
8. Linux Processes: Structure, Hangs, and Core Dumps
Troubleshooting a Linux process follows the same general methodology as that used with traditional UNIX systems. In both systems, for process hangs, we identify the system resources being used by the process and attempt to identify the cause for the process to stop responding. With application core dumps, we must identify the signal for which the process terminated and proceed with acquiring a stack trace to identify system calls made by the process at the time it died. There exists neither a “golden” troubleshooting path nor a set of instructions that can be applied for all cases. Some conditions are much easier to solve than others, but with a good understanding of the fundamentals, a solution is not far from reach.
This chapter explains various facets of Linux processes. We begin by examining the structure of a process and its life cycle from creation to termination. This is followed by a discussion of Linux threads. The aforementioned establish a basis for proceeding with a discussion of process hangs and core dumps.
Process Structure and Life Cycle
This section begins with an overview of process concepts and terms, noting the similarities and differences between UNIX and Linux. We then move on to discuss process relationships, process creation, and process termination.
Process/Task Overview
It is helpful to begin with a general comparison of processes in UNIX and in Linux. Both operating systems use processes; however, the terminology employed by each differs slightly. Both use the term “process” to refer to process structure. Linux also uses the term “task” to refer to its processes. Therefore, in Linux, the terms “process” and “task” are used interchangeably, and this chapter also so uses them. Note that UNIX does not use the term “task.”
The process structures of the two operating systems differ more dramatically, which is easily recognized when observing a multithreaded program in action. The thread is the actual workhorse of the process and is sometimes referred to as a lightweight process (LWP). In Linux, every thread is a task or process; however, this is not the case with UNIX.
As described previously, the UNIX process model places its threads within the process structure. This structure contains the process’s state, process ID (PID), parent process ID (PPID), file table, signal table, thread(s), scheduling, and other information. Thus, there is only one PID for a process that can have many threads. However, when a process calls the pthread_create() subroutine in Linux, it creates another task/PID, which just happens to share the same address space. Figure 8-1 depicts this fundamental difference.
Figure 8-1. Comparison of UNIX and Linux processes
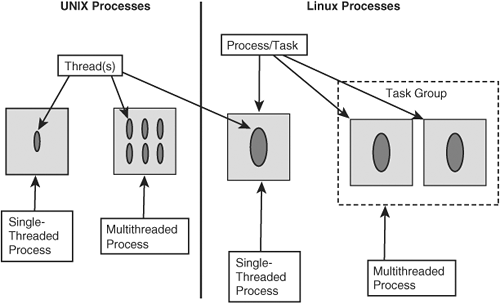
Unlike UNIX, Linux does not have a kernel object that represents the process structure; instead, it uses a task structure. Each task has a unique ID just like a UNIX PID. However, the Linux task model only represents a single thread of execution. In this way, a task can be thought of as a single UNIX thread. Just like the UNIX process structure, the Linux task structure contains the task’s state, PID, PPID, file table, address space, signals, scheduling, and so on. In addition, it contains the Task Group ID (tgid), which we elaborate on later in this chapter.
Process Relationships
When troubleshooting a process, it is crucial to identify all related tasks/processes, and there are several approaches to doing so. A task could hang or dump core because a resource it requires is in use by another process, or a parent could mask a signal that the child needs to execute properly. When it comes to identifying a process’s relationship to others, you could use the /proc/<pid>/ directory to manually search out a process’s information and its relationship to others. Relationships can also be determined by the use of commands such as ps, pstree, and top, among others, which make use of this pseudo filesystem. These tools make short work of obtaining a picture of a process’s state and its relationship to others.
Linux Process Creation
An understanding of process creation is necessary for troubleshooting a process. Processes are created in Linux in much the same way as they are created in UNIX. When executing a new command, the fork() system call sets up the child’s context to reference the parent’s context and creates a new stack. This referencing of the parent’s context (essentially a pointer to the parent’s task_struct() structure) increases overall OS performance. The child’s context references the parent’s context until modification is required, at which point the parent’s address space is copied and modified. This is achieved by the copy-on-write (COW) design.
Shortly after fork() has set up the new task for execution, the exec system call is made. This is where the copy-on-write does its magic. The parent’s structure is no longer just referenced; rather, it is copied into a new virtual location. Next, the object file (command) is copied into this location, overwriting the copied pages. Now the new task’s context is set up, and the new process is running.
There are some differences between how processes are created in UNIX and how they are created in Linux. For example, some flavors of UNIX perform a copy-on-access, for which the fork() copies the context of the parent to a new virtual memory address with no references pointing back to the parent’s context. One is no better than the other because in a majority of instances, the referenced pages must be modified, causing the COW method to copy the pages anyway.
An Example of Linux Process Creation
In this section, we demonstrate the fork() system call by tracing the parent process. In this example, we use the ls command to list a file. Because the ls program is the child of its local shell, we need to trace the shell from which the ll (ls -al alias) command is executed. Two shell windows are required to perform this test.
- Window one: Determine the pseudo terminal and PID of shell.
# echo $$
16935The parent shell’s PID is 16935. Now we must start the trace in a second window.
- Window two: Start trace of shell process.
# strace -o /tmp/ll.strace -f -p 16935
Now that the trace is running in window two, we need to issue the
llcommand in window one. - Window one: Issue the
llcommand.# ll test
-rw-r--r-- 1 chris chris 46759 Sep 7 21:53 test
Note
Check the
stdoutin window two and stop the trace by sending an interrupt (type Ctrl+c). - Window two: Here are the results of the
stdoutand stopping the trace.# strace -o /tmp/ll.strace -f -p 16935
Process 16935 attached <-- Trace running on 16935
Process 17424 attached <-- forked child process
Process 17424 detached <-- child ending returning to parent
Process 16935 detached <-- ctrl +c ending trace
The trace shows the fork() and execve() calls. Note that we are not showing the entire trace because so many system calls take place for each seemingly simple command.
