflows) shows that the benefits are greater than the perceived or actual costs (e.g. reduced completion times for development work).
Shift-left is a term that emerged from software testing circles but is relevant in other areas of IT and service management. Shift-left involves moving work closer to its source. The value-stream design principle states that highly interdependent tasks should be combined rather than performed as a sequence of specialized tasks. Shift-left is an integrated approach to improving the flow, efficiency, and effectiveness of work. It is used to move the delivery of work towards the optimum team or person with the aim of improving lead times, resolution times, customer satisfaction, and efficiency. In development environments, this means moving bug-fixing activities to the frontline of build and test teams earlier in the lifecycle. In support environments, repair or problem-solving activities can be moved from the higher-level technical teams to generalist frontline teams.
In the software development lifecycle, where the shift-left approach is more familiar, the first step is to gather requirements, which is followed by design, development, testing, and support. Applying shift-left to software development involves testing earlier in the lifecycle. Placing the testing software closer to the step for gathering requirements results in a reduction of the number of defects that are found in the production step. Consequently, this lowers the cost of resolving those defects by a significant factor. Research has shown that defects identified in production are far more expensive to fix than those identified in the design phase.
Shift-left is applicable in numerous management practices, including release management, deployment management, service validation and testing, service request management, and the service desk. It improves the quality of the work and the speed with which it is performed, and reduces the need for and cost of rework. It requires more knowledge and skills, because practitioners (or, in some cases, users) need to perform a broader scope of tasks. It can also lead to higher employee satisfaction (unless the extra tasks are too challenging, in which case there may be implications for recruitment). Comparing these benefits with the cost of having the right competencies determines whether an investment in shift-left is justified.
Shift-left is not limited to the service provider’s tasks. It can also be used to shift tasks to the service consumer, if they are willing and able to acquire the necessary competencies and to take responsibility for performing the tasks.
In software testing, where the term ‘shift-left’ originated, testing is not organized as a separate task that is performed after the software code has been developed. Rather, testing is performed as an integral part of each step of software development, beginning with testing the requirements and design. There is a shift from tester to testing. Testing is no longer performed by testing specialists but by multiple practitioners. The role of the testing specialist shifts to ensuring that others are able to perform the tests.
Similarly, information security can also be shifted left by embedding information security tasks into the daily work of development and operations. This contrasts with the traditional approach of giving these responsibilities to a specialized information security officer, who controls whether products and services conform to requirements. This is often referred to as DevSecOps.
Table 5.1 Building a shift-left approach
Step |
Activities |
Identify shift-left opportunities and goals |
Review data from a variety of sources, including: • customer and other stakeholder feedback, on time, cost, or quality metrics • delays in the flow of work due to handovers between teams • project interruptions for repetitive incident support • rework to fix bugs or defects, or other service quality concerns • staff frustration/feedback |
Clarify the costs and benefits of improvement |
Data is needed to support a business case and communicate expectations by, for example: • cost, time, quality, or experience metrics • results from a high-level cost–benefit analysis • identifying affected areas, including practices, processes, people, teams, structures, policies, training, recruitment, roles, and remuneration |
Set targets |
Define new targets, based on the type of work and the goals. For example: • resolution/fulfilment times • number of escalations/interruptions • number of deployments per day • customer or other stakeholder satisfaction ratings • number of audit failures |
Set up the improvement initiative |
Activities include: • deciding on actions and building them into a coherent strategy • planning the work required • working with key people to sell benefits and impact • communicating with employees and stakeholders • establishing rapid feedback channels |
Progress incrementally with feedback |
This step can include any of the four dimensions of service management. For example: • pilot specific tasks to leverage quick wins • periodically analyse quantitative or qualitative feedback, and adjust the shift-left approach • move a percentage or a number of tasks per month • benchmark current performance • retrain or redeploy staff • review changing roles and responsibilities • adopt new processes or work instructions • implement or change automation • review and modify contracts with partners and suppliers • update the service catalogue • define new measurements to track benefits |
Review outcomes |
On a periodic basis, or when the initiative ends, it is important to: • identify the achieved benefits, as well as the lessons learned • communicate the achieved benefits to employees, customers, and other stakeholders |
The same principles can be applied within other domains. For example:
• The division of tasks across first-line, second-line, and third-line support can be reorganized so that first-line service agents are capable of managing more challenging calls.
