
C H A P T E R 3
![]()
Choosing a High-Availability Solution
High availability has become an increasingly popular subject in SQL Server. Not only have there been entire books dedicated to high availability, but we have seen specialized books written on each topic that falls under the high-availability umbrella. Needless to say, we will not be going into great detail here, but it is important to understand how each of SQL Server's high-availability solutions can play a role in your environment. This chapter will give an overview of each solution to help differentiate what factors play a role in designing the best, overall solution for your organization. By the end of this chapter, you should be armed with the information necessary to make an informed decision on the best usage scenarios for each high-availability technique offered in SQL Server 2008.
What Exactly Is High Availability Anyway?
First of all, it is important to understand what high availability actually means. The terms high availability and disaster recovery are often confused or thought of as the same thing. Just because you have implemented a high-availability solution does not mean that you are prepared for a disaster. High availability generally covers hardware or system-related failures, while disaster recovery (DR) can be used in the event of a catastrophic failure due to environmental factors. While some of the high-availability options may help you when designing your DR strategy, they are not the be-all and end-all solution.
The goal of high availability is to provide an uninterrupted user experience with zero data loss; but high availability can have many different meanings, depending on who you ask. According to Microsoft's SQL Server 2008 Books Online, “a high-availability solution masks the effects of a hardware or software failure and maintains the availability of applications so that the perceived downtime for users is minimized.” (For more information, see http://msdn.microsoft.com/en-us/library/bb522583.aspx.) Many times users will say they need 100% availability, but what, exactly, does that mean to the user? Does being 100% available mean that the data is 100% available during business hours, Monday through Friday, or that the data is available 24/7? High availability is about setting expectations and then living up to them. That's why one of the most important things to do when dealing with high availability is to define those expectations in a Service Level Agreement (SLA) that can be agreed upon and signed by all parties involved.
Some of the things you should cover in the SLA are maintenance windows, the amount of recovery time allowed to bring the system back online due to a catastrophic failure, and the amount of acceptable data loss, if any. Defining a maintenance window allows you to apply service packs, patches, and upgrades to the system to ensure optimal performance and maintain compliance. Having a maintenance window allows you to do this in a tested and planned fashion. A drop-dead time should be determined so that a back out plan can be executed if problems are encountered, ensuring system availability by the end of the maintenance window.
Defining the amount of time allowed to recover from a disaster along with the maximum allowed data loss will help you determine what techniques you may need to use to ensure that your SLAs are met. Every organization wants 100% availability 100% of the time; but when presented with the cost of a system that would even come close to achieving this goal, they are usually willing to negotiate attainable terms. It is important to have an understanding of what it means for a system to be unavailable. Is it a minor inconvenience because users within your organization will not be able to log their time, or are you losing thousands of dollars in revenue every hour the system is down? Answering these kinds of questions will allow you to justify the cost of an appropriate solution. Each high-availability method brings unique characteristics to the table, and unfortunately there is no cookie-cutter solution. In the next few sections, we will discuss the individual techniques used to achieve your high-availably needs.
Failover Clustering
Failover clustering is a technique that uses a cluster of SQL Server instances to protect against failure of the instance currently serving your users. Failover clustering is based on a hardware solution comprised of multiple servers (known as nodes) that share the same disk resources. One server is active and owns the database. If that server fails, then another server in the cluster will take over ownership of the database and continue to serve users.
Key Terms
When discussing high availability, each technique has its own set of key terms. At the beginning of each section, we will list the terms used for each solution. Here are some of the terms you need to be familiar with when setting up a failover cluster:
- Node: Server that participates in the failover cluster.
- Resource group: Shared set of disks or network resources grouped together to act as a single working unit.
- Active node: Node that has ownership of a resource group.
- Passive node: Node that is waiting on the active node to fail in order to take ownership of a resource group.
- Heartbeat: Health checks sent between nodes to ensure the availability of each node.
- Public network: Network used to access the failover cluster from a client computer.
- Private network: Network used to send heartbeat messages between nodes.
- Quorum: A special resource group that holds information about the nodes, including the name and state of each node.
Failover Clustering Overview
You can use failover clustering to protect an entire instance of SQL Server. Although the nodes share the same disks or resources, only one server may have ownership (read and write privileges) of the resource group at any given time. If a failover occurs, the ownership is transferred to another node, and SQL Server is back up in the time it takes to bring the databases back online. The failover usually takes anywhere from a few seconds to a few minutes, depending on the size of the database and types of transactions that may have been open during the failure.
In order for the database to return to a usable state during a failover, it must go through a Redo phase to roll forward logged transactions and an Undo phase to roll back any uncommitted transactions. Fast recovery is an Enterprise Edition feature that was introduced in SQL Server 2005 that allows applications to access the database as soon as the Redo phase has completed. Also, since the cluster appears on the network as a single server, there is no need to redirect applications to a different server during a failover. The network abstraction combined with fast recovery makes failing over a fairly quick and unobtrusive process that ultimately results in less downtime during a failure.
The number of nodes that can be added to the cluster depends on the edition of the operating system (OS) as well as the edition of SQL Server, with a maximum of 16 nodes using SQL Server 2008 Enterprise Edition running on Windows Server 2008. Failover clustering is only supported in the Enterprise and Standard Editions of SQL Server. If you are using the Standard Edition, you are limited to a 2-node cluster. Since failover clustering is also dependant on the OS, you should be aware of the limitations for each edition of the OS as well. Windows Server 2008 only supports the use of failover clustering in its Enterprise, Datacenter, and Itanium Editions. Windows Server 2008 Enterprise and Datacenter Editions both support a 16-node cluster, while the Itanium edition only supports an 8-node cluster.