...
16935 fork() = 17424 <-- NEW task's PID
17424 --- SIGSTOP (Stopped (signal)) @ 0 (0) ---
17424 getpid() = 17424
17424 rt_sigprocmask(SIG_SETMASK, [RTMIN], NULL, 8) = 0
17424 rt_sigaction(SIGTSTP, {SIG_DFL}, {SIG_IGN}, 8) = 0
17424 rt_sigaction(SIGTTIN, {SIG_DFL}, {SIG_IGN}, 8) = 0
17424 rt_sigaction(SIGTTOU, {SIG_DFL}, {SIG_IGN}, 8) = 0
17424 setpgid(17424, 17424) = 0
17424 rt_sigprocmask(SIG_BLOCK, [CHLD TSTP TTIN TTOU], [RTMIN], 8) = 0
17424 ioctl(255, TIOCSPGRP, [17424]) = 0
17424 rt_sigprocmask(SIG_SETMASK, [RTMIN], NULL, 8) = 0
17424 rt_sigaction(SIGINT, {SIG_DFL}, {0x8087030, [], SA_RESTORER,
0x4005aca8}, 8) = 0
17424 rt_sigaction(SIGQUIT, {SIG_DFL}, {SIG_IGN}, 8) = 0
17424 rt_sigaction(SIGTERM, {SIG_DFL}, {SIG_IGN}, 8) = 0
17424 rt_sigaction(SIGCHLD, {SIG_DFL}, {0x80776a0, [], SA_RESTORER,
0x4005aca8}, 8) = 0
17424 execve("/bin/ls", ["ls", "-F", "--color=auto", "-l", "test"],
[/* 56 vars */]) = 0
Summary of Process Creation
The fork() call creates a new task and assigns a PID, and this step is soon followed by the execve() call, executing the command along with its arguments. In this case, we see that the ll test command is actually ls -F --color=auto -l test.
Linux Process Termination
An understanding of process termination is useful for troubleshooting a process. As with process creation, the termination or exiting of a process is like that of any other UNIX flavor. If signal handling is implemented, the parent can be notified when its children terminate irregularly. Additionally, the parent process can also wait for the child to exit with some variation of wait(). When a process terminates or calls exit(), it returns its exit code to the caller (parent). At this point, the process is in a zombie or defunct state, waiting for the parent to reap the process. In some cases, the parent has long since died before the child. In these cases, the child has become orphaned, at which point init becomes the parent, and the return codes of the process are passed to init.
Linux Threads
No discussion of process fundamentals is complete without an explanation of Linux threads because an understanding of threads is crucial for troubleshooting processes. As mentioned earlier, the implementation of threads in Linux differs from that of UNIX because Linux threads are not contained within the proc structure. However, Linux does support multithreaded applications. “Multithreading” just means two or more threads working in parallel with each other while sharing the same address space. Multithreaded applications in Linux just use more than one task. Following this logic in the source, include/linux/sched.h shows that the task_struct structure maintains a one-to-one relationship with the task’s thread through the use of a pointer to the thread_info structure, and this structure just points back to the task structure.
Excerpts from the source illustrate the one-to-one relationship between a Linux task and thread.
include/linux/sched.h
...
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
struct thread_info *thread_info;
...
To see the thread_info structure point back to the task, we review include/asmi386/thread_info.h.
...
struct thread_info {
struct task_struct *task; /* main task structure */
...
Using multithreaded processes has its advantages. Threading allows for better processor loading and memory utilization. A drawback is that it also significantly increases the program’s complexity. On a single-CPU machine, a multithreaded program for the most part performs no better than a single-threaded program. However, well-designed multithreaded applications executed on a Symmetric Multi-Processor (SMP) machine can have each thread executing in parallel, thereby significantly increasing application performance.
Threaded application performance is enhanced by the fact that threads share resources. Different types of processes share resources in different ways. The initial process is referred to as the heavyweight process (HWP), which is a prerequisite for lightweight processes. Traditionally, a thread of a process is referred to as a lightweight process (LWP), as mentioned earlier. The main difference between these two is how they share their resources. Simply stated, when an HWP forks a new process, the only thing that is shared is the parent’s text. If an HWP must share information with another HWP, it uses techniques such as pipes, PF_UNIX (UNIX sockets), signals, or interprocess communication’s (IPCS) shared memory, message queues, and semaphores. On the other hand, when an HWP creates an LWP, these processes share the same address space (except the LWP’s private stack), thus making utilization of system resources more efficient.
Note that although several forms of threads exists, such as user space GNU Portable Threads (PTH) and DCE threads, in this chapter, we only cover the concept of POSIX threads because they are the most commonly used threads in the industry. POSIX threads are implemented by the pthread library. The use of POSIX threads ensures that programs will be compatible with other distributions, platforms, and OSs that support POSIX threads. These threads are initiated by the pthread_create() system call; however, the Linux kernel uses the clone() call to create the threads. As implied by its name, it clones the task. Just as fork() creates a separate process structure, clone() creates a new task/thread structure by cloning the parent; however, unlike fork(), flags are set that determine what structures are cloned. Only a select few flags of the many flags available are required to make the thread POSIX compliant.
The Linux kernel treats each thread as an individual task that can be displayed with the ps command. At first, this approach might seem like a large waste of system resources, given that a process could have a great number of threads, each of which would be a clone of the parent. However, it’s quite trivial because most task structures are kernel objects, which enables the individual threads to just reference the address space. An example is the HWP’s file descriptor table. With clone(), all threads just reference the kernel structure by using the flag CLONE_FILES.
With help from developers from around the world, the Linux kernel is developing at an extraordinary rate. A prime example is the fork() call. With the IA-64 Linux kernel, the fork() call actually calls clone2(). In addition, pthread_create() also calls clone2(). The clone2() system call adds a third argument, ustack_size. Otherwise, it is the same as clone(). With the IA-32 2.6 kernel release, the fork() call has been replaced with the clone() call. The kernel clone() call mimics fork() by adjusting clone() flags.
