
The source code examples of the previous chapter elucidated the fundamentals of AVX programming using scalar floating-point arithmetic. In this chapter, you’ll learn how to use the AVX instruction set to perform operations using packed floating-point operands. The chapter begins with three source code examples that demonstrate common packed floating-point operations, including basic arithmetic, data comparisons, and data conversions. The next set of source code examples illustrate how to carry out SIMD computations using floating-point arrays. The final two source code examples explain how to use the AVX instruction set to accelerate matrix transposition and multiplication.
In Chapter 4 you learned that AVX supports packed floating-point operations using either 128-bit or 256-bit wide operands. All of the source code examples in this chapter use 128-bit wide packed floating-point operands, both single-precision and double-precision, and the XMM register set. You’ll learn how to use 256-bit wide packed floating-point operands and the YMM register set in Chapter 9.
Packed Floating-Point Arithmetic
Example Ch06_01
Listing 6-1 begins with the declaration of a C++ structure named XmmVal that’s declared in the header file XmmVal.h. This structure contains a publicly-accessible anonymous union that facilitates packed operand data exchange between functions written in C++ and x86 assembly language. The members of this union correspond to the packed data types that can be used with an XMM register. The structure XmmVal also includes several member functions that format and display the contents of an XmmVal variable (the source code for these member functions is not shown but included with the chapter download package).
Near the top of the C++ code are the declarations for the x86-64 assembly language functions AvxPackedMath32_ and AvxPackedMath64_. These functions carry out ordinary packed arithmetic operations using the supplied XmmVal argument values. Note that for both AvxPackedMath32_ and AvxPackedMath64_, arguments a and b are passed by reference instead of value in order to avoid the overhead of an XmmVal copy operation. Using pointers to pass a and b would also work in this example since pointers and references are the same from the perspective of the x86-64 assembly language functions.
Immediately following the assembly language function declarations is the definition for function AvxPackedMathF32. This function contains code that demonstrates packed single-precision floating-point arithmetic. Note that the XmmVal variables a, b, and c are all defined using the specifier alignas(16), which instructs the C++ compiler to align each variable on a 16-byte boundary. The next set of statements initializes the arrays a.m_F32 and b.m_F32 with test values. The C++ code then calls the assembly language function AvxPackedMathF32_ to perform various arithmetic operations using the packed single-precision floating-point operands. The results are then displayed using a series of stream writes to cout. The C++ code also contains a function named AvxPackedMath64 that illustrates arithmetic operations using packed double-precision floating-point operands. The organization of this function is similar to AvxPackedMath32.
The x86-64 assembly language code for example Ch06_01 begins with a .const section that defines packed mask values for calculating floating-point absolute values. The align 16 statement is a MASM directive that instructs the assembler to align the next variable (or instruction) to a 16-byte boundary. Using this statement guarantees that the mask AbsMaskF32 is properly aligned. Note that unlike x86-SSE, x86-AVX instruction operands in memory need not be properly aligned except for instructions that explicitly specify aligned operands (e.g., vmovaps). However, proper alignment of packed operands in memory is strongly recommended whenever possible in order to avoid the performance penalties that can occur when the processor accesses an unaligned operand. A second align 16 directive is not necessary to ensure alignment of AbsMaskF64 since the size of AbsMaskF32 is 16 bytes, but it would be okay to include such a statement.

Execution of vaddps instruction
The ensuing vsubps, vmulps, and vdivps instructions carry out packed single-precision floating-point subtraction, multiplication, and division. This is followed by a vandps xmm2,xmm1,xmmword ptr [AbsMaskF32] instruction that calculates packed absolute values using argument b. The vandps (Bitwise AND of Packed Single-Precision Floating-Point Values) instruction performs a bitwise AND using its two source operands. Note that all of the bits in each AbsMaskF32 doubleword are set to one except the most significant bit, which corresponds to the sign bit of a single-precision floating-point value. A sign bit value of zero corresponds to a positive floating-point number as discussed in Chapter 4. Performing a bitwise AND using this 128-bit wide mask and the packed single-precision floating-point operand b sets the sign bit of each element to zero and generates packed absolute values.
