
While the exercise of designing for HA does not have to be complex, it does need to be thorough. We usually whiteboard our HA designs with customers, detailing all components of a SharePoint Server 2007 server farm including dependencies such as Active Directory, load balancers, SQL Server, storage, and network components. Whether you whiteboard this design or use another method, creating a visual representation of your overall architecture allows you to quickly see what you are trying to protect and make available. It also allows you to see where the most likely bottlenecks and faults will be in your design.
A basic HA SharePoint Server 2007 design might use Windows network load balancing (NLB) with two WFE servers, a single application server, and a SQL Server cluster. This is commonly referred to as a medium server farm and is the most commonly implemented architecture. Figure 21-1 is an example of a medium server farm.
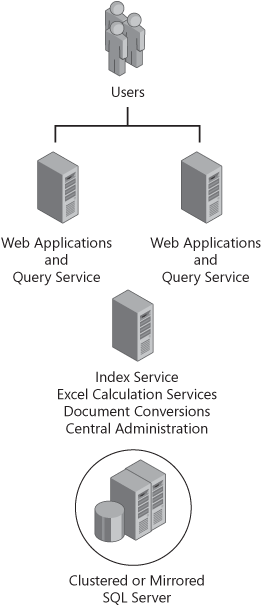
Using the medium server farm as a base topology, you can continue your design to meet your business needs. You could continue to add WFE servers, SQL Servers, multiple hardware load balancers (HLBs), switches, routers, Internet service providers (ISPs), or even failover datacenters! Some point between the medium server farm and the failover datacenter is where most medium-to-large implementations compromise. Your risk management plan and your organization’s willingness to invest in technology usually define at what point your implementation will be available. When designing for availability, it is helpful to design your server farm in components. You can then ensure HA as a whole by designing the components to be fault tolerant individually.
So, what’s the difference between fault tolerance and high availability? ITIL v3 defines fault tolerance as "the ability of an IT service or configuration item to continue to operate correctly after failure of a component part." Hard disk drive arrays, such as Random Array of Independent Disks (RAID), are a good example of fault tolerance. The disk array as a whole presents a single volume to the operating system. In most RAID configurations, a single disk failure within the array does not impact the entity presented to the operating system. See? The operating system has no knowledge that a disk failed. The volume presented to the operating system is fault tolerant.
HA is designing a service that hides or minimized the effect of a configuration item failure. ITIL v3 defines it as:
An approach or design that minimizes or hides the effects of configuration item failure on the users of an IT service. High availability solutions are designed to achieve an agreed level of availability and make use of techniques such as fault tolerance, resilience, and fast recovery to reduce the number of incidents, and the impact of incidents.
HA depends on the individual components of the system being fault tolerant. Remember that your SharePoint Server 2007 server farm is actually a system of systems (SoS). Your WFE server consists of many parts, such as memory, CPU, and disks. Your SQL Server instance may consist of multiple servers in a cluster. Each of these major components in your farm needs to be adequately fault tolerant, individually, to meet your overall system availability goals. The combination of each of these fault-tolerant components into a whole serves to form a unified service that can be highly available.
More Info
See Chapter 3, for more information on designing an SoS.
We consider your SQL Server components to be the most critical in your design. First, essentially all of your valuable content is stored in databases—the configuration database, Shared Services database, and all of your content databases. Second, without SQL Server, no number of WFE servers and applications servers will keep your solution available. There are several methods to architect SQL Server to be highly available, and each method comes with its own advantages and disadvantages.
One of the most common methods to provide fault tolerance of all databases at the SQL Server instance level is SQL Server clustering. Microsoft defines SQL Server failover clustering as follows:
A failover cluster is a combination of one or more nodes (servers) with two or more shared disks, known as a resource group. The combination of a resource group, along with its network name, and an internet protocol (IP) address that makes up the clustered application or server, is referred to as a failover cluster or a failover cluster instance. A SQL Server failover cluster appears on the network as if it were a single computer, but has functionality that provides failover from one node to another if the current node becomes unavailable. A failover cluster appears on the network as a normal application or single computer, but it has additional functionality that increases its availability.
