
CHAPTER
12
From Web Summaries to
search templates
Automation for personal tasks on the Web
Mira Dontcheva,1 Steven M. Drucker,2 David Salesin,1,3 Michael F. Cohen2
1Adobe Systems
2Microsoft Research
3University of Washington
ABSTRACT
This chapter describes the Web Summaries system, which is designed to aid people in accomplishing exploratory Web research. Web Summaries enables users to produce automation artifacts, such as extraction patterns, relations, and personalized task-specific search templates, in the context of existing tasks. By leveraging the growing amount of structured Web pages and pervasive search capabilities Web Summaries provides a set of semiautomatic interaction techniques for collecting and organizing personal Web content.
INTRODUCTION
As the amount of content delivered over the World Wide Web grows, so does the consumption of information. And although advancements in search technologies have made it much easier to find information on the Web, users often browse the Web with a particular task in mind, such as arranging travel plans, making purchases, or learning about a new topic. When users have a task in mind, they are often concerned not only with finding but also with collecting, organizing, and sharing information. This type of browsing, which we call exploratory Web research, typically lasts a long time, may span several sessions, involves gathering large amounts of heterogeneous content, and can be difficult to organize ahead of time, as the categories emerge through the tasks themselves (Sellen, Murphy, & Shaw, 2002). Current practices for collecting and organizing Web content such as using bookmarks or tabs, collecting content in documents, storing pages locally, or printing them out (Jones, Bruce, & Dumais, 2002) require a great deal of overhead, as pages must be saved manually and organized into folders, which distracts from the real task of analyzing the content and making decisions.
In our work we break out of the Web page paradigm and consider the individual pieces of content inside of the Web page to be the basic unit that must be collected, as it is the information inside the Web page that is of most importance. If the goal is to let people more easily accomplish their information tasks, then tools must support the manipulation of information, not Web pages.
There are a few examples of systems that give users access over the content inside of a Web page, such as Hunter Gatherer (schraefel et al., 2002), Internet Scrapbook (Sugiura & Koseki, 1998), and C3W (Chapter 8), but it is the Semantic Web that promises to truly transform the way people manipulate information. Unfortunately, the Semantic Web remains unrealized largely because it requires a large collaborative effort in defining an appropriate data representation and adopting that representation. Content providers are not yet willing to invest in embedding semantic information into the existing Web and coordinating their efforts with others.
We take advantage of three trends in the World Wide Web – the growing number of structured Web pages, the vast rise in online collaboration, and pervasive search technologies – and present a new approach for collecting and organizing Web content in a set of semiautomatic interaction techniques and algorithms that allow people to not only collect and organize Web content more quickly and easily but also enable them to build a form of the Semantic Web as they accomplish their own tasks.
OVERVIEW
Our goal in the design of the Web Summaries system was to make the process of collecting information as easy as possible and thereby allow the user to focus on the task at hand rather than worry about organizing and keeping track of content. Because we wanted to aid users through automation while still supporting existing habits, we implemented Web Summaries as an extension to the Firefox Web browser and presented it to the user through a toolbar (see Figure 12.1), which provides Web page clipping functionality, and a summary window (see Figure 12.2), which presents Web clippings through predefined or user-generated layout templates. When users find a Web page they want to save to their summary, they can clip content by interactively selecting parts of the Web page. For each set of user clippings, the system creates extraction patterns. These extraction patterns encode the information the user clipped in the context of the Web page structure. Since many Web sites today present content using templates, we can use structural patterns to automatically extract corresponding information from Web pages that use the same template. For example, clipping information about one hotel allows the user to automatically clip information about other hotels from the same Web site. If the user goes to a new Web site or finds Web pages that are presented with a different Web page structure, he must manually select the content of interest. However, once an extraction pattern is created, it is stored and can be reused each time the user returns to gather information from the Web site.

FIGURE 12.1
Web Summaries offers semiautomatic gathering of Web content through a browser toolbar.
