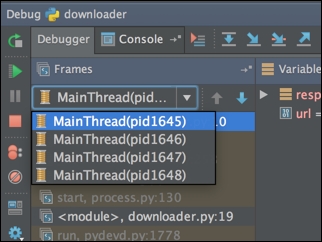
PyCharm has very good support for dealing with threads. Just like how we can change frames, we can also change threads if we so wish (that is, if we have more than one thread to begin with). Let's take the example of a simple downloader script called downloader.py:
# encoding=utf-8
from threading import Thread
import requests
def download(url):
response = requests.get(url)
if response.status_code == 200:
print "Success -> {:<75} | Length -> {}".format(response.url, len(response.content))
else:
print "Failure -> {:>75}".format(response.url)
if __name__ == '__main__':
urls = "http://www.google.com http://www.bing.com http://www.yahoo.com http://news.ycombinator.com".split()
for u in urls:
Thread(target=download, args=(u,)).start()This is a simple script that sends a get request to a url (there are four in total here), and each request is sent in its own thread. This simple script will demonstrate PyCharm's ability to debug threads. This is what the output looks similar to after an initial run:
$ python downloader.py Success -> http://www.google.com.bd/?gws_rd=cr&ei=1N_HVePAH9HiuQTHsLigDQ | Length -> 12559 Success -> http://www.bing.com/ | Length -> 58210 Success -> https://news.ycombinator.com/ | Length -> 27698 Success -> https://www.yahoo.com/ | Length -> 357013
It seems simple enough; we can now set a breakpoint after we check for a 200 status:
After we set the breakpoint, we can now debug the script, and we see that the debugger stops on every single thread.

The drop-down menu, indicated by the red arrow, allows us to jump between threads. The orange arrow indicates the URL (since that is what is used to create each new thread).
We can swap to a different thread and see a different URL.

In the preceding thread, a request is being sent to http://www.google.com, whereas in the previous one, the request was being sent to http://www.yahoo.com.
Processes are handled similarly in PyCharm. We will make only a small change to the preceding code—importing Process instead of Thread and starting Process instead of Thread:
# encoding=utf-8
from multiprocessing import Process
import requests
def download(url):
response = requests.get(url)
if response.status_code == 200:
print "Success -> {:<75} | Length -> {}".format(response.url, len(response.content))
else:
print "Failure -> {:>75}".format(response.url)
if __name__ == '__main__':
urls = "http://www.google.com http://www.bing.com http://www.yahoo.com http://news.ycombinator.com".split()
for u in urls:
Process(target=download, args=(u,)).start()If we try to debug this by setting the breakpoint at the same place, we get process IDs instead of thread numbers since we're creating processes.