
CHAPTER
10
Programming by a sample
Leveraging Web sites to program their
underlying services
Björn Hartmann,1 Leslie Wu,2 Kevin Collins,2 Scott R. Klemmer2
1University of California, Berkeley
2Stanford University
ABSTRACT
Many popular Web sites offer a public API that allows Web developers to access site data and functionality programmatically. The site and its API offer two complementary views of the same underlying functionality. This chapter introduces d.mix, a Web development tool that leverages this site-to-service correspondence to rapidly create Web-service based applications. With d.mix, users browse annotated Web sites and select elements on the page they would like to access programmatically. It then generates code for the underlying Web service calls that yield those elements. This code can be edited, executed, and shared in a wiki-based hosting environment. The application d.mix leverages prexisting Web sites as example sets and supports rapid composition and modification of examples.
INTRODUCTION
Web hosting and search have lowered the time and monetary costs of disseminating, finding, and using application programming interfaces (APIs). The number and diversity of application building blocks that are openly available as Web services is growing rapidly (Papazoglou et al., 2007). Programmableweb.com lists 4452 mashups leveraging 1521 distinct APIs as of November 2009 (the most popular being Google Maps, Flickr, YouTube, and Amazon). These APIs provide a rich selection of interface elements and data sources. Many serve as the programmatic interface to successful Web sites, where the site and its API offer complementary views of the same underlying functionality. In such cases, the Web site itself is often a complete example of the functionality that can be realized with its associated API. This chapter describes how modeling the correspondence between site and service can enable a Web site to serve as an automatic code example corpus for its service API.
Many small Web applications are created opportunistically, leveraging elements from third-party Web services (Chapter 23). These applications, commonly known as mashups, are created by amateurs who are learning the ropes, by designers creating a rapid prototype, by hobbyists, and by professionals creating in-house applications. A broad shift of this paradigm is that the designer’s effort and creativity are reallocated: less time is spent building an application up brick by brick, while more time and ingenuity is spent finding and selecting components, and then creating and shaping the “glue” between them (Hartmann et al., 2008). Automatically generating relevant examples has the potential to significantly speed up component selection and integration and lower the expertise threshold required to build software.
Integrating site and service
To enable rapid authoring of API-based Web applications, this chapter introduces d.mix (see Figure 10.1), a Web-based design tool with two notable attributes. The first is a technique for users to compose Web applications by browsing existing sites, visually specifying elements to borrow from them, and combining and modifying them. We call this technique sampling. Sampling is enabled by a programmable proxy system providing a site-to-service map that establishes the correspondence between elements shown on a site and the Web service calls needed to replicate these elements programmatically. Second, a server-side active wiki hosts scripts generated by the proxy. This active wiki provides a configuration-free environment for authoring and sharing of applications. By virtue of displaying the actual underlying code to users, d.mix also allows developers with sufficient technical expertise to drill down into source code as needed.
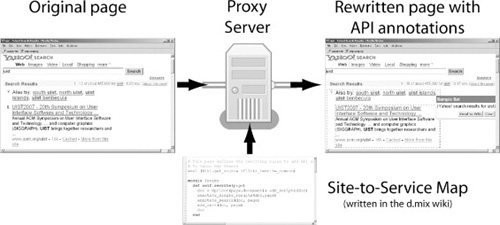
FIGURE 10.1
With d.mix, users browse Web sites through a proxy that marks API-accessible content. Users select marked elements they wish to copy. Through a site-to-service map, d.mix composes Web service calls that yield results corresponding to the user’s selection. This code is copied to the d.mix wiki for editing and hosting.
Foraging for examples
As the number and size of programming libraries increase, locating and understanding documentation and examples is playing an increasingly prominent role in developers’ activities (Stylos & Myers, 2006). To aid users in foraging for example code, d.mix co-locates two different kinds of information on one page: examples of what information a Web site offers; and information about how one would obtain this information programmatically.
Because problems often cut across package and function boundaries, example-based documentation provides value by aiding knowledge crystallization (gathering of relevant data and distinguishing it from irrelevant data) and improving information scent (the cues that describe the likely utility of the provided information) (Pirolli & Card, 1999). For this reason, examples and code snippets are a popular resource (see Chapter 23). This approach of documentation through examples complements more traditional, index-based documentation. d.mix enables developers to dynamically generate code snippets for a Web service API as they browse the canonical example of its functionality: the Web site itself.
The approach used by d.mix draws on prior work in programming by example, also known as programming by demonstration (Cypher, 1993; Lieberman, 2001; Nardi, 1993). In these systems, the user demonstrates a set of actions on a concrete example – such as a sequence of image manipulation operations – and the system infers application logic through generalization from that example. The logic can then be reapplied to other similar cases.
Although d.mix shares much of its approach with programming-by-example systems, it differs in the procedure for generating examples. Instead of specifying logic by demonstrating novel examples, with d.mix, designers choose and parameterize found examples. In this way, the task is more one of programming by example modification, which Nardi highlights as a successful strategy for end user development (Nardi, 1993). Modification of a working example also speeds development because it provides stronger scaffolding than starting from a blank slate (Chapter 23).
The rest of this chapter is structured as follows. We first introduce the main interaction techniques of d.mix through a scenario. Subsequently, we explain the d.mix implementation. We then describe applications we created with d.mix, feedback from Web professionals, and an initial laboratory study. We conclude with a discussion of related research and commercial systems, limitations of the current implementation, and an outlook to future work.
