
20. Threads and Concurrency
This chapter describes library modules and programming strategies for writing concurrent programs in Python. Topics include threads, message passing, multiprocessing, and coroutines. Before covering specific library modules, some basic concepts are first described.
Basic Concepts
A running program is called a process. Each process has its own system state, which includes memory, lists of open files, a program counter that keeps track of the instruction being executed, and a call stack used to hold the local variables of functions. Normally, a process executes statements one after the other in a single sequence of control flow, which is sometimes called the main thread of the process. At any given time, the program is only doing one thing.
A program can create new processes using library functions such as those found in the os or subprocess modules (e.g., os.fork(), subprocess.Popen(), etc.). However, these processes, known as subprocesses, run as completely independent entities—each with their own private system state and main thread of execution. Because a subprocess is independent, it executes concurrently with the original process. That is, the process that created the subprocess can go on to work on other things while the subprocess carries out its own work behind the scenes.
Although processes are isolated, they can communicate with each other—something known as interprocess communication (IPC). One of the most common forms of IPC is based on message passing. A message is simply a buffer of raw bytes. Primitive operations such as send() and recv() are then used to transmit or receive messages through an I/O channel such as a pipe or network socket. Another somewhat less common IPC mechanism relies upon memory-mapped regions (see the mmap module). With memory mapping, processes can create shared regions of memory. Modifications to these regions are then visible in all processes that happen to be viewing them.
Multiple processes can be used by an application if it wants to work on multiple tasks at the same time—with each process responsible for part of the processing. However, another approach for subdividing work into tasks is to use threads. A thread is similar to a process in that it has its own control flow and execution stack. However, a thread runs inside the process that created it, sharing all of the data and system resources. Threads are useful when an application wants to perform tasks concurrently, but there is a potentially large amount of system state that needs to be shared by the tasks.
When multiple processes or threads are used, the host operating system is responsible for scheduling their work. This is done by giving each process (or thread) a small time slice and rapidly cycling between all of the active tasks—giving each a portion of the available CPU cycles. For example, if your system had 10 active processes running, the operating system would allocate approximately 1/10th of its CPU time to each process and cycle between processes in rapid succession. On systems with more than one CPU core, the operating system can schedule processes so that each CPU is kept busy, executing processes in parallel.
Writing programs that take advantage of concurrent execution is something that is intrinsically complicated. A major source of complexity concerns synchronization and access to shared data. In particular, attempts to update a data structure by multiple tasks at approximately the same time can lead to a corrupted and inconsistent program state (a problem formally known as a race condition). To fix these problems, concurrent programs must identify critical sections of code and protect them using mutual-exclusion locks and other similar synchronization primitives. For example, if different threads were trying to write data to the same file at the same time, you might use a mutual exclusion lock to synchronize their operation so that once one of the threads starts writing, the other threads have to wait until it has finished before they are allowed to start writing. The code for this scenario typically looks like this:

There’s a joke attributed to Jason Whittington that goes as like this: “Why did the multithreaded chicken cross the road? to To other side. get the”. This joke typifies the kinds of problems that arise with task synchronization and concurrent programming. If you’re scratching your head saying, “I don’t get it,” then it might be wise to do a bit more reading before diving into the rest of this chapter.
Concurrent Programming and Python
Python supports both message passing and thread-based concurrent programming on most systems. Although most programmers tend to be familiar with the thread interface, Python threads are actually rather restricted. Although minimally thread-safe, the Python interpreter uses an internal global interpreter lock (the GIL) that only allows a single Python thread to execute at any given moment. This restricts Python programs to run on a single processor regardless of how many CPU cores might be available on the system. Although the GIL is often a heated source of debate in the Python community, it is unlikely to be removed at any time in the foreseeable future.
The presence of the GIL has a direct impact on how many Python programmers address concurrent programming problems. If an application is mostly I/O bound, it is generally fine to use threads because extra processors aren’t going to do much to help a program that spends most of its time waiting for events. For applications that involve heavy amounts of CPU processing, using threads to subdivide work doesn’t provide any benefit and will make the program run slower (often much slower than you would guess). For this, you’ll want to rely on subprocesses and message passing.
Even when threads are used, many programmers find their scaling properties to be rather mysterious. For example, a threaded network server that works fine with 100 threads may have horrible performance if it’s scaled up to 10,000 threads. As a general rule, you really don’t want to be writing programs with 10,000 threads because each thread requires its own system resources and the overhead associated with thread context switching, locking, and other matters starts to become significant (not to mention the fact that all threads are constrained to run on a single CPU). To deal with this, it is somewhat common to see such applications restructured as asynchronous event-handling systems. For example, a central event loop might monitor all of the I/O sources using the select module and dispatch asynchronous events to a large collection of I/O handlers. This is the basis for library modules such as asyncore as well as popular third-party modules such as Twisted (http://twistedmatrix/com).
Looking forward, message passing is a concept that you should probably embrace for any kind of concurrent programming in Python. Even when working with threads, an often-recommended approach is to structure your application as a collection of independent threads that exchange data through message queues. This particular approach tends to be less error-prone because it greatly reduces the need to use locks and other synchronization primitives. Message passing also naturally extends into networking and distributed systems. For example, if part of a program starts out as a thread to which you send messages, that component can later be migrated to a separate process or onto a different machine by sending the messages over a network connection. The message passing abstraction is also tied to advanced Python features such as coroutines. For example, a coroutine is a function that can receive and processe messages that are sent to it. So, by embracing message passing, you will find that you can write programs that have a great deal of flexibility.
The remainder of this chapter looks at different library modules for supporting concurrent programming. At the end, more detailed information on common programming idioms is provided.
multiprocessing
The multiprocessing module provides support for launching tasks in a subprocess, communicating and sharing data, and performing various forms of synchronization. The programming interface is meant to mimic the programming interface for threads in the threading module. However, unlike threads, it is important to emphasize that processes do not have any shared state. Thus, if a process modifies data, that change is local only to that process.
The features of the multiprocessing module are vast, making it one of the larger and most advanced built-in libraries. Covering every detail of the module is impossible here, but the essential parts of it along with examples will be given. Experienced programmers should be able to take the examples and expand them to larger problems.
Processes
All of the features of the multiprocessing module are focused on processes. They are described by the following class.
Process([group [, target [, name [, args [, kwargs]]]]])
A class that represents a task running in a subprocess. The arguments in the constructor should always been specified using keyword arguments. target is a callable object that will execute when the process starts, args is a tuple of positional arguments passed to target, and kwargs is a dictionary of keyword arguments passed to target. If args and kwargs are omitted, target is called with no arguments. name is a string that gives a descriptive name to the process. group is unused and is always set to None. Its presence here is simply to make the construction of a Process mimic the creation of a thread in the threading module.
An instance p of Process has the following methods:
p.is_alive()
Returns True if p is still running.
p.join([timeout])
Waits for process p to terminate. timeout specifies an optional timeout period. A process can be joined as many times as you wish, but it is an error for a process to try and join itself.
p.run()
The method that runs when the process starts. By default, this invokes target that was passed to the Process constructor. As an alternative, a process can be defined by inheriting from Process and reimplementing run().
p.start()
Starts the process. This launches the subprocess that represents the process and invokes p.run() in that subprocess.
p.terminate()
Forcefully terminates the process. If this is invoked, the process p is terminated immediately without performing any kind of cleanup actions. If the process p created subprocesses of its own, those processes will turn into zombies. Some care is required when using this method. If p holds a lock or is involved with interprocess communication, terminating it might cause a deadlock or corrupted I/O.
A Process instance p also has the following data attributes:
p.authkey
The process’ authentication key. Unless explicitly set, this is a 32-character string generated by os.urandom(). The purpose of this key is to provide security for low-level interprocess communication involving network connections. Such connections only work if both ends have the same authentication key.
p.daemon
A Boolean flag that indicates whether or not the process is daemonic. A daemonic process is automatically terminated when the Python process that created it terminates. In addition, a daemonic process is prohibited from creating new processes on its own. The value of p.daemon must be set before a process is started using p.start().
The integer exit code of the process. If the process is still running, this is None. If the value is negative, a value of –N means the process was terminated by signal N.
p.name
The name of the process.
p.pid
The integer process ID of the process.
Here is an example that shows how to create and launch a function (or other callable) as a separate process:

Here is an example that shows how to define this process as a class that inherits from Process:

In both examples, the time should be printed by the subprocess every 15 seconds. It is important to emphasize that for cross-platform portability, new processes should only be created by the main program as shown. Although this is optional on UNIX, it is required on Windows. It should also be noted that on Windows, you will probably need to run the preceding examples in the command shell (command.exe) instead of a Python IDE, such as IDLE.
Interprocess Communication
Two primary forms of interprocess communication are supported by the multiprocessing module: pipes and queues. Both methods are implemented using message passing. However, the queue interface is meant to mimic the use of queues commonly used with thread programs.
Creates a shared process queue. maxsize is the maximum number of items allowed in the queue. If omitted, there is no size limit. The underlying queue is implemented using pipes and locks. In addition, a support thread is launched in order to feed queued data into the underlying pipe.
An instance q of Queue has the following methods:
q.cancel_join_thread()
Don’t automatically join the background thread on process exit. This prevents the join_thread() method from blocking.
q.close()
Closes the queue, preventing any more data from being added to it. When this is called, the background thread will continue to write any queued data not yet written but will shut down as soon as this is complete. This method is called automatically if q is garbage-collected. Closing a queue does not generate any kind of end-of-data signal or exception in queue consumers. For example, if a consumer is blocking on a get() operation, closing the queue in the producer does not cause the get() to return with an error.
q.empty()
Returns True if q is empty at the time of the call. If other processes or threads are being used to add queue items, be aware that the result is not reliable (e.g., new items could have been added to the queue in between the time that the result is returned and used).
q.full()
Returns True if q is full. The result is also not reliable due to threads (see q.empty()).
q.get([block [, timeout]])
Returns an item from q. If q is empty, blocks until a queue item becomes available. block controls the blocking behavior and is True by default. If set to False, a Queue.Empty exception (defined in the Queue library module) is raised if the queue is empty. timeout is an optional timeout to use in blocking mode. If no items become available in the specified time interval, a Queue.Empty exception is raised.
q.get_nowait()
The same as q.get(False).
q.join_thread()
Joins the queue’s background thread. This is used to wait for all queue items to be consumed after q.close() has been called. This method gets called by default in all processes that are not the original creator of q. This behavior can be disabled by called q.cancel_join_thread().
q.put(item [, block [, timeout]])
Puts item onto the queue. If the queue is full, block until space becomes available. block controls the blocking behavior and is True by default. If set to False, a Queue.Full exception (defined in the Queue library module) is raised if the queue is full. timeout specifies how long to wait for space to become available in blocking mode. A Queue.Full exception is raised on timeout.
The same as q.put(item, False).
q.qsize()
Returns the approximate number of items currently in the queue. The result of this function is not reliable because items may have been added or removed from the queue in between the time the result is returned and later used in a program. On some systems, this method may raise an NotImplementedError.
JoinableQueue([maxsize])
Creates a joinable shared process queue. This is just like a Queue except that the queue allows a consumer of items to notify the producer that the items have been successfully been processed. The notification process is implemented using a shared semaphore and condition variable.
An instance q of JoinableQueue has the same methods as Queue, but it has the following additional methods:
q.task_done()
Used by a consumer to signal that an enqueued item returned by q.get() has been processed. A ValueError exception is raised if this is called more times than have been removed from the queue.
q.join()
Used by a producer to block until all items placed in a queue have been processed. This blocks until q.task_done() is called for every item placed into the queue.
The following example shows how you set up a process that runs forever, consuming and processing items on a queue. The producer feeds items into the queue and waits for them to be processed.

