
P A R T 1
![]()
Introducing Microsoft SQL Server 2008
C H A P T E R 1
![]()
New Feature Overview
The release of Microsoft SQL Server 2008 has introduced many new features that increase scalability, manageability, availability, programmability, and security across the enterprise. With many organizations focused on consolidation and virtualization, this couldn't have come at a better time. As the demand for data keeps growing and security and compliance keep tightening, the role of the database administrator (DBA) has become an increasingly critical part of the organization. It is important for every DBA to have a good understanding of the tools available to help maintain a highly available, secure environment.
This book will cover the techniques you need to understand in order to implement and manage a successful database environment. After a brief overview of some of the enhancements, you will learn how to make intelligent decisions when choosing an installation or upgrade path. You will also learn how to manage a secure and consistent database environment by implementing policies across the organization. By learning how to automate tedious administrative tasks, you will be able to focus on more important tasks, like performance tuning, which will also be covered in detail. Finally, we will be looking to see what the future holds for database administration along with giving you the resources necessary to excel as a DBA.
This chapter will present an overview of several new features available in SQL Server 2008. Although the main focus of the book is database administration, having a basic understanding of many of the new features available in SQL Server is essential to effectively managing a successful database environment. That being said, some topics are introduced here only to give you an awareness of their existence, while others have an enormous impact on database administration and will be covered in great detail throughout the book.
Figure 1-1 shows the same expanded view of the Management Studio Object Explorer in SQL Server 2005 (left) and SQL Server 2008 (right). Even at a quick glance, you can see there are several new features available in SQL Server 2008. You should also note that there are a couple of features in the SQL Server 2005 Object Explorer that are no longer in SQL Server 2008, such as the Activity Monitor and the Full-Text Search service. The functionality has not been removed; it has just been relocated. To start the Activity Monitor, you now have to right-click on the SQL Server instance and select it from the context menu. The Full-Text Search service is now fully managed using the SQL Server Configuration Manager.
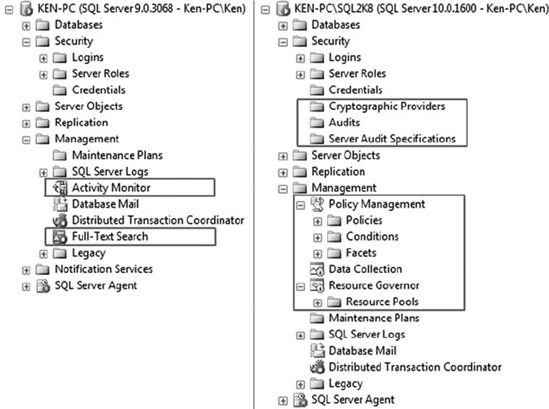
Figure 1-1. Available features in the Management Studio Object Explorer when using SQL Server 2008 (right) compared to SQL Server 2005 (left)
Scalability Enhancements
Scalability seems to be a word we keep hearing more and more these days. Companies want to get the most they can out of their hardware, and query performance plays a major role. The more efficiently SQL Server can execute a query, the more queries it can execute against the given hardware. Scalability enhancements can be categorized into three key areas: filtered indexes and statistics, table and query hints, and query performance and processing.
Filtered Indexes and Statistics
Filtered indexes are non-clustered indexes that can be created on a defined subset of rows within a table. If you've ever wanted to index only some of the rows in a table, now you can. For example, if you have a field that stores a wide variety of dates, and your application only queries dates after 1975, you can create an index that includes only those dates. Creating a filtered index will reduce the disk space required to store the index, as well as the time it takes to rebuild the index.
Filtered statistics are automatically created for filtered indexes, but you can also create filtered statistics independently in order to optimize a query plan on a subset of rows. The ability to create filtered indexes and statistics ultimately leads to more efficient queries in addition to reduced index maintenance and storage overhead.
Table and Query Hints
A few improvements have been made in SQL Server 2008 to enhance common table and query hints. The OPTIMIZE FOR query hint has been enhanced by adding the UNKNOWN option. When you use the OPTIMIZE FOR query hint by itself, the query optimizer optimizes a query based on the initial value assigned to a local variable. When you supply the UNKNOWN option, you instruct the query optimizer to use statistical data to determine the value for a local variable instead of using the initial value during the optimization phase.
