
Let's take a quick look at how we can avoid the complexity mentioned previously in the graph world. In the following figure, you will find the graph model and the relational model side by side:
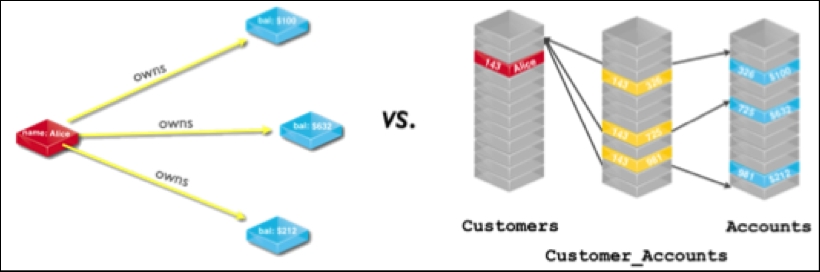
The relational model versus the graph model
On the right-hand side of the image, you will see the three tables in the relational model:
What is important here is the implication of this construction: every single time we want to find the accounts of a customer, we need to perform the following:
- Look up the customer by their key in the customer table.
- Join the customer using this key to their accounts.
- Look up the customer's accounts in the accounts table using the account keys that we found in the previous step.
Contrast this with the left-hand side of the figure, and you will see that the model is much simpler. We find the following elements:
- A node for the customer.
- Three nodes for the accounts.
- Three relationships linking the accounts to the customer.
Finding the accounts of the customer is as simple as performing the following:
- Finding the customer through an index lookup on the key that we specify in advance
- Traversing out from this customer node using the owns relationship to the accounts that we need
In the preceding example, we are performing only a single join operation over two tables. This operation will become exponentially more expensive in a relational database management system as the number of join operations increases and logarithmically more expensive as the datasets involved in the join operation become larger and larger. Calculating the Cartesian product of two sets (which is what relational databases need to do in order to perform the join) becomes more and more computationally complex as the tables grow larger.
We hope to have given you some initial pointers with regards to graph modeling compared to relational modeling, and we will now proceed to discuss some pitfalls and best practices.