In this example, the consumer process is set to daemonic because it runs forever and we want it to terminate when the main program finishes (if you forget this, the program will hang). A JoinableQueue is being used so that the producer actually knows when all of the items put in the queue have been successfully processed. The join() operation ensures this; if you forget this step, the consumer will be terminated before it has had time to complete all of its work.
If desired, multiple processes can put and get items from the same queue. For example, if you wanted to have a pool of consumer processes, you could just write code like this:

When writing code such as this, be aware that every item placed into the queue is pickled and sent to the process over a pipe or socket connection. As a general rule, it is better to send fewer large objects than many small objects.
In certain applications, a producer may want to signal consumers that no more items will be produced and that they should shut down. To do this, you should write code that uses a sentinel—a special value that indicates completion. Here is an example that illustrates this concept using None as a sentinel:

If you are using sentinels as shown in this example, be aware that you will need to put a sentinel on the queue for every single consumer. For example, if there were three consumer processes consuming items on the queue, the producer needs to put three sentinels on the queue to get all of the consumers to shut down.
As an alternative to using queues, a pipe can be used to perform message passing between processes.
Pipe([duplex])
Creates a pipe between processes and returns a tuple (conn1, conn2) where conn1 and conn2 are Connection objects representing the ends of the pipe. By default, the pipe is bidirectional. If duplex is set False, then conn1 can only be used for receiving and conn2 can only be used for sending. Pipe() must be called prior to creating and launching any Process objects that use the pipe.
An instance c of a Connection object returned by Pipe() has the following methods and attributes:
c.close()
Closes the connection. Called automatically if c is garbage collected.
c.fileno()
Returns the integer file descriptor used by the connection.
c.poll([timeout])
Returns True if data is available on the connection. timeout specifies the maximum amount of time to wait. If omitted, the method returns immediately with a result. If timeout is set to None, then the operation will wait indefinitely for data to arrive.
c.recv()
Receives an object sent by c.send(). Raises EOFError if the other end of the connection has been closed and there is no more data.
c.recv_bytes([maxlength])
Receives a complete byte message sent by c.send_bytes(). maxlength specifies the maximum number of bytes to receive. If an incoming message exceeds this, an IOError is raised and no further reads can be made on the connection. Raises EOFError if the other end of the connection has been closed and there is no more data.
c.recv_bytes_into(buffer [, offset])
Receives a complete byte message and stores it in the object buffer, which supports the writable buffer interface (e.g., a bytearray object or similar). offset specifies the byte offset into the buffer where to place the message. Returns the number of bytes received. Raises BufferTooShort if the length of the message exceeds available buffer space.
c.send(obj)
Sends an object through the connection. obj is any object that is compatible with pickle.
c.send_bytes(buffer [, offset [, size]])
Sends a buffer of byte data through the connection. buffer is any object that supports the buffer interface, offset is the byte offset into the buffer, and size is the number of bytes to send. The resulting data is sent as a single message to be received using a single call to c.recv_bytes().
Pipes can be used in a similar manner as queues. Here is an example that shows the previous producer-consumer problem implemented using pipes:

Great attention should be given to proper management of the pipe endpoints. If one of the ends of the pipe is not used in either the producer or consumer, it should be closed. This explains, for instance, why the output end of the pipe is closed in the producer and the input end of the pipe is closed in the consumer. If you forget one of these steps, the program may hang on the recv() operation in the consumer. Pipes are reference counted by the operating system and have to be closed in all processes to produce the EOFError exception. Thus, closing the pipe in the producer doesn’t have any effect unless the consumer also closes the same end of the pipe.
Pipes can be used for bidirectional communication. This can be used to write programs that interact with a process using a request/response model typically associated with client/server computing or remote procedure call. Here is an example:

In this example, the adder() function runs as a server waiting for messages to arrive on its end of the pipe. When received, it performs some processing and sends the result back on the pipe. Keep in mind that send() and recv() use the pickle module to serialize objects. In the example, the server receives a tuple (x, y) as input and returns the result x + y. For more advanced applications that use remote procedure call, however, you should use a process pool as described next.
Process Pools
The following class allows you to create a pool of processes to which various kind of data processing tasks can be submitted. The functionality provided by a pool is somewhat similar to that provided by list comprehensions and functional programming operations such as map-reduce.
Pool([numprocess [,initializer [, initargs]]])
Creates a pool of worker processes. numprocess is the number of processes to create. If omitted, the value of cpu_count() is used. initializer is a callable object that will be executed in each worker process upon startup. initargs is a tuple of arguments to pass to initializer. By default, initializer is None.
An instance p of Pool supports the following operations:
p.apply(func [, args [, kwargs]])
Executes func(*args, **kwargs) in one of the pool workers and returns the result. It is important to emphasize this does not execute func in parallel in all pool workers. If you want func to execute concurrently with different arguments, you either have to call p.apply() from different threads or use p.apply_async().
p.apply_async(func [, args [, kwargs [, callback]]])
Executes func(*args, **kwargs) in one of the pool workers and returns the result asynchronously. The result of this method is an instance of AsyncResult which can be used to obtain the final result at a later time. callback is a callable object that accepts a single input argument. When the result of func becomes available, it is immediately passed to callback. callback should not perform any blocking operations or else it will block the reception of results in other asynchronous operations.
p.close()
Closes the process pool, preventing any further operations. If any operations are still pending, they will be completed before the worker processes terminate.
p.join()
Waits for all worker processes to exit. This can only be called after close() or terminate().
p.imap(func, iterable [, chunksize])
A version of map() that returns an iterator instead of a list of results.
p.imap_unordered(func, iterable [, chunksize]])
The same as imap() except that the results are returned in an arbitrary order based on when they are received from the worker processes.
p.map(func, iterable [, chunksize])
Applies the callable object func to all of the items in iterable and returns the result as a list. The operation is carried out in parallel by splitting iterable into chunks and farming out the work to the worker processes. chunksize specifies the number of items in each chunk. For large amounts of data, increasing the chunksize will improve performance.
p.map_async(func, iterable [, chunksize [, callback]])
The same as map() except that the result is returned asynchronously. The return value is an instance of AsyncResult that can be used to later obtain the result. callback is a callable object accepting a single argument. If supplied, callback is called with the result when it becomes available.
p.terminate()
Immediately terminates all of the worker processes without performing any cleanup or finishing any pending work. If p is garbage-collected, this is called.
The methods apply_async() and map_async() return an AsyncResult instance as a result. An instance a of AsyncResult has the following methods:
a.get([timeout])
Returns the result, waiting for it to arrive if necessary. timeout is an optional timeout. If the result does not arrive in the given time, a multiprocessing.TimeoutError exception is raised. If an exception was raised in the remote operation, it is reraised when this method is called.
a.ready()
Returns True if the call has completed.
a.sucessful()
Returns True if the call completed without any exceptions. An AssertionError is raised if this method is called prior to the result being ready.
a.wait([timeout])
Waits for the result to become available. timeout is an optional timeout.
The following example illustrates the use of a process pool to build a dictionary mapping filenames to SHA512 digest values for an entire directory of files:
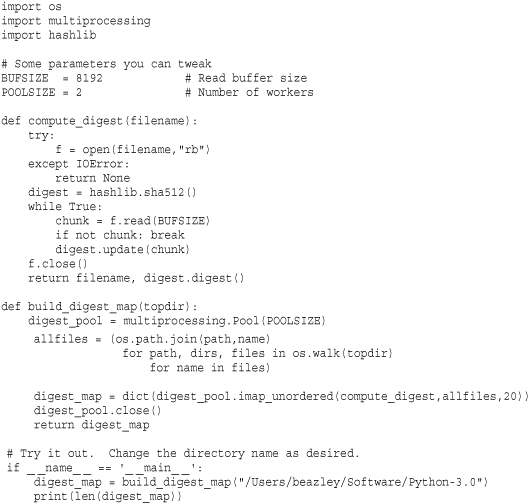
In the example, a sequence of pathnames for all files in a directory tree is specified using a generator expression. This sequence is then chopped up and farmed out to a process pool using the imap_unordered() function. Each pool worker computes a SHA512 digest value for its files using the compute_digest() function. The results are sent back to the master and collected into a Python dictionary. Although it’s by no means a scientific result, this example gives a 75 percent speedup over a single-process solution when run on the author’s dual-core Macbook.
Keep in mind that it only makes sense to use a process pool if the pool workers perform enough work to justify the extra communication overhead. As a general rule, it would not make sense to use a pool for simple calculations such as just adding two numbers together.
Shared Data and Synchronization
Normally, processes are completed isolated from each other with the only means of communication being queues or pipes. However, two objects can be used to represent shared data. Underneath the covers, these objects use shared memory (via mmap) to make access possible in multiple processes.
Value(typecode, arg1, ... argN, lock)
Creates a ctypes object in shared memory. typecode is either a string containing a type code as used by the array module (e.g., 'i', 'd', etc.) or a type object from the ctypes module (e.g., ctypes.c_int, ctypes.c_double, etc.). All extra positional arguments arg1, arg2, ... argN are passed to the constructor for the given type. lock is a keyword-only argument that if set to True (the default), a new lock is created to protect access to the value. If you pass in an existing lock such as a Lock or RLock instance, then that lock is used for synchronization. If v is an instance of a shared value created by Value, then the underlying value is accessed used v.value. For example, reading v.value will get the value and assigning v.value will change the value.
RawValue(typecode, arg1, ..., argN)
The same as Value except that there is no locking.
Array(typecode, initializer, lock)
Creates a ctypes array in shared memory. typecode describes the contents of the array and has the same meaning as described for Value(). initializer is either an integer that sets the initial size of the array or a sequence of items whose values and size are used to initialize the array. lock is a keyword-only argument with the same meaning as described for Value(). If a is an instance of a shared array created by Array, then you access its contents using the standard Python indexing, slicing, and iteration operations, each of which are synchronized by the lock. For byte strings, a will also have an a.value attribute to access the entire array as a single string.
RawArray(typecode, initializer)
The same as Array except that there is no locking. If you are writing programs that must manipulate a large number of array items all at once, the performance will be significantly better if you use this datatype along with a separate lock for synchronization (if needed).
In addition to shared values created using Value() and Array(), the multiprocessing module provides shared versions of the following synchronization primitives:

The behavior of these objects mimics the synchronization primitives defined in the threading module with identical names. Please refer to the threading documentation for further details.
It should be noted that with multiprocessing, it is not normally necessary to worry about low-level synchronization with locks, semaphores, or similar constructs to the same degree as with threads. In part, send() and receive() operations on pipes and put() and get() operations on queues already provide synchronization. However, shared values and locks can have uses in certain specialized settings. Here is an example that sends a Python list of floats to another process using a shared array instead of a pipe:

Further study of this example is left to the reader. However, in a performance test on the author’s machine, sending a large list of floats through the FloatChannel is about 80 percent faster than sending the list through a Pipe (which has to pickle and unpickle all of the values).
Managed Objects
Unlike threads, processes do not support shared objects. Although you can create shared values and arrays as shown in the previous section, this doesn’t work for more advanced Python objects such as dictionaries, lists, or instances of user-defined classes. The multiprocessing module does, however, provide a way to work with shared objects if they run under the control of a so-called manager. A manager is a separate subprocess where the real objects exist and which operates as a server. Other processes access the shared objects through the use of proxies that operate as clients of the manager server.
The most straightforward way to work with simple managed objects is to use the Manager() function.
Manager()
Creates a running manager server in a separate process. Returns an instance of type SyncManager which is defined in the multiprocessing.managers submodule.
An instance m of SyncManager as returned by Manager() has a series of methods for creating shared objects and returning a proxy which can be used to access them. Normally, you would create a manager and use these methods to create shared objects before launching any new processes. The following methods are defined:
m.Array(typecode, sequence)
Creates a shared Array instance on the server and returns a proxy to it. See the “Shared Data and Synchronization” section for a description of the arguments.
m.BoundedSemaphore([value])
Creates a shared threading.BoundedSemaphore instance on the server and returns a proxy to it.
Creates a shared threading.Condition instance on the server and returns a proxy to it. lock is a proxy instance created by m.Lock() or m.Rlock().
m.dict([args])
Creates a shared dict instance on the server and returns a proxy to it. The arguments to this method are the same as for the built-in dict() function.
m.Event()
Creates a shared threading.Event instance on the server and returns a proxy to it.
m.list([sequence])
Creates a shared list instance on the server and returns a proxy to it. The arguments to this method are the same as for the built-in list() function.
m.Lock()
Creates a shared threading.Lock instance on the server and returns a proxy to it.
m.Namespace()
Creates a shared namespace object on the server and returns a proxy to it. A namespace is an object that is somewhat similar to a Python module. For example, if n is a namespace proxy, you can assign and read attributes using (.) such as n.name = value or value = n.name. However, the choice of name is significant. If name starts with a letter, then that value is part of the shared object held by the manager and is accessible in all other processes. If name starts with an underscore, it is only part of the proxy object and is not shared.
m.Queue()
Creates a shared Queue.Queue object on the server and returns a proxy to it.
m.RLock()
Creates a shared threading.Rlock object on the server and returns a proxy to it.
m.Semaphore([value])
Creates a shared threading.Semaphore object on the server and returns a proxy to it.
m.Value(typecode, value)
Creates a shared Value object on the server and returns a proxy to it. See the “Shared Data and Synchronization” section for a description of the arguments.
The following example shows how you would use a manager in order to create a dictionary shared between processes.

