
CHAPTER
11
A world wider than the Web
End user programming across multiple domains
Will Haines,1 Melinda Gervasio,1 Jim Blythe,2 Kristina Lerman,2 Aaron Spaulding1
1SRI International
2USC Information Sciences Institute
ABSTRACT
As Web services become more diverse and powerful, end user programming (EUP) systems for the Web become increasingly compelling. However, many user workflows do not exist exclusively online. To support these workflows completely, EUP systems must allow the user to program across multiple applications in different domains. To this end, we created Integrated Task Learning (ITL), a system that integrates several learning components to learn end user workflows as user-editable executable procedures. In this chapter, we illustrate a motivating cross-domain task and describe the various learning techniques that support learning such a task with ITL. These techniques include dataflow reasoning to learn procedures from demonstration, symbolic analysis and compositional search to support procedure editing, and machine learning to infer new semantic types. Then, we describe the central engineering concept that ITL uses to facilitate cross-domain learning: pluggable domain models, which are independently generated type and action models over different application domains that can be combined to support cross-domain procedure learning. Finally, we briefly discuss some open questions that cross-domain EUP systems will need to address in the future.
A WORLD WIDER THAN THE WEB
Today’s rapid proliferation of Web services has prompted an increasingly varied use of the Web to support users’ everyday tasks (Cockburn & McKenzie, 2001). In the office, Web services now support many business processes: travel authorization and reimbursement, calendaring, and room reservation are just some of the processes that often rely on dedicated Web-based applications. At home, we visit a variety of Web sites to purchase books, make travel arrangements, and manage our finances. However, many user workflows, particularly in business environments, still involve non-Web applications (Dragunov et al., 2005). Even as some applications begin to transition to the Web – for example, email and calendar tools – the workflows will continue to involve multiple, disparate domains. Thus, any EUP tool, particularly those designed for the business environment, must accommodate procedures learned over a variety of applications, in Web domains and beyond.1
Consider Alice, who is responsible for maintaining a Web site listing all the publications by the members of a university laboratory.2 Anyone in the lab who produces a report notifies Alice by email. The email message contains the citation for the report as well as an attached electronic version of the work. The attachment may be in a single-file format, like Word or PDF, or in a multifile format such as LaTeX. Alice saves the files, and if the paper is not already a PDF, she must convert it before renaming the file to conform to a standard naming scheme. She then uploads the PDF file using the site administrator’s Web interface. This includes filling out a form with the citation information for the paper, uploading the paper, and verifying that the uploaded paper is downloadable. Finally, Alice replies to the email message, copying a direct URL link to the paper into the message for the author’s benefit.
This is a task Alice repeats several dozen times a year, and she would clearly benefit by automating it. Unfortunately, since it touches several different applications, including an email client, the file system, word-processing software, PDF converters, and a Web browser, any EUP tool designed for a single application would be able to automate only part of Alice’s workflow. For example, Alice could use a Web EUP system to automate the segment involving uploading the paper and citation information to the Web site. However, she must still manually process the email, perform the file operations, fill in the Web form, and reply to the email. Additional single-application EUP systems could potentially automate more segments, but they would require Alice not only to learn several different interfaces but also to manually link the data from one system to another. In contrast, an EUP tool that works across different applications could potentially automate the entire workflow, benefiting Alice much more significantly.
While cross-domain EUP would clearly be valuable here, it also presents many design and implementation challenges. There are many reasons why most EUP systems tackle a single application domain: it is much easier to engineer instrumentation and automation for a single platform, the relations between different domain actions are straightforward, and the procedures that can be learned are bounded by the single domain. Nevertheless, we argue that the benefits provided by cross-domain EUP make it well worth attempting to meet the unique challenges that such a system presents.
In this chapter, we present Integrated Task Learning (ITL), our approach for learning procedures across domains using EUP (Spaulding et al., 2009). ITL provides a suite of complementary learning and reasoning capabilities for acquiring procedures, some of which are shown in Figure 11.1. This includes inducing generalized procedures from observed demonstrations in instrumented applications, providing template-based procedure visualizations that are easily understandable to end users, and supporting procedure editing. To incorporate other domains, including Web domains, ITL also includes facilities for semantically mapping actions across domains. We begin by describing each of these capabilities in turn. Then we discuss the implications of such an approach on domain modeling, instrumentation, and automation. Finally, we present avenues for future work and conclusions.
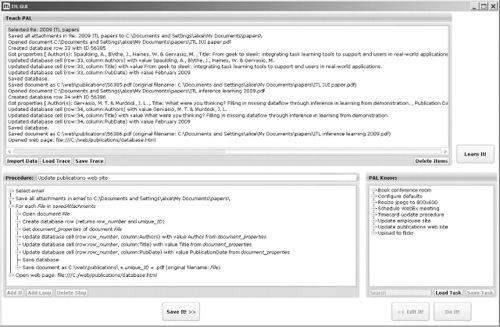
FIGURE 11.1
The ITL user interface. This interface provides a user with the ability to demonstrate (top), edit (bottom left), and execute (bottom right) procedures. Here, the demonstration trace and editor reflect a simplified version of Alice’s publications upload procedure. The “PAL Knows” pane also displays some other tasks for which ITL already learned procedures.
