
CHAPTER |
|
8 |
Stored Procedures and User-Defined Functions |
In This Chapter
This chapter introduces batches and routines. A batch is a sequence of Transact-SQL statements and procedural extensions. A routine can be either a stored procedure or a user-defined function (UDF). The beginning of the chapter introduces all procedural extensions supported by the Database Engine. After that, procedural extensions are used, together with Transact-SQL statements, to show how batches can be implemented. A batch can be stored as a database object, as either a stored procedure or a UDF. Some stored procedures are written by users, and others are provided by Microsoft and are referred to as system stored procedures. In contrast to user-defined stored procedures, UDFs return a value to a caller. All routines can be written either in Transact-SQL or in another programming language such as C# or Visual Basic.
Procedural Extensions
The preceding chapters introduced Transact-SQL statements that belong to the data definition language and the data manipulation language. Most of these statements can be grouped together to build a batch. As previously mentioned, a batch is a sequence of Transact-SQL statements and procedural extensions that are sent to the Database Engine for execution together. The number of statements in a batch is limited by the size of the compiled batch object. The main advantage of a batch over a group of singleton statements is that executing all statements at once brings significant performance benefits.
There are a number of restrictions concerning the appearance of different Transact-SQL statements inside a batch. The most important is that the data definition statements CREATE VIEW, CREATE PROCEDURE, and CREATE TRIGGER must each be the only statement in a batch.
NOTE To separate DDL statements from one another, use the GO statement.
The following sections describe each procedural extension of the Transact-SQL language separately.
Block of Statements
A block allows the building of units with one or more Transact-SQL statements. Every block begins with the BEGIN statement and terminates with the END statement, as shown in the following example:

A block can be used inside the IF statement to allow the execution of more than one statement, depending on a certain condition (see Example 8.1).
IF Statement
The Transact-SQL statement IF corresponds to the statement with the same name that is supported by almost all programming languages. IF executes one Transact-SQL statement (or more, enclosed in a block) if a Boolean expression, which follows the keyword IF, evaluates to TRUE. If the IF statement contains an ELSE statement, a second group of statements can be executed if the Boolean expression evaluates to FALSE.
NOTE Before you start to execute batches, stored procedures, and UDFs in this chapter, re-create the entire sample database.
Example 8.1

Example 8.1 shows the use of a block inside the IF statement. The Boolean expression in the IF statement,

is evaluated to TRUE for the sample database. Therefore, the single PRINT statement in the IF part is executed. Notice that this example uses a subquery to return the number of rows (using the COUNT aggregate function) that satisfy the WHERE condition (project_no='p1'). The result of Example 8.1 is
![]()
NOTE The ELSE part of the IF statement in Example 8.1 contains two statements: PRINT and SELECT. Therefore, the block with the BEGIN and END statements is required to enclose the two statements. (The PRINT statement is another statement that belongs to procedural extensions; it returns a user-defined message.)
WHILE Statement
The WHILE statement repeatedly executes one Transact-SQL statement (or more, enclosed in a block) while the Boolean expression evaluates to TRUE. In other words, if the expression is true, the statement (or block) is executed, and then the expression is evaluated again to determine if the statement (or block) should be executed again. This process repeats until the expression evaluates to FALSE.
A block within the WHILE statement can optionally contain one of two statements used to control the execution of the statements within the block: BREAK or CONTINUE. The BREAK statement stops the execution of the statements inside the block and starts the execution of the statement immediately following this block. The CONTINUE statement stops the current execution of the statements in the block and starts the execution of the block from its beginning.
Example 8.2 shows the use of the WHILE statement.
Example 8.2
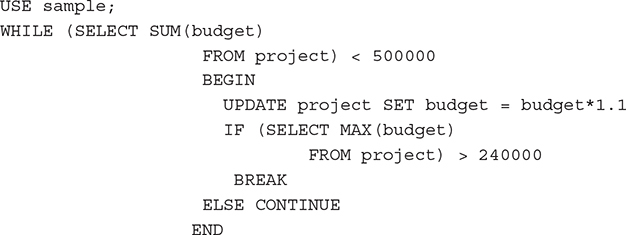
In Example 8.2, the budget of all projects will be increased by 10 percent until the sum of budgets is greater than $500,000. However, the repeated execution will be stopped if the budget of one of the projects is greater than $240,000. The execution of Example 8.2 gives the following output:

NOTE If you want to suppress the output, such as that in Example 8.2 (indicating the number of affected rows in SQL statements), use the SET NOCOUNT ON statement.
Local Variables
Local variables are an important procedural extension to the Transact-SQL language. They are used to store values (of any type) within a batch or a routine. They are “local” because they can be referenced only within the same batch in which they were declared. (The Database Engine also supports global variables, which are described in Chapter 4.)
Every local variable in a batch must be defined using the DECLARE statement. (For the syntax of the DECLARE statement, see Example 8.3.) The definition of each variable contains its name and the corresponding data type. Variables are always referenced in a batch using the prefix @. The assignment of a value to a local variable is done:
• Using the special form of the SELECT statement
• Using the SET statement
• Directly in the DECLARE statement using the = sign (for instance, @extra_budget MONEY = 1500)
The usage of the first two assignment statements for a value assignment is demonstrated in Example 8.3. The batch in this example calculates the average of all project budgets and compares this value with the budget of all projects stored in the project table. If the latter value is smaller than the calculated value, the budget of project p1 will be increased by the value of the local variable @extra_budget. We will implement this batch in two different ways. Example 8.3a uses Transact-SQL statements only.
Example 8.3a (using T-SQL only)

In Example 8.3a only T-SQL statements have been used. The sole use of these statements guarantees that all retrieved rows, independent of their number, will be sent to the system to process them at the same time. (This is called set-oriented processing.)
Example 8.3b applies a concept called cursors.
Example 8.3b (using cursor)