Detailed next are examples of tasks and threads being created on different versions and distributions of Linux:
• IA-32 (2.4.19) Fork call
2970 fork() = 3057 <-- The PID for the new HWP
• IA-32 (2.4.19) Thread creation
3188 clone(child_stack=0x804b8e8,
flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND) = 3189 <-- LWP
• IA-32 (2.6.3) Fork call
12383 clone(child_stack=0,
flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD,
child_tidptr=0x4002cba8) = 12499 <-- HWP
• IA-32 (2.6.3) Thread creation
12440 <... clone resumed> child_stack=0x42184b08,
flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYS
VSEM|CLONE_SETTLS
|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID|CLONE_DETACHED,
parent_tidptr=0x42184bf8, {entry_number:6, base_addr:0x42184bb0,
limit:1048575, s
eg_32bit:1, contents:0, read_exec_only:0, limit_in_pages:1,
seg_not_present:0, useable:1}, child_tidptr=0x42184bf8) = 12444 <--LWP
• IA-64 (2.4.21) Fork call
24195 clone2(child_stack=0, stack_size=0,
flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD,
child_tidptr=0x200000000002cdc0) = 24324 <--HWP
• IA-64 (2.4.21) Thread creation
24359 clone2(child_stack=0x20000000034f4000, stack_size=0x9ff240,
flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSV
SEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID|CLONE_DETACHED,
parent_tidptr=0x2000000003ef3960, tls=0x2000000003ef3f60,
child_tidptr=0x2000000003ef3960) = 24365 <--LWP
As the previous examples show, the kernel clone() call creates threads, whereas clone2() creates threads, new processes, or both. In addition, the previous traces reveal the creation of threads and the flags needed to make them POSIX compliant, as defined in the next listing.
clone(child_stack=0x804b8e8,
flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND)
child_stack: Unique process stack
CLONE_VM : Parent and child run in the same address space
CLONE_FS: Parent and child share file system info
CLONE_FILES: Parent and child share open file table
CLONE_SIGHAND: Parent and child share signal handlers
Identifying Threads
As previously discussed, the ps command lists all tasks in Linux, preventing the user from distinguishing the HWP from the LWP. At approximately the 2.4.9 kernel release, the Task Group ID (tgid) was added to fs/proc/array.c. This placed a task’s tgid in the /proc/<pid>/status file. A key point is that the tgid is equal to the HWP’s PID. This new feature enables users to identify threads of a multithreaded process with ease.
# ./fs/proc/array.c
...
static inline char * task_state(struct task_struct *p, char *buffer)
{
int g;
read_lock(&tasklist_lock);
buffer += sprintf(buffer,
"State: %s
"
"Tgid: %d
"
"Pid: %d
"
"PPid: %d
"
"TracerPid: %d
"
"Uid: %d %d %d %d
"
"Gid: %d %d %d %d
",
get_task_state(p), p->tgid,
...
Linux commands, such as ps, were modified to make use of this new value, enabling them to display only the parent HWP task (tgid), or all threads of a task by passing the -m or -eLf flag.
In Listing 8-1, we have included a small example of a threaded program that demonstrates how threads appear in Linux. Note that this code makes no attempt either to lock threads with mutex locks or semaphores or to perform any special signal masking. This code just creates threads that perform sequential counts to exercise the CPU(s).
Listing 8-1. Example of a Threaded Program
#include <pthread.h> /* POSIX threads */
#include <signal.h>
#include <stdlib.h>
#include <linux/unistd.h>
#include <errno.h>
#define num_threads 8
void *print_func(void *);
void threadid(int);
void stop_thread(int sig);
/* gettid() is not portable.. if compiling on other Operating Systems,
remove reference to it */
_syscall0(pid_t,gettid)
int main ()
{
int x;
pid_t tid;
pthread_t threadid[num_threads];
(void) signal(SIGALRM,stop_thread); /*signal handler */
printf("Main process has PID= %d PPID= %d and TID= %d
",
getpid(), getppid(), gettid());
/* Now to create pthreads */
for (x=1; x <= num_threads;++x)
pthread_create(&threadid[x], NULL, print_func, NULL );
sleep(60); /* Let the threads warm the cpus up!!! :) */
for (x=1; x < num_threads;++x)
pthread_kill(threadid[x], SIGALRM);
/*wait for termination of threads before main continues*/
for (x=1; x < num_threads;++x)
{
printf("%d
",x);
pthread_join(threadid[x], NULL);
printf("Main() PID %d joined with thread %d
", getpid(),
threadid[x]);
}
}
void *print_func (void *arg)
{
printf("PID %d PPID = %d Thread value of pthread_self = %d and
TID= %d
",getpid(), getppid(), pthread_self(),gettid());
while(1); /* nothing but spinning */
}
void stop_thread(int sig) {
pthread_exit(NULL);
}
Using Listing 8-1, create a binary by compiling on any UNIX/Linux system that supports POSIX threads. Reference the following demonstration:
- Compile the source.
# gcc -o thread_test thread_test.c -pthread
Next, execute
thread_testand observe the tasks withpstree. Note that we have trimmed the output ofpstreeto save space. - Execute the object.
#./thread_test
- In a different shell, execute:
# pstree -p
init(1)-+-apmd(1177)
~~~~~~Saving space~~~~~
|-kdeinit(1904)-
~~~~~~Saving space~~~~~
| |-kdeinit(2872)-+-bash(2874)---thread_test
(3194)-+-thread_test(3195)
| | |
|-thread_test(3196)
| | |
|-thread_test(3197)
| | |
|-thread_test(3198)
| | |
|-thread_test(3199)
| | |
|-thread_test(3200)
| | |
|-thread_test(3201)
| | |
`-thread_test(3202)
~~~~~~Saving space~~~~~
| | `-bash(3204)---
pstree(3250)
~~~~~~Saving space~~~~~ - We can display more details with the
pscommand. (Note that the PIDs would have matched if we had run these examples at the same time.)# ps -eo pid,ppid,state,comm,time,pri,size,wchan | grep test
28807 28275 S thread_test 00:00:12 18 82272
schedule_timeout
Display threads with -m.
