
CHAPTER |
|
27 |
Columnstore Indices |
In This Chapter
• Benefits of Columnstore Indices
• Internal Storage of Columnstore Indices
• Types of Columnstore Indices
• Editing Information Concerning Columnstore Indices
• Columnstore Indices: Performance
As you already know from Chapter 10, index access means that indices are used to access entire rows that fulfill a condition of the given query. This is a general approach and doesn’t depend on the number of columns being returned. In other words, the values of all columns of a particular row will be fetched, even if values of only one or two columns are needed. The reason for this is that the Database Engine and all other relational database systems store a table’s rows on data pages, which are units of storage that are read into memory and written back to disk. This traditional approach of storing data is called row store.
Another approach to storing data promises to improve performance in cases where the values of only a few columns of a table need to be fetched. Such an approach is called column store, and Microsoft introduced this technique using the index called columnstore. In a column store, column values are grouped and stored one column at a time. The query processor of a database system that supports column store can take advantage of the new data layout and significantly improve query execution time of such queries that retrieve just a few of a table’s columns, because the smaller the number of fetched columns, the smaller the number of I/O operations required.
Columnstore indices are designed for data warehouses where SELECT statements operate on many rows but usually use only a few columns. They can be created in fact tables of a data warehouse, but can also be applied in the case of extremely large dimension tables.
The first section of the chapter describes the benefits of columnstore indices over row store indices. After that, internal storage of these indices is discussed and the notion of segments is introduced. The third part of the chapter introduces clustered and nonclustered columnstore indices, gives the syntax for their creation, and describes how clustered columnstore indices can be modified.
The last section shows the performance benefits of column store in relation to row store, and introduces a new execution mode, called Batch Mode on Columnstore. The aim of this execution mode is to execute analytical queries more effectively.
Benefits of Columnstore Indices
As a performance-tuning technique, columnstore indices offer significant performance benefits for a certain group of queries. The following are the benefits of columnstore indices:
• The system fetches only needed columns. The smaller the number of fetched columns, the smaller the number of I/O operations required. For instance, if the values of a few columns of each row are retrieved, the use of columnstore indices can reduce I/O significantly because only a small part of the data has to be transferred from disk into memory. (This is especially true for data warehouses, where fact tables usually have millions of rows.)
• No limitation exists on the number of key columns. The concept of key columns exists only for row store. Therefore, the limitation on the number of key columns for an index does not apply to columnstore indices. Also, if a base table has a clustered index, all columns in the clustering key must be present in the nonclustered columnstore index. Otherwise, it will be added to the columnstore index automatically.
• Columnstore indices work with table partitioning. If you create a columnstore index, no changes to the table partitioning syntax are required. A columnstore index on a partitioned table must be partition-aligned with the base table (see Chapter 26). Therefore, a columnstore index can be created on a partitioned table only if the partitioning column is one of the columns in the columnstore index.
• Buffer pool usage is improved. Reading only the columns that are required improves buffer pool usage and therefore more data can be kept in memory.
Internal Storage of Columnstore Indices
Columnstore indices are based on Microsoft’s xVelocity, an advanced storage and technology that Microsoft originally incorporated in PowerPivot and the Analysis Services Tabular model, and later adapted for SQL Server. Because xVelocity offers both storage and compression techniques, I describe these two features in the following subsections.
Index Storage
To explain index storage for columnstore indices, we’ll start with a table that includes the PRIMARY KEY constraint, the employee table introduced in Chapter 1 and used throughout the book. Because the emp_no column of the employee table is specified as the primary key, the Database Engine will implicitly create a clustered index based on that column. As you already know, leaf nodes of the clustered index store data by rows, and each leaf node includes all the data associated with that row. Additionally, the data is spread across one or more data pages.
