
1.1 What is machine learning?
Over the past few years, you’ve probably heard the words “machine learning” many times, but what is it exactly? Is it the same thing as artificial intelligence? What about deep learning? Neural networks? Models?
Before diving deeper into the tools, algorithms, and what can be built, let’s start by defining some of these terms to gain a common understanding of what machine learning is and is not.
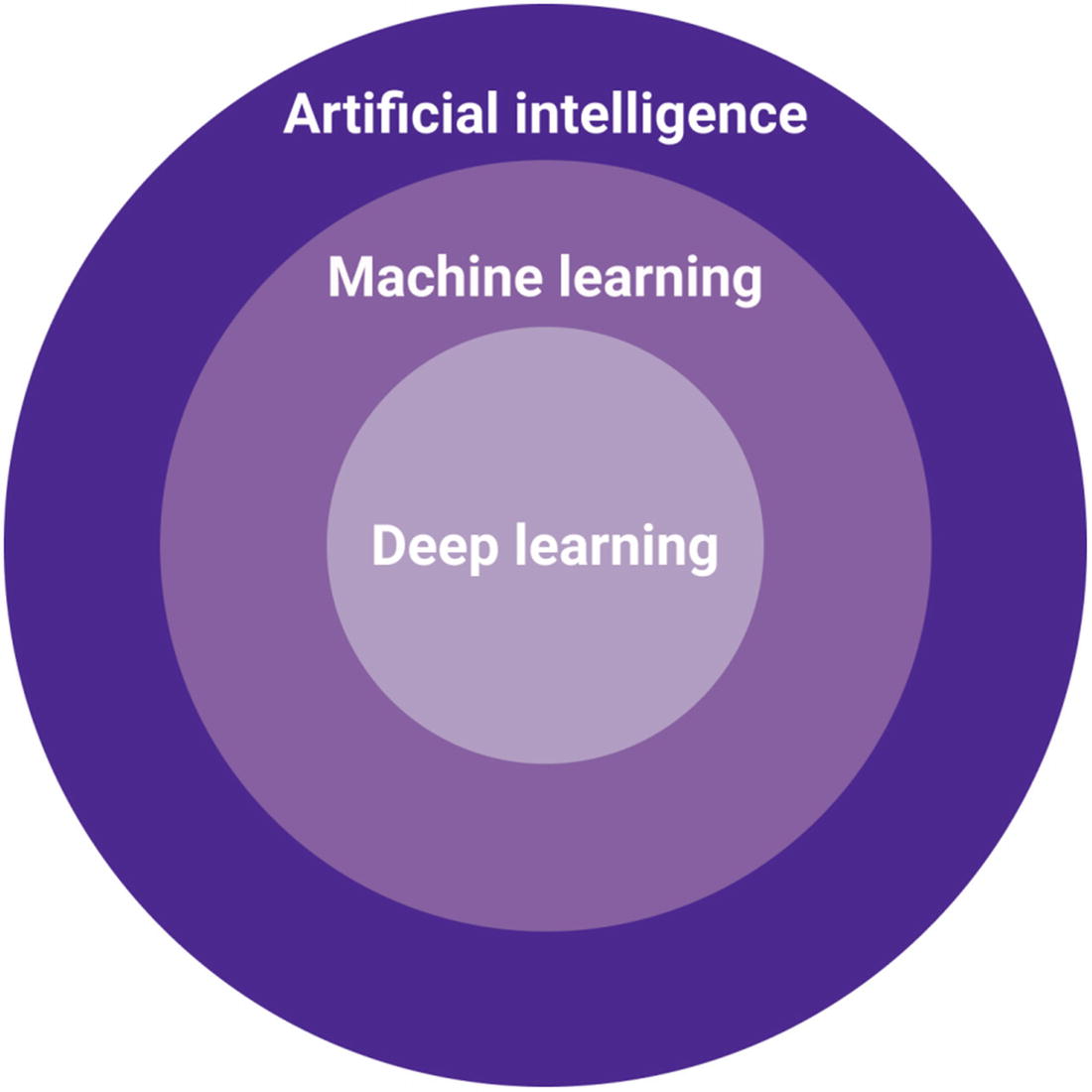
This graph is a representation of how artificial intelligence, machine learning, and deep learning connect
Artificial intelligence is the umbrella term for everything related to the expression of “intelligence” by computers. This can include speech recognition (the understanding of human speech), autonomous cars, or strategic gaming (the ability for computers to play strategic games like Go or Chess).