# ps -emo pid,ppid,state,comm,time,pri,size,wchan | grep test
28807 28275 S thread_test 00:00:00 18 82272
schedule_timeout
28808 28807 R thread_test 00:00:03 14 82272 -
28809 28807 R thread_test 00:00:03 14 82272
ia64_leave_kernel
28810 28807 R thread_test 00:00:03 14 82272
ia64_leave_kernel
28811 28807 R thread_test 00:00:03 14 82272
ia64_leave_kernel
28812 28807 R thread_test 00:00:03 14 82272 -
28813 28807 R thread_test 00:00:02 14 82272
ia64_leave_kernel
28814 28807 R thread_test 00:00:02 14 82272
ia64_leave_kernel
28815 28807 R thread_test 00:00:03 14 82272 -
Even though some UNIX distributions have modified commands such as ps or top to display a process with all its threads by including special options such as -m or -L, HPUX has not. Therefore, the HPUX ps command only shows the HWP process and not the underlying threads that build the process. On the other hand, Solaris can display the LWP of a process by using the -L option with its ps command.
Other vendors have created their own tools for displaying threads of a process. HPUX’s glance is a good example. Using the same procedures as earlier, we demonstrate multithreads in HPUX to show the main difference between UNIX threads and Linux’s implementation of threads.
HPUX 11.11:
# cc -o thread_test thread_test.c -lpthread
hpux_11.11 #glance
Process Name PID PPID Pri Name ( 700% max) CPU IO Rate RSS
Cnt
------------------------------------------------------------------------
thread_test 14689 14579 233 root 698/ 588 57.3 0.0/ 0.2
560kb 9
Thus, using HPUX’s glance, we can see that the thread count is nine, with one thread representing the main HWP and eight additional threads that were created by the program as shown in the source. Each thread does not have its own PID as with Linux threads. In addition, Linux tools such as top do not show the threads of a process consuming CPU cycles. This can be tested by executing the thread_test program in one tty and the top program in another tty.
Identifying Process Hangs
Now that we have covered the building blocks of processes and threads, it is time to address process hangs and their potential causes. There is little hope that killing an offending process with -9 (sigkill) will lead to discovering the root cause of a process hang. Neither will rebooting the OS unless you are dealing with a stale file handle. Furthermore, these steps will not prevent these anomalies from reoccurring. However, by applying the knowledge of how processes are created and how resources are used, the root cause can be identified.
When a process appears hung, the first step toward a solution is determining certain critical information about the task. Using the ps command, start by determining the task’s state, threads, priority, parent, and wait channel. In addition, identify the cumulative CPU time and the initial start time of the task. A holistic approach is needed because although a single ps command is a good start, it will not deliver all the needed information.
Let us first determine whether the process is hung because sometimes a process appears to be blocked when it actually is in the middle of a computation or non-blocking I/O. If cumulative CPU time constantly grows, the task’s state will most likely be R. In this state, the process is on the run queue and does not have a wait channel. Monitor its cumulative CPU time. If the process remains in the run queue, it might be performing some calculation that takes a while. Even the fastest computers in the world take a while to calculate an infinite loop! Nevertheless, note that a process in the run state could be the normal operation of that program, an application “feature,” or a driver problem.
If an offending process is consuming system resources at an extraordinary rate and starving production applications, killing the offending process is justified if the process can be killed. However, sometimes a process cannot be killed. When a process has exhausted its timeslice, it is put to sleep() with a given priority. When the priority of the process falls below PZERO, it is in an uninterruptible state and cannot be signaled; however, signals can be queued, and for some operations, this is normal. For others, where the program has hung and never returns, the cause is usually located in the driver or hardware. If the process has a state of D (blocked on I/O), it is uninterruptible and cannot be killed. For example, a process accessing a file over a failed hard NFS mount would be in a state of D while attempting to stat() a file or directory.
Uninterruptible processes usually take place when entering I/O calls, at which point the process has called into the kernel, which is in driver code, during which the process cannot receive signals from user space. In this state, a command cannot be signaled even by a SIGKILL (kill -9). It is important to note that signals are queued if not ignored by a sigmask and executed after the code returns from kernel space. Some signals cannot be masked; see the signal man page for more details.
Here is an excerpt from the signal man page:
...
Using a signal handler function for a signal is called "catching the
signal". The signals SIGKILL and SIGSTOP cannot be caught or ignored.
...
A zombie process is another process that a user cannot kill. These processes, however, should not be consuming any CPU cycles or memory resources other than the overhead of having the task structure in the kernel’s Virtual Address Space (VAS). The main goal of troubleshooting a zombie process is determining why the parent died without reaping its children. In short, you should focus on why and how the parent dies.
Listed next are process state codes pulled right out of the source code.
./linux/fs/proc/array.c
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char *task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"Z (zombie)", /* 4 */
"T (stopped)", /* 8 */
"W (paging)" /* 16 */
};
...
In Scenario 8-1, we demonstrate an instance in which a process cannot be killed.
Scenario 8-1: Troubleshooting a Process That Does Not Respond to kill
A user begins rewinding a tape but realizes that the wrong tape is in the drive. The user tries to kill the job but must wait for the process to finish.
Why?
The mt command has made an ioctl call to the SCSI tape driver (st) and must wait for the driver to release the process back to user space so that use signals will be handled.