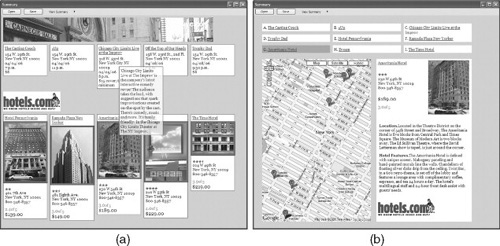
FIGURE 12.2
(a) The grid layout template places all the content on a grid and groups the content by Web site. (b) With the map layout template, the user can view the collected content with respect to a geographical map. This template presents only content that includes an address.
Web Summaries also allows users to automatically gather related information from multiple Web sites. For example, a user can collect information about a restaurant and Web Summaries will automatically retrieve reviews from a favorite review Web site or bus routes from a local transportation Web site. In order to automatically collect related information, the system requires extraction patterns for those Web sites and user-defined relations that describe how the information on the different Web sites is associated. We describe the algorithm for retrieving related information in detail in the next section on “Gathering content semiautomatically”.
Finally, Web Summaries introduces personalized search templates, which combine user-defined extraction patterns, relations, and layouts with a query interface. With search templates users can retrieve search results that include information from multiple Web sites and are formatted according to the user’s preferences (see Figures 12.3 and 12.6).
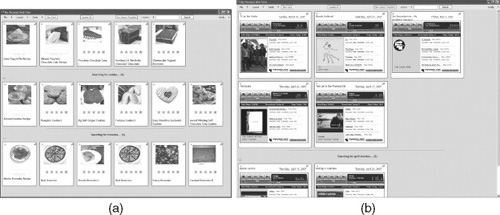
FIGURE 12.3
(a) With the recipe search template, the user collects recipes from cooking.com and allrecipes.com. Here the user has already collected five cards (shown in the first row) and has made two queries, one for “cookies” and another for “brownies.” The system automatically gathers, extracts, and displays relevant recipes. The user can drag any search result into his collection. (b) The user relates upcoming.org to myspace.com to automatically collect music samples for upcoming shows.
SYSTEM DESIGN
The Web Summaries system includes five components: an extraction pattern repository that includes user-specified extraction patterns and relations; a data repository that holds the content collections; predefined layout templates and user-defined cards that compose the summary views; and a set of search templates that combine various extraction patterns, relations, and cards and allow users to retrieve information from multiple Web sites simultaneously and compose it in a personalized way. Figure 12.4 provides a visual description.
Gathering content semiautomatically
The Web Summaries clipping interface uses the Document Object Model (DOM) structure as a mechanism for selecting content. When the user initiates the clipping mode through the toolbar, the typical behavior of the Web page is frozen, and the browser mouse event handlers are extended to allow the user to select pieces of the DOM hierarchy. As the user moves the cursor and clicks, the DOM nodes directly underneath the cursor are highlighted. Once the user has selected a set of nodes, the system generates an extraction rule for each selected node. The extraction rule consists of the selected node, the path from the root of the document to the selected node, and the user-assigned label. Web Summaries provides a set of common labels, however users can define their own personalized tags. The path in the extraction rule enables finding analogous elements in documents with similar structure. Structural extraction rules are also known as XPATH queries. The extraction rules rely on consistent structure. Thus, if the structure changes, the user will have to go back and respecify extraction rules. Gibson et al. (Gibson, Punera, & Tomkins, 2005) show that template material changes every 2 to 3 months; however, they give few details on the types of changes. To evaluate the performance of structural extraction patterns over time, we conducted a 5-month study of Web page changes. Please see Dontcheva et al. (2007a) for details.
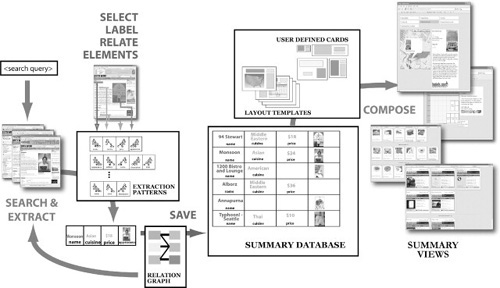
FIGURE 12.4
The user-selected page elements define extraction patterns that are stored in the extraction pattern repository. Every new page the user visits is compared with the patterns, and if matching page elements are found, the user can add them to the summary database. The layout templates filter the database and compose summary views. The user can view the database contents at any time with any view.