Machine learning represents the technology itself: all the practices and set of tools to give the ability to computers to find patterns in data without being explicitly programmed.
This includes the different types of learning and algorithms available such as supervised learning, Naive Bayes, K-nearest neighbors, and so on that we will cover in the next few chapters.
This technology is used to train computers to make their own predictions based on a developed understanding of historical data.
What this means is that we’re not telling computers exactly what to look for; instead, we feed algorithms a lot of data previously collected and let them find patterns and correlations in this dataset to draw future conclusions and probabilities when given new data.
For example, if we want to use machine learning to help us calculate the probability of a person having cancer based on their CT scans, we would build a dataset of hundreds of thousands, or even millions, of CT scans from diverse patients around the world. We would label this data between CT scans of cancerous patients and scans of healthy patients. We would then feed all this data to machine learning algorithms and let them find patterns in those medical images to try and develop an accurate understanding of what a cancerous scan looks like.
Then, using the model generated by all this training, we would be able to use it on a new scan that wasn’t part of the training data, and generate a probability of a patient having cancer or not.
Finally, deep learning is a specific tool or method. It is related to another term you might be familiar with, called artificial neural networks. Deep learning is the subset of machine learning that uses algorithms inspired by the structure and function of the brain.
The concept of neural networks in machine learning is not new, but the term deep learning is more recent.
Essentially, this method allows the training of large neural networks in the aim to make revolutionary advances in machine learning and AI.
Deep learning has been taking off over the past few years mainly thanks to advancements in computing power and the amount of data we are now collecting.
In comparison to other machine learning algorithms, deep learning ones have a performance that continues to improve as we increase the amount of data we feed them, which makes them more scalable where others plateau.

This slide illustrates how deep learning scales compared to other machine learning algorithms. Source: https://www.slideshare.net/ExtractConf
As you can see in the preceding graph, the main differential characteristic of deep learning algorithms is their ability to scale and increase performance with more data.
The term “deep” learning generally refers to the amount of layers used in the neural networks. If this does not totally make sense right now, we’ll cover the concept of layers a bit later in this book.
Now that we know more about the difference between these terms, this book is going to be focusing mainly on machine learning, the technology. We’ll be diving a little bit into deep learning as we look into different techniques but we’ll touch on broader aspects of the technology as well.
We’ve defined the different names sometimes interchangeably used to talk about intelligence expressed by computers, but what about other important idioms like “neural networks,” “algorithms,” and “models”?
We are probably going to mention them along the book, so let’s spend the next few paragraphs defining them.
Let’s start with algorithms as this is the one you might be the most familiar with as it is already used in traditional programming.
An algorithm can be defined as a set of rules or instructions to solve a particular problem or perform a computation.
In software engineering, examples of algorithms you might have heard of or used would be the quicksort algorithm, the Dijkstra algorithm, binary search, and so on. Each algorithm was created to solve a particular problem.
When it comes to machine learning algorithms, they solve different types of problems but the concept is the same; each algorithm, it being a support vector machine (SVM) or a long short-term memory (LSTM) algorithm, is only a mathematical function that solves a specific problem.
Neural networks are a set of deep learning algorithms designed to mimic the way the brain works.
The same way the brain is made of a giant network of connected neurons, neural networks are made of layers of interconnected nodes called artificial neurons.