LEARNING PROCEDURES FROM DEMONSTRATION
To automate her publications upload task with ITL, Alice uses programming by demonstration (PBD) (Cypher & Halbert, 1993; Lieberman, 2001). Alice shows the system how she performs the task, and ITL generalizes the observed actions into an automated procedure that Alice can use to perform the task in the future. Figure 11.1 shows Alice’s demonstration in the “Teach PAL” panel and the procedure learned from it in the “Procedure: Update publications web site” panel. Alice’s demonstration is generalized in two ways: parameter generalization, whereby the action arguments are variablized (e.g., row_number replaces 33), and structure generalization, whereby control flow constructs are induced (e.g., we introduce the loop: For each File…). This generalization lets Alice apply the same procedure to any email message with an arbitrary number of attachments. In ITL, this PBD capability is provided by the LAPDOG component (Gervasio, Lee, & Eker, 2008; Gervasio & Murdock, 2009). We now elaborate on the learning process by which LAPDOG generalizes an observed demonstration into a procedure.
Parameter generalization
LAPDOG was designed specifically to learn dataflow procedures. In the dataflow paradigm, actions are characterized in terms of their inputs and outputs, and within a procedure, the outputs of actions generally serve as inputs to succeeding actions. Thus, to be executable, the inputs of every action in a dataflow procedure must be supported by previous outputs.
In the simplest case, an input is directly supported by a previous action’s output or an input to the entire procedure. For example, in Alice’s scenario, the email message upon which the saveAttachments action operates is the email message that the user passes into the procedure upon invocation. A more complex case involves inputs that are supported by elements or combinations of previous outputs. For example, in Alice’s procedure, the values used for the Authors, Title, and PubDate fields of the database record need to be extracted from the DocumentProperties tuple that is the output of the getProperties action. Figure 11.2 graphically depicts a variety of support relationships induced by LAPDOG over Alice’s demonstration.
In the direct support case (e.g., the row 378 output by newDBEntry serving as an input to updateCell) LAPDOG captures the support relationship by replacing the matching action arguments with the same variable, in this case $row. In the indirect support case, LAPDOG captures the support relationship by using expressions. For example, the support provided by the Title field of the properties tuple output by getProperties to the title input to updateCell is captured by using the variable $propsTuple for the output of getProperties and using the tuple access operation (get "Title" $propsTuple) as the input to updateCell.
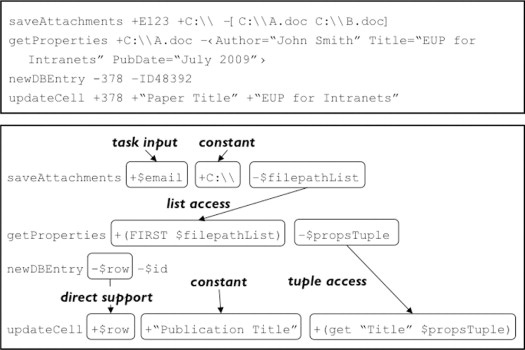
FIGURE 11.2
Examples of dataflow supports found by LAPDOG.
In general, there may be multiple possible supports for any input. LAPDOG generates them all, efficiently maintaining the alternative hypotheses in a structure that parallels the original demonstration except that every action argument is represented by its set of alternative supports. With multiple examples (i.e., demonstrations of the same procedure), LAPDOG can eliminate incorrect hypotheses. However, ITL is often used to acquire long, complex procedures for which users are unlikely to provide multiple demonstrations. To address this situation, LAPDOG employs a number of heuristics to select the best generalization given only one demonstration. This includes preferring support from action outputs to support from procedure inputs, preferring more recent supports, and preferring direct support to support through expressions. These heuristics not only make sense intuitively, but they have also proven to be appropriate in practice.
Structural generalization
The learned procedure in Figure 11.1 includes a loop over the attachments of the email message. Within the dataflow paradigm, such loops over the elements of a collection (i.e., a set or a list) are common. When the loop is over a collection that is explicitly observed in the demonstration (i.e., the collection is the output of some action), LAPDOG can use the known collection to detect loops. For example, when Alice opens the first email attachment, LAPDOG detects the start of a potential loop, by virtue of the attachment being part of a collection. When Alice opens the second email attachment, LAPDOG collects all the actions until that second attachment is opened; the collected actions form the hypothesized body of the loop. Since Alice repeats this sequence of actions for the second attachment, LAPDOG induces a loop to be performed over all the attachments of the input email message. Figure 11.3 shows the complete SPARK-L (Morley & Myers, 2004) procedure learned from the demonstration in Figure 11.1, including the induced loop.