Packed Floating-Point Compares
Example Ch06_02

Execution of the vcmpps and vcmppd instructions
The C++ function AvxPackedCompareF32 begins by initializing a couple of XmmVal test variables. Similar to the example that you saw in the previous section, the alignas(16) specifier is used with each XmmVal variable to force proper alignment to a 16-byte boundary. The remaining code in this function invokes the assembly language AvxPackedCompareF32_ and displays the results. Note that on the second iteration of the for loop, the constant numeric_limits<float>::quiet_NaN() is substituted for one of the values in XmmVal a to exemplify operation of the ordered and unordered compare predicates. An ordered compare is true when both operands are valid values. An unordered compare is true when one or both of the operands is a NaN or erroneously encoded. Substituting numeric_limits<float>::quiet_NaN() for one of the values in XmmVal a generates a true result for an unordered compare. The C++ code also includes the function AvxPackedCompareF64, which is the double-precision counterpart of AvxPackedCompareF32.
Packed Floating-Point Conversions
Example Ch06_03
The C++ code begins with an enum named CvtOP that defines the conversion operations supported by the assembly language function AvxPackedConvertFP_. The actual enumerator values in CvtOp are critical since the assembly language code uses them as indices into a jump table . The function that follows CvtOp, AvxPackedConvertF32, exercises some test cases using packed single-precision floating-point operands. Similarly, the function AvxPackedConvertF64 contains test cases for packed double-precision floating-point operands. As in the previous examples of this chapter, all XmmVal variable declarations in these functions use the alignas(16) specifier to ensure proper alignment.
Toward the bottom of the assembly language code in Listing 6-3 is the previously mentioned jump table. CvtOpTable contains a list of labels that are defined in the function AvxPackedConvertFP_. The target of each label is a short code block that performs a specific conversion. The equate CvtOpTableCount defines the number of items in the jump table and is used to validate the argument value cvt_op. The align 8 directive instructs the assembler to align CvtOpTable on a quadword boundary in order to avoid unaligned memory accesses when referencing elements in the table. Note that CvtOpTable is defined inside the assembly language function AvxPackedConvertFP_ (i.e., between the proc and endp directives), which means that storage for the table is allocated in a .code section. Clearly, the jump table does not contain any intentional executable instructions, and this is why the table is positioned after the ret instruction. This also means that the jump table is read-only; the processor will generate an exception on any write attempt to the table.
The assembly language function AvxPackedConvertFP_ begins its execution by validating the argument value cvt_op. The ensuing jmp [CvtOpTable+r9*8] instruction transfers control to a code block that performs the actual packed data conversion. During execution of this instruction, the processor loads register RIP with the contents of memory that’s specified by [CvxOpTable+r9*8]. In the current example, register R9 contains cvt_op and this value is used as an index into CvtOpTable.
Packed Floating-Point Arrays
The computational resources of AVX are often employed to accelerate calculations using arrays of single-precision or double-precision floating-point values. In this section, you learn how to use packed arithmetic to process multiple elements of a floating-point array simultaneously. You also see examples of additional AVX instructions and learn how to perform runtime alignment checks of operands in memory.
Packed Floating-Point Square Roots
Example Ch06_04
The C++ code in Listing 6-4 includes a function named AvxCalcSqrtsCpp, which calculates y[i] = sqrt(x[i]). Before performing any of the required calculations, array size argument n is tested to make sure that’s not equal to zero. The pointers y and x are also tested to ensure that the respective arrays are properly aligned to a 16-byte boundary. An array is aligned to a 16-byte boundary if its address is evenly divisible by 16. The function returns an error code if any of these checks fail.
Assembly language function AvxCalcSqrts_ mimics the functionality of its C++ counterpart. The test r8,r8 and jz Done instructions ensure that the number of array elements n is greater than zero. The ensuing test rcx,0fh instruction checks array y for alignment to a 16-byte boundary. Recall that the test instruction performs a bitwise AND of its two operands and sets the status flags in RFLAGS according to the result (the actual result of the bitwise AND is discarded). If the test rcx,0fh instruction yields a non-zero value, array y is not aligned on a 16-byte boundary, and the function exits without performing any calculations. A similar test is used to ensure that array x is properly aligned.