This graph is a representation of the different layers in a neural network
In neural networks, there are usually three main parts, an input layer that represents the input data you want to generate a prediction for (e.g., an image you want to apply object detection to, a piece of text you want to get the sentiment for, etc.), a certain number of hidden layers, and an output layer that represents your prediction.
This is a very high-level explanation of how neural networks work, but the most important part to understand is that they are made of a large number of interconnected nodes, organized in layers, that get activated or not during the training process depending on the outcome generated by neurons in the previous layer, in a similar way different neurons in the brain fire when given specific inputs.
Finally, models. In machine learning, models represent the output of a training session. When the training process is happening, algorithms are “learning” to draw conclusions from patterns they find in data; once the training steps are done, the output is a model.
Models are mathematical functions that can take new inputs as parameters and produce a prediction as output.
For example, image classification models have been trained with thousands of labelled images to recognize patterns in the data and predict the presence of certain entities (e.g., cats, dogs, cars, people, etc.). When using an image classification model in a new application, you would be able to feed it a new image that might not have been part of the training dataset, and have it generate a prediction of what might be in this image it has never “seen” before based on the learnings from the training process.
At the end of the training process, you generally test your model with new input that was not part of the training dataset to test the validity of the prediction generated.
Now that we’ve defined a few of the important terms you’ll come across when diving into machine learning, I think it is important to go quickly over what machine learning is not.
Hopefully, the last few paragraphs made it more clear that machine learning is not able to generate predictions without being fed some pregathered data.
The same way we, as humans, cannot recognize a new object or entity we’ve never been exposed to, an algorithm also needs to be given some kind of information before being able to identify a new input.
For example, the first time I heard about 3D printers, I was struggling to be able to visualize what it was. When I finally saw and interacted with one, I then had an understanding of what the object was and was able to recognize future ones.
The brain does this very fast, but algorithms need a lot more data to be trained with before being able to develop an understanding of what objects are.
Because algorithms are basically mathematical functions, it is important to take with a grain of salt what you can read about the evolution of AI in the future.
As performant as it can be, AI systems still need to be trained on a lot of data we have to previously gather. As a result, I believe the opportunity of machine learning applications resides in augmenting humans rather than replacing them.
An example of that would be in the field of healthcare. I don’t particularly believe that AI systems will replace doctors, but we’re already seeing how machine learning helps them by being able to process a massive amount of medical images and identify and diagnose diseases in CT scans and MRIs, sometimes with higher accuracy than healthcare professionals.
By relying on machine learning models this way, we can hope to diagnose and help people faster.
It is also important to remember that computers don’t have a real understanding of the context of the information they are working with. Certain problems we need to solve are very complex from a societal point of view and should probably not be solved using machine learning only. We will cover a bit more about the topic of ethics and AI toward the end of this book.
1.2 Types of machine learning
Problems solved using machine learning usually fall into one of the three main categories: supervised learning, unsupervised learning, and reinforcement learning.
You might also hear about semi-supervised learning, but this book is not going to cover it.
Knowing which type of problem you are trying to solve is important because it will determine which algorithms you’ll want to use, how you will prepare your data, and what kind of output you will get.
First of all, let’s start with the most popular one, supervised learning.
1.2.1 Supervised learning
Supervised learning is the ability to find patterns in data using both features and labels.
Here, we just introduced two new data-related terms we need to define before we keep going.
When using a dataset, features represent the characteristics of each entry and labels are how you would define these entries. Let’s use an example to put this in practice.
Let’s say you want to sell your house but are not sure about what price would be the most competitive on the market, but you have access to a large dataset containing information about all the houses and their price, in the city you live in.
In this case, the features would be details about each house (number of bedrooms, bathrooms, floors, type of house, does it have a balcony, garden, etc.), and the labels would be their price.