As with parameter generalization, there may be multiple possible structural generalizations of a demonstration trace. LAPDOG creates a separate generalized program for each hypothesis and applies the heuristic of preferring the shortest program (i.e., induce loops whenever possible) to select the final generalization. In practice, this heuristic has worked well because a demonstration including actions repeated over all the objects in a collection is typically meant to process the entire collection rather than just the specific number of elements observed. LAPDOG is currently limited to inducing loops over collections of objects; it does not yet learn conditional or counting loops. However, LAPDOG is able to leverage this specific looping context to learn loops over a rich variety of collections, including loops over either ordered or unordered collections (lists or sets), loops over one or more lists in parallel, and loops that themselves accumulate the outputs of the individual iterations into lists (Eker, Lee, & Gervasio, 2009).
Learning cross-domain dataflow procedures
The dataflow paradigm adopted by ITL is a natural fit to many information-oriented domains, with most Web services and desktop applications being easily characterized in terms of their actions’ inputs and outputs. This facilitates the use of ITL to learn procedures across these domains, since users can just demonstrate their procedures as they would naturally execute them and ITL can rely on the dataflow between actions and across domains to guide reasoning and learning. Since the learned procedures themselves may be characterized in terms of their inputs and outputs, demonstration and learning over learned procedures becomes a straightforward extension.
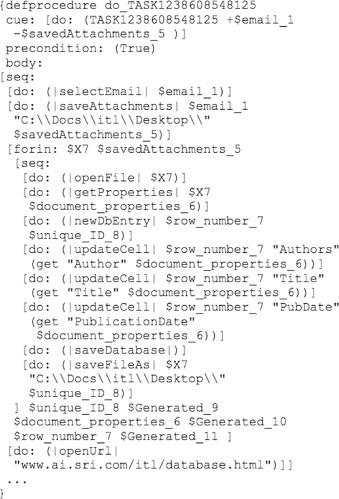
FIGURE 11.3
The SPARK-L source for Alice’s entire procedure, as learned from the demonstration in Figure 11.1.
Even engineered procedures or procedures acquired through other means potentially become available to ITL, provided they can be characterized in terms of the dataflow they support. However, this cross-domain integration through dataflow can be achieved only if there exists an appropriate mapping between the input and output types of the actions in each domain. In later sections, we discuss how we address this concern with a machine learning approach to semantic mapping as well as with the ITL framework’s extensible type system.
VISUALIZING AND EDITING PROCEDURES
Once a demonstration is successfully generalized, an end user like Alice can simply execute the newly learned procedure to perform her task. However, the life cycle of a procedure rarely ends at demonstration. As conditions change, procedures may need to change as well. Thus, a complete framework for end user programming should support the viewing and editing of procedures in addition to learning from demonstration. To this end, ITL provides an editor that visualizes procedures and allows users to make a number of postdemonstration modifications.
Before Alice starts modifying her procedure, let us first consider how the hard-to-read procedural code in Figure 11.3 becomes the human-readable display that she sees in Figure 11.1. Then, we will discuss how she makes edits that will improve the procedure’s generality.
Visualization using templates
Programming by demonstration aims to build general procedures out of concrete examples, and as such, it inevitably involves abstraction. For nonprogrammers, dealing with abstract procedures is difficult because end users tend to think of programs as the set of concrete actions that they experience at runtime, rather than as more general abstract control structures (Pane, Ratanamahatana, & Myers, 2001). Rode and Rosson demonstrated this difficulty in the Web domain (Rode & Rosson, 2003), and based on our deployment of ITL, we also conclude that in complex, cross-domain environments the user’s need to understand abstract procedures is both vital and difficult to support.
To leverage the end user’s tendency to conceive of procedures in terms of runtime actions, we can combine appropriately abstracted actions with human-readable annotations to make procedure visualizations more concrete. First, in ITL, we aim to define the domain model in terms of atomic user interactions. This level of abstraction affords a straightforward mapping from a domain action to a human-readable displayed step that reflects an atomic graphical user interface (GUI) interaction with the end user. ITL implements this mapping using a template approach that annotates domain actions to specify a human-readable display format as well as to create pointers to “live” application properties that must be queried at runtime to fill in missing display data. Figure 11.4 illustrates how this approach displays the selectEmail action when Alice replies to a publication request.
The action template indicates that when the selectEmail action is being rendered for the demonstration trace, it should display as “Selected” concatenated to the display value of the email parameter. Next, we include a template for the Email data type, which queries the application to find an application-specific representation – in this case, the email’s subject. If the Email happened to be a variable, we would instead display just the variable’s human-readable name.