In Example 8.3b, the cursor feature is used to solve the same problem as in Example 8.3a. The main difference between these two solutions is that 8.3b retrieves each row from the result separately; i.e., in this case the system processes one record (row) at a time. (For this reason, the type of processing is called record-oriented processing.)
Before discussing the differences between set-oriented processing and record-oriented processing using cursors, I will explain the cursor features in Example 8.3b.
Generally, there are several steps in creating and using cursors in batches and stored procedures. First, you declare your cursor by using the DECLARE statement and assigning the CURSOR data type. After that, you use the SET statement to assign the set of rows, which will be retrieved (one by one) with the cursor. This is followed by opening the cursor using the OPEN statement. Immediately after the OPEN statement is executed, the cursor points before the first row of the selected set of rows.
Now the data processing starts. To move the cursor to the first row in the result set, you use the FETCH NEXT statement:
![]()
This statement fetches a record from the result set and assigns values retrieved with the SELECT statement to the variables @pr_nr and @budget, respectively. The THEN part of the IF statement uses the fetched values to calculate the average of all project budgets and compare the average value with the budget of the particular project.
The WHILE statement uses the system function called @@FETCH_STATUS to create a loop, which will be terminated when all records from the result set are processed. (In other words, this system function returns the status of the last cursor FETCH statement issued against any cursor currently opened by the connection. The return value 0 means that the FETCH statement was successful, while –1 specifies that the record (row) was beyond the result set.)
Once all the data has been processed, you use the CLOSE statement to close the cursor. Finally, the DEALLOCATE statement deallocates the particular cursor. The difference between CLOSE and DEALLOCATE is that after the CLOSE statement is executed, you can still reopen the cursor, whereas after the execution of the DEALLOCATE statement, the link between the cursor and the result set is abandoned. (The explicit use of the DEALLOCATE statement is highly recommended, because that way you release all of the internal resources.)
NOTE Do not use the implementation with CURSOR unless absolutely necessary. The record-oriented processing of rows is significantly slower than the set-oriented processing. The more rows that have to be processed, the better performance you will achieve with set-oriented processing.
Miscellaneous Procedural Statements
The procedural extensions of the Transact-SQL language also contain the following statements:
• RETURN
• GOTO
• RAISEERROR()
• WAITFOR
The RETURN statement has the same functionality inside a batch as the BREAK statement inside WHILE. This means that the RETURN statement causes the execution of the batch to terminate and the first statement following the end of the batch to begin executing.
The GOTO statement branches to a label, which stands in front of a Transact-SQL statement within a batch. The RAISERROR() statement generates a user-defined error message and sets a system error flag. A user-defined error number must be greater than 50000. (All error numbers <= 50000 are system defined and are reserved by the Database Engine.) The error values are stored in the global variable @@error. (Example 17.3 shows the use of the RAISERROR() statement.)
The WAITFOR statement defines either the time interval (if the DELAY option is used) or a specified time (if the TIME option is used) that the system has to wait before executing the next statement in the batch. The syntax of this statement is
![]()
The DELAY option tells the database system to wait until the specified amount of time has passed. TIME specifies a time in one of the acceptable formats for temporal data. TIMEOUT specifies the amount of time, in milliseconds, to wait for a message to arrive in the queue. (Example 13.8 shows the use of the WAITFOR statement.)
Exception Handling with TRY, CATCH, and THROW
The Database Engine supports two statements, TRY and CATCH, to capture and handle exceptions. An exception is a problem (usually an error) that prevents the continuation of a program. In other words, an unhandled exception prevents the application from continuing. In the case of a handled exception, the existing problem will be relegated to another part of the program, which will handle the exception.
The role of the TRY statement is to capture the exception. (Because this process usually comprises several statements, the term “TRY block” typically is used instead of “TRY statement.”) If an exception occurs within the TRY block, the part of the system called the exception handler delivers the exception to the other part of the program, which will handle the exception. This program part is denoted by the keyword CATCH and is therefore called the CATCH block.
NOTE You can handle errors using the @@error global variable (see Example 13.1), but exception handling using the TRY and CATCH statements is the common way modern programming languages like C# and Java treat errors.
Exception handling with the TRY and CATCH blocks gives a programmer a lot of benefits, such as:
• Exceptions provide a clean way to check for errors without cluttering code.
• Exceptions provide a mechanism to signal errors directly rather than using some side effects.
• Exceptions can be seen by the programmer and checked during the compilation process.
The third statement in relation to handling errors is THROW. This statement allows you to throw an exception caught in the exception handling block. Simply stated, the THROW statement is another return mechanism, which behaves similarly to the already described RAISERROR() statement.
Example 8.4 shows how exception handling with the TRY/CATCH/THROW works. It shows how you can use exception handling to insert all statements in a batch or to roll back the entire statement group if an error occurs. The example is based on the referential integrity between the department and employee tables. For this reason, you have to create both tables using the PRIMARY KEY and FOREIGN KEY clauses, as done in Example 5.11.
Example 8.4

After the execution of the batch in Example 8.4, all three statements in the batch won’t be executed at all, and the output of this example is

The execution of Example 8.4 works as follows. The first INSERT statement is executed successfully. Then, the second statement causes the referential integrity error. Because all three statements are written inside the TRY block, the exception is “thrown” and the exception handler starts the CATCH block. CATCH rolls back all statements and prints the corresponding message. After that the THROW statement returns the execution of the batch to the caller. For this reason, the content of the employee table won’t change.
NOTE The statements BEGIN TRANSACTION, COMMIT TRANSACTION, and ROLLBACK are Transact-SQL statements concerning transactions. These statements start, commit, and roll back transactions, respectively. See Chapter 13 for the discussion of these statements and transactions generally.
Example 8.5 shows the batch that supports server-side paging (for the description of server-side paging, see Chapter 6).
Example 8.5

