
Phases of Continuous Delivery for Machine Learning. Source: https://martinfowler.com/articles/cd4ml.html
Types of engineers per phase.

Components of a machine learning system. Source: https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
Standard TFX pipeline

Example schema. Source: www.tensorflow.org/tfx/guide/schemagen
Components of a machine learning system. Source: https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning

Example of test pyramid. Source: https://martinfowler.com/articles/cd4ml.html
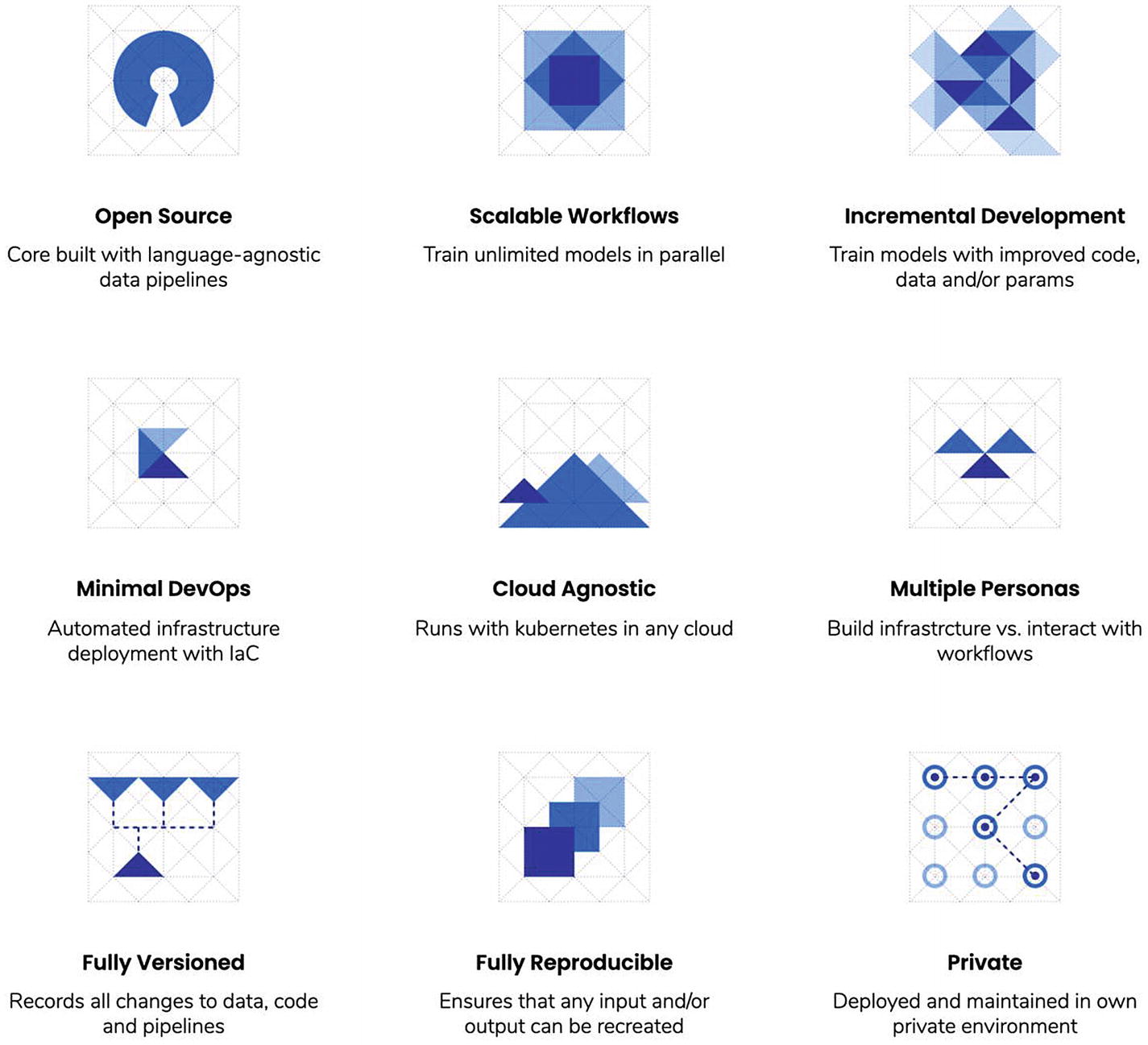
Features of kaos. Source: https://ki-labs.com/kaos/#features
Before we start, it is important to know that this chapter is not going to be a deep dive into how to set up a machine learning pipeline yourself using Kubernetes clusters, configuring load balancers, and so on, as this is in general a task taken on by a DevOps or infrastructure teams. However, it is important to understand the challenges that come with productionizing machine learning models, so we are instead going to explain some of them, as well as introduce a few different tools that should help you add machine learning in your production applications if you do not have the opportunity to work with a dedicated team.