The processing loop uses a vsqrtps instruction to calculate the required square roots. When used with 128-bit wide operands, this instruction calculates four single-precision floating-point square roots simultaneously. Using 128-bit wide operands means that the processing loop cannot execute a vsqrtps instruction if there are fewer than four element values remaining to be processed. Before performing any calculations using vsqrtps, R8 is checked to make sure that it’s greater than or equal to four. If R8 is less than four, the processing loop is skipped. The processing loop employs a vsqrtps xmm0,xmmword ptr [rdx+rax] instruction to calculate square roots of the four single-precision floating-point values located at the memory address specified by the source operand. It then stores the calculated square roots in register XMM0. A vmovaps xmmword ptr [rcx+rax],xmm0 instruction saves the four calculated square roots to y. Execution of the vsqrtps and vmovaps instructions continues until the number of elements remaining to be processed is less than four.
The source code in Listing 6-4 can be easily adapted to process double-precision instead of single-precision floating-point values. In the C++ code, changing all float variables double is the only required modification. In the assembly language code, the vsqrtpd and vmovapd instructions must be used instead of vsqrtps and vmovaps. The counting variables in AvxCalcSqrts_ must also be changed to process two double-precision instead of four single-precision floating-point values per iteration.
Packed Floating-Point Array Min-Max
Example Ch06_05
The structure of the C++ source code that’s shown in Listing 6-5 is similar to the previous array example. The function CalcArrayMinMaxF32Cpp uses a simple for loop to determine the array’s minimum and maximum values. Prior to the for loop, the template function AlignedMem::IsAligned verifies that source array x is properly aligned. You’ll learn more about class AlignedMem in Chapter 7. The initial minimum and maximum values are obtained from the global variables g_MinValInit and g_MaxValInit, which were initialized using the C++ template constant numeric_limits<float>::max(). Global variables are employed here to ensure that the functions CalcArrayMinMaxF32Cpp and CalcArrayMinMaxF32_ use the same initial values.
Upon entry to the assembly language function CalcArrayMinMaxF32_, the array x is tested for proper alignment. If array x is properly aligned, a vbroadcastss xmm4,real4 ptr [g_MinValInit] instruction initializes all four single-precision floating-point elements in register XMM4 with the value g_MinValInit. The subsequent vbroadcastss xmm5,real4 ptr [g_MaxValInit] instruction broadcasts g_MaxValInit to all four element positions in register XMM5.