This table represents an example of a labelled dataset
Price | Number of bedrooms | Number of bathrooms | Number of floors | Balcony | Garden |
|---|---|---|---|---|---|
$1,500,000 | 3 | 2 | 2 | No | Yes |
$500,000 | 1 | 1 | 1 | Yes | No |
$750,000 | 1 | 1 | 1 | No | Yes |
$1,700,000 | 4 | 2 | 2 | No | Yes |
$700,000 | 2 | 1 | 1 | No | No |
$850,000 | 2 | 1 | 1 | Yes | Yes |
$525,000 | 1 | 1 | 1 | No | No |
$2,125,000 | 5 | 3 | 3 | Yes | Yes |
$645,000 | 1 | 1 | 1 | Yes | Yes |
A real dataset would have many more entries and more features would be gathered, but this is only an example to illustrate the concept of features and labels.
Using this labelled data, we can use machine learning to predict the price at which your house should be put on the market for.
For example, based on the preceding data, if your house had 1 bedroom, 1 bathroom, no balcony but a garden, its price would be closer to about $750,000 than $1,000,000.
In this quick example, we can do it manually by looking at the data, but in a real-life situation, the amount of data would be much larger, and using machine learning would be able to do this calculation much faster than humans.
Some other examples of supervised learning problems include predicting if an email is spam or not, predicting the probability of a sports team winning based on previous game data, predicting the probability of an insurance claim being fraudulent.
In summary, supervised learning is the creation of predictions based on labelled data .
1.2.2 Unsupervised learning
Another common type of learning is called unsupervised learning . Contrary to supervised learning, unsupervised learning is the creation of predictions based on unlabelled data. What this means is that we rely only on the set of features.
If we think about our previous dataset of houses, it means we would remove the column “Price” and would end up only with the data about the characteristics of each house.
If we reuse the scenario of wanting to predict the price at which we should sell our house, you might be wondering, how can we predict this price if our data is not labelled (does not contain any price)?
This is where the importance of thinking about the problem you are trying to solve and paying attention to the data you possess comes into play.
With unsupervised learning, we are not trying to predict a single outcome, or answer a specific question, but instead, identify trends.
In our house problem, our question was “How much can I sell my house for?” where we would expect a specific price as an outcome. However, as mentioned previously in this book, a machine learning algorithm cannot really predict a price if the dataset it was fed with during training did not contain any price.
Therefore, this is not the type of situation where we would use unsupervised learning.
As unsupervised learning is about identifying trends and classifying data into groups, a good example of problems that would fall into this space would be predicting customer behavior.
With this type of problem, we are not trying to answer a question with a specific answer; instead, we are trying to classify data into different categories so we can create clusters of entities with similar features.
Using our example of predicting customer behavior, by gathering data about each customer, we can use machine learning to find behavioral correlation between customers and find buying patterns that would help in applications such as advertising.
Gathering and using data about where you shop, at what time, how many times a week, what you buy, and so on, we can draw conclusions about your gender, age, socioeconomic background, and more, which can then be used to predict what you might be likely to buy based on the cluster you belong to.
You might be familiar with a real-world application of this type of prediction if you’ve been exposed to music recommendation on Spotify or product recommendation on Amazon.
Based on your listening and buying habits, companies gather data and use machine learning to cluster customers into groups, and based on what other people like you have listened to, they propose recommendations of songs or products you might like.
1.2.3 Reinforcement learning
A third type of learning is called reinforcement learning. If you’re reading this book, you are likely just getting started with machine learning so you probably won’t be using it at first.
Reinforcement learning is mostly used for applications such as self-driving cars, games with AI players, and so on where the outcome involves more of a behavior or set of actions.
It relies on the concept of reward and penalty and the relationship between an “agent” and an “environment.”
We can imagine the scenario of a game of Pong where the environment is the game and the agent is a player. Actions from the player change the state of the game. Changing the position of the paddles influences where the ball goes and eventually results in the player winning or losing.