The capability to use table hints as query hints has also been added in SQL Server 2008. The new FORCESEEK table hint has also been added, which allows you to force an index seek on a table in the execution plan. The FORCESEEK table hint is useful when a query plan may be using an index scan to access the data, causing an excessive number of reads.
Query Performance and Processing
Several enhancements have been made in SQL Server 2008 to improve query performance and processing. You can use some of the enhancements to find and tune process-intensive queries, while the others provide an automatic benefit courtesy of the query optimizer.
- The
LOCK_ESCALATIONoption has been added to theALTER TABLEstatement to allow you to disable lock escalation on the table. Disabling lock escalation can greatly reduce lock contention on partitioned tables, as it will allow you to configure locks to escalate to the partitions instead of to the whole table. - You can use Dynamic Management Views (DMVs) to return hash values for similar queries. Finding similar hash values will allow you to locate and tune similar queries by comparing execution plans.
- Plan guides can now accept XML Showplan output as a parameter, which simplifies the process of applying a fixed query plan. A few new system functions and counters have been added for plan guides as well.
- Parallel query processing has been improved to provide an automatic benefit when querying partitioned tables and objects.
- Optimized bitmap filtering automatically improves data warehouse queries by removing non-qualifying rows early in a query plan.
Manageability Enhancements
There have been some nice features added in SQL Server 2008 to enhance your management capabilities. You can use many of the new features, such as SQL Server Audit and the Data Collector, to provide you with more insight into your servers. In addition, you can use features, such as Policy-Based Management and the Resource Governor, to attain greatly needed granular control over your environment.
Auditing
SQL Server Audit is a new feature that captures data for a specific group of server or database actions. Audits can be defined using event actions or by using action groups, which is a predefined group of actions. SQL Server Audit uses extended events to capture data, such as CPU utilization and deadlocks. The extended events method is used by the server to capture generic events. In certain situations, you can use extended events to correlate events between SQL Server, the application, and the operating system (OS). You can save the event results to a target destination, such as a text file, Windows security log, or Windows application log.
Change Data Capture
Change Data Capture is a feature that can be used to capture insert, update, and delete statements applied to a table. The data being inserted, updated, or deleted is captured in a format that mirrors the original table along with metadata explaining the action. Change Data Capture is useful when managing a data warehouse environment. For example, you can enable Change Data Capture on a large table that is used to feed a reporting server. The changes to the large table will then be captured in a separate table, and instead of processing an entire dataset every time you want to update the reporting server, you only have to process the data in the table that is tracking the changes.
Change Tracking
Change Tracking allows you to capture information about row changes in a table. Unlike Change Data Capture, Change Tracking does not capture the data that was changed. Change Tracking does, however, capture the Data Manipulation Language (DML) information about the change along with columns that were affected. The primary key is the only data element that is captured as a result of Change Tracking. Change Tracking has to be enabled at the database level and can then be enabled on specified tables. Enabling Change Tracking has no impact to the table definition, and no triggers are created on the table being tracked. Change Tracking functions are used in order to retrieve the information about the changes and can be incorporated into standard Transact-SQL (T-SQL) statements.
Backup Compression
Backup compression is a long awaited feature that is now available in SQL Server 2008 right out of the box. Although you need Enterprise Edition to create a compressed backup, you can restore a compressed backup in any edition of SQL Server 2008.
Backing up a database using backup compression takes significantly less time because fewer pages have to be written to disk. While this sounds good, the trade-off is higher CPU usage while the backup is being compressed. However, you can regulate CPU usage by using the Resource Governor to run the backup in a low-priority session.
The percentage of disk space saved by using backup compression depends on the type of data being compressed. Dividing the backup_size and compressed_backup_size columns in the backupset table in the msdb database will allow you to calculate the percentage of disk space savings. Since encrypted data usually doesn't have high compression ratios, using backup compression with Transparent Data Encryption will likely be ineffective and not worth the CPU hit.