HOW TO PROGRAM BY A SAMPLE
A scenario will help introduce the main interaction techniques. Jane is an amateur rock climber who frequently travels to new climbing spots with friends. Jane would like to create a page that serves as a lightweight Web presence for the group. The page should show photos and videos from their latest outings. She wants content to update dynamically so she doesn’t have to maintain the page. She is familiar with HTML and has some JavaScript experience, but does not consider herself an expert programmer.
Jane starts by browsing the photo and video sharing sites her friends use. David uses the photo site Flickr and marks his pictures with the tag “climbing”. Another friend also uses Flickr, but uses image sets instead of tags. A third friend shares her climbing videos on the video site YouTube.
To start gathering content, Jane opens David’s Flickr profile in her browser and navigates to the page listing all his tags. She then presses the sample this button in her browser bookmark bar (Figure 10.2a). This reloads the Flickr page, adding dashed borders around the elements that she can sample.

FIGURE 10.2
She right-clicks on the tag “climbing”, to invoke a context menu of possible actions for the selected screen element. In this case, there is only one possible action: to copy the set of images that David has tagged with “climbing” (Figure 10.2b).
A floating dialog asks her to specify which page on the d.mix wiki she would like to send the sampled content to (Figure 10.2c). This dialog permits her to either create new pages or add content to existing pages. She enters a new name, “ClimbersPortal”, to create a new page.
Her browser then loads the newly created page in the d.mix programmable wiki (Figure 10.2d). The rendered view now shows the specified images she sampled; the source view of the page contains the corresponding API call to the Flickr Web service.
Continuing her information gathering, Jane samples Sam’s climbing photo set on Flickr. Her wiki page now displays both David’s photos and several images from Sam. Jane would like the page to display only the latest three images from each person. She right-clicks on Sam’s images to invoke a property sheet, a graphical field editor for object attributes, showing that the content came from a Flickr photo set (Figure 10.2e). This sheet gives parameters for the user ID associated with the set and for the number of images to show. Changing the parameters reloads the page and applies the changes.
Jane then opens Karen’s YouTube video page. For Karen’s latest video, d.mix offers two choices: copy this particular file, or copy the most recent video in Karen’s stream. Because Jane wants the video on her page to update whenever Karen posts a new file, she chooses the latter option.
Next, Jane would like to lay out the images and add some text. In the d.mix wiki, she clicks on “edit source,” which displays an HTML document, in which each of the three samples she inserted corresponds to a few lines of Ruby script, enclosed by a structuring <div> tag (Figure 10.2f). She adds text and a table around the images. Remembering that David also sometimes tags his images with “rocks”, she modifies the query string in the corresponding script accordingly to broaden the search criteria.
When she is satisfied with the rendered view of her active wiki page, Jane emails the URL of the wiki page to her group members to let them see the page (Figure 10.2g).
IMPLEMENTATION
In this section, we describe d.mix’s implementation for sampling, parametric copying, editing, and sharing.
“Sample this” button rewrites pages
Two buttons are present in d.mix, sample this and stop sampling, that can be added to a browser’s bookmark bar to enable or disable sampling mode (Figure 10.3). Sample this is implemented as a bookmarklet – a bookmark containing JavaScript instead of a URL – that sends the current browser location to the d.mix server. The browser is then redirected to load a page through the d.mix proxy which combines the target site’s original Web markup with annotations found using the site-to-service map (see Figure 10.1). The map contains information about the correspondence between HTML elements on the current page and API calls that can retrieve that same content programmatically.
FIGURE 10.3
While it would be straightforward for site operators to provide the site-to-service map through extra markup in their page source, the original Web site need not provide any support for d.mix. The active wiki maintains a collection of site-to-service maps, contributed by knowledgeable developers. These maps describe the programmatically accessible components associated with a particular set of URLs (see Figure 10.4). Each map defines a partition of a Web site into page types through regular expression matches on URLs. For each page type, the map then defines the correspondence between the markup found on a page and the API method invocations needed to retrieve the equivalent content programmatically. It does so by searching for known markup patterns — using Xpath1 and CSS2 selectors — and recording the metadata that will be passed to Web services as parameters, such as a user or photo ID, a search term, or a page number.
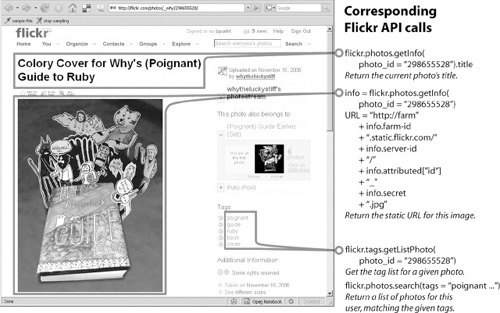
FIGURE 10.4
The site-to-service map defines a correspondence between HTML elements and Web service API calls. The shown example highlights this mapping for three items on a Flickr photo page.
For example, on Flickr.com, pages with the URL pattern http://flickr.com/photos/<username>/tags contain a list of image tags for a particular user, displayed as a tag cloud. Programs can access a user’s tags by calling the API method flickr.tags.getListUser and passing in a user ID. Similarly, photos corresponding to tags for a given user can be retrieved by a call to flickr.photos.Search.