6.1 Challenges
Putting machine learning in production creates a different set of challenges than the ones we might have had so far.
In the personal projects we have built in this book, we were the only user and we were running everything locally. We were more in a proof-of-concept phase. In production, not only an application will be used by hundreds, thousands, or even millions of users, it will also be built by multiple teams. As a result, your system will have to be able to adapt and handle more challenges.
6.1.1 Scalability
The purpose of putting machine learning models in production is to make it part of the application your users are interacting with every day. As a result, it should be able to handle a potential large amount of requests.
Either it be for a startup or a large corporation, running machine learning models requires a lot of CPUs, GPUs, and RAM, meaning you will have to make sure your system can support running the model for all users.
6.1.2 High availability
Most web applications you have worked on and will work on are expected to be available 24/7 to serve user requests.
If you decide to add machine learning models to these systems, they will also need to have a high availability.
No matter if you decide to update a model, scale it to a wider audience, or test new tools, it is very important to make sure the model is still running properly as you experiment.
6.1.3 Observability
The systems we work on are very volatile. Things can change very fast in many ways. Your user interface changes as you release new features, spikes of users can happen in different geographical locations, third-party providers can fail, and so on.
Such volatility means that models and their predictions should be watched closely. Not only is it about verifying that the model is not failing to generate predictions, it is also about regularly checking if the inputs and outputs are correct.
6.1.4 Reusability
Depending on the models you have built and are running in your application, it is sometimes important to think about their reusability.
For example, the company booking.com runs multiple models in production including one to determine if a hotel is family-friendly.
Based on different criteria, a model can highlight family-friendly hotels in both the details page of a hotel or as a filter in the results page. Similarly to how different UI components can be reusable across a front-end application, building your models so they can be reused on different pages can ensure that you are making the most of them.
Creating and testing a machine learning model being a time-consuming task, model reutilization makes this investment more productive.
Moreover, reusability ensures that models can be shared between different teams facing similar problems and can avoid wasting time re-creating models from scratch.
Now that we’ve briefly covered a few of the challenges presented by productionizing machine learning models, let’s look into the life cycle of a ML project.