Data Collector
The Data Collector is a component in SQL Server 2008 that allows you to collect data across database servers and store the information in a central location known as the management data warehouse. The management data warehouse is a relational set of tables that can be used to store data collected from a variety of sources. The type and frequency of the data collection is completely configurable and can be viewed using a collection set report in SQL Server Management Studio. Data sources must be configured for data collection, and data can come from various places, such as DMVs, performance monitor (PerfMon) counters, and SQL traces. The Data Collector comes with three system collection sets: disk usage, server activity, and query statistics. Although you can configure custom collection sets as well, the need for this will be rare due to the extensive amount of metrics that can be gathered using the predefined system collection sets.
Central Management Servers
You can create a central management server in SQL Server 2008 in order to maintain a collection or grouping of servers, much like registered servers in previous versions. Unlike registered servers, the server you designate as a central management server stores all of the information about the participating servers in the msdb database. Since the information is stored in the msdb database, you can share the collection of servers contained in the central management server among all the DBAs in the organization. When you register a server using a central management server, you must use Windows authentication (username and passwords are not allowed).
One of the major benefits you gain when using a central management server is the ability to execute a single query against all of the registered servers in a server group. You can configure the result set to include each server name along with the login name that executed the query. You can also configure the query results to be returned as multiple independent result sets or merged and returned as a single result set. Using a central management server also provides you with the capability to create and evaluate policies across a server group, which is essential when using Policy-Based Management to administer your environment.
Policy-Based Management
You can now use SQL Server Management Studio to create policies to manage objects in SQL Server. A policy consists of two parts: a check condition and a filter condition. The check condition is the condition the policy is actually validating, and the filter condition specifies the target object for the policy.
Administrators can either force target objects to comply with a given policy and rollback the changes, or allow the policy to be violated and review the violations later. You can create custom policies or import one of the predefined policies provided by Microsoft that corresponds with Best Practice Analyzer rules and default settings in the Surface Area Configuration tool. For example, you can import a predefined policy that will allow you to check the data and log file location, the database AutoShrink configuration, and even the last successful backup date.
Resource Governor
Resource Governor is a new feature that can be used to limit the amount of CPU and memory used by predefined requests to the database. Min and Max settings can be used to limit the resources in a resource pool. The interesting thing about the Resource Governor is that if no CPU or memory pressure is detected by the server, the Max threshold will be ignored. As soon as another query comes along with a higher priority, the Resource Governor will throttle lower priority work down to the Max settings, as needed, to relieve pressure. It is a good idea to always leave the Min settings at zero because the Resource Governor will reserve the minimum amount of defined CPU and memory even if it is not needed.
PowerShell
PowerShell is a powerful scripting tool that allows database administrators to write more robust scripts when T-SQL may not be a viable solution. PowerShell is now integrated into SQL Server 2008 and can even be executed in a job step using SQL Server Agent. Select PowerShell as the step type and insert the script, just as you would with T-SQL or an ActiveX script. There is an extensive script library located at http://powershell.com/ that includes several SQL Server scripts along with many other system-related scripts that can help you manage your environment.
Availability Enhancements
Availability is becoming more of a concern with many organizations wanting to achieve four and five nines. Since achieving four nines allows for less than one hour of downtime per year and achieving five nines allows for less than six minutes per year, living up to this type of expectation is not an easy task. There have been improvements in many areas, including database mirroring, clustering, and peer-to-peer replication to help achieve this goal. Some enhancements in SQL Server 2008 even have a positive impact on availability, even though availability is not their primary function. For example, while backup compression was primarily added to SQL Server to provide space savings and reduced backup times, it also reduces the time it takes to restore a database, which ultimately leads to less downtime if a disaster is encountered.
Database Mirroring
Database mirroring was introduced in SQL Server 2005 to provide highly available redundant databases. Database mirroring has been given performance enhancements in SQL Server 2008, through it can now automatically recover from corrupted pages.
Automatic recovery from a corrupted page consists of one mirroring partner requesting the unreadable page from the other. If a query is executed that contains data that resides on a corrupted page, an error will be raised and a new page will be copied from the mirror to replace the corrupted page. In most cases, by the time the query is executed again, the page will have been restored from the mirror, and the query will execute successfully.