In order to spread the workload of multiple databases across servers, every node in a cluster can have ownership of its own set of resources and its own instance of SQL Server. Every server that owns a resource is referred to as an active node, and every server that does not own a resource is referred to as a passive node. There are two basic types of cluster configurations: a single-node cluster and a multi-node cluster. A multi-node cluster contains two or more active nodes, and a single-node cluster contains one active node with one or more passive nodes. Figure 3-1 shows a standard single-node cluster configuration commonly referred to as an active/passive configuration.
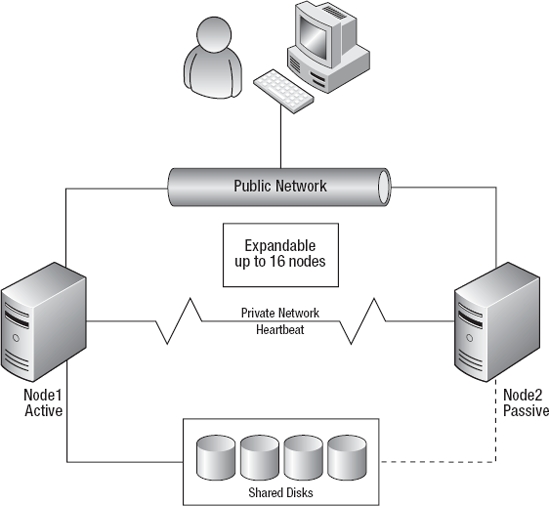
Figure 3-1. Common single-node (active/passive) cluster configuration
So if multiple active nodes allow you to utilize all of your servers, why wouldn't you make all the servers in the cluster active? The answer: Resource constraints. In a 2-node cluster, if one of the nodes has a failure, the other available node will have to process its normal load as well as the load of the failed node. For this reason, it is considered best practice to have one passive node per active node in a failover cluster. Figure 3-2 shows a healthy multi-node cluster configuration running with only two nodes. If Node 1 has a failure, as demonstrated in Figure 3-3, Node 2 is now responsible for both instances of SQL Server. While this configuration will technically work, if Node 2 does not have the capacity to handle the workload of both instances, your server may slow to a crawl, ultimately leading to unhappy users in two systems instead of just one.
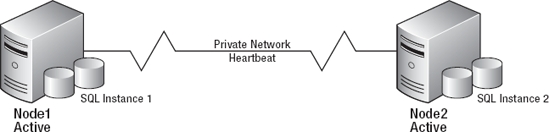
Figure 3-2. Multi-node (active/active) cluster configuration
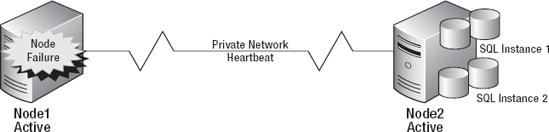
Figure 3-3. Multi-node (active/active) cluster configuration after failure
So, how does all of this work? A heartbeat signal is sent between the nodes to determine the availability of one another. If one of the nodes has not received a message within a given time period or number of retries, a failover is initiated and the primary failover node takes ownership of the resources. It is the responsibility of the quorum drive to maintain a record of the state of each node during this process. Heartbeat checks are performed at the OS level as well as the SQL Server level. The OS is in constant contact with the other nodes, checking the health and availability of the servers. For this reason, a private network is used for the heartbeat between nodes to decrease the possibility of a failover occurring due to network-related issues. SQL Server sends messages known as LooksAlive and IsAlive. LooksAlive is a less intrusive check that runs every 5 seconds to make sure the SQL Server service is running. The IsAlive check runs every 60 seconds and executes the query Select @@ServerName against the active node to make sure that SQL Server can respond to incoming requests.
Implementation
Before you can even install SQL Server, you have to make sure that you have configured a solid Windows cluster at the OS and hardware levels. One of the major pain points you used to have when setting up a failover cluster is searching the Hardware Compatibility List (HCL) to ensure that the implemented hardware solution would be supported. This requirement has been removed in Windows Server 2008. You can now run the new cluster validation tool to perform all the required checks that will ensure you are running on a supported configuration. Not only can the cluster validation tool be used to confirm the server configuration, it can be used to troubleshoot issues after setup as well.
From a SQL Server perspective, the installation process is pretty straightforward. If you are familiar with installing a failover cluster in SQL Server 2005, it has completely changed in SQL Server 2008. First you run the installation on one node to create a single-node cluster. Then you run the installation on each remaining node, choosing the Add Node option during setup. In order to remove a node from a cluster, you run setup.exe on the server that needs to be removed and select the Remove Node option. The new installation process allows for more granular manageability of the nodes, allowing you to add and remove nodes without bringing down the entire cluster. The new installation process also allows you to perform patching and rolling upgrades with minimal downtime.
Do not be afraid of failover clustering. It takes a little extra planning up front, but once it has been successfully implemented, managing a clustered environment is really not much different than any other SQL environment. Just as the SQL instance has been presented to the application in a virtual network layer, it will be presented to the administrator this way as well. As long as you use all the correct virtual names when connecting to the SQL instance, it will just be administration as usual.
