
Providing software that lets people do their jobs is usability; providing software that lets 10,000 people do their jobs is scalability. The term scalability encompasses many facets of software. It means stability, reliability, and efficient use of one or more computer resources. The goal of a scalable system is that it must be available for use at all times and remain highly responsive regardless of how many people use the system.
Scalability, with respect to software architectures, has also come to mean extensibility and modularity. This simply means that when a software system needs to scale upward in complexity, it does not need to be overhauled with each addition. In the following pages, you will learn about both aspects of scalability.
The first half of this chapter deals with scalable architecture design. This is most largely applicable when a distributed service requires more than one server and the system-performance-to-hardware-cost ratio is of paramount importance. This is followed by some hands-on code examples of how to provide added scalability to your application, such as load balancing and efficient thread management.
Google.com is certainly the Internet’s largest search engine. It serves 200 million requests per day and runs from more than 15,000 servers distributed worldwide. It is arguably one of the most scalable Internet services ever provided to the general public.
Each server that Google uses is no more powerful than the average desktop PC. Granted, each server crashes every so often, and they are prone to hardware failure, but a complex software failover system is employed by Google to account for server crashes seamlessly. This means that even if a hundred servers crashed at the same time, the service would still be available and in working order.
The rationale behind using a large number of bog-standard PCs rather than a few state-of-the-art servers is simple: cost per performance. It is possible to buy servers with 8 CPUs, 64-Gb memory, and 8 Tb of disk space, but these cost roughly three times the price of a rack of 88 dual-processor machines with 2-Gb memory and 80-Gb disk space. The high-end server would serve a single client four times faster than the rack of slower computers, but the rack could serve 22 times as many of concurrent users as the high-end server. That’s scalability.
It is not the case, however, to say that one server handles one user’s request. If this were the case, each computer would have to trawl through thousands of terabytes of data looking for a search term. It would take weeks to return a single query. Instead, the servers are divided into six different groups—Web servers, document servers, index servers, spell check servers, advertisement servers, and Googlebot servers—each performing its own task.
Google uses a sophisticated DNS system to select the most appropriate Web server for its visitors. This DNS system can automatically redirect visitors to the geographically closest data center. This is why, for instance, if you type www.google.com in Switzerland, you will be directed to www.google.ch, which is located in Zurich. But if you type www.google.com in California, you will be directed to their data center in Santa Clara. The DNS system also accounts for server load and may redirect to different centers in the event of high congestion.
When the request arrives at the data center, it goes through a hardware load balancer that selects one from a cluster of available Web servers to handle the request. These Web servers’ sole function is to prepare and serve the HTML to the client; they do not perform the actual search. The search task is delegated to a cluster of index servers, which lie behind the Web servers.
An index server cluster comprises hundreds of computers, each holding a subset (or shard) of a multiterabyte database. Many computers may hold identical subsets of the same database in case of a hardware failure on one of the index servers. The index itself is a list of correlated words and terms with a list of document IDs and a relevancy rating for each match. A document ID is a reference to a Web page or other Google-readable media (e.g., PDF, DOC). The order of results returned by the index depends on the combined relevancy rating of the search terms and the page rank of the document ID. The page rank is a gauge of site popularity measured as a sum of the popularity of the sites linking to it. Other factors also affect page rank, such as the number of links leaving the site, the structure of internal links, and so forth.
Google’s document servers contain cached copies of virtually the entire World Wide Web on their hard drives. Each data center would have its own document server cluster, and each document server cluster would need to hold at least two copies of the Web, in order to provide redundancy in case of server failure. But document servers are not merely data warehouses. They also perform retrieval of the page title and keyword-in-context snippet from the document ID provided by the index servers.
As the search is running, the peripheral systems also add their content to the page as the search is in progress. This includes the spell check and the advertisements. Once all elements of the page are together, the page is shipped off to the visitor, all in less than a second.
Google also employs another breed of software, a spider named Googlebot. This piece of software, running on thousands of PCs simultaneously, trawls the Web continuously, completing a full round-trip in approximately one month. Googlebot requests pages in an ordered fashion, following links to a set depth, storing the content in the document servers and updating the index servers with updated document IDs, relevancy ratings, and page rank values. Another spider named Fastbot crawls the Web on a more regular basis, sometimes in less than a week. It only visits sites with a high page rank and those that are frequently updated.
