
In previous chapters, you learned how to carry out scalar and packed floating-point operations using the AVX and AVX2 instruction sets. In this chapter, you learn how to perform these operations using the AVX-512 instruction set. The first part of this chapter contains source code examples that illustrate basic AVX-512 programming concepts using scalar floating-point operands. This includes examples that illustrate conditional executions, merge and zero masking , and instruction-level rounding. The second part of this chapter demonstrates how to use the AVX-512 instruction set to carry out packed floating-point calculations using 512-bit wide operands and the ZMM register set.
The source code examples of this chapter require a processor and operating system that support AVX-512 and the following instruction set extensions: AVX512F , AVX512CD , AVX512BW , AVX512DQ , and AVX512VL . As discussed in Chapter 12, these extensions are supported by processors that are based on the Intel Skylake Server microarchitecture. Future processors from both AMD and Intel are also likely to incorporate the previously-mentioned instruction set extensions. You can use one of the freely available utilities listed in Appendix A to determine which AVX-512 instruction sets your system supports. In Chapter 16, you learn how to use the cupid instruction to detect specific AVX-512 instruction set extensions at runtime.
Scalar Floating-Point
AVX-512 extends the scalar floating-point capabilities of AVX to include merge masking , zero masking , and instruction-level rounding control. The source code examples of this section explain how to use these capabilities. They also exemplify some minor differences that you need to be aware of when writing scalar float-point code using AVX-512 instructions.
Merge Masking
Example Ch13_01
The C++ code in Listing 13-1 starts with the function Avx512CalcSphereAreaVolCpp. This function calculates the surface area and volume of any sphere whose radius is greater or equal to zero. If the sphere’s radius is less than zero, Avx512CalcSphereAreaVolCpp sets the surface area and volume to error_val. The remaining C++ code in Listing 13-1 performs test case initialization, exercises the functions Avx512CalcSphereAreaVolumeCpp and Avx512CalcSphereAreaVolume_, and streams results to cout.
The assembly language function Avx512CalcSphereAreaVol_ implements the same algorithm as its C++ counterpart. This function begins with a vmovsd xmm0,xmm0,xmm2 instruction that copies argument value r to register XMM0. It then loads register XMM5 with 0.0. The vmovsd xmm16,xmm16,xmm3 instruction copies error_val into register XMM16. According to the Visual C++ calling convention, the new AVX-512 registers ZMM16–ZMM31 along with the low-order YMM and XMM counterparts are volatile across function boundaries. This means that these registers can be used by any assembly language function without preserving their values. The next instruction, vcmpsd k1,xmm0,xmm5,CMP_GE, sets opmask register bit K1[0] to one if r is greater than or equal to zero; otherwise, this bit is set to zero.
The first instruction of the surface area and volume calculation code block, vmulsd xmm1{k1},xmm0,xmm0, computes r * r if bit K1[0] is set to one (r >= 0.0 is true); it then saves the calculated product in XMM1[63:0]. If bit K1[0] is set to zero (r < 0.0 is true), the processor skips the double-precision floating-point multiplication calculation and leaves register XMM1 unaltered. The next instruction, vmulsd xmm2{k1},xmm1,[r8_four], computes 4.0 * r * r using the same merge masking operation as the previous instruction. The ensuing vmulsd and vdivsd instructions complete the required surface area (XMM3) and volume (XMM5) calculations. The merge masking operations in this code block exemplify one of AVX-512’s key computational capabilities: the processor carries out the double-precision floating-point arithmetic calculations only if bit K1[0] is set to one; otherwise no calculations are performed, and the respective destination operand registers remain unchanged.
Zero Masking
Example Ch13_02
In the C++ code, the function Avx512CalcValuesCpp performs a simple arithmetic calculation using double-precision floating-point arrays. Each loop iteration begins by calculating the intermediate value val = a[i] * b[i]. The next statement, c[i] = (val >= 0.0) ? sqrt(val) : val * val, loads c[i] with a quantity that varies depending on the value of val. The assembly language function Avx512CalcValues_ also performs the same computation. The C++ function main contains code that initializes the test arrays, exercises the functions Avx512CalcValuesCpp and Avx512CalcValues_, and displays the results.