• Change approval judgements can be taken by knowledgeable developers rather than by a separate change advisory board.
The approach involves reviewing feedback and measurement to assess the current flow of work, followed by an adjustment to the ways in which the work is organized and delivered: moving testing closer to coding, automating where possible, and moving support activities closer to the customer.
In an organization that is suffering from poor customer feedback and frequent project interruptions, and which has demand for reduced service delivery resolution times, shift-left can address those areas of need. Table 5.1 outlines the key steps in building a shift-left approach.
When done well, a shift-left approach can lead to the following improvements:
• faster resolution times, leading to increased productivity for the consumer and, therefore, increased customer satisfaction
• a reduced number of interruptions and, therefore, an increase in completed projects
• a reduction in cost per incident, owing to the availability of a self-service interface that facilitates high-volume requests and offers relevant and accurate resolutions to common issues
• an increase in the variety of tasks that team members can perform, leading to improved employee satisfaction and retention.
The ITIL story: Why do we need to prioritize work?
|
Indu: I have been working on the online payment app for the bike rental service. However, there is another initiative I need to work on too. I need guidance from the business about which initiative I should prioritize. |
|
Henri: At present, business and regulatory demands exceed our capacity, impacting our ability to complete work; we simply cannot meet the current demand. The development of the online payment app is important, but Indu’s other initiative aligns our financial processes with changes to government regulations. This has to be prioritized to ensure the company does not breach regulatory requirements. |
|
Reni: We can hold a swarming session to try to find a solution to our capacity issue. Swarming is a great problem-solving technique, which gets a group of people together to collectively look at how a problem could be solved. |
|
Francis: As demand for the electric bike service continues to rise, I don’t have enough time to manage customer bookings and repair, maintain, and source new bikes for our fleet. The sooner we get the online payment app, the better. Customers will be able to self-serve, meaning they can make payments online, freeing up my capacity. |
|
Alice: My team in the car hire branch can accommodate the manual booking process for the bikes in the short term. This will help to free up Francis’s capacity until Indu can complete her work on the online payment app. However, my team can’t take this work on indefinitely, as this will more than likely impact on our ability to maintain the current high standard of service that our car hire customers currently receive. |
5.2 Commercial and sourcing considerations
The service provider has the option of creating the service components themselves, or obtaining them from partners or suppliers.
It is important to remember:
• A partner is an organization that provides products and services to consumers and works closely with its consumers to achieve common goals and objectives.
• A supplier is an organization that provides products and services to consumers but does not have goals or objectives in common with its consumers.
• ‘Vendor’ is a generic term used to describe any organization that sells a product or service to a customer. From the service consumer’s perspective, a vendor can either be a partner or a supplier, or it can have no direct service relationship with the service consumer. A vendor can also be a partner in some areas and a supplier in others. For example:
• A cloud services provider might supply infrastructure services to a consumer, but also partner with that consumer to implement tools that allow the consumer to maximize its consumption of those services.
• A customer service provider might supply skilled staff, tools, and other resources to a consumer, but also partner with that consumer to run a marketing campaign that highlights the quality of its customer care.
This section refers to ‘service components’ as a generic term that can cover people, tools, information, or any other type of resource that is used to create, deliver, or support products and services. It uses ‘organization’ to refer to the buyer or consumer of services, and ‘vendor’ to refer to the provider of services.