When the Database Engine processes a table scan on the employee table, it moves all data pages into memory, fetching the entire table even though most of the values of its columns are not needed. In doing so, the system wastes I/O and memory resources to retrieve unnecessary data. Now let’s look at what happens when we create a columnstore index on the table.
The basic technique in relation to column index storage consists of dividing data into row groups, called segments. Each segment consists of approximately one million rows. Also, each segment contains values from one column only, which allows each column’s values to be accessed independently. However, a column can span multiple segments, and each segment can be made up of multiple data pages. Data is transferred from disk to memory by segment, not by page. The data within each column’s segment matches row-by-row so that the rows can always be assembled correctly, if needed. (This is an important performance issue when the system has to assemble data from a column store back to the corresponding row store.)
All data within a segment is encoded by using an internal algorithm. Additionally, for some of the columns that need dictionaries, an additional dictionary encoding conversion is used. The Database Engine uses two general forms of dictionaries: a global dictionary associated with the entire column, and a local dictionary associated with each segment.
NOTE The data in a column store is not sorted, not even within a column segment.
The metadata for columnstore indices is internally stored in directories. The metadata includes information about the allocation status of segments and dictionaries. It contains additional metadata about the number of rows, row size, and minimum (maximum) value inside of each segment. (You can retrieve information concerning directories using the sys.column_store_segments DMV, described later in the chapter in the section “Editing Information Concerning Columnstore Indices.”)
Compression
Before I discuss the compression technique of xVelocity, let me explain why compression is so important for column store. In the case of a row store, compressing data is generally suboptimal. The reason is that values of columns of a table have many different data types and forms: some of them are numeric and some are strings or dates. Most compression algorithms are based on similarities of a group of values. When data is stored by rows, the possibility to exploit similarity among values of different columns is thus limited. By contrast, data items from a single column have the same data type and are stored contiguously. Usually, there is repetition and similarity among values within a column. All these factors allow the system to apply compression very effectively on a column store.
As you already know, each set of rows is divided into segments of about one million rows each. Each segment is then compressed, independently and in parallel, using an internal supported technique. The result is one compressed column segment for each column included in the columnstore index.
Besides the form of compression just explained, the Database Engine supports an additional form called archival compression. This form of compression can be applied to already compressed data to further reduce the amount of storage space. In data warehouse systems, there is usually a group of data that is queried more often than other groups of data. For instance, data may be partitioned by date, and the most recent data (say, the data from the last two years) may be accessed much more frequently than older data. In such case, the older data can benefit from additional compression at the cost of slower query performance.
Archival compression should be applied to archival data that you keep for regulatory reasons. The advantage of archival compression is that you can partition a table with a columnstore index, and then change the compression mode for individual partitions.
NOTE The compression form can be specified using the DATA_COMPRESSION clause of the CREATE CLUSTERED COLUMNSTORE INDEX statement (see Example 27.1 in the next section).
After the system finishes the process of encoding and compression, the segments and the dictionaries are converted to large objects (LOBs) and are stored inside of the Database Engine. (If one of the LOBs spans more than 8KB, the regular storage mechanisms are used.)
Types of Columnstore Indices
The Database Engine supports two types of columnstore indices: clustered and nonclustered. The following subsections explain them.
Clustered Columnstore Index
This section describes how you can create a clustered columnstore index, load data into it, and modify already loaded data.
Creation of Clustered Columnstore Index
To create a clustered columnstore index, first create a row store table as a heap or clustered index, and then use the CREATE CLUSTERED COLUMNSTORE INDEX statement to convert the table to a clustered columnstore index.
Example 27.1 shows the creation of a clustered columnstore index. (The syntax of CREATE CLUSTERED COLUMNSTORE INDEX does not include the list of indexed columns, while each such index contains all columns of the corresponding table.)
Example 27.1

