
Computational Performance Evaluation of a Limited Area Meteorological Model by using the Earth Simulator
G. Cecia[email protected]http://www.cira.it; R. Mellaa; P. Schianoa; K. Takahashib[email protected]http://www.es.jamstec.go.jp; H. Fuchigamib a Informatics and Computing Department, Italian Aerospace Research Center (CIRA), via Maiorise, I-81043 Capua (CE) - Italy
b Multiscale Climate Simulation Project Research, Earth Simulator Center/Japan Agency for Marine-Earth Science and Tech., 3173-25 Showa-machi, Kanazawa-ku, Yokohama Kanagawa 236-0001, Japan
INTRODUCTION
The work described in this paper comes from an agreement signed between ESC/JAMSTEC (Earth Simulator Center/Japan Agency for Marine-Earth Science and Technology) [1] and CIRA (Italian Aerospace Research Center) [2] to study hydrogeological (landslides, floods, etc.) and local meteorological phenomena.
It is well known that meteorological models are computationally demanding and they require both accurate and efficient numerical models on high performance parallel computing. Such needs are strictly and directly related to the high resolution of the model. The interest in this paper is about computational features, parallel performance and scalability analysis on Earth Simulator (ES) supercomputer of GCRM (Global Cloud Resolving Model - regional version) meteorolgical model, currently developed at ESC by the Multiscale Climate Simulation Project Research Group.
The paper is organized as follows. In Section 1 the meteorological model is described, emphasizing above all numerical and computational features. In Section 2 the ES system and the types of parallelism available on it are presented. In Section 3 details related to computational experiments and valuation criteria are discussed. In Section 4 and 5, finally, computational results are shown and discussed, respectively.
1 THE GLOBAL/REGIONAL NON-HYDROSTATIC ATMOSPHERIC MODEL
The model is based on non-hydrostatic fully compressible three-dimensional Navier-Stokes equations in flux form; the prognostic variables are density perturbation, pressure perturbation, three components of momentum and temperature [9][10][11].
Equations are casted in spherical coordinates and they are discretized on an Arakawa C/Lorenz grid by using finite difference methods; the grid structure has a horizontal resolution of 5.5 km and 32 levels are used vertically in terrain-following σ-coordinate. A time splitting procedure is applied for fast/slow waves integration in order to improve computational efficiency [3] [4] [5] following Skamarock-Wicher formulation [6] [7]; in particular, it employs Runge Kutta Gill method (2nd, 3rd and 4th order) for advection tendencies (using large time step) and forward/backward scheme for fast modes (using small time step).
The regional version is nested in a global/larger regional model (coarse grid) by 1-way interactive nesting. A sponge/relaxation boundary condition Davies-like [8] is used to allow the atmospheric interaction between the interior domain (regional domain on fine grid) and the external domain (global/larger regional model on coarse grid). Strictly speaking, the computational domain (fine grid) is composed by a halo area (outside the physical domain) and a sponge area (inside the physical domain); in the first one relaxation values of prognostic variables are defined by interpolation from the coarser grid or by a Newman condition, while in the latter prognostic variables are relaxed. Three types of sponge functions are implemented (hyperbolic, trigonometric and linear). More details about the model are available in [9] and a summary of the features discussed above is in Table 1.
Table 1
Numerical features of the GCRM meteorological model (limited area version)
| Equation system | Non-hydrostatic fully compressible Navier-Stokes (flux form) | |
| Prognostic variables | Density perturbation, pressure perturbation, three components of momentum and temperature | |
| Grid system | Equations casted in spherical coordinates and discretized on an Arakawa-C/Lorenz grid by FDMs. | |
| Horizontal Resolution and Vertical Levels | Horizontal resolution 5.5 km; 32 vertical levels in terrain-following coordinate | |
| Time integration | HE-VI. Time splitting with Runge Kutta Gill 2nd/3rd/4th order for advection tendencies (large time step) and Forward-Backward for fast modes (small time step) | |
| Boundary Conditions | Lateral | Sponge/relaxation boundary condition Davies-like |
| Upper | Rayleigh friction | |

