
CHAPTER
23
How the Web helps people turn
ideas into code
Joel Brandt,1,2 Philip J. Guo,1 Joel Lewenstein,1 Mira Dontcheva,2 Scott R. Klemmer1
1Stanford University
2Adobe Systems, Inc.
ABSTRACT
This chapter investigates the role of online resources in building software. We look specifically at how programmers – an exemplar form of knowledge workers – opportunistically interleave Web foraging, learning, and writing code. To understand this, we have both studied how programmers work in the lab and analyzed Web search logs of programming resources. The lab provides rich, detailed information and context about how programmers work; online studies offer a naturalistic setting and the advantages of scale. We found that programmers engage in just-in-time learning of new skills and approaches, clarify and extend their existing knowledge, and remind themselves of details deemed not worth remembering. The results also suggest that queries for different purposes have different styles and durations. These results contribute to a theory of online resource usage in programming, and suggest opportunities for tools to facilitate online knowledge work.
INTRODUCTION
“Good grief, I don’t even remember the syntax for forms!” Less than a minute later, this participant in our Web programming lab study had found an example of an HTML form online, successfully integrated it into her own code, adapted it for her needs, and moved on to a new task. As she continued to work, she frequently interleaved foraging for information on the Web, learning from that information, and authoring code. Over the course of 2 hours, she used the Web 27 times, accounting for 28% of the total time she spent building her application. This participant’s behavior is illustrative of programmers’ increasing use of the Web as a problem-solving tool. How and why do people leverage online resources while programming?
Web use is integral to an opportunistic approach to programming that emphasizes speed and ease of development over code robustness and maintainability (Brandt et al., 2009a; Hartmann, Doorley, & Klemmer, 2008). Programmers do this to prototype, ideate, and discover – to address questions best answered by creating a piece of functional software. This type of programming is widespread, performed by novices and experts alike: it happens when designers build functional prototypes to explore ideas (Myers et al., 2008), when scientists write code to control laboratory experiments, when entrepreneurs assemble complex spreadsheets to better understand how their business is operating, and when professionals adopt agile development methods to build applications quickly (Martin, 2002). Scaffidi, Shaw, and Myers (2005) estimate that by the year 2012 there will be 13 million people in the United States who call themselves “programmers.” This estimate is over four times larger than the Bureau of Labor Statistics’ estimate of 3 million “professional programmers” (Scaffidi, Shaw, & Myers, 2005). This discrepancy is indicative of the trend that programming is becoming an essential part of many other professions, and that an increasing number of individuals are engaging in programming without formal training. We believe there is significant value in understanding and designing for this large population of amateur programmers.
To create software more quickly, people – especially amateurs – often tailor or “mash up” existing systems (see Chapters 8–11, and also MacLean et al., 1990; Lieberman, Paternò), & Wulf, 2006). As part of this process, they often search the Web for suitable components and learn new skills (Hoffmann, Fogarty, & Weld, 2007). How do people currently use the Web to program, and what are high impact opportunities for tools to support and improve this practice? To help readers get as much as possible out of this chapter, we’ll start with conclusions and then explain the studies that led to them. Through our studies, we have uncovered five key insights about how programmers use online resources.
FIVE KEY INSIGHTS
Programmers use Web tutorials for just-in-time learning, gaining high-level conceptual knowledge when they need it. Tools may valuably encourage this practice by tightly coupling tutorial browsing and code authoring. One system that explores this direction is d.mix (described in Chapter 10), which allows users to “sample” a Web site’s interface elements, yielding the API calls necessary to create them. This code can then be modified inside a hosted sandbox.
Web search often serves as a “translator” when programmers don’t know the exact terminology or syntax. Using the Web, programmers can adapt existing knowledge by making analogies with programming languages, libraries, and frameworks that they know well. The Web further allows programmers to make sense of cryptic errors and debugging messages. Future tools could proactively search the Web for the errors that occur during execution, compare code from search results to the user’s own code, and automatically locate possible sources of errors.