Like the previous example, the processing loop in CalcArrayMinMaxF32_ examines four array elements during each iteration. The vminps xmm4,xmm4,xmm0 and vmaxps xmm5,xmm5,xmm0 instructions maintain intermediate packed minimum and maximum values in registers XMM4 and XMM5, respectively. The processing loop continues until there fewer than four elements remaining. The final elements in the array are tested using the scalar instructions vminss and vmaxss.
Subsequent to the execution of the vmaxss instruction that’s immediately above the label SaveResults, register XMM4 contains four single-precision floating-point values, and one of these values is the minimum for array x. A series of vshufps (Packed Interleave Shuffle Single-Precision Floating-Point Values) and vminps instructions is then used to determine the final minimum value. The vshufps xmm0,xmm4,xmm4,00001110b instruction copies the two high-order floating-point elements in register XMM4 to the low-order element positions in XMM0 (i.e., XMM0[63:0] = XMM4[127:64]). This instruction uses the bit values of its immediate operand as indices for selecting elements to copy.
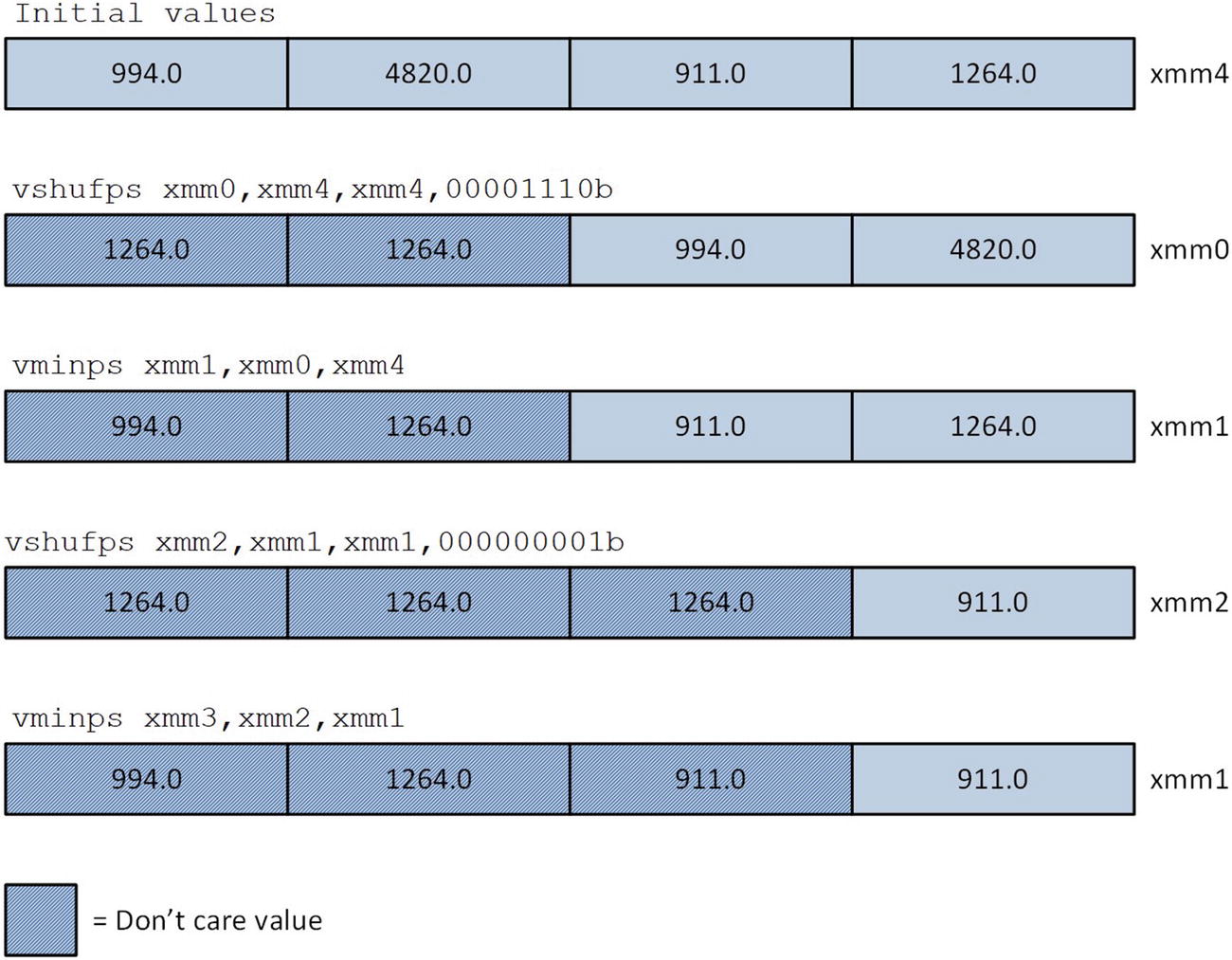
Packed minimum reduction using vshufps and vminps instructions
Packed Floating-Point Least Squares
Example Ch06_06
Simple linear regression is a statistical technique that models a linear relationship between two variables. One popular method of simple linear regression is called least squares fitting, which uses a set of sample data points to determine a best fit or optimal curve between two variables. When used with a simple linear regression model, the curve is a straight line whose equation is y = mx + b. In this equation, x denotes the independent variable, y represents the dependent (or measured) variable, m is the line’s slope, and b is the line’s y-axis intercept point. The slope and intercept point of a least squares line are determined using a series of computations that minimize the sum of the squared deviations between the line and sample data points. Following calculation of its slope and intercept point, a least squares line is frequently used to predict an unknown y value using a known x value. If you’re interested in learning more about the theory of simple linear regression and least squares fitting, consult the references listed in Appendix A.