Pros and Cons of Failover Clustering
As with any other technology solution, failover clustering brings certain benefits, but at a cost. Benefits of failover clustering include the following:
- Zero data loss
- Protection of the entire instance
- Fast recovery
- Automatic failover
The price you pay for these benefits is as follows:
- Failover clustering does not protect against disk failure.
- No standby database is available for reporting.
- Special hardware is required.
- Failover clustering is generally expensive to implement.
- There is no duplicate data for reporting or disaster recovery.
Database Mirroring
The technique of database mirroring can be summed up very simply: It's the practice of keeping two separate copies of your database in synchronization with each other so that if you lose one copy, you can continue work with the other. Mirroring is commonly used at the disk level in RAID arrays. The concept is much the same when it comes to databases.
Key Terms
Just as failover clustering has its own terminology, database mirroring has its own conventions that you need to be familiar with. Study the list to follow because some of the same terms are used in other aspects of information technology, but with slightly different meanings. Using the correct terminology for SQL Server will help make sure everyone has the same understanding when discussing high availability. The key terms to be familiar with include the following:
- Principal: Source server containing the functionally active database in the mirrored pair.
- Mirror: Target server containing the destination database in the mirrored pair.
- Witness: Optional server that monitors the principal and mirror servers.
- Partner: Opposite server when referring to the principal and mirror servers.
- Endpoint: Object that is bound to a network protocol that allows SQL Servers to communicate across the network.
Database Mirroring Overview
Database mirroring was introduced in SQL Server 2005 and provides two levels of protection: high-performance mode and high-safety mode. Both modes have the same concept, but the order in which a transaction is committed is slightly different. With high-performance mode, the transaction is committed on the principal server before the mirror. This enables the application to move forward without having to wait for the transaction to commit on the mirror. With high-safety mode, the transaction is committed on the mirror before committing on the principal. This causes the application to wait until the transaction has been committed on both servers before moving forward. Both high-performance and high-safety modes require the principal database to be set to full recovery. We will look at each mode individually and discuss the pros and cons of using each technique.
Implementation
Database mirroring has a much easier implementation process when compared to failover clustering. It requires no special hardware configuration and can be applied and managed completely through SQL Server. Here are the basic steps you must perform in order to set up database mirroring:
- Create endpoints for database communication.
- Backup the database on the principal server.
- Restore the database on the mirror server.
- Set the principal server as a partner on the mirror server.
- Set the mirror server as a partner on the principal server.
One of the downsides of database mirroring compared to failover clustering is that you must set up database mirroring for each database, whereas once you set up failover clustering, the entire instance is protected. Since mirroring is configured for each individual database, you must make sure that any external data needed by the mirror database is also copied to the mirror server. For example, you need to copy logins from the master database to the master database on the mirror server, and also make sure that any jobs needed by the mirror database are on the mirror server. Also, since database mirroring makes a copy of the database, you will need to use twice as much disk space than you would with failover clustering. On the upside, having a duplicate copy of the database makes database mirroring a far better solution than failover clustering when you are worried about disaster recovery and disk failure. SQL Server 2008 even includes a new feature that will repair corrupt data pages by copying them from the partner once the corruption has been detected.
Snapshots for Reporting
In order to use a mirrored database as a reporting solution, you must also use the database snapshot feature, which requires the Enterprise Edition of SQL Server 2008. You can use database snapshots in conjunction with database mirroring in order to provide a static reporting solution by taking regular snapshots of the mirror database. Users are unable to connect directly to the mirror database to perform queries, but you can create a snapshot of the mirror database at any given time, which will allow users to connect to the snapshot database.
The snapshot database starts out relatively small, but as changes are made to the mirror database, the original data pages are added to the snapshot database in order to provide the data as it appeared when the snapshot was created. After some time of copying the original data pages, the snapshot database could become rather large, but never larger than the size of the original database at the time the snapshot was created. In order to keep the data current and the size of the snapshot to a minimum, you should refresh the snapshot periodically by creating a new snapshot and directing the traffic there. Then you can delete the old snapshot as soon as all the open transactions have completed. The snapshot database will continue to function after a failover has occurred; you will just lose connectivity during the failover while the databases are restarted. A failover could, however, place an additional load on the production system. Since it is now being used for processing the data for the application and serving up reporting requests, you may need to drop the snapshots and suspend reporting until another server is brought online.
Redirection in the Event of a Failure
Transparent client redirect is a feature provided in the Microsoft Data Access Components (MDAC) that works with database mirroring to allow client applications to automatically redirect in the case of a failover. When connecting to a database that participates in database mirroring, MDAC will recognize there is a mirror database and store the connection information needed to connect to the mirror database, along with the principal database. If a connection to the principal database fails, the application will try to reconnect. If the application is unable to reconnect to the principal database, a connection to the mirror database is attempted. There is one major caveat when working with transparent client redirect: The application must connect to the principal database before a failover has occurred in order to receive the connection information about the mirror. If the application cannot connect to the principal server, it will never be redirected to the mirror, meaning the failure must occur during an active application session. This can be mediated by storing two possible connection strings in the application.
High-Safety Mode
You can use high-safety mode in database mirroring to provide a duplicate copy of the principal database on a mirror server in a synchronous fashion so there is no chance of data loss between the principal and the mirror. In order for a transaction to commit on the principal database, it must first commit on the mirror. High-safety mode is supported in the Enterprise and Standard Editions of SQL Server, with one caveat being that the principal and the mirror must be running the same edition.