Programmers deliberately choose not to remember complicated syntax. Instead, they use the Web as external memory that can be accessed as needed. This suggests that Web search should be integrated into the code editor in much the same way as identifier completion (e.g., Microsoft’s IntelliSense and Eclipse’s Code Assist). Blueprint is a system that is beginning to explore this direction (Brandt et al., 2010). Blueprint brings the task of searching for example code into the development environment. This integration allows Blueprint to leverage code context to return better search results, which ultimately helps programmers write better code more quickly. Another possible approach is to build upon ideas like keyword programming (Little & Miller, 2006) to create authoring environments that allow the programmer to type “sloppy” commands that are automatically transformed into syntactically correct code using Web search.
Programmers often delay testing code copied from the Web, especially when copying routine functionality. As a result, bugs introduced when adapting copied code are often difficult to find. Tools could assist in the code adaptation process by, for example, highlighting all variable names and literals in any pasted code. Tools could also clearly demarcate regions of code that were copied from the Web and provide links back to the original source.
Programmers are good at refining their queries, but need to do it rarely. Query refinement is most necessary when users are trying to adapt their existing knowledge to new programming languages, frameworks, or situations. This underscores the value of keeping users in the loop when building tools that search the Web automatically or semiautomatically. In other cases, however, query refinements could be avoided by building tools that automatically augment programmers’ queries with contextual information, such as the programming language, frameworks or libraries in the project, or the types of variables in scope.
STUDY 1: OPPORTUNISTIC PROGRAMMING IN THE LAB
We conducted an exploratory study in our lab to understand how programmers leverage online resources, especially for rapid prototyping.
Method
The participants’ task was to prototype a Web chat room application using HTML, PHP, and JavaScript. They were given a working execution environment (Apache, MySQL, and a PHP interpreter), and were asked to implement five specific features (see sidebar). Four of the features were fairly typical, but the fifth (retaining a limited chat history) was more unusual. We introduced this feature so that participants would have to do some programming, even if they implemented other features by downloading an existing chat room application (three participants did this). We instructed participants to think of the task as a hobby project, not as a school or work assignment. Participants were not given any additional guidance or constraints. An experimenter asked open-ended questions to encourage think-aloud reflection, and all participants were recorded with audio and video screen capture.
Chat room features that lab study participants were asked to implement:
1. Users should be able to set their username on the chat room page (application does not need to support account management).
2. Users should be able to post messages.
3. The message list should update automatically without a complete page reload.
4. Each message should be shown with the username of the poster and a timestamp.
5. When users first open a page, they should see the last 10 messages sent in the chat room, and when the chat room updates, only the last 10 messages should be seen.
Twenty Stanford University students participated in a 2.5-hour session. The participants had an average of 8.3 years of programming experience, but little professional experience (only one spent more than 1 year as a professional developer). Thirteen participants rated themselves as novices in at least one of the technologies involved. For a more thorough description of the method, see (Brandt et al., 2009b).
Results
On average, participants spent 19% of their programming time on the Web in 18 distinct sessions (see Figure 23.1). Web session length resembles a power-law distribution (see Figure 23.2). The shortest half (those less than 47 seconds) compose only 14% of the total time; the longest 10% compose 41% of the total time. This suggests that individuals are leveraging the Web to accomplish several different kinds of activities. Web usage also varied considerably between participants: the most active Web user spent an order of magnitude more time online than the least active user.
Intentions behind Web use
Why do programmers go to the Web? At the long end of the spectrum, participants spent tens of minutes learning a new concept (e.g., by reading a tutorial on AJAX-style programming). On the short end, participants delegated their memory to the Web, spending tens of seconds to remind themselves of syntactic details of a concept they knew well (e.g., by looking up the structure of a foreach loop). In between these two extremes, participants used the Web to clarify their existing knowledge (e.g., by viewing the source of an HTML form to understand the underlying structure). This section presents typical behaviors, anecdotes, and theoretical explanations for these three styles of online resource usage (see Table 23.1 for a summary).
