
A character set, also known as an “encoding,” is the set of bit patterns used to represent a set of characters. ASCII is one popular encoding. EBCDIC is a family of character sets with regional variations used on IBM mainframes. Unicode is a third encoding. Before describing the character sets available to Java, we need to explain “big-endian” and “little-endian” storage conventions.
Endian-ness refers to the order in memory in which bytes are stored for a multi-byte quantity. The term is a whimsical reference to the fable Gulliver's Travels, in which Jonathan Swift described a war between the Big-Endians and the Little-Endians, whose only difference was in where to crack open a hard-boiled egg. It was popularized in the famous paper, “On Holy Wars and a Plea for Peace” by Danny Cohen, USC/ISI IEN 137, dated April 1, 1980. It's a cool paper, well worth reading, and you can easily find it on the web if you search.
All modern computer architectures are byte-addressable, meaning every byte of main memory has a unique address. If you store a multibyte datum in several successive addresses, should the most significant byte of the datum go at the highest address or the lowest address? Big-endian means that the most significant byte of an integer is stored at the lowest address, and the least significant byte at the highest address (the big end comes first).
In other words, if you have an int value of 0x11223344, the four bytes:
0x11, 0x22, 0x33, 0x44
will be laid out in memory as follows on a big-endian system:
base address +0: 0x11
base address +1: 0x22
base address +2: 0x33
base address +3: 0x44
The SPARC, Motorola 68K, and the IBM 390 series are all big-endian architectures. Big-endian has the advantage of telling if a number is positive or negative by just looking at the first byte. It's also the way we read and write numbers in Western cultures in both word and digit form.
Little-endian contrasts with this by storing the least significant byte of an integer at the lowest address, and the highest byte at the highest address (the little end comes first). The number is “the other way up.” On a little-endian system the same four bytes will be arranged in memory as follows:
base address +0: 0x44
base address +1: 0x33
base address +2: 0x22
base address +3: 0x11
The Intel x86 is a little-endian architecture, as was the DEC VAX. Little-endian has the advantage of telling if a number is odd or even by just looking at the first byte (not all that frequent a need).
Java uses big-endian ordering when it processes data, regardless of the platform it is on. Big-endian is also known as “network byte order” because the fundamental Internet TCP/IP standard is defined to use big-endian. The only time endianness is an issue is when you are trying to read data that was written by a non-Java program on a PC. Then you have to remember to swap multibyte values on the way in, or wrap a buffer around an array, as explained shortly.
Table 18-1 shows some popular encodings. Every implementation of the Java platform from JDK 1.4 on is required to support these standard charsets. For character sets that include multibyte characters, endianness is an issue.
Table 18-1. Required encodings
|
Name |
Size |
Description |
|---|---|---|
|
US-ASCII |
7 bits |
The American Standard Code for Information Interchange |
|
ISO-8859-1 |
8 bits |
The problem with ASCII is that it is the American Standard Code, and has no provision for accented characters. ISO-8859-1 contains the 7-bit ASCII character set, and the eighth bit is used to represent a variety of European accented and national characters. ISO 8859-1 is shown in an appendix at the end of this text. |
|
UTF-8 |
8-24 bits |
A UCS Transformation Format is an interim code that allows systems to operate with both ASCII and Unicode. “UCS” means Universal Character Set. In UTF-8, a character is either 1, 2, or 3 bytes long. The first few bits of a UTF character identify how long it is.
UTF is a hack best avoided if possible. It complicates code quite a bit when you can no longer rely on all characters being the same size. However, UTF offers the benefit of backward compatibility with existing ASCII-based data, and forward compatibility with Unicode data. There are several variations of UTF to accommodate byte order. |
|
UTF-16BE |
16 bits |
Sixteen-bit UCS Transformation Format, big-endian byte order. |
|
UTF-16LE |
16 bits |
Sixteen-bit UCS Transformation Format, little-endian byte order. |
|
UTF-16 |
16 bits |
Sixteen-bit UCS Transformation Format, byte order identified by an optional byte-order mark. When writing out data, it uses big-endian byte order and writes a big-endian byte-order mark at the beginning. |
You gain the use of one of these encodings by passing a string containing the desired encoding as an argument to the constructor of OutputStreamWriter (for output) or InputStreamReader (for input). Recall from the previous chapter that these two classes provide a bridge between the world of 8-bit characters and the world of 16-bit characters.
What actually happens is that the bit patterns you have in your program are potentially changed in length and content, according to the encoding you specify. If you are reading in ISO 8859 single-byte characters, and mention that as the encoding, each one will be expanded to two bytes as it is read into Java Unicode characters.
Here's an example program that writes character values using an explicit encoding.