The Google architecture is one of the best in the world and is the pinnacle of scalability; however, for .NET developers, there is a slight twist in the tail. Google can afford to buy 15,000 servers by cutting down on licensing costs. This means that they use Linux, not Windows. Unfortunately, Linux isn’t exactly home turf for .NET, but there is an open-source project called MONO, which aims to provide a C# compiler for Linux (see www.gomono.com).
Keeping a backup system ready for instant deployment is redundancy; keeping the backup system identical to the live system is replication. When dealing with a high-availability Internet-based service, it is important to keep more than one copy of critical systems. Thus, in the event of software or hardware failure, an identical copy of the software can take the place of the failed module.
Backup systems do not need to be kept on separate machines. You can use redundant hard drives using a redundant array of inexpensive disks (RAID) array. This is where the file system is stored on several physical hard disks. If one disk fails, then the other disks take over, with no loss of data. Many computers can read from a RAID array at once but only one computer can write at the same time (known as “shared nothing”). Of course, it’s not just hard disks that fail. If a computer fails, another must take over in the same way.
Providing redundancy among computers is the task of a load balancer a piece of hardware or software that delegates client requests among multiple servers. In order to provide redundancy, the load balancer must be able to recognize a crashed computer or one that is unable to respond in a timely fashion. A full discussion of load balancers is included later in this chapter.
Replication provides the means by which a backup system can remain identical to the live system. If replication did not occur, data on the backup system could become so out-of-date that it would be worthless if set live. Replication is built into Microsoft SQL, accessible under the replication folder in Enterprise Manager. SQL replication works by relaying update, insert, and delete statements from one server to another. Changes made while the other server is down are queued until the server goes live again.
Server-side applications are often required to operate with full efficiency under extreme load. Efficiency, in this sense, relates to both the throughput of the server and the number of clients it can handle. In some cases, it is common to deny new clients to conserve resources for existing clients.
The key to providing scalable network applications is to keep threading as efficient as possible. In many examples in this book, a new thread is created for each new client that connects to the server. This approach, although simple, is not ideal. The underlying management of a single thread consumes far more memory and processor time than a socket.
In benchmarking tests, a simple echo server, running on a Pentium IV 1.7 GHz with 768-Mb memory, was connected to three clients: a Pentium II 233 MHz with 128-Mb memory, a Pentium II 350 MHz with 128-Mb memory, and an Itanium 733 MHz with 1-Gb memory. This semitypical arrangement demonstrated that using the approach outlined above, the server could only serve 1,008 connections before it reached an internal thread creation limit. The maximum throughput was 2 Mbps. When a further 12,000 connections were attempted and rejected, the throughput keeled off to a mere 404 Kbps.
The server, although having adequate memory and CPU time resources to handle the additional clients, was unable to because it could not create any further threads as thread creations and destructions were taking up all of the CPU resources. To better manage thread creation, a technique known as thread pooling (demonstrated later in this chapter) can be employed. When thread pooling was applied to the echo server example, the server performed somewhat better. With 12,000 client connections, the server handled each one without fail. The throughput was 1.8 Mbps, vastly outperforming the software in the previous example, which obtained only 0.4 Mbps at the same CPU load. As a further 49,000 clients connected, however, the server began to drop 0.6% of the connections. At the same time, the CPU usage reached 95% of its peak capacity. At this load, the combined throughput was 3.8 Mbps.
Thread pooling unarguably provides a scalability bonus, but it is not acceptable to consume 95% of server resources just doing socket I/O, especially when other applications must also use the computer. In order to beef up the server, the threading model should be abandoned completely, in favor of I/O completion ports (see Chapter 3). This methodology uses asynchronous callbacks that are managed at the operating system level.
By modifying the above example to use I/O completion ports rather than thread pools, the server once again handled 12,000 clients without fail; however, this time the throughput was an impressive 5 Mbps. When the load was pushed to 50,000 clients, the server handled these connections virtually flawlessly and maintained a healthy throughput of 4.3 Mbps. The CPU usage at this load was 65%, which could have permitted other applications to run on the same server without conflicts.
In the thread-pool and completion-port models, the memory usage at 50,000 connections was more than 240 Mb, including non-paged-pool usage at more than 145 Mb. If the server had less than this available in physical memory, the result would have been substantially worse.
