
15. Data Structures, Algorithms, and Code Simplification
The modules in this chapter are used to address common programming problems related to data structures; algorithms; and the simplification of code involving iteration, function programming, context managers, and classes. These modules should be viewed as a extension of Python’s built-in types and functions. In many cases, the underlying implementation is highly efficient and may be better suited to certain kinds of problems than what is available with the built-ins.
abc
The abc module defines a metaclass and a pair of decorators for defining new abstract base classes.
ABCMeta
A metaclass that represents an abstract base class. To define an abstract class, you define a class that uses ABCMeta as a metaclass. For example:

A class created in this manner differs from an ordinary class in a few critical ways:
• First, if the abstract class defines methods or properties that are decorated with the abstractmethod and abstractproperty decorators described later, then instances of derived classes can’t be created unless those classes provide a non-abstract implementation of those methods and properties.
• Second, an abstract class has a class method register(subclass) that can be used to register additional types as a logical subclass. For any type subclass registered with this function, the operation isinstance(x, AbstractClass) will return True if x is an instance of subclass.
• A final feature of abstract classes is that they can optionally define a special class method _ _subclasshook_ _(cls, subclass). This method should return True if the type subclass is considered to be a subclass, return False if subclass is not a subclass, or raise a NotImplemented exception if nothing is known.
A decorator that declares method to be abstract. When used in an abstract base class, derived classes defined directly via inheritance can only be instantiated if they define a nonabstract implementation of the method. This decorator has no effect on subclasses registered using the register() method of an abstract base.
abstractproperty(fget [, fset [, fdel [, doc]]])
Creates an abstract property. The parameters are the same as the normal property() function. When used in an abstract base, derived classes defined directly via inheritance can only be instantiated if they define a nonabstract implementation of the property.
The following code provides an example of defining a simple abstract class:

Here is an example of a class that derives from Stackable:

Here is the error message that you get if you try to create a Stack:

This error can be fixed by adding a size() property to Stack. You can either do this by modifying the definition of Stack itself or inheriting from it and adding the required method or property:

Here is an example of using the complete stack object:

See Also:
Chapter 7, “Classes and Object-Oriented Programming,” numbers (p. 252), collections (p. 262).
array
The array module defines a new object type, array, that works almost exactly like a list, except that its contents are constrained to a single type. The type of an array is determined at the time of creation, using one of the type codes shown in Table 15.1.
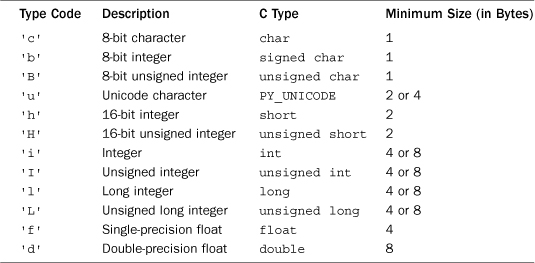
The representation of integers and long integers is determined by the machine architecture (they may be 32 or 64 bits). When values stored as 'L' or 'I' are returned, they’re returned as long integers in Python 2.
The module defines the following type:
array(typecode [, initializer])
Creates an array of type typecode. initializer is a string or list of values used to initialize values in the array. The following attributes and methods apply to an array object, a:

When items are inserted into an array, a TypeError exception is generated if the type of the item doesn’t match the type used to create the array.
The array module is useful if you need to have space-efficient storage for lists of data and you know that all items in the list are going to be the same type. For example, storing 10 million integers in a list requires about 160MB of memory whereas an array of 10 million integers requires only 40MB. Despite this space savings, none of the basic operations on an array tend to be faster than their list counterparts—in fact, they may be slower.
In performing calculations with arrays, you will want to be careful with operations that create lists. For example, using a list comprehension on an array will convert the entire array into a list, defeating any space-saving benefit. A better way to handle this is to create new arrays using generator expressions. For example:
![]()
Because the point of using an array is to save space, it may be more desirable to perform “in-place” operations. An efficient way to do this is with code that uses enumerate(), like this:
![]()
For large arrays, this in-place modification runs about 15 percent faster than the code that creates a new array with a generator expression.
Notes
• The arrays created by this module are not suitable for numeric work such as matrix or vector math. For example, the addition operator doesn’t add the corresponding elements of the arrays; instead, it appends one array to the other. To create storage and calculation efficient arrays, use the numpy extension available at http://numpy.sourceforge.net/. Note that the numpy API is completely different.
• The += operator can be used to append the contents of another array. The *= operator can be used to repeat an array.
See Also:
struct (p. 290)
bisect
The bisect module provides support for keeping lists in sorted order. It uses a bisection algorithm to do most of its work.
bisect(list, item [, low [, high]])
Returns the index of the insertion point for item to be placed in list in order to maintain list in sorted order. low and high are indices specifying a subset of the list to examine. If items is already in the list, the insertion point will always be to the right of existing entries in the list.
bisect_left(list, item [, low [, high]])
Returns the index of the insertion point for item to be placed in list in order to maintain list in sorted order. low and high are indices specifying a subset of the list to examine. If items is already in the list, the insertion point will always be to the left of existing entries in the list.
bisect_right(list, item [, low [, high]])
The same as bisect().
insort(list, item [, low [, high]])
Inserts item into list in sorted order. If item is already in the list, the new entry is inserted to the right of any existing entries.
insort_left(list, item [, low [, high]])
Inserts item into list in sorted order. If item is already in the list, the new entry is inserted to the left of any existing entries.
insort_right(list, item [, low [, high]])
The same as insort().
collections
The collections module contains high-performance implementations of a few useful container types, abstract base classes for various kinds of containers, and a utility function for creating name-tuple objects. Each is described in the sections that follow.
deque and defaultdict
Two new containers are defined in the collections module: deque and defaultdict.
deque([iterable [, maxlen]])
Type representing a double-ended queue (deque, pronounced “deck”) object. iterable is an iterable object used to populate the deque. A deque allows items to be inserted or removed from either end of the queue. The implementation has been optimized so that the performance of these operations is approximately the same as (O(1)). This is slightly different from a list where operations at the front of the list may require shifting of all the elements that follow. If the optional maxlen argument is supplied, the resulting deque object becomes a circular buffer of that size. That is, if new items are added, but there is no more space, items are deleted from the opposite end to make room.
An instance, d, of deque has the following methods:
d.append(x)
Adds x to the right side of d.
d.appendleft(x)
Adds x to the left side of d.
d.clear()
Removes all items from d.
d.extend(iterable)
Extends d by adding all the items in iterable on the right.
d.extendleft(iterable)
Extends d by adding all the items in iterable on the left. Due to the sequence of left appends that occur, items in iterable will appear in reverse order in d.
d.pop()
Returns and removes an item from the right side of d. Raises IndexError if d is empty.
d.popleft()
Returns and removes an item from the left side of d. Raises IndexError if d is empty.
d.remove(item)
Removes the first occurrence of item. Raises ValueError if no match is found.
Rotates all the items n steps to the right. If n is negative, items are rotated to the left.
Deques are often overlooked by many Python programmers. However, this type offers many advantages. First, the implementation is highly efficient—even to a level of using internal data structures that provide good processor cache behavior. Appending items at the end is only slightly slower than the built-in list type, whereas inserting items at the front is significantly faster. Operations that add new items to a deque are also thread-safe, making this type appropriate for implementing queues. deques can also be serialized using the pickle module.
defaultdict([default_factory], ...)
A type that is exactly the same as a dictionary except for the handling of missing keys. When a lookup occurs on a key that does not yet exist, the function supplied as default_factory is called to provide a default value which is then saved as the value of the associated key. The remaining arguments to defaultdict are exactly the same as the built-in dict() function. An instance d of defaultdictionary has the same operations as a built-in dictionary. The attribute d.default_factory contains the function passed as the first argument and can be modified as necessary.
A defaultdict object is useful if you are trying to use a dictionary as a container for tracking data. For example, suppose you wanted to keep track of the position of each word in a string s. Here is how you could use a defaultdict to do this easily:

In this example, the lookup wordlocations[w] will “fail” the first time a word is encountered. However, instead of raising a KeyError, the function list supplied as default_factory is called to create a new value. Built-in dictionaries have a method setdefault() that can be used to achieve a similar result, but it often makes code confusing to read and run slower. For example, the statement that appends a new item shown previously could be replaced by wordlocations.setdefault(w,[]).append(n). This is not nearly as clear and in a simple timing test, it runs nearly twice as slow as using a defaultdict object.
Named Tuples
Tuples are frequently used to represent simple data structures. For example, a network address might be represented as a tuple addr = (hostname, port). A common complaint with tuples is that the individual items have to be accessed by numerical index—for example, addr[0] or addr[1]. This leads to code that is confusing to read and hard to maintain unless you can remember what all of the index values mean (and the problem gets worse the larger the tuple gets).
The collections module contains a function namedtuple() that is used to create subclasses of tuple in which attribute names can be used to access tuple elements.
namedtuple(typename, fieldnames [, verbose])
Creates a subclass of tuple with name typename. fieldnames is a list of attribute names specified as strings. The names in this list must be valid Python identifiers, must not start with an underscore, and are specified in the same order as the items appearing in the tuple—for example, ['hostname','port']. Alternatively, fieldnames can be specified as a string such as 'hostname port' or 'hostname, port'. The value returned by this function is a class whose name has been set to the value supplied in typename. You use this class to create instances of named tuples. The verbose flag, if set to True, prints the resulting class definition to standard output.
Here is an example of using this function:
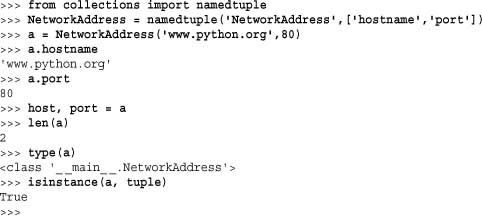
In this example, the named tuple NetworkAddress is, in every way, indistinguished from a normal tuple except for the added support of being able to use attribute lookup such as a.hostname or a.port to access tuple components. The underlying implementation is efficient—the class that is created does not use an instance dictionary or add any additional memory overhead in a built-in tuple. All of the normal tuple operations still work.
A named tuple can be useful if defining objects that really only serve as a data structures. For example, instead of a defining a class, like this:

you could define a named tuple instead:
![]()
Both versions are going to work in a nearly identical manner. For example, in either case, you would access fields by writing s.name, s.shares, and so on. However, the benefit of the named tuple is that it is more memory-efficient and supports various tuple operations such as unpacking (for example, if you had a list of named tuples, you could unpack values in a for-loop with a statement such as for name, shares, price in stockList). The downside to a named tuple is that attribute access is not as efficient as with a class. For example, accessing s.shares is more than twice as slow if s is an instance of a named tuple instead of an ordinary class.
Named tuples are frequently used in other parts of the Python standard library. Here, their use is partly historical—in many library modules, tuples were originally used as the return value of various functions that would return information about files, stack frames, or other low-level details. Code that used these tuples wasn’t always so elegant. Thus, the switch to a named tuple was made to clean up their usage without breaking backwards compatibility. Another subtle problem with tuples is that once you start using a tuple, the expected number of fields is locked forever (e.g., if you suddenly add a new field, old code will break). Variants of named tuples have been used in the library to add new fields to the data returned by certain functions. For example, an object might support a legacy tuple interface, but then provide additional values that are only available as named attributes.
Abstract Base Classes
The collections module defines a series of abstract base classes. The purpose of these classes is to describe programming interfaces on various kinds of containers such as lists, sets, and dictionaries. There are two primary uses of these classes. First, they can be used as a base class for user-defined objects that want to emulate the functionality of built-in container types. Second, they can be used for type checking. For example, if you wanted to check that s worked like a sequence, you could use isinstance(s, collections.Sequence).
Container
Base class for all containers. Defines a single abstract method _ _contains_ _(), which implements the in operator.
Hashable
Base class for objects that can be used as a hash table key. Defines a single abstract method _ _hash_ _().
Iterable
Base class for objects that support the iteration protocol. Defines a single abstract method _ _iter_ _().
Iterator
Base class for iterator objects. Defines the abstract method next() but also inherits from Iterable and provides a default implementation of _ _iter_ _() that simply does nothing.
Sized
Base class for containers whose size can be determined. Defines the abstract method _ _len_ _().
Callable
Base class for objects that support function call. Defines the abstract method _ _call_ _().
Base class for objects that look like sequences. Inherits from Container, Iterable, and Sized and defines the abstract methods _ _getitem_ _() and _ _len_ _(). Also provides a default implementation of _ _contains_ _(), _ _iter_ _(), _ _reversed_ _(), index(), and count() that are implemented using nothing but the _ _getitem_ _() and _ _len_ _() methods.
MutableSequence
Base class for mutable sequences. Inherits from Sequence and adds the abstract methods _ _setitem_ _() and _ _delitem_ _(). Also provides a default implementation of append(), reverse(), extend(), pop(), remove(), and _ _iadd_ _().
Set
Base class for objects that work like sets. Inherits from Container, Iterable, and Sized and defines the abstract methods _ _len_ _(), _ _iter_ _(), and _ _contains_ _(). Also provides a default implementation of the set operators _ _le_ _(), _ _lt_ _(), _ _eq_ _(), _ _ne_ _(), _ _gt_ _(), _ _ge_ _(), _ _and_ _(), _ _or_ _(), _ _xor_ _(), _ _sub_ _(), and isdisjoint().
MutableSet
Base class for mutable sets. Inherits from Set and adds the abstract methods add() and discard(). Also provides a default implementation of clear(), pop(), remove(), _ _ior_ _(), _ _iand_ _(), _ _ixor_ _(), and _ _isub_ _().
Mapping
Base class for objects that support mapping (dictionary) lookup. Inherits from Sized, Iterable, and Container and defines the abstract methods _ _getitem_ _(), _ _len_ _(), and _ _iter_ _(). A default implementation of _ _contains_ _(), keys(), items(), values(), get(), _ _eq_ _(), and _ _ne_ _() is also provided.
MutableMapping
Base class for mutable mapping objects. Inherits from Mapping and adds the abstract methods _ _setitem_ _() and _ _delitem_ _(). An implementation of pop(), popitem(), clear(), update(), and setdefault() is also added.
MappingView
Base class for mapping views. A mapping view is an object that is used for accessing the internals of a mapping object as a set. For example, a key view is a set-like object that shows the keys in a mapping. See Appendix A, “Python 3” for more details.
KeysView
Base class for a key view of a mapping. Inherits from MappingView and Set.
ItemsView
Base class for item view of a mapping. Inherits from MappingView and Set.
ValuesView
Base class for a (key, item) view of a mapping. Inherits from MappingView and Set.
Python’s built-in types are already registered with all of these base classes as appropriate. Also, by using these base classes, it is possible to write programs that are more precise in their type checking. Here are some examples:

See Also:
contextlib
The contextlib module provides a decorator and utility functions for creating context managers used in conjunction with the with statement.
contextmanager(func)
A decorator that creates a context manager from a generator function func. The way in which you use this decorator is as follows:

When the statement with foo(args) as value appears, the generator function is executed with the supplied arguments until the first yield statement is reached. The value returned by yield is placed into the variable value. At this point, the body of the with statement executes. Upon completion, the generator function resumes. If any kind of exception is raised inside the with-body, that exception is raised inside the generator function where it can be handled as appropriate. If the error is to be propagated, the generator should use raise to re-raise the exception. An example of using this decorator can be found in the “Context Managers” section of Chapter 5.
nested(mgr1, mgr2, ..., mgrN)
A function that invokes more than one context manager mgr1, mgr2, and so on as a single operation. Returns a tuple containing the different return values of the with statements. The statement with nested(m1,m2) as (x,y): statements is the same as saying with m1 as x: with m2 as y: statements. Be aware that if an inner context manager traps and suppresses an exception, no exception information is passed along to the outer managers.
closing(object)
Creates a context manager that automatically executes object.close() when execution leaves the body of the with statement. The value returned by the with statement is the same as object.
functools
The functools module contains functions and decorators that are useful for creating higher-order functions, functional programming, and decorators.
partial(function [, *args [, **kwargs]])
Creates a function-like object, partial, that when called, calls function with positional arguments args, keyword arguments kwargs, and any additional positional or keyword arguments that are supplied. Additional positional arguments are added to the end of args, and additional keyword arguments are merged into kwargs, overwriting any previously defined values (if any). A typical use of partial() is when making a large number of function calls where many of the arguments are held fixed. For example:

An instance p of the object created by partial has the following attributes:

Use caution when using a partial object as a stand-in for a regular function. The result is not exactly the same as a normal function. For instance, if you use partial() inside a class definition, it behaves like a static method, not an instance method.
reduce(function, items [, initial])
Applies a function, function, cumulatively to the items in the iterable items and returns a single value. function must take two arguments and is first applied to the first two items of items. This result and subsequent elements of items are then combined one at a time in a similar manner, until all elements of items have been consumed. initial is an optional starting value used in the first computation and when items is empty. This function is the same as the reduce() function that was a built-in in Python 2. For future compatibility, use this version instead.
update_wrapper(wrapper, wrapped [, assigned [, updated]])
This is a utility function that is useful when writing decorators. Copies attributes from a function wrapped to a wrapper function wrapper in order to make the wrapped function look like the original function. assigned is a tuple of attribute names to copy and is set to ('_ _name_ _','_ _module_ _','_ _doc_ _') by default. updated is a tuple containing the names of function attributes that are dictionaries and which you want values merged in the wrapper. By default, it is a tuple ('_ _dict_ _',).
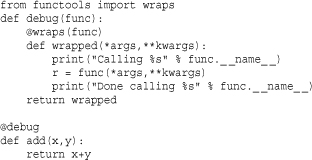
wraps(function [, assigned [, updated ]])
A decorator carries out the same task as update_wrapper() on the function to which it is applied. assigned and updated have the same meaning. A typical use of this decorator is when writing other decorators. For example:
See Also:
heapq
The heapq module implements a priority queue using a heap. Heaps are simply lists of ordered items in which the heap condition has been imposed. Specifically, heap[n] <= heap[2*n+1] and heap[n] <= heap[2*n+2] for all n, starting with n = 0. heap[0] always contains the smallest item.
heapify(x)
Converts a list, x, into a heap, in place.
heappop(heap)
Returns and removes the smallest item from heap, preserving the heap condition. Raises IndexError if heap is empty.
heappush(heap, item)
Adds item to the heap, preserving the heap condition.
Adds item to the heap and removes the smallest item from heap in a single operation. This is more efficient than calling heappush() and heappop() separately.
heapreplace(heap, item)
Returns and removes the smallest item from the heap. At the same time, a new item is added. The heap condition is preserved in the process. This function is more efficient than calling heappop() and heappush() in sequence. In addition, the returned value is obtained prior to adding the new item. Therefore, the return value could be larger than item. Raises IndexError if heap is empty.
merge(s1, s2, ...)
Creates an iterator that merges the sorted iterables s1, s2, and so on into a single sorted sequence. This function does not consume the inputs but returns an iterator that incrementally processes the data.
nlargest(n, iterable [, key])
Creates a list consisting of the n largest items in iterable. The largest item appears first in the returned list. key is an optional function that takes a single input parameter and computes the comparison key for each item in iterable.
nsmallest(n, iterable [, key])
Creates a list consisting of the n smallest items in iterable. The smallest item appears first in the returned list. key is an optional key function.
Note
The theory and implementation of heap queues can be found in most books on algorithms.
itertools
The itertools module contains functions for creating efficient iterators, useful for looping over data in various ways. All the functions in this module return iterators that can be used with the for statement and other functions involving iterators such as generators and generator expressions.
chain(iter1, iter2, ..., iterN)
Given a group of iterators (iter1, ... , iterN), this function creates a new iterator that chains all the iterators together. The returned iterator produces items from iter1 until it is exhausted. Then items from iter2 are produced. This continues until all the items in iterN are exhausted.
chain.from_iterable(iterables)
An alternative constructor for a chain where the iterables is an iterable that produces a sequence of iterable objects. The result of this operation is the same as what would be produced by the following fragment of generator code:
combinations(iterable, r)
Creates an iterator that returns all r-length subsequences of items taken from iterable. The items in the returned subsequences are ordered in the same way in which they were ordered in the input iterable. For example, if iterable is the list [1,2,3,4], the sequence produced by combinations([1,2,3,4], 2) is [1,2], [1,3], [1,4], [2,3], [3,4].
count([n])
Creates an iterator that produces consecutive integers starting with n. If n is omitted, counting starts at 0. (Note that this iterator does not support long integers. If sys.maxint is exceeded, the counter overflows and continues to count starting with -sys.maxint - 1.)
cycle(iterable)
Creates an iterator that cycles over the elements in iterable over and over again. Internally, a copy of the elements in iterable is made. This copy is used to return the repeated items in the cycle.
dropwhile(predicate, iterable)
Creates an iterator that discards items from iterable as long as the function predicate(item) is True. Once predicate returns False, that item and all subsequent items in iterable are produced.
groupby(iterable [, key])
Creates an iterator that groups consecutive items produced by iterable. The grouping process works by looking for duplicate items. For instance, if iterable produces the same item on several consecutive iterations, that defines a group. If this is applied to a sorted list, the groups would define all the unique items in the list. key, if supplied, is a function that is applied to each item. If present, the return value of this function is used to compare successive items instead of the items themselves. The iterator returned by this function produces tuples (key, group), where key is the key value for the group and group is an iterator that yields all the items that made up the group.
ifilter(predicate, iterable)
Creates an iterator that only produces items from iterable for which predicate(item) is True. If predicate is None, all the items in iterable that evaluate as True are returned.
ifilterfalse(predicate, iterable)
Creates an iterator that only produces items from iterable for which predicate(item) is False. If predicate is None, all the items in iterable that evaluate as False are returned.
imap(function, iter1, iter2, ..., iterN)
Creates an iterator that produces items function(i1,i2, .. iN), where i1, i2, ..., iN are items taken from the iterators iter1, iter2, ..., iterN, respectively. If function is None, the tuples of the form (i1, i2, ..., iN) are returned. Iteration stops whenever one of the supplied iterators no longer produces any values.
islice(iterable, [start,] stop [, step])
Creates an iterator that produces items in a manner similar to what would be returned by a slice, iterable[start:stop:step]. The first start items are skipped and iteration stops at the position specified in stop. step specifies a stride that’s used to skip items. Unlike slices, negative values may not be used for any of start, stop, or step. If start is omitted, iteration starts at 0. If step is omitted, a step of 1 is used.
izip(iter1, iter2, ... iterN)
Creates an iterator that produces tuples (i1, i2, ..., iN), where i1, i2, ..., iN are taken from the iterators iter1, iter2, ..., iterN, respectively. Iteration stops whenever one of the supplied iterators no longer produces any values. This function produces the same values as the built-in zip() function.
izip_longest(iter1, iter2, ..., iterN [,fillvalue=None])
The same as izip() except that iteration continues until all of the input iterables iter1, iter2, and so on are exhausted. None is used to fill in values for the iterables that are already consumed unless a different value is specified with the fillvalue keyword argument.
permutations(iterable [, r])
Creates an iterator that returns all r-length permutations of items from iterable. If r is omitted, then permutations have the same length as the number of items in iterable.
product(iter1, iter2, ... iterN, [repeat=1])
Creates an iterator that produces tuples representing the Cartesian product of items in item1, item2, and so on. repeat is a keyword argument that specifies the number of times to repeat the produced sequence.
repeat(object [, times])
Creates an iterator that repeatedly produces object. times, if supplied, specifies a repeat count. Otherwise, the object is returned indefinitely.
starmap(func [, iterable])
Creates an iterator that produces the values func(*item), where item is taken from iterable. This only works if iterable produces items suitable for calling a function in this manner.
takewhile(predicate [, iterable])
Creates an iterator that produces items from iterable as long as predicate(item) is True. Iteration stops immediately once predicate evaluates as False.
Creates n independent iterators from iterable. The created iterators are returned as an n-tuple. The default value of n is 2. This function works with any iterable object. However, in order to clone the original iterator, the items produced are cached and used in all the newly created iterators. Great care should be taken not to use the original iterator iterable after tee() has been called. Otherwise, the caching mechanism may not work correctly.
Examples
The following examples illustrate how some of the functions in the itertools module operate:

operator
The operator module provides functions that access the built-in operators and special methods of the interpreter described in Chapter 3, “Types and Objects.” For example, add(3, 4) is the same as 3 + 4. For operations that also have an in-place version, you can use a function such as iadd(x,y) which is the same as x += y. The following list shows functions defined in the operator module and how they are mapped onto various operators:

At first glance, it might not be obvious why anyone would want to use these functions because the operations they perform can easily be accomplished by simply typing the normal syntax. Where these functions are useful is when working with code uses callback functions and where you might otherwise be defining an anonymous function with lambda. For example, consider the following timing benchmark that uses the functools.reduce() function:

In the example, notice how using operator.add as the callback runs more than twice as fast as the version that uses lambda x,y: x+y.
The operator module also defines the following functions that create wrappers around attribute access, item lookup, and method calls.
attrgetter(name [, name2 [, ... [, nameN]]])
Creates a callable object, f, where a call to f(obj) returns obj.name. If more than one argument is given, a tuple of results is returned. For example, attrgetter('name','shares') returns (obj.name, obj.shares) when called. name can also include additional dot lookups. For example, if name is "address.hostname", then f(obj) returns obj.address.hostname.
itemgetter(item [, item2 [, ... [, itemN]]])
Creates a callable object, f, where a call to f(obj) returns obj[item]. If more than one item is given as arguments, a call to f(obj) returns a tuple containing (obj[item], obj[item2], ..., obj[itemN]).
methodcaller(name [, *args [, **kwargs]])
Creates a callable object, f, where a call to f(obj) returns obj.name(*args, **kwargs).
These functions are also useful for optimizing the performance of operations involving callback function, especially those involving common data processing operations such as sorting. For example, if you wanted to sort a list of tuples rows on column 2, you could either use sorted(rows, key=lambda r: r[2]) or use sorted(rows, key=itemgetter(2)). The second version runs much faster because it avoids the overhead associated with lambda.