Example 27.1 uses the FactInternetSales table from the AdventureWorksDW database and copies its structure and data to the table with the same name in the sample database by using the SELECT … INTO statement. After that, Example 27.1 creates the clustered columnstore index called cl_factinternetsales. As you can see from Example 27.1, the creation of a clustered columnstore index has the same syntax as the traditional CREATE INDEX statement except that it includes the additional CLUSTERED COLUMNSTORE clause.
The DATA_COMPRESSION clause specifies the data compression option for the specified table, partition number, or range of partitions. The options are COLUMNSTORE (the default value) and COLUMNSTORE_ARCHIVE.
NOTE An important property of a clustered columnstore index is that it can have one or more nonclustered row store indices.
Clustered Columnstore Index and Data Modification
Column storage significantly improves read operations, but data in that storage is very expensive to update directly, because it is compressed. For this reason, the Database Engine does not update data in compressed row groups during data modification operations. The modification operations are handled by two components in relation to clustered columnstore indices: delta stores and delete bitmaps.
NOTE As you will see in the next sections, both delta stores and delete bitmaps are row store constructs. Therefore, all update operations on them are row store operations, which are significantly faster than the same operations on highly compressed column structures.
Delta Stores If you execute DML statements, new and updated rows are inserted into a delta store, which is a traditional B-tree structure. Delta stores are included in any scan of the clustered columnstore index.
A delta store contains the same columns as the corresponding clustered columnstore index. The B-tree key is a unique integer row ID generated by the system. (A clustered columnstore index does not have unique keys.) A clustered columnstore index can have zero, one, or more delta stores. New delta stores are created automatically as needed to accept inserted rows. A delta store is either open or closed. An open delta store can accept rows to be inserted. A delta store is closed when the number of rows it contains reaches a predefined limit. Every delta store has a state column value of either 1 (open) or 2 (closed).
The Database Engine automatically checks in the background for closed delta stores and converts them into segments. This background process is called Tuple Mover and by default is executed every 5 minutes. Tuple Mover is designed not to block any read operations on data. By contrast, concurrent delete and update operations have to wait until the compression process completes.
NOTE The implementation of delta stores for disk-based tables is done as a set of internal B-tree tables.
The large bulk insert operations are handled differently by the system. During a large bulk load, the rows are stored directly in the clustered columnstore index without passing through a delta store. The operation itself is very efficient, since it stores all inserted rows in memory and applies compression in-memory. After the process is terminated, it stores that data on the disk.
In case of DELETE, an additional structure called a delete bitmap is used, which will be explained next.
Delete Bitmap Each clustered columnstore index has an associated delete bitmap that is consulted during scans to disqualify rows that have been deleted. In other words, a delete bitmap is a storage component that contains information about the deleted rows inside segments. A delete bitmap has two different representations, depending on whether it is in memory or on disk. In memory, it is a bitmap, but on disk, it is stored in the following way: a record of a deleted row is inserted into the B-tree of the corresponding delete bitmap. (This is true only if a row is in a columnstore segment. If the row to be deleted is in a delta store, the row is simply deleted.)
NOTE The implementation of delete bitmaps for disk-based tables is done as a set of internal B-tree tables.
Having discussed delta stores and delete bitmaps, we now can examine exactly what happens when an INSERT, UPDATE, or DELETE statement is executed: First, inserted data is simply added to one of the currently open delta stores. Second, if the deleted row is found inside of a segment, then the deleted bitmap information is updated with the row ID of the respective row. On the other hand, if the deleted row is actually inside of a delta store, then the direct process of removal is executed on the corresponding B-tree structure. Finally, data updates are basically represented as deletes and inserts. In other words, an update operation triggers the insertion of the old version of the row into the delete bitmap and insertion of a new version into the delta store.
Nonclustered Columnstore Index
Generally, a nonclustered columnstore index is stored in the same way as a clustered one. Only one columnstore index can be created in this situation. In other words, if a clustered (or nonclustered) columnstore index exists, it must be dropped before the new index can be created. The columnstore index requires extra storage since it contains a copy of the data in the regular (“row store”) table.
Creation of a Nonclustered Columnstore Index
Generally, the CREATE NONCLUSTERED COLUMNSTORE INDEX statement is used to create a nonclustered columnstore index on a table. The underlying table can be a row store table with or without a clustered index. In all cases, creating a nonclustered columnstore index on a table stores a second copy of the data for the columns in the index.
NOTE SQL Server does not allow you to create clustered and nonclustered columnstore indices at the same time. You have to drop the clustered index in Example 27.1 if you want to create cs_index1 in Example 27.2.
Example 27.2