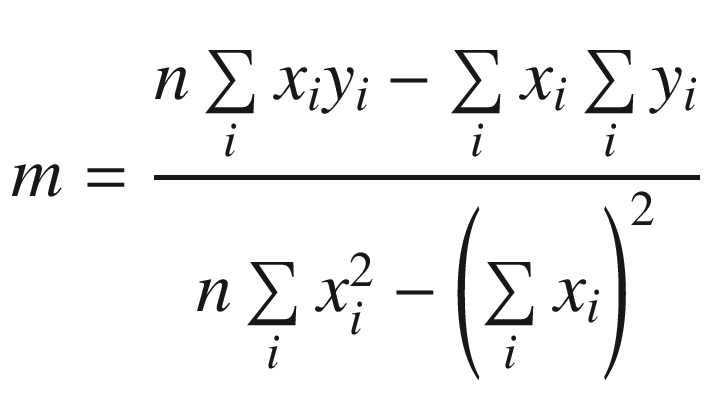
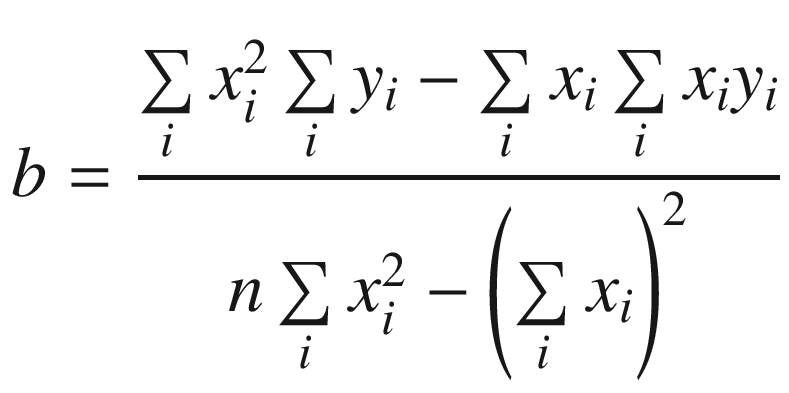


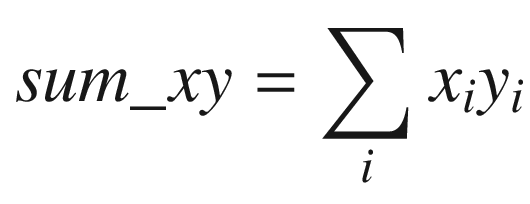
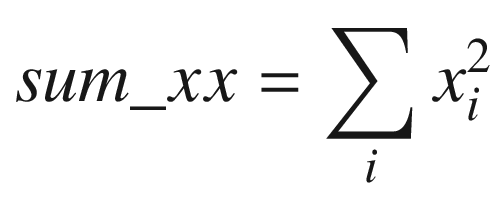
Subsequent to the calculation of the sum variables, the least-squares slope and intercept point are easily derived using straightforward multiplication, subtraction, and division.
The C++ source code in Listing 6-6 includes a function named AvxCalcLeastSquaresCpp that calculates a least-squares slope and intercept point for comparison purposes. AvxCalcLeastSquaresCpp uses AlignedMem::IsAligned() to validate proper alignment of the two data arrays. The C++ class AlignedMem (source code not shown but included in the download package) contains a few simple member functions that perform aligned memory management and validation. These functions have been incorporated into a C++ class to facilitate code reuse in this example and subsequent chapters. The C++ function main defines a couple of test arrays named x and y using the C++ specifier alignas(16), which instructs the compiler to align each of these arrays on a 16-byte boundary. The remainder of main contains code that exercises both the C++ and x86 assembly language implementations of the least squares algorithm and streams the results to cout.
The x86-64 assembly language code for function AvxCalcLeastSquares_ begins with saves of non-volatile registers RBX, XMM6, XMM7, and XMM8 using the macros _CreateFrame and _SaveXmmRegs. Argument value n is then validated for size, and the array pointers x and y are tested for proper alignment. Following validation of the function arguments, a series of initializations is performed. The vcvtsi2sd xmm3,xmm3,r8d instruction converts the value n to double-precision floating-point for later use. The value n in R8D is then rounded down to the nearest even number using an and r8d,0fffffffeh instruction and EAX is set to zero or one depending on whether the original value of n is even or odd. These adjustments are carried out to ensure proper processing of arrays x and y using packed arithmetic.
Recall from the discussions earlier in this section that in order to compute the slope and intercept point of a least squares regression line, you need to calculate four intermediate sum values: sum_x, sum_y, sum_xx, and sum_xy. The summation loop that calculates these values in AvxCalcLeastSquares_ uses packed double-precision floating-point arithmetic. This means that AvxCalcLeastSquares_ can process two elements from arrays x and y during each loop iteration, which halves the number of required iterations. The sum values for array elements with even-numbered indices are computed using the low-order quadwords of XMM4-XMM7, while the high-order quadwords are used to calculate the sum values for array elements with odd-numbered indices.
