
Chapter Nine. Automate Processes and Deliver Fast
Don’t make anything until it is needed; then make it very quickly.
James P. Womack and Daniel T. Jones1
1. James P. Womack and Daniel T. Jones, Lean Thinking: Banish Waste and Create Wealth in Your Corporation (Simon & Schuster, 1996), p. 71.
In the previous chapter, Plan for Change and Mass-Customize, and in Chapter 3, The Integration Factory, we introduced process automation and fast delivery by showing how assembly lines can be used to mass-customize integration components, and how decoupling systems allows organizations to change and grow with more agility. Across the entire landscape and life cycle of integration, there are significant opportunities for eliminating much waste and delivering fast by using a mantra we’ll describe as “Use the computer!”
What do we mean by this? Doesn’t all integration, by definition, use the computer? While integration “code” certainly runs on computers to integrate data, applications, or systems, the design, development, testing, deployment, and change of this integration “code” are usually done manually by visually inspecting code, data, metadata, and documentation. Human eyeballs examine flat files, database tables, message structures, and interface definitions to understand the structure, content, and semantics of data. Knowledgeable developers laboriously trace the dependencies between data models, business processes, services, and applications to understand how integration solutions should be designed or changed. Administrators collect lists of objects that need to be moved from development to test to production, manually ensuring that these lists contain the proper dependent objects and that impact analysis was validated properly.
As the integration hairball grows in an enterprise, the complexity escalates beyond what humans can reasonably be expected to efficiently and effectively maintain. The vast majority of organizations are using computers simply as a code-editing interface, generating individual integration artifacts and thereby increasing the size of the hairball without improving their ability to manage it more effectively going forward.
So when we say, “Use the computer!” we mean harness computer power not just for business systems, but also for integration systems. And also not just to develop integration code, but to automate the flow of materials and flow of information in the development process. In its ultimate form this transforms manual custom development into rapid implementation of self-service integrated solutions.
The chapter closes with a case study from Wells Fargo Bank that illustrates how computers can be used to automate and speed up a business process that was traditionally viewed as manual and paper-intensive. The Lean principles that were used to generate the impressive benefits and continuous improvements for the bank are the same ones that can be applied to the integration process under the direction of an Integration Competency Center.
Pitfalls of Automation—Building “Stuff” Faster
Automation can be an extremely powerful tool, helping people accomplish repetitive tasks more quickly. However, an important Lean principle that we discussed in depth in Chapter 7 is to ensure that we are optimizing the whole end-to-end process, rather than optimizing individual parts of the process that may not add any value to the end-to-end process.
For instance, there is little or no benefit to making an activity that is not on the critical path of a project more efficient. To use a restaurant example, it would not make sense to invest in a handheld device for waiters to transmit orders wirelessly to the kitchen if the food preparation step is the bottleneck. In fact, this could make the problem worse by giving customers the expectation of rapid delivery while the electronic order simply sits in a queue. By the same token, providing software developers with tools to more rapidly generate Web service interfaces could make problems worse if the primary reason for slow implementation times is integration testing; more Web service interfaces could actually lengthen the integration testing time frame.
There are many examples of exciting software technologies that IT can use to more efficiently meet the needs of the business. These software solutions automate much of the work that IT departments have traditionally done using low-level tools, allowing people to quickly craft new solutions to a variety of different problems. Did you ever notice how most vendors demo their products? Most demos (and therefore most vendor tool requirements) seem to be driven by the creation of new things, not the maintenance of existing complex things in the context of their real-world environment. Do you need nice-looking reports with drill-down capabilities? Easy. Drag and drop using this nifty business intelligence tool, and within seconds you’ve got a good-looking report. Do you need a new service? Easy, use the service creation environment and at the push of a button craft another that meets the requirements.
It’s so easy. Perhaps it’s too easy.
The reality is that IT organizations spend five to ten times the cost of the original development effort on integrating and maintaining components, so the true objective should be to “build for change.” Let’s look at some of these examples in more detail.