# mt -f /dev/st0 rewind
# ps -emo state,pid,ppid,pri,size,stime,time,comm,wchan | grep mt
D 9225 8916 24 112 20:46 00:00:00 mt wait_for_completion
[root@atlorca2 root]# kill -9 9225
[root@atlorca2 root]# echo $? # This produces the return code for the
previous command. 0 = success
0
[root@atlorca2 root]# ps -elf | grep 9225
0 D root 9225 8916 0 24 0 - 112 wait_f 20:46 pts/1
00:00:00 mt -f /dev/st0
The mt command has entered a wait channel, and after the code returns from the driver, the signal will be processed.
Let’s check the pending signals:
cat ../9225/status
Name: mt
State: D (disk sleep)
Tgid: 9225
Pid: 9225
PPid: 8916
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 256
Groups: 0 1 2 3 4 6 10
VmSize: 2800 kB
VmLck: 0 kB
VmRSS: 640 kB
VmData: 96 kB
VmStk: 16 kB
VmExe: 32 kB
VmLib: 2560 kB
SigPnd: 0000000000000100 <-- SigPnd is a bit mask which indicates the
value of the pending signal. Each byte accounts for 4 bits. In this
case, the pending signal has a value of 9, so the first bit on the 3rd
byte is set. This algorithm is detailed in linux/fs/proc/array.c under
the render_sigset_t() function. The following table illustrates this
function.
Signal : 1 2 3 4 . 5 6 7 8 . 9 10 11 12 . 13 14 15 16
bit value : 1 2 4 8 . 1 2 4 8 . 1 2 4 8 . 1 2 4 8
kill -3 yields bit mask 0000000000000004
kill -9 yields bit mask 0000000000000100
ShdPnd: 0000000000000100
SigBlk: 0000000000000000
SigIgn: 0000000000000000
SigCgt: 0000000000000000
CapInh: 0000000000000000
CapPrm: 00000000fffffeff
CapEff: 00000000fffffeff
Troubleshooting the hung process involves these steps:
- Identify all the tasks (threads) for the program.
- Assess the hanging process. Is it easily reproducible?
- Assess the other things going on. What else is the machine doing? Check load and other applications’ response time.
The following scenario demonstrates a way of troubleshooting a process that periodically hangs and then continues.
Scenario 8-2: Troubleshooting a Hanging Web Browser
A user complains that her machine is working great except for her Web browsing application. When accessing Web sites, the browser hangs for a few minutes every so often. The user has installed several different versions and tried other browsers to no avail.
You ask her the following question: Has it ever worked? The reply is “Yes . . . several days ago it was fine.”
For the sake of simplicity, we attempt to find the problem with a light Web browser with little overhead.
# strace -f -F -r -T -o /tmp/lynx.strace_2 lynx http://www.hp.com
Using the vi editor and greping for network calls, such as poll(), we can identify what seems to be a problem right away:
:g/poll/p
3660 0.000085 poll([{fd=0, events=POLLIN}], 1, 0) = 0 <0.000020>
3660 0.000186 poll([{fd=0, events=POLLIN}], 1, 0) = 0 <0.000008>
3660 0.000049 poll([{fd=3, events=POLLIN}], 1, 5000) = 0 <5.005154>
3660 0.000043 poll([{fd=3, events=POLLIN}], 1, 5000) = 0 <5.009763>
3660 0.000042 poll([{fd=3, events=POLLIN}], 1, 5000) = 0 <5.008875>
3660 0.000043 poll([{fd=3, events=POLLIN}], 1, 5000) = 0 <5.009264>
3660 0.000042 poll([{fd=3, events=POLLIN}], 1, 5000) = 0 <5.009216>
3660 0.000043 poll([{fd=3, events=POLLIN, revents=POLLIN}], 1,
5000) = 1 <0.001146>
3660 0.000081 poll([{fd=0, events=POLLIN}], 1, 0) = 0 <0.000017>
3660 0.000088 poll([{fd=0, events=POLLIN}], 1, 0) = 0 <0.000008>
3660 0.000088 poll([{fd=0, events=POLLIN}], 1, 0) = 0 <0.000022>
We see that some poll() calls took over five seconds each. That would explain the Web browser hanging and taking a long time to browse sites.
Focusing on the trace, we see the following:
3660 0.000254 socket(PF_INET, SOCK_DGRAM, IPPROTO_IP) = 3 <0.000044>
3660 0.000095 connect(3, {sa_family=AF_INET, sin_port=htons(53),
sin_addr=inet_addr("15.50.74.40")}, 28) = 0 <0.000017>
3660 0.000108 send(3, "245`1��1������3www2hp3com��
34�1", 28, 0) = 28 <0.000404>
3660 0.000476 gettimeofday({1097369839, 928119}, NULL) = 0 <0.000005>
3660 0.000049 poll([{fd=3, events=POLLIN}], 1, 5000) = 0 <5.005154>
3660 5.005262 send(3, "245`1��1������3www2hp3com��
34�1", 28, 0) = 28 <0.000426>
Checking the man page on poll, we see that it is waiting for an event to take place on a file descriptor.
# ls -al /proc/3660/fd/3 -> socket:[52013]
This confirms a network issue. After reviewing the /etc/resolv.conf file, we see that 15.50.64.40 is the nameserver.
The user contacted her IT department and found that the nameserver configuration for her network had changed. Switching to a different nameserver in the resolv.conf file alleviated the five-second poll() call and resolved the problem.
Commands commonly used to troubleshoot a hung process include the following:
• ps—Concentrate on pid, ppid, state, comm, time, pri, size, and wchan flags.
• lsof—Determine the open files on the system.
• pstree—Focus on processes and how they relate to each other.
• strace—Flags most commonly used: -f -F -r -T -o <outfile>.
• man pages—Believe it or not, the manual helps.
• source code—Use it to determine what the application is doing.
• /proc filesystem—It offers a wealth of information.
In Scenario 8-3, we show a process that appears to be hung but is not.
Scenario 8-3: Troubleshooting an Apparent Process Hang
In this scenario, a user’s goal is to create a file that takes data, automatically compresses it, and sends it to a new file. To perform this task, the user creates a named pipe and issues gzip, redirecting input from the pipe to a new file. The odd part is that the gzip process seems to hang, and the user cannot find the gzip process when searching ps -ef.