When a sequence of actions results in the player winning, the system gets some kind of reward to indicate that this particular set of interactions resulted in achieving the goal of the training process, creating an AI player that can win a game by itself.
The training process then continues, iterating over different sets of interactions, getting rewards when winning (+1 point), a penalty when losing (-1 point), and correcting itself to develop an understanding of how to win the game against another player over time.
This type of learning does not rely on a preexisting dataset used to feed an algorithm.
Instead, it uses a set of goals and rules (e.g., the paddle can only go up and down, the goal is to win against the other player, etc.) to learn by itself the correct behavior to optimize its opportunities to achieve the set goal.
Reinforcement learning lets the system explore an environment and make its own decisions.
This type of learning often demands a very long training process involving a huge amount of steps. One of the issues resides in the fact that, when receiving a penalty for losing a game, the system assumes that the entire sequence of actions taken in the round caused it to lose. As a result, it will avoid taking all these steps again instead of identifying which steps in the action sequence contributed to losing.
1.2.4 Semi-supervised learning
Finally, let’s talk briefly about semi-supervised learning.
Semi-supervised learning sits between supervised and unsupervised learning. As mentioned in the last few pages, supervised learning deals with labelled data and unsupervised learning uses unlabelled data.
Sometimes, when using a large dataset of unlabelled data, we can proceed to label a subset of it and use semi-supervised learning to do what is called pseudo-labelling .
What this means is that we’re going to manually label a portion of our dataset and let the algorithm label the rest to end up with a fully labelled set.
For example, if we have a collection of hundreds of thousands of images of cats and dogs that are not already labelled, we can label a part of it ourselves and feed it to a semi-supervised learning algorithm that is going to find patterns in these images and is going to be able to take the rest of the unlabelled dataset as input and attach the label “cat” or “dog” to each new image, resulting in all the data being labelled.
This technique allows us to generate a labelled dataset much faster than having to do it manually so we can then proceed to use supervised learning on it.
Understanding which type of learning your problem falls into is usually one of the first steps.
Now that we’ve covered the main ones, let’s look into some of the most well-known algorithms.
1.3 Algorithms
As with standard programming, machine learning uses algorithms to help solve problems.
However, it is not essential to understand the implementation of all algorithms before being able to use them. The most important is to learn which type of learning they belong to and the type of data they are the most efficient with.
If you compare it with web programming, there are a lot of different JavaScript frameworks available, and you don’t necessarily need to understand their source code to be able to build your applications using them. What you need to know, however, is if they support the features you need.
In the context of machine learning, some algorithms are very good at working with image data, while others are better at handling text data.
Let’s dive into some of them.
1.3.1 Naive Bayes
The Naive Bayes algorithm is a supervised learning classification algorithm.
It predicts the probability of different classes based on various attributes and prior knowledge.
It is mostly used in text classification and with problems having multiple classes. It is considered highly scalable and requires less training data than other algorithms.
A practical example of problem that could be solved with Naive Bayes would be around filming a TV series.
Unless all of the plot happens indoors, the production of the show will be impacted by environmental factors such as the weather, humidity level, temperature, wind, season, and so on.
As parts of a TV show are not filmed in order, we could use machine learning to help us find the best days certain parts of the show should be filmed on, based on the requirements of certain scenes.
Gathering a dataset of weather attributes and whether or not an outdoor scene was filmed, we would be able to predict the probability of being able to film a new scene on a future day.
This algorithm is called “Naive” as it makes the assumption that all the variables in the dataset are not correlated to each other.
For example, a rainy day does not have to also be windy or a high level of humidity does not have to correlate to a high temperature.
1.3.2 K-nearest neighbors
Another popular algorithm is called K-nearest neighbors .
This algorithm is a classification algorithm that assumes that similar things exist in close proximity to each other, so near each other.

