
Chapter 5: Cross color dominant deep autoencoder for quality enhancement of laparoscopic video: A hybrid deep learning and range-domain filtering-based approach
Apurba Dasa,b; S.S. Shylajaa a Department of CSE, PES University, Bangalore, India
b Computer Vision (IoT), Tata Consultancy Services, Bangalore, India
Abstract
In minimally invasive surgery, laparoscopy video can be corrupted by haze, noise, oversaturated illumination, and other factors. These adverse internal environmental effects in turn impact the subsequent processing, such as segmentation, detection, and tracking the object or region of interest. Enhancement of each frame of video by considering color channels independently gives birth to unintended phantom colors due to its ignorance of the psychovisual correspondence. On the other hand, addressing each frame separately without honoring the interframe correspondence results in a video having impulsive transitions of psychovisual perception and unacceptable quality enhancement. To address all the aforementioned, we have proposed a novel algorithm to ensure enhancement of video with faster performance. The proposed cross color dominant deep autoencoder (C2D2A) uses the strength of (a) a bilateral filter that addresses the one-shot filtering of images both in the spatial neighborhood domain and psychovisual range; (b) a deep autoencoder that can learn salient patterns. The domain-based color sparseness has further improved the performance, modulating a classical deep autoencoder to a color dominant deep autoencoder. The work has shown promise not only as a generic framework of quality enhancement of video streams but also in addressing performance. This in turn improves the image/video analytics such as segmentation, detection, and tracking the objects or regions of interest.
Keywords
Laparoscopy; Endoscopy; Deep autoencoder; Color sparseness; Bilateral filtering
Acknowledgments
The authors would like to acknowledge Ms. Pallavi Saha, Mr. Shashidhar Pai, and Ms. Shormi Roy for their support in data annotation and cleaning.
1: Introduction
It has been well accepted (Stoyanov, 2012) that laparoscopic video streams are one of the best modalities for operating surgeons as far as the intraoperative data is concerned. Quality degradation due to multiple artifacts like haze, blood, nonuniform illumination, and specular reflection impacts not only the visibility of the surgeon but also the accuracy of image/video analytics. Haze is directly responsible for reducing the contrast of the surgical video stream. Hence, it is of the utmost importance to dehaze laparoscopic videos in guided surgery to ensure improved visualization of the operative field. Laparoscopic desmoking has been addressed in a few recent works (Kotwal et al., 2016; Baid et al., 2017; Tchakaa et al., 2017) that essentially utilized the idea of the dark channel prior (DCP) dehazing algorithm (He et al., 2011, 2013) for images, as depicted in Eq. (1):
where I is the observed intensity, J is the scene radiance, A is the global atmospheric light, and t is the medium transmission describing the light that reaches the camera without suffering from scatter due to dust or water particles in the medium. The goal of any dehazing algorithm is to extract the scene radiance J from a hazy input image I.
He et al. (2011) observed that, in outdoor environments, most of the local patches have lowest intensity in at least one color channel. Based on this observation, they proposed the DCP model, which has been considered to be the traditional model for dehazing an image since its publication. Later, the use of a guided filter (He et al., 2013) was proposed to improve the quality of the results. However, there is a basic difference between dehazing an outdoor scene and a laparoscopic video. Essentially, concentration of haze in an outdoor scene is dependent on scene depth whereas in laparoscopy the haze or smoke is a local phenomenon. Rather, it depends on the tip of the thermal cutting instrument. In laparoscopic surgery, the light source does not ensure uniform illumination nor is the organ surface Lambertian (which assures only defused reflection). These constraints violate the assumptions of Eq. (1). Wang et al. (2018) have analyzed the same and proposed a new algorithm considering two specialized properties of laparoscopic dehazing: haze has low contrast and low intrachannel differences. But most of the works until now, to the best of our knowledge, focussed on defogging images and completely ignored the intraframe correspondence in laparoscopic "video." Das et al. (2018a) and Das and Shylaja (2020) have proposed a fast bilateral filter using two different layers of adaptiveness to the filter for dehazing and deraining. In the current work, we exploit the property of intraframe correspondence in laparoscopic videos and dominance of cross color in the domain of organ surgery. This improves not only the clarity of vision but also further image analytics in distinctive detection/segmentation of the object of interest in near real time. The chapter is organized as follows. In Section 2, the fundamental idea of bilateral filtering is described. Next, in Section 3, the novel algorithm of a color dominant deep autoencoder is presented. Section 4 depicts the experimental results of cross color dominant deep autoencoder quality enhancement on laparoscopic video. Finally, our observations and findings are summarized in Section 5.