6.2 Machine learning life cycle
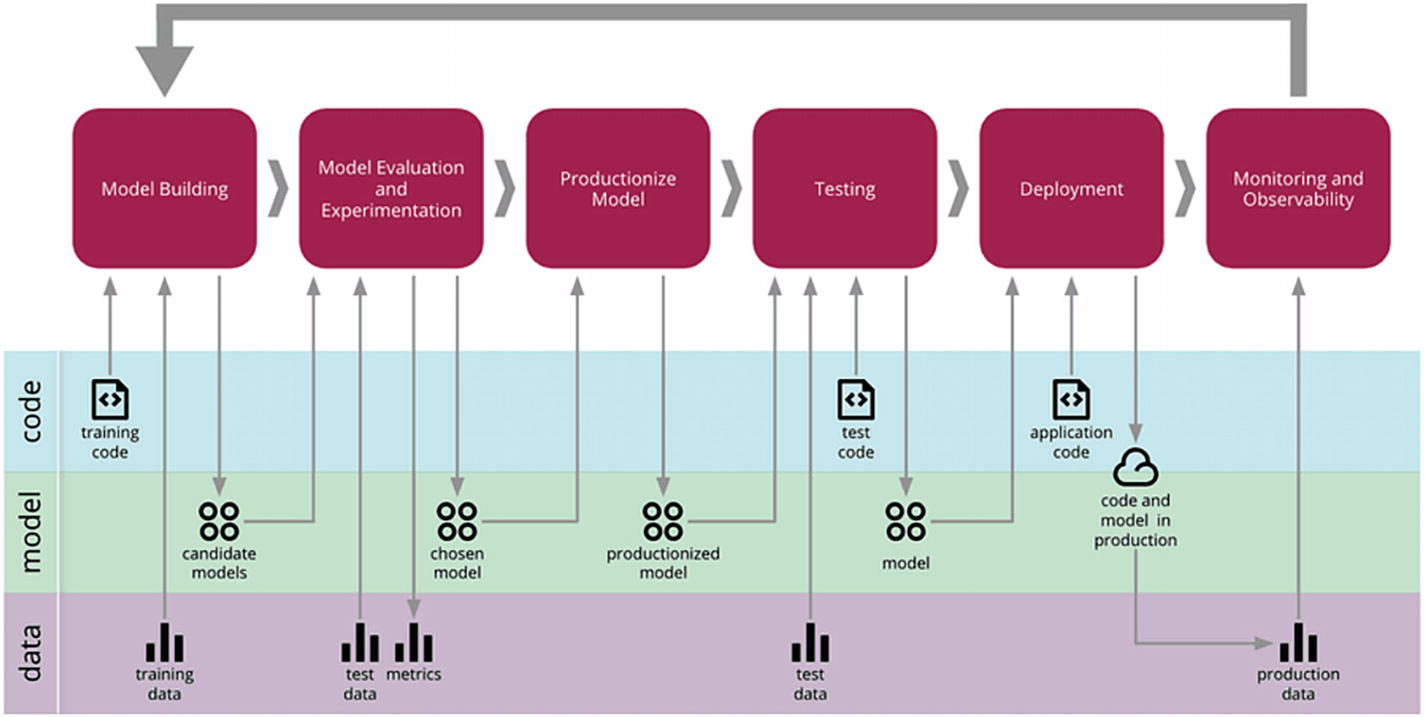
The following diagram is a visual guide for the concept of Continuous Delivery for Machine Learning (CD4ML) popularized by Martin Fowler.
In this diagram, we can see outlined six different phases:
Model building is about understanding the problem, preparing the data, extracting features, and writing the initial code to create the model.
Model evaluation and experimentation is about selecting features, hyperparameter tuning, comparing algorithms, and overall experimenting with different solutions.
Productionizing the model is the step that goes from experimentation or research to preparing it for deployment.
Testing focuses on ensuring that the model and the code we are about to deploy to production behave as we expect, and that the results match the ones observed during the second phase of evaluation and experimentation.
Deployment is getting the model into production.
Finally, monitoring and observability is about ensuring that the model behaves as expected in the production environment.
One of the main differences between a standard software project life cycle and a machine learning project is in the way these phases should repeat.
As the arrow suggests from the last phase (Monitoring and Observability) back to the first one (Model Building), we should make decisions about our models based on information collected after seeing how it behaves in production.
Models should be updated or abandoned based on this information.
Based on your application, your model needs to be regularly retrained with new data to avoid becoming obsolete.
For example, a platform like AutoScout24 that helps users sell their vehicles online uses machine learning to predict the price range at which people should sell their car, based on a few parameters including the brand, the year of production, and the model.
If they do not retrain their model regularly with real user data, their prediction will quickly be out of date and not represent the real value of their users’ vehicle on the market. As a result, people could either undersell or struggle to sell their car because the prices are not adjusted to the current market.
This cycle that retrains the model with new data can be done manually or automatically.