Also important to note is the fact that this template does not present all parts of an action to the user – in particular, the output argument of the selectEmail action is never shown. Our research indicates that some parameters simply complicate a user’s understanding of the overall procedure flow (Spaulding et al., 2009). For example, although the procedure executor might need to know a window’s onscreen pixel position to execute a procedure, such information is irrelevant to most end users. As such, adding the ability to suppress parameters and even entire actions to a “details” view is another simple way to improve user comprehension of complex procedures.
For any given domain, determining exactly which actions and parameters to display and how exactly to display them is best discovered through iterative testing with end users. In our experience, every attempt to determine this information a priori has been unsuccessful, so any approach must be flexible and respond well to iterative refinement. To date, the ITL framework’s action metadata approach has provided us with the necessary flexibility to craft readable procedures.

FIGURE 11.4
Action template application – before and after.
Typed dataflow and editing
Given an understandable representation of their procedures, users want to make changes that span a range of complexity – from simple edits, like changing constant parameters in steps, to complex modifications, like adding conditionals and iterative loops. Simple edits may be required when the task to be performed by an existing procedure changes slightly or to correct an initial hypothesis from another learning component. Further, support for multiple domains increases the chance that users will also need to add new steps to procedures, modify step ordering, or change the structure of the procedure. This occurs because some domains are less reliant on a graphical interface where demonstration-based techniques are natural. In these nongraphical domains, users may want to supplement demonstration by instead choosing available actions from a menu, or describing them and composing within an editor.
In the dataflow-oriented model, full user support for editing poses many of the same challenges faced by demonstration-based learning. For example, users may insert an action but omit auxiliary steps or queries that provide inputs for that action. In a dataflow model, those missing steps must themselves make use of inputs that are established earlier in the procedure. The use of typing in the domain specification allows one to frame the problem of inferring missing steps as compositional search over a graph of data types in which queries or steps are composed to form a path from existing inputs to those that are needed.
An editing tool for a typed dataflow model should provide several complementary kinds of support. First, it should allow users to perform edits, not only to add or delete steps, but also to add conditions or loops by suggesting candidates based on queries and lists that are available. Another desirable characteristic is to allow users to copy steps between procedures, facilitating best practices, while using the dataflow model to ensure that the resulting procedure is executable. Finally, it should warn the user if the newly edited procedure is missing critical inputs or otherwise has potential flaws, and it should use dataflow information to suggest potential fixes.
In ITL, the Tailor component supports the procedure editing capabilities (Blythe, 2005; Spaulding et al., 2009) of the user interface. Tailor allows users to add or delete steps, add conditions and iterative loops, and copy steps between procedures. It searches over possible queries and actions arranged in the same space to find plausible missing steps, composing steps and queries if needed.
Tailor uses compositional search over a graph of data types to infer missing steps or queries when users add steps. For example, rather than demonstrate a new step, Alice can ask the editor to add a step that she describes as “copy project leader.” Using the templates described above, Tailor can match this description to the addCC action, which requires a recipient. By searching from known inputs, Tailor can identify “leader of project that funds the work” as the most plausible match. Building procedures by demonstration and description can both be ambiguous individually, but they complement each other well because they do not cause the same ambiguities.
Support for copying steps between procedures
Description is a powerful technique for editing; however, our research indicates that users find the process of describing a brand new step difficult and do not perform it often, preferring instead to copy or move steps from a library of available actions (Spaulding et al., 2009). Suppose Alice demonstrated her procedure on PDF documents and now wishes to handle Word documents as well, by first converting them to PDF. Instead of demonstrating a new procedure, Alice can utilize another previously learned procedure that converts a Word file into PDF by copying over the relevant steps. Tailor supports this by changing the arguments of the copied command to refer to each email attachment, after searching for plausible matches.
By copying all or part of a procedure, as illustrated in Figure 11.5, users can reuse long demonstrations or complex constructs, such as conditions and loops. The procedures learned in ITL use no global variables, so the variables in the steps that are copied must be replaced by terms in the target procedure, either by (1) changing them to an existing variable, (2) changing them to a constant, or (3) adding auxiliary steps to establish a new variable. The same search technique used to recognize new steps supports a wide range of other activities, including copying steps, generating potential fixes for flaws, and adding conditions or loops. Tailor finds potential replacements of all three kinds using its compositional search method (Blythe & Russ, 2008). The search naturally prefers to use an existing variable or constant for each copied variable, because it leads to a shorter solution. In ITL, we extended this capability to enable copying sequences of steps, by composing the variable mappings of the component steps. We also added domain-specific heuristics that replace variables with constants when the intended value is known.
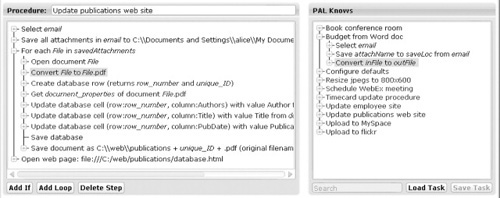
FIGURE 11.5
Alice copies the step to convert a file to PDF by dragging it from another procedure for which it was demonstrated (right side) to the active procedure (left side). The editor suggests the objects in the new procedure to which the step applies.
