
In my opinion, this book would not be complete without mentioning the topic of bias in machine learning.
As we give the ability to computers to generate predictions and rely on them in production applications that people will interact with, it is essential to spend some time thinking about the consequences and impact of using this technology.
In this last chapter, we are going to talk about the different types of biases, why this is an issue and what can be done to minimize it in our machine learning systems.
7.1 What is bias?
a strong feeling in favour of or against one group of people, or one side in an argument, often not based on fair judgement.
—Quote source: www.oxfordlearnersdictionaries.com/definition/english/bias_1?q=bias
Confirmation bias: This can happen when the person performing the data analysis wants to prove a predetermined assumption and will intentionally exclude particular variables from an analysis until it comes to the wanted conclusion.
Selection bias or sample bias : This happens when the sample of data used is not a good reflection of the population.
Prejudice bias : Result of training data that is influenced by cultural or other stereotypes. For example, if we train an algorithm to recognize people at work based on images found online, a lot of them show men coding, for example, and women in the kitchen. As a result, the model will be predicting men as being more likely coders and women cook, which is incorrect and replicating biases found online.
If you are not familiar with the topic of bias in machine learning, you might be wondering why it is a problem.
Humans are biased in many ways; we can make unfounded assumptions about people or situations that can lead to discrimination. However, when this bias makes it into products or systems used in our daily lives and developed to make decisions for us and about us, this can have terrible widespread consequences that should not be ignored.
Let’s look at some examples.
7.2 Examples of bias in machine learning
Over the next couple of pages, we are going to look at two examples of situations where biased machine learning models were used in real applications.
7.2.1 Gender bias
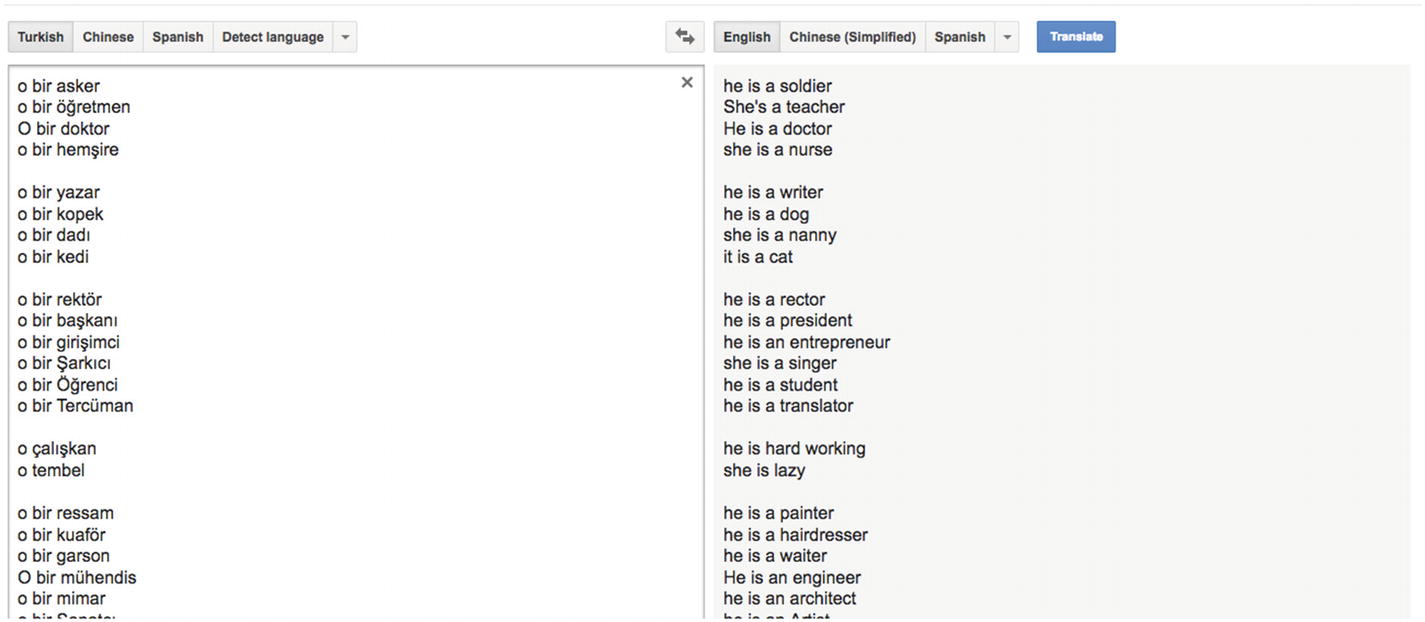
Google Translate showing biased results
As you can see in the preceding image, even though the Turkish language did not specify a certain gender for each term, Google Translate guessed a particular one, resulting in stereotypes such as matching the word “doctor” with the pronoun “he” and the word “nurse” with “she”.