When the user is in sampling mode, d.mix’s programmable HTTP proxy rewrites the viewed Web page, adding JavaScript annotations. These annotations serve two functions. First, d.mix uses the site-to-service map to derive the set of components that can be sampled on the current page. Second, d.mix’s annotation visually augments those elements with a dashed border as an indication to the user.
In the other direction, the stop sampling button takes a URL of a proxy page, extracts the nonproxy URL of the target site from it, and redirects the browser to this page, ending access through the proxy.
d.mix is implemented in the Ruby programming language. We chose Ruby to leverage its metaprogramming libraries for code generation and dynamic evaluation, and for MouseHole,3 a Ruby-based HTTP proxy. Largely for expediency, the d.mix research prototype also uses Ruby as the user-facing scripting language inside the d.mix active wiki. One could also use a different scripting language for the active wiki, such as PHP.
Annotating Web pages
HTML elements (e.g., an image on a photo site) are annotated with d.mix with a set of potential actions. It presents these options to the user in a context menu. Each menu entry corresponds to a Ruby script method. The site-to-service mapping uses elements’ class and ID to determine which options are available.

FIGURE 10.5
As an example, consider a tag cloud page found on Flickr. All tags are found inside the following structure:
<pi d="TagCloud">
<a href="…">Tag1</a>
<a href ="…">Tag2</a>…
</p>
The site-to-service mapping script to find each element and annotate it is:
@user_id=doc.at("input[@name=‘w’]")["value"]
doc.search("//p[@i d=‘TagCloud’]/a").each do |link|
tag =link.inner_html
src = generate_source(:tags=>tag, :user_id=>@user_id)
annotations += context_menu(link, "tag description", src)
end
In this example, the Ruby code makes use of an HTML parser library, Hpricot,4 to extract the user’s ID from a hidden form element. It then iterates over the set of links within the tag cloud, extracts the tag name, generates source code by parameterizing a source code stub for flickr.photos.search, and generates the context menu for the element.
The d.mix mapping code scrapes Web pages as the developer visits them in order to extract the needed information for code generation. Scraping can be brittle because matching expressions can break when site operators change class or ID attributes of their pages. Still, scraping is common practice in Web development (Hartmann, Doorley, & Klemmer, 2008) as it is often the only technique for extracting data without the site operator’s cooperation. An important design decision in d.mix is to scrape at authoring-time, when the designer is creating pages such as the Flickr-and-YouTube mashup in the scenario. By scraping parameters first, d.mix’s user-created pages can then make API calls at runtime, which tend to be more stable than the HTML format of the initial example pages.
Authoring and maintaining the site-to-service map
The keystone of the sampling approach is the site-to-service map. For d.mix to be aware of the functionality of a Web service, a corresponding map must be created and maintained. For the d.mix research prototype, the authors implemented the necessary rewrite and code generation rules for three popular sites (see Figure 10.6). Though these rules are relatively concise, authoring them requires expertise with DOM5 querying. The appeal of the sampling approach is that the one-time – or at least infrequent – effort of creating the map is hopefully very small relative to the recurring benefits reaped every time a user creates a new site with d.mix.
Additionally, we see four approaches a production tool could employ to ease the creation of site-to-service maps. First, a declarative, domain-specific language could be devised to express mappings. Second, visual DOM selection tools like Solvent6 could enable markup selection by demonstration. Third, given such direct manipulation tools, one could build and maintain the map through crowdsourcing, splitting the modeling task into many small subtasks (e.g., identifying a single API call correspondence) that can be completed through volunteer efforts. The success of community-created sites like Wikipedia demonstrates that large-scale volunteer effort can create significant works (Krieger, Stark, & Klemmer, 2009). Finally, the map may not have to be authored by users at all – Web companies may have incentive to publish them themselves. Companies expose their Web APIs because they want them to be used. Since these companies designed both their site and their API, it would be relatively straightforward for them to embed site-to-service map annotations directly into the generated HTML pages, without requiring an intermediate proxy.

FIGURE 10.6
The site-to-service map implemented by the authors supports three services.
Server-side active wiki hosts and executes script
In d.mix’s active wiki, developers can freely mix text, HTML, and CSS to determine document structure, as well as Ruby script to express program logic. The wiki format offers two primary benefits. First, the preconfigured, server-side environment enables rapid experimentation with code and sharing of created pages. Second, the wiki offers the opportunity to view, copy, and include any existing wiki page to leverage the practice of programming by example modification (Nardi, 1993). Like other wiki environments, the active wiki also offers page versioning.
When a d.mix user creates a new page that remixes content from multiple data sources, another end user can just as easily remix the remix. Currently, this involves copying and pasting the generated code from one wiki page to another. To further lower the threshold for reuse, each wiki page itself could contain an automatically generated site-to-service map that allows sampling elements from wiki pages in the same manner users sample from other supported sites. Users of d.mix can also contribute new site-to-service maps for their own Web sites, or submit fixes to mappings as Web sites evolve.
When a developer sends code to the wiki through sampling, she has to provide a page name that will receive the generated code. For a new name, a page containing the generated code is created. For an existing name, the generated code is appended to the existing page. The browser then displays a rendered version of the wiki page, which includes executing the specified Web API calls (see Figure 10.2d). In this rendered version, HTML, CSS, and JavaScript take effect, the embedded Ruby code is evaluated, and its output is inserted into the page.