Support for adding conditions and loops
Alice’s newly modified procedure is syntactically correct, but it will attempt to convert every attachment into PDF, whether or not it is a Word document. To have the convertFileType step be applied only to Word documents, Alice needs to make this step conditional on the file’s extension. As with creating steps, we have found that users prefer to select an appropriate condition from a list of alternatives rather than to supply a description of the condition. The ITL editing interface allows the user to select a set of steps to put into a loop or condition, without providing any initial information about the loop or condition itself. This simplifies the interface and reduces the cognitive burden on the user, who may find it difficult to describe a conditional or loop without assistance.
Tailor again uses compositional search and heuristics to generate a set of reasonable candidate specifications. Once it generates a set of candidates for a new action, condition, loop, or change to a parameter value, the interface can present them as options. Here it is critical that the user can understand both the current procedure and the available alternatives in order to make a reasoned choice. The alternatives are displayed within the procedure visualization described above and use templates to provide a uniform view. By presenting the user with appropriate bounds, the editor makes it easier to create complex control structures and limits the user’s capacity to make errors.
In our example, Alice selects the step that converts Word to PDF and clicks “Add If” to add a condition around it. As shown in Figure 11.6, Tailor searches for plausible conditions, preferring those that use objects referenced in or just before the step to be made conditional. Depending on the known properties and actions, it may suggest conditions involving the document’s type, author, age, or size as well as conditions on the conference or journal. Alice chooses "file extension = .doc" to make the action conditional. Tailor also adds the step to retrieve the file’s extension.
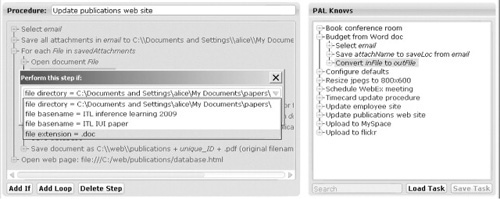
FIGURE 11.6
Alice chooses from a set of conditions to place on convertFileType, to make it be applied only to Word documents.
Support for editing errors or flaws
Users often make errors when editing procedures, despite help from structured editors. After the user makes a modification, Tailor checks the procedure for simple errors, such as a step that has been deleted even though it produced a value that was needed later in the procedure (Blythe, 2005). To make this check, Tailor performs a symbolic analysis of the procedure, aiming to find important errors before the procedure is executed. This means that it does not know, for example, which of several conditional branches may be taken during execution or how and when a loop will terminate. ITL’s execution engine is also capable of interleaving many concurrent actions, and this means that one cannot prove that global variables will be unavailable when a step is to be run (Morley & Myers, 2004). Because of this, Tailor provides a warning for an unbound global variable only at the time that a modification removes or reorders a step or query that provides a value.
For each warning, Tailor uses templates to provide a set of potential fixes that may include reordering steps, removing them, or undoing the user’s last edit. In some cases, modifications requiring several coordinated edits can be made by picking one edit and choosing the appropriate recovery steps. Further, Tailor can use compositional search to suggest steps that may be added to provide missing inputs.
For example, if the convertFileType action that Alice made conditional creates a PDF file as output and that output is used outside the scope of the conditional, she will see a warning that the PDF file does not exist unless the input document has the extension “.doc”. Tailor can help Alice fix this potential error by making the later actions also be conditional on the PDF file’s existence. We are currently investigating how best to help users add steps along alternative branches of a condition, for example, to warn the user if the procedure is unable to produce a PDF file.
MAPPING ACTIONS ACROSS DOMAINS
Online data sources, such as Web services, could be incorporated into ITL by direct instrumentation. However, in many cases, it may be easier and more cost-effective to instead generate special purpose information extractors over these data sources.3 For our example, suppose Alice also wishes to automate her task of compiling all the papers published by the members of a particular project. In ITL, Alice can teach ITL one procedure for extracting the names of the members of the project from the project Web page, another for extracting all the papers from the publications Web page, and then create a conditional to output only the publications authored by project members. Key to this is the ability to extract structured information from Web pages – that is, names and publication information – and to be able to map the names extracted from the project page to the authors extracted from the publications page in order to complete the dataflow. In ITL, this ability to translate online data sources into actions with semantically typed inputs and outputs is provided by the PrimTL component, which automatically creates semantic definitions for data contained in online data sources, which can then be interpreted and executed by ITL.
Semantic mapping with PrimTL
The Semantic Mapper in PrimTL uses machine learning techniques to leverage existing knowledge in order to semantically type data from new sources. The learner relies on background knowledge captured in the domain model, in particular the set of known semantic types, such as PersonName and Year, that can be used to describe the inputs and outputs of actions. We assume that the learner can populate the domain model with examples of each type by querying known data sources.
