
In this section, we will give you a few examples of how you can import small(ish) datasets into Neo4j. Small-ish means comfortably importing anything from a few hundred nodes to a few hundred thousand nodes and relationships and importing larger datasets with considerable patience.
We will present three approaches in this section:
- Importing using spreadsheets
- Importing using Neo4j-shell-tools
- Importing using Load CSV
All of these approaches have specific pros and cons, and it depends on your specific situation to choose your most appropriate option.
Many people work with spreadsheets and are comfortable manipulating their data in this environment. This is why for smaller datasets, this is often a very suitable way of importing your data. The process is very simple:

Spreadsheet import process
This approach works in most of the common spreadsheet solutions out there (Microsoft Excel, Open Office Calc, Google Sheets, Apple Numbers) as it relies on a very simple mechanism: using string concatenation based on cell values to compose a query statement. Let's take a brief look at this.
First, let's assume that we have a simple data table with people like the one in the following figure. These people have a unique identifier (first column), a name (second column), and a type/label (third column):
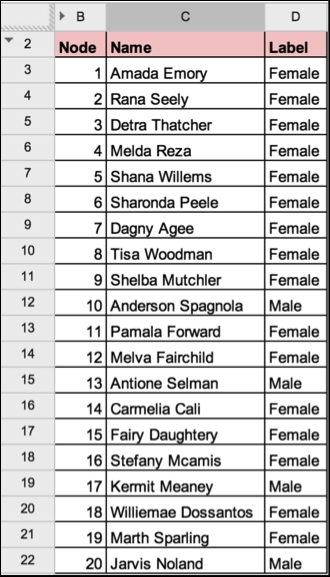
Nodes in a spreadsheet
Let's also assume that in order to import this data in a meaningful way into a graph database management system like Neo4j, we would have some additional information about the relationships between these people:
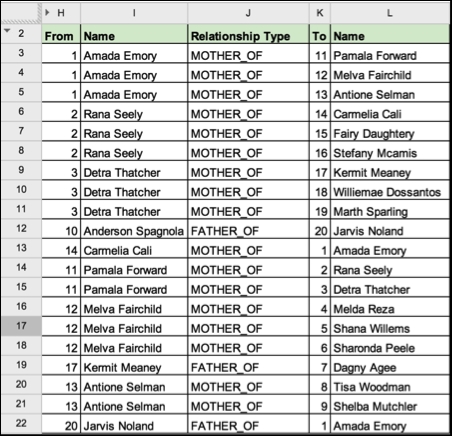
Relationships in a spreadsheet
Using the string concatenation function of your favorite spreadsheet program, you can then create two formulas that will look something like these:
- One formula to create the nodes of your graph:

- One formula to create the relationships of your graph:
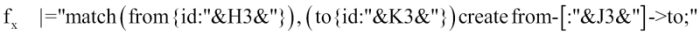
So, using this approach, you can create a long list of cypher statements that will allow you to create your graph by simply executing them.
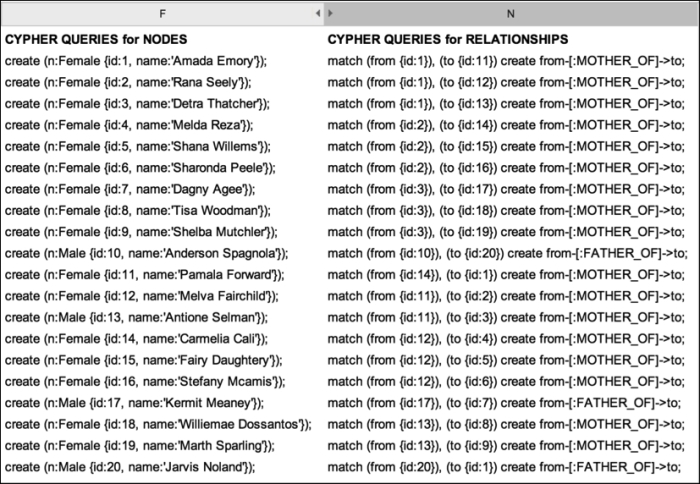
Cypher queries in a spreadsheet