SQL Server clustering provides one or more servers in groups of active and passive nodes. The active node acts as the current SQL Server for SharePoint Server 2007. You can have multiple active nodes in a cluster, but a smart implementation will have a single active node and single passive node for SharePoint Server 2007. The passive node is a warm standby SQL Server that can assume responsibility for the instance name. If you have experienced database administrators (DBAs) on staff or are a DBA yourself, you can implement your cluster any way you like as long as you test your solution.
To properly test a clustered SQL Server instance, we recommend loading a copy of your production data on the SQL Server instance to test, but never to test using live production data. If you do not yet have production SharePoint Server 2007 data, then use a tool such as SPSiteBuilder (available from CodePlex at http://www.codeplex.com/SPSiteBuilder) to pre-populate your farm with a sample amount of planned content. It is not enough to simply test active to passive node failover with small databases. Many of the complexities of SQL Server clustering appear with populated databases. Don’t forget to also test the failover of busy databases. SharePoint Server 2007 content databases often host very dynamic content, and the transaction logs can become quite large. This can negatively affect the failover of the SQL Server instance from the active node to the passive node. When the passive node takes control of the shared clustered disk, it must replay the transaction logs to bring the SQL Server instance content up to date. We have seen large content databases, whose logs are only truncated on a daily basis during backups, take several hours to come online. For this reason, you should carefully consider how often you are truncating logs. If you need a minimal RPO and a short RTO, you should consider SQL Server mirroring.
More Info
For more information on SQL Server clustering, including the operating system requirements, see http://technet.microsoft.com/en-us/library/ms189134.aspx.
Database mirroring is new to Microsoft SQL Server 2005 and requires Service Pack 1 or later. SQL Server mirroring sends transactions from the principal SQL Server to the mirror SQL Server, with these two servers called partners. Database mirroring has the primary advantage over SQL Server clustering in that logs do not have to replay. Basically, you can have automatic failover of data in almost real time. A witness server can monitor the principal SQL Server instance and automatically failover to the mirrored SQL Server instance for a principal failure.
More Info
For detailed information on SQL Server mirroring with SharePoint Server 2007, see http://go.microsoft.com/fwlink/?LinkId=83725&clcid=0x409. For detailed information on SQL Server 2005 mirroring, see http://www.microsoft.com/technet/prodtechnol/sql/2005/dbmirror.mspx.
But there is a disadvantage in that you must alias the SQL Server instance name, which was not supported when this book was published, or you must manually execute the stsadm.exe –o renameserver command and IISReset in every server in the farm. We expect aliasing the SQL Server instance to be supported, so it is covered here briefly. Most enterprise mirroring implementations (and there weren’t many when this was written) are using an alias to the SQL Server instance. Using an alias allows you to install SharePoint Server 2007 to a name such as SQLSP, with the actual SQL Server instance names being SQL01 and SQL02, as an example. Figure 21-2 shows a logical example what this mirroring looks like.

Why use an alias? SharePoint Server 2007 stores the database connection information in the configuration database. It contains a record of each content database and on what SQL Server instance that database is hosted. Additionally, each server in the farm has record of where the configuration database is stored and all content databases. If you choose to script your server farm to failover, you must IISReset all servers in the farm to update the application pool to content database association. This will read the new information from the previously executed stsadm.exe –o renameserver command and bring your Web applications back online.
More Info
For a free white paper on how to use the stsadm.exe command, visit the premium content area of Mindsharp’s Web site at http://www.mindsharp.com.
Unfortunately, at this time, Microsoft supports only a full farm replication from one instance to a mirrored instance. Microsoft does not support mirroring multiple principal SQL Server instances to multiple mirrored instances. While this may be a short-term limitation and outdated when you read this, we must state it. This means that you cannot leverage multiple SQL Server mirroring technologies to address a multi-tiered SLA, as shown in Table 21-2. While it is most certainly possible, you may have difficulty obtaining support from Microsoft Customer Support Services. Check TechNet to see the most recently supported SQL Server mirroring topologies.