The data returned by online sources usually has some structure or format. PrimTL learns this structure and uses it to recognize new instances of the same semantic type. What makes this problem difficult is the wide variety of formats that represent the same semantic type and inconsistent use of a format within a given source. Similar to other data validating approaches, such as Topes (Scaffidi, Myers, & Shaw, 2008), PrimTL uses a domain-independent data representation language to model the structure of data as a sequence of tokens or token types (Lerman, Minton, & Knoblock, 2003). Tokens are strings generated from an alphabet containing different syntactic types (e.g., alphabetic, numeric), which the tokens inherit. The symbolic representation of data as a sequence of tokens and syntactic token types is concise and flexible, and we can easily extend it by adding new semantic or syntactic types as needed.
PrimTL can efficiently learn data structure from examples of the data type. Consider the list in Figure 11.7, which gives examples of semantic types PersonName and PhoneNumber. PrimTL will learn that the set of examples for PersonName is described well by patterns “CAPS CAPS” (two capitalized words) and “CAPS 1UPPER. CAPS” (capitalized word, followed by an initial, period, and another capitalized word). Similarly, PrimTL will learn a description of the semantic type PhoneNumber that consists of patterns “(650) 859 – NUMBER”, “(310) 448 – NUMBER”, as well as the more general “( NUMBER ) NUMBER - NUMBER”.
The learned patterns can be used to recognize new instances of the same type by evaluating how well the patterns describe them (Blythe, Kapoor, Knoblock, Lerman, & Minton, 2008). PrimTL allows the user to specify the data she wants to extract from a Web source, and then it uses its learned patterns to map the extracted data to known semantic data types. In Alice’s publications upload task, the member names extracted from the project Web page and the authors extracted from the publications page are mapped into compatible semantic types, allowing the former to be compared against the latter when filtering the publications.
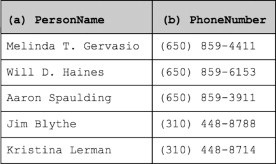
FIGURE 11.7
Some examples for learning the semantic types PersonName and PhoneNumber.
By semantically typing the inputs and outputs of Web sources, PrimTL creates well-defined actions for ITL, allowing a wider variety of online data sources to be used in procedures acquired by demonstration or editing. While mashup tools such as Yahoo! Pipes allow users to combine sources, our approach is more general: using PrimTL, users can demonstrate and edit procedures that incorporate live data and use it in conditions and loops.
CREATING PLUGGABLE DOMAIN MODELS
The previous sections describe a number of complementary techniques that ITL uses to learn procedures across multiple domains. To accomplish this learning, ITL must encode the domain knowledge that supports reasoning across different applications. By engineering this knowledge appropriately, one can make it much easier for a suite of learning components to interact and support the full life cycle of procedure creation, editing, and execution.
Our earliest domain modeling approach, realized in the CALO cognitive desktop assistant, was to commit to a master shared ontology of all the objects and relations in the desktop world and also all the actions or tasks involving them (Chaudhri et al., 2006). Such an approach is very powerful, supporting deep reasoning over tasks spanning different applications (Gervasio & Murdock, 2009). However, this power comes at a very high engineering and maintenance cost. Knowledge engineers must develop an all-encompassing ontology, and as such any changes to the ontology must be carefully vetted to avoid unintended consequences and significant re-engineering. In a large, distributed EUP system comprising applications that are only loosely, if at all, connected, these concerns present an unacceptable cost. For ITL, we instead decided to use an extensible architecture that models each domain as a separate, pluggable module. Here, we discuss the issues that arise when specifying such domain models, and we suggest some guidelines for their development.
Action-oriented domain model
EUP is concerned primarily with automating user workflows, so the domain actions must be a primary focus of modeling. Recall that ITL uses a dataflow model of actions, wherein each action is a named operation with a set of typed input and output parameters such that, in a procedure, outputs of actions serve as inputs to succeeding actions. Notationally, we represent an action as name [parameters] where parameters are of the form +/−paramName:paramType, with “+” indicating an input and “−” indicating an output.
Let us consider some of the actions necessary to learn Alice’s task with ITL. To model her workflow, we need to select an email and save its attachments in an email client. We need to open files, look at their properties, and possibly convert types in a document viewer like Word or Acrobat. In a database application, we need to add rows and update cells. Finally, we need to open a Web page in the browser to verify that everything worked correctly. Figure 11.8 shows these dataflow actions in pseudo code.
In ITL, we allow each application to specify its set of actions in its own module. Thus, for the Alice scenario, we end up working with an action model composed of four modules, one for each application domain. Application developers can create and modify each module individually without breaking the others. Note, however, that several of the modules have data types in common; we discuss this issue in more detail in the section entitled Extensible Type System.