SOA—Generating the Next-Generation Hairball More Rapidly?
Taking an SOA approach when creating composite applications or other business solutions solves a raft of historical problems. The holy grail of software engineering has been to compose applications out of easily reusable building blocks that can be modified, mixed, and matched quickly. “Business agility” is touted as the key benefit, and certainly SOA can be an enabler to achieving this goal, but it can also be a detractor.
Besides the oft-cited problem of difficulties in achieving business/IT alignment, early experiences of organizations that adopted SOA showed that a newer, more modern service-oriented hairball was growing, and the rate of growth was far faster than that of the original hairball that they hoped SOA would eradicate.
Furthermore, because one of the benefits of SOA is decoupling the services from the underlying applications, the hairball is more abstract and harder to detangle. The registries and tools in place have been constructed primarily to assist service consumers, the people seeing the SOA iceberg above the waterline. Tools to assist the service providers in maintaining the growing hairball below the waterline are mostly missing. For instance, if data semantics in a source application change, how do the service providers know what services are affected? The explosion in Java code development for data access within these services and the abstraction from the service interfaces result in more complex dependencies that are poorly understood and more difficult to detangle than before. Reducing point-to-point interfaces is a desirable goal, but it needs to be done with an understanding of the end-to-end problems over the long term; otherwise a new problem develops that marginalizes the benefits.
Were Business Intelligence Environments Better before Drag and Drop?
With business intelligence (BI) tools, all too quickly the user community creates an enormous bucket of reports with tremendous duplication and waste. This report morass makes it challenging for users to find what they need. Certainly some great examples with high information content and good layout exist, but it is hard for users to find the gems amid the rocks.
Making it easy to create reports should be a good thing. But there’s something to be said for the days when it was so difficult to create an enterprise information management system that requirements and business thinking had to be deeply understood before solutions were constructed. In the most successful examples, actual “analytic applications” were built, rather than buckets of reports. Certainly, those analytic applications were difficult to construct and modify, but deep business understanding was built into them, effectively incorporating what was inside the heads of the most valuable SMEs, and they were constructed in such a way that other business users became nearly as knowledgeable. Commercial examples of these applications include budgeting and forecasting applications, anti-money-laundering applications, and fraud detection applications.
Industry Data Models—Too Much of a Good Thing?
Here’s a different example where “building faster” may turn out to have short-term benefits but higher long-term costs. Some organizations buy industry data models to jump-start their enterprise data model initiative. The vendors of these models sell the inbuilt domain expertise and how they’ve considered so many details and industry vertical permutations through their vast experience. These vendors also humbly state that they can’t fully know your business, so you should expect to have to change or extend perhaps 40 percent of the model.
What those vendors don’t say is that their models actually contain perhaps 400 to 600 percent of the requirements that you need. In other words, you need to learn how to use the pieces of their models that are relevant to your business, modify things that they missed, and hide the rest. This means you need to navigate through and understand an overly complex model to find the components you need, strip away what is not of interest, and customize and extend the parts you do need.
Then comes the hard part. How do you actually use the model to meet the needs of your business? That is typically something that you have to discover for yourself, and it is where the majority of time is spent. Because you didn’t go through the effort of understanding the requirements for the model in the first place, you’re missing the understanding of how the business can and should use the model.
The point of this example is that automation or purchased content needs to be evaluated within the context of the big-picture end-to-end process and life cycle. Buying a solution to part of a problem may solve that problem but create a more expensive problem or not provide as much value as originally anticipated.
Once again, the point is not to optimize a part if it results in sub-optimizing the whole. The goal is to optimize the whole by having a clear understanding of the end-to-end value chain. We clearly want to achieve agile and iterative (small batch size) changes, and powerful tools can help, but they need to be harnessed and governed in a way that supports the entire value chain from the perspective of the end customer.
Delivering Fast
There is an old project manager saying that goes “Do you want it fast, good, or cheap? Pick any two.” That trade-off may be true for custom point solutions, but it is not true for integration development if you approach it as a repeatable process. Some organizations have reduced their integration costs by a factor of ten while also delivering rapidly and with consistently high quality. The secret to achieving this amazing result is to focus on time.