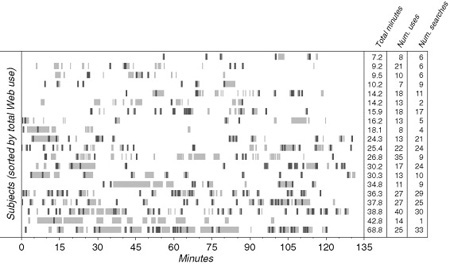
FIGURE 23.1
Overview of when participants referenced the Web during the laboratory study. Subjects are sorted by total amount of time spent using the Web. Web use sessions are shown in light gray, and instances of Web search are shown as dark bars.
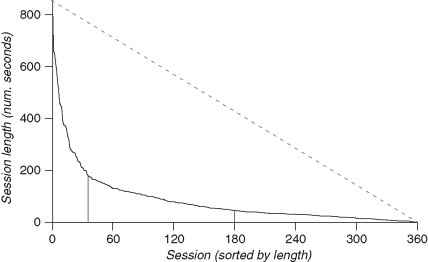
FIGURE 23.2
All 360 Web use sessions among the 20 participants in our lab study, sorted and plotted by decreasing length (in seconds). The left vertical bar represents the cutoff separating the 10% longest sessions, and the right bar the cutoff for 50% of sessions. The dotted line represents a hypothetical uniform distribution of session lengths.
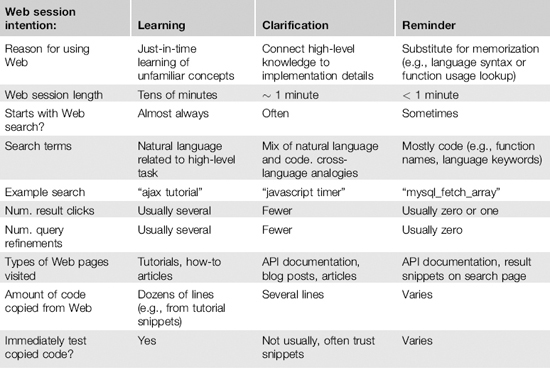
Just-in-time learning
Participants routinely stated that they were using the Web to learn about unfamiliar technologies. These Web sessions typically started with searches used to locate tutorial Web sites. After selecting a tutorial, participants frequently used its source code for learning-by-doing.
Searching for tutorials. Participants’ queries usually contained a natural language description of a problem they were facing, often augmented with several keywords specifying technology they planned to use (e.g., “php” or “javascript”). For example, one participant unfamiliar with the AJAX paradigm performed the query “update web page without reloading php”. Query refinements were common for this type of Web use, often before the user clicked on any results. These refinements were usually driven by familiar terms seen on the query result page: In the previous example, the participant refined the query to “ajax update php”.
Selecting a tutorial. Participants typically clicked several query result links, opening each in a new Web browser tab before evaluating the quality of any of them. After several pages were opened, participants would judge their quality by rapidly skimming. In particular, several participants reported using cosmetic features – such as prevalence of advertising on the Web page or whether code on the page was syntax-highlighted – to evaluate the quality of potential Web sites. When we asked one participant how she decided what Web pages are trustworthy, she explained, “I don’t want [the Web page] to say ‘free scripts!’ or ‘get your chat room now!’ or stuff like that. I don’t want that because I think it’s gonna be bad, and most developers don’t write like that…they don’t use that kind of language.” This assessing behavior is consistent with information scent theory, in that users decide which Web pages to explore by evaluating their surface-level features (Pirolli, 2007).
Using the tutorial. Once a participant found a tutorial that he believed would be useful, he would often immediately begin experimenting with its code samples (even before reading the prose). We believe this is because tutorials typically contain a great deal of prose, which is time-consuming to read and understand. Subject 10 said, “I think it’s less expensive for me to just take the first [code I find] and see how helpful it is at…a very high level…as opposed to just reading all these descriptions and text.”
Participants often began adapting code before completely understanding how it worked. One participant explained, “there’s some stuff in [this code] that I don’t really know what it’s doing, but I’ll just try it and see what happens.” He copied four lines into his project, immediately removed two of the four, changed variable names and values, and tested. The entire interaction took 90 seconds. This learning-by-doing approach has one of two outcomes: It either leads to deeper understanding, mitigating the need to read the tutorial’s prose, or it isolates challenging areas of the code, guiding a more focused reading of the tutorial’s prose.