2 THE ES SYSTEM
The ES is a distributed-memory parallel system made up by 640 NEC SX-6 nodes and each node is a parallel/vectorial shared-memory MIMD (Multiple Instruction Multiple Data) computer having 8 CPUs. The peak performance is about 40 TFLOPS (64 GFLOPS per node), the total main memory is of 10 TB and currently it is one of the most powerful supercomputers in the world [12].
The operating system is SUPER-UX, which is based on Unix System V, suitable languages and libraries (FORTRAN90/ES, C++/ES, MPI/ES, OpenMP) are provided to achieve high performance parallel computing. In particular, two types of parallelism can be implemented: hybrid and flat. The first one means that parallelism among nodes (inter-node parallelism) is achieved by MPI (Message Passing Interface) or HPF (High Performance Fortran), while in each node (intra-node parallelism) by microtasking or OpenMP. The latter, instead, means that both intra- and inter-node parallelism is archived by HPF or MPI; consequently the ES is viewed as made up by 8×640 processors. Roughly speaking, in the first case a program is subdivided into n MPI-tasks (each one running on each node) and the intra-node parallelism is performed by OpenMP or microtasking. In the second case, instead, a program is subdivided into n MPI-tasks running on n processors. Detailed description of ES is reported in [1].
3 IMPLEMENTATION DETAILS AND COMPUTATIONAL EXPERIMENTS
The programming language is Fortran90 and the algorithm is based on a SPMD (Single Program Multiple Data) program. The parallel computation of the non-hydrostatic atmospheric model, which has been developed at ESC, is implemented by a hybrid parallelization model: intra- and inter-node parallelisms are performed by micro-tasking and by MPI, respectively.
The selected test refers to an intense precipitation event occurred during November 2002 on North-Western of Italy.
To study scalability of the code (performance changing varying problem size or number of processors) experiments have been carried out keeping constant the problem size and varying the number of processors. The sizes along x−, y− and z-direction of the considered computational domains are 600×1152×32 (small domain), 1200×1152×32 (medium domain, twice bigger) and 1200×2304×32 (large domain, four times bigger). In order to reduce the communication cost a block-wise processors grid is adopted in horizontal for all the performed tests; consequently each processor works on a sub-domain having 32 vertical levels. The number of used processors varies between 16 and 512 (that means 2 and 64 nodes on the ES, respectively); in all cases the step incrementing the number of processors is by powers of two.
To evaluate runtime performances suitable compilation options and environment variables have been set. In particular, the performance analysis tool ftrace has been used to collect detailed information on each called procedure (both subroutine and function); we emphasize that it is better to use this option just for tuning since it causes an overhead. Such collected information is related to elapsed/user/system times, vector instruction execution time, MOPS (million of operations per second), MFLOPS (million of floating-point operations per second), VLEN (average vector length), Vector Operation Ratio (vector operation rate), MIPS (million of instructions per second) and so on. Criteria to achieve best performance are: vector time has to be close to user time; MFLOPS should be obviously as high as possible; VLEN, being the average vector length processed by CPUs, should be as much as possible close to the hardware vector length (256 on NEC SX-6) and, consequently, best performances are obtained on longer loops; vector operation rate (%) should be close to 100. Such information has been took into account for each performed experiment.
Scalability has been evaluated in terms of speed-up and efficiency. Since the program cannot be run sequentially, both speed-up and efficiency have been calculated using the elapsed time obtained running the parallel program with the minimum number of processors. In particular, speed-up has been evaluated by Amdhal’s Law [13] in the following form:
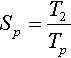
where T2 and Tp are the wall clock times on 2 nodes (16 processors) and p nodes (p * 8 processors), respectively.
4 COMPUTATIONAL RESULTS
A feature verified in all performed tests is the good load balance among MPI processes: in fact, as showed in Table 2, the minimum value of the elapsed time is always very close to the maximum one.
Table 2
Minimum and maximum real times
| domain size | # nodes | # processors | min (sec) | max (sec) |
| 600x1152×32 | 2 | 16 | 1098,735 | 1098,845 |
| 4 | 32 | 568,688 | 568,918 | |
| 8 | 64 | 292,654 | 293,462 | |
| 16 | 128 | 165,918 | 166,260 | |
| 32 | 256 | 91,712 | 92,698 | |
| 1200×1152×32 | 4 | 32 | 1117,389 | 1117,858 |
| 8 | 64 | 575,914 | 576,783 | |
| 16 | 128 | 339,519 | 341,198 | |
| 32 | 256 | 170,163 | 172,292 | |
| 64 | 512 | 100,435 | 101,677 | |
| 1200x2304x32 | 8 | 64 | 1419,989 | 1420,469 |
| 16 | 128 | 733,698 | 733,945 | |
| 32 | 256 | 387,153 | 387,458 | |
| 64 | 512 | 215,181 | 216,717 |