In addition to the structural extraction rules just described, the system also provides content-based rules. Content-based extraction rules collect content from new Web pages by matching text patterns instead of structural patterns. To specify a content-based rule, the user selects an element and labels it not with a keyword, as he does with the structural rules, but with text from the selected element that should be matched in analogous elements. For example, to only collect articles by author “John”, the user selects an article and its author, chooses “semantic rule” from the right-button context menu, and types “John”. A content-based rule first tries to find matching content using the structural path, but if it is not successful, the rule searches the entire document. It finds matching content only if the node types match. For example, if the rule finds the word “John” in a <table> node and the selected node defining the rule is in a <p> node, the rule will fail. This limits the number of spurious matches and ensures consistency in the gathered content. The effectiveness and power of content-based rules, when possible, was shown by Bolin et al. in Chickenfoot (Chapter 3).
The user may specify any number of extraction rules for a given page. Because those rules should always be applied together, the system collects the extraction rules into extraction patterns and then stores them in the extraction pattern repository (see Figure 12.4). An extraction pattern can include any number of extraction rules and can be edited by the user to add or remove rules. For example, the user might care about the name, hours, and address of a restaurant. The system creates an extraction rule for each of these elements and then groups them together so that for any new restaurant page, it searches for all page elements in concert.
When the user visits a Web page, each available extraction pattern for that Web domain is compared with the DOM hierarchy, and the pattern with the highest number of matching rules is selected as the matching pattern. If the user chooses to store the matched content, the Web page is stored locally, and the elements found by the matching pattern are added to the summary database (see Figure 12.4). The user can select hyperlinks and collect content from multiple pages simultaneously. The system loads the linked pages in a browser not visible to the user, compares the pages with the extraction patterns, and adds all matching elements to the database. If an extraction pattern does not match fully, it may be because some of the content is absent from the page, or because the structure of the page is slightly different. In these cases, the user can augment the extraction pattern by selecting additional elements from a page that includes the new content.
Although the growing use of Web page layout templates for formatting and organizing content on the Web makes it possible to automate collecting information from the Web, this automation comes at a cost. The automatic extraction is sensitive to the structure of HTML documents and depends on a sensible organization to enable clipping of elements of interest. If the structure does not include nodes for individual elements, the user is forced to select and include more content than necessary. On the other hand, if the structure is too fine, the user must select multiple elements, adding overhead to the clipping process. Most Web sites that do use templates tend to use those with good structure, because good structure makes it easier to automate Web page authoring.
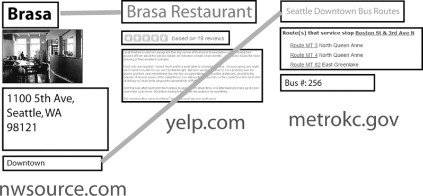
FIGURE 12.5
To create relationships between Web sites, the user can draw links between similar page elements.
To collect content from multiple Web sites automatically, the user must first specify the relationship between the Web sites by drawing a line in the summary connecting the page elements that are similar (see Figure 12.5). We represent this relationship as a relation and define a relation as a directed connection from tagi from websiteA to tagj from websiteB. For example, when the user draws a line between the names of the restaurants, he creates a relation from the “name” tag on Northwest Source to the “name” tag on Yelp. When the user connects restaurants and buses, he creates a relation from the “area” tag to the “route” tag. All relations are stored in the data repository and are available to the user at any time. Web page elements that are associated through relations form a relation graph.
When the user collects content from a new Web page, the system checks for relations that connect any of the collected Web page elements to other Web sites. When such relations exist, the system uses them to generate new search queries and limits the search results to the Web site specified in the relation. For example, when the user collects information about the restaurant “Nell’s,” the system generates two queries. To collect restaurant reviews it generates a query using the “name” tag (i.e., “Nell’s”) and limits the search results to yelp.com. To collect bus schedules the system generates a query using the “area” tag (i.e., “Green Lake”) and limits the search results to the bus Web site, metrokc.gov.