The processing loop of Avx512CalcValues_ begins with two vmovsd instructions that load a[i] and b[i] into registers XMM0 and XMM1, respectively. The ensuing vmulsd xmm2,xmm0,xmm1 instruction computes the intermediate product val = a[i] * b[i]. Following the calculation of val, the vcmpsd k1,xmm2,xmm5,CMP_GE instruction compares val against 0.0 and sets bit K1[0] to one if val is greater than or equal to zero; otherwise bit K1[0] is set to zero. The next instruction, vsqrtsd xmm3{k1}{z},xmm3,xmm2, calculates the square root of val if K1[0] is set to one and saves the result in XMM3. If K1[0] is zero, the processor skips the square root calculation and sets register XMM3 to 0.0.
Instruction-Level Rounding
Example Ch13_03
The C++ code in Listing 13-3 begins with the function ConvertF32ToU32. This function performs test case initialization and exercises the assembly language function Avx512CvtF32ToU32_, which converts a single-precision floating-point value to an unsigned doubleword (32-bit) integer using different rounding modes. The results are then streamed to cout. The C++ functions ConvertF64ToU64 and ConvertF64ToF32 carry out similar test case initializations for the assembly language functions Avx512CvtF64ToU64_ and Avx512CvtF64ToF32_, respectively.
The first instruction of assembly language function Avx512CvtF32ToU32_, vcvtss2usi eax,xmm1{rn-sae} converts the scalar single-precision floating-point value in XMM1 (or val) to an unsigned doubleword integer using the rounding mode round-to-nearest . As mentioned in Chapter 12, the -sae suffix that’s appended to the embedded rounding mode string is a reminder that floating-point exceptions and MXCSR flag updates are always disabled when an instruction-level rounding control operand is specified. The ensuing mov dword ptr [rcx],eax instruction saves the converted result in val_cvt[0]. Avx512CvtF32ToU32_ and then employs additional vcvtss2usi instructions to carry out the same conversion operation using rounding modes round-down , round-up , and round-to-zero . The organization of function Avx512CvtF64ToU64_ is similar to Avx512CvtF32ToU32_ and uses the vcvtsd2usi instruction to convert a double-precision floating-point value to an unsigned quadword integer. Note that both vcvtss2usi and vcvtsd2usi are new AVX-512 instructions. AVX-512 also includes the instructions vcvtusi2s[d|s], which perform unsigned integer to floating-point conversions. Neither AVX nor AVX2 include instructions that perform these types of conversions.
Packed Floating-Point
The source code examples of this section illustrate how to use AVX-512 instructions to carry out computations using packed floating-point operands. The first three source code examples demonstrate basic operations with 512-bit wide packed floating-point operands including simple arithmetic, compare operations, and merge masking . The remaining examples focus on specific algorithms including vector cross product calculations, matrix-vector multiplications, and convolutions.
Packed Floating-Point Arithmetic
Example Ch13_04
Listing 13-4 starts with the declaration of the C++ structure ZmmVal , which is declared in the header file ZmmVal.h. This structure is analogous to the XmmVal and YmmVal structures that were used by the source code examples in Chapters 6 and 9. The structure ZmmVal contains a publicly-accessible anonymous union that simplifies packed operand data exchange between functions written in C++ and the x86 assembly language. The members of this union correspond to the packed data types that can be used with a ZMM register . The structure ZmmVal also includes several string formatting functions for display purposes (the source code for these member functions is not shown).
The remaining C++ code in Listing 13-4 is similar to the code that was used in example Ch09_01. The declarations for assembly language functions Avx512PackedMathF32_ and Avx512PackedMathF64_ follow the declaration of structure ZmmVal. These functions carry out various packed single-precision and double-precision floating-point arithmetic operations using the supplied ZmmVal arguments. The C++ functions Avx512PackedMathF32 and Avx512PackedMathF64 perform ZmmVal variable initializations, invoke the assembly language calculating functions, and display results. Note that the alignas(64) specifier is used with each ZmmVal variable definition.
The assembly language code in Listing 13-4 begins with a 64-byte aligned custom memory segment named ConstVals. This segment contains definitions for the packed constant values that are used in the calculating functions. A custom segment is used here since the MASM align directive does not support aligning data items on a 64-byte boundary. Chapter 9 contains additional information about custom memory segments. The segment ConstVals contains the constants AbsMaskF32 and AbsMaskF64, which are used to calculate absolute values for 512-bit wide packed single-precision and double-precision floating-point values.