To switch from the rendered view to the source view containing Web markup and Ruby code, a user can click on the edit button, as in a standard wiki. The markup and snippets of script are then shown in a browser-based text editor, which provides syntax highlighting and line numbering. As browser-based development environments such as Mozilla Bespin7 mature, we expect that the functionality and usability gap between such Web-based editors and integrated development environments on the desktop will narrow. In d.mix wiki code, snippets of Ruby are encapsulated in a reserved tag <%= #code %> to distinguish them from plain text. Clicking on the save button saves the document source as a new revision, and redirects the user back to the rendered version of the wiki page.
Pasted material can be parameterized and edited
In comparison to a standard copy-and-paste of Web content, the notable advantage of d.mix’s parametric copy is that it copies a richer representation of the selected data. This allows the arguments of each API call to be changed after pasting. The d.mix wiki offers graphical editing of parameters through property sheets to enable a level of customization without having to modify the generated source code directly. The structure of these property sheets, implemented as layers floating above the rendered page in JavaScript, is determined during the code generation step. In our current implementation, property editors are generated for each argument of each Web service API call. It may be valuable to provide additional parameters such as formatting commands in the future.
As a test of the complexity of code that can be written in a wiki environment, we implemented all site-to-service mapping scripts as wiki pages. This means that the scripts used to drive the programmable proxy and thus create new wiki pages are, themselves, wiki pages. To allow for modularization of code, a wiki page can import code or libraries from other wiki pages, analogous to “#include” in the C language.
The generated code makes calls into d.mix modules that broker communication between the active wiki script and the Web services. For example, users’ Ruby scripts often need to reference working API keys to make Web service calls. Modules in d.mix provide a default set of API keys so that users can retrieve publicly accessible data from Web services without having to obtain personal keys. Although using a small static number of Web API keys would be a problem for largescale deployment (many sites limit the number of requests one can issue), we believe our solution works well for prototyping and for deploying applications with a limited number of users.
ADDITIONAL APPLICATIONS
In this section, we review additional applications of d.mix beyond the use case demonstrated in the scenario.
Existing Web pages can be virtually edited
The same wiki-scripted programmable HTTP proxy that d.mix employs to annotate API-enabled Web sites can also be used to remix, rewrite, or edit existing Web pages to improve usability, aesthetics, or accessibility, enabling a sort of recombinant Web. As an example, we have created a rewriting script on our wiki that provides a connection between the event-listing site Upcoming8 and the calendaring site 30 Boxes.9 By parsing an event’s microformat on the site and injecting a graphical button, users can copy events directly to their personal calendar. Because this remix is hosted on our active wiki, it is immediately available to any Web browser.
Another example is reformatting of Web content to fit the smaller screen resolution and lower bandwidth of mobile devices. Using d.mix, we wrote a script that extracts only essential information – movie names and show times – from a cluttered Web page. This leaner page can be accessed through its wiki URL from any mobile phone browser (see Figure 10.7). Note that the reformatting work is executed on the server and only the small text page is transmitted to the phone. The server-side infrastructure of d.mix made it possible for one author and a colleague to develop, test, and deploy this service in 30 minutes. In contrast, client-side architectures, such as Greasemonkey,10 do not work outside the desktop environment. The Highlight system in Chapter 6 presents an alternative architecture for reformatting Web sites for mobile consumption.
Web applications to monitor and control physical spaces
The scenario presented in this chapter focused on data-centric APIs from successful Web sites with large user bases. Though such applications present the dominant use case of mashups today, we also see opportunity for d.mix to enable development of situated ubiquitous computing applications. A wide variety of ubicomp sensors and actuators are equipped with embedded Web servers and publish their own Web services. This enables d.mix’s fast iteration cycle and “remix” functionality to extend into physical space. To explore d.mix design opportunities in Web-enabled ubicomp applications, we augmented two smart devices in our laboratory to support API sampling: a camera that publishes a video feed of lab activity and a network-controlled power outlet. Combining elements from both servers, we created a wiki page that allows remote monitoring of lab occupancy to turn off room lights if they were left on at night (see Figure 10.8).
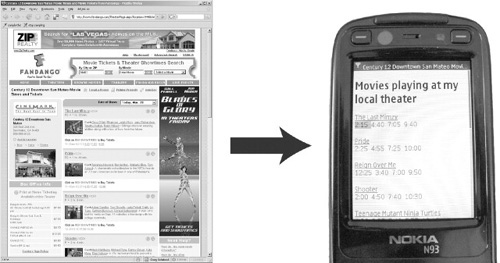
FIGURE 10.7
The rewriting technology in d.mix can be used to tailor content to mobile devices. Here, essential information is extracted from a movie listings page.

FIGURE 10.8
An example of a d.mix ubiquitous computing mashup: Web services provide video monitoring and lighting control for an office.
More important than the utility of this particular example is the architectural insight gained: because the Web services of the camera and power outlet were open to us, we were able to embed API annotations directly into the served Web pages. This proof of concept demonstrated that Web service providers can integrate support for API sampling into their pages, obviating the need for a separate site-to-service map on the d.mix server.
FEEDBACK FROM WEB PROFESSIONALS
As d.mix matured, we met weekly with Web designers to obtain feedback for a period of 8 weeks. Some of these meetings were with individuals, others were with groups; the largest group had 12 members. Informants included attendees of Ruby user group meetings, Web developers at startup companies in Silicon Valley, and researchers at industrial research labs interested in Web technologies.
