
6
Search
WHAT'S IN THIS CHAPTER?
- Using the Enterprise Search product line
- Understanding architecture and user experience features
- Customizing search, from user experience and social search to federation, connectors, and content processing
- Recognizing common patterns for developing search extensions and search-based applications
- Exploring examples you can use to get started on custom search projects
Search is now everywhere, and most people use it numerous times a day to keep from drowning in information. Enterprise search provides a powerful way to access information of all types, and it lets you bridge across the information silos that proliferate in many organizations. Perhaps because of the simplicity and ubiquity of the search user experience, the complexity of search under the hood is rarely appreciated until you get into it. Developing with search and SharePoint 2010 is rewarding and not difficult, although it requires an understanding of search and sometimes a different mindset.
Microsoft has been in the Enterprise Search business for a long time. Over the last three years focus in this area has increased, including the introduction of Search Server 2008 and the acquisition of FAST Search and Transfer. Search is becoming a strategic advantage in many businesses, and Microsoft's investments reflect this.
Enterprise Search delivers content for the benefit of the employees, customers, partners, or affiliates of a single company or organization. Companies, government agencies, and other organizations maintain huge amounts of information in electronic form, including spreadsheets, policy manuals, and web pages, just to name a few. Contemporary private datasets can now exceed the size of the entire Internet in the 1990s — running into petabytes or even exabytes of information. This content may be stored in file shares, websites, content management systems, or databases, but without the ability to find this corporate knowledge, managing even a small company would be difficult.
Enterprise Search applications are found throughout most enterprises — both in obvious places (like intranet search) and in less visible ways (search-driven applications often don't look like “search”). Search supports all these applications, and complements all the other workloads within SharePoint 2010 — Insights, Social, Composites, and the like — in powerful ways.
Learning to develop great applications, including search, will serve you and your organization very well. You can build more flexible, more powerful applications that bridge different information silos while providing a natural, simple user experience.
This chapter provides an introduction to developing with search in SharePoint 2010. First, it covers the options, capabilities, and architecture of search. A section on the most common search customizations gives you a sense of what kind of development you are likely to run into. Next, it runs through different areas of search: social search, indexing connectors, federation, content processing, ranking and relevance, the UI, and administration. In each of these areas, you get a look at the capabilities, learn how a developer can work with them, and review an example. Combining these techniques leads to the realm of search-driven applications, which we cover as a separate topic with tips for successful projects. A section on search and the cloud reviews ways to work with Office 365 and Azure. Finally, the summary gives an overview of the power of search and offers some ways to combine it with other solutions in SharePoint 2010.
SEARCH OPTIONS WITH SHAREPOINT 2010
With the 2010 wave, Microsoft added new Enterprise Search products and updated existing ones — bringing in a lot of new capabilities. Some of these are brand new, some are evolutions of the SharePoint 2007 search capabilities, and some are capabilities brought from FAST. The result is a set of options that lets you solve any search problem, but because of the number of options, it can also be confusing.
Figure 6-1 shows the Enterprise Search products in the 2010 wave. There are many options; in fact, there are 9 offerings for Enterprise Search. This is evidence of the emphasis Microsoft is putting on search, and also a byproduct of the ongoing integration of the FAST acquisition.
This lineup might seem confusing at first, and the sheer number of options is a bit daunting. As you will see, there is method to this madness. For most purposes, you will be considering only one or two of these options.
Looking at the lineup from different perspectives helps to understand it. There are three dimensions to consider:
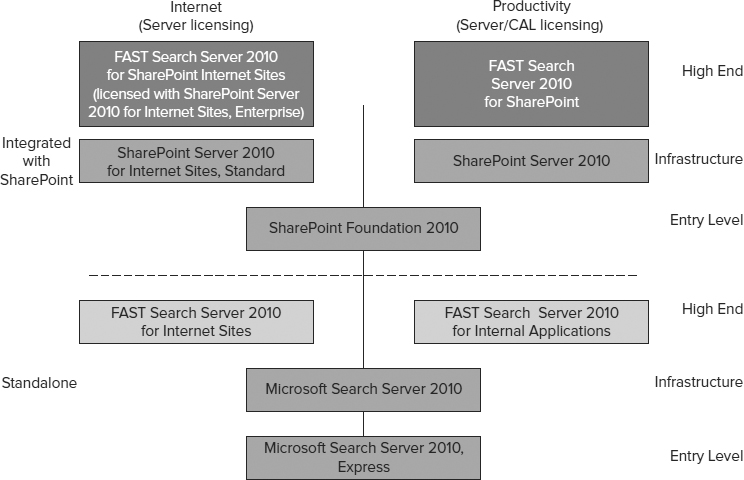
FIGURE 6-1
- Tier (labeled along the right side of Figure 6-1): Microsoft adopted a three-tier approach in 2008 when it introduced Search Server 2008 Express and acquired FAST. These tiers are entry level, infrastructure, and high end. Search Server 2010 Express, Search Server 2010, and the search in SharePoint Foundation 2010 are all entry level; SharePoint Server flavors cover the infrastructure tier, and any option labeled “FAST” is high end.
- Integration (labeled along the left side of Figure 6-1): Search options integrated with SharePoint have features, such as social search, that build on and therefore require other parts of SharePoint. Standalone search products don't require SharePoint, but they lack these features.
- Application (labeled across the top of Figure 6-1): Applications are classified as Internet applications or Productivity applications. For the most part, the distinction between search applications inside the firewall (Productivity) and outside the firewall (Internet) is purely a licensing distinction. Inside the firewall, products are licensed per server and per client access license (CAL). Outside the firewall, it isn't possible to license clients, so products are licensed only per server. The media, documentation, support, and architecture are the same across these application areas (shown horizontally across Figure 6-1). There are a few minor feature differences, which are called out in this chapter where relevant.
Another perspective useful in understanding this lineup is that of the codebase. The acquisition of FAST brought a large codebase of high-end search code, different from the SharePoint search codebase. As the integration of FAST proceeds, ultimately all Enterprise Search options will be derived from a single common codebase.
At the moment there are three separate codebases from which Enterprise Search products are derived. The first is the SharePoint 2010 search codebase, an evolution from the MOSS 2007 search code. Search options derived from this codebase are in medium gray boxes as shown in Figure 6-1. The second is the FAST standalone codebase, a continuation of the code from FAST ESP, the flagship product provided by FAST up to this time. Search options derived from this codebase are shown in light gray boxes in Figure 6-1. The third is the FAST integrated codebase, a new one resulting from reworking the ESP code, integrating it with the SharePoint search architecture, and adding in new elements. Search options derived from this codebase are shown in dark gray boxes in Figure 6-1.
The codebase perspective is useful for developers, as it provides a sense of what to expect with APIs and system behavior. The FAST integrated codebase uses the same APIs as the SharePoint search codebase, but extends those APIs to expose additional capabilities. The FAST standalone codebase uses different APIs. Note that search products from the FAST standalone codebase are in a special status — licensed through FAST as a subsidiary and under different support programs. This book doesn't cover products from the FAST standalone codebase or the APIs specific to them.
If you consider the search options across application areas as the same, and disregard the FAST standalone codebase, you are left with five options in the Enterprise Search lineup, rather than nine. Look at each of these options and see where you might use each one. This chapter also introduces some shorter names and acronyms for each option to make the discussion simpler.
SharePoint Foundation
Microsoft SharePoint Foundation (also called SharePoint Foundation, or SPF) is a free, downloadable platform that includes basic search capabilities. SPF search is limited to content within SharePoint — no search scopes, and no refinement. SPF is in the entry-level tier and is integrated with SharePoint.
If you are using SharePoint Foundation and care about search (which is likely, because you are reading this book!), you should forget about the built-in search capability and use one of the other options. Most likely this will be Search Server Express, as it is also free.
Search Server 2010 Express
Microsoft Search Server 2010 Express (also called Search Server Express or MSSX) is a free, downloadable standalone search offering. It is intended for tactical, small-scale search applications (such as departmental sites), requiring little or no cost and IT effort. Microsoft Search Server 2008 Express was a very popular product — Microsoft reports over 100,000 downloads. There is a lot added with the 2010 wave: better connectivity, search refiners, improved relevance, and much more.
Search Server Express is an entry-level standalone product. It is limited to one server with up to 300,000 documents. It lacks many of the capabilities of SharePoint Server's search, such as taxonomy, or people and expertise search, not to mention the capabilities of FAST. It can, however, be a good enough option for many departments that require a straightforward site search.
If you have little or no budget and an immediate, simple, tactical search need, use Search Server Express. It is quick to deploy, easy to manage, and free. You can always move to one of the other options later.
Search Server 2010
Microsoft Search Server 2010 (also called Search Server or MSS) has the same functional capabilities as MSS Express, with full scale — up to about 10 million items per server and 100 million items in a system using multiple servers. It isn't free, but the per-server license cost is low. MSS is a great way to scale up for applications that start with MSS Express and grow (as they often do).
MSS is an infrastructure-tier standalone product. Both MSS and MSS Express lack some search capabilities that are available in SharePoint Server 2010, such as taxonomy support, people and expertise search, social tagging, and social search (where search results improve because of social behavior), to name a few. And, of course, MSS does not have any of the other SharePoint Server capabilities (BI, workflow, etc.) that are often mixed together with search in applications.
If you have no other applications for SharePoint Server, and need general intranet search or site search, MSS is a good choice. But in most cases, it makes more sense to use SharePoint Server 2010.
SharePoint Server 2010
Microsoft SharePoint Server 2010 (also called SharePoint Server or SP) includes a complete intranet search solution that provides a robust search capability out of the box. It has many significant improvements over its predecessor, Microsoft Office SharePoint Server 2007 (also called MOSS 2007) search. New capabilities include refinement, people and expertise search with phonetic matching, social tagging, social search, query suggestions, editing directly in a browser, and many more. Connectivity is much broader and simpler, both for indexing and federation. SharePoint Server 2010 also has a markedly improved architecture with respect to scalability, performance, and capacity. It supports a wide range of configurations, growth, and changing needs.
SharePoint Server has three license variants in the 2010 wave — all with precisely the same search functionality. With all of them, Enterprise Search is a component or “workload,” not a separate license. SharePoint Server 2010 is licensed in a typical Microsoft server/CAL model. Each server needs a server license, and each user needs a client access license (CAL). For applications where CALs don't apply (typically outside the firewall in customer-facing sites), there is SharePoint Server 2010 for Internet Sites, Standard (FIS-S) and SharePoint Server 2010 for Internet Sites, and Enterprise (FIS-E).
For the rest of this chapter, these licensing variants will be ignored, and we will refer to all of them as SharePoint Server 2010 or SP. All of them are infrastructure-tier, integrated offerings.
SharePoint Server 2010 is a good choice for general intranet search, people search, and site search applications. It is a fully functional search solution and should cover the scale and connectivity needs of most organizations. However, it is no longer the best search offered with SharePoint, given the integration of FAST in this wave.
FAST Search Server 2010 for SharePoint
Microsoft FAST Search Server 2010 for SharePoint (also called FAST Search for SharePoint or FS4SP) is a new product introduced along with SharePoint 2010. It is a high-end Enterprise Search product, providing an excellent search experience out of the box and the flexibility to customize search for very diverse needs at essentially unlimited scale. FS4SP is notably simpler to deploy and operate than other high-end search offerings. It provides high-end search, integrated with SharePoint.
The frameworks and tools used by IT professionals and developers are common across the SharePoint search codebase and the FAST integrated codebase. FAST Search for SharePoint builds on SharePoint Server, and integrates into the SharePoint 2010 architecture using some of the new elements, such as the enhanced connector framework and the federation framework. This means that FAST Search for SharePoint shares the same object models and APIs for connectors, queries, and system management. In addition, administrative and frontend frameworks are common — basically the same management console and the same Search Center web parts.
Figure 6-2 shows how FAST adds on to SharePoint Server. In operation, both SharePoint servers and FAST Search for SharePoint servers are used. SharePoint servers handle crawling, accept and federate queries, and serve up people search. FAST Search for SharePoint servers handle all content processing and core search. The result is a combination of SharePoint search and FAST search technology in a hybrid form, plus several new elements and capabilities.

FIGURE 6-2
FAST Search for SharePoint provides significant enhancements to the Enterprise Search capabilities. This means that there are capabilities and extensions to APIs that are specific to FAST Search for SharePoint. For example, there are extensions to the Query Object Model (OM), to accommodate the additional capabilities of FAST such as FAST Query Language (FQL). The biggest differences are in the functionality available: a visual and “contextual” search experience; advanced content processing, including metadata extraction; multiple relevance profiles and sorting options available to users; more control of the user experience; and extreme scale capabilities.
FAST LICENSING VARIANTS
Just like SharePoint Server, FS4SP has licensing variants for internal and external use. FS4SP is licensed per server, requires Enterprise CALs (e-CALs) for each user, and needs SharePoint Server 2010 as a prerequisite. FAST Search Server 2010 for SharePoint Internet Sites (FS4SP-IS) is for situations where CALs don't apply, typically Internet-facing sites with various search applications. In these situations, SP-FIS-E (enterprise) is a prerequisite, and SP-FIS-E server licenses can be used for either SP-FIS-E servers or FS4SP-IS servers. FS4SP and FS4SP-IS have essentially the same search functionality with a few exceptions. The most notable difference is that the thumbnails and previews that come with FS4SP aren't available for use with SP-FIS-E. We largely ignore these variants for the remainder of this chapter and refer to them both as FAST Search for SharePoint or FS4SP.
FAST Search for SharePoint handles general intranet search, people search, and site search applications, providing more capability than SharePoint Server does, including the ability to give different groups using the same site different experiences based on user context. FS4SP is particularly well suited for high-value search applications such as those described next.
Choosing the Right Search Product
Most often, organizations implementing a Microsoft Enterprise Search product choose between SharePoint Server 2010's search capabilities and FAST Search for SharePoint. SharePoint Server's search has improved significantly since 2007, so it is worth a close look, especially if you are already running SharePoint 2007's search. FAST Search for SharePoint has many capabilities beyond SharePoint Server 2010's search, but it also carries additional licensing costs. By understanding the differences in features and the requirements that can be addressed by each feature, you can determine whether you need the additional capabilities offered by FAST.
With Enterprise Search inside the firewall, there are two distinct types of search applications:
- General-purpose search applications increase employee efficiency by connecting “everyone to everything.” General-purpose search solutions increase employee efficiency by connecting a broad set of people to a broad set of information. Intranet search is the most common example of this type of search application.
- Special-purpose search applications help a specific set of people make the most of a specific set of information. Common examples include product support applications, research portals ranging from market research to competitive analysis, knowledge centers, and customer-oriented sales and service applications. This kind of application is found in many places, with variants for essentially every role in an enterprise. These applications typically are the highest-value search applications, as they are tailored to a specific task that is usually essential to the users they serve. They are also typically the most rewarding for developers.
SharePoint Server 2010's built-in search is targeted at general-purpose search applications, and can be tailored to provide specific intranet search experiences for different organizations and situations. FAST Search for SharePoint can be used for general-purpose search applications, and can be an “upgrade” from SharePoint search to provide superior search in those applications. However, it is designed with special-purpose search applications in mind. So applications you identify as fitting the “special-purpose” category should be addressed with FAST Search for SharePoint.
Because SP and FS4SP share the connector framework (with a few exceptions covered later), you won't find big differences in connectors or security, which traditionally are areas where search engines have differentiated themselves. Instead, you see big differences in content processing, user experience, and advanced query capabilities. Examples of capabilities specific to FAST Search for SharePoint are:
- Content-processing pipeline
- Metadata extraction
- Structured data search
- Deep refinement
- Visual search
- Advanced linguistics
- Visual best bets
- Development platform flexibility
- Ease of creating custom search experiences
- Extreme scale and performance
Common Platform and APIs
There are more aspects in common between SharePoint Server 2010 Search and FAST Search for SharePoint than there are differences. The frameworks and tools for use by IT pros and developers are kept as common as possible across the product line, given the additional capabilities in FAST Search Server 2010 for SharePoint. In particular, the object models for content, queries, and federation are all the same, and the web parts are largely common. All of the products described previously provide a unified Query Object Model. The result is that if you develop a custom solution that uses the Query Object Model for SharePoint Foundation 2010, for example, it continues to work if you upgrade to SharePoint Server 2010, or if you migrate your code to FAST Search Server 2010 for SharePoint.
Figure 6-3 shows the “stack” involved with Enterprise Search, from the user down to the search cores.