A funny thing happens when you speed up the development of integrations using sustainable Lean thinking—costs drop and quality improves. This may seem counterintuitive since speed is often equated with throwing more people at a problem to get it done faster, which drives up cost. Another common misperception is that speed means rushing, which causes mistakes and reduces quality, thereby driving up cost because of errors and rework. If you are stuck in a paradigm where each integration is a custom solution and your processes are reliant on manual labor, the result will most likely be higher defects and increased downstream costs. Time-based competition—or using time to differentiate your capabilities—can fight the old paradigm.
Time-based competition2 (TBC) is a time-compressing operational strategy. Time is emphasized throughout organizational processes as the main aspect of accomplishing and upholding a competitive edge. The goal is to compress time cycles. As they are reduced, productivity increases and resource potential is released.
2. George Stalk, “Time—The Next Source of Competitive Advantage,” Harvard Business Review, no. 4 (July–August 1988).
The best way to speed up development of integrations is to eliminate wasted activities, reduce delays, and reuse common components. Here are few additional TBC techniques that can improve delivery times.
First, take integration development off the critical path for projects. Each project has a critical path or bottleneck that is the limiting factor in how quickly the end-to-end project can be completed. Integration activities are often on the critical path because of the complexities and uncertainties about how all the pieces work together. This doesn’t need to be the case if you clearly understand the root cause of problems that tend to put integration activities on the critical path, and tackle them head-on. For example, data quality issues between disparate systems are a common cause of significant delays during integration testing. Not understanding the dependencies and relationships between systems leads to delays in the project. The next section will discuss some approaches to solving these issues, helping to take integration development off the critical path for projects.
Second, implement a variable staffing model and develop processes to rapidly ramp up new staff. Supply and demand mismatch is another common root cause of delays. For example, if you have a fixed number of integration staff to support new project development, some of them may be idle at times when the demand is low, while at other times demand may peak at well above the planned staffing level. If you have 10 staff members and the demand jumps to 15 for a period of several months, there are only a few options available:
1. Get all the work done with 10 people by cutting some corners and reducing quality. This is not sustainable since reduced quality will come back to haunt you as increased maintenance costs or reduced future flexibility.
2. Make the 10 people work overtime and weekends. This is not sustainable since you could end up “burning out” the staff.
3. Delay some of the projects until demand drops. This is not sustainable since you are in fact chasing away your customers (telling them that you can help them in two months when they need help now is the same as not helping them).
4. Bring on additional staff. This is the only sustainable model, but only if you can ramp up the staff quickly and then ramp them down when the volume of work subsides. The keys to making this happen include having well-defined standard processes, good documentation, and a long-term relationship with consulting firms or some other pool of resources.
Third, focus on driving down end-to-end project cycle time and not on optimizing each activity. This may seem counterintuitive, but optimizing the whole requires sub-optimizing the parts. For example, the task of creating user documentation is most efficient when all the software is developed. However, this can significantly delay the overall project if the documentation is prepared in a sequential manner. The overall project timeline can be reduced if the documentation effort is started early (even in the requirements phase), despite the fact that some of it will need to be rewritten to reflect the changes that take place in the design and development phases. But if all functional groups that support a project are motivated to reduce the total cycle time rather than focusing on the efficiency of their teams, the overall improvements can be very significant.
Automating Processes—Using the Computer to Make Complexity Manageable
Rather than simply “build faster,” you can harness the power of the computer to eliminate the real bottlenecks that slow projects up. Start by identifying the slowness and waste that result from excessive complexity, and use the computer to automate the tedious, error-prone, and laborious aspects of integration. Previous chapters discussed how mass customization and planning for change automate common development processes, creating assembly lines that leverage the patterns to eliminate development waste and variation in integrations.