Scalability can also apply to the ability of an application to evolve gracefully to meet future demands without major overhaul. When software is first designed, the primary goal is to hit all of the customer’s requirements or to meet the perceived needs of a typical end-user. After rollout of the product, it may address these requirements perfectly. Once the market demands some major change to the application, the program has to scale to meet the new demands without massive recoding.
This connotation of scalability is not the focus of the chapter, but some of the following tips may help create a future-proof application:
Use classes instead of basic types for variables that represent elements within your software that may grow in complexity. This ensures that functions accept these variables because parameters will not need to be changed as dramatically in the future.
Keep culture-specific strings in a resource file; if the software is ever localized for a different language, this will reduce the change impact.
Keep abreast of modern technologies. It may soon be a requirement of network applications to be IPv6 compliant.
Provide a means to update your software automatically post deployment.
The key to architectural scalability is to make everything configurable and to assume nothing of the deployment environment.
Every computer has a limit to the number of threads it can process at one time. Depending on the resources consumed by each thread, this number could be quite low. When given the choice either to guarantee your software to handle a set number of clients or to “max out” the computer’s resources and risk a system crash, choose the first option: thread pooling.
Threads can improve the responsiveness of applications, where each thread consumes less than 100% processor time. Multitasking operating systems share the available CPU resources among the running threads by quickly switching between them to give the impression that they are all running in parallel. This switching, which may occur up to 60 times per second, incurs some small switching cost, which can become prohibitive if the number of threads becomes too large. Threads that are blocked waiting for some event do not, however, consume CPU resources while they wait, but they still consume some kernel memory resources. The optimum number of threads for any given application is system dependent. A thread pool is useful at finding this optimum number of threads to use.
To give some perspective on the effect of unpooled threading, examine the code below:
C#
public static void IncrementThread()
{
while(true)
{
myIncrementor++;
long ticks = DateTime.Now.Ticks – startTime.Ticks;
lock (this)
{
lblIPS.Text = "Increments per second:" +
(myIncrementor / ticks) * 10000000;
}
}
}VB.NET
Public Shared Sub IncrementThread()
Dim ticks as long
Do
MyIncrementor = MyIncrementor+1
Ticks = DateTime.Now.Ticks – startTime.Ticks
SyncLock(me)
lblIPS.Text = "Increments per second:" + _
(myIncrementor / ticks) * 10000000
End synclock
Loop
End SubThis code adds one to a public variable named MyIncrementor. It then takes an accurate reading of system time, before updating the screen to show the level of increments per second. The SyncLock or Lock statement is used to ensure that no two threads attempt to update the screen at the same time because this causes unpredictable results. The results shown onscreen should not be used as a measure of how quickly the computer can perform subtraction because most of the processor time is actually spent showing the results!
When this thread was instantiated on its own, it operated at a speed of 235 increments per second; however, when this thread was instantiated 1,000 times and ran concurrently, the threads consumed more than 60 Mb of memory stack frame, which on some older computers would go directly to a paging file on disk, creating a systemwide loss of performance. In a group of 1,000 threads, the overall performance was a mere 98 increments per second, meaning that a single thread could take more than 10 seconds to iterate through one while loop. The test machine was a 333 MHz Pentium III with 128 Mb of RAM.
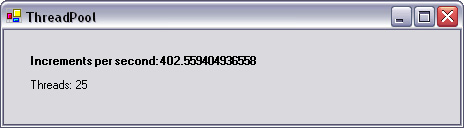
With a thread pool, the optimal number of threads on this particular computer was found to be 25, which gave an overall operating speed of 402 increments per second, with a slightly modified IncrementerThread() routine.
Thread pools are used constantly in servers, where a reliable service must be provided regardless of load. This sample application is a simply a benchmarking utility, but with experimentation it could be adapted for any purpose.
Create a new project in Visual Studio .NET and drop in two labels: lblThreads and lblIPS. The thread pool will be populated with threads as soon as the form loads. The exact time at which the form starts is stored in a public variable named startTime. Every thread then adds one to a public variable named myIncrementor, which helps gauge overall performance. Both of these are included in the code directly after the class declaration:
C#
public class Form1 : System.Windows.Forms.Form
{
public double myIncrementor;
public DateTime startTime;
...VB.NET
Public Class Form1 Inherits System.Windows.Forms.Form Public myIncrementor As Double Public startTime As DateTime ...