2: Range-domain filtering
Since the bilateral filter concept was proposed by Tomasi and Manduchi (1998), it has been a major area of contribution in the image processing and computer vision community. Consider a high-dimensional image ![]() and a guide image
and a guide image ![]() . Here d is the dimension of the domain, and n and ρ are dimensions of the ranges of the input image f and guide p, respectively. The output of the bilateral filter
. Here d is the dimension of the domain, and n and ρ are dimensions of the ranges of the input image f and guide p, respectively. The output of the bilateral filter ![]() is given as
is given as
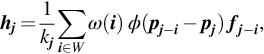
where
Here ![]() is the spatial kernel and
is the spatial kernel and ![]() is the range kernel. If f and p are different, then this filter is a cross-bilateral filter (Eisemann and Durand, 2004; Petschnigg et al., 2004).
is the range kernel. If f and p are different, then this filter is a cross-bilateral filter (Eisemann and Durand, 2004; Petschnigg et al., 2004).
The said filter is not only restricted to gray images but also extends the operations to color images with the promise to solve different applications in computer vision, such as dehazing and joint upsampling. Traditional spatial filtering is domain filtering, and enforces closeness by nonuniformly weighing neighboring pixel values. On the other hand, range filtering averages image values with weights that decay with dissimilarity in intensity. Range filtering is nonlinear and its output changes for every pixel to be filtered. The computations in Eqs. (2), (3) are performed over set W, which is a set of neighborhood pixels around the pixel of interest. Various examples of input f are discussed in Nair and Chaudhury (2017). The aforementioned variation of bilateral filters has been tested both for gray and color images and has shown superior enhancement ensuring edge preservation, as depicted in Figs. 1 and 2, respectively.

3: Cross color dominant deep autoencoder (C2D2A) leveraging color spareness and saliency
In the current work, we have leveraged the property of dimension reduction of the autoencoder (Chen and Lai, 2019) to extract the dominant color from the larger color range present in any image. The idea of sparse color occupancy for any group of images depicting the same object or action has been utilized further to create the dominant color map (DCM) offline as a table to be referenced in real time. The offline DCM table has next been used as an LUT for real-time processing, ensuring much faster bilateral filtering with respect to the state of art.
3.1: Evolution of DCM through C2D2A
The principal idea here is to determine dominant/salient colors from a group of homogeneous images (e.g., laparoscopic or endoscopic images; Ye et al., 2015). The dominant colors might be even interpolated colors of the quantized available colors in the image set. The autoencoder architecture, as depicted in Fig. 3, has been employed to determine the salient/dominant color for different groups of homogeneous images at a time with the objective of deriving a DCM (Das and Shylaja, 2021) in a coded and reduced dimension format, offline. This DCM further would be processed during image filtering. The proposed method of DCM derivation has the five following stages:
- 1. Imagification of weighted histogram as input to the autoencoder (C2D2A).
- 2. Unsupervised learning of DCM from large number of images for 1000 epochs.
- 3. Validating the converged DCM for unseen query image.
- 4. Hyperparameter tuning and retraining the C2D2A if the result of previous stage is unsatisfactory.
- 5. Freezing the C2D2A as offline look-up table (LUT) to be referred for primary path of bilateral image filtering.

In order to improve the speed of the bilateral image filtering, it is important to identify the dominant color from the sparse color occupancy in the entire color gamut. The process of histogram imagification and extracting the DCM are the activities to achieve the aforementioned target. First, the histograms of red, green, and blue color channels are calculated and normalized between 0 and 255, to be represented as the image shown in Fig. 4. The representation has been depicted in Eq. (4).
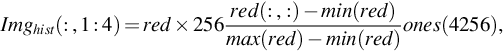
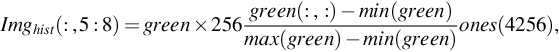
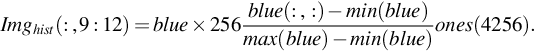

As described in Eq. (4), the color histogram has been imagified and repeated four times as four columns of Imghist(:, :) to enable the imagified weighted histogram to be consumed by the autoencoder (Fig. 3). One sample laparoscopic image and its imagified histogram has been shown in Fig. 4. For training the autoencoder to extract the DCM for laparoscopic/endoscopic images, 1000 laparoscopic images have been used for training samples. As depicted in the autoencoder architecture, the encoded form has dimension 64 × 3, which is the reduced dimension from the original dimension of 256 × 3. This dimensionality reduction is exactly 75% and the same could be reconstructed from the DCM as shown in Fig. 4D; this image was reconstructed by CDF linearization, an idea described by Das (2015). It can be observed that the specular reflection also was reasonably addressed in the reconstructed frame. In this case, the number 64 could be treated as the number of clusters having the dominant encoded color of the selected class images. The same can be interpolated to any other number of clusters. Fig. 4 also shows that the compromise of color is at the background of the scene, not at the region of interest. The reconstructed histogram (Fig. 4C) has a similar relative pattern to the input imagified histogram (Fig. 4B). This is only in the verification stage through CDF linearization.