It is increasingly rare for organizations to create products and services using only their existing resources. As a result, organizations frequently have to decide whether to build or buy service components. These decisions should be made using data and evidence rather than emotion, rumour, or unconfirmed reports. In response to the growing complexity of such decision-making, many organizations, especially large enterprises, adopt formal sourcing strategies in which they consider factors such as:
• the organization’s current and future sourcing needs
• the current and estimated future costs of sourcing service components (often, the TCO is considered)
• the scarcity of resources in the ecosystem
• the influence of competition, suppliers, and customers within the ecosystem
• the barriers preventing new suppliers from emerging, and those preventing existing suppliers from winding down
• the costs and risks of sourcing components from an array of suppliers.
These considerations are used to form a sourcing strategy, along with associated plans and models on how to source each type of service component.
5.2.1 ‘Build vs buy’ considerations
It is important to recognize biases or pressures that arise from:
• familiarity with a prior version of a tool, or with the tool vendor’s products and services
• prior experience in using the product and service without recognizing the difference in context15
• a strong desire to work with new tools or skills simply because they are new
• aggressive sales tactics by the vendor
• pressures to reduce cost, often at the expense of quality.
Building service components using existing resources works better in contexts where:
• the service component heavily relies on knowledge of the organization and its business
• customer demand for personalized products, services, or experience is high
• the ecosystem is volatile or subject to rapid change (e.g. when customers face little or no cost when switching between competitors, the provider’s business model is rapidly changing, or the use of products or services is evolving16)
• service components lack mass-market adoption
• compliance to standards and policies is a high priority
• the service provider is undergoing rapid growth, either organically or through acquisitions or transformations, which can lead to inconsistent or frequently changing requirements.
Buying (or otherwise acquiring) service components from partners and suppliers works well when:
• in-house resources are scarce or highly utilized in other areas
• the skills or competencies needed to create, operate, and maintain the component are highly specialized and would take time to build (e.g. most organizations do not manufacture their own computing equipment)
• the processes to build products and services are immature and need to be developed and implemented
• components or services are highly commoditized
• the demand for service components is low or subject to significant fluctuation (e.g. seasonal demand or demand triggered by rare events)
• the service component is not core to the strategy, brand, or competitive differentiation of the service provider
• creating the service component is predictable and repetitive work
• the ecosystem is stable and generally not subject to volatility.
5.2.1.1 Commodification
As technology adoption increases, there is often a need for higher-order tools to manage technology more efficiently and effectively.17 For example:
• As the use of data centres became more prevalent and as computing power increased, virtualization tools emerged to manage virtual infrastructure.
• As the cost of computing and storage fell, and as virtualization tools matured, cloud computing models (infrastructure-as-a-service) emerged.
• As cloud computing models matured, other cloud-enabled platforms emerged, such as platforms-as-a-service, software-as-a-service, and more recently, functions-as-a-service.
This means that when considering whether to build or buy a service component, it is important to consider the current level of ‘commodification’ and ongoing industry trends to commodify that component.
5.2.1.2 Defining requirements for service components
When defining requirements, an organization should reflect the needs of all relevant stakeholders. As a result, requirements for service components should cover a broad range of topics and should not be limited to the functional needs that are articulated by users. Requirements that other stakeholders might address include:
• maintainability and supportability of the component
• geographic location of vendor resources
• cultural alignment between the organization and the vendor
• cost of service consumption (e.g. skills needed in-house, and financial outflow over time18)
• alignment with the organization’s business, technical, and information architecture
• vendor brand and public image
• interchangeability of vendors.
A common approach to defining requirements is to focus on the technical (functional and non-functional) features of a product or the technical quality of a service. However, it is frequently better to define requirements using outcomes. For example, a technical requirement to:
• ‘use email’ could be phrased as ‘communicate with users’ when described as an outcome requirement
• ‘provide check-out and check-in code’ could be phrased as ‘provide version control code’ when described as an outcome requirement.
A key challenge when defining requirements for service components is determining which features are essential and which are merely beneficial. For example, when defining requirements for:
• an incident management tool, an organization might consider integration with the corporate email system to be essential, and integration with SMS or text messaging systems to be beneficial
• a code repository tool, the requirement to ‘check out’ and ‘check in’ might be deemed essential, and the ability to send notifications when a code has been changed might be deemed beneficial.