This illustration represents a visualization generated by using a K-nearest neighbors classification algorithm. Source: https://machinelearningmastery.com/tutorial-to-implement-k-nearest-neighbors-in-python-from-scratch/
In the preceding visualization, we can see that the data plotted ends up creating some kind of organized clusters. Similar data points exist close to each other.
The K-nearest neighbors algorithm (KNN) works on this idea of similarity to classify new data.
When using this algorithm, we need to define a value for “K” that will represent the amount of closest data points (neighbors) we will take into consideration to help us classify a new entry.
For example, if we pick the value K = 10, when we want to predict the class for a new entry, we look at the 10 closest neighbors and their class. The class that has the highest amount of neighbors to our new data point is the class that is predicted to be the correct one.
A practical example for this would be in predicting customer behavior or likelihood to buy certain items.
A supermarket chain has access to data from people’s purchases and could use unsupervised learning to organize customers into clusters based on their buying habits.
Examples of clusters could be customers who are single vs. those who have a family, or customers who belong to a bracket of certain ages (young vs. old).
Considering that people have, in general, similar buying habits to people in the same cluster, using the K-nearest neighbors algorithm would be useful in predicting what kind of products people would be likely to buy and use this information for advertising.
1.3.3 Convolutional neural networks
Convolutional neural network, also known as ConvNet or CNN, is an algorithm that performs really well at classifying images. It can be used for problems such as object detection and face recognition.
Unlike humans, computers process images as an array of pixels which length would be equal to height * width * dimension. A RGB image of 16x16 pixels would be interpreted as a matrix of 16*16*3 so an array of 768 values.

This is a representation of how a convolutional network works, from an input image to hidden layers, and outputting a number Source: https://towardsdatascience.com/mnist-handwritten-digits-classification-using-a-convolutional-neural-network-cnn-af5fafbc35e9
The preceding image illustrates how a convolutional neural network would predict the number handwritten in the input image.
It would start by transforming the image into an array of 2352 values (28*28*3) to transform a 3D input into a 1D one. It would then run the data into different layers and filters of the neural network to end up with an output layer of 10 options, as the digit to predict would be between 0 and 9.
The output of the prediction would be a probability for each entry of the output layer, and the entry with the highest probability would be the correct one.
If the problem you are trying to solve involves a dataset of images, you probably want to play around with a CNN algorithm.
These three algorithms fall into different categories. Naive Bayes belongs to Bayesian algorithms, K-nearest neighbors to instance-based algorithms, and convolutional neural networks (CNN) to deep learning algorithms.
There are a lot more categories and algorithms to explore; however, covering all of them is not the goal of this book. As you dive deeper into machine learning and build your own applications, you should definitely look into more of them as you experiment. There is not always a single solution to a problem, so learning about different algorithms will allow you to find the one best suited to what you are trying to achieve.
1.4 Applications
Some applications were mentioned in the last few pages of this book when attempting to illustrate concepts with examples; however, there are many more use cases for machine learning in various fields.
1.4.1 Healthcare
An example of using machine learning in healthcare was introduced when I talked about how systems can be used to detect diseases in CT scans.
Apart from making diagnoses from image analysis, other applications in this field include treatment personalization and “data wrangling” of personal records.
Clinical data is not always digital, with a lot of forms and prescriptions still being handwritten; and if it is digital, each health system customizes their Electronic Health Records (EHR), making the data collected in one hospital different from the data collected at others.
Data wrangling is the concept of capturing, organizing, and triaging data. Using Optical Character Recognition (OCR), a system could scan a handwritten document, parse words, and use a technique called “entity extraction” to understand them and their semantical relationship to each other.
This way, medical documents can be automatically saved in a database, respecting the same format, which makes it easier to search, analyze, or use in the future.
A few of the biggest tech companies dedicate a part of their research center to the development of innovative solutions in this space.
Microsoft, for example, is working on a few research projects like project InnerEye, that aims to turn radiological images into measuring devices. Using machine learning algorithms, the goal of this project is to automatically detect tumors in 3D radiological images, as well as generating precise surgery planning and navigation.