The first instruction of Avx512PackedMathF32_, vmovaps zmm0,ymmword ptr [rcx], loads argument a (the 16 floating-point values in ZmmVal a) into register YMM0. The vmovaps can be used here since ZmmVal a was defined using the alignas(64) specifier . The operator zmmword ptr directs the assembler to treat the memory location pointed to by RCX as a 512-bit wide operand. Like the operators xmmword ptr and ymmword ptr, the zmmword ptr operator is often used to improve code readability even when it’s not explicitly required. The ensuing vmovaps zmm1,zmmword ptr [rdx] instruction loads ZmmVal b into register ZMM1. The vaddps zmm2,zmm0,zmm1 instruction that follows sums the packed single-precision floating-point values in ZMM0 and ZMM1 and saves the result in ZMM2. The vmovaps zmmword ptr [r8],zmm2 instruction saves the packed sums to c[0].
The ensuing vsubps, vmulps, and vdivps instructions carry out packed single-precision floating-point subtraction, multiplication, and division. This is followed by a vandps zmm2,zmm1,zmmword ptr [AbsMaskF32] instruction that calculates packed absolute values using argument b. The remaining instructions in Avx512PackedMathF32_ calculate packed single-precision floating-point square roots, minimums, and maximums.
Prior to its ret instruction, the function AvxPackedMath32_ uses a vzeroupper instruction, which zeros the high-order 384 bits of registers ZMM0–ZMM15. As explained in Chapter 4, a vzeroupper instruction is used here to avoid potential performance delays that can occur whenever the processor transitions from executing x86-AVX code to executing x86-SSE code. Any assembly language function that uses one or more YMM or ZMM registers and is callable from code that potentially uses x86-SSE instructions should ensure that a vzeroupper instruction is executed before program control is transferred back to the calling function. It should be noted that according to the Intel 64 and IA-32 Architectures Optimization Reference Manual, the vzeroupper use recommendations apply to functions that employ x86-AVX instructions with registers ZMM0–ZMM15 or YMM0–YMM15. Functions that only exploit registers ZMM16–ZMM31 or YMM16–YMM31 do not need to observe the vzeroupper use recommendations.
Packed Floating-Point Compares
Example Ch13_05
The C++ function Avx512PackedCompareF32 that’s shown in Listing 13-5 starts its execution by loading test values into the single-precision floating-point elements of ZmmVal variables a and b. Note that these variables are defined using the C++ alignas(64) specifier . Following variable initialization, the function Avx512PackedCompareF32 invokes the assembly language function Avx512PackedCompareF32_ to perform the packed compares. It then streams the results to cout.
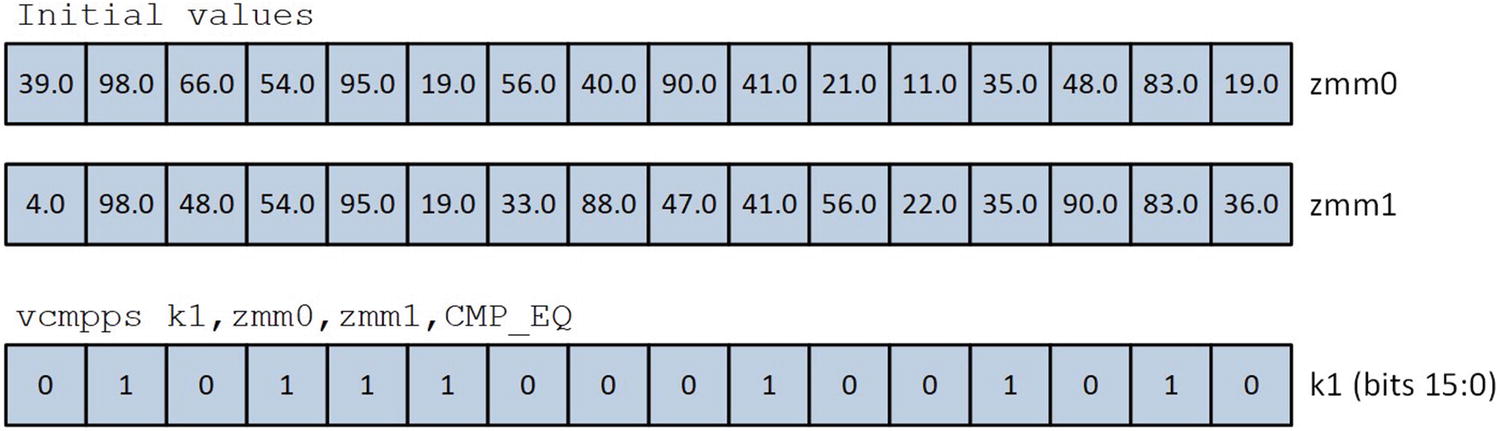
Example execution of the vcmpps k1,zmm0,zmm1,CMP_EQ instruction
On systems that support AVX-512, assembly language functions can also use the vcmppd instruction with a destination operand opmask register to perform packed double-precision floating-point compares. In these instances, the resultant mask is saved in the low-order eight bits of the destination operand opmask register.