Defining and prioritizing requirements is often a complex and emotionally charged exercise. The MoSCoW method is a simple prioritization technique for managing requirements. It relies on cooperation, and often negotiation, between all relevant stakeholders. As a result, it allows stakeholders to explicitly agree on priorities.
The MoSCoW acronym stands for:
• Must have The requirement is critical to success..
• Should have The requirement is important, but not necessary, for success.
• Could have The requirement is desirable, but not important or necessary.
• Won’t have The requirement is not necessary, appropriate, or is least-critical for success.
The method covers the requirements that will not be delivered. This is useful, as lists are commonly overpopulated with unnecessary requirements, such as reports that nobody needs. These requirements increase cost without adding value.
5.2.1.3 Selecting a suitable vendor
When looking for a vendor, organizations typically publish requirements for services or service components and invite potential partners and suppliers to respond. Depending on the needs or context, this exercise can be described as:
• A request for quote (RFQ) This technique is used when requirements have been defined and prioritized, and the organization needs information on:
• how vendors might meet requirements
• how much it might cost to meet the published requirements.
• A request for proposal (RFP) This technique is used when the problem or challenge statement has been clearly articulated, but the exact requirements or specifications of the service components are unclear or likely to change. Vendors need to provide recommendations or potential solutions, articulating benefits and outcomes as well as costs.
• A request for information (RFI) This technique is used when requirements are unclear or incomplete and external assistance is needed to refine or add requirements. RFIs are often followed by an RFQ or RFP.
In some cases, organizations can include their internal IT teams to participate as a vendor when conducting their search for a suitable vendor. This approach allows organizations to compare their internal IT with external organizations. However, where this occurs, it is important to:
• recognize the difference in relationships and ensure that colleagues are not treated as vendors
• understand that the internal IT operating model shares the same characteristics, strengths, weaknesses, opportunities, and threats as the wider organization
• balance the often-higher cost of in-house resources with the shared knowledge and goals that these resources have with the wider organization.
Ideally, a vendor will reflect the organization’s vision, mission, ethics, and principles, thus minimizing friction and tension between the two groups. In many cases, a vendor can be seen as an extension of the organization’s brand. It is critical that this idea is considered and remembered throughout the selection process.
The ITIL story: ‘Build vs buy’ considerations
|
Francis: We had a target that every bike should be safe, reliable, and comfortable. The bikes don’t have to be fast, but they need to be resilient. The electric bikes must have a good range and the charging stations have to be as standardized as possible. We considered building the bikes ourselves; however, the cost was prohibitive with lengthy timelines. We bought bikes off-the-shelf to both minimize costs and ensure the bikes would be ready for the pilot. I prepared each one before it was available for hire. We use off-the-shelf GPS units which have a very basic functionality but are easily sourced. However, we did not want to collect data using a third-party vendor’s free app in case the software is withdrawn or the vendor changes to a cost model. We plan to develop our own GPS mapping software instead. |
5.2.2 Sourcing models and options
A sourcing model is a component of an overall sourcing strategy. It describes topics such as:
• the conditions under which the organization will source service components or a specific type of component
• the roles and responsibilities of the vendor
• the degree of oversight that the organization requires over the vendor resources
• vendor assessment criteria, such as
• service levels, warranties, and guarantees
• geographic coverage
• time to deliver
• general management policies, such as:
• payment terms
• use of preferred suppliers and an exception management process
• use of RFI, RFQ, or RFP techniques
• standard terms and conditions when engaging with vendors.
• financial management policies, such as:
• capitalization of payments made for service components
• acceptable price ranges or pricing models
• tax reporting.
An organization may have many sourcing models, which reflect factors such as:
• line of business
• budget accountability
• type of service component (for instance, there may be a model to source contractors, another to source computing equipment, another to source infrastructure, etc.)
• reporting, auditing, and compliance requirements.