FIGURE 6-3
For the rest of this chapter, we describe one set of capabilities and OMs and call out specific differences within the product line where relevant.
SEARCH USER EXPERIENCE
Information workers typically start searches either from the Simple Search box or by browsing to a site based on a Search Center site template. Figure 6-4 shows the Simple Search box that is available by default on all site pages. By default, this search box issues queries that are scoped to the current site, because users often navigate to sites that they know contain the information they want before they perform a search.
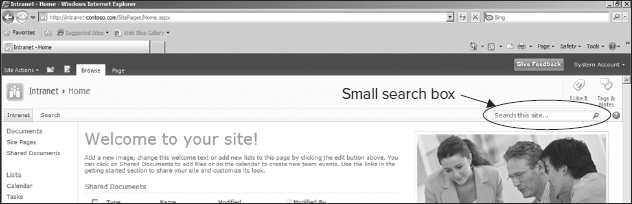
FIGURE 6-4
Search Center
Figure 6-5 shows a search site based on the Enterprise Search Center template. Information workers use Search Center sites to search across all crawled and federated content.
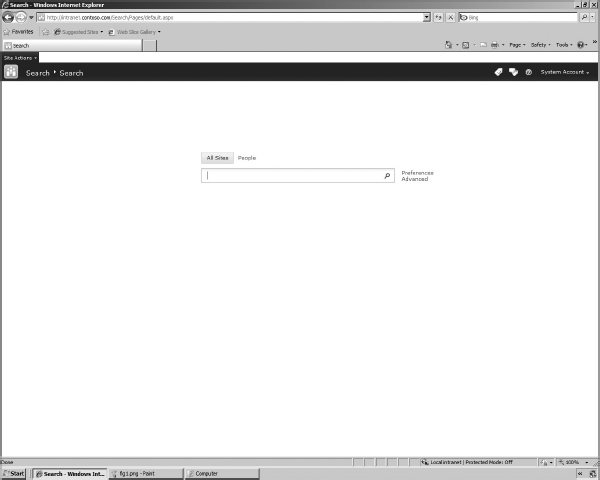
FIGURE 6-5
Note how the Search Center includes an Advanced Search Box that provides links to the current user's search preferences and advanced search options. By default, the Search Center includes search tabs to toggle between All Sites and People.
Figure 6-6 shows the default view for performing an advanced search, with access to phrase management features, language filters, result type filters, and property filters.
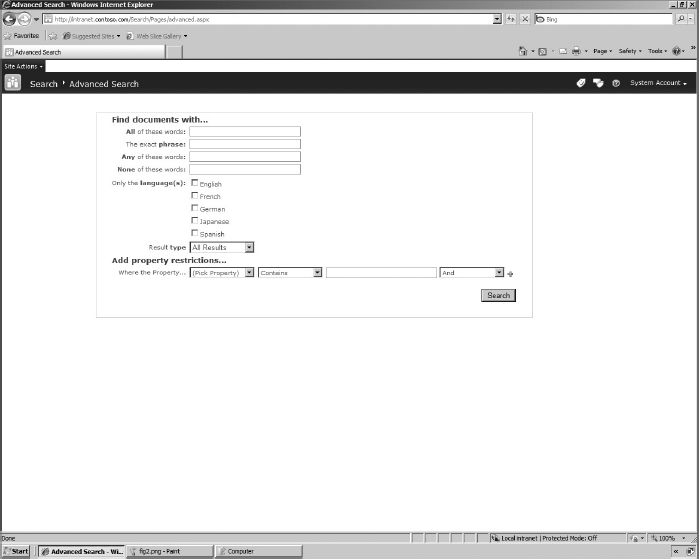
FIGURE 6-6
All of the search user interfaces are intuitive and easy to use, so information workers can start searches in a very straightforward way. When someone performs a search, the results are displayed on a results page, as shown in Figure 6-7. The SharePoint Sever 2010 Search core results page offers a very user-friendly and intuitive user interface. People can use simple and familiar keyword queries, and get results in a rich and easy-to-navigate layout. A Search Center site template is provided, as well as a simple search box that can be made available on every page in a SharePoint Server 2010 site.

FIGURE 6-7
Visual Cues in Search Results
FAST Search for SharePoint adds visual cues into the search experience. These provide an engaging, useful, and efficient way for information workers to interact with search results. People find information faster when they recognize documents visually. A search result from FAST Search for SharePoint is shown in Figure 6-8.
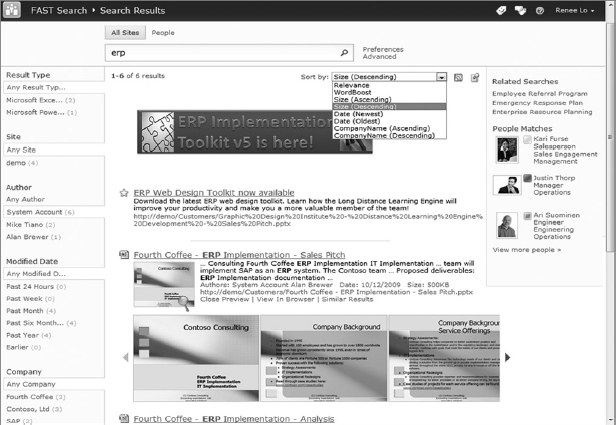
FIGURE 6-8
Thumbnails and Previews
Word documents and PowerPoint presentations can be recognized directly in search results. A thumbnail image is displayed along with the search results to provide rapid recognition of information and, thereby, faster information finding. This feature is part of the Search Core Results web part for FAST Search Server 2010 for SharePoint, and can be configured in that web part.
In addition to the thumbnail, a scrolling preview is available for PowerPoint documents, enabling an information worker to browse the actual slides in a presentation. People are often looking for a particular slide, or remember a presentation on the basis of a couple of slides. This preview helps them recognize what they're looking for quickly, without having to open the document.
Visual Best Bets
SharePoint Server 2010 Search keywords can have definitions, synonyms, and Best Bets associated with them. A Best Bet is a particular document set up to appear whenever someone searches for a keyword. It appears along with a star icon and the definition of that keyword. FAST Search Server 2010 for SharePoint enables you to define Visual Best Bets for keywords. This Visual Best Bet may be anything you can identify with a URI — an image, video, or application. It provides a simple, powerful, and very effective way to guide people's search experience.
These visual search elements are unique to FAST Search Server 2010 for SharePoint and are not provided in SharePoint Server 2010 Search.
Exploration and Refinement
SharePoint Server 2010 also provides a new way to explore information — via search refinements, as shown in Figure 6-9. These refinements are displayed down the left side of the page in the core search results. They provide self-service drill-down capabilities for filtering the search results returned. The refinements are automatically determined by SharePoint Server 2010 using tags and metadata in the search results. Such refinements include searching by the type of content (web page, document, spreadsheet, presentation, and so on), location, author, last modified date, and metadata tags. Administrators can extend the refinement panel easily to include refinements based on any managed property.

FIGURE 6-9
Refinement with FAST Search Server 2010 for SharePoint is considerably more powerful than refinement in SharePoint Server 2010. SharePoint Server 2010 automatically generates shallow refinement for search results that enable a user to apply additional filters to search results based on the values returned by the query. Shallow refinement is based on the managed properties returned from the first 50 results by the original query.
In contrast, FAST Search Server 2010 for SharePoint offers the option of deep refinement, which is based on statistical aggregation of managed property values within the entire result set.
Using deep refinement, you can find the needle in the haystack, such as a person who has written a document about a specific subject, even if this document would otherwise appear far down the result list. Deep refinement can also display counts and lets the user see the number of results in each refinement category. You can also use the statistical data returned for numeric refinements in other types of analysis.
“Conversational” Search
Search is more than “find” it is also “explore.” In many situations, the quickest and most effective way to find or explore is through a dialogue with the machine — a “conversation” allowing the user to respond to results and steer towards the answer or insight. The conversational search capabilities in FAST Search for SharePoint provide ways for information workers to interact with and refine their search results, so that they can quickly find the information they require.
Sorting Results
With FAST Search Server 2010 for SharePoint, users can sort results in different ways, such as sorting by Author, Document Size, or Title. Relevance ranking profiles can also be surfaced as sorting criteria, allowing end users to pick different relevance rankings as desired.
This sorting is considerably more powerful than sorting in SharePoint Server 2010 Search. By default, SharePoint Server 2010 sorts results on each document's relevance rank. Information workers can re-sort the results by date modified, but these are the only two sort options available in SharePoint Server 2010 without writing custom code.
Similar Results
With FAST Search Server 2010 for SharePoint, results returned by a query include links to “Similar Results.” When a user clicks on the link, the search and result set are expanded to include documents that are similar to the previous results.
Result Collapsing
FAST Search Server 2010 for SharePoint documents that have the same numeric value stored in the index are collapsed as one document in the search result. This means that documents stored in multiple locations in a source system are displayed only once during a search using the collapse search parameter. The collapsed results include links to Duplicates. When a user clicks on the link, the search result displays all versions of that document. Similar results and result collapsing are unique to FAST Search Server 2010 for SharePoint and are not provided in SharePoint Server 2010 Search.
Contextual Search Capabilities
FAST Search Server 2010 for SharePoint allows you to associate the properties of a user's context with Best Bets, Visual Best Bets, document promotions, document demotions, site promotions, and site demotions to tailor the search experience. You can use the FAST Search User Context link in the Site Collection Settings pages to define user contexts for these associations.
For example, people in different roles might receive a different visual best bets — so that a salesperson sees content about sales promotions while a consultant sees content about delivery. Similarly, people in different geographies might get different content. You can create tailored experiences easily using this feature.
Relevancy Tuning by Document or Site Promotions
SharePoint Server 2010 enables you to identify varying levels of authoritative pages that help you tune relevancy ranking by site. FAST Search Server 2010 for SharePoint adds the ability for you to specify individual documents within a site for promotion and, furthermore, enables you to associate each promotion with user contexts.
Synonyms
SharePoint Server 2010 keywords can have one-way synonyms associated with them. FAST Search Server 2010 for SharePoint extends this concept by enabling you to implement both two-way and oneway synonyms. With a two-way synonym set of, for example, {auto car}, a search for “auto” would be translated into a search for “auto OR car,” and a search for “car” would be translated into a search for “car OR auto.” With a one-way synonym set of, for example, {car coupe}, a search for “car” would translate into a search for “car OR coupe,” but a search for “coupe” would remain just “coupe.”
People Search
SharePoint Server 2010 provides an address-book-style name lookup experience with name and expertise matching, making it easy to find people by name, title, expertise, and organizational structure. This includes phonetic name matching that returns names that sound similar to what the user has typed in a query. It also returns all variations of common names, including nicknames.
The refiners provided for the core search results are also provided with people search results — exploring results via name, title, and various fields in a user's profile enable quick browsing and selection of people. People search results also include real-time presence through Office Communication Server, making it easy to immediately connect with people once they are found through search. Figure 6-10 shows a people search results page.
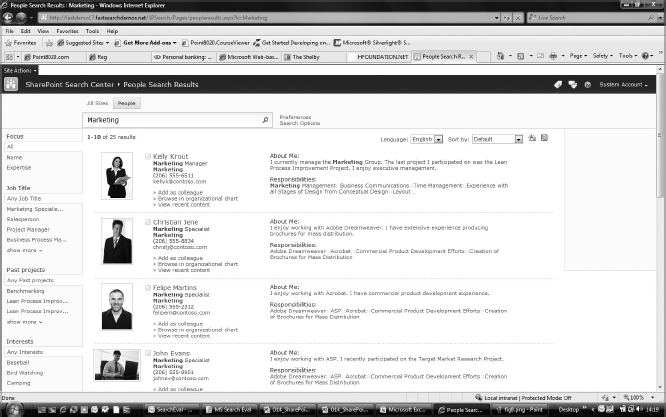
FIGURE 6-10
The people and expertise finding capabilities with SharePoint Server 2010 are a dramatic enhancement over MOSS 2007. They are remarkably innovative and effective, and tie in nicely to the social computing capabilities covered in Chapter 5. The exact same capabilities are available with FAST Search for SharePoint.
SEARCH ARCHITECTURE AND TOPOLOGIES
The search architecture has been significantly enhanced with SharePoint Server 2010. The new architecture provides fault-tolerance options and scaling to 100 million documents, well beyond the limits of MOSS 2007 search. Adding FAST provides even more flexibility and scale. Of course, these capabilities and flexibility add complexity. Understanding how search fits together architecturally will help you build applications that scale well and perform quickly.
SharePoint Search Key Components
Figure 6-11 provides an overview of the logical architecture for the Enterprise Search components in SharePoint Server 2010.

FIGURE 6-11
As shown in Figure 6-11, four main components deliver the Enterprise Search features of SharePoint Server 2010:
- Crawler: This component invokes connectors that are capable of communicating with content sources. Because SharePoint Server 2010 can crawl different types of content sources (such as SharePoint sites, other websites, file shares, Lotus Notes databases, and data exposed by Business Connectivity Services), a specific connector is used to communicate with each type of source. The crawler then uses the connectors to connect to and traverse the content sources, according to crawl rules that an administrator can define. For example, the crawler uses the file connector to connect to file shares by using the FILE:// protocol, and then traverses the folder structure in that content source to retrieve file content and metadata. Similarly, the crawler uses the web connector to connect to external websites by using the HTTP:// or HTTPS:// protocols and then traverses the web pages in that content source by following hyperlinks to retrieve web page content and metadata. Connectors load specific IFilters to read the actual data contained in files. Refer to the “New Connector Framework Features” section later in this document for more information about connectors.
- Indexer: This component receives streams of data from the crawler and determines how to store that information in a physical, file-based index. For example, the indexer optimizes the storage space requirements for words that have already been indexed, manages word breaking and stemming in certain circumstances, removes noise words, and determines how to store data in specific index partitions if you have multiple query servers and partitioned indexes. Together with the crawler and its connectors, the indexing engine meets the business requirement of ensuring that enterprise data from multiple systems can be indexed. This includes collaborative data stored in SharePoint sites, files in file shares, and data in custom business solutions, such as customer relationship management (CRM) databases, enterprises resource planning (ERP) solutions, and so on.
- Query Server: Indexed data that is generated by the indexing engine is propagated to query servers in the SharePoint farm, where it is stored in one or more index files. This process is known as “continuous propagation” that is, while indexed data is being generated or updated during the crawl process, the changes are propagated to query servers, where they are applied to the index file (or files). In this way, the data in the indexes on query servers experience a very short latency. In essence, when new data has been indexed (or existing data in the index has been updated), those changes are applied to the index files on query servers in just a few seconds. A server that is performing the query server role responds to searches from users by searching its own index files, so it is important that latency be kept to a minimum. SharePoint Server 2010 ensures this automatically. The query server is responsible for retrieving results from the index in response to a query received via the Query Object Model. The query sever is also responsible for the word breaking, noise-word removal, and stemming (if stemming is enabled) for the search terms provided by the Query Object Model.
- Query Object Model: As mentioned earlier, searches are formed and issued to query servers by the Query Object Model. This is typically done in response to a user performing a search in a SharePoint site, but it may also be in response to a search service call from either within or outside the SharePoint farm. Furthermore, the search might have been issued by custom code, for example, from a workflow or from a custom navigation component. In any case, the Query Object Model parses the search terms and issues the query to a query server in the SharePoint farm. The results of the query are returned from the query server to the Query Object Model, and the object model provides the results back to the caller.
Figure 6-12 shows a process view of SharePoint Server Search. The Shared Service Architecture (SSA), new to SharePoint 2010, is used to provide a shareable and scalable service. A search SSA can work across multiple SharePoint farms, and is administered on a service level.
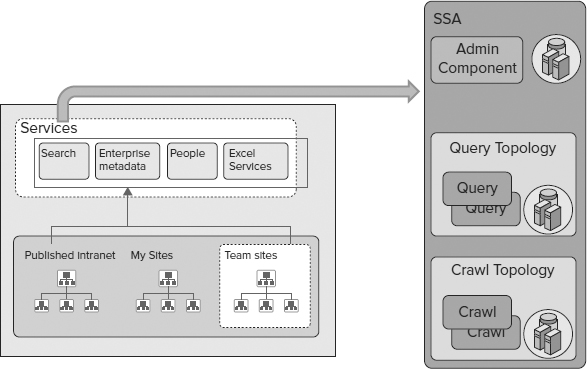
FIGURE 6-12
Search Topologies, Scaling, and High Availability
SharePoint Server 2010 enables you to add multiple instances of each of the crawler, indexing, and query components. This level of flexibility means that you can scale your SharePoint farms. Previous versions of SharePoint Server did not allow you to scale or provide redundancy for the indexing component.
The Enterprise Search features in SharePoint Server 2010 aim to provide subsecond query latencies for all queries, regardless of the size of your farm, and to remove bottlenecks that were present in previous versions of SharePoint Server. You can achieve these aims by implementing a scaled-out architecture. SharePoint Server 2010 enables you to scale out every logical component in your search architecture, unlike previous versions.
As shown in Figure 6-13, the architecture provides scaling at multiple levels. You can add multiple crawlers/ indexers to your farm to increase availability and to achieve higher performance for the indexing process. You can also add multiple query servers to increase availability and to achieve high query performance. All components, including administration, can be fault tolerant and can take advantage of the mirroring capabilities of the underlying databases.