In order to provide the highest level of availability, you can use a witness server to verify connectivity between the principal and the mirror (see Figure 3-4). The witness server is not a requirement for high-safety mode, but it is a requirement for automatic failover capabilities. The witness server runs an instance of SQL Server that consumes very little resources and can even run using SQL Server Workgroup and Express Editions. Using a witness provides a communication check between the principal and the mirror, similar to the heartbeat in failover clustering. This communication check provides the ability for the mirror to assume the role of the principal should the principal become unavailable. The witness is not a single point of failure and does not actually perform the failover; it just provides verification to the mirror server that the principal server is down. If the witness server crashes, database mirroring is still operational and completely functioning between the principal and the mirror, and you will just lose the ability to automatically fail over. The reason for this behavior is to prevent unnecessary failovers due to network connectivity. In order for a server to become a principal server, it has to be able to communicate with at least one other server; therefore, the only purpose of the witness is to answer the question, “Is the principal down?” In order to automatically recover from a failure, the witness and the mirror servers must agree that the principal is actually down.
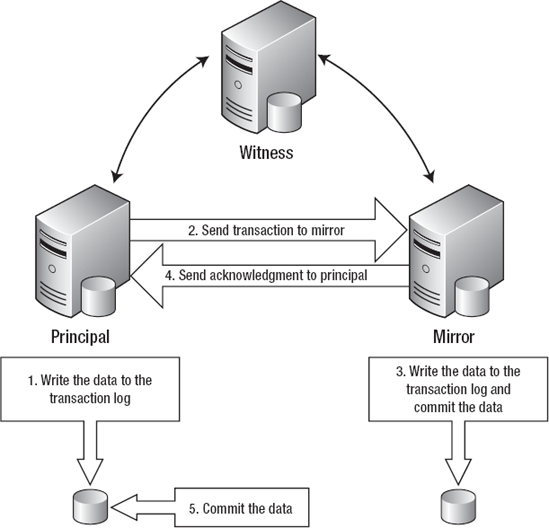
Figure 3-4. Database mirroring high-safety mode with witness server
High-Performance Mode
You can use high-performance mode in database mirroring to perform asynchronous operations between the principal and mirror databases. High-performance mode supports only a manual failover with the possibility of data loss. There is no need to use a witness server in high-performance mode because there is no automatic failover capability. Since the principal database does not have to wait for acknowledgment from the mirror server in order to keep processing requests, high-performance mode could increase application performance if you have a slow network connection or latency issues between the principal and mirror servers. Asynchronous processing also means that the mirror server can be several minutes behind when processing a high volume of transactions, which may or may not be acceptable, depending on the requirements agreed upon in the SLA. High-performance mode is only supported if you are using the Enterprise Edition of SQL Server.
![]() Tip SQL Server 2008 introduces the capability to compress the individual transactions being transmitted to the mirror database to help improve performance on slow networks with bandwidth limitations. This may increase performance enough to allow you to implement high-safety mode when using database mirroring in SQL Server 2008 on networks that may have prevented you from using high-performance mode in SQL Server 2005.
Tip SQL Server 2008 introduces the capability to compress the individual transactions being transmitted to the mirror database to help improve performance on slow networks with bandwidth limitations. This may increase performance enough to allow you to implement high-safety mode when using database mirroring in SQL Server 2008 on networks that may have prevented you from using high-performance mode in SQL Server 2005.
Figure 3-5 shows the typical configuration of database mirroring using high performance mode. Notice the order of operations using high performance mode that allows the application to perform requests without having to wait for the transactions to commit on the mirror.
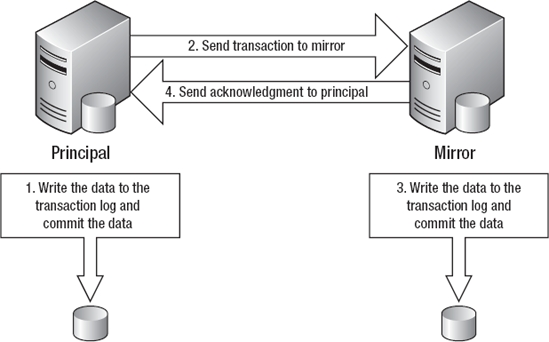
Figure 3-5. Database mirroring high-performance mode
Pros and Cons of Database Mirroring
As always, there are trade-offs to think about. The benefits of database mirroring include the following:
- No special hardware or windows configurations
- No distance limitations
- Duplicate data for disaster recovery
- Possible reporting solution using database snapshots of the mirror
Following are some restrictions and drawbacks of database mirroring to be aware of:
- Requires more disk space to store duplicate data
- Must be configured separately for each database
- May cause application performance issues on slow networks (high-performance mode)
In addition, keep in mind the following differences between high-safety mode and high-performance mode:
- High-safety mode ensures zero data loss. High-performance mode trades the chance of some data loss for increased performance.
- High-safety mode can cause application performance issues on slower networks. High-performance mode avoids performance issues by not waiting for the mirror to commit first (hence, the risk of data loss).
- Recovery is faster in high-safety mode because no uncommitted transactions need to be applied or undone.
- For the same reason, failover can be automatic in high-safety mode, but not in high-performance mode.