IBM has a project called IBM Watson for Oncology that helps physicians identify key information in a patient’s medical record to help explore personalized treatment options.

Example of timeline built using patient’s health records. Source: https://ai.googleblog.com/2018/05/deep-learning-for-electronic-health.html
The preceding visualization represents a timeline of patient’s health record data. Each gray dot is a piece of data stored in the open data standard FHIR. A deep learning model can then analyze this data to make predictions.
1.4.2 Home automation
The application for machine learning you might be the most familiar with is in home automation.
You probably have heard of, or may even possess, some Internet of Things devices that use machine learning such as the Amazon Alexa or Google Home.
These devices use speech recognition algorithms and natural language processing (NLP) to identify the words you are saying, analyze the intent, and provide the most accurate response possible.
Something worth mentioning is that there is a difference between a “connected” device and a “smart” one. The Internet of Things can be defined as a network of connected “things,” meaning that devices are connected to each other, usually via Wi-Fi or Bluetooth.
However, some devices are simply connected, such as the Philips Hue light bulb, that you can control remotely from your phone. It does not use any machine learning algorithm to produce any output; it only turns on and off or changes color.
On the other hand, devices like the Nest thermostat would fall into the category of “smart devices.” It implements a more complex functionality as it really learns from your behavior over time. As you change the temperature of your house over a period of time, sometimes even during the same day, it learns your habits and adapts automatically.
Just like the Philips Hue, it also lets you control it from anywhere using your phone, but the additional learning part is an example of using machine learning in home automation.
Some research centers are working on improving devices like the Google Home to go beyond speech recognition toward activity recognition.

Examples of spectrograms representing the sound data produced by different activities. Source: www.gierad.com/projects/ubicoustics/
1.4.3 Social good
There is a rising fear in the consequences of using machine learning to solve certain problems, for example, in the justice system; however, there is also a lot of potential of using it for social good.
Either it be for animal protection or to prevent deforestation, the applications of machine learning in this space are very exciting.
Some projects aim to protect endangered species like the killer whales (also known as orcas) in the Salish Sea, from British Columbia to Washington State. With only about 73 of them left, Google partnered with Fisheries and Oceans Canada (DFO), as well as Rainforest Connection, to track and monitor orca’s behavior using deep neural networks.