But there are more opportunities for waste elimination. Our investigations into dozens of companies’ different integration projects revealed that significant time is spent understanding and documenting data, applications, and systems, as well as understanding and documenting dependencies and version histories, because so many of these tasks are manual efforts. If ICCs had the full power of the computer to search, analyze, and drive integration life cycles to assist people in an automated fashion, developers, architects, and analysts could be significantly more productive in solving integration problems.
Using Data Profiling to Eliminate Project Waste
Integration project overruns frequently occur because data issues surface late in the project cycle. Rather than being uncovered as early as possible in the planning and estimation stages of integration projects, data issues usually surface once testing is performed in earnest, well down the project path. At this point, changes are expensive and project timelines are at risk.
In most integration projects, manual examination of data is done in order to understand the kinds of code and logic required to deliver or integrate the data. Frequently this kind of manual examination doesn’t find many of the issues because the process is haphazard, looks only at sandbox data, or is dependent upon the experience and approach of the individual integration developer. Additionally, the developers performing these tests are not the analysts who are most knowledgeable about the data. In many cases, the integration developers would not notice a problem with the data if they saw one because they do not have the business and semantic knowledge of the data that a data analyst on the business side has.
Data profiling is a useful software utility that “uses the computer” to process vast quantities of data, finding and documenting the patterns and anomalies so that analysts and integration developers can work together to construct the best logic to deal with the data. It is good to understand where data is missing, inconsistent, or wrong as early in a project as possible in order to prevent rework and even longer delays later. Additionally, documenting the semantic meaning of data is helpful, not just for the task at hand, but for future analysts or developers who will need to make changes to integrations when the business changes down the road.
Understanding the characteristics of information in ERP systems, mainframes, message queues, database applications, complex flat files, and XML documents is a critical component of integrating this information with other information. Because of the incredibly vast quantity of information out there, cataloging this knowledge for current and future consumption is time well spent.
To really harness the power of data profiling, tagging and categorizing data are also important. Constructing a business glossary that provides a common language between business and IT can help to solve communication issues between these teams. This also helps search and find operations to organize and classify the data within the integration systems for better management and governance. Data-profiling attributes are simply additional metadata attached to data structures.
Testing Automation
The process of developing test plans and test cases is an area where QA developers have typically tested systems manually. The most mature ICCs create regression test harnesses and use the computer to test the before and after images of data to ensure that integration logic is operating as designed.
In scheduled or batch integration scenarios, tests are built that sum or analyze the target data and compare that to the source data to ensure that the number of records, the sum of the results, and other data characteristics tie together properly. Comparing large data sets and summing and aggregating large amounts of information are things that computers do really well. Unfortunately, we see developers doing all too much manual querying of source and target data during testing phases. These queries are typically not put into an automated test harness for continual testing, which is yet another waste.
Similarly, with real-time integration, testing typically doesn’t cover all the different scenarios that can occur because data profiling wasn’t used to uncover many of the different potential variants and outliers that can (and inevitably will) occur. Using the computer (through data profiling) to help identify and construct the test cases is a powerful way to ensure that test coverage is sufficient to deliver the desired integration quality.
Deployment and Change Management Automation
Other areas where automation can reduce manual activities are change management and integration deployment. Release management of changes to production systems often requires understanding a highly complex combination of dependencies that can be difficult to manage, slow, and error-prone if done manually. In particular, many times the person doing the deployment is different from the person doing the development or the testing, and therefore information often gets lost in translation.
The goal is actually to catch dependency problems long before deployments to other systems take place. For instance, in cases where a new integration requires a minor change to a shared object, it is optimal to know the impact of this change on all other places this shared object is used. You don’t want to wait until the object is promoted to production to learn about the dependency and detailed impact of the change. If metadata is used properly, “the computer” can figure this out and visualize it for the developer and administrator early in the process.
Figure 9.1 shows the realities of change management in a retail organization. Some retailers generate over 50 percent of their sales volume during the last two months of the year, between Thanksgiving and Christmas. Yet this graph shows that the organization’s systems suffered half as many errors during November and December (the first two bars on the chart) as they did during the other ten months. The reason for this is that during times of system stress, end of year, or other critical business periods, changes to operational systems are drastically reduced. The fact that few changes were allowed from mid-October through the end of the year meant that the systems would run with far fewer outages than normal. Seemingly, the only good change is no change.