Packed Floating-Point Column Means
Example Ch13_06
The function Avx512CalcColumnMeansCpp contains a C++ implementation of the columns means algorithm. This function uses two nested for loops to sum the elements of each column in the two-dimensional array. During each inner loop iteration, the value of array element x[i][j] is added to the current column running sum in col_means[j] only if it’s greater than or equal to x_min. The number of elements greater than or equal to x_min in each column is maintained in the array col_counts. Following the summing loops, the final column means are calculated using a simple for loop.
Following its prolog, the function Avx512CalcColumnMeans_ validates argument values nrows and ncols. It then performs its required initializations. The mov ebx,1 and vpbroadcastq zmm4,rbx instructions load the value one into each quadword element of ZMM4. Registers RBX and R13 are then initialized as pointers to col_counts and x_min, respectively. The final initialization task employs a simple for loop that sets each element in col_means and col_counts to zero.
Similar to source code example Ch09_03, the inner for loop in Avx512CalcColumnMeans_ employs slightly different instruction sequences to sum column elements, which vary depending on the number of columns in the array (see Figure 9-2) and the current column index. For each row, elements in the first eight columns of x can be added to col_means using 512-bit wide packed double-precision floating-point addition. The remaining column element values are added to col_means using 512-, 256-, or 128-bit wide packed or scalar double-precision floating-point addition.
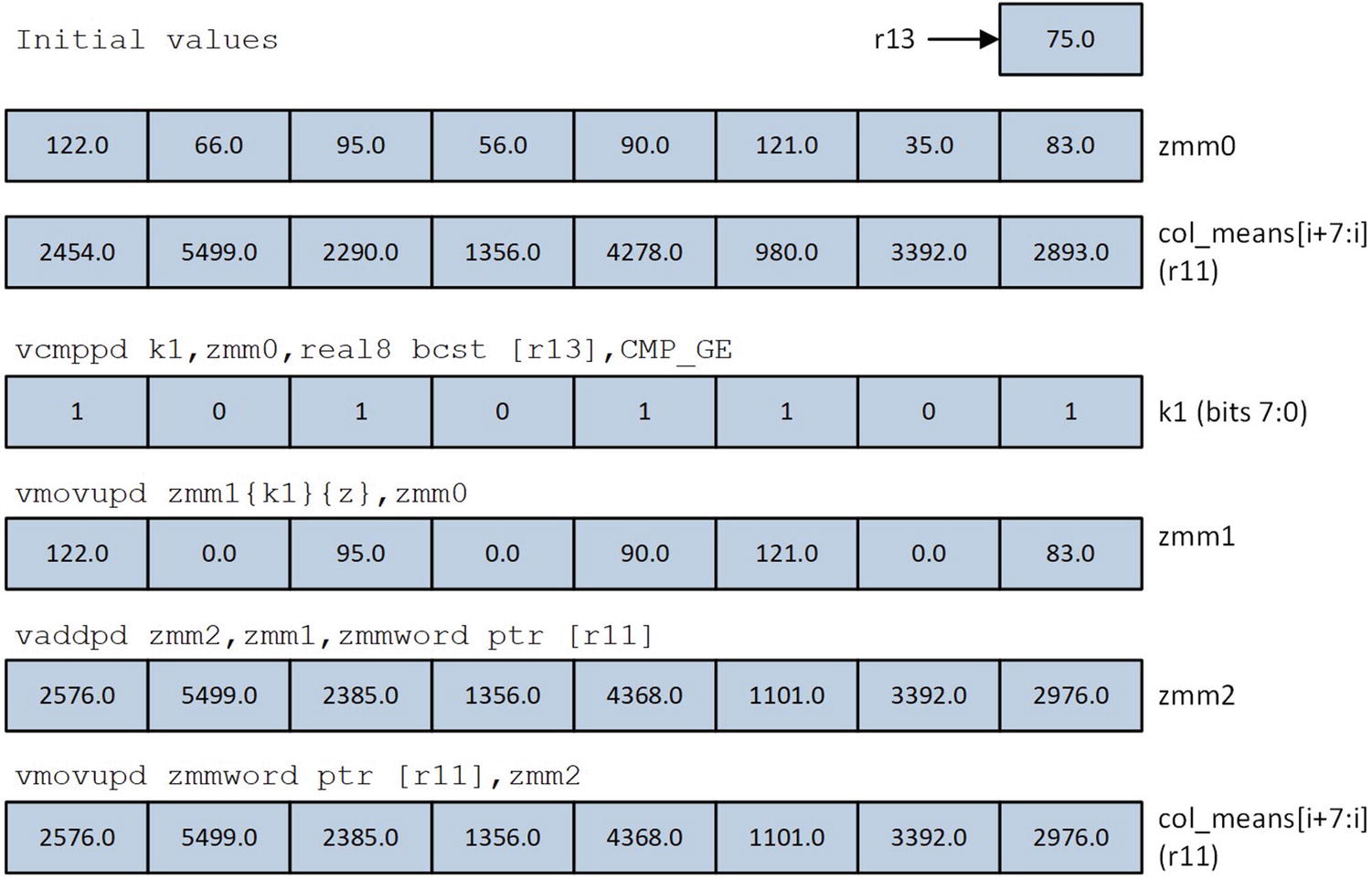
Updating the intermediate sums in col_means using zero merging

Updating the intermediate element counts in col_counts
Vector Cross Products
Example Ch13_07

The C++ header file Ch13_07.h that’s shown in Listing 13-7 includes the structure definitions Vector and VectorSoA. The structure Vector contains three double-precision floating-point values—X, Y, and Z—that represent the components of a three-dimensional vector. The VectorSoA structure incorporates three pointers to double-precision floating-point arrays. Each array contains the values for a single vector component. Example Ch13_07 uses these structures to compare the performance of two different vector cross product calculating algorithms. The first algorithm performs its calculations using an array of structures (AOS) , while the second algorithm exploits a structure of arrays (SOA) .