Prior to entering the summation loop, each sum value register is initialized to zero using a vxorpd instruction. At the top of the summation loop, a vmovapd xmm0,xmmword ptr [rcx+rbx] instruction copies x[i] and x[i+1] into the low-order and high-order quadwords of XMM0, respectively. The next instruction, vmovapd xmm1,xmmword ptr [rdx+rbx], loads y[i] and y[i+1] into the low-order and high-order quadwords of XMM1. A series of vaddpd and vmulpd instructions update the packed sum values that are maintained in XMM4 - XMM7. Array offset register RBX is then incremented by 16 (or the size of two double-precision floating-point values) and the count value in R8D is adjusted before the next summation loop iteration. Following completion of the summation loop, a check is made to determine if the original value of n was odd. If true, the final element of array x and array y must be added to the packed sum values. The AVX scalar instructions vaddsd and vmulsd carry out this operation.
Packed Floating-Point Matrices
Software applications such as computer graphics and computer-aided design programs often make extensive use of matrices. For example, three-dimensional (3D) computer graphics software typically employs matrices to perform common transformations such as translation, scaling, and rotation. When using homogeneous coordinates, each of these operations can be efficiently represented using a single 4 × 4 matrix. Multiple transformations can also be applied by merging a series of distinct transformation matrices into a single transformation matrix using matrix multiplication. This combined matrix is typically applied to an array of object vertices that defines a 3D model. It is important for 3D computer graphics software to carry out operations such as matrix multiplication and matrix-vector multiplication as quickly as possible since a 3D model may contain thousands or even millions of object vertices.
In this section, you learn how to perform matrix transposition and multiplication using 4 × 4 matrices and the AVX instruction set. You also learn more about assembly language macros, how to write macro code, and some simple techniques for benchmarking algorithm performance.
Matrix Transposition

Transposition of a 4 × 4 matrix
Example Ch06_07
The function main begins by instantiating a 4 × 4 single-precision floating-point test matrix named m_src using the C++ template Matrix. This template, which is defined in the header file Matrix.h (source code not shown), contains C++ code that implements a simple matrix class for test and benchmarking purposes. The internal buffer allocated by Matrix is aligned on a 64-byte boundary, which means that objects of type Matrix are properly aligned for use with AVX, AVX2, and AVX-512 instructions. The function main calls AvxMat4x4TransposeF32, which exercises the matrix transposition functions written in C++ and assembly language. The results of these transpositions are then streamed to cout. The function main also invokes a benchmarking function named AvxMat4x4TransposeF32_BM that measures the performance of each transposition function as explained later in this section.