To populate the thread pool, a check is made to see how many threads should run together concurrently. That number of threads is then added to the thread pool. There is no problem in adding more than the recommended number of threads to the pool because the surplus threads will not execute until another thread has finished. In this case, the threads run in an infinite loop; therefore, no surplus threads would ever execute.
Double-click on the form and add the following code:
C#
private void Form1_Load(object sender, System.EventArgs e)
{
int workerThreads=0;
int IOThreads=0;
ThreadPool.GetMaxThreads(out workerThreads,out IOThreads);
lblThreads.Text = "Threads: " + workerThreads;
for (int threads=0;threads<workerThreads;threads++)
{
ThreadPool.QueueUserWorkItem(new
WaitCallback(Increment),this);
}
startTime = DateTime.Now;
}VB.NET
Private Sub Form1_Load(ByVal sender As Object, _ ByVal e As System.EventArgs) Dim workerThreads As Integer = 0 Dim IOThreads As Integer = 0 ThreadPool.GetMaxThreads(workerThreads, IOThreads) lblThreads.Text = "Threads: " & workerThreads Dim threads As Integer = 0 For threads = 1 To workerThreads ThreadPool.QueueUserWorkItem(New WaitCallback _ (AddressOf Increment), Me) Next startTime = DateTime.Now End Sub
This code first obtains the default number of threads that can run concurrently on the local machine using the GetMaxThreads method. It then displays this value on-screen before creating and running these threads.
There can only be one thread pool in an application, so only static methods are called on the thread pool. The most important method is QueueUserWorkItem. The first parameter of this method is the function (delegate) to be called, and the second parameter (which is optional) is the object that is to be passed to the new thread. The Increment function is then implemented thus:
C#
public void Increment()
{
while(true)
{
myIncrementor++;
long ticks = DateTime.Now.Ticks - startTime.Ticks;
lock (this)
{
lblIPS.Text = "Increments per second:"+
(myIncrementor/ticks) * 10000000;
}
}
}VB.NET
Public Sub Increment()
Dim ticks As Long
Do
myIncrementor = myIncrementor + 1
ticks = DateTime.Now.Ticks - startTime.Ticks
SyncLock (Me)
lblIPS.Text = "Increments per second:" & _
(myIncrementor / ticks) * 10000000
End SyncLock
Loop
End SubThe lock (or syncLock) is required for application stability. If two threads repeatedly access the same user interface element at the same time, the application’s UI becomes unresponsive.
Finally, the threading namespace is required:
C#
using System.Threading;
VB.NET
imports System.Threading
To test the application, run it from Visual Studio .NET and wait for a minute or two for the increments-per-second value to settle on a number (Figure 10.1). You can experiment with this application and see how performance increases and decreases under certain conditions, such as running several applications or running with low memory.
Deadlocks are the computing equivalent of a Catch-22 situation. Imagine an application that retrieves data from a Web site and stores it in a database. Users can use this application to query from either the database or the Web site. These three tasks would be implemented as separate threads, and for whatever reason, no two threads can access the Web site or the database at the same time.
The first thread would be:
The second thread would be:
Wait for access to the database.
Restrict other threads’ access to the database.
Read from the database.
Execute thread three, and wait for its completion.
Relinquish the restriction on the database.
The third thread would be:
Wait for access to the Web site.
Restrict other threads’ access to the Web site.
Read from the Web site.
Relinquish the restriction on the Web site.
Any thread running on its own will complete without any errors; however, if thread 2 is at the point of reading from the database, while thread 1 is waiting for access to the database, the threads will hang. Thread 3 will never complete because thread 1 will never get access to the database until thread 2 is satisfied that thread 3 is complete.
A deadlock could have been avoided by relinquishing the database restriction before executing thread 3, or in several different ways, but the problem with deadlocks is spotting them and redesigning the threading structure to avoid the bug.
Load balancing is a means of dividing workload among multiple servers by forwarding only a percentage of requests to each server. The simplest way of doing this is DNS round-robin, which is where a DNS server contains multiple entries for the same IP address. So when a client requests a DNS, it will receive one of a number of IP addresses to connect to. This approach has one major drawback in that if one of your servers crashes, 50% of your clients will receive no data. The same effect can be achieved on the client side, where the application will connect to an alternative IP address if one server fails to return data. Of course, this would be a nightmare scenario if you deploye a thousand kiosks, only to find a week later that your service provider had gone bust and you were issued new IP addresses. If you work by DNS names, you will have to wait 24 hours for the propagation to take place.