If you run this example, the watch() function prints out the value of d every time the passed event gets set. In the main program, a shared dictionary and event are created and manipulated in the main process. When you run this, you will see the child process printing data.
If you want to have shared objects of other types such as instances of user-defined classes, you have to create your custom manager object. To do this, you create a class that inherits from BaseManager, which is defined in the multiprocessing.managers submodule.
managers.BaseManager([address [, authkey]])
Base class used to create custom manager servers for user-defined objects. address is an optional tuple (hostname, port) that specifies a network address for the server. If omitted, the operating system will simply assign an address corresponding to some free port number. authkey is a string that is used to authenticate clients connecting to the server. If omitted, the value of current_process().authkey is used.
If mgrclass is a class that inherits from BaseManager, the following class method is used to create methods for returning proxies to shared objects.
![]()
Registers a new data type with the manager class. typeid is a string that is used to name a particular kind of shared object. This string should be a valid Python identifier. callable is a callable object that creates or returns the instance to be shared. proxytype is a class that provides the implementation of the proxy objects to be used in clients. Normally, these classes are generated by default so this is normally set to None. exposed is a sequence of method names on the shared object that will be exposed to proxy objects. If omitted, the value of proxytype._exposed_ is used and if that is undefined, then all public methods (all callable methods that don’t start with an underscore (_) are used). method_to_typeid is a mapping from method names to type IDS that is used to specify which methods should return their results using proxy objects. If a method is not found in this mapping, the return value is copied and returned. If method_to_typeid is None, the value of proxytype._method_to_typeid_ is used if it is defined. create_method is a Boolean flag that specifies whether a method with the name typeid should be created in mgrclass. By default, this is True.
An instance m of a manager derived from BaseManager must be manually started to operate. The following attributes and methods are related to this:
m.address
A tuple (hostname, port) that has the address being used by the manager server.
m.connect()
Connects to a remote manager object, the address of which was given to the BaseManager constructor.
m.serve_forever()
Runs the manager server in the current process.
m.shutdown()
Shuts down a manager server launched by the m.start() method.
m.start()
Starts a separate subprocess and starts the manager server in that process.
The following example shows how to create a manager for a user-defined class:
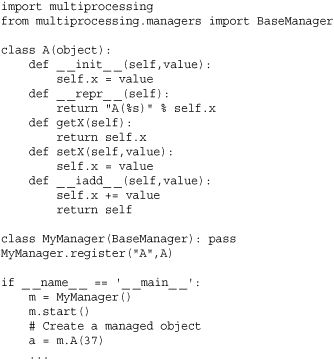
In this example, the last statement creates an instance of A that lives on the manager server. The variable a in the previous code is only a proxy for this instance. The behavior of this proxy is similar to (but not completely identical to) referent, the object on the server. First, you will find that data attributes and properties cannot be accessed. Instead, you have to use access functions:

With proxies, the repr() function returns a string representing the proxy, whereas str() returns the output of _ _repr_ _() on the referent. For example:

Special methods and any method starting with an underscore (_) are not accessible on proxies. For example, if you tried to invoke a._ _iadd_ _(), it doesn’t work:

In more advanced applications, it is possible to customize proxies to more carefully control access. This is done by defining a class that inherits from BaseProxy, which is defined in multiprocessing.managers. The following code shows how you could make a custom proxy to the A class in the previous example that properly exposes the _ _iadd_ _() method and which uses a property to expose the x attribute:

An instance proxy of a class derived from BaseProxy has the following methods:
proxy._callmethod(name [, args [, kwargs]])
Calls the method name on the proxy’s referent object. name is a string with the method name, args is a tuple containing positional arguments, and kwargs is a dictionary of keyword arguments. The method name must be explicitly exposed. Normally this is done by including the name in the _exposed_ class attribute of the proxy class.
proxy._getvalue()
Returns a copy of the referent in the caller. If this call is made in a different process, the referent object is pickled, sent to the caller, and is unpickled. An exception is raised if the referent can’t be pickled.
Connections
Programs that use the multiprocessing module can perform message passing with other processes running on the same machine or with processes located on remote systems. This can be useful if you want to take a program written to work on a single system and expand it work on a computing cluster. The multiprocessing.connection submodule has functions and classes for this purpose:
![]()
Connects to another process which must already be listening at address address. address is a tuple (hostname , port) representing a network address, a file name representing a UNIX domain socket, or a string of the form r'\servernamepipepipename' representing a Windows named pipe on a remote system servername (use a servername of '.' for the local machine). family is a string representing the addess format and is typically one of 'AF_INET', 'AF_UNIX', or 'AF_PIPE'. If omitted, the family is inferred from the format of address. authentication is a Boolean flag that specifies whether digest authentication is to be used. authkey is a string containing the authentication key. If omitted, then the value of current_process().authkey is used. The return value from this function is a Connection object, which was previously described in the pipes section of “Interprocess Communication.”
![]()
A class that implements a server for listening for and handling connections made by the Client() function. The address, family, authenticate, and authkey arguments have the same meaning as for Client(). backlog is an integer corresponding to the value passed to the listen() method of sockets if the address parameter specifies a network connection. By default, backlog is 1. If address is omitted, then a default address is chosen. If both address and family are omitted, then the fastest available communications scheme on the local system is chosen.
An instance s of Listener supports the following methods and attributes:
s.accept()
Accepts a new connection and returns a Connection object. Raises AuthenticationError if authentication fails.
s.address
The address that the listener is using.
Closes the pipe or socket being used by the listener.
s.last_accepted
The address of the last client that was accepted.
Here is an example of a server program that listens for clients and implements a simple remote operation (adding):