Informants repeatedly raised scaling concerns for mashups. One informant noted that many Web services impose limits on how many API calls a user can make in a given amount of time. This feedback suggests that social norms of acceptable use may place a stronger limit on the number of d.mix applications and users a d.mix server can support than available processing power.
As the reach of mashups expands, informants were interested in how users and developers might find relevant services. Several informants noted that while services are rapidly proliferating, there is a dearth of support for search and sensemaking in this space. Prior work on software customization (Mackay, 1990; MacLean et al., 1990) has explored the social side of end-user–created software, and recent work on CoScripter (see Chapter 5) has made strides in enabling sharing of end user browser automations. Additional efforts in this direction are a promising avenue for future work.
Informants saw the merits of extending the d.mix approach beyond PC-based browsers. A researcher at an industrial research lab expressed interest in creating an “elastic office,” where Web-based office software is adapted for mobile devices. This focus on mobile interaction kindled our interest in using a mashup approach to tailoring Web applications for mobile devices.
Informants also raised the broader implications of a mashup approach to design. A user experience designer and a platform engineer at the offices of a browser vendor raised end user security as an important issue to consider. At another Web startup, a Web developer brought our attention to the legal issues involved in annotating sites in a public and social way.
Our recruiting method yielded informants with more expertise than d.mix’s target audience; consequently, they asked questions about the complexity ceiling (Myers, Hudson, & Pausch, 2000) of the tool. In a group meeting with 12 Web designers and developers, informants expressed interest in creating annotations for a new API, and asked how time-consuming this process was. We explained that annotation in d.mix requires about 10 lines of (complex) code per HTML element; this was met with a positive response. For future work informants suggested that d.mix could fall back to HTML scraping when sites lack APIs.
EVALUATION
Our evaluation of d.mix was guided by the following questions:
1. Is the sampling approach embodied in d.mix accessible to Web developers? Is the mental model of sampling and modifying what was sampled clear?
2. Is the sampling approach useful? Can pages of sufficient complexity and value be created with d.mix?
3. What is the usability of the current interaction techniques?
To answer these questions, we conducted a first-use evaluation study with eight participants: seven were male, one female; their ages ranged from 25 to 46 years. We recruited participants with at least some Web development experience. All participants had some college education; four had completed graduate school. Four had a computer science education; one was an electrical engineer; three came from the life sciences. Recruiting developers with Ruby experience proved difficult – only four participants had more than a passing knowledge of this scripting language. Everyone was familiar with HTML; six participants were familiar with JavaScript; and six were familiar with at least one other scripting language. Four participants had some familiarity with Web APIs, but only two had previously attempted to build a mashup. Our participants thus match our target audience along the dimensions of familiarity and expertise with Web development practices although they were more expert in general engineering and computer science.
Study protocol
Study sessions took approximately 75 minutes. We wrote a site-to-service mapping for three Web sites – Yahoo Web search, Flickr photo sharing, and YouTube video sharing. For each site, d.mix supported annotations for a subset of the site’s API (see Figure 10.6). For example, with Flickr, participants could perform full-text or tag searches and copy images with their metadata, but they could not extract user profile information. Participants were seated at a single-screen workstation with a standard Web browser. We first demonstrated d.mix’s interface for sampling from Web pages, sending content to the wiki, and editing those pages. Next, we gave participants three tasks to perform.
The first task tested the overall usability of our approach – participants were asked to sample pictures and videos, send that content to the wiki, and change simple parameters of pasted elements, such as how many images to show from a photo stream. The second design task was similar to our scenario – it asked participants to create an information dashboard for a magazine’s photography editor. This required combining data from multiple users on the Flickr site and formatting the results. The third task asked participants to create a meta-search engine – using a text input search form, participants should query at least two different Web services and combine search results from both on a single page. This task required generalizing a particular example taken from a Web site to a parametric form by editing the source code d.mix generated. Figure 10.9 shows two pages produced by one participant, who was Web design–savvy but a Ruby novice. After completing the tasks, participants filled out a qualitative questionnaire on their experience and were debriefed verbally.
Successes
On a high level, all participants understood and successfully used the workflow of browsing Web sites for desired content or functionality, sampling from the sites, sending sampled items to the wiki, and editing items. Given that less than one hour of time was allocated to three tasks, it is notable that all participants successfully created pages for the first two tasks. In task 3, five participants created working meta-search engines (see Figure 10.9). However, for three of the participants without Ruby experience, its syntax proved a hurdle; they only partially completed the task.
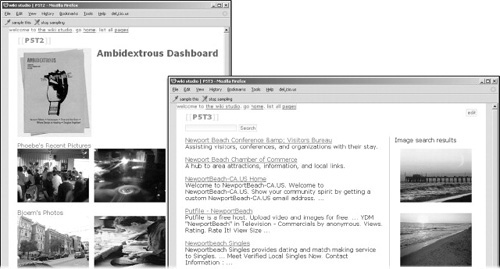
FIGURE 10.9
Two pages a participant created during our user study. Left image: Information dashboard for a magazine editor, showing recent relevant images of magazine photographers. Right image: Meta-search engine showing both relevant Web pages and image results for a search term.