To define this process more formally, the execution of a relation can be expressed as a database query. For a given relation r, where r = websiteA.tagi websiteB.tagj, one can express the process of automatically collecting content for any new data record from websiteA for tagi as a JOIN operation or the following SQL pseudo-query:
SELECT * FROM websiteB WHERE websiteB.tagj = websiteA.tagi
Since the Web is not made up of a set of uniform databases, we use a number of techniques to make this query feasible. We use the Google Search AJAX API to find Web pages within websiteB that are relevant. To extract content from each of the search results, we employ the user-defined extraction patterns. Finally, we designed a number of heuristics to compute a similarity metric and rank the extracted search results. The system displays only the highest ranked extracted search result to the user but makes the remaining search results available.
In the current implementation, the system extracts content from only eight search results, because the Google AJAX Search API limits the search results to a maximum of eight. For all of the examples in this chapter, eight search results are sufficient and limit the delay in collecting information. For very common keywords, however, collecting eight search results is not sufficient. For example, searching for “Chili’s” will yield many instances of the restaurant chain. For those types of queries, narrowing the search through one of the approaches discussed in the next section is necessary.
Our approach for collecting related content is limited to Web sites that are indexed by general search engines. There are many Web sites, such as many travel Web sites, that are not indexed by search engines because they create Web pages dynamically in response to user input. To handle these dynamic Web pages, in subsequent work we hope to leverage research into macro recording systems, such as WebVCR (Anupam et al., 2000), Turquoise (Miller & Myers, 1997), Web Macros (Safonov, 1999), TrIAs (Bauer, Dengler, & Paul, 2000), PLOW (Chapter 16), and Creo (Chapter 4). These systems allow users to record a series of interactions, store them as scripts, and replay them at any time to retrieve dynamic pages. Recent research on retroactive macro recording could be even more applicable for Web Summaries (Hupp & Miller, 2007). Madhavan et al. (2007) are developing information retrieval approaches to this problem that do not require user intervention.
The search process introduces ambiguity at two levels, the query level and the search result level. The system must be able to formulate a good query so that it can retrieve the relevant content. It must also be able to find the correct result among potentially many that may all appear similar. Both of these forms of ambiguity pose considerable challenges and are active areas of research. Liu et al. (Liu, Dong, & Halevy, 2006) pose the query formulation problem as a graph partitioning. Dong et al. (Dong, Halevy, & Madhavan, 2005) propose propagating information across relations to better inform similarity computation. Next, we describe how we address these two types of ambiguity.
Query formulation
We formulate two keyword queries in parallel. One query includes only the extracted text content, and the other includes the extracted content and the tag associated with the content. These two queries are usually sufficient to collect the appropriate result within the top eight search results. Sometimes, however, queries may include too many keywords, and the search results are irrelevant or cannot be extracted. In such cases, we employ heuristics to reformulate the query. If characters such as “/”, “−”, “+”, or “:” appear in the text, we split the string whenever they appear and issue several queries using the partial strings. We found this approach particularly effective for situations in which something is described in multiple ways or is part of multiple categories. For example, a yoga pose has a Sanskrit name and an English name. Querying for either name returns results, but querying for both does not, as the query becomes too specific. Queries may also be augmented to include additional Web page elements, such as the address, to make the query more or less specific. With an interactive system, processing a large number of queries can be prohibitive because of the delay caused by the search and extraction process. We focus on finding good heuristics that quickly retrieve results that are close to the desired content. If the system fails to find a good search result, the user can always go to the Web site and collect the content interactively.