Computers can change their IP addresses by themselves, by simply returning a different response when they receive an ARP request. There is no programmatic control over the ARP table in Windows computers, but you can use specially designed load-balancing software, such as Microsoft Network Load Balancing Service (NLBS), which ships with the Windows 2000 advanced server. This allows many computers to operate from the same IP address. By way of checking the status of services such as IIS on each computer in a cluster, every other computer can elect to exclude that computer from the cluster until it fixes itself, or a technician does so. The computers do not actually use the same IP address; in truth, the IP addresses are interchanged to create the same effect.
NLBS is suitable for small clusters of four or five servers, but for high-end server farms from between 10 and 8,000 computers, the ideal solution is a hardware virtual server, such as Cisco’s Local Director. This machine sits between the router and the server farm. All requests to it are fed directly to one of the 8,000 computers sitting behind it, provided that that server is listening on port 80.
None of the above solutions—DNS round-robin, Cisco Local Director, or Microsoft NLBS—can provide the flexibility of custom load balancing. NLBS, for instance, routes requests only on the basis of a percentage of the client requests they will receive. So if you have multiple servers with different hardware configurations, it’s your responsibility to estimate each system’s performance compared to the others. Therefore, if you wanted to route a percentage of requests based on actual server CPU usage, you couldn’t achieve this with NLBS alone.
There are two ways of providing custom load balancing, either through hardware or software. A hardware solution can be achieved with a little imagination and a router. Most routers are configurable via a Web interface or serial connection. Therefore, a computer can configure its own router either through an RS232 connection (briefly described in Chapter 4) or by using HTTP. Each computer can periodically connect to the router and set up port forwarding so that incoming requests come to it rather than the other machine. The hardware characteristics of the router may determine how quickly port forwarding can be switched between computers and how requests are handled during settings changes. This method may require some experimentation, but it could be a cheap solution to load balancing, or at least to graceful failover.
Custom software load balancers are applicable in systems where the time to process each client request is substantially greater than the time to move the data across the network. For these systems, it is worth considering using a second server to share the processing load. You could program the clients to connect to switch intermittently between servers, but this may not always be possible if the client software is already deployed. A software load balancer would inevitably incur an overhead, which in some cases could be more than the time saved by relieving server load. Therefore, this solution may not be ideal in all situations.
This implementation of a software load balancer behaves a little like a proxy server. It accepts requests from the Internet and relays them to a server of its choosing. The relayed requests must have their HOST header changed to reflect the new target. Otherwise, the server may reject the request. The load balancer can relay requests based on any criteria, such as server CPU load, memory usage, or any other factor. It could also be used to control failover, where if one server fails, the load balancer could automatically redirect traffic to the remaining operational servers. In this case, a simple round-robin approach is used.
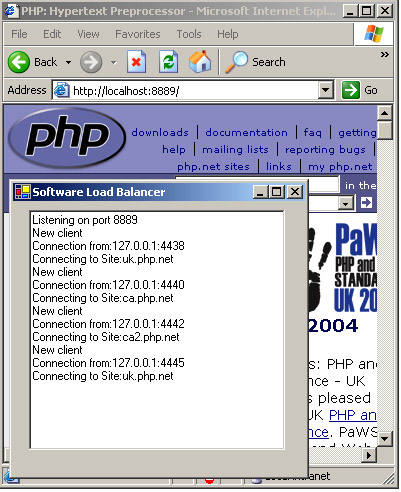
The example program balances load among three mirrored HTTP servers: uk.php.net, ca.php.net, and ca2.php.net. Requests from users are directed initially to the load-balancing server and are then channeled to one of these servers, with the response returned to the user. Note that this approach does not take advantage of any geographic proximity the user may have to the Web servers because all traffic is channeled through the load balancer.
To create this application, start a new project in Microsoft Visual Studio .NET. Draw a textbox on the form, named tbStatus. It should be set with multiline to true.
Add two public variables at the top of the Form class as shown. The port variable is used to hold the TCP port on which the load balancer will listen. The site variable is used to hold a number indicating the next available Web server.