FIGURE 6-13
The crawlers handle indexing as well. Each crawler can be assigned to a discrete set of content sources, so not all indexers need to index the entire corpus. This is a new capability for SharePoint Server 2010. Crawlers are now stateless, so that one can take over the activity of another, and they use the crawl database to coordinate the activity of multiple crawlers. Indexers no longer store full copies of the index; they simply propagate the indexes to query servers. Crawling and indexing are I/O and CPU intensive; adding more machines increases the crawl/index throughput linearly. Because content freshness is determined by crawl frequency, adding resources to crawling can provide fresher content, too.
When you add multiple query servers, you are really implementing index partitioning; each query server maintains a subset of the entire logical index and, therefore, does not need to query the entire index (which could be a very large file) for every query. The partitions are maintained automatically by SharePoint Server 2010, which uses a hash of each crawled document's ID to determine in which partition a document belongs. The indexed data is then propagated to the appropriate query server.
Another new feature is that property databases are also propagated to query servers so that retrieving managed properties and security descriptors is much more efficient than in Microsoft Office SharePoint Server 2007.
High Availability and Resiliency
Each search component also fulfills high-availability requirements by supporting mirroring. Figure 6-14 shows a scaled-out and mirrored architecture, sized for 100 million documents. SQL Server mirroring is used to keep multiple instances synchronized across geographic boundaries. In this example, each of the six query processing servers serves results from a partition of the index and also acts as a failover for another partition. The two crawler servers provide throughput (multiple crawlers) as well as high availability — if either crawler server fails the crawls continue.

FIGURE 6-14
As with any multi-tier system, understanding the level of performance resiliency you need is the starting point. You can then engineer for as much capacity and safety as you need.
FAST Architecture and Topology
FAST Search for SharePoint shares many architectural features of SharePoint Server 2010 search. It uses the same basic layers (crawl, index, query) architecturally. It uses the same crawler and query handlers, and the same people and expertise search. It uses the same OMs and the same administrative framework.
However, there are some major differences. FAST Search for SharePoint adds on to SharePoint server in a hybrid architecture (see Figure 6-2). This means that processing from multiple farms is used to form a single system. Understanding what processing happens in what farm can be confusing; remembering the hybrid approach with common crawlers and query OM, but separate people and content search is key to understanding the system configuration.
Figure 6-15 shows a high-level mapping of processing to farms. Light gray represents the SharePoint farm, medium gray represents the FAST backend farm, and dark gray represents other systems such as the System Center Operations Manager (SCOM).

FIGURE 6-15
SharePoint 2010 provides shared service applications (SSAs) to serve common functions across multiple site collections and farms. SharePoint Server 2010 search uses one SSA (see Figure 6-12). FAST Search for SharePoint uses two SSAs: the FAST Query SSA and the FAST Content SSA. This is a result of the hybrid architecture (shown in Figure 6-2) with SharePoint servers providing people search and FAST servers providing content search. Both SSAs run on SharePoint farms and are administered from the SharePoint 2010 central administration console.
The FAST farm (also called the FAST backend) includes a Query Service, document processors that provide advanced content processing, and FAST-specific indexing connectors used for advanced content retrieval. Configuration of the additional indexing connectors is performed via XML files and through Windows PowerShell cmdlets or command-line operations, and are not visible via SharePoint Central Administration. Figure 6-16 gives an overview of where the SSAs fit in the search architecture.
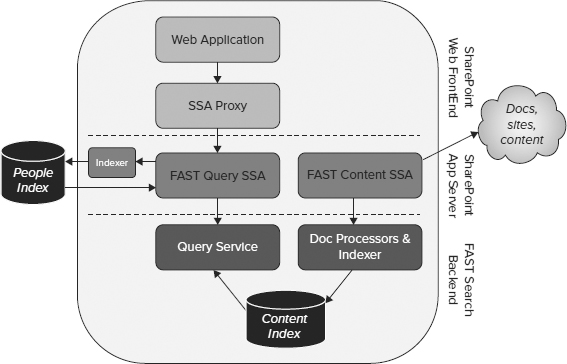
FIGURE 6-16
The use of multiple SSAs to provide one FAST Search for SharePoint system is probably the most awkward aspect of FAST Search for SharePoint and the area of the most confusion. In practice, this is pretty straightforward, but you need to get your mind around the hybrid architecture and keep this in mind when you are architecting or administering a system. As a developer, you have to remember this when you are using the Administrative OM as well. The FAST backend is essentially a black box as far as SharePoint is concerned; all the administrative UI functions run in SharePoint and administer via the SSAs. One result of this is that the FAST Search for SharePoint distribution is only available in English, whereas the SharePoint distribution has many different language packs.
The FAST Query SSA handles all queries and also serves people search. If the queries are for content search, it routes them to a FAST Query Service (which resides on a FAST farm). Routing uses the default service provider property — or overrides this if you explicitly set a provider on the query request.
The FAST Query SSA also handles crawling for people search content. This is confusing to many because the people search is served from the same process that serves SharePoint 2010 search; it is in fact exactly the same search. If you look at the crawl administration screens for the FAST Query SSA, you should see it crawling the profile store, and nothing else. All other crawls appear in the FAST Content SSA.
The FAST Content SSA handles all the content crawling that goes through the SharePoint connectors or connector framework. It feeds all content as crawled properties through to the FAST farm (specifically a FAST content distributor), using extended connector properties. The FAST Content SSA includes indexing connectors that can retrieve content from any source, including SharePoint farms, internal/external web servers, Exchange public folders, line-of-business data and file shares.
Scale Out with FAST
FAST Search for SharePoint is built on a highly modular architecture where the services can be scaled individually to achieve the desired performance. The architecture of FAST Search for SharePoint uses a row and column approach for core system scaling, as shown in Figure 6-17.
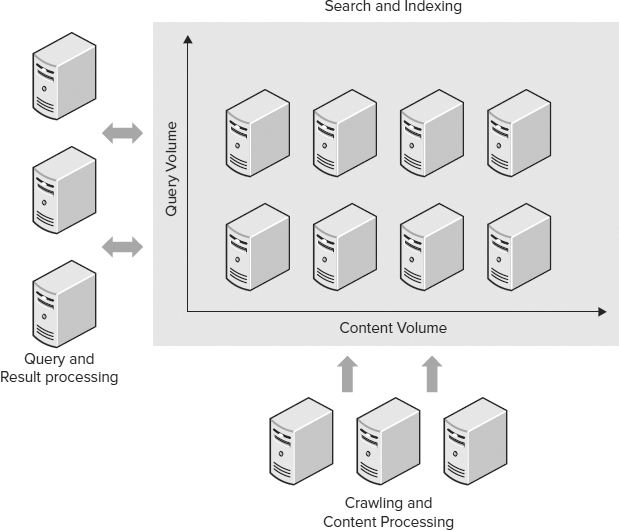
FIGURE 6-17
This architecture provides extreme scale and fault tolerance with respect to:
- Amount of indexed content: Each column handles a partition of the index, which is kept as a file on the file system (unlike SharePoint Server search index partitions, which are held in a database). By adding columns, the system can scale linearly to extreme scale — billions of documents.
- Query load: Each row handles a set of queries; multiple rows provide both fault tolerance and capacity. An extra row provides full fault tolerance, so if an application required four rows for query handling, a fifth row would provide fault tolerance. (For most inside-the-firewall implementations, a single row provides plenty of query capacity).
- Freshness (indexing latency): FAST Search for SharePoint enables you to optimize for low latency from the moment a document is changed in the source repository to the moment it is searchable. This can be done by proper dimensioning of the crawling, item processing, and indexing to fulfill your requirements. These three parts of the system can be scaled independently through the modular architecture.
Figure 6-18 shows an example of a FAST Search for SharePoint topology, with full fault tolerance, sized for several hundred million documents.
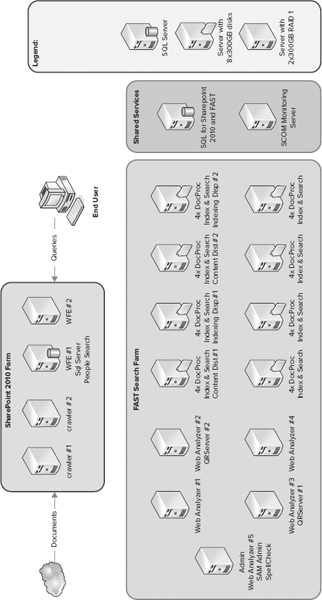
FIGURE 6-18
This example includes both the SharePoint Server farm and the FAST Search backend farm. Because the connector framework is the same, crawling scale out and redundancy are the same as with SharePoint Server 2010 Search — unless FAST-specific connectors are in use. The query-mirroring approach is the same as with SharePoint Server Search, except that content queries are processed very lightly before handing off to FAST — so query capacity per machine or virtual machine (VM) is much higher for the SharePoint servers. The center layer is a farm of FAST Search servers, in a row-column architecture — which provides both scaling and fault tolerance.
FAST Search for SharePoint provides a high-density mode that supports up to 45 million items per node (versus 15 million in standard mode). When you are working in this mode, your query response times are slightly longer. Using high-density mode is nearly always the best approach, because the hardware savings are significant and the added delay is quite small. Figure 6-19 compares the server counts for SharePoint search, FAST, and FAST with high-density mode.
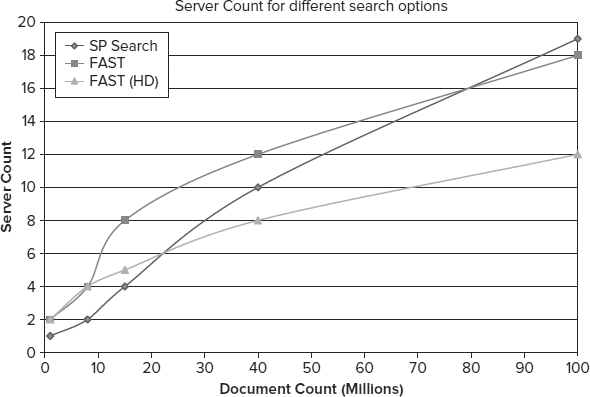
FIGURE 6-19
SharePoint runs well with virtualization and with centralized storage such as Storage Area Networks (SANs), but planning and operating a large search topology with a SAN is a complex task. Search performance depends on I/O latency for random I/O, and each query may generate a dozen or more I/Os. Using SANs can be a great way to provide the needed storage, but shared SANs can be problematic, especially those engineered for low cost rather than high performance. Search performance using virtual machines is lower than on bare metal, and all VMs need adequate resources. Both SharePoint Search and FAST Search for SharePoint work well in virtual environments when set up properly. Figure 6-20 shows an example large-scale configuration planned for a virtual environment.
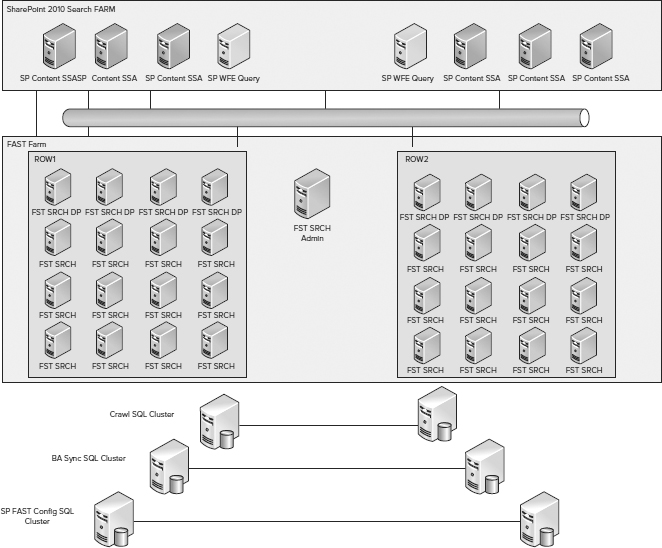
FIGURE 6-20
How Architecture Meets Applications
Capacity planning, scaling, and sizing are usually the domain of the IT pro; as a developer, you need only be aware that the architecture supports a much broader range of performance and availability than MOSS 2007. You can tackle the largest, most demanding applications without worrying that your application won't be available at extreme scale.
Architecture is also important for applications that control configuration and performance. You may want to set up a specific recommended configuration — or implement self-adjusting performance based on the current topology, load, and performance. The architecture supports adding new processing on the fly — in fact, the central administration console makes it easy to do so. This means that your applications can scale broadly, ensure good performance, and meet a broad range of market needs.
DEVELOPING WITH ENTERPRISE SEARCH
Developing search-powered applications has been a difficult task. Even though search is simple on the outside, it is complicated on the inside. With SharePoint 2010, developers have a development platform that is much more powerful and simpler to work with than MOSS 2007. That fact extends to search-based applications as well. Through a combination of improvements to the ways in which developers can collect data from repositories, query that data from the search index, and display the results of those queries, SharePoint Server 2010 offers a variety of possibilities for more complex and flexible search applications that access data from a wide array of locations and repositories.
There are many areas where development has become simpler — where you can cover with configuration what you used to do with code, or where you can do more with search. The new connector framework provides a flexible standard for connecting to data repositories through managed code. This reduces the amount of time and work required to build and maintain code that connects to various content sources. Enhanced keyword query syntax makes it easier to build complex queries by using standard logical operators, and the newly public Federated Search runtime object model provides a standard way of invoking those queries across all relevant search locations and repositories. The changes enable a large number of more complex interactions among Search web parts and applications, and ultimately a richer set of tools for building search result pages and search-driven features.
Range of Customization
Customization of search falls into three main categories:
- Configure: Using configuration parameters alone, you can set up a tailored search system. Usually, you are working with web part configuration, XML, and PowerShell. Most of the operations are similar to what IT pros use in administering search — but packaged ahead of time by you as a developer.
- Extend: Using the SharePoint Designer, XSLT, and other “light” development, you can create vertical and role-specific search applications. Tooling built into SPD lets you build new UIs and new connectors without code.
- Create: Search can do amazing things in countless scenarios when controlled and integrated using custom code. Visual Studio 2010 has tooling built in, which makes developing applications with SharePoint much easier. In many of these scenarios, search is one of many components in the overall application.
Figure 6-21 shows the range of customization and the tooling typically used in these three categories. There are no hard rules here — general-purpose search applications, such as intranet search, can benefit from custom code and might be highly customized in some situations, even though intranet search works with no customization at all. However, most customization tends to be done on special-purpose applications with a well-identified set of users and a specific set of tasks they are trying to accomplish. Usually, these are the most valuable applications as well — ones that make customization well worth it.
FIGURE 6-21
Top Customization Scenarios
Although there are no hard rules, there are common patterns found when customizing Enterprise Search. The most common customization scenarios are:
- Modify the end user experience to create a specific experience and/or surface specific information. Examples: add a new refinement category, show results from federated locations, modify the look and feel of the OOB end user experience, enable sorting by custom metadata, add a Visual Best Bet for an upcoming sales event, configure different rankings for the human resources and engineering departments.
- Create a new vertical search application for a specific industry or role. Examples: connecting to and indexing specific new content, designing a custom search experience, adding Audio/ Video/Image search.
- Create new visual elements that add to the standard search. Examples: show location refinement on charts/maps, show tags in a tag cloud, enable “export results to a spreadsheet,” summarize financial information from customers in graphs.
- Develop content pipeline plug-ins: Used to process content in more sophisticated ways. Example: create a new “single view of the customer” application that includes customer contact details, customer project details, customer correspondence, internal experts, and customer-related documents.
- Query and indexing shims: Add terms and custom information to the search experience. Examples: expand query terms based on synonyms defined in the term store, augment customer results with project information, show popular people inline with search results, or show people results from other sources. Both the query OM and the connector framework provide a way to write “shims” — simple extensions of the .NET assembly where a developer can easily add custom data sources and/or do data mash-ups.
- Create new search-driven sites and applications: Create customized content exploration experiences. Examples: show email results from personal mailbox on Exchange Server through Exchange Web Services (EWS), index content from custom repositories like Siebel, create content-processing plug-ins to generate new metadata.
Search-Driven Applications
Search is generally not well understood or fully used by developers. SharePoint 2010 can change all that. By making it easier to own and use high-end search capabilities, and by including tooling and hooks specifically for application developer, Microsoft has taken a big step forward in helping developers do more with search.
Figure 6-22 shows some examples of search-driven applications. These are applications like any other, except that they take advantage of search technology in addition to other elements of SharePoint to create flexible and powerful user experiences.