Search result comparison
For each query we extract the first eight search results and rank the extracted content according to similarity to the Web page content that triggered the query. To compute similarity we compare the text of the extracted Web page elements using the correspondence specified in the relation that triggered the search. For example, when collecting content for the “Ambrosia” restaurant from nwsource.com, the system issues the query “Ambrosia” limiting the results to the yelp.com domain. The search results include reviews for the following establishments: “Ambrosia Bakery” (in San Francisco), “Cafe Ambrosia” (in Long Beach), “Cafe Ambrosia” (in Evanston), “Ambrosia Cafe” (in Chicago), “Ambrosia on Huntington” (in Boston), “Ambrosia Cafe” (in Seattle), and “Caffe Ambrosia” (in San Francisco). Because the relation between nwsource.com and yelp.com links the names of the restaurants, we compare the name “Ambrosia” to all the names of the extracted restaurants. We compare the strings by calculating the longest common substring. We give more weight to any strings that match exactly. For all seven restaurants in this example, the longest common substring is of length eight; thus, they receive equal weight. Next, we compare any additional extracted elements. We again compute the longest common substring for corresponding Web page elements. In this example, we compare the addresses of the extracted restaurants and compute the longest common substring for each pair of addresses, resulting in a ranking that places the Seattle restaurant “Ambrosia Cafe” as the best match to the original content. We display the highest ranked extracted content but provide all of the extracted content to the user so that he can correct any errors. The highest ranked content is marked as confident when multiple Web page elements match between Web sites.
The problem of retrieving related information from multiple sources is described in the database community as data integration (Halevy, Rajaraman, & Ordille, 2006). Data integration is the problem of combining data residing in different sources and providing the user with a unified view of these data. The difficulty in data integration lies in forming mappings between heterogeneous data sources that may include different types of data and defining one single query interface for all of the sources. This problem emerges in a variety of situations both commercial (when two similar companies need to merge their databases) and scientific (combining research results from different bioinformatics repositories). With the growth of the Web, database researchers have shifted their focus toward data integration of unstructured Web content and its applications to Web search (Madhavan et al., 2007). Our work is complementary to database research in that it offers interactive techniques for data integration on a personal scale. We provide an interface that allows users to specify mappings between different data sources (i.e., Web sites) and then use these mappings to automatically extract content from the Web.
Finally, the current implementation allows the user to specify only one-to-one relations. In some situations a one-to-many relation is more appropriate, for example, if the user is interested in collecting academic papers and wants to collect all of the papers written by each of the authors for any given publication. The system can actually query for all of the papers by a given author, but it is not designed to let the user view all elements of the collection as relevant. In future work, we plan to explore other types of relations and also introduce transformations into the relations.
Summary composition
User collections are displayed using layout templates that filter the database to create summaries. Web Summaries includes two kinds of layout templates: predefined and user-specified. The predefined layout templates organize the entire collection. For example, table-based layouts organize the content in a grid, whereas anchor-based layouts relate the content through a central graphical element, such as a map or calendar.
User-specified layout templates, which we call cards, provide the user flexibility in the summary display. With cards, users can create different views for the items they are collecting. For example, the user can create a big card that includes a restaurant name, rating, address, price, and review, and a small card that includes just the restaurant name and price. All layout templates are defined with respect to the user-specified tags associated with the extracted content.
Predefined layout templates
To demonstrate different possibilities for summarizing Web content we implemented six layout templates: grid-based (see Figure 12.2a), map (see Figure 12.2b), calendar, text-based, PDA, and printbased. A layout template consists of placement and formatting constraints. The placement constraints specify how the data should be organized in the summary. For example, a placement constraint can specify that all content with the label “name” be placed in a list at the top of the document. The position of each element can be specified in absolute pixel coordinates or be relative to previously placed elements. For relative placement, the browser layout manager computes the final content position; for absolute placement, the template specifies all final element positions. Placement constraints can be hierarchical. For example, the template designer can specify that content collected from the same Web page be grouped into one visual element and that such groupings be organized in a list. Although the hierarchy can have any depth, in practice we have found that most layout templates include placement constraint hierarchies no deeper than two or three levels. Formatting constraints specify the visual appearance of the elements, such as size, spacing, or borders.
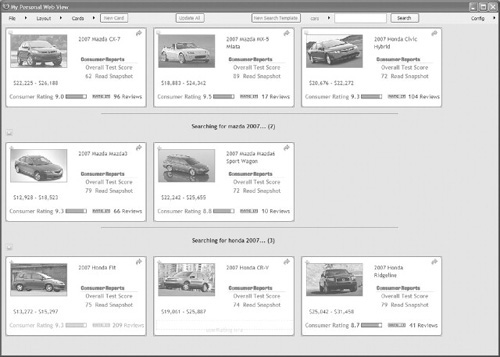
FIGURE 12.6
The user is shopping for cars and using a car search template to find new cars. He has three cards in his collection (shown in the first row) and has made two queries: “mazda 2007” (second row) and “honda 2007” (third row). Each card includes car reviews from autos.msn.com and edmunds.com.