One of the most prominent performance enhancements is stream compression between the principal and the mirror server to minimize network bandwidth. This feature will add more value to networks having latency issues by reducing the amount of traffic that is being sent between servers. If you have a high-speed network with plenty of bandwidth, the effects of stream compression may hardly be noticeable at all. Your server may experience higher CPU utilization as a result of stream compression because it takes more cycles to compress and decompress the files. Also, the server will be processing more transactions per second, requiring more CPU cycles.
Log send buffers are used more efficiently by appending log records of the next log-flush operation to the most recently used log cache if it contains sufficient free space. Write-ahead events have been enhanced by asynchronously processing incoming log records and log records that have already been written to disk. In a failover, read-ahead during the undo phase is enhanced by the mirror server sending read-ahead hints to the principal to indicate the pages that will be requested so the principal server can put it in the copy buffer.
Clustering
The SQL Server clustering installation process has changed from SQL Server 2005 where you only ran the install on one node and the binaries were pushed to the other node. In SQL Server 2008, you install a one-node cluster and then run the install on the other nodes, adding them one by one. Any time you want to add or remove a node, the setup is run from the node that is being added or removed, thus reducing the need for downtime. This approach also allows for rolling upgrades, service packs, and patches.
Several changes have been made in Windows Server 2008 to enhance failover clustering. While these are not necessarily SQL Server changes, SQL Server does reap the benefits. The new Windows Server 2008 Cluster Validation tool allows you to run through validation tests on your cluster configuration to ensure the cluster is configured correctly without having to search the hardware compatibility list (HCL) to ensure the server configuration will be supported. Windows Server 2008 also supports up to 16 node clusters, enabling SQL Server 2008 to take full advantage of this architecture.
![]() Caption While Windows Server 2008 no longer requires clustered nodes to be on the same subnet, this feature is not currently supported in SQL Server 2008.
Caption While Windows Server 2008 no longer requires clustered nodes to be on the same subnet, this feature is not currently supported in SQL Server 2008.
Peer-to-Peer Replication
The concept of peer-to-peer replication was introduced in SQL Server 2005 so that multiple servers could act as both a publisher and subscriber while maintaining a full, usable dataset. In SQL Server 2008, you now have the ability to add and remove nodes without impacting the application. The capability to detect conflicts prevents issues such as application inconsistency that may have otherwise been overlooked. The Topology Wizard allows for visual configuration, while improved replication monitoring eases replication management.
Hot-Add CPU
It is now possible to hot-add CPUs to SQL Servers that reside on compatible hardware. This is a critical addition to the ability to hot-add memory, introduced in SQL Server 2005. Combining both of these features increases the ability to perform hardware changes without impacting the application or more importantly the end user. This also supports a pay-as-you-grow scenario, allowing you to add hardware resources as they become necessary. This provides flexibility when capacity planning and budgeting, allowing minimal hardware to be deployed in order to meet the needs of the current workload instead of purchasing and deploying additional hardware up front on a system that may or may not need the extra resources.
Programmability Enhancements
Several programming enhancements have been added to SQL Server 2008. New data types allow for a more granular and precise storage, including date, time, and spatial data. The addition of the user-defined table type is a key new feature that enables passing entire tables to procedures and functions by implementing another new feature, known as table-valued functions. Full-Text Search has undergone an architecture overhaul, enabling it to be a fully integrated database feature.
Some manageability improvements also apply to programming. Unstructured data, such as images and documents, are now supported by using FILESTREAM to store the data on the file system. Partition switching is another useful feature that allows you to quickly switch your partition from one table to another while maintaining data integrity.
A couple of new features allow you to take advantage of space savings. Rarely used columns can be defined as sparse columns and will not use any space to store NULL data in the data pages or the indexes. Compressed storage of tables and indexes allows both row and page compression for tables and indexes. Several T-SQL enhancements have been made as well. The INSERT statement has been enhanced with a new feature called row constructors that allows you to specify multiple INSERT sets in the VALUES clause. The new MERGE statement allows you to perform an INSERT, UPDATE, or DELETE in a single statement based on the results of a JOIN. GROUPING SETS is a new operator that allows you to generate the union of multiple, pre-aggregated result sets. Let's not forget about variables; they can now be declared and set in the same operation while the use of compound operators make for simplified code logic.