For programmers, what is the cognitive benefit of experimentation over reading? Results from cognitive modeling may shed light on this. Cox and Young developed two ACT-R models to simulate a human learning the interface for a central heating unit (Cox & Young, 2000). The first model was given “‘how-to-do-the-task’ instructions” and was able to carry out only those specific tasks from start to finish. The second model was given “‘how-the-device-works’ instructions,” (essentially a better mapping of desired states of the device to actions performed) and afterwards could thus complete a task from any starting point. Placing example code into one’s project amounts to picking up a task “in the middle.” We suggest that when participants experiment with code, it is precisely to learn these action/state mappings.
Approximately one third of the code in participants’ projects was physically copied and pasted from the Web. This code came from many sources: whereas a participant may have copied a hundred lines of code altogether, he did so ten lines at a time. This approach of programming by example modification is consistent with the Yeh et al. study of students learning to use a Java toolkit (Yeh, Paepcke, & Klemmer, 2008).
Clarification of existing knowledge
There were many cases where participants had a high-level understanding of how to implement functionality, but did not know how to implement it in the specific programming language. They needed a piece of clarifying information to help map their schema to the particular situation. The introduction presented an example of this behavior: The participant had a general understanding of HTML forms, but did not know all of the required syntax. These clarifying activities are distinct from learning activities, because participants can easily recognize and adapt the necessary code once they find it. Because of this, clarifying uses of the Web are shorter than learning uses.
Searching with synonyms. Participants often used Web search when they were unsure of exact terms. We observed that search works well for this task because synonyms of the correct programming terms often appear in online forums and blogs. For example, one participant used a JavaScript library that he had used in the past but “not very often,” to implement the AJAX portion of the task. He knew that AJAX worked by making requests to other pages, but he forgot the exact mechanism for accomplishing this in his chosen library (named Prototype). He searched for “prototype request”. The researchers asked, “Is ‘request’ the thing that you know you’re looking for, the actual method call?” He replied, “No. I just know that it’s probably similar to that.”
Clarification queries contained more programming language–specific terms than learning queries. Often, however, these terms were not from the correct programming language! Participants often made language analogies: For example, one participant said “Perl has [a function to format dates as strings], so PHP must as well.” Similarly, several participants searched for “javascript thread”. Though JavaScript does not explicitly contain threads, it supports similar functionality through interval timers and callbacks. All participants who performed this search quickly arrived at an online forum or blog posting that pointed them to the correct function for setting periodic timers: setInterval.
Testing copied code (or not). When participants copied code from the Web during clarification uses, it was often not immediately tested. Participants typically trusted code found on the Web, and indeed, it was typically correct. However, they would often make minor mistakes when adapting the code to their needs (e.g., forgetting to change all instances of a local variable name). Because they believed the code correct, they would then work on other functionality before testing. When they finally tested and encountered bugs, they would often erroneously assume that the error was in recently written code, making such bugs more difficult to track down.
Using the Web to debug. Participants also used the Web for clarification during debugging. Often, when a participant encountered a cryptic error message, he would immediately search for that exact error on the Web. For example, one participant received an error that read, “XML Filtering Predicate Operator Called on Incompatible Functions.” He mumbled, “What does that mean?” then followed the error alert to a line that contained code previously copied from the Web. The code did not help him understand the meaning of the error, so he searched for the full text of the error. The first site he visited was a message board with a line saying, “This is what you have:”, followed by the code in question and another line saying, “This is what you should have:”, followed by a corrected line of code. With this information, the participant returned to his code and successfully fixed the bug without ever fully understanding the cause.
Reminders about forgotten details
Even when participants were familiar with a concept, they often did not remember low-level syntactic details. For example, one participant was adept at writing SQL queries, but unsure of the correct placement of a limit clause. Immediately after typing “ORDER BY respTime”, he went online and searched for “mysql order by”. He clicked on the second link, scrolled halfway down the page, and read a few lines. Within ten seconds he had switched back to his code and added “LIMIT 10” to the end of his query. In short, when participants used the Web for reminding about details, they knew exactly what information they were looking for, and often knew exactly on which page they intended to find it (e.g., official API documentation).