FIGURE 6-22
The rest of this chapter covers different aspects of search with SharePoint 2010, highlighting how you can customize them and how you can include them in search-driven applications.
CUSTOMIZING THE SEARCH USER EXPERIENCE
While the out-of-the-box user interface is very intuitive and useful for information workers, power users can create their own search experiences. SharePoint Server 2010 includes many search-related web parts for power users to create customized search experiences, including Best Bets, refinement panel extensions, featured content, and predefined queries. Figure 6-23 shows the Search web parts.

FIGURE 6-23
IT pros or developers can configure the built-in search web parts to tailor the search experience. As a developer, you can also extend the web parts, which makes it unnecessary to create web parts to change the behavior of built-in web parts on search results pages. Instead of building new web parts, developers can build onto the functionality of existing web parts.
The most important search web parts provided are as follows:
- Advanced Search box: Allows users to create detailed searches against Managed Properties
- Federated Results: Displays results from a federated search location
- People Refinement Panel: Presents facets that can be used to refine a people search
- People Search box: Allows users to search for people using a keyword
- People Search Core Results: Displays the primary result set from a people search
- Refinement panel: Presents facets that can be used to refine a search
- Related Queries: Presents queries related to the user's query
- Search Action links: Displays links for RSS, alerts, and Windows Explorer
- Search Best Bets: Presents best-bets results
- Search box: Allows users to enter keyword query searches
- Search Core Results: Displays the primary result set from a query
- Search Paging: Allows a user to page through search results
- Search Statistics: Presents statistics such as the time taken to execute the query
- Search Summary: Provides a summary display of the executed query
- Top Federated Results: Displays top results from a federated location
You can use these web parts in combination with each other, and create new search web parts by extending the OOB ones.
Example: New Core Results Web Part
This section walks you through the creation of a new search web part in Visual Studio 2010. (The full code is included with Code Project 6-P-1, which contains SortedSearch.zip and is courtesy of Steve Peschka.) This web part inherits from the CoreResultsWebPart class and displays data from a custom source. The standard CoreResultsWebPart part includes a constructor and then two methods that you learn how to modify in this example.
The first step is to create a new WebPart class. Create a new web part project that inherits from the CoreResultsWebPart class. Override CreateChildControls to add any controls necessary for your interface, and then override CreateDataSource. This is where you get access to the “guts” of the query. In the override, you create an instance of a custom datasource class you build.

class MSDNSample : CoreResultsWebPart { public MSDNSample() { //default constructor; } protected override void CreateChildControls() { base.CreateChildControls(); //add any additional controls needed for your UI here } protected override void CreateDataSource() { //base.CreateDataSource(); this.DataSource = new MyCoreResultsDataSource(this); }
![]()
![]() All code in this section is from the SortedSearch.zip project file. To follow along, download the code and unzip it. The file has a complete ready-to-go project.
All code in this section is from the SortedSearch.zip project file. To follow along, download the code and unzip it. The file has a complete ready-to-go project.
The second step is to create a new CoreResultsDatasource class. In the override for CreateDataSource, set the DataSource property to a new class that inherits from CoreResultsDataSource. In the CoreResultsDataSource constructor, create an instance of a custom datasource view class you will build. No other overrides are necessary.
public class MyCoreResultsDataSource : CoreResultsDatasource
{
public MyCoreResultsDataSource(CoreResultsWebPart ParentWebpart)
: base(ParentWebpart)
{
//to reference the properties or methods of the web part
//use the ParentWebPart parameter
//create the View that will be used with this datasource
this.View = new MyCoreResultsDataSourceView(this,“MyCoreResults”);
}
}
The third step is to create a new CoreResultsDatasourceView class. Set the View property for your CoreResultsDatasource to a new class that inherits from CoreResultsDatasourceView. In the CoreResultsDatasourceView constructor, get a reference to the CoreResultsDatasource so that you can refer back to the web part. Then, set the QueryManager property to the shared query manager used in the page.
public class MyCoreResultsDataSourceView : CoreResultsDatasourceView
{
public MyCoreResultsDataSourceView(SearchResultsBaseDatasource
DataSourceOwner, string ViewName):
base(DataSourceOwner, ViewName)
{
//make sure we have a value for the datasource
if (DataSourceOwner == null)
{
throw new ArgumentNullException(“DataSourceOwner”);
}
//get a typed reference to our datasource
MyCoreResultsDataSource ds = this.DataSourceOwner as
MyCoreResultsDataSource;
//configure the query manager for this View
this.QueryManager =
SharedQueryManager.GetInstance(ds.ParentWebpart.Page
.QueryManager);
}
You now have a functional custom web part displaying data from your custom source. In the next example, you take things one step further to provide some custom query processing.
Example: Adding Sorting to Your New Web Part
The CoreResultsDataSourceView class lets you modify virtually any aspect of the query. The primary way to do that is in an override of AddSortOrder. This class provides access to SharePointSearchRuntime class, which includes: KeywordQueryObject, Location, and RefinementManager.
The following code example adds sorting by overriding AddSortOrder. (The full code is included with Code Project 6-P-1, courtesy of Steve Peschka.)
public override void AddSortOrder(SharePointSearchRuntime runtime)
{
#region Ensure Runtime
//make sure our runtime has been properly instantiated
if (runtime.KeywordQueryObject == null)
{
return;
}
#endregion
//remove any other sorted fields we might have had
runtime.KeywordQueryObject.SortList.Clear();
//get the datasource so we can get to the web part
//and retrieve the sort fields the user selected
SearchResultsPart wp = this.DataSourceOwner.ParentWebpart
as SearchResultsPart;
string sortField = wp.SortFields;
//check to see if any sort fields have been provided
if (Istring.IsNullOrEmpty(sortField))
{
//if posting back, then use the value from the sort drop-down
if (wp.Page.IsPostBack)
{
//get the sort direction that was selected
SortDirection dir =
(wp.Page.Request.Form[SearchResultsPart.mFormSortDirection]
== “ASC” ?
SortDirection.Ascending : SortDirection.Descending);
//configure the sort list with sort field anddirection
runtime.KeywordQueryObject.SortList.Add
(wp.Page.Request.Form[SearchResultsPart.mFormSortField],
dir);
}
else
{
//split the value out from its delimiter and
//take the first item in descending order
string[] values = sortField.Split(“;”.ToCharArray(),
StringSplitOptions.RemoveEmptyEntries);
runtime.KeywordQueryObject.SortList.Add(values[0],
SortDirection.Descending);
}
}
else
//no sort fields provided so use the default sortorder
base.AddSortOrder(runtime);
}
![]()
The KeywordQueryObject class is what's used in this scenario. It provides access to key query properties like:
- EnableFQL
- EnableNicknames
- EnablePhonetic
- EnableStemming
- Filter
- QueryInfo
- QueryText
- Refiners
- RowLimit
- SearchTerms
- SelectProperties
- SortList
- StartRow
- SummaryLength
- TrimDuplicates
- … and many more
To change the sort order in your web part, first remove the default sort order. Get a reference to the web part, as it has a property that has the sort fields. If the page request is a post-back, then get the sort field the user selected. Otherwise, use the first sort field the user selected. Finally, add the sort field to the SortList property.
To allow sorting, you also need to provide fields on which to sort. Ordering can be done with DateTime fields, Numeric fields, or Text fields where: HasMultipleValues = false, IsInDocProps = true, and MaxCharactersInPropertyStoreIndex > 0.
You can limit the user to selecting only fields by creating a custom web part property editor. This would follow the same process as in SharePoint 2007: inherit from EditorPart and implement IWebEditable. The custom version of EditorPart in this example web part uses a standard LINQ query against the search schema to find properties.
Web Parts with FAST
SharePoint search and FAST Search for SharePoint share the same UI framework. When you install FAST Search for SharePoint, the same Search Centers and Small Search Box web parts apply; the main Result web part and Refiner web part are replaced with FAST-specific versions, and a Search Visual Best Bets web part is added. Otherwise, the web parts (like the Related Queries web part or Federated Results web part) remain the same.
Because of the added capabilities of FAST, there are some additional configuration options. For example, the Core Results web part allows for configuration of thumbnails and scrolling previews — whether to show them or not, how many to render, and so forth. The search Action Links web part provides configuration of the sorting pulldown (which can also be used to expose multiple ranking profiles to the user). The Refinement web part has additional options, and counts are returned with refiners (since they are deep refiners — over the whole result set).
The different web parts provided with FAST Search for SharePoint and the additional configuration options are fairly self-evident when you look at the web parts and their documentation. Because web parts are public with SharePoint 2010, you can look at them directly and see the available configuration options within Visual Studio.
There are many features you can build with search and web parts. By modifying the Content Query web part to use data from search, for example, you can show dynamic content on your pages in nearly any format you like. Something as simple as adding a Survey web part on your search page can make a big difference in the search experience and is a great way to gather feedback that you can use to improve search for everyone.
SEARCH CONNECTORS AND SEARCHING LOB SYSTEMS
Acquiring content is essential for search: if it's not crawled, you can't find it! Typical enterprises have hundreds of repositories of dozens of different types. Bridging content silos in an intuitive UI is one of the primary benefits of search applications. SharePoint 2010 supports this through a set of pre-created connectors, plus a framework and set of tools that make it much easier to create and administer connectivity to whatever source you like. There is already a rich set of partner-built connectors to choose from, and as a developer, you can easily leverage these or add to them.
Using Out-of-Box Connectors
A number of connectors provide built-in access to some of the most popular types of data repositories (including SharePoint sites, websites, file shares, Exchange public folders, Documentum instances, and Lotus Notes databases). The same connectors can be configured to work with a wide range of custom databases and web services via Business Connectivity Services (BCS). For complex repositories, custom code lets you access line-of-business data and make it searchable.
SharePoint Server 2010 supports existing protocol handlers (custom interfaces written in unmanaged C++ code) used with MOSS 2003 and MOSS 2007. However, the new BCS connector framework is now the primary way to create interfaces to data repositories. The connector framework uses .NET assemblies, and supports the BCS declarative methodology for creating and expressing connections. It also enables connector authoring by means of managed code. This increased flexibility, with enhanced APIs and a seamless end-to-end experience for creating, deploying, and managing connectors, makes the job of collecting and indexing data considerably easier.
Search leverages BCS heavily in this wave (see Chapter 11 for more information about BCS). BCS is a set of services and features that provides a way to connect SharePoint solutions to sources of external data and to define External Content Types that are based on that external data. External Content Types allow the presentation of and interaction with external data in SharePoint lists (known as external lists), web parts, Microsoft Outlook 2010, Microsoft SharePoint Workspace 2010, and Microsoft Word 2010 clients. External systems that BCS can connect to include SQL Server databases, SAP applications, web services (including Windows Communication Foundation web services), custom applications, and websites based on SharePoint. With BCS you can design and build solutions that extend SharePoint collaboration capabilities and the Office user experience to include external business data and the processes that are associated with that data.
Microsoft BCS solutions use a set of standardized interfaces to provide access to business data. As a result, developers of solutions don't have to learn programming practices that apply to a specific system or need to be adapted to work with each external data source. Microsoft BCS also provides a runtime environment in which solutions that include external data are loaded, integrated, and executed in supported Office client applications and on the web server. Enterprise Search uses these same practices and framework — and connectors can reveal information in SharePoint that is synchronized with the external line-of-business system, including writing back any changes.
New Connector Framework Features
The connector framework, shown in Figure 6-24, provides improvements over the protocol handlers in previous versions of SharePoint Server. For example, connectors can now crawl attachments, as well as the content, in email messages. Also, item-level security descriptors can now be retrieved for external data exposed by Business Connectivity Services. Furthermore, when crawling a BCS entity, additional entities can be crawled via its entity relationships. Connectors also perform better than previous versions by implementing concepts such as inline caching and batching.
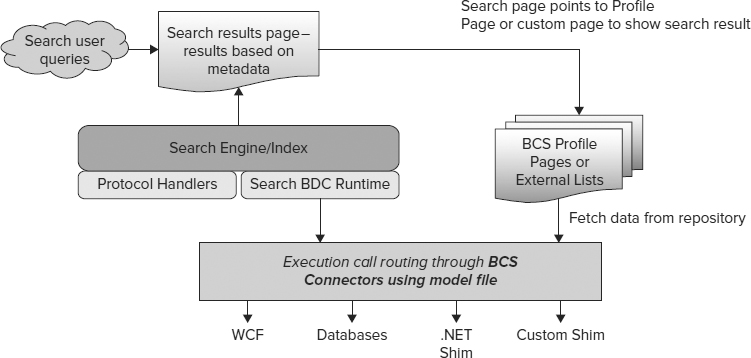
FIGURE 6-24
Connectors support richer crawl options than the protocol handlers in previous versions of SharePoint Server. For example, they support the full crawl mode that was implemented in previous versions, and they support timestamp-based incremental crawls. However, they also support change log crawls that can remove items that have been deleted since the last crawl.
FAST-Specific Indexing Connectors
The connector framework and all of the productized connectors work with FAST Search for SharePoint as well as SharePoint Server search. FAST also has two additional connectors.
The Enterprise crawler provides web crawling at high performance with more sophisticated capabilities than the default web crawler. It is good for large-scale crawling across multiple nodes and supports dynamic data, including JavaScript.
The Java Database Connectivity (JDBC) connector brings in content from any JDBC-compliant source. This connector supports simple configuration using SQL commands (joins, selects, and so on) inline. It supports push-based crawling, so that a source can force an item to be indexed immediately. The JDBC connector also supports change detection through checksums, and high-throughput performance.
These two connectors don't use the connector framework and cannot be used with SharePoint Server 2010 Search. They are FAST-specific and provide high-end capabilities. You don't have to use them if you are creating applications for FAST Search for SharePoint, but it is worth understanding if and when they apply to your situation.
Creating Indexing Connectors
In previous versions of SharePoint Server, it was very difficult to create protocol handlers for new types of external systems. Protocol handlers had to be coded in unmanaged C++ code and typically took a long time to test and stabilize.
With SharePoint Server 2010, you have many more options for crawling external systems:
- Use SharePoint Designer 2010 to create external content types and entities for databases or web services and then simply crawl those entities
- Use Visual Studio 2010 to create external content types and entities for databases or web services, and then simply crawl those entities
- Use Visual Studio 2010 to create .NET types for Business Connectivity Services (typically for backend systems that implement dynamic data models, such as document management systems), and then use either SharePoint Designer 2010 or Visual Studio 2010 to create external content types and entities for the .NET type
![]() You can still create protocol handlers (as in previous versions of SharePoint Server) if you need to.
You can still create protocol handlers (as in previous versions of SharePoint Server) if you need to.
Model Files
Every indexing connector needs a model file (also called an application definition file) to express connection information and the structure of the backend, and a BCS connector for code to execute when accessing the backend (also called a shim). The model file tells the search indexer what information from the repository to index and any custom-managed code that developers determine they must write (after consulting with their IT and database architects). The connector might require, for example, special methods for authenticating to a given repository and other methods for periodically picking up changes to the repository.
You can use OOB shims with the model file or write a custom shim. Either way, the deployment and connector management framework makes it easy — crawling content is no longer an obscure art. SharePoint 2010 also has great tooling support for connectors.
Using OOB shims (Database/WCF/.NET) is very straightforward with SharePoint 2010. OOB shims are most appropriate when connecting to “flat” data structures for read-write or flat views for read-only look-ups, and custom shims often become necessary when connecting to complex data types (for example, multi-level hierarchies or tables with multiple relationships), or when fault tolerance logic needs to be applied (for example, to provide resiliency against source schema changes).
Tooling in SPD and VS2010
Both SharePoint Designer 2010 and Visual Studio 2010 have tooling that helps in authoring connectors. You can use SharePoint Designer to create model files for out-of-box BCS connectors (such as a database), to import and export model files between BCS services applications, and to enable other SharePoint workloads using external lists. Use Visual Studio 2010 to implement methods for the .NET shim or to write custom shim for your repository.
When you create a model file through SharePoint Designer, it is automatically configured for full-fidelity performant crawling. This takes advantage of features of the new connector framework, including inline caching for better citizenship, and timestamp-based incremental crawling. You can specify the search click-through URL to go to the profile page, so that content includes writeback, integrated security, and other benefits of BCS. Crawl management is automatically enabled through the Search Management console.
Figure 6-25 shows the relationships between the elements that are most commonly changed when creating a new connector using SharePoint Designer and OOB shims.
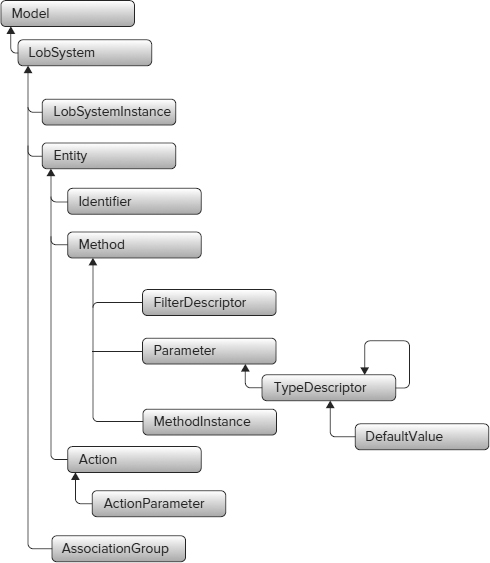
FIGURE 6-25
Figure 6-26 shows the Configuration panel within SharePoint Designer.