The CREATE INDEX statement in Example 27.2 creates a columnstore index for three columns of the FactInternetSales table: OrderDateKey, ShipDateKey, and UnitPrice. This means that all values of each of the three columns will be grouped and stored separately.
Filtered Index
The nonclustered columnstore index definition supports the use of a filter. A filtered index is an index that is specified for a condition in the WHERE clause of the SELECT statement. (You can define a filtered index both for regular indices and for columnstore indices.) Example 27.3 shows creation of such an index. (Again, only one index can be specified for a columnstore. For this reason, drop the index from Example 27.2 before creating the index in Example 27.3.)
Example 27.3

Editing Information Concerning Columnstore Indices
As mentioned previously in the “Index Storage” section, principal storage for metadata concerning columnstore indices is called a directory The metadata includes information about the allocation status of segments and dictionaries. The directory also contains additional metadata about the number of rows, size, and minimum and maximum values inside each of the segments.
If you want to display this information, you can use the following dynamic management views:
• sys.column_store_segments
• sys.column_store_row_groups
• sys.column_store_dictionaries
The following subsections describe these DMVs.
sys.column_store_segments
The sys.column_store_segments view contains a row for each column in a columnstore index. Example 27.4 displays information about segments of existing columnstore indices.
Example 27.4
![]()

The result of Example 27.4 is

The SELECT statement in Example 27.4 displays the name of the index, its ID, and the index type (NONCLUSTERED COLUMNSTORE). The last column displays the number of assigned segments.
sys.column_store_row_groups
The sys.column_store_row_groups view provides metadata information in relation to a clustered columnstore index on a per-segment basis. sys.column_store_row_groups has a column for the total number of rows physically stored (including those marked as deleted) and a column for the number of rows marked as deleted. Use sys.column_store_row_groups to determine which segments have a high percentage of deleted rows and should be rebuilt.
Example 27.5 shows the use of this DMV.
Example 27.5

The result is

The query in Example 27.5 joins three tables, sys.column_store_row_groups, sys.indexes, and sys.objects, to display the name of the table and names and IDs of associated columnstore indices. The last column of the output, type_desc, displays the type of the associated index.
sys.column_store_dictionaries
The sys.column_store_dictionaries DMV contains a row for each dictionary used in columnstore indices. Dictionaries are used to encode some, but not all, data types; therefore, not all columns in a columnstore index have dictionaries.
The most important columns of the DMV are hobt_id, column_id, and dictionary_id. The hobt_id column value is the unique identifier of the B-tree index (hobt) for the table that has the corresponding columnstore index. The column_id column value is the ID of the columnstore column, starting with 1. The first column has ID = 1, the second column has ID = 2, and so on. The dictionary_id column value specifies the ID of the corresponding dictionary. The value 0 represents the global dictionary that is shared across all column segments (one for each row group) for that column. The value <> 0 specifies a local dictionary.
Columnstore Indices: Performance
As you already know from the first section of this chapter, the use of columnstore indices can reduce I/O significantly, because only a small part of the data has to be transferred from disk into memory. (The Microsoft website states that the columnstore index can achieve query performance gains up to ten times greater than traditional index, as well as ten times the data compression rate over the uncompressed data size.)
In the following two subsections we first take a closer look at a performance comparison of the columnstore index and a corresponding traditional index. After that, a set-at-time execution, called Batch Mode, will be introduced. The aim of this mode is to execute a query that processes millions and billions of rows more effectively.
Columnstore Indices vs. Rowstore Indices
Generally, columnstore indices should have significant performance benefits in relation to traditional (B-tree) indices. Example 27.6 uses the AdventureworksDW2016_EXT sample database to compare the CPU and execution time of two identical queries.
NOTE The AdventureworksDW2016_EXT database is another Microsoft sample database. This database is similar to the AdventureworksDW database, with significant extensions in relation to a number of tables as well as the cardinality of existing ones. You can download this database from the following site: https://github.com/Microsoft/sql-server-samples/releases/tag/adventureworks
Example 27.6