Searching for reminders (or not). When participants used the Web for learning and clarification, they almost always began by performing a Web search and then proceeded to view one or more results. In the case of reminders, sometimes participants would perform a search and view only the search result snippets without viewing any of the results pages. For example, when one participant forgot a word in a long function name, a Web search allowed him to quickly confirm the exact name of the function simply by browsing the snippets in the results page. Other times, participants would view a page without searching at all. This is because participants often kept select Web sites (such as official language documentation) open in browser tabs to use for reminders when necessary.
The Web as an external memory aid. Several participants reported using the Web as an alternative to memorizing routinely used snippets of code. One participant browsed to a page within PHP’s official documentation that contained six lines of code necessary to connect and disconnect from a MySQL database. After he copied this code, a researcher asked him if he had copied it before. He responded, “[yes,] hundreds of times,” and went on to say that he never bothered to learn it because he “knew it would always be there.” We believe that in this way, programmers can effectively distribute their cognition (Hollan, Hutchins, & Kirsh, 2000), allowing them to devote more mental energy to higher-level tasks.
STUDY 2: WEB SEARCH LOG ANALYSIS
Do query styles in the real world robustly vary with intent, or is this result an artifact of the particular lab setting (Carter et al., 2008; Grimes, Tang, & Russell, 2007)? To investigate this, we analyzed Web query logs from 24,293 programmers making 101,289 queries about the Adobe Flex Web application development framework in July 2008. These queries came from the Community Search portal on Adobe’s Developer Network Web site. This portal indexes documentation, articles, blogs, and forums by Adobe and vetted third-party sources.
To cross-check the lab study against this real-world data set, we began this analysis by evaluating four hypotheses derived from those findings:
H1: Learning sessions begin with natural language queries more often than reminding sessions.
H2: Users more frequently refine queries without first viewing results when learning than when reminding.
H3: Programmers are more likely to visit official API documentation in reminding sessions.
H4: The majority of reminding sessions start with code-only queries. Additionally, code-only queries are least likely to be refined and contain the fewest number of result clicks.
Method
We analyzed the data in three steps. First, we used IP addresses (24,293 unique IPs) and time stamps to group queries (101,289 total) into sessions (69,955 total). A session was defined as a sequence of query and result-click events from the same IP address with no gaps longer than 6 minutes. This definition is common in query log analysis (e.g., Silverstein et al., 1999).
Second, we selected 300 of these sessions and analyzed them manually. We found it valuable to examine all of a user’s queries, because doing so provided more contextual information. We used unique IP addresses as a proxy for users, and randomly selected from among users with at least 10 sessions; 996 met this criteria; we selected 19. This IP-user mapping is close but not exact: a user may have searched from multiple IP addresses, and some IP addresses may map to multiple users. It seems unlikely, though, that conflating IPs and users would affect our analysis.
These sessions were coded as one of learning, reminding, unsure, or misgrouped. (Because the query log data is voluminous but lacks contextual information, we did not use the clarifying midpoint in this analysis.) We coded a session as learning or reminding based on the amount of knowledge we believed the user had on the topic he was searching for, and as unsure if we could not tell. To judge the user’s knowledge, we used several heuristics: whether the query terms were specific or general (e.g., “radio button selection change” is a specific search indicative of reminding), contents of pages visited (e.g., a tutorial indicates learning), and whether the user appeared to be an expert (determined by looking at the user’s entire search history – someone who occasionally searches for advanced features is likely to be an expert). We coded a session as misgrouped if it appeared to have multiple unrelated queries (potentially caused by a user performing unrelated searches in rapid succession, or by pollution from multiple users with the same IP address).
Finally, we computed three properties about each search session. For details on how each property is computed, see Brandt et al. (2009b).
1. Query type – whether the query contained only code (terms specific to the Flex framework, such as class and function names), only natural language, or both.
2. Query refinement method – between consecutive queries, whether search terms were generalized, specialized, otherwise reformulated, or changed completely.
3. Types of Web pages visited – each result click was classified as one of four page types: Adobe APIs, Adobe tutorials, tutorials/articles (by third-party authors), and forums.