Near the top of assembly language code is a macro named _Mat4x4TransposeF32. You learned in Chapter 5 that a macro is an assembler text substitution mechanism that allows a single text string to represent a sequence of assembly language instructions, data definitions, or other statements. During assembly of an x86 assembly language source code file, the assembler replaces any occurrence of the macro name with the statements that are declared between the macro and endm directives . Assembly language macros are typically employed to generate sequences of instructions that will be used more than once. Macros are also frequently used to avoid the performance overhead of a function call.
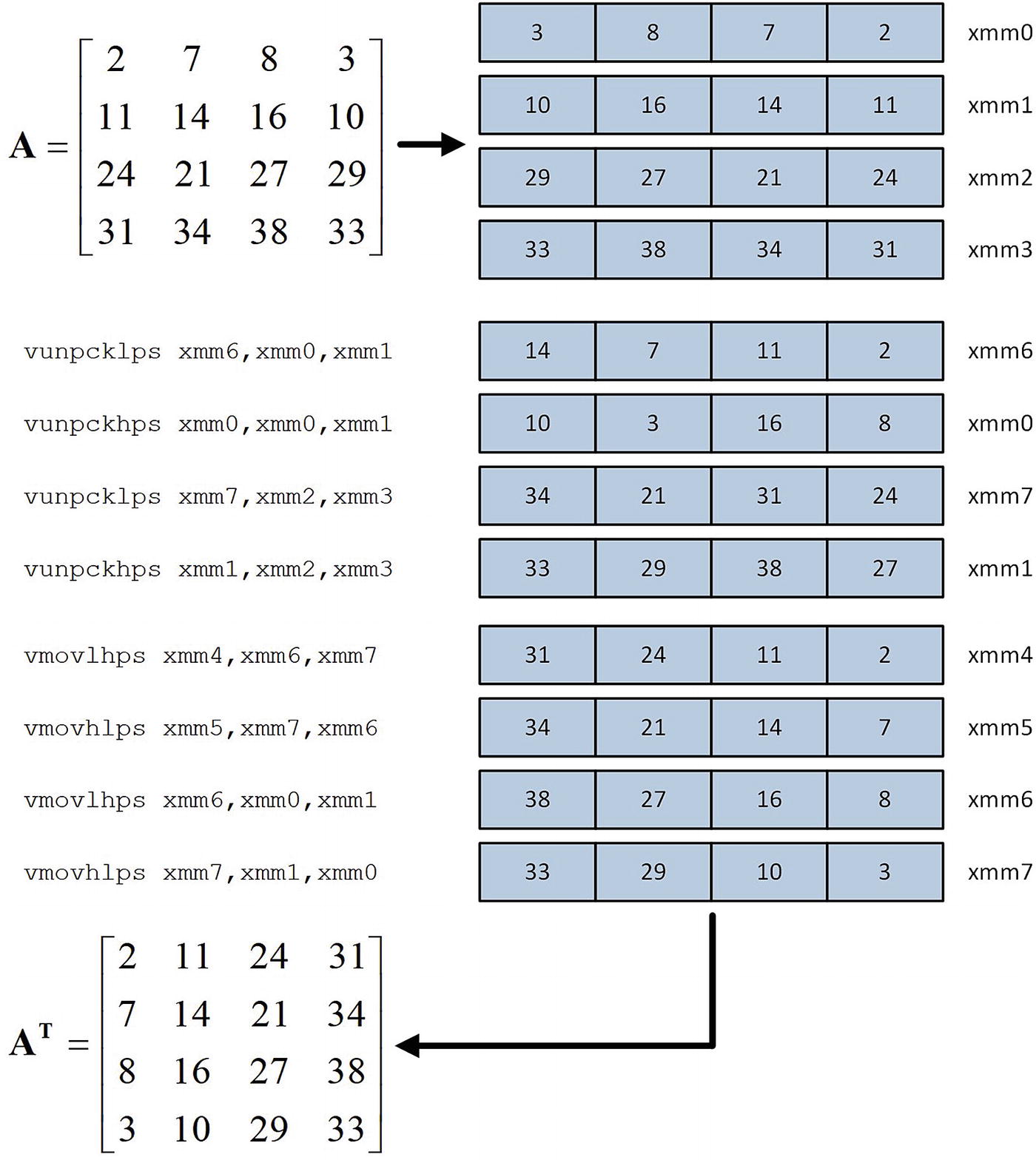
Instruction sequence used by _Mat4x4TransposeF32 to transpose a 4 × 4 matrix of single-precision floating-point values

Expansion of macro _Mat4x4TransposeF32
Source code example Ch06_07 includes a function named AvxMat4x4TransposeF32_BM that contains code for measuring execution times of the C++ and assembly language matrix transposition functions. Most of the timing measurement code is encapsulated in a C++ class named BmThreadTimer . This class includes two member functions, BmThreadTimer::Start and BmThreadTimer::Stop, that implement a simple software stopwatch. Class BmThreadTimer also includes a member function named BmThreadTimer::SaveElapsedTimes, which saves the timing measurements to a comma-separated text file. AvxMat4x4Transpose_BM also uses a C++ class named OS . This class includes member functions that manage process and thread affinity. In the current example, OS::SetThreadAffinityMask selects a specific processor for benchmark thread execution. Doing this improves the accuracy of the timing measurements. The source code for classes BmThreadTimer and OS is not shown in Listing 6-7, but is included as part of the chapter download package.
Matrix Transposition Mean Execution Times (Microseconds), 1,000,000 Transpositions
CPU | C++ | Assembly Language |
|---|---|---|
Intel Core i7-4790S | 15885 | 2575 |
Intel Core i9-7900X | 13381 | 2203 |
Intel Core i7-8700K | 12216 | 1825 |
The values shown in Table 6-1 were computed using the CSV file execution times and the Excel spreadsheet function TRIMMEAN (array,0.10). The assembly language implementation of the matrix transposition algorithm clearly outperforms the C++ version by a wide margin. It is not uncommon to achieve significant speed improvements using x86 assembly language, especially by algorithms that can exploit the SIMD parallelism of an x86 processor. You’ll see additional examples of accelerated algorithmic performance throughout the remainder of this book.