![]() Note The primary focus of this book is on administration, and we will not be going into great detail with T-SQL. Thus we will demonstrate a few of the concepts previously listed, as the new syntax may be used in code samples throughout the book.
Note The primary focus of this book is on administration, and we will not be going into great detail with T-SQL. Thus we will demonstrate a few of the concepts previously listed, as the new syntax may be used in code samples throughout the book.
Variables
When it comes to working with variables, a few enhancements have been made that align variable usage in SQL Server with other programming languages, such as VB.Net and C#. You can now declare and initialize your variables in a single line of code. You can also take advantage of compound operators when using variables in mathematical operations. Both of these new variable enhancements result in shorter, cleaner, and altogether more elegant code.
- Variable initialization: The following sample allows you to declare and set your variables with a single line of code (
Declare @x int = 1). - Compound operators: Compound operators allow you to perform mathematical operations on a variable without having to reference the variable twice. Table 1-1 shows a sample of how you would use the new compound operator syntax along with the equivalent syntax prior to SQL Server 2008.
| Compound Operator | SQL Server 2005 |
Set @x+=1 |
Set @x = @x + 1 |
Set @x-=1 |
Set @x = @x − 1 |
Set @x*=2 |
Set @x = @x * 2 |
Putting it all together, Table 1-2 shows a simple code sample that performs a loop, increments a variable, and prints the output. The table shows the code sample for both SQL Server 2005 and SQL Server 2008. The SQL Server 2008 version is very similar to the code you would see in VB.Net.
Transact-SQL Row Constructors
Row constructors provide a syntax enhancement to the INSERT statement, allowing multiple value lists to be supplied, provided each value list is separated from the previous one by a comma. Listing 1-1 demonstrates a code sample that uses three different methods to insert three records into the @DateRecords table variable. The reason we say that row constructors are a syntax enhancement is that, while you will get better performance using row constructors over multiple INSERT statements, the row constructor sample in Listing 1-1 will produce exactly the same execution plan as the UNION ALL method. Thus the enhancement is one of syntax more than of performance.
Listing 1-1. Row Constructors Compared to Prior Methods of Inserting Multiple Rows
DECLARE @DateRecords TABLE (RecordID int, StartDate Datetime)
--Multiple inserts using UNION ALL
INSERT INTO @DateRecords
SELECT 1,'1/1/2008'
UNION ALL
SELECT 2,'1/2/2008'
UNION ALL
SELECT 3,'1/3/2008'
--Multiple inserts using single statements
INSERT INTO @DateRecords VALUES(4,'1/4/2008')
INSERT INTO @DateRecords VALUES(5,'1/5/2008')
INSERT INTO @DateRecords VALUES(6,'1/6/2008')
--Multiple inserts using row constructors
INSERT INTO @DateRecords
VALUES(7,'1/7/2008'),
(8,'1/8/2008'),
(9,'1/9/2008')
--Display INSERT results
SELECT * FROM @DateRecords
Table-Valued Parameters
Table-valued parameters are exposed through the new user-defined table type in SQL Server 2008. Table-valued parameters provide an easy way to pass an entire dataset or table to functions and procedures. This prevents you from having to loop through a dataset calling a stored procedure multiple times for each row in the dataset.
Following are some of the benefits from using table-valued parameters:
- Does not acquire locks for the initial population of data from a client
- Reduces round trips to the server
- Supports unique constraints and primary keys
- Strongly typed
Alas, most good things come with a price. When you use table-valued parameters, keep the following restrictions in mind:
- SQL Server does not maintain statistics on columns of table-valued parameters
- Parameters are passed to the routines as
READONLYvalues - Cannot be the target of a
SELECT INTOorINSERT EXECstatement
Listing 1-2 provides an example of all the steps needed to create and execute a table-valued function. First, we do some cleanup work just in case we run the script multiple times, but the real work begins in the second section of the script where we create the user-defined table type CustomerPreferenceTableType. Once we have the user-defined table type, we create the CustomerPreferences_Insert stored procedure, which accepts a parameter that we defined using the CustomerPreferencesTableType data type. Next, we create a variable that uses the CustomerPreferencesTableType data type, load some sample data to the variable, and then execute the CustomerPreferences_Insert stored procedure passing the variable we just created. Finally, we query the CustomerPreferences table to show that multiple records were actually inserted into the table with only a single call to the insert stored procedure.