The batch in Example 8.5 uses the AdventureWorks database and its Employee table (from the HumanResources schema) to show how generic server-side paging can be implemented. The @Pagesize variable is used with the FETCH NEXT statement to specify the number of rows per page (20, in this case). The other variable, @CurrentPage, specifies which particular page should be displayed. In this example, the content of the third page will be displayed. (The result is not shown because it is too lengthy.)
Stored Procedures
A stored procedure is a special kind of batch written in Transact-SQL, using the SQL language and its procedural extensions. The main difference between a batch and a stored procedure is that the latter is stored as a database object. In other words, stored procedures are saved on the server side to improve the performance and consistency of repetitive tasks.
The Database Engine supports stored procedures and system procedures. Stored procedures are created in the same way as all other database objects—that is, by using the DDL. System procedures are provided with the Database Engine and can be used to access and modify the information in the system catalog. This section describes (user-defined) stored procedures, while system procedures are explained in Chapter 9.
When a stored procedure is created, an optional list of parameters can be defined. The procedure accepts the corresponding arguments each time it is invoked. Stored procedures can optionally return a value that displays the user-defined information or, in the case of an error, the corresponding error message.
A stored procedure is precompiled before it is stored as an object in the database. The precompiled form is stored in the database and used whenever the stored procedure is executed. This property of stored procedures offers an important benefit: the repeated compilation of a procedure is (almost always) eliminated, and the execution performance is therefore increased. This property of stored procedures offers another benefit concerning the volume of data that must be sent to and from the database system. It might take less than 50 bytes to call a stored procedure containing several thousand bytes of statements. The accumulated effect of this savings when multiple users are performing repetitive tasks can be quite significant.
NOTE Stored procedures can be natively compiled, meaning that the particular procedure is compiled when it is created, rather than when it is executed. This special form of stored procedures is described in Chapter 21 (see Example 21.7).
Creation and Execution of Stored Procedures
Stored procedures are created with the CREATE PROCEDURE statement, which has the following syntax:

schema_name is the name of the schema to which the ownership of the created stored procedure is assigned. proc_name is the name of the new stored procedure. @param1 is a parameter, while type1 specifies its data type. The parameter in a stored procedure has the same logical meaning as the local variable for a batch. Parameters are values passed from the caller of the stored procedure and are used within the stored procedure. default1 specifies the optional default value of the corresponding parameter. (Default can also be NULL.)
The OUTPUT option indicates that the parameter is a return parameter and can be returned to the calling procedure or to the system (demonstrated a bit later in Example 8.9).
As you already know, the precompiled form of a procedure is stored in the database and used whenever the stored procedure is executed. If you want to generate the compiled form each time the procedure is executed, use the WITH RECOMPILE option.
NOTE The use of the WITH RECOMPILE option destroys one of the most important benefits of the stored procedures: the performance advantage gained by a single precompilation. For this reason, the WITH RECOMPILE option should be used only when database objects used by the stored procedure are modified frequently or when the parameters used by the stored procedure are volatile.
The EXECUTE AS clause specifies the security context under which to execute the stored procedure after it is accessed. By specifying the context in which the procedure is executed, you can control which user account the Database Engine uses to validate permissions on objects referenced by the procedure.
By default, only the members of the sysadmin fixed server role, and the db_owner and db_ddladmin fixed database roles, can use the CREATE PROCEDURE statement. However, the members of these roles may assign this privilege to other users by using the GRANT CREATE PROCEDURE statement. (For the discussion of user permissions, fixed server roles, and fixed database roles, see Chapter 12.)
Example 8.6 shows the creation of the simple stored procedure for the project table.
Example 8.6

NOTE The GO statement is used to separate two batches. (The CREATE PROCEDURE statement must be the first statement in the batch.)
The stored procedure increase_budget increases the budgets of all projects for a certain percentage value that is defined using the parameter @percent. The procedure also defines the default value (5), which is used if there is no argument at the execution time of the procedure.
NOTE It is possible to create stored procedures that reference nonexistent tables. This feature allows you to debug procedure code without creating the underlying tables first, or even connecting to the target server.
In contrast to “base” stored procedures that are placed in the current database, it is possible to create temporary stored procedures that are always placed in the temporary system database called tempdb. You might create a temporary stored procedure to avoid executing a particular group of statements repeatedly within a connection. Analogous to local and global temporary tables, you can create local or global temporary procedures by preceding the procedure name with a single pound sign (#proc_name) for local temporary procedures and a double pound sign (##proc_name) for global temporary procedures. A local temporary stored procedure can be executed only by the user who created it, and only during the same connection. A global temporary procedure can be executed by all users, but only until the last connection executing it (usually the creator’s) ends.
The life cycle of a stored procedure has two phases: its creation and its execution. Each procedure is created once and executed many times. The EXECUTE statement executes an existing procedure. The execution of a stored procedure is allowed for each user who either is the owner of or has the EXECUTE privilege for the procedure (see Chapter 12). The EXECUTE statement has the following syntax:

All options in the EXECUTE statement, other than return_status, have the equivalent logical meaning as the options with the same names in the CREATE PROCEDURE statement. return_status is an optional integer variable that stores the return status of a procedure. The value of a parameter can be assigned using either a value (value) or a local variable (@variable). The order of parameter values is not relevant if they are named, but if they are not named, parameter values must be supplied in the order defined in the CREATE PROCEDURE statement.
The DEFAULT clause supplies the default value of the parameter as defined in the procedure. When the procedure expects a value for a parameter that does not have a defined default and either a parameter is missing or the DEFAULT keyword is specified, an error occurs.
NOTE When the EXECUTE statement is the first statement in a batch, the word “EXECUTE” can be omitted from the statement. Despite this, it would be safer to include this word in every batch you write.
Example 8.7 shows the use of the EXECUTE statement.
Example 8.7
![]()
The EXECUTE statement in Example 8.7 executes the stored procedure increase_budget (Example 8.6) and increases the budgets of all projects by 10 percent each.
Example 8.8 shows the creation of a procedure that references the tables employee and works_on.
Example 8.8

The procedure modify_empno in Example 8.8 demonstrates the use of stored procedures as part of the maintenance of the referential integrity (in this case, between the employee and works_on tables). Such a stored procedure can be used inside the definition of a trigger, which actually maintains the referential integrity (see Example 14.3). To execute this procedure, use the EXECUTE statement and assign values to both input parameters, @old_no and @new_no.
Example 8.9 shows the use of the OUTPUT clause.
Example 8.9

This stored procedure can be executed using the following batch:
![]()
The preceding example contains the creation of the delete_emp procedure as well as its execution. This procedure calculates the number of projects on which the employee (with the employee number @employee_no) works. The calculated value is then assigned to the @counter parameter. After the deletion of all rows with the assigned employee number from the employee and works_on tables, the calculated value will be assigned to the @quantity variable.
NOTE The value of the parameter will be returned to the calling procedure if the OUTPUT option is used. In Example 8.9, the delete_emp procedure passes the @counter parameter to the calling statement, so the procedure returns the value to the system. Therefore, the @counter parameter must be declared with the OUTPUT option in the procedure as well as in the EXECUTE statement.
The EXECUTE Statement with RESULT SETS Clause
Using the WITH RESULT SETS clause for the EXECUTE statement, you can change conditionally the form of the result set of a stored procedure.
The following two examples help to explain this clause. Example 8.10 is an introductory example that shows how the output looks when the WITH RESULT SETS clause is omitted.
Example 8.10

employees_in_dept is a simple stored procedure that displays the numbers and family names of all employees working for a particular department. (The department number is a parameter of the procedure and must be specified when the procedure is invoked.) The result of this procedure is a table with two columns, named according to the names of the corresponding columns (emp_no and emp_lname). To change these names (and their data types, too), use the WITH RESULTS SETS clause (see Example 8.11).
Example 8.11