Figure 9.1 Integration problem tickets closed by month
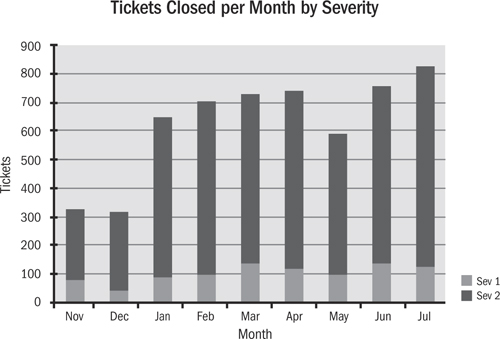
Certainly, outages are not just the result of problems with the deployment and change management processes. Many times they are caused by inadequate testing of code or other issues. Introducing a repeatable automated process that reduces the chances for the introduction of human error means that files or pieces of the release don’t get lost in translation.
Life-Cycle Automation
One of the innovative uses of automation is noticing that what is usually thought to be unstructured information actually has a structure. For instance, design specifications and requirements documents typically follow a common structure or template. Tools are available that allow the relatively simple ability to translate .pdf, Word, Excel, email, and other “semistructured” documents into structured metamodels for import into a metadata repository. (In the Wells Fargo case study at the end of this chapter, similar automation was used to translate “unstructured” business documents into automatically consumable digital documents in an analogous fashion.) Bringing project documentation into the metadata repository and tying it to the actual integration implementation artifacts is a powerful way to create “live” documentation for your integration environment.
Normally, all of these unstructured documents are stored on file servers, in SharePoint, or somewhere away from the actual integration artifacts. Developers probably don’t spend as much time as they should on documentation for this very reason—the documentation is disconnected from the actual artifacts, so the chances that someone will find and read the relevant document in a timely manner are pretty low. Developers know this. If documentation is directly connected with the artifacts of the integration system, more time would be spent on quality documentation, thereby cutting waste for the inevitable future changes to come.
Understanding the requirements, specifications, test plans, and other documentation that surrounds the integration artifacts greatly speeds the time to change those artifacts when the business changes. This is a critical aspect of the Integration Factory. Making the necessary changes to integration interfaces, services, mappings, and so on is a constant challenge because of the complexity of the logic, the usual lack of up-to-date documentation, and the lack of anything to link metadata across different vendor products to create an end-to-end view. Having an active metadata repository that links the data models, the integration logic, and the applications models to show the impact and lineage of integration points is a critical part of using the computer to change what is otherwise a wasteful, manual, error-prone process into a task that can be done quickly and accurately. We will talk more about this in Chapter 13 on Metadata Management.
Furthermore, being able to bring together the business and IT is critical for making integration projects of all types work more effectively. It is a truism to say that the business knows the data, but IT is responsible for the systems behind the data. They must work together to be successful and to truly support the concept of the Integration Factory.
Case Study: Automating Processes at Wells Fargo Home Mortgage
This case study concerns Wells Fargo Home Mortgage’s Post Closing business group and how a new imaging and IT automation initiative implemented in 2002 improved processes.
The role of Post Closing is to make Wells Fargo Home Mortgage loans salable to investors, serviceable with high-quality data for customers, and insurable with risk partners. This is a critical aspect of the mortgage business and incredibly complex when considering the regulatory rules to be followed, management of financial risks, handling of paper, and sustained collaboration with multiple organizations. Of course, this all needs to happen while making the process look seamless to customers, keeping their loan and personal information secure, and retrieving it quickly when needed.
Take a moment to consider the processing of paper alone. In 2002 the Post Closing group was handling 2 million mortgages per year. Each case file contained dozens of documents, typically totaling 100 to 150 individual pieces of paper. If stacked one sheet on top of the next, one year’s worth of the paper required in processing would stack 23 miles high or, laid end-to-end, reach around the world 1½ times, or fill 95 offices (wall to wall and floor to ceiling of a 160-square-foot room). Each year the required paperwork grew larger, and all the paper needed to be copied, distributed, inventoried, archived, and then remain retrievable for years.