Each layout template can also specify mouse and keyboard interactions for the summary. For example, when the user moves the cursor over an item in the calendar layout template, a short description of the event is presented. When the user clicks on the item, a detailed view of that item is displayed in a panel next to the calendar.
The layout templates are implemented with Dynamic HTML (DHTML), JavaScript and Cascading Style Sheet (CSS) style rules. To create the summary, the system loads an empty HTML document and dynamically populates the document with the DOM nodes in the database, using the placement constraints of the current layout template.
Authoring cards
When the user collects content from multiple Web sites, the summary may include duplicate information. For example, Figure 12.7 shows that the summary includes the Andaluca restaurant address twice, once from nwsource.com and once from yelp.com. Although this duplication is not necessarily a problem, it does take up extra space, making it difficult for the user to quickly scan through many options. Web Summaries allows users to author cards to customize the view of collected information to their personal needs.
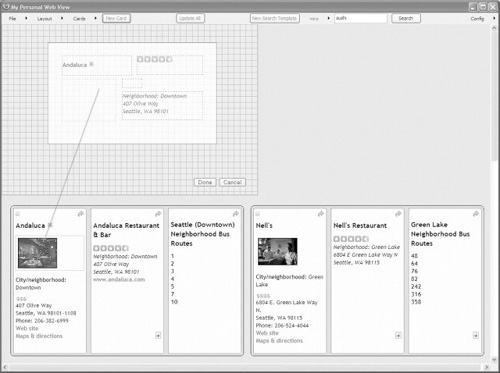
FIGURE 12.7
To design a new card, the user opens a canvas and begins drawing. He first draws the outline of the card and then draws containers. To place content in the containers, the user draws a line from the Web page element to the container. Here, the user adds an image to the card.
A card imposes a uniform design on content that may come from many different Web sites and may initially appear very different. Similarly to the predefined layout templates, a card defines which content should be displayed and how the content should be organized visually. Recall that the user’s content collection is stored in the data repository and is accessible through a relation graph. It is the relation graph that specifies which records in the data repository are related. In database terminology, a card can also be described as defining a view on the relation graph in the data repository – that is, it lists the tags for the data that should be displayed in the card. For example, a card can include the name and address of a restaurant. Or it can also include pricing, rating, and images. The system includes a default card, which displays all records and Web page elements in the relation graph irrespective of the tags associated with the Web page elements. The user can use an interactive editing tool to create new cards at any time. Cards are persistent and can be reused and shared with others.
To create a new card the user clicks on the “New Card” button, which opens a canvas directly in his collection of Web content (see Figure 12.7). The card designer is tightly integrated with the collection space so that the user can quickly and easily merge content from different Web sites without switching windows or views. The user first draws the outline of the card and then proceeds to create containers that hold the Web page elements. To assign data to a container, the user clicks on a Web page element and drags a line to the container. The data is automatically resized to fit the size of the container. Each container is associated with the tag of the Web page element it contains and the element Web site. When the user is finished creating containers and assigning data, he clicks on the “Done” button, and the system transforms his drawing into a template for organizing and displaying Web content, a card. The user can at any time edit the card and add or remove content. Currently, the cards are presented in a grid, but they could also be manually organized into piles or arranged visually on a map or calendar. The authoring principles behind the card designer can also extend to authoring layout templates that organize the cards.
Cards can be interactive in nature, encoding interactions specific to the type of data that is collected. The card authoring tool does not currently provide capabilities for specifying interactions. We could expose a scripting interface and allow the user to specify any type of card interactions, but since Web Summaries does not require programming we chose to remove all scripting from the interactions.