So you devise an action plan: Re-create the event and trace the process involved.
- Create a named pipe.
$ mknod /tmp/named_pipe p
$ ll /tmp/named_pipe
prw-r--r-- 1 chris chris 0 Oct 9 16:53
/tmp/named_pipe | - Acquire the current process ID.
$ echo $$ # note that the current PID = the shell
5032 - From the same shell window, start the
gzipprocess on the named pipe.$ gzip < /tmp/named_pipe > /tmp/pipe.out.gz
- Find the process with a parent of 5032.
$ ps -emo pid,ppid,state,comm,time,pri,size,wchan | grep 5032
5236 5032 S bash 00:00:00 30 1040 pipe_waitNotice that the command name is
bash, and it is in the sleep state, sleeping on wait channelpipe_wait. Yetgzipwas the command executed. - In another shell window, start a trace on the parent before executing the
gzipcommand.$ strace -o /tmp/pipe.strace -f -F -r -T -v -p 5032
Process 5032 attached - interrupt to quit ........Parent shell
process
Process 5236 attached ....................................The gzip
process being forked
Process 5032 suspendedAs mentioned earlier,
fork()essentially creates a process structure by copying the parent. Untilexecve()executes the binary, the new executable is not loaded into memory, sops -ef | grep gzipdoes not show the process. In this case, thegzipprocess waits for something to be sent to the pipe before executinggzip. - A review of the trace explains why the
ps -ef | grep gzipcommand does not show the process.PID Time call()
...
5032 0.000079 fork() = 5236 <0.000252>.........."GZIP was
executed at command line"
5032 0.000678 setpgid(5236, 5236) = 0 <0.000008>
5032 0.000130 rt_sigprocmask(SIG_SETMASK, [RTMIN], NULL, 8)
= 0 <0.000007>
...
5032 0.000074 waitpid(-1, <unfinished ...>..........."man
waitpid: -1 means wait on child"
5236 0.000322 --- SIGSTOP (Stopped (signal)) @ 0 (0) ---
5236 0.000078 getpid() = 5236 <0.000006>
5236 0.000050 rt_sigprocmask(SIG_SETMASK, [RTMIN], NULL, 8)
= 0 <0.000007>
5236 0.000067 rt_sigaction(SIGTSTP, {SIG_DFL}, {SIG_IGN},
8) = 0 <0.000009>
5236 0.000060 rt_sigaction(SIGTTIN, {SIG_DFL}, {SIG_IGN},
8) = 0 <0.000007>
5236 0.000057 rt_sigaction(SIGTTOU, {SIG_DFL}, {SIG_IGN},
8) = 0 <0.000007>
5236 0.000055 setpgid(5236, 5236) = 0 <0.000008>
5236 0.000044 rt_sigprocmask(SIG_BLOCK, [CHLD TSTP TTIN
TTOU], [RTMIN], 8) = 0 <0.000007>
5236 0.000071 ioctl(255, TIOCSPGRP, [5236]) = 0 <0.000058>
5236 0.000102 rt_sigprocmask(SIG_SETMASK, [RTMIN], NULL, 8)
= 0 <0.000007>
5236 0.000060 rt_sigaction(SIGINT, {SIG_DFL}, {0x8087030,
[], SA_RESTORER, 0x4005aca8}, 8) = 0 <0.000007>
5236 0.000075 rt_sigaction(SIGQUIT, {SIG_DFL}, {SIG_IGN},
8) = 0 <0.000007>
5236 0.000057 rt_sigaction(SIGTERM, {SIG_DFL}, {SIG_IGN},
8) = 0 <0.000007>
5236 0.000058 rt_sigaction(SIGCHLD, {SIG_DFL}, {0x80776a0,
[], SA_RESTORER, 0x4005aca8}, 8) = 0 <0.000007>
5236 0.000262 open("/tmp/named_pipe", O_RDONLY|O_LARGEFILE)
= 3 <141.798572>
5236 141.798719 dup2(3, 0) = 0 <0.000008>
5236 0.000051 close(3) = 0 <0.000008>
5236 0.000167 open("/tmp/pipe.out.gz",
O_WRONLY|O_CREAT|O_TRUNC|O_LARGEFILE, 0666) = 3 <0.000329>
5236 0.000394 dup2(3, 1) = 1 <0.000007>
5236 0.000042 close(3) = 0 <0.000008>
5236 0.000127 execve("/usr//bin/gzip", ["gzip"]So 141.79 seconds after opening, the named pipe data was received,
evecve()executedgzip, and the data was compressed and redirected to the file/tmp/pipe.out.gz. Only at this point would thegzipprocess show up in thepslisting. So what was initially thought to be a hung process is simply a sleeping process waiting on data. - Now
ps -ef | grep gzipworks.$ ps -ef | grep 5236
chris 5236 5032 0 17:01 pts/4 00:00:00 gzip
Process Cores
Now that we have sufficiently covered structure and hangs as they pertain to Linux processes, let us move on to process core dumps. A core dump enables the user to visually inspect a process’s last steps. This section details how cores are created and how to best use them.
Signals
Process core dumps are initiated by the process receiving a signal. Signals are similar to hardware interrupts. As with interrupts, a signal causes a task to branch from its normal execution, handling a routine and returning to the point of interruption. Normal executing threads encounter signals throughout their life cycles. However, there are a finite number of signal types that result in a core dump, whereas other signal types result in process termination.
A process can receive a signal from three sources: the user, the process, or the kernel.
From the User
A user can send a signal in two ways: either using an external command such as kill or within a controlling tty, typing Ctrl+c to send a sigint as defined by stty -a. (Note that by definition, daemons do not have a controlling tty and therefore cannot be signaled in this manner.)