Modeling human-level actions
Key to successful procedure representation and learning is to capture actions at the right level of granularity, as this has a big impact on learning. Based on our experience, we believe that actions should be modeled at the level at which humans would typically describe their own actions and should expose the objects that humans would find relevant to the actions as arguments (Spaulding et al., 2009). For example, in an email application, it is preferable to model the actions selectEmail and saveEmailAttachment rather than low-level actions like moveMouse and rightClick, or high-level actions like replyToFaculty.
Capturing actions at a low level generally results in more compact action models, which simplify instrumentation. However, low-level actions result in incomprehensible learned procedures, for example, a procedure composed entirely of mouse drags and clicks (Spaulding et al., 2009). Such procedures are difficult to learn and nearly impossible for end users to read or edit. On the other hand, capturing actions at too high a level often imposes an impractical reasoning burden on the instrumentation to divine the user’s intent from what can actually be observed. Further, it is difficult for users to manipulate such high-level actions when editing because they cannot break them down into smaller units should they want to realign them.

FIGURE 11.8
Examples of dataflow actions.
When one models actions that match how users think of themselves interacting with applications, one is more likely to strike the right balance between the cost of instrumentation and user comprehension of procedures. Such comprehension is an essential prerequisite to creating systems that allow users to later modify and debug their procedures (Spaulding et al., 2009).
Beyond actions: Modeling objects and relations
While an action-oriented domain model presents a number of advantages for a cross-domain EUP system, actions often do not capture the full scope of information in the world. As such, supplemental modeling of the objects in a domain and the relations between them can often simplify action modeling while also improving our ability to learn and reason over procedures. For example, suppose that Alice sends the email confirming an uploaded publication not only to the paper’s authors but also to their supervisors. Without knowledge of the relation “X supervises Y,” a learner cannot capture this requirement in a procedure. Relations and properties are also needed for the tests that decide control flow in conditional branches.
Referring explicitly to properties and relations of objects does require additional mechanisms to be defined to support querying for object properties or relations when a procedure is executed. Compared with an alternative approach that represents each object as a static tuple of its properties, this approach provides two distinct advantages. First, the properties themselves may be most natural for users to view and edit in the domain application’s interface, which necessitates that the system can query that application to pick up changes. Second, the object properties may be live, that is, they may change concurrently within the domain application. Live data could invalidate a tuple representation, which is simply a snapshot of the value at a given time. In short, explicit references can be useful anywhere one wants a pointer rather than a copy.
Extensible type system
Recall that we define an action in ITL as taking a set of typed inputs and outputs. These types are used to allow the learners to make reasonable comparisons and substitutions between actions operating on compatible types of data. Figure 11.9 shows a variety of types, ranging from simple primitives such as string to more complex types such as Email.
As with actions, it is preferable to allow application domain models to specify arbitrary types. However, since the type system is critical to capturing dataflow across applications, it is important that types be compatible across applications. For example, in Alice’s procedure, the email client provides the File used by the document viewer, so they must have compatible representations.
We can achieve this agreement either by having the two domains use the same name for these object types, or by providing a central module that asserts the equivalence of the types. Providing shared type names or conversions does not in itself solve the problem of bridging information across multiple domains by matching types. This problem is similar to the ontology alignment or database integration problems (Euzenat & Valtchev, 2004; Parent & Spaccapietra, 1998). Although there are a number of sophisticated approaches, our general strategy in ITL is to maintain a lightweight central type system that is relatively easy for domain model developers to align to, and to rely on PrimTL to automatically align types into our system (Lerman, Plangprasopchock, & Knoblock, 2007).
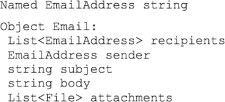
FIGURE 11.9
Building the EmailAddress and Email types.
A lightweight type system allows for easier type alignment; however, it is also useful to allow domain developers to create arbitrarily complex types to support their domain models. To accommodate increased expressiveness while maintaining ease of alignment, ITL implements a hierarchical type system that lets application domain models build up complex data types from primitive data types (Spaulding et al., 2009). For example, consider the complex Email type used in Alice’s procedure as depicted in Figure 11.9.
Complex types are built by aggregating string, integer, float, Boolean, and named primitives into lists or tuples. Lists are ordered groups of identically typed parameters, such as the list of email attachments. Tuples are records of typed fields used to represent complex domain objects, such as Email above. Named types are structurally represented by another type but are not considered equivalent to that type. For example, EmailAddress is represented by a string but should not be considered equivalent to an arbitrary string. This representational scheme allows one to build arbitrarily complex data types while still supporting reasoning over the simpler primitive components (Chaudhri et al., 2006).
OPEN QUESTIONS IN CROSS-DOMAIN END USER PROGRAMMING
Cross-domain EUP is a powerful approach that enables users to extend automation beyond the Web and into the rich desktop applications that pervade so much of our everyday lives. In this chapter, we presented Integrated Task Learning, our approach to cross-domain EUP. Clearly, there are both significant benefits and considerable costs associated with an extensible cross-domain EUP system such as ITL, and in this chapter we explored in detail some of these issues. However, there remain a number of other challenges and avenues for future work.