// Write chars using UTF-Big Endian encoding
import java.io.*;
import java.util.*;
public class Codeset {
public static void main (String args[]) throws Exception {
FileOutputStream fos = new FileOutputStream("results.txt");
OutputStreamWriter osw = new OutputStreamWriter(fos, "utf-16be");
char data[] = { 0x11, 0x22, 0x33, 0x44, 0x55, 0x66, 0x77,
0x88, 0x99, 0xAA, 0xBB, 0xCC, 0xDD, 0xEE };
osw.write( data );
osw.close();
}
}
If you run this program and try “utf-16be” and other character sets, you will see results as shown in Table 18-2. Appendix C shows the 8859-1, ASCII, and EBCDIC character sets.
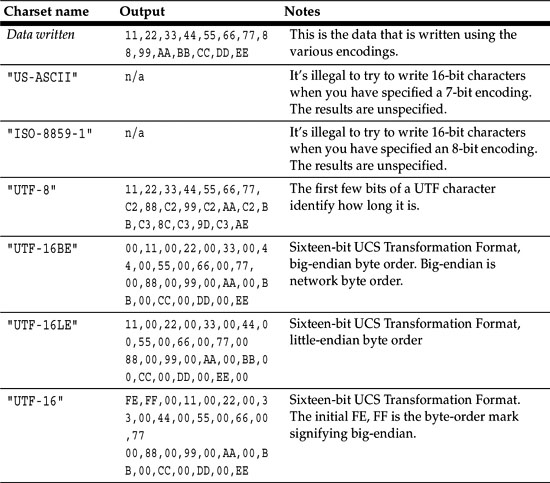
Consult the release documentation for your implementation to see if any other charsets are supported.
Table 18-3 lists some popular encodings that may be supported on your system. There are literally dozens and dozens of other encodings.
Table 18-3. Other popular encodings
|
Name |
Size |
Description |
Code for letter 'A' |
|---|---|---|---|
|
windows-1252 |
8 bits |
The default file.encoding property for most of Windows is “cp1252.” Microsoft diverged from the standard ISO 8859-1 Latin-1 character set (which is shown in an appendix at the end of this book) by changing 27 characters in the range 0x80 to 0x9f, and called the result Code Page 1252. Complicating the situation, under Windows the shell uses a different encoding set to the rest of the system. It uses an older encoding for compatibility with MS-DOS. The shell uses either code page cp850 or cp437. To find out what code page is being used by the command shell, execute the DOS command “chcp” and see what it returns. |
0x41 |
|
Unicode |
16 bits |
The problem with 8859_1 is that it can represent only 256 distinct characters. That's barely enough for all the accented and diacritical characters used in western Europe, let alone the many alphabets used around the rest of the world. Unicode is a 16-bit character set developed to solve this problem by allowing for 65,536 different characters. Strings in Java are made up of Unicode characters. |
hex 0041 |
|
EBCDIC |
8 bits |
The Extended Binary Coded Decimal Interchange Code is an 8-bit code used on IBM mainframes instead of ASCII. It was originally intended to simplify conversion from 12 bit punch card codes to 8-bit internal codes. As a result, it has some horrible properties, like the letters not being contiguous in the character set. EBCDIC is really a family of related character sets with country-specific variations. An EBCDIC chart is shown in Appendix C |
0xC1 |
|
ISO/IEC 10646 |
32 bits |
This is the Universal Character Set. There are two forms: UCS-2 and UCS-4. UCS-2 is a 2-byte encoding, and UCS-4 uses a 4-byte per-character encoding. This enormous encoding space is divided into 64K “planes” of 64K characters each. The ISO people want everyone to think of Unicode as just a shorthand way of referring to Plane Zero of the complete 4-byte ISO/IEC 10646 encoding space. Unicode, in other words, is UCS-2, which is a subset of the full UCS-4. They call this the “Basic Multilingual Plane” or BMP. |
0x00000041 |
The character sets only affect character I/O. You cannot apply an encoding to do automatic endian-swapping of binary data. But if you are using Java to read little-endian binary data, i.e., binary data that was written by a native program on a PC, you need to do this byte-swapping. We use the buffer class introduced in JDK 1.4. In Java 1.4, you can fill a buffer directly from a file, then pull values out of it with your choice of endian-order. To byte-swap a buffer, use code like this:
FileInputStream fis = new FileInputStream("ints.bin");
FileChannel c = fis.getChannel();
ByteBuffer bb = ByteBuffer.allocate(40);
int num = c.read(bb);
bb.rewind();
bb.order(ByteOrder.LITTLE_ENDIAN);
Float f1 = bb.getFloat();