3.2: Inclusion of DCM into principal flow of bilateral filtering
Based on clustering of sparse color space, Durand and Dorsey (2002) and Yang et al. (2009, 2015) have proposed to quantize the range space to approximate the filter using a series of fast spatial convolutions. Motivated by the aforementioned work, Nair and Chaudhury (2017) has proposed an algorithm based on clustering of the sparse color space. There the idea is to perform high-dimensional filtering on a cluster-by-cluster basis. For K number of clusters, where 1 ≤ k ≤ K,
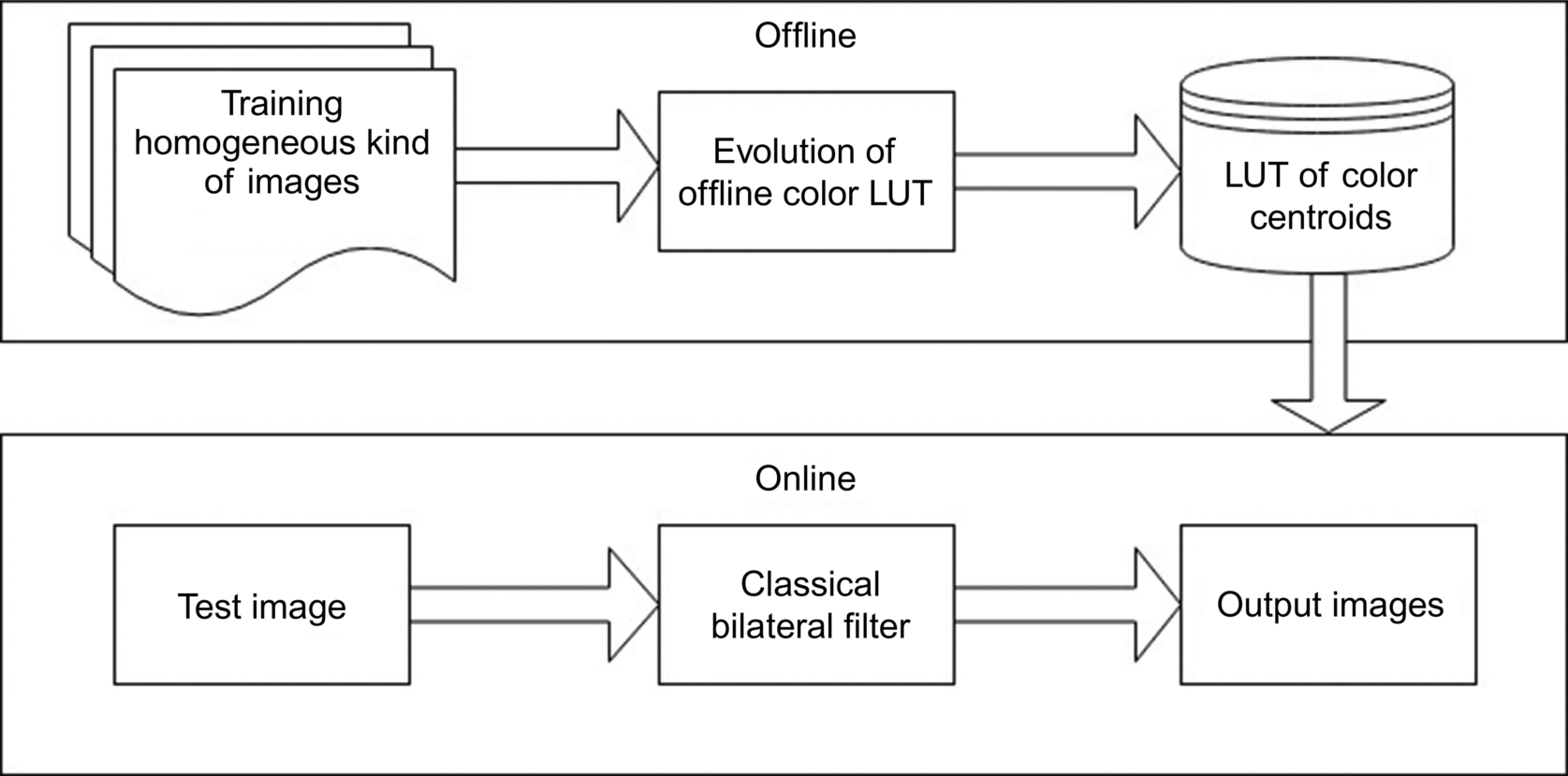
Here, Eqs. (5), (6) represent the numerator and denominator of Eqs. (2), (3) replacing pi by the cluster centroids μk. The scheme of hybridizing online and offline processing has been shown in Fig. 5. As the algorithm to construct the color LUT is working offline and the principal flow of filtering is operated in real time, the performance has been improved significantly, as presented in Das et al. (2018b).