C#
public class Form1 : System.Windows.Forms.Form
{
public int port;
public int site;Public Class Form1
Inherits System.Windows.Forms.Form
Public port As Integer
Public Shadows site As IntegerWhen the application starts, it will immediately run a thread that will wait indefinitely for external TCP connections. This code is placed into the form’s Load event:
C#
private void Form1_Load(object sender, System.EventArgs e)
{
Thread thread = new Thread(new
ThreadStart(ListenerThread));
thread.Start();
}VB.NET
Private Sub Form1_Load(ByVal sender As System.Object, _
ByVal e As System.EventArgs) Handles MyBase.Load
Dim thread As Thread = New Thread(New ThreadStart( _
AddressOf ListenerThread))
thread.Start()
End SubThe ListenerThread works by listening on port 8889 and waiting on connections. When it receives a connection, it instantiates a new instance of the WebProxy class and starts its run method in a new thread. It sets the class’s clientSocket and UserInterface properties so that the WebProxy instance can reference the form and the socket containing the client request.
C#
public void ListenerThread()
{
port = 8889;
TcpListener tcplistener = new TcpListener(port);
reportMessage("Listening on port " + port);
tcplistener.Start();
while(true)
{
WebProxy webproxy = new WebProxy();
webproxy.UserInterface = this;
webproxy.clientSocket = tcplistener.AcceptSocket();
reportMessage("New client");
Thread thread = new
Thread(new ThreadStart(webproxy.run));
thread.Start();
}
}Public Sub ListenerThread()
port = 8889
Dim tcplistener As TcpListener = New TcpListener(port)
reportMessage("Listening on port " + port.ToString())
tcplistener.Start()
Do
Dim webproxy As WebProxy = New WebProxy
webproxy.UserInterface = Me
webproxy.clientSocket = tcplistener.AcceptSocket()
reportMessage("New client")
Dim thread As Thread = New Thread(New ThreadStart( _
AddressOf webproxy.run))
thread.Start()
Loop
End SubA utility function that is used throughout the application is reportMessage. Its function is to display messages in the textbox and scroll the textbox automatically, so that the user can see the newest messages as they arrive.
C#
public void reportMessage(string msg)
{
lock(this)
{
tbStatus.Text += msg + "
";
tbStatus.SelectionStart = tbStatus.Text.Length;
tbStatus.ScrollToCaret();
}
}Public Sub reportMessage(ByVal msg As String)
SyncLock Me
tbStatus.Text += msg + vbCrLf
tbStatus.SelectionStart = tbStatus.Text.Length
tbStatus.ScrollToCaret()
End SyncLock
End SubThe core algorithm of the load balancer is held in the getMirror function. This method simply returns a URL based on the site variable. More complex load-balancing techniques could be implemented within this function if required.
C#
public string getMirror()
{
string Mirror = "";
switch(site)
{
case 0:
Mirror="uk.php.net";
site++;
break;
case 1:
Mirror="ca.php.net";
site++;
break;
case 2:
Mirror="ca2.php.net";
site=0;
break;
}
return Mirror;
}Public Function getMirror() As String
Dim Mirror As String = ""
Select Case site
Case 0
Mirror = "uk.php.net"
site = site + 1
Case 1
Mirror = "ca.php.net"
site = site + 1
Case 2
Mirror = "ca2.php.net"
site = 0
End Select
Return Mirror
End FunctionThe next step is to develop the WebProxy class. This class contains two public variables and two functions. Create the class thus:
C#
public class WebProxy
{
public Socket clientSocket;
public Form1 UserInterface;
}VB.NET
Public Class WebProxy
Public clientSocket As Socket
Public UserInterface As Form1
End ClassThe entry point to the class is the run method. This method reads 1,024 (or fewer) bytes from the HTTP request. It is assumed that the HTTP request is less than 1 Kb in size, in ASCII format, and that it can be received in one Receive operation. The next step is to remove the HOST HTTP header and replace it with a HOST header pointing to the server returned by getMirror. Having done this, it passes control to relayTCP to complete the task of transferring data from user to Web server.