For the final property, 10,909 of the most frequently visited pages were hand-classified (out of 19,155 total), accounting for 80% of all visits. Result clicks for the remaining 8246 pages (20% of visits) were labeled as unclassified.
Results
Out of 300 sessions, 20 appeared misgrouped, and we were unsure of the intent of 28. Of the remaining 252 sessions, 56 (22%) had learning traits and 196 (78%) had reminding traits. An example of a session with reminding traits had a single query for “function as parameter” and a single result click on the first result, a language specification page. An example of a session with learning traits began with the query “preloader”, which was refined to “preloader in flex” and then “creating preloader in flex”, followed by a result click on a tutorial.
We used the Mann-Whitney U test for determining statistical significance of differences in means and the chi-square test for determining differences in frequencies (proportions). Unless otherwise noted, all differences are statistically significant at p < .001.
H1: The first query was exclusively natural language in half of learning sessions, versus one third in reminding sessions (see Table 23.2).
H2: Learning and reminding sessions do not have a significant difference in the proportion of queries with refinements before first viewing results.
H3: Programmers were more likely to visit official API documentation in reminding sessions than in learning sessions (31% versus 10%, see Table 23.3). Notably, in reminding sessions, 42% of results viewed were Adobe tutorials.
Table 23.2 For Hand-Coded Sessions of Each Type, Proportion of First Queries of Each Type (252 Total Sessions).
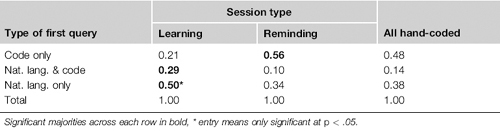
Table 23.3 For Queries in Hand-Coded Sessions of Each Type, Proportion of Result Clicks to Web Sites of Each Type (401 Total Queries).
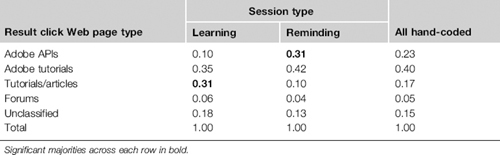
H4: Code-only queries accounted for 51% of all reminding queries. Among all (including those not hand-coded) sessions, those beginning with code-only queries were refined less (μ = 0.34) than those starting with natural language and code (μ = 0.60) and natural language only (μ = 0.51). It appears that when programmers perform code-only queries, they know what they are looking for, and typically find it on the first search.
After evaluating these hypotheses, we performed further quantitative analysis of the query logs. In this analysis, we focused on how queries were refined and the factors that correlated with types of pages visited.
Programmers rarely refine queries, but are good at it
In this data set, users performed an average of 1.45 queries per session (the distribution of session lengths is shown in Figure 23.3). This is notably less than other reports, such as 2.02 (Silverstein et al., 1999). This may be a function of improving search engines, that programming as a domain is well-suited to search, or that the participants were skilled.
Across all sessions and refinement types, 66% of queries after refinements have result clicks, which is significantly higher than the percentage of queries before refinements (48%) that have clicks. This contrast suggests that refining queries generally produces better results.
When programmers refined a query to make it more specialized, they generally did so without first clicking through to a result (see Table 23.4). Presumably, this is because they assessed the result snippets and found them unsatisfactory. Programmers may also see little risk in “losing” a good result when specializing – if it was a good result for the initial query, it ought to be a good result for the more specialized one. This hypothesis is reinforced by the relatively high click rate before performing a completely new query (presumably on the same topic) – good results may be lost by completely changing the query, so programmers click any potentially valuable links first. Finally, almost no one clicks before making a spelling refinement, which makes sense because people mostly catch typos right away.
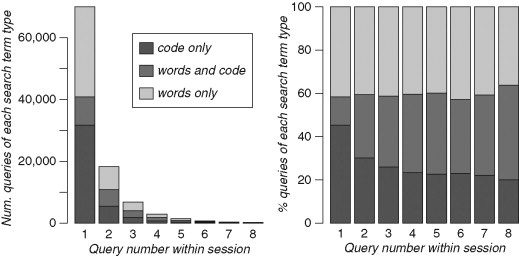
FIGURE 23.3
How query types changed as queries were refined. In both graphs, each bar sums all ith queries over all sessions that contained an ith query (e.g., a session with three queries contributed to the sums in the first three bars). The graph on the left is a standard histogram; the graph on the right presents the same data, but with each bar’s height normalized to 100 to show changes in proportions as query refinements occurred.
