
In Chapters 7 and 10, you learned how to use the AVX and AVX2 instruction sets to perform packed integer operations using 128-bit and 256-bit wide operands. In this chapter, you learn how to use AVX-512 instructions set to carry out packed integer operations using 512-bit wide operands. You also learn how to use AVX-512 instructions with 256-bit and 128-bit wide packed integer operands. The first source code example explains how to perform basic packed integer arithmetic using ZMM registers. This is followed by several examples that exemplify image-processing algorithms and techniques using AVX-512 instructions. Like the previous chapter, all of source code examples in this chapter require a processor and operating system that support AVX-512 and the following instruction set extensions: AVX512F , AVX512CD , AVX512BW , AVX512DQ , and AVX512VL . You can use one of the freely available utilities listed in Appendix A to determine whether your system supports these extensions.
Basic Arithmetic
Example Ch14_01
The C++ functions Avx512PackedMathI16 and Avx512PackedMathI64 are the base routines that handle AVX-512 packed integer operations using word and quadword values. Each function begins its execution by initializing the applicable integer elements of two ZmmVal variables. Note that the C++ alignas(64) specifier is used with each ZmmVal. Following variable initialization, each base routine invokes its corresponding assembly language function: Avx512PackedMathI16_ or Avx512PackedMathI64_. The results are then streamed to cout.
The assembly language function Avx512PackedMathI16_ starts its execution with two vmovdqa64 instructions that load ZmmVal variables a and b into registers ZMM0 and ZMM1, respectively. Somewhat surprisingly, AVX512BW does not include aligned move instructions for 512-bit wide packed byte and word operands. Another alternative here would be to use the vmovdqu16 instruction. Note that this latter instruction must be used in cases where merge or zero masking is required. AVX512BW also includes a vmovdqu8 instruction for 512-bit wide packed byte operands. Following operand value loading, Avx512PackedMathI16_ demonstrates the packed word instructions vpaddw, vpaddsw, vpsubw, vpsubsw, vpminsw, vpmaxsw. Each 512-bit packed word result is then saved in the array c. Note that Avx512PackedMathI16_ uses a vzeroupper instruction prior to its ret instruction.
Image Processing
The source code examples in this section explicate image-processing algorithms and techniques using AVX-512 packed integer instructions. Most of the source code examples are updated versions of examples from earlier chapters that exploited AVX or AVX2 instructions. Besides exemplifying AVX-512 packed integer instruction usage, the source code examples that follow also accentuate alternative algorithmic approaches and instruction sequences that often result in improved performance.
Pixel Conversions
Example Ch14_02
The C++ code in Listing 14-2 begins with the requisite function declarations. The first declaration set is for the functions Avx512ConvertImgU8ToF32Cpp and Avx512ConvertImgU8ToF32Cpp, which are defined in the file Ch14_02_Misc.cpp. The source code for these functions is not shown since they’re almost identical to the AVX2 counterpart functions that were used in source code example Ch07_06. Two minor changes were made: the source and destination pixel buffers are aligned on a 64-byte instead of a 16-byte boundary; the number of pixels in these buffers must be evenly divisible by 64 instead of 32.
The function Avx512ConvertImgU8ToF32 initializes the test arrays for converting pixels values from uint8_t to float. This function uses the C++ template class AlignedArray<> to allocate these arrays on a 64-byte boundary. Following test array initialization, Avx512ConvertImgU8ToF32 invokes the C++ and assembly language conversion functions. It then calls Avx512ConvertImgVerify to verify the results. The function Avx512ConvertImgF32ToU8 converts pixel values from float to uint8_t. Note that this function intentionally initializes the first few values of the source pixel buffer src to known values in order to verify that the conversion functions properly clip out-of-range pixel values.
The assembly language function Avx512ConvertImgU8ToF32_ begins its execution by validating num_pixels. It then confirms that the pixel buffers src and des are properly aligned on a 64-byte boundary. In source code example Ch07_06 from Chapter 7, pixel normalization was performed by dividing each pixel value by 255.0. Avx512ConvertImgU8ToF32_ carries out pixel normalization using the multiplicative scale factor 1.0/255.0 since floating-point multiplication is usually faster than floating-point division. The vbroadcastss zmm5,xmm1 instruction loads a packed version of this scale factor into register ZMM5.