Copying Data with Log Shipping
One way to think of log shipping is as a poor man's approach to mirroring. The end goal is much the same as for database mirroring—to keep a second copy of a database in case the first copy is lost or damaged. The difference is that log shipping achieves its goal by making clever use of SQL Server's built-in backup and recovery functionality. Log shipping may have a few advantages over database mirroring, depending on your needs. For one thing, you can log ship to multiple servers, whereas you can only mirror to a single server. You can also use log shipping between different editions of SQL Server, while it is recommended that all servers are running the same edition when using database mirroring. You can also control the interval that the transactions are applied to when using log shipping because the databases are kept in sync by applying an entire transaction log at once instead of applying individual transactions.
Key Terms
The key terms in log shipping are pretty self explanatory, but once again it is best to know the correct terminology for each high-availability solution. Terms to know include the following:
- Primary: Server containing the source database sending the transaction logs.
- Secondary: Server containing the target database receiving the transaction logs.
- Monitor: Server that tracks information related to log shipping such as backup and restore times and sends alerts in the case of a failure.
Log Shipping Overview
Log shipping consists of a primary server copying the transaction logs of one or more databases and restoring them on one or more secondary servers. You can use a monitor server to track information about the status of log shipping. During the setup process, an alert job is configured on the monitor to send a failure notification if the primary and secondary databases are past the configured sync threshold. The monitor can be the same server as the primary or secondary, but it should be located on a different server to increase the chances of receiving an alert if the primary or secondary server has issues. All servers involved in log shipping must be running the Enterprise, Standard, or Workgroup Edition of SQL Server. You can also configure log compression with log shipping to reduce the network bandwidth needed to transfer the logs, but this requires the Enterprise Edition of SQL Server 2008.
Implementation
As with database mirroring, you must configure log shipping for each database, and log shipping does not provide protection at the instance level. For this reason, you must also copy any data that may be needed by the secondary database, such as logins and jobs. Unlike database mirroring, log shipping relies on copying the entire transaction log instead of sending and committing single transactions. The recovery model for the primary database can be full or bulk-logged. (Database mirroring must use the full recovery model.) Also, there is no option that provides automatic failover using log shipping; it is purely a manual process referred to as a role change. During a role change, you manually bring online the secondary server, and it assumes the “role” of the primary server.
Log shipping uses a fairly fundamental process. One database makes normal transaction log backups, while another database is in constant restore mode. You would take the following actions during a typical log shipping setup process:
- Take a full backup of the primary database.
- Restore that backup on the secondary server, leaving the database in a state to accept further restores.
- Create a job on the primary server to back up the transaction logs for the primary database.
- Create a job on the secondary server to copy transaction logs.
- Create a job on the secondary server to restore the transaction logs.
- Create an alert job on the monitor to indicate a failure if the databases are out of sync beyond the configured threshold.
You can use network load balancing to mask the role change from the application. Using network load balancing allows both servers to appear on the network with the same IP address. The client applications can connect to the primary server using the virtual IP address, and if a role change occurs, you can use network load balancing to transfer the traffic to the new primary server without having to modify the application. While network load balancing still does not provide automatic failover, it does make the role change a faster process, since the applications will be ready to use the database as soon as the role change has occurred. Figure 3-6 shows a typical configuration using log shipping with network load balancing.
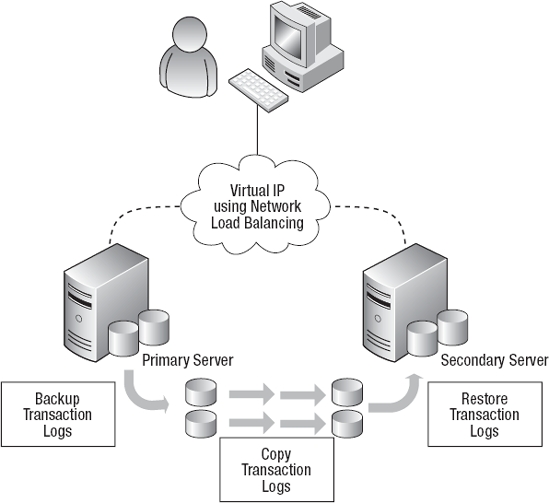
Figure 3-6. Log shipping configuration and workflow
There are two types of role changes: planned and unplanned. A planned role change occurs when the primary and secondary servers are still online. This is obviously the best kind of role change, since you are not in emergency mode trying to get the database back online. An unplanned role change occurs when the primary server crashes, and you bring the secondary server online to service the requests.
Restoring to the Secondary Server
You can restore the database on the secondary server using two different options, NORECOVERY and STANDBY. Using the NORECOVERY option will place the database in a loading state and will not allow any connections to the database. Using the STANDBY option will place the database in a read-only state that will allow connectivity, but any time a new log is restored, all the connections to the database must be dropped or the restore will fail. If you are trying to use log shipping as a reporting solution as well as a high-availability solution, we don't think your users will enjoy getting kicked out of the database every 15 minutes while the transaction logs are restored. One way to avoid this is by setting a load delay of 12 hours or so to bypass log restores during business hours. The logs will continue copying to the secondary server, and only the ones older than the load delay will be applied. After business hours, the load delay can be reset to 15 minutes or so to allow the logs to catch up with the primary server, which will ensure that no logs are restored during business hours. Using a load delay works well with systems that require static, day-old reporting capabilities. Another benefit of using a load delay is that it protects against human errors, such as users deleting the wrong records in a table. If you set a load delay of four hours and a user calls you about a mistake that was made two hours ago, the transaction log containing the mistake has not yet been applied to the secondary server, so you can recover the data from there.