Interleaved demonstration and editing
EUP in ITL currently primarily involves learning from demonstration, with procedure editing occurring as a postprocessing stage, and data source integration happening orthogonally. However, EUP workflows may not always unfold this way. Consider the case where the user already has a library of smaller procedures that can be composed into what she wants. It may be more natural for the user to use direct manipulation to first construct the procedure, and then to use demonstration to fill in any remaining gaps, including gaps requiring the integration of new data sources. More generally, users will likely want to be able to switch seamlessly back and forth between demonstration and editing as circumstances dictate. Supporting such programming workflows would greatly enhance the usability of an EUP system.
Mixed-initiative learning
Learning in ITL is currently heavily user driven, with the user indicating when to learn from a demonstration and how to correct a learned procedure. Though ITL supports the user by suggesting the most likely generalizations and modifications and by ensuring that no errors are introduced during editing, the user is still ultimately in control of the learning process. There are often situations, however, where ITL could learn more efficiently if it could sometimes ask the user for additional guidance. There may also be cases where offline reasoning suggests procedure merges, subtask extraction, and other refactoring to improve procedure understandability and performance. Unsupervised learning techniques may even be applicable for automatically acquiring procedures based on repeated patterns in a user’s activities. By allowing ITL some of the initiative in the learning process, we could potentially learn a larger, more effective set of procedures.
Procedure sharing
In addition to supporting the reuse of one’s own procedures, an EUP system should support procedure reuse across users. Given that making procedures understandable to the author is already difficult, making them understandable to others is even more challenging. This problem is compounded when there is a wide range in the computational literacy of the user population. Advanced users may be comfortable with complex structures, such as conditionals and iteration, but these may confuse novice users. A simple approach that we have explored is to allow users to explicitly define arbitrary sections within a procedure and to enter descriptions summarizing the procedure and individual steps. Similar to comments in code, this metadata can help users understand and evaluate shared procedures; however, they will be useful only if users feel motivated to add them to their procedures. Automated reasoning and learning approaches, in combination with recent work on leveraging social annotations, may lead to more powerful approaches to procedure sharing.
Another issue that arises with shared procedures is that a given procedure may contain certain types of personal data, such as names, email and mailing addresses, passwords, and credit card information. These types of information will need to be identified and hidden to protect the original author and to be personalized for new users. A possible approach is to use the notion of a personal data store for these data types, as CoScripter does (Leshed et al., 2008), and use semantic mapping capabilities, such as those provided by PrimTL, to find appropriate instantiations for new users.
Consistency in a heterogeneous environment
A widely recognized interface design principle, consistency (Nielsen & Molich, 1990), is difficult enough to achieve in an unregulated environment like the Web. When attempting to integrate Web applications with desktop applications, achieving consistency becomes even more challenging. One option is to return to the native application to edit procedure parameters. Although this leverages users’ familiarity with that application and makes sense for certain dialogs (such as Save As options), it is problematic for other operations like defining loops. A second option, managing editing operations entirely within the EUP tool, raises new questions. Should the EUP system follow platform conventions, Web standards, or some other standard entirely? An extensible visualization system like the one in ITL should allow us to test various approaches with end users, but there are currently no clear answers.
Our Integrated Task Learning system for cross-domain EUP supports programming by demonstration, editing by direct manipulation, and online data source integration. It leverages a variety of artificial intelligence techniques, including structure induction, compositional search, knowledge base inference, and pattern recognition to facilitate these EUP approaches. To support this variety of algorithms, ITL learns dataflow models using a centralized action-oriented domain model and a lightweight, extensible type system. This design streamlines instrumentation and automation while allowing diverse methods for learning, reasoning over, and visualizing cross-domain procedures. In short, ITL demonstrates that by modeling the world around us in a modular, extensible fashion, one can facilitate learning and expand the scope of end user workflow automation to the Web and beyond.
Acknowledgments
We thank Tom Lee, Steven Eker, and Janet Murdock for helping conceptualize and realize LAPDOG; Vijay Jaswal for working out the type system engineering details that hold the ITL system together; and the various other members of the ITL team for helping to bring Integrated Task Learning to life.
This material is based upon work supported by the Defense Advanced Research Projects Agency (DARPA) under Contract No. FA8750-07-D-0185/0004. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of DARPA or the Air Force Research Laboratory (AFRL).
1In this chapter, we use the terms application and domain interchangeably, with the recognition that the Web, while typically involving a single client application, encompasses a rich variety of domains.
2This use case was adapted from a real user workflow discovered in a contextual inquiry user study (Beyer & Holtzblatt, 1998) we conducted in 2008 to observe office workers performing potentially automatable tasks on their computers.
3See also Chapter 8 (Intel Mash Maker) for another take on this approach.