Each processing loop iteration starts with a vpmovzxbd zmm0,xmmword ptr [rdx] instruction. This instruction copies and zero-extends the 16-byte (or uint8_t) pixels pointed to by RDX to doublewords ; it then saves these values in register ZMM0. Three more vpmovzxbd instructions are then employed to load another 48 pixels into registers ZMM1, ZMM2, and ZMM3. This is followed by four vcvtudq2ps instructions that convert each unsigned doubleword pixel value in registers ZMM0–ZMM3 to single-precision floating-point. The ensuing vmulps instructions multiply these values by the normalization scale factor; the results are then saved to the destination pixel buffer des using a series of vmovaps instructions.
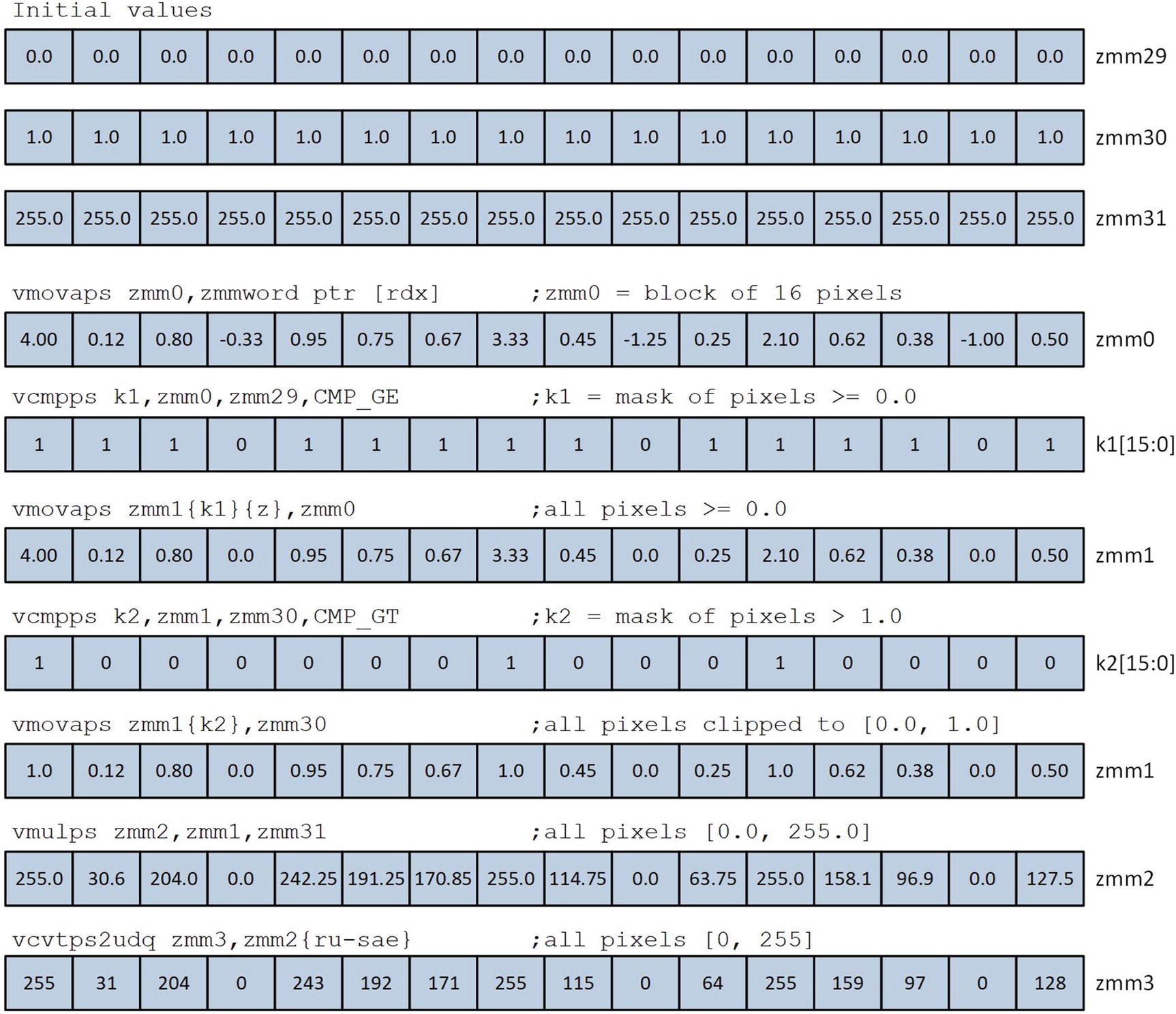
Instruction sequence used to convert packed pixel values from floating-point to unsigned doubleword integers
Image Thresholding
Example Ch14_03
Near the top of the header file Ch14_03.h is an enum named CmpOp, which contains identifiers for the common compare operations. This is followed by the example’s function declarations. The C++ functions Init and ShowResults are ancillary functions that perform test array initialization and display results. The source code for these functions is not shown in Listing 14-3 but included with the chapter download package. The function Avx512ComparePixels_ is an AVX-512 assembly language functions that implements the pixel thresholding algorithm.