The C++ function Avx512Vcp begins its execution by allocating storage space for sets of vector data structures. This function uses the C++ template class unique_ptr<Vector> to allocate storage for three AOSs. Note that each Vector object is not explicitly aligned on a 64-byte boundary since doing this would consume a considerable about of storage space that’s never used. Each unique_ptr<Vector> AOS is also representative of how this type of data construct is commonly employed in many real-world programs. Avx512Vcp uses the C++ template class AlignedArray<double> to allocate properly aligned storage space for the vector SOAs. Following data structure allocation, the function InitVec initializes both sets of vectors a and b using random values. It then invokes the assembly language vector cross product functions Avx512VcpAos_ and Avx512VcpSoa_.

Memory ordering of components X, Y, and Z in an array of Vector objects
Following validation of num_vec, three vmovdqa64 (Move Aligned Packed Quadword Values) instructions load the gather /scatter indices for Vector components X, Y, and X into registers ZMM29, ZMM30, and ZMM31, respectively. The processing loop begins with a kxnorb k1,k1,k1 instruction that sets the low-order eight bits of opmask register K1 to one. The subsequent vgatherqpd zmm0{k1},[rdx+zmm29*8] instruction loads eight X component values from Vector a into register ZMM0. The vgatherqpd instruction loads eight values since the low-order eight bits of opmask register K1 are all set to one.
Five more sets of kxnorb and vgatherqpd instructions load the remaining Vector components into registers ZMM1–ZMM5. Note that during its execution, the vgatherqpd instruction sets the entire opmask register to zero unless an exception occurs due to an invalid memory access, which can be caused by an incorrect index or bad base register value. This updating of the opmask register introduces a potential register dependency that is eliminated by using a different opmask register for each vgatherqpd instruction. The next code block calculates eight vector cross products using basic packed double-precision floating-point arithmetic. The cross-product results are then saved to the destination Vector array c using three vscatterqpd instructions. Like the vgatherqpd instruction, the vscatterqpd instruction also sets its opmask register operand to zero unless an exception occurs.