Pros and Cons of Log Shipping
Log shipping is a fairly inexpensive way to get data from point A to point B. It was officially released in SQL Server 2000, but homegrown implementations were used prior to its release. Because log shipping works by copying transaction logs across the network, there is no way to ensure zero data loss. Also, the latency between the primary database and the secondary database can be significant. If log shipping is all your budget will allow, and you have set the proper expectations with your management, log shipping can be configured in several different ways to provide a flexible solution for high availability and recovery.
The benefits of log shipping include the following:
- No special hardware or windows configurations
- No distance limitations
- Duplicate data for disaster recovery
- Limited reporting capabilities
Restrictions and drawbacks of log shipping are that it
- Requires more disk space to store duplicate data
- Must be configured separately for each database
- Does not fail over automatically
- Will likely result in some data loss in the event that a failover occurs
Making Data Available Through Replication
Replication refers to the technology behind creating and maintaining duplicate copies of database objects, such as tables. For example, you can create a copy of a key table—say, a customer table—in several reporting databases located at different regional offices of your company. You can synchronize those copies manually or automatically. If automatically, you can schedule synchronizations to occur at specific times of day. You can even go so far as to force all replicated copies to be kept fully up to date as transactions against the master copy occur.
Replication is best thought of as a way to make business data available in different databases or at different locations. The idea is to give different applications access to the same data or to make data conveniently available for reporting. Replication isn't really intended as a high-availability mechanism, though it does sometimes get used as one.
Key Terms
As with every other high-availability technique discussed in this chapter, replication has its own way of referring to the participating servers and objects. Here is a list of key terms that you should be familiar with while reading this section and when talking about replication in SQL Server:
- Publisher: Source server containing the primary database
- Subscriber: Target server receiving the publication
- Distributor: Server used to keep track of the subscriptions and manages the activity between the publisher and the subscriber
- Articles: Database objects that are being replicated
- Publications: Collection of articles
- Agents: Executables used to help perform replications tasks
Replication Overview
Replication offers a wide variety of options and methods of implementation. Unlike anything else discussed thus far, replication allows you to copy data at the object level instead of the database level. Unfortunately, replication requires several up front design considerations that may prevent you from deploying it in your environment, especially if you are supporting a vendor-supplied application. For example, each table that is published using transactional replication must have a primary key; or when using identity columns in a multi-node replication topology, each node must be configured to use a distinct range of values.
Replication is a good solution when working with disconnected data sources or subsets of data. It allows users in separate locations the ability to work with their own subscription database and sync back up with the publisher on a periodic basis by using a push or pull subscription. In a push subscription, the distributor pushes the data to the subscriber; in a pull subscription, the subscriber pulls the data. Replication supports the distribution of publications to many subscribers. The replicated data is first sent from the publisher and then stored on the distributor until the transactions are sent to the subscriber. You can configure the distributor to run on the same server as the publisher, but this will add extra overhead to the server. The publisher will run more efficiently if the distributor is on a separate server. The subscription database is not required to be read-only and remains in a completely functional state, allowing normal operations to occur.
Replication uses executables called replication agents to support certain replication actions that are performed. Different replication agents are used depending on the type of replication that is implemented. The three basic types of replication are known as snapshot, merge, and transactional. Each replication type has different capabilities that will be discussed in the following sections. Replication is supported in all editions of SQL Server with the exception that publishing is not allowed in SQL Server Express or SQL Server Compact 3.5 SP1.
![]() Note If you are looking purely from a high-availability standpoint, in our opinion, replication is usually a poor choice. We have always thought of replication as a way of combining or sharing disconnected data sets and not as a high-availability technique. You will generally notice the lack of the word failover when dealing with replication. That is because high availability is not the primary function of replication; it's more of a side effect. However, replication does allow more granular capabilities for transferring data and may prove to be the best solution in certain situations.
Note If you are looking purely from a high-availability standpoint, in our opinion, replication is usually a poor choice. We have always thought of replication as a way of combining or sharing disconnected data sets and not as a high-availability technique. You will generally notice the lack of the word failover when dealing with replication. That is because high availability is not the primary function of replication; it's more of a side effect. However, replication does allow more granular capabilities for transferring data and may prove to be the best solution in certain situations.
Snapshot Replication
Snapshot replication runs on a periodic basis and copies the entire publication to the subscriber every time it is run. It lays the foundation for transactional and merge replication by sending the initial publication to the subscriber. No updates can be performed on a table while the snapshot agent copies the data from the publisher to the distributor. The entire table is locked during the process. To boost the speed of the snapshot generation process, parallel processing is available in SQL Server 2008 when scripting objects and bulk copying data. SQL Server 2008 also allows for interrupted snapshot delivery, meaning that if the delivery of the snapshot is interrupted during initialization, only the data that has not been copied will be transferred when the snapshot is resumed. Figure 3-7 shows the configuration of snapshot replication.