The selection of a particular sourcing model will reflect the organization’s framework for managing, reporting, auditing, and ensuring compliance with the organization’s vision, mission, ethics, and values across its service supply chain. Within each line of business, the differences in the models will have a significant impact on who is accountable and who is responsible for the work.
Common sourcing models include:
• Insourcing Where the organization’s existing resources are leveraged to create, deliver, and support service components
• Outsourcing Where the organization transfers the responsibility for the delivery of specific outputs, outcomes, functions, or entire products or services to a vendor; for instance:
• a local data centre vendor is used to provide computing and storage resources
• a recruitment agency is used either to source candidates for open roles or to find contractors.
Outsourcing models can be further subdivided based on the location of the vendors or their resources. This categorization might not apply when describing many technology vendors or providers of cloud computing services (infrastructure-as-a-service, software-as-a-service etc.) because the physical location of vendor resources is not always publicized. There are three categories of vendor location:
• Onshoring Vendors are in the same country.
• Nearshoring Vendors are located in a different country or continent, but there is a minimal difference in time zone (e.g. a UK-based organization using a vendor in continental Europe).
• Offshoring Vendors are located in a different country or continent, often several time zones away from the organization (e.g. a US-based organization using a vendor in India).
When outsourcing work, the organizational resources that remain after the work has been shifted to a vendor are referred to as the ‘retained organization’.
The ITIL story: Sourcing models and options
|
Francis: Although we could have bought the bikes cheaper online, I consciously procured the fleet from a local cycle shop. This sourcing model helps to ensure our targets are met. I can inspect our bikes for reliability and safety prior to purchasing. The shop offers same-day service, meaning that if demand continues to rise I can quickly expand our fleet. We will also have a service contract with the partner in the event of any malfunctions or safety issues. |
5.2.3 Outsourcing considerations
Many organizations decide to outsource work to reduce short-term operational costs, only to find that they have become constrained, they are unable to pivot business models, or they are spending more in the long term.
Outsourcing might also lead to higher costs over time, because the organization may have to bear higher costs to increase the scope of services and manage the quality of deliverables. It might also incur travel costs if work is sent offshore.
A holistic approach to outsourcing can help to reduce the likelihood of these negative impacts. It is important to consider:
• whether it is important to retain knowledge and skills that might potentially be sent offshore
• what the impacts are to enterprise risk management when sending work offshore: which risks are mitigated, worsened, or created as a result?
• whether the industry or scope of work supports outsourcing
• the cultural or language differences between the organization and the vendor
• whether and how much management overhead will be added when outsourcing work.
The ITIL story: Outsourcing considerations
|
Solmaz: We released a request for quote (RFQ) to seven vendors for the development of the GPS mapping software. |
|
Indu: The vendors who responded to our RFQ were locally and globally based. The location of the vendor was not a consideration in our competitive review process, and offshore vendors were not disadvantaged during our evaluation process. |
|
Henri: When outsourcing services such as software development, the location of our vendors isn’t as critical as it is for other services, as we can test and release code virtually. For other services such as on-site support, location is an obvious consideration. |
|
Indu: We did have to consider what additional management overhead and risks would be introduced by outsourcing the app development. It is important that we monitor these to make sure that the cost and timeframe of the development don’t exceed the expected levels. |
5.2.4 Service integration and management
Service integration and management refers to an approach whereby organizations manage and integrate multiple suppliers in a value stream. This is a new challenge for outsourced services and suppliers, where previously the end-to-end ownership and coordination of various third-party suppliers were managed by a single entity.
Service integration and management can be delivered using different models, although the basic concept, that the delivery of outsourced products and services is managed by a single entity, regardless of the number of vendors, remains the same.
5.2.4.1 Service integration and management models
There are four main models in this area (Figure 5.2). Organizations must consider the best model for their circumstances in order to transition to a more coordinated service–supplier landscape:
• Retained service integration Where the retained organization manages all vendors and coordinates the service integration and management function itself.
• Single provider Where the vendor provides all services as well as the service integration and management function.