FIGURE 6-26
Writing Custom Connectors
This section walks through how to create a connector with a custom shim. Assume that you have a product catalog in an external system and want to make it searchable. Code project 6-P-2 shows the catalog schema and walks through this example step by step.
There are two types of custom connectors: a managed .NET Assembly BCS connector and a custom BCS connector. In this case, you use the .NET BCS connector approach. You need to create only two things: the URL parsing classes, and a model file.
The code is written with .NET classes and compiled into a Dynamic Link Library (DLL). Each entity maps to a class in the DLL, and each BDC operation in that entity maps to a method inside that class. After the code is done and the model file is uploaded, you can register the new connector either by adding DLLs to the global assembly cache (GAC) or by using PowerShell cmdlets to register the BCS connector model file. Configuration of the connector is then available through the standard UI; the content sources, crawl rules, managed properties, crawl schedule, and crawl logs work as they do in any other repository.
If you chose to build a custom BCS connector, you implement the ISystemUtility interface for connectivity. For URL mapping, you implement the ILobUri and INamingContainer interfaces. Compile the code into a DLL and add the DLL to the GAC, author a model file for the custom backend, register the connector using PowerShell, and you are done! The SharePoint Crawler invokes the Execute() method in the ISystemUtility class (as implemented by the custom shim), so you can put your special magic into this method.
A Few More Tips
The new connector framework takes care of a lot of things for you. There are a couple more new capabilities you might want to take advantage of:
- To create item-level security: Implement the GetSecurityDescriptor() method. For each entity, add a method instance property:
<Property Name = “WindowsSecurityDescriptorField” Type =“System.Byte[]”> Field name </Property>
- To crawl through entity associations: For association navigators (foreign key relationships), add the following property:
<Property Name=“DirectoryLink” Type=“System.String”> NotUsed </Property>
Deploying Connectors
Deploying connectors is quite straightforward for simple search systems. Out-of-the-box connectors are already installed with SharePoint and the configuration is easy. Some Microsoft-supplied connectors (notably the Documentum connector) are not provided with the SharePoint distribution, but are downloadable from TechNet. Third-party connectors have their own installation and configuration instructions. Custom connectors you write now have a straightforward packaging and deployment process as well.
Because SharePoint 2010 provides a highly scalable architecture, with the ability to provision multiple crawlers and multiple crawl databases, deployment of connectors for more complex search systems is possible. In these situations some planning and performance benchmarking is important. It is no longer unusual to crawl systems with 10 million items, which requires high throughput to keep full crawls to a reasonable timeframe. Deployments with 100 million items or more are now happening fairly regularly. At this scale, the throughput and reliability of connectors becomes the critical factor, especially in managing full crawls.
Packaging and Deploying Custom Connectors
Developers and administrators use the Windows SharePoint Services 3.0 solutions framework to deploy connectors. After authoring a solution, the developer creates a CAB (.cab) file that combines the application's definition file and the solution code. An administrator or a developer then creates a Windows SharePoint Services 3.0 solutions management consumable package — a manifest file that contains the CAB file, connection information, and other resources. When the CAB file is available, the administrator uses the Windows SharePoint Services Stsadm command-line tool to upload the file, placing the CAB file into the configuration database of the server farm. Then, the administrator deploys the solution in the Windows SharePoint Services solutions management interface. This step also registers the solution and puts its DLLs in the global assembly cache of all the index servers.
After the connector is installed, the associated repository can be managed and crawled via the Content Source type list in the administration UI.
Planning for Connector Development
Even though it is easier with SharePoint 2010, connector development is harder than it looks. If you are considering developing a connector, there are some factors worth your consideration:
- Size of content source: For small content sources, a straightforward implementation such as a custom BCS connector is fine. For large sources, optimizing the throughput makes a big difference in the time it takes to do a full crawl. The difference can be orders of magnitude for some systems.
- Impact on the source system: Some source systems are fragile, and a continual crawl may have an impact on production systems. You can mitigate this through crawl plans and exclude rules, but your connector may need to throttle its operations. You should also understand the maintenance windows for the source system in production, and schedule crawling around these windows.
- Security mapping: Each system may have its own security, and mapping that security can be challenging. SharePoint 2010 allows only for AD-format ACL information with content outside of SharePoint. For some systems (especially those with dynamic security groups and/ or claims-based security) this is not sufficient. Some security schemes may push you towards real-time security trimming, which requires more development, and has a significant performance impact on search performance.
- Data schema and APIs: Systems with a static schema and direct database access are generally straightforward to write connectors for; a BCS connector fits this model very well. Systems that have dynamically changing schemas, user-specific views, complex APIs, and so on become more challenging.
- Maintenance: If you are connecting to a commercial system (rather than one you have built), you may need to update your connector when there are updates to the system. Support and maintenance is ongoing and can be a significant effort.
The bottom line is that you shouldn't underestimate the effort involved in connector development and deployment. There are third-party connectors you can buy, and the advent of FAST Search for SharePoint has grown this market so there are options to buy or use third-party frameworks rather than build your own. Don't fear connector development, especially for moderate-scale systems with straightforward security and data schema. This development has become much easier with SharePoint 2010. But watch out for the classic quicksand trap — a development project that gets to basic connectivity quickly but struggles to achieve security and scale and is then dragged further down in troubleshooting and maintenance as the source system changes. Plan your development carefully to avoid this trap.
Summary — Customizing Connectivity
Search becomes more and more powerful as you add additional content sources. Getting a unified view across multiple silos of information is one of the most common motivations for building search-based applications. SharePoint 2010 provides several connectors out of the box. They offer considerable flexibility in configuration and enable you to scale out far more than was possible in previous versions. You can create your own connectors using BCS, using the new connector framework, with tooling built in to SharePoint Designer, and Visual Studio 2010. You can use third-party connectors and frameworks for more complex cases, or to minimize development and maintenance effort. As your search system becomes more sophisticated, you may find yourself combining connectivity from all of these approaches. However you do it, getting content rapidly and securely into search is the foundation for many interesting applications.
WORKING WITH FEDERATION
In addition to indexing information, search can present information to the user via federation. This is a “scatter-gather” approach: the same query is sent to a variety of different places, and the results are displayed together on the same page. Federation is not a replacement for indexing, but it is an essential tool for situations in which indexing is impossible (web search engines have the whole web covered; you don't have the storage or computer power to keep up with that) or impractical (you have an existing vertical search application that you don't want to touch). Federation can also be a great mechanism for migration.
The following list shows some of the situations where you might use indexing and federation. Microsoft has embraced federation wholeheartedly, in particular the OpenSearch standard.
When to Use Indexing
- If there is no search available with a repository.
- You want common relevance ranking.
- You want to extract full text and metadata.
- You want to be able to scope to an arbitrary subset of content.
- The source system's search performance/reliability is insufficient.
When to Use Federation
- You need a quick, powerful way to bring together results across multiple search systems.
- Data is distributed across multiple repositories.
- Search already exists in the repository.
- Crawling is not feasible:
- Cost or integration difficulty
- Geo-distribution of systems
- Proprietary/Legal restrictions on source content access
Microsoft began supporting OpenSearch in 2008 with the introduction of Search Server 2008. Now all of Microsoft's Enterprise Search products support OpenSearch, and all of them have implemented comprehensive support for federation with out-of-the-box federation connectors to a range of search interfaces. Federation is built to be extremely easy to set up. It takes less than five minutes for an administrator to add a federated connector and see federated results appear in search queries. Additional flexibility and control over the use of federated connectors come from triggering, presentation, and security features. Enterprise Search offerings can act as OpenSearch providers, OpenSearch clients, or both.
OpenSearch is a standard for search federation, originally developed by Amazon.com for syndicating and aggregating search queries and results. It is a standard used throughout the industry, and new OpenSearch providers are being created every day.
The operation of OpenSearch is shown in Figure 6-27. The basic operation involves a search client — which could be a desktop (Windows 7), a browser (Internet Explorer 8), or a server (SharePoint 2010). It also involves a search provider — which is any server with a searchable RSS feed, meaning that it accepts a query as a URL parameter and returns results in RSS/Atom.
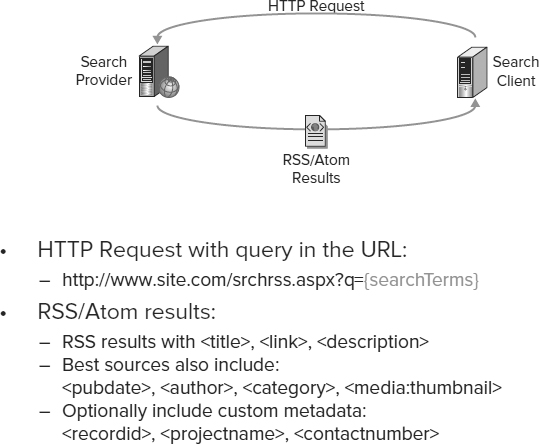
FIGURE 6-27
OpenSearch is now supported by a broad community (see Opensearch.org) and is in common use among online information service providers such as Bing, Yahoo!, Wikipedia, and Dow Jones-Factiva. It is becoming more and more common in business applications. Following Microsoft's introduction of OpenSearch into its Enterprise Search products, partners built OpenSearch connectors to applications such as EMC Documentum, IBM FileNet, and OpenText Hummingbird.
Microsoft Search Server 2008 supported OpenSearch and Local Index Federation. It included a federation administration UI and several Federation web parts, but federation was a bit of a side capability. The main Results web part, for example, couldn't be configured to work with federation.
With SharePoint Server 2010, all web parts are built on the federation OM. Connections to Windows 7, Bing, IE8, and third-party clients are built in. FAST Search for SharePoint supports federation in the same way, and the federation OM is now public — so you can create your own type of federated connector!
Customization Examples Using Federation
The following code example shows a custom OpenSearch provider (the full code is included with Code Project 6-P-3, which contains OpenSearchAdventureWorks./zip). This code creates a simple RSS feed from the result of a database query.
resultsXML.Append(“<rss version=“2.0”
xmlns:advworks=“http://schemas.adventureworks.com/Products/Search/RSS”
xmlns:media=“http://search.yahoo.com/mrss/“>”);
resultsXML.Append(“<channel>”);
resultsXML.AppendFormat(“<title>Adventure Works: {0}</title>”, queryTerm);
resultsXML.AppendFormat(“<link>{1}?q={0}</link>”, queryTerm, RSSPage);
resultsXML.Append(“<description>
Searches Products in the Adventure Works database.
</description>”);
while (sqlReader.Read())
{
…
resultsXML.Append(“<item>”);
resultsXML.AppendFormat(“<title>{0}</title>”, sqlReader[0]);
resultsXML.AppendFormat(“<link>{1}?v={0}&
q={2}</link>”, sqlReader[1], RSSPage, query);
resultsXML.AppendFormat(“<description>
{0} ({1}) has {2} units of inventory and
will need to order more at {3} units.</description>”, sqlReader[0],
sqlReader[1], sqlReader[2], sqlReader[4]);
…
resultsXML.Append(“</item>”);
}
resultsXML.Append(“</channel></rss>”);
![]()
The behavior of this is described in an OSDX file, which is shown next. An OSDX file is simple XML, and clients like Windows 7 can incorporate this with one click. Of course, SharePoint 2010 also acts as an OpenSearch client (as well as an OpenSearch provider).
<?xml version=“1.0” encoding=“UTF-8”?> <OpenSearchDescription xmlns:ms-ose=“http://schemas.microsoft.com/opensearchext/2009/” xmlns=“http://a9.com/-/spec/opensearch/1.1/”> <ShortName>ProductsSearch</ShortName> <Description> Searches the Adventure Works Products database. </Description> <Url> type=“text/html” template=“http://demo/sites/advsearchprod/Pages/productresults.aspx ?k={searchTerms} ” </Url> <Url> type=“application/rss+xml” template=“http://demo/_layouts/adventureworks/productsearch.aspx ?q={searchTerms}” </Url> </OpenSearchDescription>
![]()
Further Considerations in Federation
There are a number of additional points to remember when using federation. First, ranking is up to the provider, so mixing results is not as dependable as you might think. Simple mixers that use round-robin results presentation are okay for situations in which all the sources are of the same type and strong overall relevance ranking is not crucial. Second, OpenSearch does not support refinement OOB. Use custom runtime code and OpenSearch extensions to pass refiners if you need to. You may want to translate the query syntax to match a given source system. Use a custom web part or runtime code for that. Security also needs special handling with federation. There is nothing built into OpenSearch. Microsoft has provided extensions to OpenSearch and a framework that handles security on a wide range of authentication protocols. Implementing this, however, requires you to be aware of the security environments your application will run in.
When designing an application using federation, plan synchronous and asynchronous federation approaches. If the federation is synchronous, it is only as strong as its weakest link; results will be returned only when the slowest system comes back, and relevance ranking will be worse than the worst system involved. If federation is asynchronous, pay careful attention to the number of different result sets and how they are laid out on the UI. If you want to make your solution available via desktop search, this is easy with Windows 7 — and it works out of the box with standard SharePoint or FAST Search. You do this by creating an OpenSearch Description (.osdx) file, which can then be deployed to Windows 7 via Group Policy if you like.
We have noted a few common federation design patterns. The federation-based search vertical focuses on using federation with core results to provide a complete results experience. A lightweight preview of results, in contrast, would show a few (about three) results to preview a source. Instant answer across multiple sources is supported by the top Federated Results web part, which is useful for finding an exact match or quick factoid. Last, a custom application using the Federation OM might use query alteration, refinement, and query steering across multiple sources.
There are limits to OpenSearch, and situations where capabilities beyond custom OpenSearch providers are needed. For example, combining and creating refiners isn't supported with OpenSearch. Interleaving multiple search results into one result set is possible, but doing this well is a deceptively difficult task. There are now third-party components available that support these cases, and allow you to build extensions.
Federation is a powerful tool in your arsenal, and SharePoint 2010 has made it easy to use it. It is not a panacea — if you can pragmatically index content, doing so is nearly always better. However, using the Federation OM and building OpenSearch providers can help in many situations.
WORKING WITH THE QUERY OM
Query processing is an essential part of search. Because effective search depends on getting good queries from the user, query processing is often used to improve the queries, by adding context or doing pre-processing. An example is location-aware searches, where the user is looking for results within a preferred distance of a particular location, and the location might be taken from the user's context (such as the office location stored in the user profile, or a GPS coordinate provided by a mobile phone). Query-side processing can be used to examine search results as they return and trigger more searches based on their contents. There is a huge range of things you can do using the SharePoint Query OM, and some very exciting applications you can build with it.
Query-Side APIs and OMs
Figure 6-28 shows the “stack” with query-side APIs and OMs with SharePoint Server 2010 search.
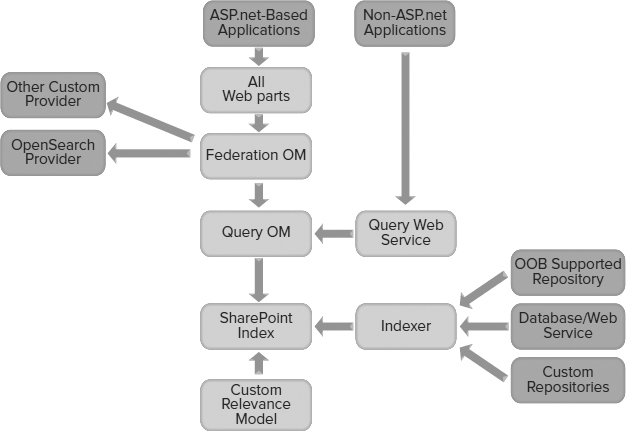
FIGURE 6-28
Figure 6-29 shows the same “stack” with FAST Search for SharePoint.
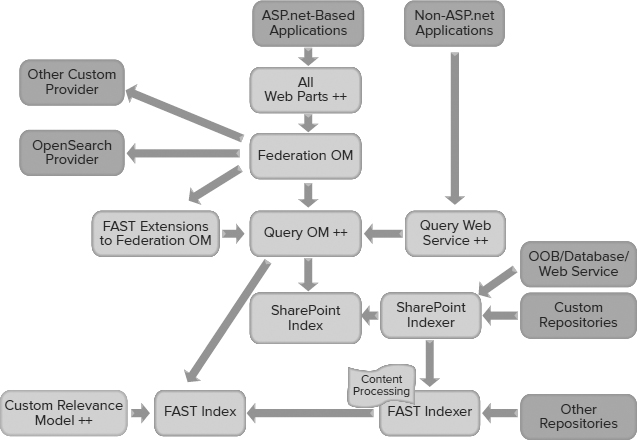
FIGURE 6-29
In these figures, light grey components are on SharePoint Server farms or FAST Search backend farms, and dark grey components are on other servers. Content flow is also shown in these figures, so that you can see how the whole system fits together.
It's important to understand the different ways you can access queries and results, so these next sections go through each of the query-side OMs.
The Federation Object Model
This is a new search object model in SharePoint 2010. It provides a unified interface for querying against different locations (search providers), giving developers of search-driven web parts a way to implement end-user experiences that are independent of the underlying search engine. The object model (OM) also allows for combining and merging results from different search providers. Out-of-box web parts in SharePoint 2010 are based on this OM, and SharePoint 2010 ships with three different types of locations: SharePoint Search, FAST Search, and OpenSearch. The Federation OM is also extensible, should you want or need to implement a custom search location outside of the supported types.
The Federated Search runtime object model is now public, enabling developers to build custom web parts that search any federated location. This change, combined with richer keyword query syntax, provides a common and flexible interface for querying internal and external locations. The Federated Search object model now provides a consistent way to perform all queries from custom code, making it easier to write clean, reusable code.
An important enhancement of the Federated Search OM is the public QueryManager class, which makes it possible to customize the query pipeline. For example, developers can build a web part that passes search results from a given location or repository to other web parts. A single query can, therefore, serve multiple web parts.
The Query Web Service
This is the integration point for applications outside your SharePoint environment, such as standalone, non-web-based applications or Silverlight applications running in a browser. The Query web service is a SOAP-based ASMX web service and supports a number of operations, including:
- Querying and getting search results
- Getting query suggestions
- Getting metadata, for example managed properties
The same schema is shared by SharePoint Search and FAST Search, and both products support the same operations. For querying, clients can easily switch the search provider by setting a ResultsProvider element in the request XML. A number of extensions are available for FAST Search, for example, refinement results, advanced sorting using a formula, and issuing queries using the FAST Query Language.
The Query RSS Feed
Certain scenarios, such as simple mash-ups, may need only a simple search result list. The RSS feed is an alternative, lightweight integration point for supplying applications outside of SharePoint with a simple RSS result list. The Search Center — the default search front end in SharePoint 2010 — includes a link to a query-based RSS feed. Switching the engine to the RSS format is done simply by setting a URL provider. Because it was designed to be simple, there are some limitations to what can be returned and customized in the Query RSS feed. The use object models or web service integration scenarios are recommended for more advanced applications.
The Query Object Model
This is the lowest-level object model, used by the Federation OM, the Query web service, and the Query RSS feed. Both SharePoint Search and FAST Search support the KeywordQuery object in this object model. Whereas the Federation OM returns XML (to web parts), the Query OM returns data types.
Figure 6-30 shows the newly customizable pipeline for queries that originate from SharePoint Server 2010. All objects in the figure can be customized with the exception of the cross-hatched one, Query Processing, which cannot be customized.
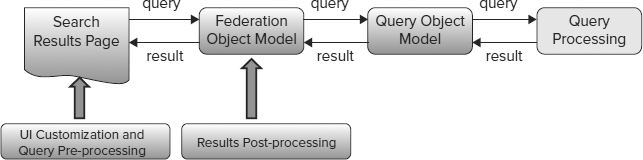
FIGURE 6-30
Query Syntax
The federation and query OM are the methods for submitting queries. The queries themselves are strings that you construct and pass to the Search Service. A query request from a query client normally contains the following main parts:
- The user query: This consists of the query terms that the user types into a query box found on the user interface. In most cases, the user simply types one or more words, but the user query may also include special characters like “+”and “-”. The user query will normally be treated as a string that is passed transparently by the query client on the interface.
- Property filters: These are additional constraints on the query that are added by the query client to limit the result set. These may include filters limiting the results by creation date, file type, written language, or any other metadata associated with the indexed items.
- Query features and options: These are additional query parameters that specify how a query is executed and how the query result is to be returned. This includes linguistic options, refinement options, and relevancy options.
Search in SharePoint supports four search syntax types for building search queries:
- KQL (Keyword Query Language) syntax: Search terms are passed directly to the Search Service
- SQL syntax: Extension of SQL syntax for querying databases, for SharePoint search only
- FQL (FAST Query Language): For FAST only
- URL syntax: Search parameters are encoded in URL and posted directly to the search page
KQL is the only syntax that end users would typically see. This syntax is simpler for developers to use than the SQL search syntax because it is not necessary to parse search terms to build a SQL statement; you pass the search terms directly to the Search Service. You also have the advantage that KQL works across both SharePoint and FAST, whereas SQL and FQL are codebase-specific. You can pass two types of terms in a Windows SharePoint Services Search keyword query: keywords (the actual query words for the search request) and property filters (the property constraints for the search request). KQL has been enhanced with SharePoint 2010 to include parametric search, so there should be very little need for SQL.
Keywords can be a word, a phrase, or a prefix. (With FAST you can also use full wildcards, so a keyword can be a partial word or phrase). These can be simple (contributes to the search as an OR), included (must be present — for example, AND, denoted by +), or excluded (must not be present — for example, AND NOT, denoted by -).
Property filters provide you with a way to narrow the focus of the keyword search based on managed properties. These are used for parametric searches, which allow users to formulate queries by specifying a set of constraints on the managed property values. For example, searching for a wine with parameters of {Varietal: Red, Region: France, Rating: ≥90, Price: ≤$10} is easy to achieve with property filters, and easy to explore using refiners.
KQL supports using multiple property filters within the same query. You can use multiple instances of the same property filter or different property filters. When you use multiple instances of the same filter, it means OR; for example, author:“Charles Dickens” author:“Emily Bronte” returns results with either author. When you use different property filters, it means AND; for example, author:“Isaac Asimov” title:“Foundation*” returns only results that match both. Property filters also enable you to collapse duplicates; for example, duplicate:http://<displayUrl> requests duplicate items for the specified URL (which would otherwise be collapsed).
With SharePoint Server 2010, enhancements to keyword query syntax enable more complex search queries that in the past were supported only by the SQL query syntax. These enhancements include support for wildcard suffix matching, grouping of query terms, parentheses, and logical operators, such as AND, OR, NOT, and NEAR. Improved operators now support regular expressions, case-sensitivity, and content source prioritization. KQL can express essentially anything you can say with SQL. The Advanced Search page, for example, now creates KQL rather than SQL.
FAST Query Language (FQL)
FAST Search has a number of extensions beyond the standard SharePoint search that are available on both the Federation and Query OMs, and also on the Query web service. Some examples are:
- The FAST Query Language, which supports advanced query operators, such as XRANK for dynamic (query-time) term weighting and ranking
- Deep refiners over the whole results set and the possibility of adding refiners over any managed property
- Advanced sorting using managed properties or a query-time sort formula
- Advanced duplicate trimming, also called result collapsing, with the ability to specify a custom property on which to base duplicate comparisons
- Similar documents matching using document vectors
- The FAST Search Admin OM for promoting documents or assigning visual Best Bets to query keywords/phrases
The FAST Query Language (FQL) is intended for programmatic creation of queries. It is a structured language and not intended to be exposed to the end users. FQL can be used only with FAST Search for SharePoint. Certain FAST Search for SharePoint features may be accessed only using this query language, such as:
- Detailed control of ranking at query time, using RANK/XRANK operators, query term weighting, and switching on/off ranking for parts of a query
- Advanced proximity operators (ordered/unordered NEAR operators)
- Advanced sorting, using SORT/SORTFORMULA operators
- Complex combinations of query operators, such as nesting of Boolean operators
FQL opens a whole world of search operations to the developer. The full set of capabilities is too long to cover in this book, but the reference documentation is available on MSDN.
Examples Using Query Customization
This section shows how to apply query customization through a few examples with simple applications.
Picture Search example: Imagine you wanted to implement an image search where pictures are displayed if they match a query, but only if they are in a picture library. This can be done simply by using a KQL query with property filters.
{query-string},
isDocument:1, ContentClass:STS_ListItem_PictureLibrary
In this case, the properties are built-in managed properties. isDocument indicates whether this item is a container (such as a folder in a document library) or not, so isDocument:1 tells search not to return folders. ContentClass describes what kind of content this is, and in this case we are asking only for members of picture libraries.
One of the great things about learning and using query customization is that it can be applied very easily. In this example, the property filters could be specified as a fixed part of the query simply by configuring the Search Results web part. A final touch for this application would be to create XSLT that formats the search result to display pictures and their metadata in an appealing UI.
Topic page example: A similar approach can be used to create topic pages, where content around a particular topic is gathered even if the content is in different site collections or even different farms. The following KQL query handles items from any discussion board:
{topic-query-string},
isDocument:1, ContentClass:STS_ListItem_DiscussionBoard
For a topic page, a useful technique is to have the whole query be a fixed query, and let the page-load event which loads the web part fire the initial query. It is straightforward to modify the Content Query web part to use Enterprise Search queries and format and display Enterprise Search results. There are several blog postings on this subject as well as commercial web parts available which do this.
Company research example: Imagine that you are building an application for research about companies, from a financial trading perspective. Perhaps you want to bring back additional information about a company whenever it is mentioned. This might include rules like these:
- If a query uses a company name of a publicly listed company, bring back stock information.
- If a query uses a ticker symbol, put that information on top.
- If a query brings back information about a public company (has a public_company managed property populated), show the current stock price as metadata in the main Results web part.
- If there are more than 10 results around a company (where the refiner on the public_company managed property has a value less than 10), add in a link to the URL of that company at the top of the page.
To do this kind of processing, you need to intercept the query, the result, and the refiners, and add your own processing. You can do this by accessing the query manager. The following code shows how simple it is to do this:
protected override System.Xml.XPath.XPathNavigator
GetXPathNavigator(string viewPath)
{
QueryManager queryManager =
SharedQueryManager.GetInstance(this.Page).QueryManager;
//Get in pipeline before query is run
string taskQueryLanguage =
queryManager.UserQuery;
//Get in pipeline after query is run
XmlDocument resultsDoc =
queryManager.GetResults(queryManager[0]);
//Return Refiner
return resultsDoc.CreateNavigator();
}
For this example, you would likely use a call to a public web service to recognize company names and sticker symbols in the user query. You might get back synonyms and parameters from this (such as alternate forms of the company name) to use in the search. Determining the value of a specific managed property or refiner is straightforward once you have the results. After you have a ticker symbol, another public web service can be used to return current stock value, URL, and other information.
Localized Results example: Imagine that you want to display results that are personalized to each user's department and office location. For example, the finance department may want to see results that have “finance” in them ahead of others. Someone searching for “cafeteria menu” most likely wants to see what's for lunch in the office where they work.
This is much simpler to do with FAST. First of all, FAST has user context awareness for queries built-in. The FAST user context administration provides the ability to trigger keyword actions (best bets, visual best bets, and synonyms) OOB. These are populated based on fields in the user's profile (from the SharePoint profile store), and will be available in the <UserContext> element of the query string. If you have configured the user context feature to use office location (this is configured OOB) then you can determine myOfficeLocation from the <UserContextData> tag within the <ContextGroupID> that matches OfficeLocation.
Although user context does not change the search results or ranking OOB, this can be adjusted by modifying the query string in your code. For a straight filter, you can use properties just like the earlier examples:
{query-string},
OfficeLocation:myOfficeLocation
However, you wouldn't want to simply add the term finance into the query in this case. Adding it via AND finance removes many desired results; adding it via OR finance brings back many things that only matched the term “finance” and weren't what the user was looking for in her query.
This is where the FQL constructs for RANK and XRANK apply. They change the relevance ranking of the results. This query will have the desired effect:
RANK(query-string,“finance”)
Only results that match query-string will be returned, but those that contain the word “finance” will show up higher on the list. XRANK takes this further and can apply to properties, as well as allowing an explicit boost parameter. This query ranks items explicitly tagged with the user's office location ahead of those that aren't:
XRANK(query-string, OfficeLocation:myOfficeLocation)
This query boosts items tagged with the user's office location by 200 ranking points and those with the word “finance” by 100 points:
XRANK(XRANK(query-string, OfficeLocation:myOfficeLocation,boost=200), “finance”,boost=100)
The ranking flexibility with XRANK is incredible; some trial-and-error may be needed to get the appropriate boost parameters for the desired behavior.
Location Aware Search example: imagine that you want to have search results that are based on location. Location aware search, sometimes called geosearch, arises in many situations; finding the hotels nearest the user would be an example. To do this, you must use a FAST-specific operator, SORTFORMULA, to sort results in order of distance. Figure 6-31 shows how this works.