Listing 1-2. Sample Script Demonstrating the Use of Table-Valued Parameters
USE tempdb
--1. Prep work
--Drop objects
IF OBJECT_ID('CustomerPreferences') IS NOT NULL
DROP TABLE CustomerPreferences;
GO
IF OBJECT_ID('CustomerPreferences_Insert') IS NOT NULL
DROP PROCEDURE CustomerPreferences_Insert;
GO
IF EXISTS (SELECT * FROM sys.types st
JOIN sys.schemas ss
ON st.schema_id = ss.schema_id
WHERE st.name = N'CustomerPreferenceTableType'
AND ss.name = N'dbo')
DROP TYPE [dbo].[CustomerPreferenceTableType]
GO
--Create table to hold results from procedure
CREATE TABLE CustomerPreferences
(CustomerID INT, PreferenceID INT)
GO
--2. Create table type
CREATE TYPE CustomerPreferenceTableType AS TABLE
( CustomerID INT,
PreferenceID INT );
GO
--3. Create procedure
CREATE PROCEDURE CustomerPreferences_Insert
@CustomerPrefs CustomerPreferenceTableType READONLY
AS
SET NOCOUNT ON
INSERT INTO CustomerPreferences
SELECT *
FROM @CustomerPrefs;
GO
--4. Execute procedure
--Table variable
DECLARE @CustomerPreference
AS CustomerPreferenceTableType;
--Insert data into the table variable
INSERT INTO @CustomerPreference
Values (1,1),(1,2),(1,3);
--Pass the table variable data to a stored procedure
EXEC CustomerPreferences_Insert @CustomerPreference;
--View the results inserted using the table-valued function
SELECT * FROM CustomerPreferences
MERGE Statement
You can use the MERGE statement to perform INSERT, UPDATE, or DELETE actions in a single statement based on the results of a TABLE JOIN. This functionality is very useful when writing stored procedures that insert records into a table if they do not exist, and update records if they do exist. You can use the optional OUTPUT clause to return information about which operation actually occurred.
![]() Note The
Note The MERGE statement must be terminated with a semicolon, or you will receive an error message during execution.
Listing 1-3 shows three executions of a MERGE statement. Execute the listing on your own system, and take some time to understand the results. It may help to execute each MERGE statement individually so that you can see the effect of each. You can view the results in Figure 1-2.
Listing 1-3. Three Different Uses of the MERGE Statement
--Prep work
DECLARE @DateRecords TABLE (RecordID int, StartDate Datetime)
INSERT INTO @DateRecords VALUES(1,'1/1/2008'),
(2,'1/2/2008'),
(3,'1/4/2008'),
(5,'1/5/2008')
--Display original dataset
SELECT * FROM @DateRecords ORDER BY RecordID
--Sample UPDATE WHEN MATCHED
MERGE @DateRecords AS Target
USING (Select '1/4/2008') as Source (StartDate)
ON (Target.StartDate = Source.StartDate)
WHEN MATCHED THEN
UPDATE SET StartDate = '1/3/2008'
WHEN NOT MATCHED THEN
INSERT (RecordID, StartDate)
VALUES (4,'1/4/2008')
OUTPUT deleted.*, $action, inserted.*;
--Display changed result set
SELECT * FROM @DateRecords ORDER BY RecordID
--Sample INSERT WHEN NOT MATCHED
MERGE @DateRecords AS target
USING (Select '1/4/2008') as Source (StartDate)
ON (target.StartDate = Source.StartDate)
WHEN MATCHED THEN
DELETE
WHEN NOT MATCHED THEN
INSERT (RecordID, StartDate)
VALUES (4,'1/4/2008')
OUTPUT deleted.*, $action, inserted.*;
--Display changed result set
SELECT * FROM @DateRecords ORDER BY RecordID
--Running the same query again will result
--in a Delete now that the record exists.
