
Information security is an important consideration when you decide to deploy any technology solution, and Microsoft Office SharePoint Server 2007 is certainly no exception. Protecting information and information systems from unauthorized use, modification, disruption, and destruction is fundamental to the success of your implementation. This chapter is not meant to be an exhaustive review of information security concepts and related theory, but rather an overview of key information security concepts and practical application of best practices within Office SharePoint Server 2007.
Confidentiality, integrity, and authenticity are core principals of information security. As we explore these key concepts and their related common objectives, it will be become apparent that many of the implementation vectors discussed here are mutually exclusive within the context of customer requirements and system constraints. Therefore, it’s important to consider both the policy and infrastructure ramifications of selecting a given alternative. We will discuss ways to approach each, so that you can make an objective comparison. Specifically, we will touch on the following:
Protection of confidential information has become an increasingly hot topic as our appetite for information exchange continues to grow in both volume and speed. But what does it mean to say that a given piece of information is confidential? When conditions exist, such as the expectation that provided information will be kept in confidence or made available only to a limited group, the information is generally considered confidential. This occurs every time we provide vendors, partners, or other individuals with information for a shared purpose, under the expectation that the information provided will be accessed only by persons who are authorized and only when they have a genuine need to do so.
Losing control of information provided in confidence can be disastrous! Recent security breaches involving the loss of confidential customer information have attracted the attention of both the general public and the media. Often, these events constitute a violation of privacy law, with far-reaching and often costly implications. Protection of private or confidential information is a priority concern of organizations working with such information.
The underlying motivators, which often create the expectation of confidentiality, are value and risk. When information is industrially sensitive, proprietary, or concerns matters of national security, it is often considered high-value information. Likewise, when information is considered private, or shared with the expectation of privacy or confidentiality, it is often considered high-risk information. In both cases, the information must be managed and secured commensurate to its value or risk.
Let’s assume that a confidential contract agreement with a strategic partner was intentionally or inadvertently made available on an Internet-facing Web site, thereby disclosing the detailed terms to the media or competition. Or perhaps the document was left open on an unattended computer display or thrown away without being shredded. What if a conniving caller managed to squeeze the details out of an employee? In each of these cases, sensitive information is now in the hands of someone who is not authorized to have it, which constitutes a breach of confidentiality.
SharePoint Server 2007 provides a multitude of security features which, when implemented in concert with well-understood information security policies, provide significant protection of confidential information. All content is rendered via a security-trimmed interface, which greatly reduces the potential exposure of confidential information. Users are allowed to read only information for which they have authorization. SharePoint Server 2007 also provides the capability to secure individual documents with unique permissions, which allows for more granular control of information throughout its life cycle. Information can be easily identified as confidential, secured accordingly, and audited as appropriate.
In order to properly secure information, we must first be able to identify its information classification. There are many different information classification schemes. Often, an organization already has a policy with predetermined information classes in place. These concepts are common to most information classification schemes as follows:
All information has an owner.
All information is classified as confidential by default.
The owner is responsible for updating the classification.
The owner is responsible for declaring who is allowed access to the information.
The owner is responsible for securing the information or for seeing that it is properly secured by the administrator.
The following classes are common to most information classification schemes:
Public
Internal
Confidential
Secret
Each of these classes would have its own policy for the storage, transmission, and disposal of information. The point of this section is not to prescribe any single set of classification definitions, but rather to convey that it is a best practice to implement a well-understood data classification scheme. This allows content being developed in the system to be readily classified and identified by users, who will in turn be able to handle the information appropriate to its sensitivity.
Content types are a central building block in SharePoint Server 2007 and provide the basis for the classification of data. Content types, as they relate to creating detailed information taxonomies, were covered earlier in this book in more detail. They are identified here as a preferred method for providing a simple yet extendable information classification capability to information owners. Let’s suppose we want to achieve the objectives outlined in the example classification policy described in the previous section.
More Info
For additional information regarding information architecture, refer to Chapter 7.
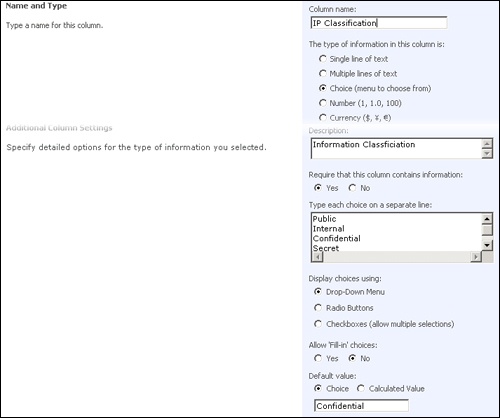
In order to implement the classification policy, we must set up the system so it can be used as would normally be expected, without requiring additional document library configuration steps on the behalf of end-users. Information owners should be required to fill or update a new field, "IP Classification" (shown in Figure 17-1), when adding or uploading a document. It should not be possible to store any document in the system without proper classification. Finally, all documents should be classified as confidential unless specified otherwise.
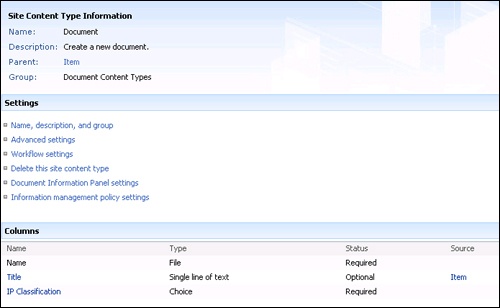
Content types provide an elegant alternative to making list column modifications to individual libraries. In addition to being unenforceable, traditional list column modifications would place an additional burden on users creating new libraries. By making similar settings changes to the pre-provided root Document content type (shown in Figure 17-2), we achieve multiple implementation advantages. Because the root Document content type is located at the top of the site collection, it can easily be protected from unwanted tampering by end-users. Such is the case for the additional site column we need to create as well. Additionally, changes made to the root Document content type can easily be rolled down to both existing and yet-to-be-created document libraries. This is important because it removes any need to customize these libraries or provide alternate custom list definitions (shown in Figure 17-3). Lastly, it ensures that any newly derived-content types created by subsite owners or users will also include the additional required field, which will be inherited from the Top-Level site, thereby protecting the content from modification or removal.
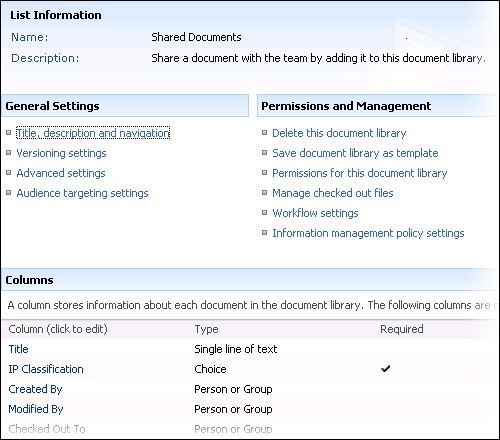
Lastly, let us consider how we might best achieve this effect on all new sites created within the implementation. This is a common goal of larger implementations where site collections are being created and disposed of on an ongoing basis. In order to accomplish this, we must create a new custom feature that can be activated through stapling. This ensures that creation of each new site includes activation of the new feature. We will then use the feature event receivers to perform the same activities in our code that we performed manually in the example.
Note
Stapling a feature is also known as Feature Site Template Association and allows for the activation of newly created custom features upon site creation when you use the associated template. You can also perform what is referred to as a Global Stapler, in which you associate to the Global template, thereby effectively stapling your new feature to all site types.