The output is

As you can see, the WITH RESULT SETS clause in Example 8.11 allows you to change the name and data types of columns displayed in the result set. Therefore, this functionality gives you the flexibility to execute stored procedures and display the output result sets in another form.
NOTE The Database Engine provides capabilities to create temporary stored procedures, too. The semantics of temporary stored procedures is the same as the semantics of the temporary tables. In other words, a scope and lifetime of temporary stored procedures is for the duration of a session, and you use the symbol # as a prefix to specify temporary stored procedures.
Changing the Structure of Stored Procedures
The Database Engine also supports the ALTER PROCEDURE statement, which modifies the structure of a stored procedure. The ALTER PROCEDURE statement is usually used to modify Transact-SQL statements inside a procedure. All options of the ALTER PROCEDURE statement correspond to the options with the same name in the CREATE PROCEDURE statement. The main purpose of this statement is to avoid reassignment of existing privileges for the stored procedure.
A stored procedure is removed using the DROP PROCEDURE statement. Only the owner of the stored procedure and the members of the db_owner and sysadmin fixed roles can remove the procedure.
User-Defined Functions
In programming languages, there are generally two types of routines:
• Stored procedures
• User-defined functions (UDFs)
As discussed in the previous major section of this chapter, stored procedures are made up of several statements that have zero or more input parameters but usually do not return any output parameters. In contrast, functions always have one return value. This section describes the types of UDFs and the creation and use of UDFs.
Types of User-Defined Functions
User-defined functions can be
• Scalar
• Table-valued
The return value of scalar functions is always a single value. Scalar functions are generally used within a query. Also, scalar functions can be called using the EXECUTE statement, the same way as stored procedures. (An example of a scalar UDF is given in the upcoming “Scalar UDF Inlining” section.)
A table-valued function is a user-defined function that returns data of a table type. The return type of a table-valued function is a table. For this reason, you can use the table-valued function just like you would use a table. (A detailed description of these functions is given in the upcoming “Table-Valued Functions” section.)
Creation and Execution of User-Defined Functions
UDFs are created with the CREATE FUNCTION statement, which has the following syntax:

schema_name is the name of the schema to which the ownership of the created UDF is assigned. function_name is the name of the new function. @param is an input parameter, while type specifies its data type. Parameters are values passed from the caller of the UDF and are used within the function. default specifies the optional default value of the corresponding parameter. (Default can also be NULL.)
The RETURNS clause defines a data type of the value returned by the UDF. This data type can be any of the standard data types supported by the database system, including the TABLE data type. (The only standard data type that you cannot use is TIMESTAMP.)
UDFs are either scalar-valued or table-valued. A scalar-valued function returns an atomic (scalar) value. This means that in the RETURNS clause of a scalar-valued function, you specify one of the standard data types. Functions are table-valued if the RETURNS clause returns a set of rows (see the next subsection).
The WITH ENCRYPTION option encrypts the information in the system catalog that contains the text of the CREATE FUNCTION statement. In that case, you cannot view the text used to create the function. (Use this option to enhance the security of your database system.)
The alternative clause, WITH SCHEMABINDING, binds the UDF to the database objects that it references. Any attempt to modify the structure of the database object that the function references fails. (The binding of the function to the database objects it references is removed only when the function is altered, so the SCHEMABINDING option is no longer specified.)
Database objects that are referenced by a function must fulfill the following conditions if you want to use the SCHEMABINDING clause during the creation of that function:
• All views and UDFs referenced by the function must be schema-bound.
• All database objects (tables, views, or UDFs) must be in the same database as the function.
block is the BEGIN/END block that contains the implementation of the function. The final statement of the block must be a RETURN statement with an argument. (The value of the argument is the value returned by the function.) In the body of a BEGIN/END block, only the following statements are allowed:
• Assignment statements such as SET
• Control-of-flow statements such as WHILE and IF
• DECLARE statements defining local data variables
• SELECT statements containing SELECT lists with expressions that assign to variables that are local to the function
• INSERT, UPDATE, and DELETE statements modifying variables of the TABLE data type that are local to the function
By default, only the members of the sysadmin fixed server role and the db_owner and db_ddladmin fixed database roles can use the CREATE FUNCTION statement. However, the members of these roles may assign this privilege to other users by using the GRANT CREATE FUNCTION statement (see Chapter 12).
Example 8.12 shows the creation of the scalar user-defined function called compute_costs.
Example 8.12

The compute_costs function computes additional costs that arise when all budgets of projects increase. The single input variable, @percent, specifies the percentage of increase of budgets. The BEGIN/END block first declares two local variables: @additional_costs and @sum_budget. The function then assigns to @sum_budget the sum of all budgets, using the SELECT statement. After that, the function computes total additional costs and returns this value using the RETURN statement.
Invoking User-Defined Functions
Each UDF can be invoked in Transact-SQL statements, such as SELECT, INSERT, UPDATE, or DELETE. To invoke a function, specify the name of it, followed by parentheses. Within the parentheses, you can specify one or more arguments. (Arguments are values or expressions that are passed to the input parameters that are defined immediately after the function name.) When you invoke a function, and all parameters have no default values, you must supply argument values for all of the parameters and you must specify the argument values in the same sequence in which the parameters are defined in the CREATE FUNCTION statement. (As you already know, the scalar UDFs can be invoked using the EXEC statement, too.)
Example 8.13 shows the use of the compute_costs function (Example 8.12) in a SELECT statement.
Example 8.13