Template-based search
Search templates combine the user-designed cards and relations as a basis for a new type of search interface that targets the keyword query to appropriate domains and organizes the search results in a visual summary. The user can thus bypass visiting Web pages directly and collect content through a search template. For example, if the user wants to find vegetarian restaurants but does not know where to start, he can simply query with the word “vegetarian” directed toward the data underlying the restaurant card. More formally, a search template includes a set of Web sites and any associated relations. When a user types a query in the search template, the system sends the query to a general search engine, in this case through the Google Search AJAX API, limiting the search results to the list of Web sites defined in the template. For each search result, the system extracts content using predefined extraction patterns and triggers any relations that are in the template to collect additional content. Because of limitations on the number of search results provided by the Google Search AJAX API, for each query/Web site pair, the system processes only eight search results. The user can also modify the search template by adding additional Web sites to be queried and relations to be triggered. Extracted search results are presented to the user as a set of cards. These are initially considered temporary, indicated by being displayed below the main collection of cards. The user can promote a search result to the actual collection, or he can delete all of the search results for a given query. For a visual description, please see Figure 12.8.
Because search templates combine information from multiple Web sites that is retrieved without the user’s help, it becomes important to convey to the user the system’s confidence in the retrieved results. Web Summaries achieves this through transparency. If content is not marked as confident during the automatic retrieval process, it is rendered semitransparent to alert users that they may want to confirm the information by clicking on it to go to the source Web page. In Figure 12.6 the rating for the 2007 Honda Fit is rendered in this way.
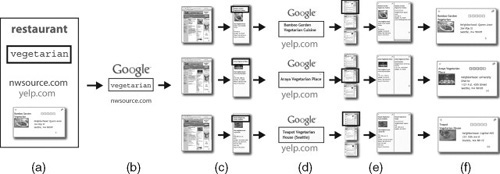
FIGURE 12.8
(a) The user types the query “vegetarian” into the restaurant search template to collect vegetarian restaurants. This search template includes two Web sites and a relation. The nwsource.com Web site is considered primary, because information from yelp.com is collected through a relation. (b) The system issues the query “vegetarian” to a general search engine and limits the results to nwsource.com. (c) Each search result is processed with an extraction pattern to extract relevant content. (d) The extracted content triggers relations, which issue further queries. (e) The subsequent search results are extracted, ranked, and added to the content that triggered the additional retrieval. (f) Finally, the user sees the extracted content as a series of cards.
Search templates may include Flash content as well. Figure 12.3b shows a collection of upcoming shows. In this example the user has related concerts from upcoming.org with band Web pages at myspace.com. Whenever the user adds a new concert to his collection, the system automatically collects music samples. The music samples are embedded in a music player, and because the player is just another HTML object, a Flash object, one can extract it just like any other Web page element. The music player retains full functionality, and the user can press the “play” button on the control to listen to the music.
The success of template-based search lies in the ability to extract semantic information from Web pages. Although semantic extraction is only in its infancy, we believe that it will only grow in the coming years, and template-based search is an example of the powerful new applications that will take advantage of machine-readable Web pages.
DISCUSSION
The interaction techniques embodied in the Web Summaries system enable users to transform the Web into their own personal Web that provides personalized access to the information they care about in the form of their choosing. First, we take advantage of the growth in template material on the Web and design semiautomatic interactive extraction of content from similar Web pages using structural and content extraction patterns. Second, we employ layout templates and user labeling to create rich displays of heterogeneous Web content collections. Third, we use search technology for proactive retrieval of content from different related Web sites through user-defined relations. Fourth, we let users define their own personalized and aesthetic views of heterogeneous content from any number of Web sites through cards. And finally, we introduce a new template-based search paradigm that combines the user-defined relations and cards into a search template. Search templates present a goal-driven search mechanism that creates visual personalized summaries of the content users need to accomplish their task. As users accomplish their goals with these tools, they also produce artifacts, such as the extraction patterns and relations that are persistent and sharable. These artifacts can be stored in a public repository and reused by others. Furthermore, they can be added to the Web sites where they originated, thereby enhancing the existing Web with semantic information, such as relationships between different Web sites or the types of content available in a particular Web page. If popularized by an online community, the ideas we present here can help realize a machine-readable World Wide Web.
To better understand how the Web Summaries system works in practice and to test how it would interact with an online community for sharing extraction patterns, we deployed the system for 10 weeks with 24 participants. Here we present the main conclusions from this field study. For more details, please see (Dontcheva et al., 2008).