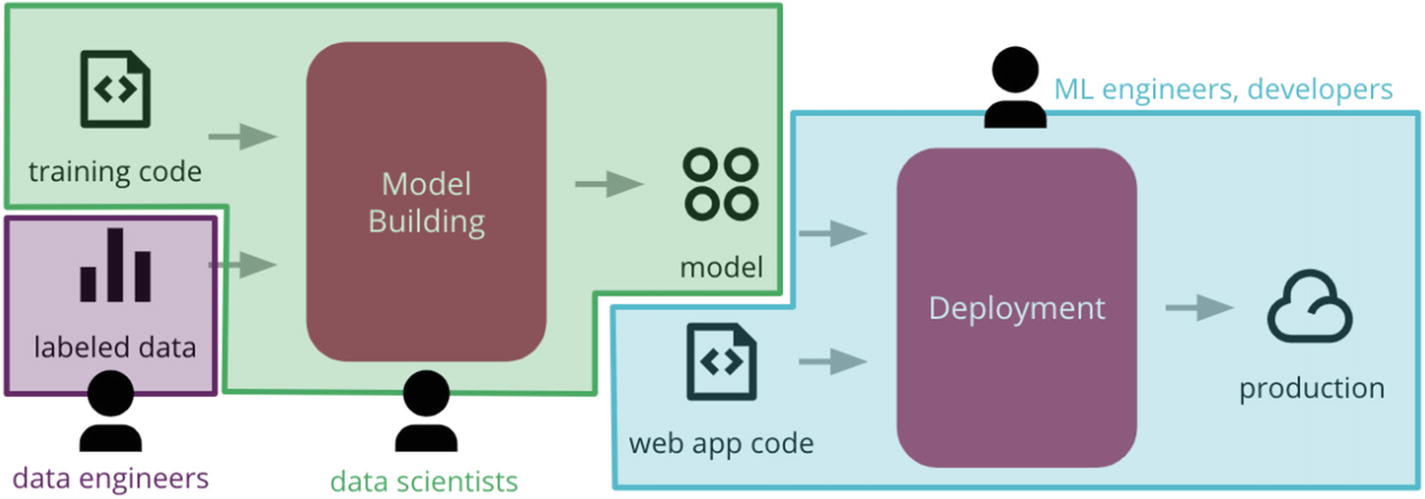
Also, not all of these phases have to be executed by the same engineers.
The first two phases of model building and experimentation can and/or should be done by data scientists or machine learning engineers. The following phases should be undertaken by DevOps engineers or software engineers with experience in deploying applications to production, like the following image illustrates.
Seeing how different parts of this life cycle are separated by types of engineer leads us to talk about machine learning systems
6.3 Machine learning systems
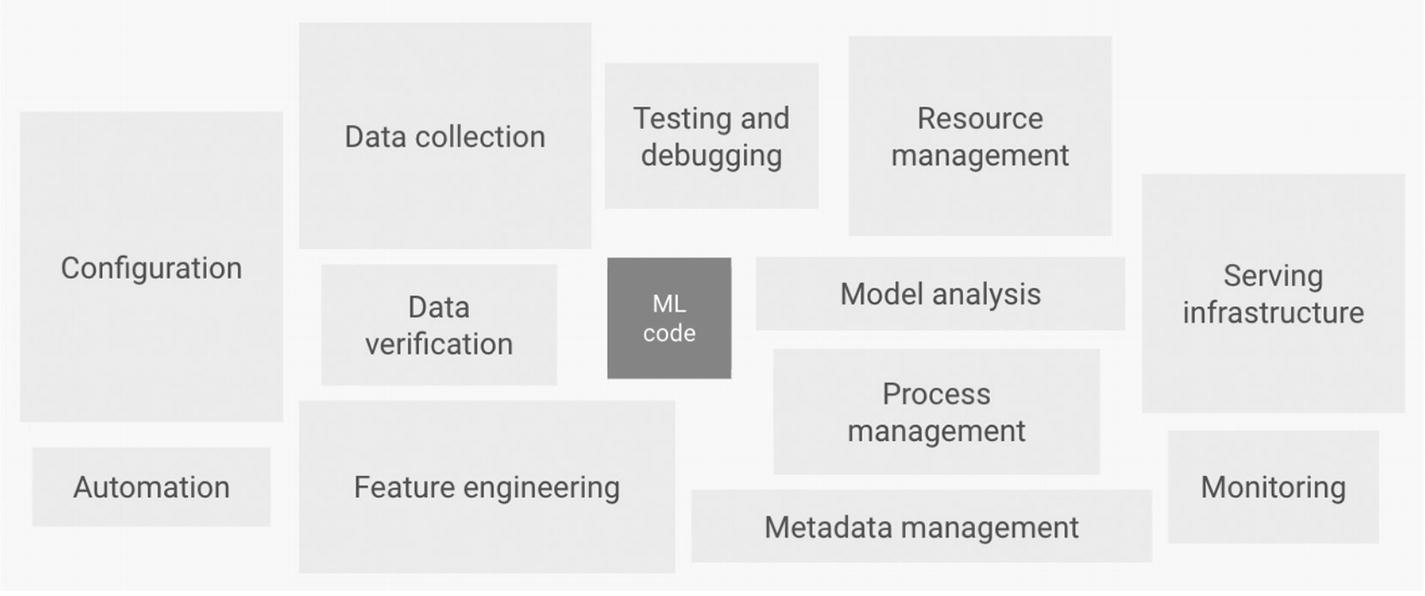
In this book, we have talked a lot about how to use pre-trained models and generate predictions; however, machine learning systems are made up of a lot more components.