Google Translate showing results with multiple pronouns
Even though this is an improvement, the fault was not necessarily on the algorithm itself but most likely due to the fact that the data used to train it probably contained biased information.
Besides, displaying both “she” and “he” pronouns does not take into account people who use the pronoun “they”, which should be included to achieve better fairness.
7.2.2 Racial bias
One of the most impactful examples of biased machine learning algorithm used in the past few years is with a software powered by AI called COMPAS.
This software has been used by judges in courtrooms to generate risk assessments and forecast which criminals are most likely to reoffend based on responses to 137 survey questions.
The issue with using this algorithm is that it was discovered that, when it was wrong about its predictions, the results were displaying differently for black and white offenders.

COMPAS software results
The fact that such erroneous predictions were used in the justice system is already a serious issue, but the scale at which it was used makes this even more concerning.
Considering the United States imprisons a large number of people each year, one can only imagine the amount of incorrect convictions.
Besides, as the company behind COMPAS, called Northpointe, refused to disclose the details of their algorithm, it made it impossible for researchers to evaluate the extent of its unfairness.
These are only two examples of situations where bias can be introduced in machine learning algorithms. There are unfortunately plenty more and I would recommend to dive deeper into the topic.
7.3 Potential solutions
Even though bias in machine learning cannot be completely eradicated, there are a few options to minimize it.
7.3.1 Framing the problem
Before working on building a model and generating predictions, data scientists need to decide what problem they are trying to solve. It is already at this stage that some bias can be found. If you are building a model for a credit company that wants to automatically evaluate the “creditworthiness” of people, there are already decisions made around the concept what defines someone who is worthy of getting a credit that might embed some unfairness and discrimination.
For example, a company can decide that it wants to maximize its profit margins, meaning creditworthiness will be based on how rich a client is as they will probably contract bigger loans. Otherwise, it can also decide that it would rather focus on maximizing the amount of loans contracted, no matter if clients can afford them or not.
Overall the issue lies within the fact that these decisions are made with business objectives in mind, and not fairness, even though they will end up impacting real people in many ways.
If an algorithm predicted that the giving subprime loans was an effective way to maximize profit, the company would end up engaging in predatory behavior even if it wasn’t the direct intention.
7.3.2 Collecting the data
This may be a more frequent example of how bias makes its way into machine learning models and can show up in two ways.
Incorrect representation of reality
You may have heard of cases where collecting data that was unrepresentative of reality caused a machine learning model to generate incorrect predictions.
For example, in face recognition, if an algorithm is trained with more images representing people with light-skinned faces than dark-skinned faces, the model created will inevitably be better at recognizing light-skinned faces.
To try to prevent this kind of discrimination, analyzing the data you are using before feeding it to an algorithm will give you an idea of its quality and its potential in generating more fair predictions.
In general, if you decide to use a pre-trained model, there should be a link documented for you to have a look at the dataset used. If you cannot find it, I would request it to the company or person sharing the model.
If you are unable to verify the quality of the data, I would advise to find a different model.
If you found the original dataset and noticed that it was lacking diversity and was not a good representation of reality, you could either decide not to use the model trained using this data, or you could decide to leverage it, collect some additional, more diverse data, and apply transfer learning to generate a new, less biased model to use in your application.
If you take the route of collecting your own data and not rely on some existing model, I would advise to start by analyzing what diversity means in your particular case, what problem is your model going to solve, who will it be used on, what sources are you planning on using to collect the data, are these sources representative of reality, and so on.
The analysis work is essential to raise potential issues or concerns early and build a model that will minimize the perpetuation of biases.
Reflection of existing prejudices
A second issue when it comes to collecting data is in using some that contains existing prejudices.
Some companies use some of their internal historical data to train machine learning models to automate tasks.
For example, a couple of years ago in 2018, Amazon realized that their internal AI recruiting tool was biased against women.
They had been using data gathered for the past 10 years of job applications to rate new candidates from 0 to 5 stars. However, as most people hired to work at Amazon were males, the model had deduced that male candidates were preferable.
Looking at historical hiring data and analyzing thousands of resumes, the model’s logic was that Amazon did not like resumes with the word “women” in it.
As a result, any resume that was containing this word, for example, “Captain of the women’s team” or “Studied at a women’s college,” was getting a lower rating than the ones not mentioning it.
Even though this made the news in 2018, Amazon had realized its new system was not rating candidates in a gender-neutral way, since 2015.