Executing these queries can be as simple as copying and pasting them into the Neo4j browser or shell, or (and this is probably the better option) putting them into a text file and either piping it into the shell (using the | operator on Unix-based systems) or uploading it to the Neo4j server. The Neo4j browser has a specific functionality to drop a file onto the browser web application and execute the queries:
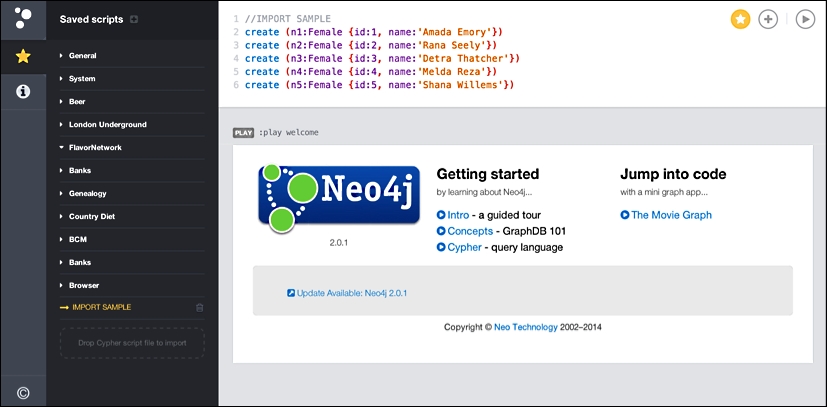
Running the spreadsheet queries
The end result will then be our graph database with the imported data, which we can interactively query from the browser:
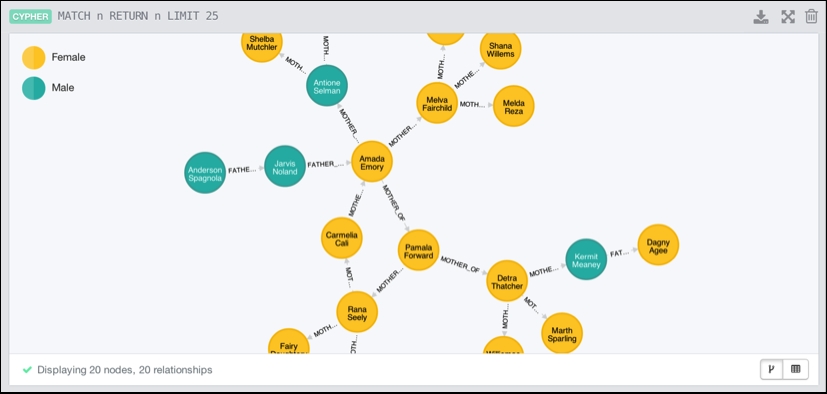
The resulting database from the spreadsheet
As mentioned before, this system works very well for smaller imports, but we will want to use different mechanisms for somewhat larger imports. Let's start exploring these.
As you probably know by now, the Neo4j system also has a command-line utility that you can access by executing the following command from the terminal in your main Neo4j directory (or bin
eo4shell.bat on Windows machines):
bin/Neo4j-shell
In this shell, you can not only execute cypher commands, but you can also extend the shell with some additional tools. At the time of writing this book, installing these tools is very easy: just download and extract them in Neo4j's lib directory. Here's how you can do this:
cd /path/to/your/Neo4j/server curl http://dist.Neo4j.org/jexp/shell/Neo4j-shell-tools-2.0.zip -o Neo4j-shell-tools.zip unzip Neo4j-shell-tools.zip -d lib
Once you have done this, the shell should be equipped with a new import functionality. This functionality works as follows:
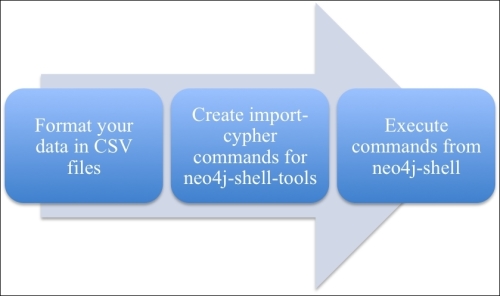
The Neo4j-shell-tools import process
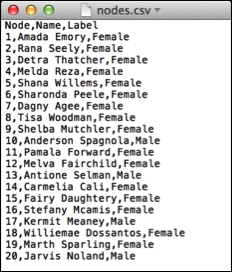
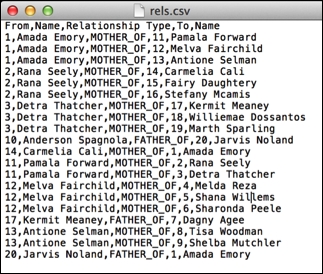
Let's try this for the same dataset as in the previously used spreadsheet example. We will create two .csv files in this case: one for nodes (nodes.csv) and one for relationships (rels.csv). Here's the nodes.csv file for you to take a look at:
Here's the rels.csv file that we will be using:
Then, using the Neo4j-shell-tools syntax, we want to execute two commands to populate our database. We can prepare these in our favorite text editor as follows:
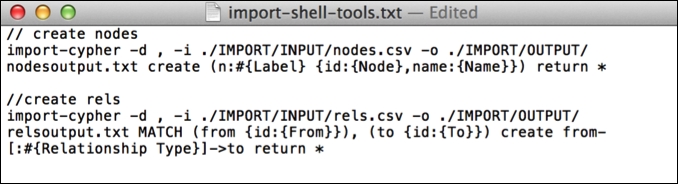
Neo4j-shell-tools commands
Executing the following query in the shell gives us immediate results:
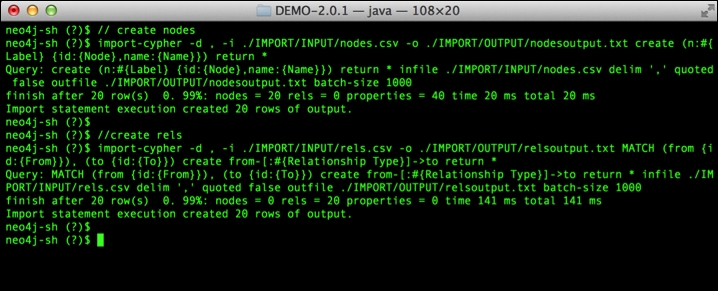
Neo4j-shell-tools result
The generated graph will then immediately be accessible in the Neo4j browser. The result, of course, will be identical to the graph shown previously
The Neo4j-shell-tools are much more powerful than what we have highlighted in these few paragraphs. It allows for different delimiters, quoted values, and variable batch sizes to tweak the performance of the import. It also supports other file formats such as the GEOFF and GraphML formats and supports exporting to many of these formats as well. So all in all, it is a very potential tool that can probably scale for importing millions of nodes and relationships—but not for billions. We will address this use case a bit later.
Now, we will finish this section by treating a very new methodology—Load CSV.
During the course of 2013, Neo Technology saw a very steep ramp in adoption for Neo4j and started getting a lot more user feedback. One of the most prominent pieces of consistent feedback was that Neo4j needed to improve its native import capabilities, and this is why this feature was added as a capability as part of the 2.1 release of Neo4j.
The import workflow is similar to that of Neo4j-shell-tools, but has the following exceptions:
- It is embedded into cypher.
- The
.csvfiles can be loaded from anywhere; it just needs a URI. - It is accessible from the new Neo4j browser tool.
- It does not yet (at the time of writing this book) allow for variable labels and relationship types. This is somewhat important for us in this example, as it will mean that we cannot immediately assign the right labels and relationship types from the current CSV files; we will have to add these as properties first and then run another cypher query to fix this.
So, let's go through the import of the same files using this final toolset:
The Load CSV process
Let's start by importing the nodes. Executing the following query in the Neo4j browser works out very well:
//Loading CSV with Nodes
load csv with headers from
"file:/your/path/to/nodes.csv"
as nodes