MERGE @DateRecords AS target
USING (Select '1/4/2008') as Source (StartDate)
ON (target.StartDate = Source.StartDate)
WHEN MATCHED THEN
DELETE
WHEN NOT MATCHED THEN
INSERT (RecordID, StartDate)
VALUES (4,'1/4/2008')
OUTPUT deleted.*, $action, inserted.*;
--Display changed result set
SELECT * FROM @DateRecords ORDER BY RecordID
The first record set in Figure 1-2 shows the original result set we will be working with prior to using any MERGE statements. The second record set shows the actions that took place as a result of the first MERGE statement in the script and is returned by adding the OUTPUT clause to the MERGE statement. As you can see, since a match was found between the target and the source, RecordID 3 was updated from 1/4/2008 to 1/3/2008. If no match was found between the target and the source, 1/14/2008 would have been inserted into the target. You can see that this is exactly what occurred by viewing the new query results displayed in the third record set. You can apply the same logic to the remaining record sets to follow the chain of events that occur throughout the script in Listing 1-3.
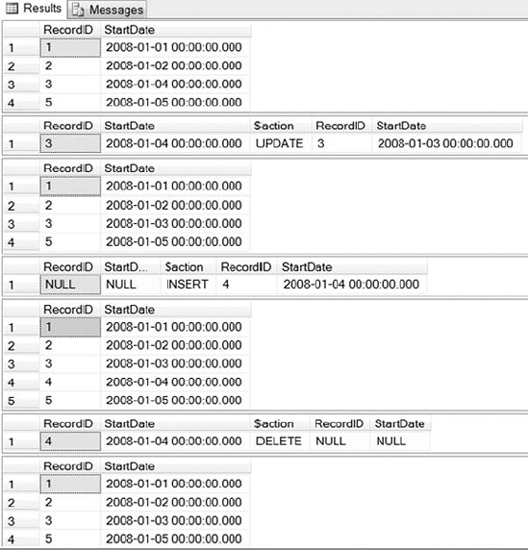
Figure 1-2. Results returned using the script in Listing 1-3
GROUPING SETS Operator
The script we will be reviewing in Listing 1-4 covers the new GROUPING SETS operator. This new operator allows you to group aggregated result sets that would normally be accomplished by combining the results of two GROUP BY statements using UNION ALL. As you can see in Listing 1-4, the code is much cleaner using GROUPING SETS rather than using the alternative UNION ALL syntax. You can view the results of Listing 1-4 in Figure 1-3. We have only included the result sets returned using GROUPING SETS, since the UNION ALL queries would only produce duplicate results.
Listing 1-4. Script Demonstrating the New GROUPING SETS Operator
DECLARE @DateRecords TABLE (RecordID int, StartDate Datetime)
INSERT INTO @DateRecords
VALUES(1,'1/1/2008'),
(2,'1/2/2008'),
(3,'1/4/2008'),
(4,'1/4/2008')
--GROUP BY using GROUPING SETS
SELECT RecordID, StartDate
FROM @DateRecords
GROUP BY GROUPING SETS (RecordID, StartDate)
--Equivalent to the previous query
SELECT NULL AS RecordID, StartDate
FROM @DateRecords
GROUP BY StartDate
UNION ALL
SELECT RecordID, NULL AS StartDate
FROM @DateRecords
GROUP BY RecordID, StartDate
--Include all records by using MAX
SELECT MAX(RecordID) MaxRecordID, MAX(StartDate) MaxStartDate
FROM @DateRecords
GROUP BY GROUPING SETS (RecordID,StartDate)
--Equivalent to the previous query
SELECT MAX(RecordID) MaxRecordID, StartDate
FROM @DateRecords
GROUP BY StartDate
UNION ALL
SELECT RecordID, MAX(StartDate)
FROM @DateRecords
GROUP BY RecordID, StartDate
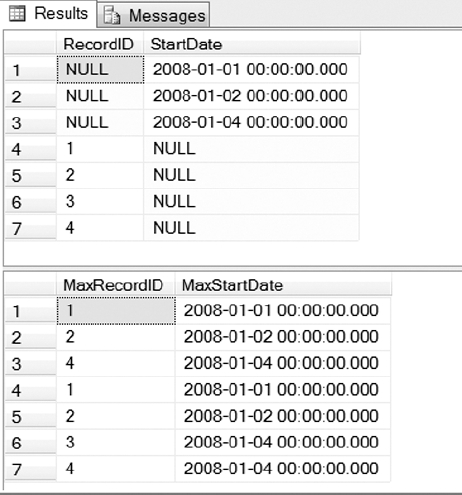
Figure 1-3. Results returned using the new GROUPING SETS operator in Listing 1-4
Listing 1-5 provides the new ROLLUP and CUBE syntax introduced in SQL Server 2008. You should make sure to use the new syntax whenever writing new code and change any existing code whenever possible because the old syntax has been deprecated and will be removed in a future release. There is also a new GROUPING_ID function you can use to return more information about the grouping level than you can get with the existing GROUPING function. The results of Listing 1-5 can be seen in Figure 1-4.