The benchmark timing measurements cited in this book provide reasonable approximations of function execution times. Like automobile fuel economy and battery runtime estimates, software performance benchmarking is not an exact science and subject to a variety of pitfalls. It is also important to keep mind that this book is an introductory primer about x86-64 assembly language programming and not benchmarking. The source code examples are structured to hasten the study of a new programming language and not maximum performance. In addition, the Visual C++ options described earlier were selected mostly for practical reasons and may not yield optimal performance in all cases. Like many high-level compilers, Visual C++ includes a plethora of code generation and speed options that can affect performance. Benchmark timing measurements should always be construed in a context that’s correlated with the software’s purpose. The methods described in this section are generally worthwhile, but results can vary.
Matrix Multiplication
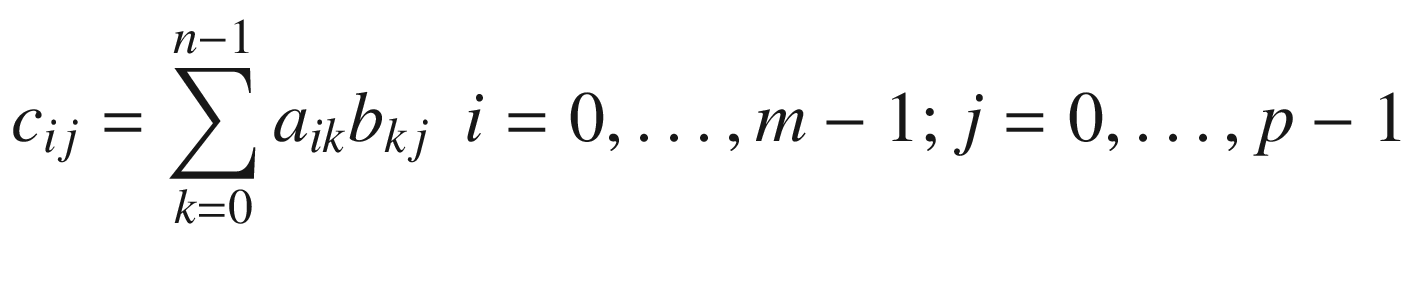
Before proceeding to the sample code, a few comments are warranted. According to the definition of matrix multiplication, the number of columns in A must equal the number of rows in B. For example, if A is a 3 × 4 matrix and B is a 4 × 2 matrix, the product AB (a 3 × 2 matrix) can be calculated but the product BA is undefined. Note that the value of each c(i, j) in C is simply the dot product of row i in matrix A and column j in matrix B. The assembly language code will exploit this fact to perform matrix multiplications using packed AVX instructions. Also note that unlike most mathematical texts, the subscripts in the matrix multiplication equation use zero-based indexing. This simplifies translating the equation into C++ and assembly language code.
Example Ch06_08

Equations for first row of matrix C = AB
Matrix Multiplication Mean Execution Times (Microseconds), 1,000,000 Multiplications
CPU | C++ | Assembly Language |
|---|---|---|
Intel Core i7-4790S | 55195 | 5333 |
Intel Core i9-7900X | 46008 | 4897 |
Intel Core i7-8700K | 42260 | 4493 |
Summary
The vaddp[d|s], vsubp[d|s], vmulp[d|s], vdivp[d|s], and vsqrtp[d|s] instructions carry out common arithmetic operation using packed double-precision and packed single-precision floating-point operands.
The vcvtp[d|s]2dq and vcvtdq2p[d|s] instructions perform conversions between packed floating-point and packed signed-doubleword operands. The vcvtps2pd and vcvtpd2ps perform conversions between packed single-precision and double-precision operands.
The vminp[d|s] and vmaxp[d|s] instructions perform packed minimum and maximum value calculations using double-precision and single-precision floating-point operands.
The vbroadcasts[d|s] instructions broadcast (or copy) a single scalar double-precision or single-precision value to all element positions of an x86 SIMD register.
Assembly language functions that use the vmovap[d|s] and vmovdqa instructions can only be used with operands in memory that are properly aligned. The MASM align 16 directive aligns data items in a .const or .data section to a 16-byte boundary. C++ functions can use the alignas specifier to guarantee proper alignment.
Assembly language functions can use the vunpck[h|l]p[d|s] instructions to accelerate common matrix operations, especially 4 × 4 matrices.
Assembly language functions can use the vhaddp[d|s] and vshufp[d|s] instructions to perform data reductions of intermediate packed values.
Many algorithms can achieve significant performance gains by using SIMD programming techniques and the x86-AVX instruction set.