Benchmark Timing Measurements for Vector Cross Product Calculating Functions (1,000,000 Cross Products)
CPU | Avx512VcpAos_ | Avx512VcpSoa_ |
|---|---|---|
i7-4790S | ---- | ---- |
i9-7900X | 4734 | 4141 |
i7-8700K | ---- | ---- |
Matrix-Vector Multiplication
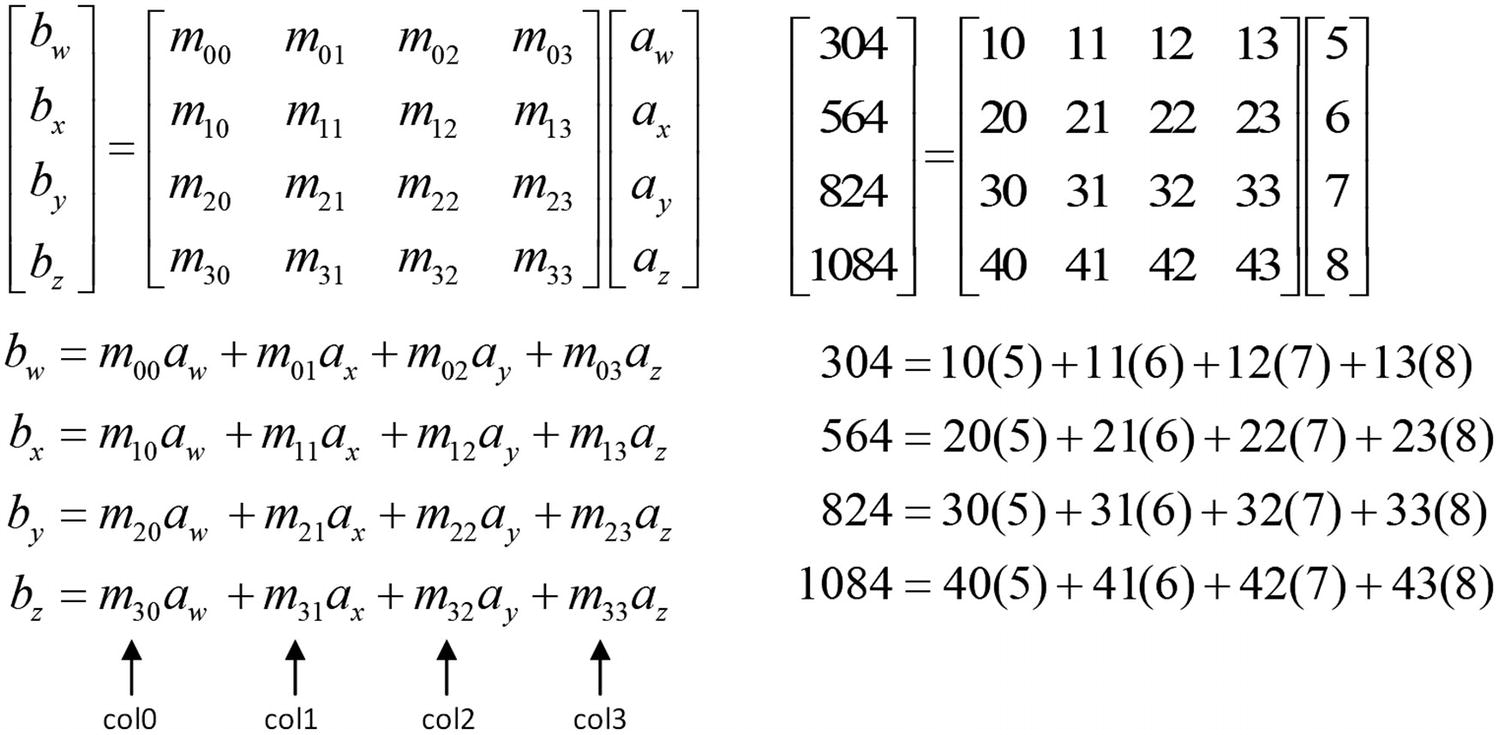
Equations for matrix-vector multiplication and a sample calculation
Example Ch13_08
The C++ code in Listing 13-8 begins with header file Ch13_08.h that contains the requisite function declarations. This file also includes a declaration for the structure Vec4x1_F32, which incorporates the four components of a 4 × 1 column vector. The source code file Ch13_08.cpp includes a function named Avx512MatVecMulF32Cpp. This function implements the matrix-vector multiplication equations that are shown in Figure 13-5. The remaining C++ code in Listing 13-8 performs test case initializations, invokes the calculating functions, and displays the results.