Listing 1-5. New Syntax Used with ROLLUP, CUBE, and GROUPING_ID
DECLARE @DateRecords TABLE (RecordID int, StartDate Datetime)
INSERT INTO @DateRecords
VALUES(1,'1/1/2008'),
(2,'1/2/2008'),
(3,'1/4/2008'),
(4,'1/4/2008')
--Old ROLLUP deprecated syntax
SELECT MAX(RecordID) MaxRecordID, StartDate
FROM @DateRecords
GROUP BY StartDate WITH ROLLUP
--New Syntax
SELECT MAX(RecordID) MaxRecordID, StartDate
FROM @DateRecords
GROUP BY ROLLUP(StartDate)
--New GROUPING_ID function
SELECT RecordID, StartDate, GROUPING_ID(RecordID,StartDate) GroupingID
FROM @DateRecords
GROUP BY CUBE(RecordID, StartDate)
ORDER BY GROUPING_ID(RecordID,StartDate)
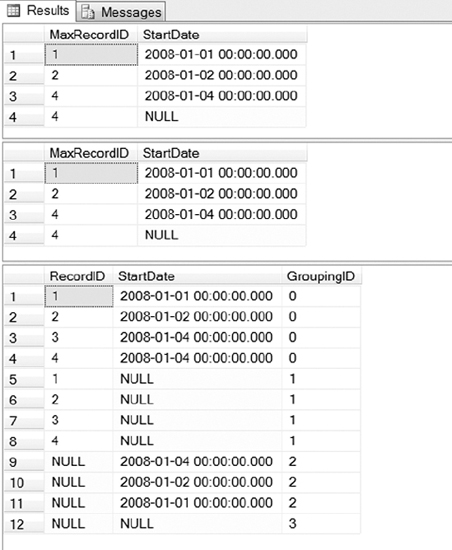
Figure 1-4. Query results returned by Listing 1-5
Security Enhancements
Microsoft has made some key additions to security management by introducing the new Transparent Data Encryption and Extensible Key Management technologies. These new features along with the auditing enhancements are an integral part of meeting the growing compliance needs of the organization.
Transparent Data Encryption
Transparent Data Encryption enables the database administrator to store the data, log, and backup files in a secure manner by automatically encrypting and decrypting the data as it is read from and written to the disk. The database uses a database encryption key, and without the correct certificate, the data files or the backups cannot be restored to another server. This process is implemented at the data layer and is transparent to front-end applications. This does not mean that the data is encrypted between the application and the server, only the pages containing the data on the server.
Extensible Key Management
Extensible Key Management provides an enhanced method for managing encryption keys. It enables third-party software vendors to provide and manage keys by supporting hardware security module (HSM) products that can be registered and used with SQL Server. This provides many advantages, including the physical separation of data and keys.
Summary
As you can see, SQL Server 2008 is a feature-heavy release. There are several enhancements that not only make database administration easier, but that would be almost impossible to implement in earlier releases without purchasing third-party tools. Many of the features presented in this chapter require the Enterprise Edition of SQL Server 2008 in order to take full advantage of their functionality. A breakdown of features by edition will be provided in the next chapter, where we will be going over decisions that need to be made before a SQL Server install. Many of these new features will change the way DBAs manage data by removing limitations and providing the more industrial level tools needed to meet today's business needs. It's perfectly acceptable to drive a nail with a hammer, but we sure would rather use a nail gun to build a house.