The function Avx512ComparePixelsCpp contains the C++ implementation of the updated thresholding algorithm. This function begins its execution by validating num_pixels for size and divisibility by 64. It then verifies that the pixel buffers src and des are properly aligned on a 64-byte boundary. Following argument validation code is a switch statement that applies the selector cmp_op to select a compare operation. Each switch statement case code block is a simple for loop that compares src[i] against cmp_val using the specified operator and sets pixels in the mask image to 0xff (true compare) or 0x00 (false compare). The function main includes code that allocates the image pixel buffers, exercises the functions Avx512ComparePixelsCpp and Avx512ComparePixels_ using various compare operators and displays results.
The assembly language code in Listing 14-3 commences with the macro _CmpPixels. This macro generates AVX-512 code that implements a processing loop for a pixel compare operator. The macro _CmpPixels requires the following register initializations prior to its use: RAX = 0, RCX = mask image pixel buffer, RDX = grayscale image pixel buffer, R8 = number of pixels, ZMM4 = packed byte threshold values, and ZMM5 = packed 0xff byte values. Each processing loop iteration of _CmpPixels begins with a vmovdqa64 zmm0,zmmword ptr [rdx+rax] instruction that loads 64 unsigned 8-bit integers into register ZMM0. The next instruction, vpcmpub k1,zmm0,zmm4,CmpOp, compares the grayscale pixel intensity values in ZMM0 to the packed values in ZMM4; it then saves the resultant mask in opmask register K1. The ensuing vmovdqu8 zmm1{k1}{z},zmm5 instruction sets each mask pixel value in ZMM1 to 0xff (true compare) or 0x00 (false compare) according to the value of the corresponding bit position in K1. The instruction vmovdqa64 zmmword ptr [rcx+rax],zmm1 then saves the 64 mask pixels to the mask image pixel buffer.
Image Statistics
Example Ch14_04

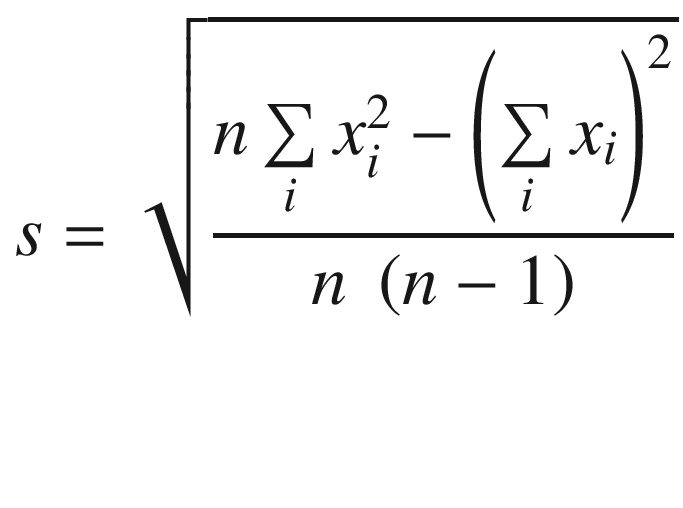
In the mean and standard deviation equations, the symbol x i represents an image buffer pixel and n denotes the number of pixels. If you study these equations carefully, you will notice that two intermediate sums must be calculated: the sum of all pixels and the sum of all pixel values squared. Once these quantities are known, the mean and standard deviation can be determined using simple arithmetic. The standard deviation equation that’s detailed here is simple to calculate and suitable for this source code example. For other use cases, however, this same equation is often unsuitable for standard deviation calculations especially those that involve floating-point values. You may want to consult the statistical variance calculating references that are listed in Appendix A before using this equation in one of your own programs.