Additionally, mirroring more than 20 databases may not be possible without a substantial hardware investment. Once again, be sure to test your solution with real data. If you need to test your solution with hundreds or thousands of user requests, refer to Chapter 23, for information on using Microsoft Visual Studio Team System 2008 for stress testing.
Transaction log shipping differs from database mirroring in that the SQL Server agent takes backups of the logs from the primary SQL Server instance and ships them to the secondary SQL Server instance. SQL Server mirroring is constant replication and done at the database engine level, not the agent level. This presents advantages and disadvantages with SQL Server mirroring. The obvious disadvantage is the lag in RPO between the two SQL Server instances. If the logs are only being shipped every 15 minutes, then you could lose the content in that time span. Second, you cannot have a witness server as you do with mirroring. So, there is not automatic failover. To failover a log-shipped server farm, you must manually update the server farm’s configuration for every content database. There are many others, but the last primary concern is that you cannot log-ship the configuration database, Central Administration content database, or Shared Services database. Yes, this has been done successfully, but it was not supported at the time this book was written.
Transaction log shipping does have some advantages. First, you can introduce an intentional delay for log shipping to provide a backup of user data. Second, you have the possibility of stopping replication during your introduced delay before a known database corruption is shipped. With SQL Server mirroring, everything is mirrored immediately, including data corruption and user errors. Third, multiple secondary SQL Server instances are supported when log shipping. This gives you the ability to send your content to more than one failover SQL Server instance and possibly support a multi-tiered SQL Server failover posture.
You should understand that this section was not meant to be a complete reference guide for SQL Server failover strategies. Depending on your business requirements, budget, and technical expertise, your solution will vary greatly. Remember, the most important part of your design is testing your solution before production use. Also remember to update your failover solution when your farm architecture changes. Examples of farm changes that require updates to your SQL Server failover solution include new Web applications, content databases, and Shared Services Providers (SSPs).
Once you have designed your SQL Server availability solution, you should next design availability for SharePoint Server 2007 farm members. Keep in mind that it is relatively easy to add new servers to a SharePoint Server 2007 farm. The farm = the configuration database, so simply install the binaries on a Windows Server system and connect to the server farm via the SharePoint Products and Technologies Configuration Wizard. We sometimes architect solutions with a warm server installed into a farm, with no server roles enabled, for the explicit purpose of rapid provisioning in the event that another farm member fails. The following section will cover some of the best practices for designing farm roles for high availability. Notice that we are designing for roles availability, such as Query, Index, and Web, and not individual servers. Because we can transfer roles between farm members, the physical location is not usually as important as the role itself.
The most visible server role to your users is the Windows SharePoint Services Web Application role, and a server with that role is a WFE server. This role provides the content-rendering capability of content from the database through Internet Information Services (IIS). When you create Web applications, this server role is responsible for copying the metabase and inetpub information contained in the configuration database to the WFE server.
If you stop this server role on a WFE server, you will notice that all SharePoint Server 2007–specific IIS Web applications and associated inetpub directories are automatically deleted. This is a double-edged sword. It is bad because any customizations directly in IIS, such as multiple host headers, assigned IP addresses, and secure sockets layer (SSL) certificate associations, are lost. Additionally, because the inetpub directories for those Web applications are also deleted, you lose any customizations to files contained therein, such as the commonly modified Web.config file. But we also use this to our advantage. If you really foul up your IIS configuration for a given Web application, restarting the Windows SharePoint Services Web application server will delete your IIS configuration for the farm and copy a new one back. Don’t forget to reassign IP addresses, add host headers, update modifications to the web.config, and reassociate SSL certificates when doing so.
To provide HA for the WFE server role, you need more than one server hosting this role. You then must provide fault tolerance through either Windows NLB or HLB. If you have a small implementation, Windows NLB may work fine for you.