For example, if you cannot find a pre-trained models for your application and decide to create your own, you will also need to think about data collection, verification, feature extraction, and monitoring, as the following figure shows.
Using a machine learning model in production requires you to set up a certain pipeline.
Not only your model needs to be served, but you will need to think about how to collect new data and retrain your model so it does not become obsolete, how and what to monitor, and so on.
Luckily, you do not need to build all of these components yourself. Platforms like TensorFlow Extended (TFX) offer an end-to-end solution for deploying production ML pipelines.
TFX includes different components that can help you set up a machine learning pipeline like TensorFlow Data Validation to help you understand your data, TensorFlow Transform to help you preprocess your data and convert it between formats as needed, and TensorFlow Serving to support model versioning and ensuring high performance with concurrent models.
The benefit of using such platforms is that most of your ML pipeline can be set up in a single platform, reducing complexity in the setup and maintenance, as well as being able to leverage the work of dedicated teams at Google, to give you more confidence in the performance and reliability of your system.
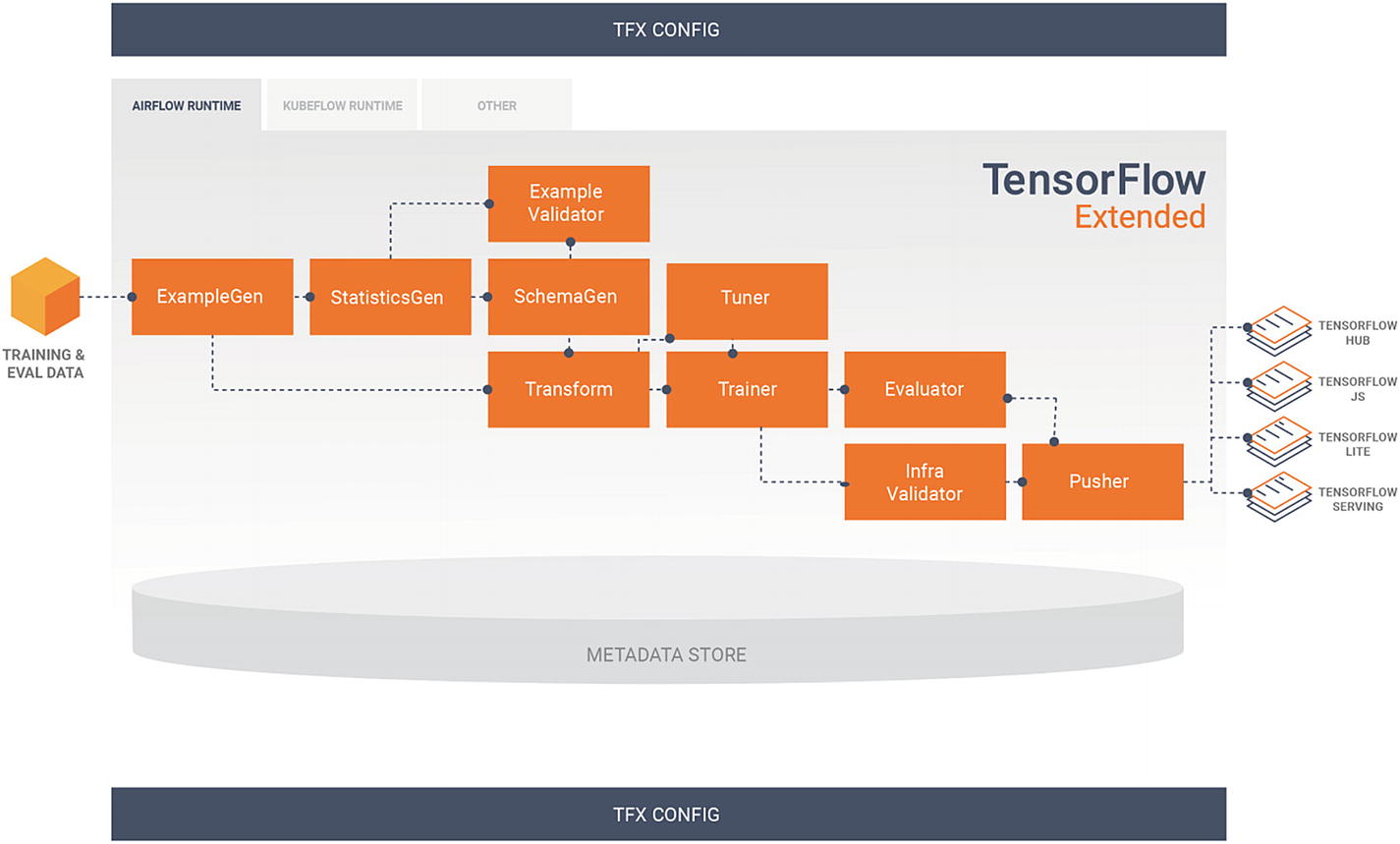
The following is an example of a typical TFX pipeline.
First, ExampleGen is the initial input component that consumes external files and ingests the data into the pipeline.
StatisticsGen is in charge of calculating statistics for the dataset that will be used to generate a schema.
SchemaGen generates the schema that contains information about your input data, for example, data types for each feature or if the feature has to be present every time. An example of what a schema could look like is shown in the following image.
ExampleValidator is used to identify anomalies in the training data.