• Service guardian Where a vendor provides the service integration and management function, and one or more delivery functions, in addition to managing other vendors.
• Service integration as a service Where a vendor provides the service integration and management function and manages all the other suppliers, even though the vendor does not deliver any services to the organization.
Service integration and management is increasing in importance, owing to a variety of factors:
• Vendors increasingly specialize in niche areas, which has led to an increased number of vendors working with a single typical organization.
• The commodification of some types of service component means that vendors can be regularly replaced by other vendors to leverage a better pricing or service experience.
• The increasing complexity of technology products and services means using multiple vendors to support the organization.
When an organization chooses a service integration and management approach, it should regard the approach as a strategic imperative and tender service integration and management contracts separately from individual vendor contracts. A clear organizational structure, with an appropriate governance and management model, is also required.
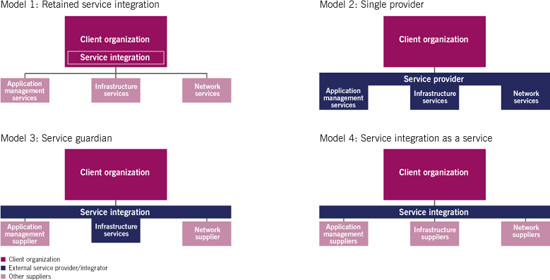
Figure 5.2 Service integration models
5.2.4.2 Service integration and management considerations
When deciding whether to take a service integration and management approach, it is important to consider:
• whether the organization is mature and capable enough to run or work within such a model
• the metrics that are appropriate to measure and incentivize:
• quality of service delivery
• quality of outcomes that require coordination and collaboration across multiple vendors
• transparency, coordination, and collaboration between vendors and the service integration and management function
• how the use of multiple vendors changes the design and measurement of service level agreements
• how service level agreements will influence behaviours among different vendors
• how vendors will be incentivized to align with organizational outcomes (or penalized if they choose not to)
• which vendor selection criteria are appropriate to this approach
• whether services will be delivered by a single supplier or require collaboration between vendors
• how service management practices will change as a result of service integration and management, including:
• knowledge management
• incident management
• service desk
• problem management
• change management
• service request management.
The ITIL story: Service integration and management
|
Solmaz: Axle works with a multitude of partners around the world. Some services are provided by a global partner; for example, our IT network infrastructure. Others, such as our electric bike breakdown retrieval service, are specific to our Montreux branch and our bike hire service. It is our responsibility to ensure that the work done by different third parties is coordinated and integrated effectively to support our products and services. |
|
Reni: One of the services we will offer with our rented bikes is a free pick-up if a bike breaks down. In order for this to work effectively, we need to coordinate work across our IT network (the provider of which is based in the US), our support centre (which dispatches calls from its office in India), our breakdown team in Montreux (which picks these calls up), and our local tow-truck partner (who will collect the bikes). Each of these organizations is crucial for the service to work effectively. We need to ensure that any differences in our suppliers’ locations, language, timeframes, and ways of working are properly managed so that things can run smoothly. |
|
Solmaz: At the moment, Axle is responsible for coordinating our suppliers as a ‘retained service integrator’. As the service grows and expands in other locations, we will revisit our service integration model to make sure it is still fit for purpose. |
Organizations are rarely able to balance capacity and demand, leading to queues or backlogs of work, which increases the risk of unhappy customers, users, and other stakeholders. In order to mitigate this risk, organizations have a wide variety of techniques to either manage demand or prioritize the various types of demand.
Organizations should be careful when using these techniques and apply the guiding principle of think and work holistically to assess the impact of these techniques on other parts of the organization, on customers, on stakeholders, and even on the flow of work from demand to value.
Organizations may also turn to external partners and suppliers to source additional capacity or capabilities, or even to transfer responsibilities for the delivery of outputs, outcomes, functions, or entire services. As the number of partners and suppliers increases, so the management overhead to direct and coordinate external activities can increase dramatically, often requiring dedicated resources to integrate, manage, and align external providers with the organization’s products and services.