Our participants were comfortable with editing the generated source code directly, without using the graphical property editor. Making the source accessible to participants allowed them to leverage their Web design experience. For example, multiple participants leveraged their knowledge of CSS to change formatting and alignment of our generated code to better suit their aesthetic sensibility. Copy and paste within the wiki also allowed participants to reuse their work from a previous task in a later one.
In their post-test responses, participants highlighted three main advantages that d.mix offered compared to their existing toolset: elimination of setup and configuration barriers, enabling of rapid creation of functional Web application prototypes, and lowering of required programming expertise.
First, participants commented on the advantage of having a browser-based editing environment. There was “minimum setup hassle,” since “you don’t need to set up your own server.” One participant’s comments sum up this point succinctly: “I don’t know how to set up a Ruby/API environment on my Web space. This lets me cut to the chase.” Second, participants also highlighted the gain in development speed. Participants perceived code creation by selecting examples and then modifying them to be faster than writing new code or integrating third-party code snippets. Third, participants felt that d.mix lowered the expertise threshold required to work with Web APIs because they were not required to search or understand an API first. A Web development consultant saw value in d.mix because he felt it would enable his clients to update their sites themselves.
Shortcomings
We also discovered a range of challenges our participants faced when working with d.mix. Universally, participants wished for a larger set of supported sites. This request is not trivial because creating new annotations requires manual programming effort. However, we believe the amount of effort is reasonable when amortized over a large number of users. Other shortcomings fall into four categories. First, inconsistent ways in which d.mix annotated pages caused confusion about how to sample from a given page. Second, participants had difficulty switching between multiple languages interspersed in a single wiki page. Third, documentation and error handling in the wiki was insufficient compared to other tools. Fourth, wiki-hosted applications may not scale well beyond prototypes for a few users.
Inconsistent models for sampling
Participants were confused by limitations in what source elements were “sampling-aware.” For example, to specify a query for a set of Flickr images in d.mix, the user currently must sample from the link to the image set, not the results. This suggests that the d.mix architecture should always enable sampling from both the source and from the target page. Also, where there is a genuine difference in effect, distinct highlighting treatments could be used to convey this.
Participants complained about a lack of visibility as to whether a given page would support sampling or not. Since rewriting pages through the d.mix proxy introduces a page-load delay, participants browsed the Web sites normally, and only turned on the sampling proxy when they had found elements they wished to sample. Only after this action were they able to find out whether the page was enhanced by d.mix. One means of addressing this shortcoming is to provide feedback within the browser as to whether the page may be sampled; another would be to minimize the latency overhead introduced through the proxy so that users can always leave their browser in sampling mode.
Multi-language scripting
Dynamic Web pages routinely use at least three different notation systems: HTML for page structuring, JavaScript for client-side interaction logic, and a scripting language, such as PHP, Python, or Ruby, for server-side logic. This mix of multiple languages in a single document is a general source of both flexibility and confusion for Web developers. The d.mix implementation exacerbated this complexity. An interaction between Ruby scripts and generated HTML tags wrapping these scripts prevented users from adding Ruby variables inside the attributes of the wrapping tag, a non-obvious restriction that confused users.
Lack of documentation and error handling
Many participants requested more complete documentation. One participant asked for more comments in the generated code explaining the format of API parameters. A related request was to provide structured editors inside property sheets that offered alternative values and data validation.
Participants also commented that debugging their wiki pages was hard, since syntax and execution errors generated “incomprehensible error messages.” The current version of d.mix catches and displays Ruby exceptions along with the source code that generated the exception, but it does not interpret or explain the exceptions. Debugging is further hampered by the absence of the common read-eval-print command line for inspecting state and experimenting with changes in dynamic languages.
How to deploy applications outside the wiki environment?
Participants valued the active wiki for its support of rapid prototyping. However, because of a perceived lack of security, robustness, and performance, participants did not regard the wiki as a viable platform for larger deployment. One participant remarked, “I’d be hesitant to use it for anything other than prototyping” and two others expressed similar reservations.
RELATED WORK
Existing work in three areas supports d.mix: tools for end user modification of the Web, tools that lower the threshold of synthesizing new Web applications, and research on locating, copying, and modifying program documentation and examples. We discuss each area in turn.
Tools for end user modification of Web experiences
Greasemonkey, Chickenfoot (Chapter 3), and CoScripter (Chapter 5) are client-side Firefox browser extensions that enable users to rewrite Web pages and automate browsing activities.
Greasemonkey enables the use of scripts that alter Web pages as they are loaded; users create these scripts manually, generally using JavaScript to modify the page’s Document Object Model. Chickenfoot builds on Greasemonkey, contributing an informal syntax based on keyword pattern matching; the primary goal of this more flexible syntax was to enable users with less scripting knowledge to create scripts. CoScripter further lowers the threshold, bringing to the Web the approach of creating scripts by generalizing the demonstrated actions of users (an approach pioneered by EAGER (Cypher, 1991; Myers, 1993)).