Transform will actually use the schema generated from the SchemaGen component and perform feature engineering on the data emitted from ExampleGen to generate a SavedModel instance that will be used by the following component.
Trainer uses the Python TensorFlow API to train models.
Tuner does hyperparameter tuning, meaning it chooses a set of optimal parameters to use with a model.
Evaluator performs analysis on the results of your model to ensure that it is good to be pushed to production.
InfraValidator is responsible for validating the model in the model serving infrastructure. It launches a sand-boxed model server with the model and checks if it can be loaded and queried.
Pusher is the component pushing a validated model to a deployment target.
If this seems a bit complicated, it is totally normal. As I mentioned at the beginning of this chapter, I would not expect any person reading this book to understand straight away all the components needed in a machine learning pipeline.
As it is unlikely that you will have to set one up yourself, this information is mainly presented so you get an idea of the components involved in setting up a system when working with deploying a custom model.
Now that we briefly went over what a standard TFX pipeline looks like, let’s go back and talk about pipelines more broadly. What are the necessities of building a pipeline?
If we look back at the image at the beginning of this section, the machine learning code to create the model actually represents a very small portion of the system.
The rest is composed of elements such as data collection, automation, testing, analysis, and so on, where you need to apply DevOps principles to ML systems.
This kind of system works similarly to a software system in the sense that you need it to be reliable and have short development cycles but differs in the following ways:
Diversity of skills: If you work on a production application that uses machine learning models, your team will likely involve data scientists that will need to interact with the system but may not have experience or knowledge of software practices. Your system will have to take this into account by having components ML researchers can use.
