
Oracle—A Relational Database
Relational databases are simply a way of accessing and merging data together where the end user does not need to know how the data will be extracted by the computer. A relational database differs from other kinds of data retrieval methods in that the end user needs only to have an understanding of the data, not an understanding of how to retrieve the data.
Other data retrieval methods include hierarchical and network database systems. Hierarchical data retrieval systems such as ISAM and VSAM are traditionally accessed via COBOL programs in a mainframe environment. Network data retrieval systems such as DMSII (Burroughs), IMS, and IDMS (IBM Mainframe Systems) are also traditionally accessed with a COBOL program utilizing a programmer or a team of programmers that have the knowledge and understand the arrangement of the data. The advantage of these COBOL-based data storage systems is that the access time is traditionally very fast compared to that of relational databases. The huge disadvantage is the complex process for accessing particular data for particular needs. The access to data is very specific and does not lend itself well for today's data warehouse and ad-hoc accesses.
Cobol programming is not for the novice. A simple program can consist of hundreds of lines of code.
What Is a Database?
A hierarchical system stores its data to be later referenced by a particular data or data items known as a key value.
The data is then stored in the order of this key value and can only be accessed by this key value and previous knowledge of what the key value is.
Figure 1.1 depicts how a department and an employee database might be stored in an ISAM hierarchical storage system, or ISAM files. Accessing data in ISAM files is very quick, but the data can only be accessed via its key value. This kind of storage mechanism is very handy for online systems where the data is always accessed via a known number such as a social security number or by last name. Selecting data between ISAM files is handled by the COBOL program by reading the department file first, then reading the employee file, and searching for the particular field. Access can be very fast if the department information is accessed via the employee file. Selecting the data for all employees of department 10 could be a lengthy process. Selecting employees that report to a certain manager could be a lengthy process. Selecting employees by their EmployeeID number is a very quick process. There is no relationship between the department file and the employee file.
Figure 1.1. Hierarchical file configuration.

A network system also stores its data by a key value, but dissimilar data types can be separated into separate storage areas and be reassembled via an access path. For example, in Figure 1.2, accessing data through the department table first would be the only access of the employee data. This storage mechanism is more flexible, as files with single record data such as departments within a company, can easily be related to all the employees that belong to that department.
Figure 1.2. Network file configuration.

Once again, access to the data is very quick but the way the data is accessed is always fixed. Selecting data for all employees of department 10 could be a quick process; however, selecting all employees that report to a certain manager could be a very slow process. Note the location of the crow's foot, which indicates that there are employee records associated with each department record. In a network database environment, these employee records can only be retrieved by first reading the department record.
NOTE
Crow's Foot—This data modeling term indicates that there is a one-to-many relationship from this object or file to the one that it points to.
The relational database supports a single, logical structure called a relation, a two-dimensional data structure commonly called a table in the database. Attributes or columns contain information about the structure. In Figure 1.3, the employee table contains attributes such as employee name, salary, manager, and so on. The actual data values of a table are called tuples or rows. A relationship can exist between two or more tables that have no data at all.
Figure 1.3. Components of Table Employee.

Attributes can be grouped with other attributes based on their relationship with one another and become a composite key or even a composite primary key. A primary key is an attribute or group of attributes (composite key) that uniquely identifies a row in a table. Oracle will automatically create a unique index on a primary key. A table can have only one primary key, and when using referential integrity, every table will have one defined. Because primary key values are used as identifiers, they must contain a data item, that is, not be NULL.
NOTE
A composite key is one or more columns, placed at the beginning of the table, in the order of importance, and the group becomes the key value.
You can have additional attributes in a relation with values that you define as unique to the relation. Unlike primary keys, unique keys can contain NULL values. In practice, unique keys are used to prevent duplication in the table rather than to identify rows. Consider a relation that contains the attribute United States Social Security Number (SSN). In some rows, this attribute may be null because not every person has an SSN; however, for a row that contains a non-null value for the SSN attribute, the value must be unique to the relation.
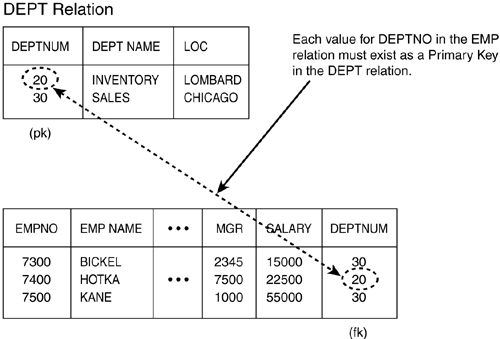
Selecting data from two tables involves a column attribute that is common to both tables. Figure 1.4 shows the relationship between two tables. The relationship between tables can be maintained by the relational database. The primary table or parent table may have one or more related rows in another table or child table. This automatic maintenance and definition is called Referential Integrity. Referential integrity rules dictate that foreign key values in one relation reference the primary key values in another relation.
Figure 1.4. Primary/Foreign key relationships.
NOTE
Referential integrity is simply SQL code that enforces the relationship between two or more tables based on primary and foreign keys. This really makes the programmer's life easy in our example of employees and departments. With referential integrity defined, the programmer does not need to make sure the department exists in the department table when adding new employees. The Oracle database will check and enforce these rules when defined.
Many tools can take advantage of primary/foreign key relationships and referential integrity rules. You will learn how to use these tools throughout this book. This book will make frequent references to the DEPT and EMP sample tables that install with the Oracle database. These example tables are perfect for learning the SQL syntax. This book will use the EMP and DEPT sample tables through Chapter 4, “Building an Oracle9i Database,” then the book will concentrate on the Sales Tracking sample application.
Relational tables have several advantages:
Tables are easy to create.
Tables are easy to add to or change.
Tables are easily related to other tables to present the desired results.
The end user simply needs to understand his or her data, not how to access the data, as depicted in Figure 1.3. Selecting all employees of department 10 is as easy as selecting all employees that report to a certain manager. The user would have the knowledge of the data stored by department and employee and could select data based on any of the columns, not just certain key fields. Selecting data from two or more tables involves a column type (or attribute) that is common to both (or all) tables. One would not relate the Employee Name with the Department ID; however, one could relate the Department ID from each table together.