Listing 14-4 begins with the C++ header file Ch14_04.h that includes the declaration of a structure named ImageStats. This structure is used to pass image data to the C++ and assembly language calculating functions and return results. A semantically equivalent structure is also defined in the assembly language file Ch14_04_.asm. The file Ch14_04.h also includes the constant definitions c_PixelValMin and c_PixelValueMax, which define the range limits that a pixel value must fall between to be included in any statistical calculations.
The function Avx512CalcImageStatsCpp is the principal calculating function in the C++ code. This function requires a pointer to an ImageStats structure as its sole argument. Following argument validation, Avx512CalcImageStatsCpp initializes the ImageStats intermediate sums m_PixelSum, m_PixelSumOfSquares, and m_NumPixelsInRange to zero. A simple for loop follows, which calculates m_PixelSum and m_PixelSumOfSquares. During each loop iteration, pixel values are tested for in-range validity before being included in any calculations. Following computation of the intermediate sums, the function Avx512CalcImageStatsCpp calculates the final mean and standard deviation . Note that m_NumPixelsInRange is used to calculate these statistical quantities instead of m_NumPixels. The remaining code in Ch14_04.cpp performs test case initialization, invokes the calculating functions, and streams the results to cout.
Toward the top of the file Ch14_04_.asm is the assembly language version of the structure ImageStats. This is followed by the macro definition _UpdateSums whose inner workings will be described shortly. The function Avx512CalcImageStats_ begins its execution by performing the same argument validation checks as its C++ counterpart. It then initializes packed versions of the intermediate values PixelValMin and PixelValMax. The ensuing vpxorq instructions initialize packed quadword versions of PixelSum and PixelSumOfSquares to zero. Note that the vpxor[d|q] (and other AVX-512 bitwise Boolean) instructions can optionally specify an opmask operand register to perform merge or zero masking of doubleword or quadword elements. The final initialization instruction, xor r10d,r10d, sets NumPixelsInRange to zero.

Calculations performed by instructions in macro _UpdateSums
Following the four _UpdateSums usages, the doubleword elements of registers ZMM16 and ZMM17 contain packed copies of the values pixel_sum and pixel_sum_of_squares for the current block of 64 pixels. The vextracti32x8 ymm0,zmm16,1 and vpaddd ymm1,ymm0,ymm16 instructions reduce the number of doubleword values in register ZMM16 from 16 to 8. The ensuing vpmovzxdq zmm2,ymm1 instruction promotes these doubleword values to quadwords, and the vpaddq zmm29,zmm29,zmm2 instruction updates the global packed quadword pixel_sum values that are maintained in register ZMM29. A similar sequence of instructions is then used to update the global packed quadword pixel_sum_of_squares values in register ZMM28. Following these instructions, the processing loop updates its pointer register and counters; it then repeats until the number of remaining pixels falls below 64.
Benchmark Timing Measurements for Image Statistics Calculating Functions Using TestImage4.bmp
CPU | Avx512CalcImageStatsCpp | Avx512CalcImageStats_ |
|---|---|---|
i7-4790S | ---- | ---- |
i9-7900X | 404 | 29 |
i7-8700K | ---- | ---- |
RGB to Grayscale Conversion
Example Ch14_05
The algorithm that’s used in this example to perform RGB to image grayscale conversion is the same one that was used in Ch10_06. As explained in Chapter 10, the algorithm uses a simple weighted average to transform an RGB image pixel into a grayscale image pixel. The C++ function Avx512RgbToGs begins its execution by loading the test image file. It then copies the RGB pixels of im_rgb into three separate color component image buffers. The reason for doing this is that this example’s RGB to grayscale conversion functions require a structure of arrays (AOS) instead of an array of structures (SOA) , which was employed in source code example Ch10_06. Following allocation of the grayscale image buffers, Avx512RgbToGs invokes the C++ and assembly language conversion functions. The resultant grayscale image buffers are then compared for equality and saved.