Teaching a machine learning model to recognize orca sounds, it can then detect the presence of the animal and alert experts in real time. This type of system can help monitor the animals’ health and protect them in the event of an oil spill, for example.
Another project by Rainforest Connection aims to prevent illegal deforestation using machine learning and used cell phones.
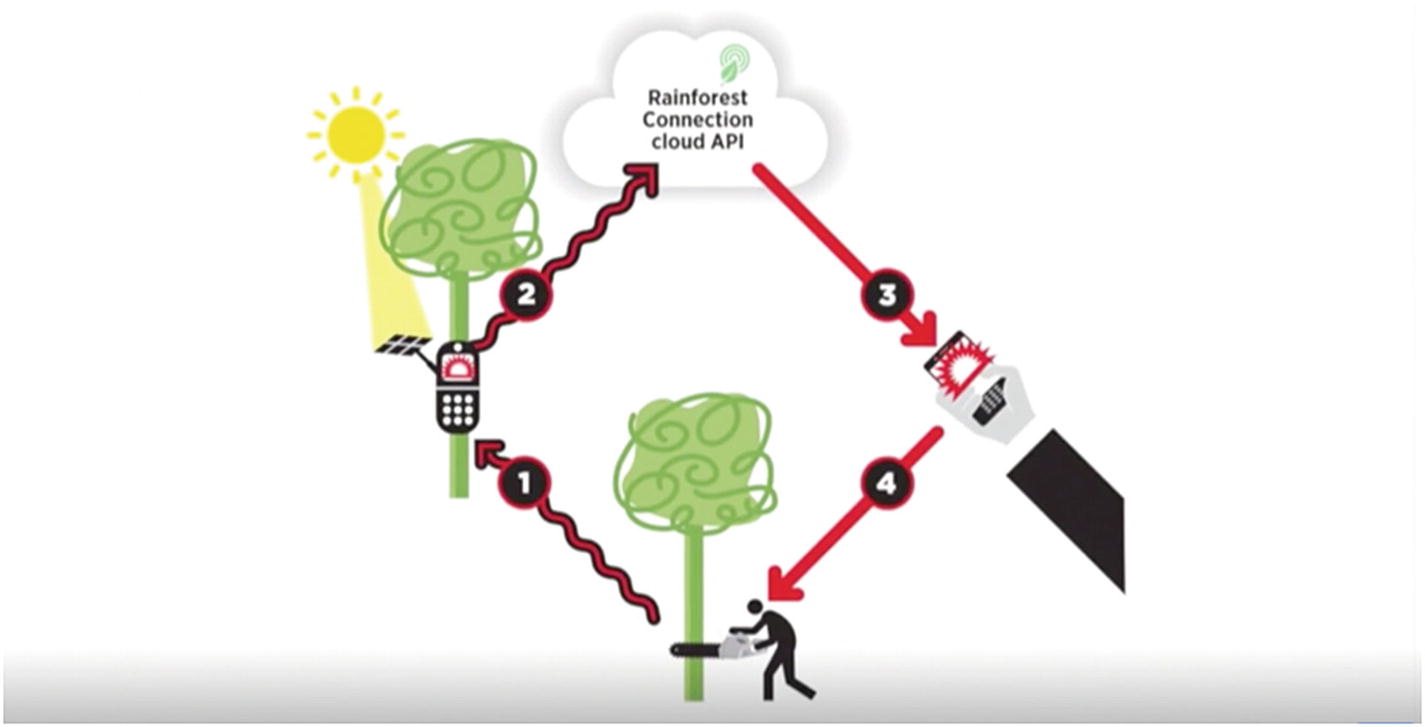
Visual representation of how the Rainforest Connection project against illegal deforestation works. Source: www.ted.com/talks/topher_white_what_can_save_the_rainforest_your_used_cell_phone#t-289131
There are plenty more interesting projects focusing on leveraging the possibilities of machine learning to help social causes. Even though this is not the focus of this book, I encourage you to do further research if this is something you would like to contribute to.
1.4.4 Art
Art might not be your first concern when wanting to learn more about machine learning; however, I really think its importance is deeply underrated in the field of technology.
Art very often experiments with the latest technological innovations much faster than any other field.
Monitoring how machine learning is used in creative ways can give us an idea of how far the technology can go.
Not only is it important to expose yourself to the work of artists, but I would also recommend trying to build creative applications yourself.

Sample from art project “Learning to See” by Memo Akten. Source: www.memo.tv/portfolio/gloomy-sunday/
Creativity can help you identify new use cases, opportunities, and limits of the tools you are using.
Especially in a field like machine learning, where so many things are still unknown, there is a vast potential to come up with new ideas of what is possible.
Some examples of machine learning used in creative ways are in the work of artists like Memo Akten. In his project “Learning to See,” he uses deep neural networks and a live camera input to try to make sense of what it sees, in the context of what it has seen before.
A model has been trained with images of oceans. It is given a new input from a camera feed (on the left), analyses it, and tries to understand its meaning based on the training data it was fed with. The outcome is what it “sees,” how the model understands the new input, in the context of what it knows.
Another example is the work from the Magenta team at Google, working on building machine learning models that can generate pieces of music by themselves. Such work can revolutionize the way humans use technology in music production.
1.5 Summary
After introducing some of the general theoretical concepts of machine learning, it is time to start diving into some more practical content and talk about how to get started building AI projects as a front-end developer.