Our study revealed that users collect a variety of Web content including highly structured content, such as tables and lists, and highly unstructured content, such as entire articles. Our participants actively used automatic retrieval on many Web sites and for their own personal tasks. They created over 250 extraction patterns by clipping pieces of Web pages and collected over 1000 items automatically. Though Web Summaries was useful for content-intensive tasks, users found it less applicable for transient daily tasks, because the tool required opening a summary window and actively saving content. Many participants also used Web Summaries as a mechanism for storing permanent versions of Web content that they view as highly dynamic. The participants were very positive about the layout templates and the resulting summaries. They used a variety of layout templates and requested more flexible customizable templates. Finally, the participants used a community pattern repository to download patterns created by others. They often modified downloaded patterns to suit their own needs. They suggested many improvements to the interface to help make sharing patterns as fast and easy as creating them through clippings.
These findings lead us to the following design implications for future semiautomatic and automatic tools for collecting Web content. First, tools for collecting and organizing Web content need to support the ability to collect both structured and unstructured Web content and display a heterogeneous collection of content. Second, in order to become well integrated into a user’s daily Web usage, automation tools need to be sensitive not only to long and permanent Web tasks but also to transient and short-lived tasks, otherwise users will not integrate them into their Web browsing habits. Since Web browsing is such an integral part of users’ lives, tools that support information management must be fluidly integrated into the browser and be available at any time. Finally, an online repository of extraction pattern information is still very new to users, and visualizations for exposing the available information must be carefully designed such that this type of shared automation can aid rather than hinder users from accomplishing their tasks.
Acknowledgments
We would like to thank Sharon Lin, Cheyne Mathey-Owens, and our study participants for all of their time and effort. Special thanks to Allen Cypher, Jeffrey Nichols, and Hyuckchul Jung for their insightful comments during the chapter preparation and review process.
This work is based on two earlier works:
1. Dontcheva, M., Drucker, S. M., Wade, G., Salesin, D., and Cohen, M. F. 2006. Summarizing Personal Web Browsing Sessions. In Proceedings of the 19th Annual ACM Symposium on User Interface Software and Technology. UIST ’06, 115-124. DOI= http://doi.acm.org/10.1145/1166253.1166273.
2. Dontcheva, M., Drucker, S. M., Salesin, D., and Cohen, M. F. 2007. Relations, Cards, and Search Templates: User-Guided Web Data Integration and Layout. In Proceedings of the 20th Annual ACM Symposium on User Interface Software and Technology. UIST ’07, 61-70. DOI= http://doi.acm.org/10.1145/1294211.1294224.
Intended users: |
All users |
Domain: |
All Web sites |
Description: |
With Web Summaries, users can create personalized search templates that can automatically retrieve content from multiple Web sites and display the information with a personally specified view. Search templates include user-defined extraction patterns for Web pages, relations between Web sites, and layout templates. |
Example: |
Restaurant Search. The user first clips and visually links information from a restaurant and bus Web site. The system automatically collects the same information for a few more restaurants and their associated bus routes. The user then arranges the restaurant and bus information in a visual card. Web Summaries uses the card to initialize a restaurant search template. The user can now query for sushi and the system retrieves sushi restaurant cards that present information from multiple local restaurant and bus Web sites. |
Automation: |
Yes. It automates collecting and organizing Web content. |
Mashups: |
Yes. Users can link information from multiple Web sites together and view it on maps, calendars, and grids. |
Scripting: |
No. |
Natural language: |
No. |
Recordability: |
No. |
Inferencing: |
Yes, Web Summaries infers data types using heuristics. |
Sharing: |
Yes, summaries can be shared as regular HTML pages. |
Comparison to other systems: |
Similarly to C3W and Zoetrope, Web Summaries allows users to link content from multiple Web sites and automatically retrieve related information. It is unique in its emphasis on data. The user manipulates data and creates personalized views of that data and as a side effect creates automation artifacts such as extraction patterns, relations, and search templates. |
Platform: |
Implemented as an extension to the Mozilla Firefox browser. |
Availability: |
Not currently available. |