The assembly language code in Listing 14-5 includes two functions: Avx512Rgb2Gs_ and Avx2Rgb2Gs_. As implied by their respective name prefixes, these functions perform RGB to grayscale image conversions using AVX-512 and AVX2 instructions, respectively. The function Avx512Rgb2Gs_ begins its execution by validating num_pixels for size and divisibility by 64. It then checks the source and destination pixel buffers for proper alignment. The ensuing series of vbroadcastss instructions load packed versions of the color conversion coefficients into registers ZMM10, ZMM11, and ZMM12. This is followed by another set of vbroadcastss instructions that broadcast the single-precision floating-point constants 0.5, 255.0, and 0.0 to registers ZMM13, ZMM14, and ZMM15. The mov r8d,r8d instruction zero-extends num_pixels into R8, and the mov r10,16 instruction loads R10 with the number of pixels to process during each loop iteration.
Each Avx512Rgb2Gs_ processing loop iteration in starts with three vpmovzxbd instructions that load 16 red, green, and, blue pixel values into registers ZMM0, ZMM1, and ZMM2. The ensuing vcvtdq2ps instructions convert the doubleword pixel values to single-precision floating-point. The floating-point color values are then multiplied by the corresponding color coefficients using a series of vmulps instructions. These values are then summed using three vaddps instructions. The resultant 16 grayscale pixel values are then clipped to [0.0, 255.0] and converted to doubleword values. The vpmovusdb xmm3,zmm2 instruction size-reduces the doubleword values to bytes using unsigned saturation, and the vmovdqa xmmword ptr [rcx+rax],xmm3 instruction saves the 16 byte pixel values to the destination grayscale image buffer.
Mean Execution Times (Microseconds) for RGB to Grayscale Image Conversion Using TestImage3.bmp
CPU | Avx512RgbToGsCpp | Avx512Rgb2Gs_ | Avx2Rgb2Gs_ |
|---|---|---|---|
i7-4790S | ---- | ---- | ---- |
i9-7900X | 1125 | 134 | 259 |
i7-8700K | ---- | ---- | ---- |
The benchmark time differences between the AVX-512 and AVX2 implementations of the RGB to grayscale conversion algorithm are consistent with what one might expect. It is interesting to compare these numbers with the benchmark timing measurements from source code example Ch10_06 (see Table 10-2). This earlier example used an array of RGB32 pixels (or AOS) for the source image buffer, and the mean execution time for the conversion function Avx2ConvertRgbToGs_ was 593 microseconds. The current example exploits separate image pixel buffers for each color component (or SOA) , which significantly improves performance.
Summary
Assembly language functions can use AVX-512 promoted versions of most AVX and AVX2 packed integer instructions to perform operations using 512-, 256-, and 128-bit wide operands.
Assembly language functions can use the vmovdqa[32|64] and vmovdqu[8|16|32|64] to perform aligned and unaligned moves of packed integer operands.
Assembly language functions can use the vpmovus[qd|qw|qb|dw|db|wb] instructions to carry out packed integer size reductions using unsigned saturation. AVX-512 also supports an analogous set of packed integer size-reducing instructions using signed saturation.
The vpcmpu[b|w|d|q] instructions perform packed unsigned integer compare operations and save the resultant compare mask to an opmask register.
The vpand[d|q], vpandn[d|q], vpor[d|q], and vpxor[d|q] instructions can be used with an opmask register to perform merge or zero masking using doubleword or quadword elements.
The vextracti[32x4|32x8|64x2|64x4] instructions can be used to extract packed doubleword or quadword values from a packed integer operand.
When performing SIMD calculations using packed integer or floating-point operands, a structure-of-arrays construct is often significantly faster than an array-of-structures construct.