More Info
Refer to http://technet2.microsoft.com/windowsserver/en/technologies/nlb.mspx for Windows Server 2003 NLB information, and http://technet2.microsoft.com/windowsserver2008/en/library/30eeb2ff-47ce-4a78-bf22-34b8db1967211033.mspx?mfr=true for Windows Server 2008 updated information.
If you have a non-trivial SharePoint Server 2007 implementation, you should strongly consider using HLB. HLB has proven to be more stable than NLB and a feature-rich platform for providing fault tolerance at the Web tier. Be careful not to design in single points of failure with your HLB solution. We have seen more than one customer with a single HLB appliance load balancing multiple WFE SharePoint Server 2007 servers. This single HLB hardware may provide better performance, but it will cause the entire Web tier to fail if the appliance breaks. Figure 21-3 shows a common enterprise example of load balancing the WFE server tier.

Figure 21-3. Use multiple switches, load balancers, and a WFE server for a truly redundant Web tier.
Somewhere, every organization must draw the line in its redundancy. You could have multiple routes to the Internet, supported by multiple routers and ISPs, multiple switches, datacenters, hardware load balancers, SQL Server instances, power grids, and storage frames. Only those that require multiple 9s will require such extreme HA measures. Be forewarned that large datacenter HA solutions are very expensive to build, and usually more expensive to maintain. In fact, unless all appropriate staff managing their respective components are well trained, you could actually make your solution less available due to administrative errors. Once again, thoroughly test your solution for failover and capacity before production deployment.
The index server role is the least flexible role in a SharePoint Server 2007 server farm. You cannot cluster the index server, and you can have only one copy of the index. For this reason, you should carefully choose and monitor the hardware you install for an Index role. One possible way to create a failover strategy might be hosting the Index role on a Windows Server 2008 Hyper-V system as a virtual machine. You can then fail the virtual machine to another host should there be a hardware failure. Be aware that this is not yet officially supported, so be sure to check before implementing!
If you design your farm for availability, however, losing the index server isn’t usually a catastrophic event. We usually install Central Administration on the index server, along with Excel Calculation Services and Document Conversions in a medium server farm. The most important service in your farm is often rendering Web content, so losing your index server isn’t immediately noticed. While you might lose the functionality of the application services on the server, your users can still access their valuable user content. If you host the query role on your WFE servers, users’ searches will work as well. Be aware that user queries will become stale rather quickly, so restoring your index server should be a priority. For this reason, query roles are not "true" fault tolerance for the index.
Be thoughtful when designing for search. First, we highly recommend moving the index to a dedicated drive or at least one other than the system disk. Your index can grow quite large and might fill up the system disk, causing a service outage. We often create an I: drive on index servers, with the index directory located in I:SSPName. You also need to carefully design for the search database. In fact, it is usually one of the two busiest databases in your farm, with the SSP database being the other. If you have a large or enterprise search strategy, you should create a dedicated spindle set on your SQL Server instance that will be dedicated to the search database.
If you lose your index server due to corruption or hardware failure, the best way to return to service is by restoring from backups. When requiring a speedy return to service, you should consider using disk-to-disk backups for your indexes. The best practice is to always use the native catastrophic backup tool [stsadm.exe –o backup –directory] to back up and restore your SSPs. You cannot back up only the search components. You must back up the entire SSP that manages that index. Therefore, the only way to restore the index is by restoring the SSP that managed it. While third-party tools might be able to back up and restore much of the farm, the only way we have found to reliably return indexing to its previous state was through the native tools. This isn’t to say that there isn’t a third-party tool that will do it successfully; there just wasn’t when this book was written. You can safely assume a best practice is testing the restoral of your SSPs.
The query role can he hosted on any server in the farm, including the index server. But if you will have more than one query server, you cannot host the query role on the index server. If you do, your index will never propagate to the other query servers in the farm. Other than this limitation, you can technically place the query role where you want. But, there are some design considerations to think about.