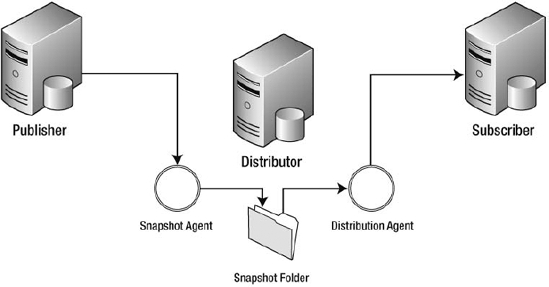
Figure 3-7. Snapshot replication configuration
Transactional Replication
Transactional replication is most often preferred when high availability is a concern because it provides the highest level of precision by using distributed transactions to ensure consistency. Transactional replication works by sending an initial snapshot to the subscriber and then keeping the subscriber up to date by sending only specific marked transactions. The snapshot is periodically resent on a scheduled basis, and transactions are used to update subscribers between snapshots. SQL Server 2008 allows the initial snapshot to be created from any backup that has been taken after the publication has been enabled for initialization with a backup.
The transactions are stored in the distribution database until they have been applied to all the subscribers. The transactions are applied to the subscribers in the order they were received on the publisher to ensure accuracy. It is important to note that transactions cannot be cleared from the transaction log on the publisher until they have been sent to the distributor. If connectivity is lost between the publisher and the distributor, this could cause excessive growth in the transaction log. Also, some database administrators like to disable auto growth and put a cap on the size of the data files. This could also lead to a failure in the case of excessive transaction log growth. Figure 3-8 shows the configuration of transactional replication.
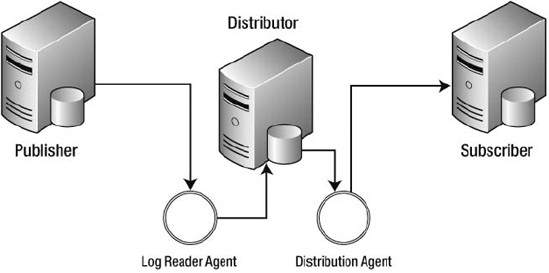
Figure 3-8. Transactional replication configuration
![]() Tip You need to make sure to size the drives appropriately to account for the possibility of excessive file growth due to connection issues so you will not suffer an outage due to lack of disk space.
Tip You need to make sure to size the drives appropriately to account for the possibility of excessive file growth due to connection issues so you will not suffer an outage due to lack of disk space.
Updateable Subscriptions
You can use updateable subscriptions in transactional replication to allow the subscriber to update the publications and synchronize them with the publisher. Triggers are added to the subscription database that fire when data needs to be sent to the publisher. The two types of updateable subscriptions are known as immediate updating and queued updating.
Immediate updating uses the Microsoft Distributed Transaction Coordinator (MSDTC) to apply a two-phase commit transaction. Along with the triggers that are created on the subscriber to transmit data changes to the publisher, stored procedures are created on the publisher to update the data. The triggers on the subscriber use the MSDTC to call the stored procedures on the publisher to update the data. If there is any conflict due to out-of-date data on the subscriber, the entire transaction is rolled back at the publisher and the subscriber. Once the change has been made to the publisher, the publisher will then distribute the changes to any other subscribers. Figure 3-9 demonstrates transactional replication with immediate updating.
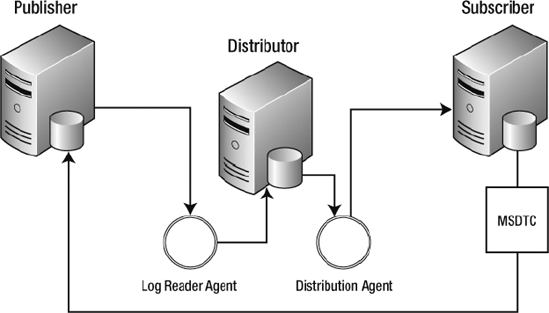
Figure 3-9. Transactional replication with immediate updating
Queued updating works similarly to immediate updating, except instead of making a two-phase commit, it uses the MSreplication_queue to store the transactions. The queue reader agent then reads the transactions from the MSreplication_queue and calls the stored procedures on the publisher to update the data. If a conflict is encountered, it is resolved by the rules defined in the conflict resolution policy set when the publication was created. Just as in immediate updating, the changes are then distributed to the other subscribers. The benefit of using queued updating is that the subscriber does not have to be connected in order to make changes to the database. Figure 3-10 demonstrates transactional replication with queued updating.
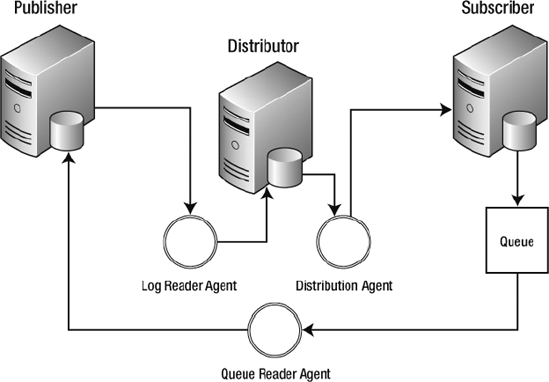
Figure 3-10. Transactional replication with queued updating
Peer-to-Peer Replication
Peer-to-peer replication was introduced in SQL Server 2005 and is an important feature when using replication as a high-availability aid. It is a special form of transactional replication that maintains an almost real-time copy of the data across multiple servers. The servers participating in peer-to-peer replication are referred to as nodes because each server is a publisher and a subscriber. Since the data is propagated to all of the servers in the topology, you can easily take a server out of the mix to perform maintenance by redirecting the traffic to another server. One of the downfalls is that you never know where a transaction is in the process of replicating to the other servers in the topology.