# stty -a
speed 9600 baud; rows 41; columns 110; line = 0;
intr = ^C; quit = ^; erase = ^?; kill = ^U; eof = ^D; eol = <undef>;
eol2 = <undef>; start = ^Q; stop = ^S;
From the Program
From a program, you can perform the raise() or alarm() system call, allowing a program to signal itself. Consider this example: a ten-second sleep without using the sleep call.
main()
{
alarm(10);
pause()
}
From the Kernel
The kernel can send a signal, such as SIGSEGV, to a process when it attempts an illegal action, such as accessing memory that it does not own or that is outside of its address range.
Linux supports two types of signals: standard and real-time. A complete overview of signals is outside the scope of this chapter; however, there are a few key differences to note. Standard signals have predefined meanings, whereas real-time signals are defined by the programmer. Additionally, only one standard signal of each type can be queued per process, whereas real-time signals can build up. An example of this was shown earlier in this chapter when a process was blocked on I/O. A kill -9 sigkill was sent to the process and placed in SigPnd.
SigPnd: 0000000000000100 <— A signal waiting to be processed, in this
case sigkill
In troubleshooting a process, a user might want to force a process to dump core. As stated, this is accomplished by sending the appropriate signal to the process. Sometimes after this step is taken, the dump does not follow because the process has not returned from an interrupt due to some other issue. The result is a pending signal that needs to be processed. Because the signals that result in a core are standard signals, sending the same signal multiple times does not work because subsequent signals are ignored until the pending signal has been processed. The pending signals are processed after the program returns from the interrupt but before proceeding to user space. This fact is illustrated in the entry.S source file, as shown in the following:
arch/i386/kernel/entry.S
...
ret_from_intr()
...
_reschedule()
...
_signal_return()
...
jsr do_signal ; arch/cris/kernel/signal.c
...
It is also possible to have difficulty achieving the dump because signals are being blocked (masked), caught, or ignored. An application might have signal handlers that catch the signal and perform their own actions. Signal blocking prevents the delivery of the signal to the process. Ignoring a signal just means that the process throws it away upon delivery. Additionally, the signal structure of a process is like any other structure in that the child inherits the parent’s configuration. That being stated, if a signal is blocked for the parent, the child of that process has the same signals blocked or masked. However, some signals cannot be masked or ignored, as detailed in the man page on signal. Two such signals are sigkill and sigstop.
The user can obtain a list of signals from the kill command. This yields a list of signals that the user can send to a process. Possible signals include the following (note that this is not a complete list):
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD
...
As mentioned earlier and illustrated next, the man page on signal details the signals that produce a core file.
$ man 7 signal
...
Signal Value Action Comment
-------------------------------------------------------------------------
SIGHUP 1 Term Hangup detected on controlling terminal
or death of controlling process
SIGINT 2 Term Interrupt from keyboard
SIGQUIT 3 Core Quit from keyboard
SIGILL 4 Core Illegal Instruction
SIGABRT 6 Core Abort signal from abort(3)
SIGFPE 8 Core Floating point exception
...
The source code on signal also provides this list as illustrated next:
linux/kernel/signal.c
...
#define SIG_KERNEL_COREDUMP_MASK (
M(SIGQUIT) | M(SIGILL) | M(SIGTRAP) | M(SIGABRT) |
M(SIGFPE) | M(SIGSEGV) | M(SIGBUS) | M(SIGSYS) |
M(SIGXCPU) | M(SIGXFSZ) | M_SIGEMT )
...
Limits
By default, most Linux distributions disable the creation of process core dumps; however, the user can enable this capability. The capability to create or not create core dumps is accomplished by the use of resource limits and the setting of a core file size. Users can display and modify their resource limits by using the ulimit command.
In this listing, we depict core dumps being disabled by displaying the user soft limits:
$ ulimit -a
core file size (blocks, -c) 0 <— COREs have been disabled
data seg size (kbytes, -d) unlimited
file size (blocks, -f) unlimited
max locked memory (kbytes, -l) unlimited
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4095
virtual memory (kbytes, -v) unlimited
There are two limits for each resource: a soft limit (shown previously) and a hard limit. The two limits differ in how they can be modified. The hard limit can be thought of as a ceiling that defines the maximum value of a soft limit. Users can change their hard limit only once, whereas they can change their soft limits to any values at any time as long as they do not exceed the hard limit.
Rerunning the ulimit command with the -Ha option as shown below, we see the hard limits for each resource.
$ ulimit -Ha
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
file size (blocks, -f) unlimited
max locked memory (kbytes, -l) unlimited
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
stack size (kbytes, -s) unlimited
cpu time (seconds, -t) unlimited
max user processes (-u) 4095
virtual memory (kbytes, -v) unlimited
A user can set a hard or soft limit to unlimited, as in the previous example. unlimited just means that the process does not have an artificial limit imposed by setrlimit. However, the kernel must represent “unlimited” with a value so that it has a manageable range. The program is limited by what the kernel can address or the physical limits of the machine, whichever comes first. Thus, even when set to unlimited, a limit exists. The 32-bit representation of unlimited (denoted “infinity”) is defined in sys_ia32.c as indicated next:
...
#define RLIM_INFINITY32 0xffffffff <-- Equals 4294967295 bytes ~ 4Gig
#define RESOURCE32(x) ((x > RLIM_INFINITY32) ? RLIM_INFINITY32 : x)
struct rlimit32 {
unsigned rlim_cur; <-- soft limit
unsigned rlim_max; <-- hard limit
};
...
Anytime a process dumps core and the resource limit core file size is anything other than zero, the kernel writes the core image. There are times, however, when user limits are set to low, resulting in a corrupt or unusable core image. If the core file resource limit is not adequate to accommodate the process’s core image, the kernel either does not produce a dump, truncates the dump, or attempts to save only the stack portion of the process’s context.