The Business Challenge
In 2001 the Post Closing group identified a problem: Mortgage volume was increasing rapidly. While growing the business was desirable, the core processes were heavily paper-based and highly manual and did not scale well. The group consisted of around 1,300 staff, and it was not practical to continue expanding into new buildings each year to house all the people and paper resulting from acquisitions and the refinancing boom that was going on at the time.
The manual processes were also expensive and slow and had increased potential for human error. The average cost per loan (CPL) was not decreasing with increased volumes as would be expected, and the cycle times were too long. One of the key metrics related to processing efficiency and business risk is the number of uninsured loans after 60 days, that is, the number of loans that cannot be insured by FHA or packaged and sold as securities because a required closing document was missing or a post-closing activity was outstanding. At the end of 2001, there were more than 19,000 mortgages in the “Uninsured >60 days” category.
The Solution
A decision was made to invest in technology that would enable the elimination of paper and that would automate many of the manual loan review processes. From an architectural perspective, there were several key elements that enabled the outcome (see the second part of this case study in Chapter 15).
The first was to turn all the paper into information. It wasn’t sufficient to simply make an electronic image of the paper documents; all the key information on the documents also needed to be converted to structured data that would allow a computer to process it. This not only required a large investment in imaging technology, but it was a paradigm shift in how people would have to work.
The decision to use a straight-through processing (STP) approach was contrary to the prevailing practice in the industry. The question was whether to make the workflow capability the heart of the system or make the process state engine the heart of the system and have it process everything that didn’t require human attention. The common practice at the time was to mimic paper-handling processes and keep people in control of each step, gradually automating selected activities over time. The program leaders believed that STP would be more effective, but it was not an easy decision. In the end, the team moved forward with this approach and developed a customized process state engine.
Another key architectural principle was that each business process include a mechanism for handling exceptions. The Post Closing business was very focused on reducing costs and increasing throughput. The team identified the easiest and highest-volume transactions first. This meant that nonautomated steps still needed to be handled by a person in conjunction with performance support tools.
Having a manual work queue was also useful for handling unplanned exceptions. If a message or document arrived that the system couldn’t process, rather than send an error message back, it would place it in a work queue for a person to review. This is a powerful technique in an environment of loosely coupled systems where it is virtually impossible to anticipate and/or test every possible permutation and combination of process states. Furthermore, in cases where the requirements or design was not complete, the exception messages tended to fill up the manual work queues quickly, making them visible and allowing the team to resolve the issues.
Perhaps surprisingly, there was little resistance from staff to the business process changes. As soon as people saw what was possible with the new solution, they embraced the changes and other innovations began to surface throughout the organization. The biggest factors that created an appetite for change included the frustrations of spending a great deal of time chasing paper files, managing a high ratio of temporary staff, and consistently feeling behind in the process.
The Results
The results were impressive. The new process
• Significantly reduced the cost of operations
• Lowered the business risks and the seasonal cycle time and inventory level variation
• Dramatically improved process cycle times, making them more consistent
• Thrilled customers with the rapid turnaround and responsive support
• Improved staff morale and the ability to perform more valued activities
• Built upon Wells Fargo’s reputation among government groups as a leader in industry improvements
The CPL was reduced from $61 in early 2002 to $46 in early 2004, equating to a 25 percent reduction. This is extremely impressive for any organization that has the size, scale, and complexity of the Post Closing group. And if $15 per loan doesn’t sound like a lot of money, just multiply it by 2 million loans per year.
An example of risk reduction and process improvement is the change in quality and cycle time of insuring government loans. FHA loans must be reviewed by HUD to ensure that they are complete and accurate and meet all requirements. Once all the paperwork for a government loan was complete, it was copied, printed, and sent as a case file to HUD for review. Under the paper-based process, the average time from “ready to send” to “insured by HUD” was 12 days for clean case files. Twenty percent of the case files were rejected because of errors or omissions; these loans required an average of 49 days to become insurable.