FIGURE 6-31
First, the content needs to be tagged with geo-coordinates (latitude and longitude). A lot of content is already tagged; for example, cameras with GPS automatically add geo-coordinates to pictures, so many pictures are already geo-tagged. There are also many geo-tagging packages available commercially and via open source, so content can be geo-tagged during indexing by applying one of these packages via the FAST content pipeline extensibility API.
Second, you need to determine the user's current location. A default location could be kept in the user profile, so that user context would apply. In addition, most mobile devices now provide their current location, which the application can pick up and add to the query. For illustration purposes, let's say that you have found the user's location to be (50,100).
Finally, you use SORTFORMULA, to sort results in order of distance. If desired, you can cut out results beyond a threshold, but often displaying the whole result set is fine. This query sorts results matching the user's query in order of distance from the user's location, using 2-dimensional Euclidian distance:
{query-string}, sortby(formula:
sqrt(pow(50-latitude,2)+pow(100-longitude,2)))
There are many operators supported for formula, so this distance metric could be 3-dimensional or even more complex.
SOCIAL SEARCH
A significant aspect to an individual's work in an organization is interacting with other people and finding the right people to connect — those who have specific skills and talents. This can be a daunting challenge in a large organization. SharePoint Server 2010 addresses this challenge through search and connects this search to the social capabilities in SharePoint Server 2010. A People Search Center provides specific capabilities for connecting with people.
End-User-Visible Functionality
We touched on the people search function at the beginning of this chapter (see Figure 6-10). Now let's run through a few other aspects of social search that are visible to the end user, so that you can see how to use this in your application.
Mining and Discovering Expertise
Users can manually submit or automatically generate a list of colleagues mined from Outlook. Using automatically generated lists of colleagues is a way of rapidly inferring social relationships throughout the organization, which speeds the adoption and usefulness of people search results. SharePoint Server 2010 also infers expertise by automatically suggesting topics mined from the user's Outlook inbox and suggesting additions to her expertise profile in her My Site. This makes it easy to populate My Site profiles and means that more people have well-populated profiles and get the benefits of this in searches and within communities.
Improving Search Results Based on Social Behavior
For many organizations, SharePoint sites have become gathering places where people create, share, and interact with information. Social behavior is taken into account to provide high-quality search results in several ways. First, the relevance ranking for people search takes social distance into account: a direct colleague appears before someone three degrees removed (for example a friend-of-a-friend-of-a-friend). Second, SharePoint Server 2010 supports the social tagging of content, and this feedback can influence the relevance of content in search results. People's day-to-day usage of information in SharePoint Server 2010 and Microsoft Office can have a measurable effect on search relevance, thereby helping the organization harness the collective wisdom of its people.
Social Search Architecture
Social search capabilities work directly out of the box. In most cases, you won't need to change them; you can just use them as part of your application. However, understanding the architecture and good practices for operations is useful, regardless of whether you plan to extend social search capabilities.
Architecture and Key SSAs
Three shared service applications are critical to the SharePoint 2010 farm tuned for social search. The user profile SSA is the datasource, which can draw from AD, LDAP, or other repositories storing data about employees. The Managed Metadata SSA provides a way of storing relationships between metadata values and allowing admins some control over the health of the data in the profile store. The Search SSA features tune results, refinement, and ranking to take advantage of the data coming from the user profile application and the managed metadata application.
Figure 6-32 shows these components and how they relate to SharePoint 2010.
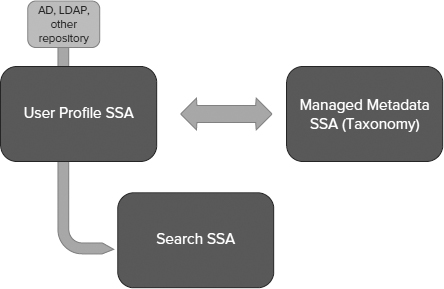
FIGURE 6-32
Managing User Profiles
Because social search is based in large part on user profiles, there are some basic techniques organizations should use to help keep these profiles lively and high quality. These include encouraging users to use photos and update profile information. Turning on “knowledge mining” and encouraging users to publish suggested keywords are also possible techniques. All of these use out-of-the-box features, without any extensions.
SharePoint 2010 provides out-of-the-box taxonomy properties such as Responsibilities, Interest, Skills, and Schools, but as a developer, you may want to add new taxonomy properties. This involves setting up a connection to the Managed Metadata SSA, adding custom profile properties, and then adding the new taxonomy property to the profile store.
You may also want to extend user profiles and social search in other ways — for example, by bringing in external profile information, generating and normalizing profile information, and so forth. You can also to extend the colleague and expertise suggestion capabilities.
Social Tags
Social tags are indexed as part of the people content source. The tag is stored with the person not the item, until it gets to the search system. This is important because it means that end users can tag external content (meaning anything with a URL).
Social tags affect the ranking of search results for SharePoint Server 2010 Search but not for FAST Search for SharePoint. To provide this for FAST, you would extend the standard crawl and/or provide application logic to collect and pre-process social tags.
EXTENDING SOCIAL SEARCH
People search can be extended in the same ways that we described for content search: customized web parts, federation, and query processing. It can also be extended via people profiles as described earlier.
CONTENT ENHANCEMENT
The old adage “garbage in, garbage out” springs to mind when considering content quality. Content preparation means selecting the right content, appropriately transforming and tagging it, cleansing or normalizing the content (making content regular and consistent, using appropriate spelling or style), and reducing the complexity of disparate data types. Information sources may include everything under the sun: web/intranet (HTML, XML, multimedia), file and content management systems (DOC, XLS, PDF, text, XML, CAD, etc.), email (email text, attachments), and databases (structured records). Findability is enhanced significantly by content enhancements and linguistic techniques.
Metadata, Linguistics, and Search
Metadata and linguistics are essential to search. Understanding how they work and how you can extend them enables you to build great search-driven applications.
Crawled Properties, Managed Properties, and Schemas
Search is performed on managed properties. Managed properties contain the content that will be indexed, including metadata associated with the items. Mapping from crawled properties to managed properties is controlled as part of the search configuration. A typical approach is to first perform a crawled property discovery based on an initial set of crawled items. Based on the results, you can change the mapping to managed properties.
Managed properties can be used for ranking, sorting, and navigation (refiners). Assessing which managed properties to use as metadata in your application is one of the most important aspects of creating great findability — search finds information anywhere via a full-text search on the body of documents, but using metadata makes the search quality better and enables sorting and navigation. You can add more managed properties at any point in the development and deployment process, but having a good core set to start makes development and testing much easier.
Multilingual Search
In the search world, linguistics is defined as the use of information about the structure and variation of languages so that users can more easily find relevant information. This is important for properly using search tools in various natural languages; think of the structural differences between English and Chinese. It is also important to industry-specific language usage — for instance, the English used in an American pharmaceutical company versus that used in a Hong Kong-based investment bank.
As you plan your application, get a sense of the number of languages involved — both in the content and among the user population. Find out what vocabularies exist in the organization — these may be formal taxonomies, dictionaries purchased from specialist firms, or informal lists harvested from glossaries and team sites.
The Problem of Missing Metadata
Missing or incorrect metadata is a significant problem. An anecdotal example illustrates this point: a census performed on our company's PowerPoint presentations a year ago showed that nearly a quarter were authored by the CEO himself. This result was, doubtless, because, as the founder, he created early presentations that have since been edited, copied, and modified many times over.
Metadata is essential for many aspects of content programs, including search. Good metadata means more findable content; metadata drives the search refiners, so good metadata is crucial for a good search exploration experience. Unfortunately, most metadata today is of poor quality or even missing entirely. Of the five OOB refiners, only document size and file type are reliable:
- Author is often incorrect (as illustrated previously)
- Site is often useless, because documents may be placed in arbitrary places. (Good practices in site- or filesystem structure and contents go a long way to help this, but it's rare to find this in operation.)
- Modify date can be incorrect, because many processes that move content update the modify date.
Without good metadata, search returns less relevant results (because managed properties normally carry higher weight than the body of the text). Without good metadata, search refiners aren't useful. Without good metadata, many other capabilities of SharePoint (workflows, content routing, and so on) can't be enjoyed to their full extent.
Quality metadata can be generated in different ways:
- By hand, which is a laborious process, and often practically impossible to do
- As a side effect of a structured workflow, form, or business process, for example via forms, workflows, or content organizer rules
- By machine, using techniques like entity extraction, auto-tagging, categorization, and clustering. Most of these are the realm of third-party software (some of which is built for integration with SharePoint 2010). Some automated metadata generation is available with FAST — most notably entity extraction.
Advanced Content Processing with FAST
FAST Search for SharePoint includes a scalable, fault-tolerant, and extensible content-processing pipeline, based on technology from FAST. Figure 6-33 shows the high-level structure of the content-processing pipeline.
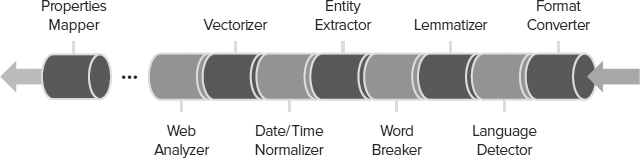
FIGURE 6-33
The content-processing pipeline is a framework for refining content and preparing it for indexing, with the following characteristics:
- A content-processing pipeline is composed of small simple stages, each of which does one thing. Stages identify attributes such as language, parse the structure of the document encodings (document format, language morphology, and syntax), extract metadata, manipulate properties and attributes, and so forth.
- A wide range of file formats (over 400) are understood and made available for indexing by the pipeline.
- A wide range of human languages are detected and supported by the pipeline (82 languages detected, 45 languages with advanced linguistics features). This includes spell-checking and synonyms (which improves the search experience) and lemmatization (which provides higher precision and recall than standard techniques like stemming.)
- Property extraction creates and improves metadata by identifying words and phrases of particular types. Pre-built extractors include Person, Location, Company, E-mail, Date, and Time. A unique offensive-content-filtering capability is also included.
Detecting and parsing file formats is a fundamental step in search indexing. For SharePoint search, iFilters are used to detect file formats and parse them. The Microsoft Filter Pack 2.0 (which is included with SharePoint 2010) includes iFilters for the following formats: .docx, .docm, .pptx, .pptm, .xlsx, .xlsm, .xlsb, -zip, .one, .vdx, .vsd, .vss, .vst, .vdx, .vsx, and .vtx — essentially the Office file formats and .zip files. Third-party iFilters are required for other file formats (the most popular is for .pdf files), and there is a range of quality and performance found in these iFilters. FAST Search for SharePoint includes an Advanced Filter Pack that covers over 400 file formats — essentially everything you are going to run into.
Property extraction is one of the most powerful capabilities in the content pipeline. The person, location, and company extractors are the basic workhorses; they use the shape of language as well as some dictionaries to do their magic, so “Acme Inc” would be recognized as a company. When you think about the fact that “Bob Jones” is a person, “Dow Jones” is a company, and “Albert Hall” is a location, it underscores how interesting this technology is.
Custom property extractors are supported in the pipeline (up to 5). These are verbatim extractors; they work off of a list of terms to be recognized and do high-performance text processing to identify these terms within documents. Creating a property extractor is very simple: You take a list of terms, run a powershell command to compile an extractor, and configure the pipeline to include it. A common use of these extractors is to recognize all of a company's products by name, thus tagging documents automatically with the products mentioned. Similarly, property extractors for customer names, project names, and industry names provide simple ways to create very useful metadata.
Note that property extractors can reduce the throughput of a pipeline considerably. They are so useful that they are worth it in most cases, but don't be caught by surprise by this slowdown.
Content Pipeline Configuration
The content-processing pipeline in FAST Search for SharePoint can be configured and extended. This is made available in a structured fashion — simpler, more robust, and less error prone than with FAST ESP. Each stage is configures via GUI or XML and is available via PowerShell. In the pipeline, content is mapped into “crawled properties” (whatever is found in the content) and then into “managed properties” (mapped into a schema and made available for searching, sorting, and navigation). This schema is accessible via GUI or PowerShell.
Content Pipeline Extensibility
There are several ways for developers and partners to add value in content processing:
- Configure connectors, pipeline configurations, and the index schema to support specific search applications.
- Apply optional pipeline stages, such as using the XML properties mapper, the Offensive Content Filter, and field collapsing (which allows grouping or folding results together).
- Create custom verbatim extractors. These are dictionary-driven identification terms and phrases and are used, for example, to ID all product names or project names and extract these as managed properties for each document.
- Create custom connectors, using BCS (or other APIs) to bring in and index data from specific systems and applications.
- Process content prior to crawling — for some applications pre-processing content prior to crawling is useful (such as separating large reports into separate documents). This can be done externally to search or within a connector shim.
- Extend the pipeline by creating code that is called right before the PropertiesMapper stage, specialized classifiers, entity extractors, or other processing elements can be used to support specialized scenarios.
Multilingual Search
If your organization is truly global, the need for multilingual search is clear. But even if you initially think that all of your organization's search needs are English only, it is fairly common to discover that some percentage of users and content are non-English.
You should think carefully about the language-specific features of your search function. If people search only for content in their own language, or if there is wide variation in the language types used (English, Polish, and Chinese, for example), then it helps to have users specify their language in the query interface. Where there are common linguistic roots — on an e-commerce site featuring English and Dutch content, say — it may be easier to handle everything in the most common language, in this case, English.
A full description of linguistics and how you can use it to improve search is beyond the scope of this book. But there are a few things you should know about linguistics:
- Better use of linguistics will improve precision and recall.
- Industry and user knowledge are needed to optimize search systems.
- Linguistic choices can affect hardware and performance.
- Some sites should favor language independence.
- Bad queries can be turned into good queries with the proper linguistic tools.
For many search applications, the out-of-the-box search configuration is all you need. User language choices are set in the Preferences panel of the Search Center and, by default, are determined from the browser. But be aware that linguistic processing can provide a lot of power in multilingual situations or in situations that demand particularly tuned recall and precision.
EXTENDING SEARCH USING THE ADMINISTRATIVE OM
SharePoint Server 2010 provides an extensible Search Health Monitoring OM. This object model enables administrators and developers to customize the administrative dashboards and pages that provide snapshots of the overall health of the search system, and to provide ways to troubleshoot and identify the underlying causes of any problems. The Search Health Monitoring user interface provides tools for monitoring the health of functional search subsystems (for example, crawling and indexing), search content sources, and key components (for example, databases) of the search system's topology.
Authentication and Security
Security in search is both a simple and a deep subject. Simply put, search uses the user's credentials and the entitlements on any content that has been indexed to ensure that users can see only content they are authorized to read. For OOB connectors and straightforward security environments, this just works. As you build custom connectors and work in heterogeneous and complex security environments, you also have the responsibility to extend security for search.
There are two major new security capabilities with SharePoint 2010. First, item-level security descriptors can now be retrieved for external data exposed by Business Connectivity Services. This means that search security is straightforward when building new connectors with BCS. Second, claims authentication (see Chapter 11) provides a wide range of security options for heterogeneous environments. Search benefits from these significantly, because search is often used as a bridge to discover information from many different systems.
Search Reports
The object model supports a reporting system that you can easily customize and extend. You can modify default alert rules and thresholds, for example, by changing the alert rules XML file. You can also upload new reporting applications developed by third parties to a standard search administration document library. The reports generated by these reporting applications are XML files in the standard Report Definition Language Client-Side (RDLC) format. For more information, see the Report Definition Language Specification, which is available on Microsoft TechNet.
COMBINING SEARCH WITH OTHER WORKLOADS
The search capabilities in SharePoint 2010 and FAST Search for SharePoint are very powerful. Through configuration and custom development, you can do amazing things with search. Once you become familiar with how to use Enterprise Search, you can also combine search with other parts of SharePoint (Insights, Social, Composites, Sites, and Content) to create compelling solutions.
Search and Content
Search and content management are close cousins. Where good content management prevents information overload, relevant search results improve the value of search to the enterprise. Applications that provide value include archiving, discovery, and content analysis.
Although search and taxonomy management are complementary, they are loosely coupled rather than tightly coupled in SharePoint 2010. For example, search refiners OOB are not hierarchical (with the exception of sites), so metadata that comes from a multilevel Managed Term Set is flattened out for search. The paradigms used for searching and browsing are different. To unify these requires additional code, or the use of third-party components.
Structure is the heart of successful content management, and metadata is the heart of content structure. However, most metadata sucks! It is typical to have poor metadata (or no metadata) on a vast amount of content, and the most common metadata (like author or modify date) is rarely useful. To address this, metadata can be generated by hand — by content editors, for example. Metadata can be generated as a side effect of a structured workflow, form, or business process. Metadata can also be generated by machine, using search technology. The two most common techniques for generating metadata by machine are entity extraction and auto-classification. Though neither of these is built in to SharePoint 2010, both are available and can be integrated.
Entity extraction is available with FAST Search for SharePoint, as described earlier in this chapter. By using OOB entity extractors (such as people names, place names, and organizational names), content can be enriched during the indexing process to address missing or poor quality metadata. You can also create your own extractors. As described earlier, it is straightforward to make a verbatim entity extractor that rapidly matches a set of names or terms you provide. Specialized entity extractors are also available from third parties for complex or domain-specific cases (such as chemicals, proteins, and genomics).
Auto classification also generates metadata by machine, but differently from entity extraction. Rather than marking up text wherever terms or phrases are found, auto-classifiers determine a set of tags to apply to a document as a whole. Auto classification works on hierarchies, for example to identify:
- Europe->France->Paris vs.
- North_America->USA->Maine->Paris
where these strings would never be found explicitly in the text.
Auto categorizers are available for SharePoint 2010 as third-party components. This allows you to integrate them into applications that use the SharePoint term store as well as enterprise search.
Examples of combining search and content management include the following:
- Extending the search refiners to handle taxonomies
- Enhancing records management using entity extraction and auto classification
- Using search to support e-Discovery programs
- Informing archiving and migration strategies using the search reports (for example, to migrate only the content people have been looking for)
- Improving taxonomies and ontologies by analyzing the terms that people use to search and their success at locating relevant content.
You can combine search with all flavors of content management, including Enterprise Content Management (ECM), Records Management (RM), and Web Content Management (WCM). Some of these combinations are already built-in to SharePoint 2010, like e-discovery search. Some are combinations that require custom development.
Search and Insights
SharePoint has search and business intelligence (BI) features. Before we talk about how to use them together, it will help you to understand the difference between BI and enterprise search. Both are technologies dedicated to the discovery and analysis of data. However, each is suited to different types of information, and they have radically different approaches to finding that information.
Business intelligence and data warehousing were designed to process, manage, and explore structured data, often line-of-business data from production systems. Search tools are, for the most part, designed to index and query unstructured data, such as websites and document repositories.
Anyone can use a typical search engine to find information quickly. BI tools, on the other hand, are based on complex and refined queries that return precise results and reports. BI applications, thus, tend to have a high level of complexity, which means that only business analysts or those specifically trained on BI systems can effectively use them.
Despite their differences, BI and search are ultimately in the business of discovering information, and when effectively combined, they can provide a broad and insightful information discovery system. For example, a search system can lower the usage barrier for BI, providing access to business intelligence data from a search interface that anyone can use. A BI tool can also make it possible for search results to include structured strategic data, such as sales information. The combination of the two has the potential to help users find answers to vital business questions.
The overall convergence of Search and BI has been on the radar of analysts for five or six years now. For example, Forrester Research publishes pieces on the convergence of search and BI regularly; Figure 6-34 shows an overview of how search and BI are learning from each other (courtesy of Forrester).