Model serving : There seems to be three different ways to serve models in production. It can either be done with an embedded model where you treat it as a dependency packaged with the application, a model as a service (MAAS) where the model is wrapped in a separate service that can be deployed and updated independently, and a model as data where the model is also independent but ingested as data at runtime.
Experiment tracking : Machine learning models go through a lot of experimentation before being pushed to production, resulting in a lot of the code being thrown away and never being deployed. As a result, it is important to keep track of the different experiments being undertaken to avoid repeating them.
Monitoring: Even though monitoring and logging systems are usually also used in standard software projects, monitoring machine learning models is a bit different. Not only do we need to monitor that the model generates predictions when given input data, we also need to capture data about how our model is behaving using the following metrics – model inputs (track what data is being fed to the model), interpretability of outputs (understanding how models are making predictions), model outputs themselves, and model fairness (analysis outputs for bias).
Testing : Different types of tests can be introduced in a machine learning workflow. We can test the model quality by looking at error rates and accuracy, the validity of the data by comparing it to schemas generated, or even attempt to test model bias and fairness. The following is an example of test pyramid for machine learning systems.
Even though this kind of system might be the responsibility of an infrastructure team, as a developer, you should still be involved in setting up a way for the application to interact with the model.
How to write an API that will generate predictions from the model?
How to best deploy that API to production?
What kind of data needs to be collected?
What information should the API return?
Now that we briefly covered the different components of a machine learning system, let’s go through some of the tools currently available to make the use of machine learning in production easier.
6.4 Tools
In this last section, we are going to quickly cover some tools you can use if you want to add machine learning in a production application without having to set up a complex system.
6.4.1 Pre-trained models
Hopefully, after going through the projects in this book, you are familiar with using pre-trained models with TensorFlow.js.
So far, we used the MobileNet image classification model, PoseNet, the Toxicity Classifier, speech commands, Facemesh, Handpose, and the Question Answering model; however, there are a few more.
Indeed, if you decide to explore further, you will see that there also exist a face landmark detection model, an object detection model, a body segmentation model, and a few more.
However, pre-trained models do not have to be developed by the TensorFlow.js team to be usable with TensorFlow.js.
Keras models typically created using Python can be saved in different formats and converted to TensorFlow.js Layers format to be loaded with the framework.
As a result, if you find an open source model you are interested in working with, feel free to check if it can be converted to the format that works with TensorFlow.js so you can load it in a JavaScript application.
6.4.2 APIs
To make it easier for developers to implement machine learning in production applications, technology companies like Amazon, Google, and Microsoft have been working on developing ML services available as APIs .
For example, Amazon currently has multiple APIs for services including image and video analysis, personalized recommendations, real-time translation, advanced text analysis, chatbots, and fraud prevention.
Comprehend for advanced text analysis
CodeGuru for automated code reviews
Lex for chatbots
Textract for document analysis
Detector for fraud prevention
Recognition for image and video analysis
Polly for text to speech
Vision AI: To get image insights, detect objects, faces, and text
Video intelligence API: To recognize objects, places, and actions in stored and streaming video
Speech-to-text API: To accurately convert speech into text
And Microsoft has a suite of tools called Cognitive Services with APIs including a content moderator service, a QnA Maker, a speaker recognition service that can identify and verify the people speaking based on audio, and similar APIs around image and text recognition.
6.4.3 Serving platforms
Finally, if you are more interested in building and serving a custom model, here are some tools that aim at making it simpler.
The Google Cloud AI platform as well as Amazon Web Services and Microsoft offer more complete solutions for you to serve your custom machine learning projects; however, other model serving platforms can be found such as the open source BentoML, Seldon, or kaos by KI labs.
Even though teams may be tempted to rely on tools from Google, Microsoft, or Amazon, these platforms do not often give you the freedom you may want in picking your tooling. They optimize for the use of their own offerings and sometimes make it complicated to integrate with other third-party tools.
Besides, depending on the size of your application, using these platforms may be overengineering.
Overall, there are multiple options available when it comes to productionizing machine learning models. However, as this is still something most companies are not doing, the standards are not set and will probably evolve. As a result, if this is an area you are interested in learning more about, you should definitely do some extra research and experimentation.