A way to prevent this type of discrimination is related to the section earlier, analyzing the data you are using. The fact that data is internal does not mean it is unbiased. However, considering that this data had been collected over the past 10 years, we can agree that it might be too much data to analyze manually. I would still advise to collect a random set of samples and have people assess their fairness and diversity.
Besides, when using a model for a task as important as hiring, I would hope that some testing of the model was done before using it. Bias in hiring is a well-known issue and can take many forms. As a result, if you decide to build or use a recruitment software that relies on machine learning, I would advise to test it for different biases, from gender to educational background, to ethnicity, and so on.
7.3.3 Data preparation
Another place where bias can be introduced is when preparing the data. Even if you have analyzed your data and made sure that it is diverse and represents the reality of the environment it is going to be used for, the preparation stage also needs some attention.
This phase involves selecting attributes you want your algorithm to consider when learning and generating predictions and can be described as more of an art than a science.
Often, some experimentations with attributes and parameters are needed to fine-tune a model.
However, you also need to make sure that reaching high accuracy does not also introduce bias. While the impact of experimenting with attributes on accuracy is measurable, its impact on bias isn’t.
In the case of the recruitment tool at Amazon, attributes could have been candidates’ gender, education level, years of experience, programming languages, geographical location, and so on.
For the purpose of hiring someone as an engineer, for example, a person’s gender should not matter at all so should be omitted as an attribute to train the model.
A person’s geographical location would only matter if the company cannot sponsor visas to relocate.
As a result, to maximize fairness, a model trained to rank candidates should take into consideration attributes impacting their skill level, including years of experience and programming languages.
It could also use education level, but this could introduce some bias toward people who have had the privilege of getting higher education.
In the technology industry, many very good developers have not taken the path of getting a computer science degree, so using this as an attribute could result in ranking people lower even though, in practice, they possess the right skills and would be great employees.
Hopefully this example demonstrates how important the data preparation phase is, no matter if you have already spent some time making sure the dataset you are using is diverse.
7.3.4 Team diversity
Finally, minimizing bias in machine learning also lies in the makeup of the teams working on developing models.
We all have biases, and an efficient way to mitigate diversity deficits is in improving diversity in your teams.
You can imagine that issues found in facial recognition models would have been prevented if the teams working on them included more non-white people.
Not only would this help in testing the predictions of a model to make sure their accuracy is high across a diverse set of faces, it would also improve the overall process.
Previous phases of framing the problem, collecting, and preparing the data would benefit from people with different backgrounds, life experiences, and so on. Potential issues could be raised early and influence the development of a more fair model while still working toward high accuracy.
Not only is this an ethical challenge but also a technical one. How good really is a facial recognition model if it’s mostly accurate when used on light-skinned people? If the goal of machine learning is to develop models with the highest accuracy, then the real technical challenge is in high accuracy across a diverse set of samples.
7.4 Challenges
Unfortunately, even though the previous section stated a few of the potential solutions to reduce bias in machine learning, this issue is a difficult one to fix and will probably still be present for a while.
In this section, we are going to go through a few challenges of mitigating bias.
Unknowns
It can be unclear where bias was introduced in a system. Even if you work with a diverse dataset, make sure to use attributes that do not alter the fairness of the predictions; it is sometimes difficult to understand how a model generated a certain result.
In the case of Amazon and its gender-biased recruiting tool, once they realized that the model was picking up words like “women’s” to rank candidates lower, they updated their model to ignore explicitly gendered words; however, that was not enough. They later discovered that the updated system was still picking up on implicitly gendered words that were more commonly found on men’s resumes, such as “executed” and “captured”, and was using this to made decisions.
Fairness is relative
Another challenge when it comes to bias in machine learning is around the fact that not everyone agrees on what is considered fair or unfair. Unfortunately, more work has been done on the technical side than on the ethics side of AI, so there are no real standards, regulations, and policies at this point when it comes to designing ethical AI applications.
Be socially beneficial
Avoid creating or reinforcing unfair bias
Be built and tested for safety
Be accountable to people
Incorporate privacy design principles
Uphold high standards of scientific excellence
Be made available for uses that accord with these principles
Even though these are a good start, we should hope that governments will soon provide real regulations around the development and use of machine learning models and how to assess their fairness, so we can hope to avoid the widespread implementation of biased systems.
In this chapter, we covered briefly some examples of situations where biased machine learning models were used and the consequences, as well as some possible solutions.
If you are interested in learning more about this topic, I would highly recommend you read the books Weapons of Math Destruction by Cathy O’Neil and Algorithms of Oppression by Safiya Noble, in which the authors cover this fascinating subject in much more depth.