FIGURE 6-34
There are many ways to use Enterprise Search and BI together, and quite a few inventive approaches to building systems that combine aspects of both. These fall into three main patterns:
- Text analytics: Where search technology serves as a content preprocessor for BI technology. This includes text mining, semantic analysis, sentiment detection, and much more.
- Search analytics: This involves applying BI to outputs of search. This includes analysis of search behavior and performance, search results visualization, and search engine optimization.
- Unified information access: This means combining search and BI elements into one system, including report finders, query preprocessors, unified view systems, hybrid databases, and search-based datamarts.
All of these are possible with the search and BI workloads in SharePoint 2010, if you put enough effort and development into it. Covering these in detail is beyond the scope of this book; each of these topics could be a book in itself.
There are some very simple things you can do to make search and BI work together in SharePoint 2010. One of them is to create information centers that combine BI dashboards and search-driven content discovery. These are useful for many applications, including voice-of-the-customer scenarios and similar cases that organize both structured and unstructured information around a specific entity. For example, to create a voice-of-the-customer dashboard driven by search and BI you would do the following:
- Index all information relevant to customer interaction. This might include CRM systems, customer invoices, call center case records, customer surveys, social media such as Facebook or LinkedIn groups, and so on. Capturing this information would typically involve several connectors, both OOB connectors, simple custom connectors (for example, for a database of customer survey results), and third-party connectors (for example for invoices in SAP).
- Add machine-generated metadata. This includes entity extraction to identify which customers were mentioned, the topics and products they were talking about, and the projects or companies they were associated with — doable with OOB extractors and custom verbatim extractors in FAST. It would also include sentiment detection, either custom-built or added as a third-party component.
- Surface search-generated topic pages using query-customization techniques. Use techniques like those described earlier and grouping or rollup using result collapsing (a FAST-specific feature).
- Surface search refiners in charts and graphs, using custom code or third-party components.
- Add traditional BI dashboard elements for the data that is already in reporting format (for example sales, product return rates, etc.).
A second scenario is to use search for discovery and dissemination of BI artifacts, in a report finder application. By crawling the various places BI reports are archived, you can create a report center, perhaps as simply as adding a tab to your existing search center. A third scenario is to apply search to a structured data repository. By indexing content, such as a product catalog or claims database, you can add structure to the text blobs within it and make the content much more findable.
Whether you work with these relatively simple scenarios or delve into the complexity of advanced integration, it's useful to know that these features can work together.
Search and Composites
Another workload in SharePoint 2010 is composites, including workflow (see Chapter 12) and Infopath forms (see Chapter 9). Although combining search and composites is not that common today, some strong architectural patterns arise that combine search and SharePoint workflows, or search and InfoPath forms.
The main combinations of search and workflow arise with less structured workflows, such as case management. A search may trigger a workflow — for example in research investigations where a set of search results is sent downstream for archiving, further research, report review, and so on. Or a workflow may trigger a search. A case that involves background checking, for example, may need to do one or more searches in the context of a workflow — looking for any relevant information in different repositories, based on the parameters set in ‘upstream’ activity. A search can also be a step within a workflow — perhaps conducting more searches based on the results of earlier ones.
With SharePoint 2010, workflows can't trigger searches out of the box, nor can searches trigger workflows. But with additional development these scenarios can be built. There are already commercial components that can add on to SharePoint 2010 to fulfill some of these needs, or you can build the integration to fit your situation.
InfoPath forms provide a convenient way to capture and display information. When there are large numbers of these forms, people get lost in the sea of information and Enterprise Search can help. Search can be applied either to the forms themselves (find me the form for purchasing bulk supplies in Canada) or to their content (show me the people who have entered a desire to attend development training).
In general terms, the way that most search applications are put together is a composite — a solution that doesn't require deep coding but does require business awareness. Search is flexible to changes in schema, content sources, and scale. Patterns that combine search and composites in SharePoint 2010, whether using workflows, forms, or lightweight application development, are useful in many search-based applications.
Search and Communities
There are many ways in which SharePoint's Search and social features work together. The out-of-the-box people search, for example, makes social interactions better by making it easy to find people and expertise. The colleague and expertise suggestions offered on your My Site are powered by search technology. And social behavior (tagging, social distance, and so on) is considered in search relevance to provide better results.
There are many scenarios in which you, as a developer, can combine search and communities. For example, My Sites and Team Sites can benefit from better navigation of content and the ability to post searches to the site to help guide other people to relevant content. Search can foster knowledge sharing. For example, by indexing the email sent to distribution lists and revealing it in a search-driven content web part, a distribution list can be turned into a knowledge base.
An increasingly common pattern is the use of search to create a virtual social directory of everything related to a given concept, whether a person, subject, event, project, customer, and so on. The simplest version of this can be built without code by configuring the static query term in the Search Results web part. Simply by federating with external sources such as Facebook and Wikipedia, you build a page surfacing both internal and external information about a given term. The search refiners provide a way to show and explore connections between dimensions, for example, people that tweet the most about a particular topic, or sites that hosts the most content about a particular project/product/client, or DLs that contains the most people interested in a topic (based on what they have authored or touched).
Combining Search with Other Features
Search can be combined with all the other parts of SharePoint (called content, sites, BI, composites, and communities) to build powerful capabilities and applications.
- Search combines with all the forms of content management: ECM, RM, and WCM. By extending SharePoint you can use search technology to add machine-generated metadata to content, which makes amazing applications possible.
- Search combines nicely with sites; in fact search is nearly always used along with sites in SharePoint 2010. The Search Center is a site, for example, and there is a small Search box on the majority of sites. Adding capabilities like search-driven topic pages to sites is straightforward once you know how.
- Search combines with insights (BI) in several ways, from simple co-existence in information centers, to complex text analytics, search analytics, and unified information access.
- Search can combine with composites — with workflows, forms and codeless application development.
- Search also combines very frequently with communities.
Some of these combinations are available out of the box, but many of them require you to extend SharePoint and do innovative development work. As you become fluent in developing applications with search and SharePoint 2010, keep these patterns and combinations in mind. You will discover many ways to apply them.
SEARCH AND THE CLOUD
Cloud-based software is becoming pervasive, and search is no exception. SharePoint 2010 is now available in the cloud as Office 365 (see Chapter 15), which includes Enterprise search capabilities. In addition, the advent of cloud-based software has created content silos. Search federation can bridge the silos and create a unified view across content stored both on-premises and in the cloud.
Search Capabilities in Office 365
Office365 has strong search capabilities — much stronger than its predecessor, BPOS. Search has refiners, social capabilities, and strong scale in Office365. Search online has gotten broader and includes the capability to search across site collections. People search is a huge difference for O365; you can find someone much more easily with the new capabilities. Phonetic search and built-in nicknames means you don't have spell name correctly, and you can review recent content or browse in an organizational chart right from the search results page, which saves a lot of time.
However there are some limitations with search in Office365. For example, as of this book's publication FAST is not available in Office365. Any capabilities that do not support the multi-tenant topology (predominantly those that involve mining the query logs, such as query suggestions) are not available. Table 6-1 shows an overview of the search capabilities across different editions of search, including Office 365.
TABLE 6-1: Office 365 Search Capabilities