4: Experimental results
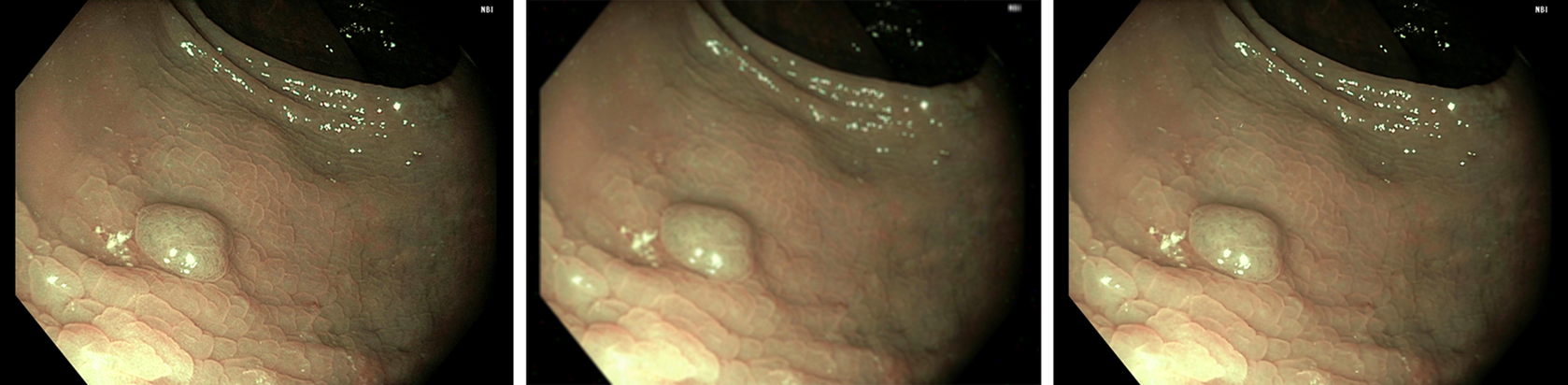
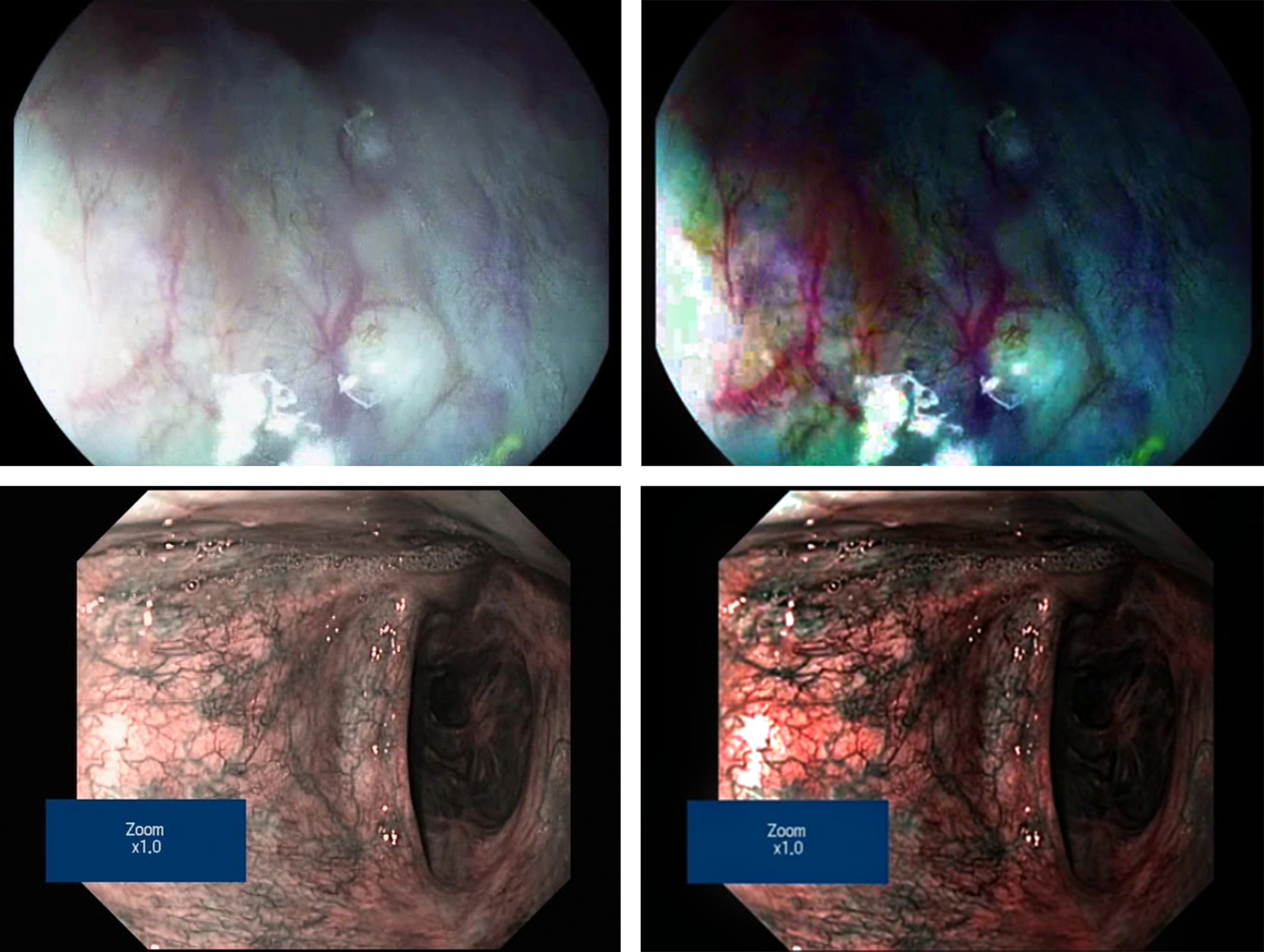
In the preceding sections, the necessity of dehazing in laparoscopic video has been established along with its challenges in achieving real-time performance, especially for videos. The idea (Das et al., 2018a) of key-frame identification, estimation of atmospheric and transmission parameters from key frames, and applying the aforementioned onto subsequent frames without further estimation computation would ensure fast processing, as shown in Table 1. The flow chart has been presented in Fig. 6. Both manual key-frame selection and dynamic automated key-frame detection have been employed to present the results. Finally, the laparoscopic video enhancement has been depicted through two sample frames in Fig. 7. Here, C2D2A-based dynamic bilateral filtering is applied on laparoscopic video (Ye et al., 2015). It is clearly observed that the enhancement of dominant colors ensures significant emphasis on the regions of veins and arteries. It is also observed that the unwanted noise could be cleaned without disturbing the detailing, edges, and thin lines in the video frame. This confirms the effectiveness of the proposed algorithm both in terms of quality of enhancement and performance.
Table 1
| Key-frame (KF) interval | Execution time (s) | FPS |
|---|---|---|
| All | 1359 | 0.5 |
| 3 | 525 | 1.3 |
| 5 | 395 | 1.8 |
| 10 | 200 | 3.5 |
| 15 | 161 | 4.4 |
| Dynamic (avg. = 22.5) | 147 | 4.8 |

5: Conclusion
For minimally invasive surgeries like laparoscopy and invasive medical procedures like endoscopy, the laparoscopic/endoscopic videos are well-accepted best modalities for analysis and inference. The quality of the aforementioned videos is largely deteriorated by haze, blood, etc., which in turn makes the quality of acquisition unacceptable. The current work focuses on efficient dehazing of laparoscopic/endoscopic videos addressing both quality and performance requirements. In the current chapter, we have discussed an algorithm of cross color dominant deep autoencoder (C2D2A)-based bilateral filtering, which enabled the method of video quality enhanement to achieve the aforementioned performance objective, too. We have presented promising results on the target modality of videos, showing the strength of a hybrid model of deep learning and bilateral filtering in medical video enhancement.