Of this prior work, CoScripter and d.mix are the most similar; d.mix shares with CoScripter the use of programming-by-demonstration techniques and the social-software mechanism of sharing scripts server-side on a wiki page. There are several important ways that d.mix distinguishes itself. First, d.mix stores and executes all code on a server. In this way, d.mix takes an infrastructure service approach to support end user remixing of Web pages. This approach obviates the need for users to install any software on their client machine – the increasing use of the Web as a software platform provides evidence as to the merit of this approach. Second, d.mix generates and stores API calls as its underlying representation. Chickenfoot and CoScripter focus on automating Web browsing and rewriting Web pages using the DOM in the page source – they do not interact with Web service APIs directly. Third, CoScripter shields users from the underlying code representation. The approach used by d.mix is more akin to Web development tools, such as Adobe’s Dreamweaver HTML editor,11 which use visual representations when they are expedient yet also offer source code editing. Often, experts can perform more complex tasks by directly editing the source code; it also avoids some of the “round-trip” errors that can arise when users iteratively edit an intermediate representation.
Tools for end user synthesis of Web experiences
In the second category, there are several tools that lower the expertise threshold required to create Web applications that synthesize data from multiple pre-existing sources. Most notably, Yahoo! Pipes,12 Kapow,13 and Marmite (Wong & Hong, 2007) employ a data flow approach for working with Web services.
Yahoo! Pipes draws on the data flow approach manifest in Unix pipes, introducing a visual node-and-link editor for manipulating Web data sources. It focuses on visually rewriting RSS feeds. Kapow offers a desktop-based visual editing environment for creating new Web services by combining data from existing sites through API calls and screen scraping. Services are deployed on a remote “mashup server.” The main difference between these systems and d.mix is that Kapow and Pipes are used to create Web services meant for programmatic consumption, not applications or pages intended directly for users.
The Marmite browser extension offers a graphical language for sequentially composing Web service data sources and transformation operations; the interaction style is somewhat modeled after Apple’s Automator14 system for scripting desktop behaviors. Marmite combines a visual dataflow language for expressing data transformations with a spreadsheet view, which shows the current data set at a given step. The user experience benefit of this linked view is an improved understanding of application behavior. Unlike d.mix, Marmite applications run client side, and cannot be shared as easily. An additional distinction is that the Marmite programming model is one of starting from a blank slate, whereas d.mix’s is based on example modification. Clearly, both approaches have merit, and neither is globally optimal. A challenge of composition, as the Marmite authors note, is that users have difficulty “knowing what operation to select” – we suggest that the direct manipulation embodied in d.mix’s programming-by-demonstration approach ameliorates this gulf-of-execution (Hutchins, Hollan, & Norman, 1985) challenge.
IBM’s QEDWiki (now part of IBM Mashup Center)15 uses a widget-based approach to construct Web applications in a hosted wiki environment. This approach suggests two distinct communities – those that create the widget library elements, and those that use the library elements – echoing prior work on a “tailoring culture” within Xerox Lisp Buttons (MacLean et al., 1990). QEDWiki and d.mix have a shared interest in supporting different “tiers” of development, with two important distinctions. First, d.mix does not interpose the additional abstraction of creating graphical widgets; with d.mix, users directly browse the source site as the mechanism for specifying interactive elements. Second, d.mix better preserves the underlying modifiability of remixed applications by exposing script code on demand.
Finding and appropriating documentation and code
The literature shows that programmers often create new functionality by finding an example online or in a source repository (Fairbanks, Garlan, & Scherlis, 2006; Hartmann, Doorley, & Klemmer, 2008; Kim et al., 2004) – less code is created tabula rasa than might be imagined. Recent research has begun to more fully embrace this style of development. The Mica (Stylos & Myers, 2006) and Assieme (Hoffmann, Fogarty, & Weld, 2007) systems augment existing Web search with tools specifically designed for finding API documentation and examples. Although Mica, Assieme, and d.mix all address the information foraging issues (Pirolli & Card, 1999) involved in locating example code, their approaches are largely complementary.
Several tools have offered structured mechanisms for deeply copying content. Most related to d.mix, Citrine (Stylos, Myers, & Faulring, 2004) introduced techniques for structured copy and paste between desktop applications, including Web browsers. Citrine parses copied text, creating a structured representation that can be pasted in rich format, for example, as a contact record into Microsoft Outlook. The idea of structured copy is extended by d.mix into the domain of source code.
In other domains, Hunter Gatherer (schraefel et al., 2002) aided in copying Web content; clip, connect, clone enabled copying Web forms (Chapter 8); and WinCuts (Tan, Meyers, & Czerwinski, 2004) and Façades (Stuerzlinger, Chapuis, Phillips, & Roussel, 2006) replicate regions of desktop applications at the window management level. Broadly speaking, d.mix differs from this prior work by generating code that retrieves content from Web services rather than copying the content itself.
LIMITATIONS AND FUTURE WORK
The primary concern of this chapter is an exploration of authoring by sampling. There are security and authentication issues that a widely released tool would need to address. Most notably, the current d.mix HTTP proxy does not handle cookies of remote sites as a client browser would. This precludes sampling from the “logged-in Web” – pages that require authentication beyond basic API keys. Extending d.mix to the logged-in Web comprises two concerns: sampling from pages that require authentication to view, and then subsequently performing authenticated API calls to retrieve the content for remixed pages. To sample from logged-in pages, both client-side solutions (e.g, a browser extension that forwards a full DOM to d.mix to be rewritten) and server-side solutions (e.g., by utilizing a “headless” browser like Crowbar16) are possible. To perform API calls authenticated with private tokens, the private variable mechanism of CoScripter (Chapter 5) could be adapted. Implementation of private data would also require the addition of access permissions through user accounts to the d.mix wiki.