The assembly language code in Listing 13-8 starts with a constant data segment that defines a series of packed permutation indices. The assembly language implementation of the matrix-vector multiplication algorithm uses these values to reorder the elements of the source matrix and vectors. The reason for this reordering is to facilitate the simultaneous calculation of four matrix-vector products. The function Avx512MatVecMulF32_ begins its execution by validating num_vec for divisibility by four. It then checks the matrix and vector buffer pointers for proper alignment on a 64-byte boundary.

Permutation of matrix columns using vpermps instructions

Permutation of vector components using vpermps instructions

Matrix-vector multiplications using vmulps and vaddps
Benchmark Timing Measurements for Matrix-Vector Multiplication Functions (1,000,000 Vectors)
CPU | Avx512MatVecMulF32Cpp | Avx512MatVecMulF32_ |
|---|---|---|
i7-4790S | ---- | ---- |
i9-7900X | 6174 | 1778 |
i7-8700K | ---- | ---- |
Convolutions
Example Ch13_09
The C++ portion of source code example Ch13_09 is not shown in Listing 13-9 since it’s almost identical to the C++ code in example Ch11_02. Modifications made in the Ch13_09 C++ code include a few function name changes. The test arrays are also allocated on a 64-byte instead of a 32-byte boundary.
The assembly language function Avx512Convolve2_ implements the variable-size kernel convolution algorithm that’s described in Chapter 11. The primary difference between this function and its AVX2 counterpart Convolve2_ (see Listing 11-2) is the use of ZMM registers instead of YMM registers . The code that adjusts the index counter in register RBX was also modified to reflect the processing of 16 data points per iteration instead of 8. Similar changes were also made to the fixed-size kernel convolution function Avx512Convolve2Ks5_.
Mean Execution Times (Microseconds) for AVX2 and AVX-512 Convolution Functions Using Five-Element Convolution Kernel (2,000,000 Signal Points)
CPU | Convolve2_ | Avx512Convolve2_ | Convolve2Ks5_ | Avx512Convolve2Ks5_ |
|---|---|---|---|---|
i7-4790S | 1244 | ----- | 1067 | ---- |
i9-7900X | 956 | 757 | 719 | 693 |
i7-8700K | 859 | ----- | 595 | ---- |
Summary
When using merge masking with scalar or packed operands, the processor carries out the instruction’s calculation only if the corresponding opmask register bit is set to one. Otherwise, no calculation is performed and the destination operand element remains unchanged.
AVX-512 assembly language functions can use an opmask register destination operand with most instructions that perform scalar or packed compare operations. The bits of the opmask register can then be employed to effect data-driven logic decisions sans any conditional jump instructions using either merge or zero masking and (if necessary) simple Boolean operations.
AVX-512 assembly language functions must use the vmovdqu[32|64] and vmovdqa[32|64] instructions to perform move operations using 512-bit wide packed doubleword and quadword integer operands. These instructions can also be used with 256-bit and 128-bit wide operands.
Unlike AVX and AVX2, AVX-512 includes instructions that perform conversions between floating-point and unsigned integer operands.
AVX-512 functions should ensure that packed 128-, 256-, and 512-bit wide operands are aligned on a proper boundary whenever possible.
Assembly language functions that use AVX-512 instructions with registers ZMM0–ZMM15 or YMM0–YMM15 register operands should always use a vzeroupper instruction before program control is transferred back to the calling function.
Assembly language functions and algorithms that employ a structure of arrays are often faster than those that use an array of structures.
The Visual C++ calling convention treats AVX-512 registers ZMM16–ZMM31, YMM16–YMM31, and XMM16–XMM31 as volatile across function boundaries. This means that a function can use these registers without needing to preserve their values.