Combining On-premises and In-cloud Content with Search
As more and more applications and content is moving to the cloud, a problem arises. The cloud actually creates data silos for many organizations. Consider a hybrid implementation of SharePoint with some content stored on-premises (on prem) and some in the cloud (online). In this case it becomes harder to find and explore all this content. Search can solve this problem.
Figure 6-35 shows the scenarios involved in searching across on-prem and in-cloud content. Content can be in either location, as can the search index.
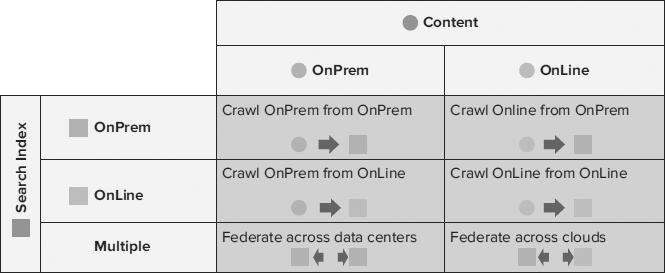
FIGURE 6-35
Four scenarios are used in crawling content into a single search index. Each scenario has unique security, bandwidth, and operational challenges:
- Crawling on-prem from on-prem: This is the traditional indexing scenario, and most indexing connectors are designed for this. Even with the prevalence of this model, practices are still maturing as content volumes explode, more and more systems are crawled into the index, and the variety of content types increases. Although bandwidth within the data center is not a problem, distributed crawling across regional centers is a common issue and working with failover/backup sites can be challenging. Security is usually not homogenous in this scenario; there are models for different systems, so these need to be integrated into a single sign-on or another security mapping approach.
- Crawling on-line from on-prem: This is the predominant hybrid scenario. Usually there is a single search index on-prem, anchored by on-prem LoB systems. There is usually a single tenant, fully owned search system (including FAST), with one or more online systems such as Salesforce, MS-CRM online, Office 365, and so on. The bandwidth requirements are usually manageable (although building a simple bandwidth model and doing an audit is recommended). The SLA from the on-line provider(s) is very important, and working with the providers on crawl scheduling and crawl performance should be part of the arrangement. Security with each of these providers usually has a standard model, often federated with Active Directory Federation Services (ADFS) and/or claims. When there are multiple online systems from different providers, this can get tricky.
- Crawling on-prem from online: This is a hosted search scenario, with a single search index online, either single- or multi-tenant. This involves crawling on-prem systems (e.g.: a corporate website) from the hosting provider. This model is being used more frequently as it removes the headache of search management. The SLA with the search hosting provider should account for the security and bandwidth required. Bandwidth should be reviewed with hosting provider, and a bandwidth limiter is usually important, as is the negotiation of crawl scheduling and crawl times. A maintenance window for an on-prem system can look like a service problem from the hosting provider. Security can be difficult in this scenario, especially for multi-tenant arrangements, but there are models that work for this. In fact, hosters are often more secure than their clients! Office365 does not yet offer this model, though it will be possible in the future.
- Crawling online from online: This is an unusual scenario today; the most common application is for searching email in Exchange Online from a hosted search provider. Bandwidth is rarely an issue, as there is backbone traffic capacity between major data centers. Security issues can be very tricky in this scenario, and it requires a common SSO approach across multiple providers with coordination across multiple SLAs.
Content is nearly always hybrid (some on-prem, some on-line), so in the real world a unified view arrangement is a combination of these four scenarios.
In addition to crawling, federation can be applied to bridge data silos. Federation has challenges as well. It is only as good as the weakest link, and poses a higher and less predictable load on source systems. Each data source may communicate via a unique protocol, although OpenSearch is a common denominator that you can use for this, as described earlier in this chapter. This is easiest when it doesn't require tight security or interleaved results, but you can use third-party components or build more sophisticated software yourself to handle most scenarios. It is important to have the ability to assess source performance (such as availability and latency) and take corrective actions if necessary (for example take sources offline).
SUMMARY
Building powerful search applications is easier than ever in SharePoint 2010. You can create a wide range of applications based on search, with various levels of customization. You can also combine search with other parts of SharePoint (Insights, Social, Composites, Sites, and Content) to create compelling solutions.
FAST Search is now integrated into the SharePoint platform and provides advantages for scalability in addition to powerful features like dynamic ranking, flexible sort formulae, and deep refiners for insight into the full result set. Developers of search-driven solutions can leverage a common platform and common APIs for both SharePoint Search and FAST Search. This means you can build applications to support both search engines and then extend them if and when desired to take advantage of the more advanced features available with FAST Search. FAST Search Server 2010 for SharePoint web parts use the same unified object model as SharePoint Server 2010 and the other search platforms from Microsoft. When you develop a custom solution that uses the Query Object Model for SharePoint Server 2010, it will continue to work if you migrate your code to FAST Search Server 2010 for SharePoint.