A second limitation is that using d.mix is currently limited to sites and types of content that are amenable to Web scraping. Scraping is only reliable if the site generates static HTML, as opposed to HTML with AJAX, which modifies page content dynamically based on state, or Flash, which does not offer any ability to inspect its content. In addition, the type of content that users can sample also has to be a static element of the page DOM. We have not yet researched whether a sampling approach could be used to reuse dynamic page aspects like animations or interaction patterns.
Third, d.mix makes a fundamental assumption that API and Web site mirror each other, and that the site provides good coverage of possible API calls. This is not always the case. For example, Web developers have used the Google Maps API to create more sophisticated visualizations than the Google Maps site offers. Conversely, not all content on a site may be accessible programmatically. The Google site offers browsing of the entire result set for a given query, whereas the current API only returns a maximum of 60 matches. A comprehensive tool should offer support both for working with content that is accessible through APIs and content that is not (Hartmann, Doorley, & Klemmer, 2008); d.mix could be combined with existing techniques for scraping by demonstration.
Lastly, while d.mix is built on wikis, a social editing technology, we have not yet evaluated how use by multiple developers would change the d.mix design experience. Prior work on desktop software customization has shown that people share their customization scripts (Mackay, 1990). It would be valuable to study code-sharing practices on the Web.
SUMMARY
We have introduced the technique of programming by a sample. The application d.mix addresses the challenge of becoming familiar with a Web service API and provides a rapid prototyping solution structured around the acts of sampling content from an API-providing Web site and then working with the sampled content in a wiki. Our system is enabled on a conceptual level by a mapping from HTML pages to the API calls that would produce similar output. It is implemented using a programmable proxy server and wiki. Together with our past work (Hartmann et al., 2006; Hartmann, Doorley, & Klemmer, 2008), we regard d.mix as a building block toward new authoring environments that facilitate prototyping of rich data and interaction models.
Acknowledgments
We thank Leith Abdulla and Michael Krieger for programming and production help, whytheluckystiff for Ruby support, and Wendy Ju for comments. This research was supported through NSF grant IIS-0534662, a Microsoft New Faculty Fellowship for Scott Klemmer, an SAP Stanford Graduate Fellowship for Björn Hartmann, and a PC donation from Intel.
© ACM, 2007. This is a minor revision of the work published in Proceedings of the 20th Annual ACM Symposium on User Interface Software and Technology (UIST ‘07). http://doi.acm.org/10.1145/1294211.1294254.
Intended users: | All users |
Domain: | Web service-backed Web sites |
Description: | With d.mix, users browse annotated Web sites and select elements to sample. The sampling mechanism used by d.mix generates the underlying service calls that yield those elements. This code can be edited, executed, and shared in d.mix’s wikibased hosting environment. This sampling approach leverages pre-existing Web sites as example sets and supports fluid composition and modification of examples. |
Example: | Jane would like to create a Web site for her rock climbing club, showing off pictures and videos of their trips. The content lives in service-backed Web sites. With d.mix, Jane can browse to the relevant sites, and “sample” it – sampling copies the underlying service calls that would generate this content. She can then paste this code into d.mix’s wiki-based hosting environment, and use it to create a custom site. |
Automation: | No, d.mix relies on Web service calls rather than automation. |
Mashups: | Yes! Users of d.mix will often want to compose and integrate content from multiple sites. |
Scripting: | Yes, in d.mix’s active wiki, people can freely mix text, HTML, CSS, JavaScript and Ruby to create new custom sites. |
Natural language: | No, sampling is accomplished through direct manipulation. |
Recordability: | No, though direct manipulation is used to specify samples. |
Inferencing: | No, a manually specified site-to-service map is used to infer underlying service calls. |
Sharing: | Yes, the wiki-based hosting environment lets users share code; the site-to-service maps are also globally shared. |
Comparison to other systems: | Like Chickenfoot and CoScripter, lowers the programming threshold by piggybacking on the existing Web. Differs in its focus on content creation rather than automation. |
Platform: | Implemented in Ruby, using the MouseHole proxy. |
Availability: |
1XML Path Language: http://www.w3.org/TR/xpath.
2Cascading Style Sheets: http://www.w3.org/Style/CSS/.
3MouseHole scriptable proxy: http://rubyforge.org/projects/mousehole/.
4Hpricot HTML parser library: http://github.com/hpricot/hpricot/.
5Document Object Model: http://www.w3.org/DOM.
6Solvent Firefox extension for screen scraping: http://simile.mit.edu/wiki/Solvent.
7Mozilla Bespin Web code editor: https://bespin.mozilla.com/.
8Upcoming event listings: http://upcoming.yahoo.com.
930 Boxes calendar: http://30boxes.com.
10Greasemonkey Firefox extension: http://addons.mozilla.org/en-US/firefox/addon/748.
11Adobe Dreamweaver HTML editor: http://www.adobe.com/products/dreamweaver.
12Yahoo! Pipes feed composition tool: http://pipes.yahoo.com.
13StrikeIron Kapow Web Data Services: http://strikeiron.com/kapow.
14Apple Automator: http://developer.apple.com/macosx/automator.html.
15IBM Mashup Center: http://www-01.ibm.com/software/info/mashup-center/.
16Crowbar headless browser: http://simile.mit.edu/wiki/Crowbar.