What occurs if the kernel is unable to create the dump depends on the type of executing process. Linux supports a multitude of executable formats. Originally, the a.out binary was used, which contains a magic number in its header. Traditionally, this magic number was used to characterize the binary type—for example, exec magic, demand magic, shared_mem magic, and so on. However, it was decided early on that the Executable and Linking Format (ELF) would be Linux’s default binary format because of its flexibility. Although AT&T defined the original ELF-32 binary format, UNIX System Laboratories performed the original development of this format. Later HP and INTEL defined the ELF-64 binary format. Today’s Linux systems contain very few, if any, a.out binaries, and support has been removed from the main kernel and placed into a module called binfmt_aout.o, which must be loaded before executing one of these binaries.
Referencing the binfmt source for each format details what action is taken in the event of a process attempting to produce a core file, as illustrated next.
The following snippet is from fs/binfmt_aout.c.
...
/* If the size of the dump file exceeds the rlimit, then see what would
happen
if we wrote the stack, but not the data area. */
...
The next snippet is from fs/binfmt_elf.c.
...
/*
* Actual dumper
*
* This is a two-pass process; first we find the offsets of the bits,
* and then they are actually written out. If we run out of core limit
* we just truncate.
*/
The Core File
After the core file is generated, we can use it to determine the reason for the core dump. First, we must identify the process that created the core and the signal that caused the process to die. The most common way of determining this information is through the file command. Next, we determine whether the program in question has had its symbols stripped. This information can be determined by executing the file command against the binary. As mentioned earlier, the core file is the process’s context, which includes the magic number or type of executable that created the core file. The file command uses a data file to keep track of file types, which by default is located in /etc/magic.
In Scenario 8-4, we show an example of a program with an easily reproducible hang. We can use tools such as gdb and other GNU debuggers/wrappers such as gstack to solve the problem.
Scenario 8-4: Using GDB to Evaluate a Process That Hangs
We use gdb to evaluate a core file created when a program was terminated because it hangs.
$ ll gmoo*
-rwxr-xr-x 1 chris chris 310460 Jan 2 20:25 gmoo.stripped*
-rwxr-xr-x 1 chris chris 321486 Jan 2 22:25 gmoo.not.stripped*
The file command informs us of the type of executable (defined in /etc/magic). In the previous example, we have one binary that hangs when executing.
It is helpful to determine the type of binary, as in the following example:
$ file gmoo.*
gmoo.not.stripped: ELF 32-bit LSB executable, Intel 80386, version 1
(SYSV), for GNU/Linux 2.2.5, dynamically linked (uses shared libs), not
stripped
gmoo.stripped: ELF 32-bit LSB executable, Intel 80386, version 1
(SYSV), for GNU/Linux 2.2.5, dynamically linked (uses shared libs),
stripped
When the command is hung, we send a kill -11 (SIGSEGV) to the program, causing the program to exit and dump core. An example of such a resulting core file follows:
$ file core.6753
core.6753: ELF 32-bit LSB core file Intel 80386, version 1 (SYSV), SVR4-
style, SVR4-style, from 'gmoo.stripped'
Using the GNU Project Debugger (GDB), we get the following:
$ gdb -q ./gmoo.striped ./core.6753
...
Core was generated by './gmoo.striped'.
Program terminated with signal 11, Segmentation fault.
Reading symbols from /usr/lib/libgtk-1.2.so.0...(no debugging symbols
found)...done.
Loaded symbols for /usr/lib/libgtk-1.2.so.0
Reading symbols from /usr/lib/libgdk-1.2.so.0...(no debugging symbols
found)...done.
Loaded symbols for /usr/lib/libgdk-1.2.so.0
Reading symbols from /usr/lib/libgmodule-1.2.so.0...(no debugging symbols
found)...done.
Loaded symbols for /usr/lib/libgmodule-1.2.so.0
Reading symbols from /usr/lib/libglib-1.2.so.0...(no debugging symbols
found)...done.
...
(gdb) backtrace
#0 0x4046b8e6 in connect () from /lib/i686/libpthread.so.0
#1 0x0806bef1 in gm_net_connect ()
#2 0x080853e1 in gm_world_connect ()
#3 0x0806c7cf in gm_notebook_try_add_world ()
#4 0x0806cd8c in gm_notebook_try_restore_status ()
#5 0x08061eab in main ()
#6 0x404c5c57 in __libc_start_main () from /lib/i686/libc.so.6
(gdb) list
No symbol table is loaded. Use the "file" command.
(gdb)
Without the source, we have gone about as far as we can. We must use other tools, such as strace, in combination with gdb. Other tool suites such as valgrind can also prove useful.
Now, let us look at an example of the same hang with a non-stripped version of the binary.
$ gdb -q ./gmoo.not.stripped ./core.6881
...
Core was generated by './gmoo.not.stripped'.
Program terminated with signal 11, Segmentation fault.
Reading symbols from /usr/lib/libgtk-1.2.so.0...done.
Loaded symbols for /usr/lib/libgtk-1.2.so.0
Reading symbols from /usr/lib/libgdk-1.2.so.0...done.
Loaded symbols for /usr/lib/libgdk-1.2.so.0
Reading symbols from /usr/lib/libgmodule-1.2.so.0...done.
...
(gdb) backtrace
#0 0x40582516 in poll () from /lib/i686/libc.so.6
(gdb)
Although the stack trace appears to be different, we have identified the root cause. The program is hung on a network poll call, which, according to the man page, is a structure made up of file descriptors. Using other tools, such as lsof, strace, and so on, we can determine exactly the network IP address upon which the process is hung.
Summary
As is apparent from the discussion in this chapter, the topic of process structure, hangs, and core files is a complex one. It is crucial to understand the process structure to troubleshoot hangs and most efficiently use core files. New troubleshooting tools are always being developed, so it is important to keep up with changes in this area. Although troubleshooting process hangs can be intimidating, as you can conclude from this chapter, it simply requires a step-by-step, methodical approach that, when mastered, leads to efficient and effective resolution practices.