Table 23.4 For Each Refinement Type, Proportion of Refinements of That Type Where Programmers Clicked on Any Links Before the Refinement (31,334 Total Refinements).

Users began with code-only searches 48% of the time and natural language searches 38% of the time (see Figure 23.3). Only 14% of the time was the first query mixed. The percent of mixed queries steadily increased to 42% by the eighth refinement, but the percent of queries containing only natural language stayed roughly constant throughout.
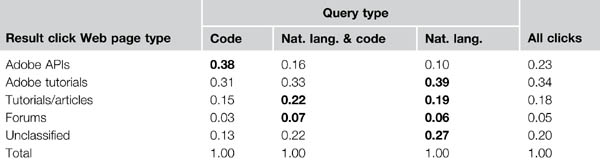
Query type predicts types of pages visited
There is some quantitative support for the intuition that query type is indicative of query intent (see Table 23.5). Code-only searches, which one would expect to be largely reminding queries, are most likely to bring programmers to official Adobe API pages (38% versus 23% overall) and least likely to bring programmers to all other types of pages. Natural-language-only queries, which one would expect to be largely learning queries, are most likely to bring programmers to official Adobe tutorials (39% versus 34% overall).
CONCLUSIONS AND FUTURE WORK
In this chapter, we have seen how many of the fundamental barriers that programmers face (Ko, Myers, & Aung, 2004) can be overcome using Web resources. This research is part of a larger intellectual endeavor to create a psychological account of programming (Détienne, 2001), and to use programming as a petri dish for understanding problem-solving and knowledge work more broadly (Newell & Simon, 1972).
Table 23.5 For Queries of Each Type, Proportion of Result Clicks Leading Programmer to Web Pages of Each Type (107,343 Total Queries). Significant Majorities and Near-Ties Across Each Row in Bold.
Specifically, this chapter illustrated an emerging problem-solving style that uses Web search to enumerate possible solutions. The Web has a substantially different cost structure than other information resources: It is cheaper to search for information, but its diverse nature may make it more difficult to understand and evaluate what is found (Choo, Detlor, & Turnbull, 2000). Programmers – and likely, other knowledge workers – currently lack tools for rapidly understanding and evaluating these possible solutions. Understanding how to build these tools remains an important direction for future work.
In practice, programmers use many resources other than the Web, such as colleagues and books. What is the role these other resources could and do play? This chapter looks exclusively at Web usage; other researchers have similarly examined other information resources individually. (For example, Chong and Siino (2006) examined collaboration between programmers during solo and pair programming.) Future work is needed to compare the trade-offs of these different information resources.
For programmers to use online resources, there must be people who create these resources. What motivates individuals to contribute information, such as tutorials and code snippets, and how can technology make sharing easier and more common? For example, is it possible to “crowdsource” finding and fixing bugs in online code? Can we improve the experience of reading a tutorial by knowing how the previous 1000 readers used that tutorial? These are just some of the many open questions in this space.
Finally, how does the increasing prevalence and accessibility of Web resources change the way we teach people to program? With ready access to good examples, programmers may need less training in languages, frameworks, and libraries, and greater skill in formulating and breaking apart complex problems. It may be that programming is becoming less about knowing how to do something and more about knowing how to ask the right questions.
Acknowledgments
We thank Rob Liebscher and Diana Joseph at Adobe Systems for their help in acquiring the Web query logs; Beyang Liu for his help in coding video data from our lab study; Intel for donating computers for this research; and all of the study participants for sharing their insights. This research was supported in part by NSF Grant IIS-0745320.
This work is based on an earlier work: “Two Studies of Opportunistic Programming: Interleaving Web Foraging, Learning, and Writing Code,” in Proceedings of the 27th International Conference on Human Factors in Computing Systems, © ACM, 2009. http://doi.acm.org/10.1145/1518701.1518944.