The result is

The SELECT statement in Example 8.13 displays names and numbers of all projects where the budget is lower than the total additional costs of all projects for a given percentage.
NOTE Each function used in a Transact-SQL statement must be specified using its two-part name—that is, schema_name.function_name.
Scalar UDF Inlining
In all versions prior to SQL Server 2019, scalar user-defined functions are generally a performance issue because they are generally processed in a row-oriented way, meaning that they run for every returned row. That way, they do not allow parallel execution of rows.
SQL Server 2019 supports a new feature called scalar UDF inlining, the goal of which is to improve performance of queries that invoke scalar UDFs. In other words, the feature allows certain scalar UDFs to have their definitions placed directly into the query so that the query does not call the UDF when executing each row.
Scalar UDF inlining will be discussed in detail in Chapter 28 (see Example 28.14).
Table-Valued Functions
As you already know, functions are table-valued if the RETURNS clause returns a set of rows. Depending on how the body of the function is defined, table-valued functions can be classified as inline or multistatement functions. If the RETURNS clause specifies TABLE with no accompanying list of columns, the function is an inline function. Inline functions return the result set of a SELECT statement as a table variable; that is, a variable of the TABLE data type. In other words, an inline function can contain only one root SELECT statement that is used to describe its result. This is good from an optimization prospective, because the Query Optimizer may inline a function’s text into a query and thus optimize a query as a whole.
A multistatement table-valued function includes a name followed by TABLE. (The name defines an internal variable of the type TABLE.) You can use this variable to insert rows into it and then return the variable as the return value of the function. Multistatement table-valued functions are difficult to optimize, and are not considered by the Query Optimizer.
Example 8.14 shows an inline function that returns a table variable.
Example 8.14

The employees_in_project function is used to display names of all employees that belong to a particular project. The input parameter @pr_number specifies a project number. While the function generally returns a set of rows, the RETURNS clause contains the TABLE data type. (Note that the BEGIN/END block in Example 8.14 must be omitted, while the RETURN clause contains a SELECT statement.)
Example 8.15 shows the use of the employees_in_project function.
Example 8.15

The result is

Table-Valued Functions and APPLY
The APPLY operator is a relational operator that allows you to invoke a table-valued function for each row of a table expression. This operator is specified in the FROM clause of the corresponding SELECT statement in the same way as the join operator is applied. There are two forms of the APPLY operator:
• CROSS APPLY
• OUTER APPLY
The CROSS APPLY operator returns those rows from the inner (left) table expression that match rows in the outer (right) table expression. Therefore, the CROSS APPLY operator is logically the same as the INNER JOIN operator.
NOTE CROSS APPLY is Microsoft’s extension to the SQL standard. You can rewrite most queries with the CROSS APPLY operator using INNER JOIN, but the advantage of the former is that it can yield a better execution plan and better performance, since it can limit the set being joined, before the join occurs.
The OUTER APPLY operator returns all the rows from the inner (left) table expression. (For the rows for which there are no corresponding matches in the outer table expression, it contains NULL values in columns of the outer table expression.) OUTER APPLY is logically equivalent to LEFT OUTER JOIN.
Examples 8.16 and 8.17 show how you can use APPLY.
Example 8.16


The fn_getjob() function in Example 8.16 returns the set of rows from the works_on table. This result set is “joined” in Example 8.17 with the content of the employee table.
Example 8.17