Computational results were analyzed according to criteria discussed in the previous Section. Results concerning elapsed times and speed-up are shown in Figure 2, Figure 3 and Figure 4 going on from the small (600×1152×32), to the medium (1200×1152×32) to the large (1200×2304×32) domain, respectively. Efficiency related to each run is in Table 3.



Table 3
Efficiency (%) on each domain obtained changing the number of processors along x- and y-directions
| Domain 600×1152×32 | Domain 1200×1152×32 | Domain 1200×2304×32 | ||||||
| Procs along x | Procs alongy | Efficiency (%) | Procs along x | Procs along y | Efficiency (%) | Procs along x | Procs along y | Efficiency (%) |
| 1 | 16 | − | ||||||
| 1 | 32 | 96.5 | 2 | 16 | − | |||
| 1 | 64 | 93.8 | 2 | 32 | 96.88 | 2 | 32 | − |
| 1 | 128 | 82.5 | 2 | 64 | 82.04 | 2 | 64 | 96.76 |
| 1 | 256 | 74.1 | 2 | 128 | 81.01 | 2 | 128 | 91.63 |
| 2 | 256 | 68.68 | 2 | 256 | 81.79 | |||

Performance analysis concerns also performed GFLOPS: analogously, the sustained peak performance obtained on small, medium and large domain is shown in Figures 5 and a comparison of sustained peak performance versus the theoretical one is in Table 6.

Table 6
Comparison of sustained with theoretical peak performance (%) on each domain varying the number of processors
| Domain 600×1152×32 | Domain 1200×1152×32 | Domain 1200×2304×32 | ||||||
| Procs along x | Procs along y | Sust/theor p.p.(%) | Procs along x | Procs along y | Sust/theor p.p. (%) | Procs along x | Procs along y | Sust/theor p.p.(%) |
| 1 | 16 | 51.50 | ||||||
| 1 | 32 | 49.89 | 2 | 16 | 50.79 | |||
| 1 | 64 | 48.75 | 2 | 32 | 49.36 | 2 | 32 | 51.21 |
| 1 | 128 | 43.27 | 2 | 64 | 42.14 | 2 | 64 | 49.70 |
| 1 | 256 | 39.97 | 2 | 128 | 42.48 | 2 | 128 | 47.33 |
| 2 | 256 | 36.59 | 2 | 256 | 42.98 | |||

5 CONCLUSIONS
Results shown in the Section 4 are very satisfactory and promising for the future developments.
In all cases, ftrace tool shows that MFLOPS achieved in each routine are more or less 50% of the theoretical peak performance and that Vector Operation Ratio is very close to 100%. The small gap between the minimum and maximum real time testifies a high granularity and a good load balancing among processors: all times vary between 0.11 seconds and 2.13 seconds.
Obtained values in all performed tests show a speed-up varying nearby linearly and an efficiency staying always up to 70%. Varying the number of nodes on each domain, such values of speed-up and efficiency get worse since, increasing the number of processors, each subdomain becomes too small.
On the other hand, as shown above, the sustained performance is greater than about 40% of theoretical peak performance related to the number of used processors.
Moreover, the hybrid parallelization (MPI processes + OpenMP threads) has been compared with the flat one (only MPI processes) and in the first case an efficiency up to 25% has been achieved.