public void run()
{
string sURL = UserInterface.getMirror();
byte[] readIn = new byte[1024];
int bytes = clientSocket.Receive(readIn);
string clientmessage = Encoding.ASCII.GetString(readIn);
clientmessage = clientmessage.Substring(0,bytes);
int posHost = clientmessage.IndexOf("Host:");
int posEndOfLine = clientmessage.IndexOf("
",posHost);
clientmessage =
clientmessage.Remove(posHost,posEndOfLine-posHost);
clientmessage =
clientmessage.Insert(posHost,"Host: "+ sURL);
readIn = Encoding.ASCII.GetBytes(clientmessage);
if(bytes == 0) return;
UserInterface.reportMessage("Connection from:" +
clientSocket.RemoteEndPoint + "
");
UserInterface.reportMessage
("Connecting to Site:" + sURL + "
");
relayTCP(sURL,80,clientmessage);
clientSocket.Close();
}VB.NET
Public Sub run()
Dim sURL As String = UserInterface.getMirror()
Dim readIn() As Byte = New Byte(1024) {}
Dim bytes As Integer = clientSocket.Receive(readIn)
Dim clientmessage As String = _
Encoding.ASCII.GetString(readIn)
clientmessage = clientmessage.Substring(0, bytes)
Dim posHost As Integer = clientmessage.IndexOf("Host:")
Dim posEndOfLine As Integer = clientmessage.IndexOf _
(vbCrLf, posHost)
clientmessage = clientmessage.Remove(posHost, _
posEndOfLine - posHost)
clientmessage = clientmessage.Insert(posHost, _
"Host: " + sURL)
readIn = Encoding.ASCII.GetBytes(clientmessage)
If bytes = 0 Then Return
UserInterface.reportMessage("Connection from:" + _
clientSocket.RemoteEndPoint.ToString())
UserInterface.reportMessage("Connecting to Site:" + sURL)
relayTCP(sURL, 80, clientmessage)
clientSocket.Close()
End SubThe data transfer takes place on relayTCP. It opens a TCP connection to the Web server on port 80 and then sends it the modified HTTP header sent from the user. Immediately after the data is sent, it goes into a loop, reading 256-byte chunks of data from the Web server and sending it back to the client. If at any point it encounters an error, or the data flow comes to an end, the loop is broken and the function returns.
C#
public void relayTCP(string host,int port,string cmd)
{
byte[] szData;
byte[] RecvBytes = new byte[Byte.MaxValue];
Int32 bytes;
TcpClient TcpClientSocket = new TcpClient(host,port);
NetworkStream NetStrm = TcpClientSocket.GetStream();
szData =
System.Text.Encoding.ASCII.GetBytes(cmd.ToCharArray());
NetStrm.Write(szData,0,szData.Length);
while(true)
{
try
{
bytes = NetStrm.Read(RecvBytes, 0,RecvBytes.Length);
clientSocket.Send(RecvBytes,bytes,SocketFlags.None);
if (bytes<=0) break;
}
catch
{
UserInterface.reportMessage("Failed connect");
break;
}
}
}Public Sub relayTCP(ByVal host As String, ByVal port _
As Integer, ByVal cmd As String)
Dim szData() As Byte
Dim RecvBytes() As Byte = New Byte(Byte.MaxValue) {}
Dim bytes As Int32
Dim TcpClientSocket As TcpClient = New TcpClient(host, port)
Dim NetStrm As NetworkStream = TcpClientSocket.GetStream()
szData = _
System.Text.Encoding.ASCII.GetBytes(cmd.ToCharArray())
NetStrm.Write(szData, 0, szData.Length)
While True
Try
bytes = NetStrm.Read(RecvBytes, 0, RecvBytes.Length)
clientSocket.Send(RecvBytes, bytes, SocketFlags.None)
If bytes <= 0 Then Exit While
Catch
UserInterface.reportMessage("Failed connect")
Exit While
End Try
End While
End SubAs usual, some standard namespaces are added to the head of the code:
C#
using System.Net; using System.Net.Sockets; using System.Text; using System.IO; using System.Threading;
VB.NET
Imports System.Net Imports System.Net.Sockets Imports System.Text Imports System.IO Imports System.Threading
To test the application, run it from Visual Studio .NET, and then open a browser on http://localhost:8889; you will see that the Web site is loaded from all three servers. In this case, data transfer consumes most of the site’s loading time, so there would be little performance gain, but it should serve as an example (Figure 10.2).
Scalability problems generally only start appearing once a product has rolled out into full-scale production. At this stage in the life cycle, making modifications to the software becomes a logistical nightmare. Any changes to the software will necessarily have to be backwards compatible with older versions of the product.
Many software packages now include an autoupdater, which accommodates postdeployment updates; however, the best solution is to address scalability issues at the design phase, rather than ending up with a dozen versions of your product and the server downtime caused by implementing updates.
The next chapter deals with network performance, including techniques such as compression and multicast.