The result is

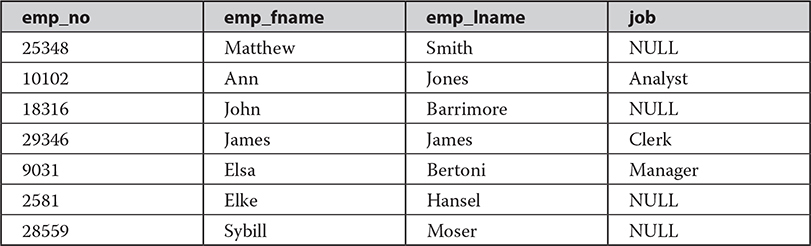
In the first query of Example 8.17, the result set of the table-valued function fn_getjob() is “joined” with the content of the employee table using the CROSS APPLY operator. fn_getjob() acts as the right input, and the employee table acts as the left input. The right input is evaluated for each row from the left input, and the rows produced are combined for the final output.
The second query is similar to the first one, but uses OUTER APPLY, which corresponds to the outer join operation of two tables.
Table-Valued Parameters
Sometimes it is necessary to send many parameters to a routine. One way to do it is to use a temporary table, insert the values into it, and then call the routine. The better way is to use table-valued parameters (see Example 8.18).
Example 8.18
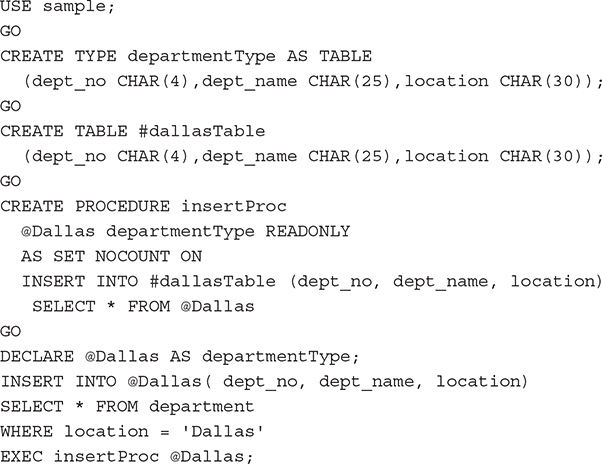
Example 8.18 first defines the type called departmentType as a table. This means that its type is the TABLE data type, so rows can be inserted in it. The second statement creates the temporary table called #dallasTable. In the insertProc procedure, the @Dallas variable, which is of the departmentType type, is specified. (The READONLY clause specifies that the content of the table variable cannot be modified.) In the subsequent batch, data is added to the table variable, and after that the procedure is executed. The procedure, when executed, inserts rows from the table variable into the temporary table #dallasTable. The content of the temporary table is as follows:

The use of table-valued parameters gives you the following benefits:
• It simplifies the programming model in relation to routines.
• It reduces the round trips to the server.
• The resulting table can have different numbers of rows.
Changing the Structure of UDFs
The Transact-SQL language also supports the ALTER FUNCTION statement, which modifies the structure of a UDF. This statement is usually used to remove the schema binding. All options of the ALTER FUNCTION statement correspond to the options with the same name in the CREATE FUNCTION statement.
A UDF is removed using the DROP FUNCTION statement. Only the owner of the function (or the members of the db_owner and sysadmin fixed database roles) can remove the function.
Summary
A stored procedure is a special kind of batch, written either in the Transact-SQL language or using the Common Language Runtime (CLR). (This version of the book describes only how T-SQL can be used to implement stored procedures.) Stored procedures are used for the following purposes:
• To improve the performance of repetitive tasks
• To control access authorization
• To create an audit trail of activities in database tables
• To enforce consistency and business rules with respect to data modification
User-defined functions have a lot in common with stored procedures. The main difference is that UDFs return a single data value, which can also be a table.
The next chapter discusses the system catalog of the Database Engine.
Exercises
E.8.1 Create a batch that inserts 3000 rows in the employee table. The values of the emp_no column should be unique and between 1 and 3000. All values of the columns emp_lname, emp_fname, and dept_no should be set to 'Jane', 'Smith', and 'd1', respectively.
E.8.2 Modify the batch from E.8.1 so that the values of the emp_no column should be generated randomly using the RAND function. (Hint: Use the temporal system functions DATEPART and GETDATE to generate the random values.)