SQL Server 2008 has enhanced peer-to-peer replication by allowing you to add and remove servers without interrupting the other servers in the topology. Conflict detection has also been provided in SQL Server 2008, allowing you to catch conflicts that may have otherwise been overlooked in SQL Server 2005. The topology wizard has also been added in SQL Server 2008 to enable visual configuration of peer-to-peer replication. Figure 3-11 shows a typical peer-to-peer transactional replication configuration.
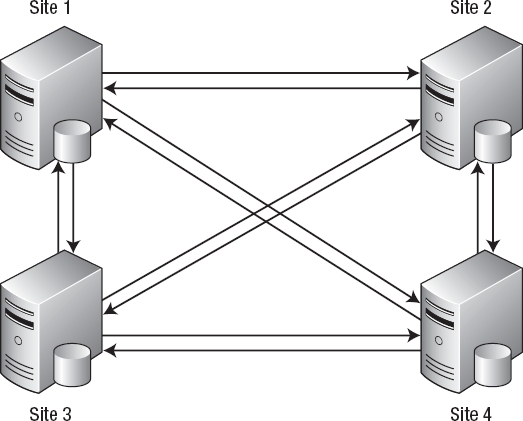
Figure 3-11. Peer-to-peer transactional replication configuration
Merge Replication
You can use merge replication to allow publishers and subscribers to make changes to data independently and then merge the results. The merge process is not immediate and depends on the push and pull processes to combine the data. One of the benefits of merge replication is that you can write custom code to handle conflicts. With transactional replication, either the publisher or subscriber is deemed the winner, and their transaction is applied, or the conflict is logged and human intervention is required. Writing custom code allows you to apply complex business logic so that no human intervention will be required when a conflict is encountered.
The merge agent watches for conflicting changes, and the conflict resolver determines what change will be applied. You can track conflicts at the column level or the row level. Column-level conflicts occur if multiple updates have been made to the same column in a row by multiple servers; row-level conflicts occur when multiple updates have been made to any column in a given row. Figure 3-12 shows the configuration of merge replication.
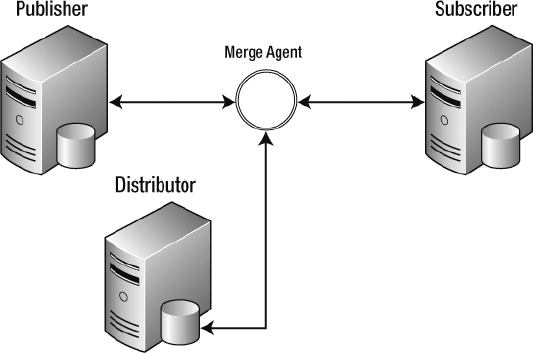
Figure 3-12. Merge replication configuration
Pros and Cons of Replication
Instead of going into the benefits and restrictions of each type of replication and various configurations, we will summarize the benefits and restrictions of replication as a whole. The benefits of replication include the following:
- No distance limitations
- Duplicate data for disaster recovery
- Disconnected data manipulation and synchronization
Restrictions and drawbacks are as follows:
- Possible data loss
- Possible data conflicts
- No automatic failover
- Requires special database design considerations
Other High-Availability Techniques
High availability is not limited to the techniques already discussed in this chapter. You should utilize anything that can attribute to less downtime and a better end-user experience. There are third-party solutions to supplement SQL Server, such as geographically disbursed clusters. Geographically disbursed clustering allows you to break the network limitations in failover clustering and place the nodes in separate geographic locations. Hardware configurations, such as drive mirroring and RAID levels, provide fault tolerance and protect against a single disk failure.
Other capabilities in SQL Server can be used to help ensure availability as well. Change Data Capture will allow you to capture changes that have been made in certain tables and ship them off to another server. Having a good backup solution is always your last line of defense when dealing with high availability. If all else fails, you can always restore from a recent backup. No matter how much money you spend on the hardware and software, it is critical to have the appropriate level of knowledge to support it. If you do not have the proper comprehension to spring into action when the time comes, you could make costly mistakes. A lack of knowledge could cause something that may have taken a few minutes to possibly take a few days, and in certain situations, valuable data could be lost that may never be recovered.
High Availability Feature Comparison
Table 3-1 can be used as a quick reference when comparing the features of the major high-availability techniques. You can quickly narrow down which solution you may need in your environment by highlighting the required features. For example, if zero data loss is required, then that leaves you with failover clustering and high-safety mirroring. If you require protection against disk failure, the only remaining option is high-safety mirroring. Sometimes the best solution is a combination of high-availability techniques. You can find out more about combining high-availability techniques by reading the article “High Availability: Interoperability and Coexistence” at SQL Server Books Online (http://msdn.microsoft.com/en-us/library/bb500117.aspx).
Summary
Microsoft SQL Server 2008 offers many different techniques to help you implement and maintain the highest available solution possible. Many of the features offered by these techniques can be combined to ensure an even higher level of availability. Having the knowledge necessary to understand what technologies are available and determining how they will be implemented in your environment is key to the successful deployment of any application. Now that we've covered many of the things you should consider during the planning stages, you will finally be able to get your hands dirty. The next section will cover the ins and outs of installing and upgrading SQL Server 2008.