First, the index is continuously propagated from the index server to the query servers via a file share on the query servers. When you scale out to multiple query servers, you are prompted for this file share creation on the Service Initiation page. Thus, you must have the correct network ports open between the index server and all query servers for file sharing. Otherwise, the shadow index will never propagate. If you will build large indexes, then consider gigabit Ethernet as a design requirement between server farm members. Second, with two or three WFE servers, we generally place the query role on all WFE servers. Be aware that query servers also communicate with the search database and can generate a substantial amount of SQL Server traffic on a busy farm.
It is quite possible to have servers in your SharePoint Server 2007 server farm that only host the query role. This is rare and is usually done to support a Web tier of more than three servers or when you have very large indexes. Figure 21-4 shows an example of an enterprise server farm with dedicated query servers.
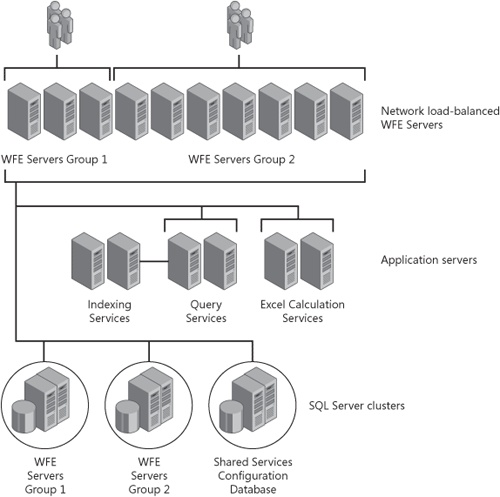
In medium and large server farms, you will usually create a substantial amount of network traffic and negate the processing advantages of dedicated query role hosting. We primarily move the query role to dedicated servers to reduce the replication of the content index. If you have a very large content index, it is now replicated to all query servers in the farm, as well as being hosted on the index server. If you have five WFE servers and all the servers host the query role, you now have the index on disk six times. Offloading this disk storage from all WFEs is the primary reason for using dedicated query servers.
Excel Calculation Services is basically self configuring when it comes to HA. The act of starting the service in Central Administration notifies the configuration database that the server hosts the role. The other farm members will see that configuration update and automatically use the server for Excel Services processing. In fact, multiple Excel Calculation Services servers will load balance with no input from you. That’s nice. Be aware, however, that a heavily used Excel Calculations Services configuration will quickly consume hardware resources. If you are planning for HA and know you will need Excel Calculations Services, carefully monitor the CPU on those servers hosting the role. If you were to implement a warm server that is not hosting any roles but is joined to the server farm, you can quickly and easily add additional Excel Calculation Services horsepower to your solution.
Document conversions are also straightforward when you design for availability. You should first define an application server as the load balancer for the farm. This is not required when defining a single server to the document conversions role. Only those organizations that will heavily use the document conversion process will need multiple application servers for that role. If required, you must first assign the document conversions load balancer role, as seen in Figure 21-5.

After you have started the load balancer service, you can then enable multiple servers in the farm with the role. While we almost never start the role on WFE servers, the WFE server must have communications opened to the document conversions load balancer, and document conversions servers.
Note
The document conversions service runs as a local machine account. While we never recommend running SharePoint Server 2007 on a domain controller for production use, many developers and administrators test applications in a virtualized, single-server environment. Be aware whether this single-server environment includes a domain controller; if it does, you will not be able to test or use document conversions.
Central Administration is not required for your farm to be available. It is basically a graphical tool to manage your farm. Central Administration is a dedicated Web application, with a site collection in the root managed path. In other words, it exists in the content database. You can quickly enable any server in the farm to host the visual interface, an IIS Web application, to render the site collection. Therefore, its placement completely depends on your design.
For security purposes, we generally do not place Central Administration on servers that render Web content to users. But you can quickly provision Central Administration on any farm member by running the SharePoint Products and Technologies Configuration Wizard (psconfigui.exe) or via psconfig.exe.
Note
The command to provision Central Administration is psconfig.exe -cmd adminvs -provision -port <TCP Port> -windowsauthprovider onlyusentlm. Psconfig.exe is in the SharePoint Root directory, also called the 12 hive. Note that this example uses NTLM as the Windows authentication provider. You may need to change the syntax to suit your environment.