The result is
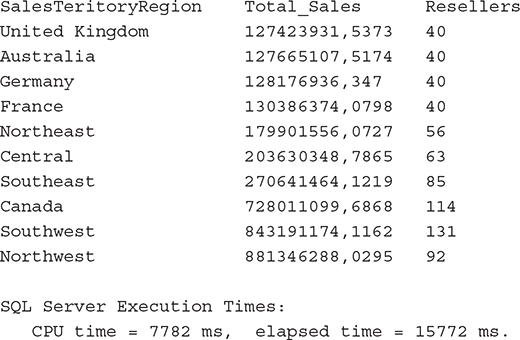
We use the AdventureworksDW_EXT sample database in Examples 27.6 and 27.7 because it contains two tables: FactResellerSalesXL_PageCompressed (Example 27.6) and FactResellerSalesXL_CCI (Example 27.7). The only difference is that the second table has the clustered columnstore index. Therefore, Example 27.6 uses row store to retrieve results, while Example 27.7 displays the same result set using a columnstore index.
Example 27.7


The result set is the same as for Example 27.6. The execution time is
![]()
As you can see from the performance parameters of Examples 27.6 and 27.7, the execution time of the query using a columnstore index is eight times faster than the corresponding execution time of the same query using row store.
NOTE You cannot expect that each query will have such huge performance advantages if you use the column store. Generally, using a columnstore index benefits a wide group of queries, but typically the execution time is not several times faster.
Batch Mode on Columnstore
When you run a query in the Database Engine, the Query Processor plans how it should actually get the optimal result. This plan is expressed as a tree with operators, where the operators build the nodes of the tree. Each operator with its properties represents a certain processing action applied to a portion of data.
The query optimizer generally uses record-at-time execution, meaning that each query plan operator processes one row at a time. Prior to SQL Server 2012, a unit of data transferred through a tree was a row. With the introduction of columnstore indices, a set-at-time execution, called Batch Mode, was designed. The aim of this mode is to execute a query that processes millions and billions of rows more effectively.
Therefore, the columnstore index allows the system to choose between two modes: Row Mode, which is the conventional execution mode, and Batch Mode, the new execution mode for analytical queries with columnstore indices.
A batch is a structure of 64KB, allocated for a bunch of rows, that contains column vectors and qualifying rows vector. Depending on the number of columns, it may contain up to 1000 rows.
The benefits of Batch Mode are
• Allows the use of algorithms that are optimized for multicore CPUs
• Increased memory throughput
• Significant reduction of database accesses
NOTE The downside of Batch Mode is that not all operators of the execution plan can be executed in that mode. In other words, if there is just one unsupported operator in a particular query plan, the whole query will be executed in row-mode processing.
The following examples show you how a query is executed in Batch Mode. Example 27.8 creates the tables that are necessary for the query.
Example 27.8

The SELECT statement in Example 27.8 creates the FactInternetSales table in the sample database and loads all rows from the FactInternetSales table of the AdventureWorksDW database into it. The subsequent INSERT statement loads the same load six more times. That way, we created a new table in the sample database with 422,786 rows.
Example 27.9 repeats the process of creating and loading two other tables from the AdventureWorksDW database.
Example 27.9

After the execution of the queries in Example 27.9, the sample database contains two new tables, DimCustomer and DimDate, with the same structure and content as the tables with the same names in the AdventureWorksDW database.
Example 27.10 creates a nonclustered columnstore index.
Example 27.10