Table 9.1 Before and After Metrics for HUD Review of FHA-Insured Loans

Once the new system was up and running, the reject rate dropped to 1 percent since the system could automatically check for completeness and accuracy of all the required information before it was sent to HUD. With the elimination of copying, printing, packaging, and mail delays, the cycle time for clean loans was virtually same-day. Many rejected loans could also be resolved as quickly as the same day, and nearly all resolved within five days.
It is important to note that these improvements did not happen overnight and were implemented in several phases. Phase 1 automated most of the New Loan Boarding processes by imaging the relevant loan documents, keying data from the images, and conducting the servicing system comparison from that data. This enabled the paper files to flow more directly to the Government Insuring team. Subsequent phases applied this same approach to the work to insure loans with HUD. The Post Closing group also changed the organizational structure from a caseworker approach to one that split the loan review and deficiency correction activities. Wells Fargo then began working with HUD on eInsuring, helping to implement the same philosophies around STP and EBP (exception-based processing) that had proven effective in the Post Closing operation. After detailed process and risk reviews, the group accepted data-only submissions with follow-up image submission on an exception basis (to support quality audits). This set the foundation for big improvements in insuring performance, which continued in subsequent implementations. The final phase resulted in the biggest drop in rejection rates, from 20 percent or so to less than 1 percent.
Customers also are being more rapidly serviced. For example, the Wells Fargo Home Mortgage group receives a wave of calls each year around income tax time from customers who need copies of their HUD-1 Settlement Statement or other documents that they simply cannot find. If the customers are able to accept email and print their own copies, they can have the documents instantly.
The staff is also happier as they have a better work environment. For example, the New Loan Management department went from a staff of 140 full-time members to 30. The reduction was achieved primarily by terminating contract staff, and the team members who remain are doing more value-added activities.
All of these improvements have combined to create a powerful capability for Wells Fargo.
The Key Lessons Learned
There were several key insights that the Post Closing project team gained:
• Turning paper documents into electronically usable data allowed process improvements to come from several dimensions. The obvious improvements came from the ability to store, search, and transfer documents instantly. However, this alone was not sufficient to justify the investment.
• A less obvious improvement came from the ability to process activities in parallel rather than serially. This benefit enabled Post Closing to drive down insuring risks.
• There were benefits from combining STP and EBP. One of the favorite sayings in the group is “The best image is the one no one ever sees.” When an image does need to be seen, the ability to present it to users at the right time, with the right data, in an easy-to-view format, is a tremendous benefit.
An incremental and iterative “test and learn” approach is highly recommended. This project had high-quality people, technology, management support, and an urgent problem. Nevertheless, the team found significant errors in its business analysis and technical designs at several points, some of which in retrospect should have been obvious. The approach of having a broad, flexible architecture, and implementing partial solutions to reap business benefits as quickly as they could be deployed, avoided what could have been an indeterminately long integration test-and-fix period, and an awful lot of rework.
The question remains: Should servicers start with STP or workflow and migrate to the target state? If the end game is for staff to continue to touch most steps in the process and be the gating factor, starting with workflow is appropriate. But if the end game is to automate most of the process steps, making the process state engine the heart of the solution is the first step. This is a paradigm shift that requires a different state of mind, so research indicates it is ideal to begin with this step.
Maintaining the conceptual integrity of the architecture is essential. An initiative of this scale and complexity involves hundreds of people over the life of the program. The team members have their own experiences and knowledge bases, which drive their views of what the “right” technical solution is. As a result, a constant tug-of-war could emerge among project team members to apply different techniques. It is essential to keep the team aligned so that the program can be developed to include a coordinated set of architectural principles and an established delivery team that is responsible for both development and architecture, and to ensure that technical leaders see themselves as business leaders who are responsible for making decisions in the best interests of shareholders and customers.