create (n {id: nodes.Node, name: nodes.Name, type: nodes.Label})
return nExecuting this query in the Neo4j browser tool gives us the following result:
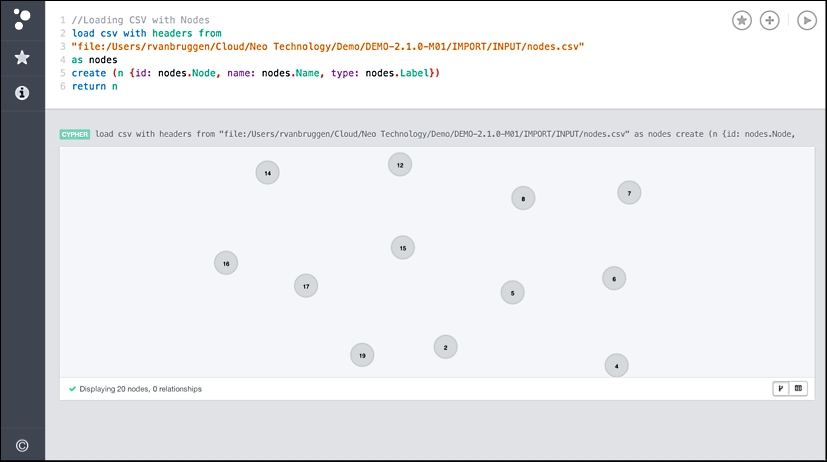
Loading nodes with Load CSV
Then, we will add the relationships to the graph using the following query:
//Loading CSV with Rels
load csv with headers from
"file:/your/path/to/rels.csv"
as rels
match (from {id: rels.From}), (to {id: rels.To})
create from-[:REL {type: rels.`Relationship Type`}]->to
return from, toThen, we get the following result that is very similar to what we had in the previous import scenarios:
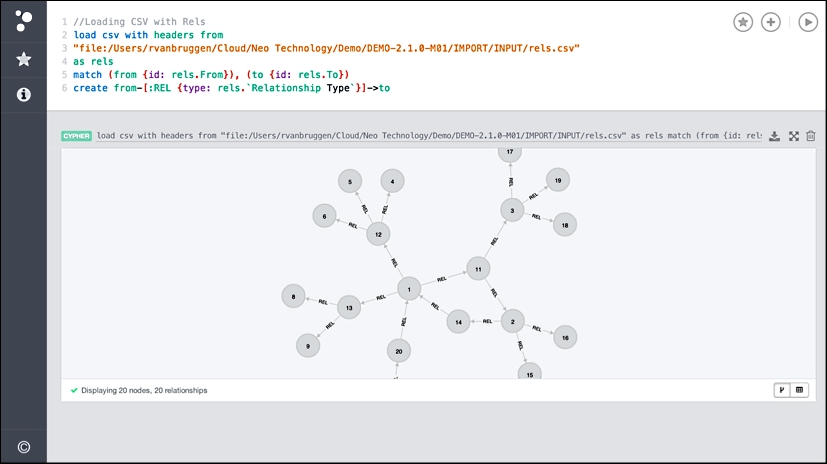
Loading relationships with Load CSV
However, the difference between the current graph and the ones that we had in our previous import scenarios is that we have not used any labels or relationship types yet. Therefore, the preceding screenshot looks a bit different. The following two queries correct this though:
- Query 1:
//Assign labels for Males and Females match (m {type:"Male"}), (f {type:"Female"}) set m:Male, f:Female return m,f - Query 2:
//Create duplicate relationship with appropriate type match (n)-[r1 {type:"MOTHER_OF"}]->(m), (s)-[r2 {type:"FATHER_OF"}]->(t) create n-[:MOTHER_OF]->m, s-[:FATHER_OF]->t return *; //Remove duplicate relationships match ()-[r:REL]-() delete r;
The following screenshot shows the final result of Load CSV:
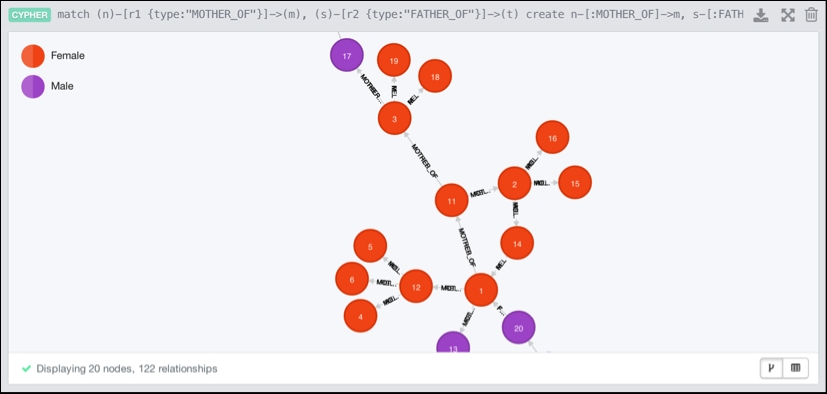
From working with the Load CSV toolset at this early milestone release, it seems clear that there are still quite a few things to iron out, but in general, we still recommend that you take a look at it as it presents you with a very intuitive and native way of importing data into Neo4j. Neo Technology also claims that this approach should work well for imports into millions (but not billions) of nodes and relationships, especially if you want to make use of the periodic commit functionality that is tied to Load CSV. If you start your Load CSV statements with a "using periodic commit {a number}", Neo4j will periodically commit your import transactions, thereby making it a lot easier to scale your import.
For a larger import use case, we will now take a look at a final data import toolset.