The creation of a columnstore index is a condition for which the query optimizer can choose Batch Mode on Columnstore. (The creation of a columnstore index does not mean that the query optimizer will automatically choose to use Batch Mode for the execution of a query.)
As previously noted, Batch Mode processing uses algorithms that are optimized for multicore CPUs. This means the query optimizer will not choose Batch Mode if the number of processors is one, which is the default value. Therefore, Example 27.11 increases the number of processors to four, using the max degree of parallelism (MAXDOP) configuration option. This is an advanced configuration option that controls the number of processors that are used for the execution of a query in a parallel plan.
Example 27.11

Example 27.12 shows the query that is processed in Batch Mode using a columnstore index.
Example 27.12

Figure 27-1 shows the execution plan of the query in Example 27.12 in general and the properties of the Columnstore Index Scan operator in particular. Two properties are important in relation to Batch Mode on Columnstore: Estimated Execution Mode and Storage. The former has the value Batch and the latter the value ColumnStore. This means that the query is processed in Batch Mode using the columnstore index called CLI_CS_IFactInternetSales.
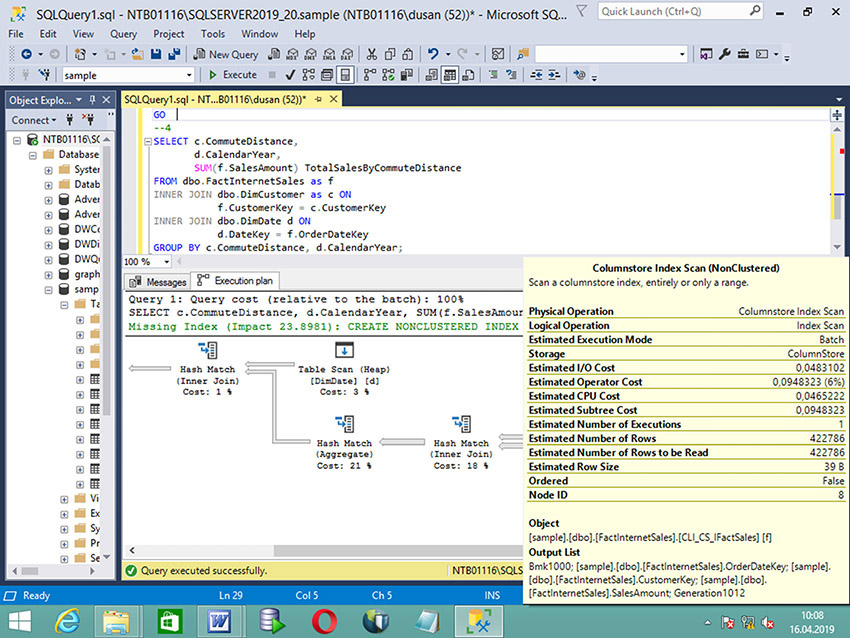
Figure 27-1 Execution plan of the query in Example 27.12
Summary
Column store is one of most important performance-tuning techniques supported by SQL Server for BI. This technique offers significant performance benefits for a group of queries with the following properties:
• When an aggregate needs to be computed over many rows but only for a notably smaller subset of all columns of data
• When new values of a column are supplied for all rows at once, because that column data can be written efficiently and replace old column data without touching any other columns
On the other hand, column store should not be used when the values of many columns but only a few rows are retrieved at the same time.
The next chapter describes a group of sophisticated performance features called Intelligent Query Processing.
Exercises
E.27.1 Calculate the average unit price from the FactInternetSales table of the AdventureWorksDW database. (Use the UnitPrice column of the same table.) Do not use any indices. Using the STATISTICS TIME option of the SET statement, display the execution times and elapsed time for this query.
E.27.2 Create a nonclustered columnstore index for the following columns of the FactInternetSales table: OrderDateKey, ShipDateKey, UnitPrice. Again, calculate the average unit price from the FactInternetSales table of the AdventureWorksDW database. Using the STATISTICS TIME option of the SET statement, display the execution times and elapsed time for this query.
E.27.3 Calculate the performance gains of the second query in relation to the first one.