Here is a simple client program that connects to this server and sends some messages:

Miscellaneous Utility Functions
The following utility functions are also defined:
active_children()
Returns a list of Process objects for all active child processes.
cpu_count()
Returns the number of CPUs on the system if it can be determined.
current_process()
Returns the Process object for the current process.
freeze_support()
A function that should be included as the first statement of the main program in an application that will be “frozen” using various packaging tools such as py2exe. This is needed to prevent runtime errors associated with launching subprocesses in a frozen application.
Returns the logging object associated with the multiprocessing module, creating it if it doesn’t already exist. The returned logger does not propagate messages to the root logger, has a level of logging.NOTSET, and prints all logging messages to standard error.
set_executable(executable)
Sets the name of the Python executable used to execute subprocesses. This is only defined on Windows.
General Advice on Multiprocessing
The multiprocessing module is one of the most advanced and powerful modules in the Python library. Here are some general tips for keeping your head from exploding:
• Carefully read the online documentation before building a large application. Although this section has covered the essential basics, the official documentation covers some of the more sneaky issues that can arise.
• Make sure that all data passed between processes is compatible with pickle.
• Avoid shared data and learn to love message passing and queues. With message passing, you don’t have to worry so much about synchronization, locking, and other issues. It also tends to provide better scaling as the number of processes increases.
• Don’t use global variables inside functions that are meant to run in separate processes. It is better to explicitly pass parameters instead.
• Try not to mix threads and multiprocessing together in the same program unless you’re vastly trying to improve your job security (or to have it reduced depending on who is doing the code review).
• Pay very careful attention to how processes get shut down. As a general rule, you will want to explicitly close processes and have a well-defined termination scheme in place as opposed to just relying on garbage collection or having to forcefully terminate children using the terminate() operation.
• The use of managers and proxies is closely related to a variety of concepts in distributed computing (e.g., distributed objects). A good distributed computing book might be a useful reference.
• The multiprocessing module originated from a third-party library known as pyprocessing. Searching for usage tips and information on this library may be a useful resource.
• Although this module works on Windows, you should carefully read the official documentation for a variety of subtle details. For example, to launch a new process on Windows, the multiprocessing module implements its own clone of the UNIX fork() operation, in which process state is copied to the child process over a pipe. As a general rule, this module is much more tuned to UNIX systems.
• Above all else, try to keep things as simple as possible.
threading
The threading module provides a Thread class and a variety of synchronization primitives for writing multithreaded programs.
Thread Objects
The Thread class is used to represent a separate thread of control. A new thread can be created as follows:
Thread(group=None, target=None, name=None, args=(), kwargs={})
This creates a new Thread instance. group is None and is reserved for future extensions. target is a callable object invoked by the run() method when the thread starts. By default, it’s None, meaning that nothing is called. name is the thread name. By default, a unique name of the form "Thread-N" is created. args is a tuple of arguments passed to the target function. kwargs is a dictionary of keyword arguments passed to target.
A Thread instance t supports the following methods and attributes:
t.start()
Starts the thread by invoking the run() method in a separate thread of control. This method can be invoked only once.
t.run()
This method is called when the thread starts. By default, it calls the target function passed in the constructor. This method can also be redefined in subclasses of Thread.
t.join([timeout])
Waits until the thread terminates or a timeout occurs. timeout is a floating-point number specifying a timeout in seconds. A thread cannot join itself, and it’s an error to join a thread before it has been started.
t.is_alive()
Returns True if the thread is alive and False otherwise. A thread is alive from the moment the start() method returns until its run() method terminates. t.isAlive() is an alias for this method in older code.
t.name
The thread name. This is a string that is used for identification only and which can be changed to a more meaningful value if desired (which may simplify debugging). In older code, t.getName() and t.setName(name) are used to manipulate the thread name.
t.ident
An integer thread identifier. If the thread has not yet started, the value is None.
t.daemon
The thread’s Boolean daemonic flag. This must be set prior to calling start() and the initial value is inherited from daemonic status of the creating thread. The entire Python program exits when no active non-daemon threads are left. All programs have a main thread that represents the initial thread of control and which is not daemonic. In older code, t.setDaemon(flag) and t.isDaemon() are used to manipulate this value.
Here is an example that shows how to create and launch a function (or other callable) as a thread:

Here is an example that shows how to define the same thread as a class:

If you define a thread as a class and define your own _ _init_ _() method, it is critically important to call the base class constructor Thread._ _init_ _() as shown. If you forget this, you will get a nasty error. Other than run(), it is an error to override any of the other methods already defined for a thread.
The setting of the daemon attribute in these examples is a common feature of threads that will run forever in the background. Normally, Python waits for all threads to terminate before the interpreter exits. However, for nonterminating background tasks, this behavior is often undesirable. Setting the daemon flag makes the interpreter quit immediately after the main program exits. In this case, the daemonic threads are simply destroyed.
Timer Objects
A Timer object is used to execute a function at some later time.
Timer(interval, func [, args [, kwargs]])
Creates a timer object that runs the function func after interval seconds have elapsed. args and kwargs provide the arguments and keyword arguments passed to func. The timer does not start until the start() method is called.
A Timer object, t, has the following methods:
t.start()
Starts the timer. The function func supplied to Timer() will be executed after the specified timer interval.
t.cancel()
Cancels the timer if the function has not executed yet.
Lock Objects
A primitive lock (or mutual exclusion lock) is a synchronization primitive that’s in either a “locked” or “unlocked” state. Two methods, acquire() and release(), are used to change the state of the lock. If the state is locked, attempts to acquire the lock are blocked until the lock is released. If more than one thread is waiting to acquire the lock, only one is allowed to proceed when the lock is released. The order in which waiting threads proceed is undefined.
A new Lock instance is created using the following constructor:
Lock()
Creates a new Lock object that’s initially unlocked.
A Lock instance, lock, supports the following methods:
lock.acquire([blocking ])
Acquires the lock, blocking until the lock is released if necessary. If blocking is supplied and set to False, the function returns immediately with a value of False if the lock could not be acquired or True if locking was successful.
lock.release()
Releases a lock. It’s an error to call this method when the lock is in an unlocked state or from a different thread than the one that originally called acquire().
RLock
A reentrant lock is a synchronization primitive that’s similar to a Lock object, but it can be acquired multiple times by the same thread. This allows the thread owning the lock to perform nested acquire() and release() operations. In this case, only the outermost release() operation resets the lock to its unlocked state.
A new RLock object is created using the following constructor:
RLock()
Creates a new reentrant lock object. An RLock object, rlock, supports the following methods:
rlock.acquire([blocking ])
Acquires the lock, blocking until the lock is released if necessary. If no thread owns the lock, it’s locked and the recursion level is set to 1. If this thread already owns the lock, the recursion level of the lock is increased by one and the function returns immediately.
Releases a lock by decrementing its recursion level. If the recursion level is zero after the decrement, the lock is reset to the unlocked state. Otherwise, the lock remains locked. This function should only be called by the thread that currently owns the lock.
Semaphore and Bounded Semaphore
A semaphore is a synchronization primitive based on a counter that’s decremented by each acquire() call and incremented by each release() call. If the counter ever reaches zero, the acquire() method blocks until some other thread calls release().
Semaphore([value])
Creates a new semaphore. value is the initial value for the counter. If omitted, the counter is set to a value of 1.
A Semaphore instance, s, supports the following methods:
s.acquire([blocking])
Acquires the semaphore. If the internal counter is larger than zero on entry, this method decrements it by 1 and returns immediately. If it’s zero, this method blocks until another thread calls release(). The blocking argument has the same behavior as described for Lock and RLock objects.
s.release()
Releases a semaphore by incrementing the internal counter by 1. If the counter is zero and another thread is waiting, that thread is awakened. If multiple threads are waiting, only one will be returned from its acquire() call. The order in which threads are released is not deterministic.
BoundedSemaphore([value])
Creates a new semaphore. value is the initial value for the counter. If value is omitted, the counter is set to a value of 1. A BoundedSemaphore works exactly like a Semaphore except the number of release() operations cannot exceed the number of acquire() operations.
A subtle difference between a semaphore and a mutex lock is that a semaphore can be used for signaling. For example, the acquire() and release() methods can be called from different threads to communicate between producer and consumer threads.

The kind of signaling shown in this example is often instead carried out using condition variables, which will be described shortly.
Events
Events are used to communicate between threads. One thread signals an “event,” and one or more other threads wait for it. An Event instance manages an internal flag that can be set to true with the set() method and reset to false with the clear() method. The wait() method blocks until the flag is true.
Event()
Creates a new Event instance with the internal flag set to false. An Event instance, e, supports the following methods:
e.is_set()
Returns true only if the internal flag is true. This method is called isSet() in older code.
e.set()
Sets the internal flag to true. All threads waiting for it to become true are awakened.
e.clear()
Resets the internal flag to false.
e.wait([timeout])
Blocks until the internal flag is true. If the internal flag is true on entry, this method returns immediately. Otherwise, it blocks until another thread calls set() to set the flag to true or until the optional timeout occurs. timeout is a floating-point number specifying a timeout period in seconds.
Although Event objects can be used to signal other threads, they should not be used to implement the kind of notification that is typical in producer/consumer problems. For example, you should avoid code like this:

This code does not work reliably because the producer might produce a new item in between the evt.wait() and evt.clear() operations. However, by clearing the event, this new item won’t be seen by the consumer until the producer creates a new item. In the best case, the program will experience a minor hiccup where the processing of an item is inexplicably delayed. In the worst case, the whole program will hang due to the loss of an event signal. For these types of problems, you are better off using condition variables.
Condition Variables
A condition variable is a synchronization primitive, built on top of another lock that’s used when a thread is interested in a particular change of state or event occurring. A typical use is a producer-consumer problem where one thread is producing data to be consumed by another thread. A new Condition instance is created using the following constructor:
Condition([lock])
Creates a new condition variable. lock is an optional Lock or RLock instance. If not supplied, a new RLock instance is created for use with the condition variable.
A condition variable, cv, supports the following methods:
cv.acquire(*args)
Acquires the underlying lock. This method calls the corresponding acquire(*args) method on the underlying lock and returns the result.
cv.release()
Releases the underlying lock. This method calls the corresponding release() method on the underlying lock.
cv.wait([timeout])
Waits until notified or until a timeout occurs. This method is called after the calling thread has already acquired the lock. When called, the underlying lock is released, and the thread goes to sleep until it’s awakened by a notify() or notifyAll() call performed on the condition variable by another thread. Once awakened, the thread reacquires the lock and the method returns. timeout is a floating-point number in seconds. If this time expires, the thread is awakened, the lock reacquired, and control returned.
cv.notify([n])
Wakes up one or more threads waiting on this condition variable. This method is called only after the calling thread has acquired the lock, and it does nothing if no threads are waiting. n specifies the number of threads to awaken and defaults to 1. Awakened threads don’t return from the wait() call until they can reacquire the lock.
cv.notify_all()
Wakes up all threads waiting on this condition. This method is called notifyAll() in older code.
Here is an example that provides a template of using condition variables:

A subtle aspect of using condition variables is that if there are multiple threads waiting on the same condition, the notify() operation may awaken one or more of them (this behavior often depends on the underlying operating system). Because of this, there is always a possibility that a thread will awaken only to find that the condition of interest no longer holds. This explains, for instance, why a while loop is used in the consumer() function. If the thread awakens, but the produced item is already gone, it just goes back to waiting for the next signal.
Working with Locks
Great care must be taken when working with any of the locking primitives such as Lock, RLock, or Semaphore. Mismanagement of locks is a frequent source of deadlock or race conditions. Code that relies on a lock should always make sure locks get properly released even when exceptions occur. Typical code looks like this:

Alternatively, all of the locks also support the context management protocol which is a little cleaner:

In this last example, the lock is automatically acquired by the with statement and released when control flow leaves the context.
Also, as a general rule you should avoid writing code where more than one lock is acquired at any given time. For example:

This is usually a good way to have your application mysteriously deadlock. Although there are strategies for avoiding this (for example, hierarchical locking), you’re often better off writing code that avoids this altogether.
Thread Termination and Suspension
Threads do not have any methods for forceful termination or suspension. This omission is by design and due to the intrinsic complexity of writing threaded programs. For example, if a thread has acquired a lock, forcefully terminating or suspending it before it is able to release the lock may cause the entire application to deadlock. Moreover, it is generally not possible to simply “release all locks” on termination either because complicated thread synchronization often involves locking and unlocking operations that must be carried out in a very precise sequence to work.
If you want to support termination or suspension, you need to build these features yourself. Typically, it’s done by making a thread run in a loop that periodically checks its status to see if it should terminate. For example:

Keep in mind that to make this approach work reliability, the thread should take great care not to perform any kind of blocking I/O operation. For example, if the thread blocks waiting for data to arrive, it won’t terminate until it wakes up from that operation. Because of this, you would probably want to make the implementation use timeouts, non-blocking I/O, and other advanced features to make sure that that the termination check executes every so often.
Utility Functions
The following utility functions are available:
active_count()
Returns the number of currently active Thread objects.
current_thread()
Returns the Thread object corresponding to the caller’s thread of control.
enumerate()
Returns a list of all currently active Thread objects.
local()
Returns a local object that allows for the storage of thread-local data. This object is guaranteed to be unique in each thread.
Sets a profile function that will be used for all threads created. func is passed to sys.setprofile() before each thread starts running.
settrace(func)
Sets a tracing function that will be used for all threads created. func is passed to sys.settrace() before each thread starts running.
stack_size([size])
Returns the stack size used when creating new threads. If an optional integer size is given, it sets the stack size to be used for creating new threads. size can be a value that is 32768 (32KB) or greater and a multiple of 4096 (4KB) for maximum portability. A ThreadError exception is raised if this operation isn’t supported on the system.
The Global Interpreter Lock
The Python interpreter is protected by a lock that only allows one thread to execute at a time even if there are multiple processors available. This severely limits the usefulness of threads in compute-intensive programs—in fact, the use of threads will often make CPU-bound programs run significantly worse than would be the case if they just sequentially carried out the same work. Thus, threads should really only be reserved for programs that are primarily concerned with I/O such as network servers. For more compute-intensive tasks, consider using C extension modules or the multiprocessing module instead. C extensions have the option of releasing the interpreter lock and running in parallel, provided that they don’t interact with the interpreter when the lock is released. The multiprocessing module farms work out to independent subprocesses that aren’t restricted by the lock.
Programming with Threads
Although it is possible to write very traditional multithreaded programs in Python using various combinations of locks and synchronization primitives, there is one style of programming that is recommended over all others—and that’s to try and organize multithreaded programs as a collection of independent tasks that communicate through message queues. This is described in the next section (the queue module) along with an example.
queue, Queue
The queue module (named Queue in Python 2) implements various multiproducer, multiconsumer queues that can be used to safely exchange information between multiple threads of execution.
The queue module defines three different queue classes:
Queue([maxsize])
Creates a FIFO (first-in first-out) queue. maxsize is the maximum number of items that can be placed in the queue. If maxsize omitted or 0, the queue size is infinite.
LifoQueue([maxsize])
Creates a LIFO (last-in, first-out) queue (also known as a stack).
Creates a priority queue in which items are ordered from lowest to highest priority. When working with this queue, items should be tuples of the form (priority, data) where priority is a number.
An instance q of any of the queue classes has the following methods:
q.qsize()
Returns the approximate size of the queue. Because other threads may be updating the queue, this number is not entirely reliable.
q.empty()
Returns True if the queue is empty and returns False otherwise.
q.full()
Returns True if the queue is full and returns False otherwise.
q.put(item [, block [, timeout]])
Puts item into the queue. If optional argument block is True (the default), the caller blocks until a free slot is available. Otherwise (block is False), the Full exception is raised if the queue is full. timeout supplies an optional timeout value in seconds. If a timeout occurs, the Full exception is raised.
q.put_nowait(item)
Equivalent to q.put(item, False).
q.get([block [, timeout]])
Removes and returns an item from the queue. If optional argument block is True (the default), the caller blocks until an item is available. Otherwise (block is False), the Empty exception is raised if the queue is empty. timeout supplies an optional timeout value in seconds. If a timeout occurs, the Empty exception is raised.
q.get_nowait()
Equivalent to get(0).
q.task_done()
Used by consumers of queued data to indicate that processing of an item has been finished. If this is used, it should be called once for every item removed from the queue.
q.join()
Blocks until all items on the queue have been removed and processed. This will only return once q.task_done() has been called for every item placed on the queue.
Queue Example with Threads
Multithreaded programs are often simplified with the use of queues. For example, instead of relying upon shared state that must be protected by locks, threads can be linked together using shared queues. In this model, worker threads typically operate as consumers of data. Here is an example that illustrates the concept:

The design of this class has been chosen very carefully. First, you will notice that the programming API is a subset of the Connection objects that get created by pipes in the multiprocessing module. This allows for future expansion. For example, workers could later be migrated into a separate process without breaking the code that sends them data.
Second, the programming interface allows for thread termination. The close() method places a sentinel onto the queue which, in turn, causes the thread to shut down when processed.
Finally, the programming API is also almost identical to a coroutine. If the work to be performed doesn’t involve any blocking operations, you could reimplement the run() method as a coroutine and dispense with threads altogether. This latter approach might run faster because there would no longer be any overhead due to thread context switching.
Coroutines and Microthreading
In certain kinds of applications, it is possible to implement cooperative user-space multithreading using a task scheduler and a collection of generators or coroutines. This is sometimes called microthreading, although the terminology varies—sometimes this is described in the context of tasklets, green threads, greenlets, etc. A common use of this technique is in programs that need to manage a large collection of open files or sockets. For example, a network server that wants to simultaneously manage 1,000 client connections. Instead of creating 1,000 threads to do that, asynchronous I/O or polling (using the select module) is used in conjunction with a task scheduler that processes I/O events.
The underlying concept that drives this programming technique is the fact that the yield statement in a generator or coroutine function suspends the execution of the function until it is later resumed with a next() or send() operation. This makes it possible to cooperatively multitask between a set of generator functions using a scheduler loop. Here is an example that illustrates the idea:

It is uncommon for a program to define a series of CPU-bound coroutines and schedule them as shown. Instead, you are more likely to see this technique used with I/O bound tasks, polling, or event handling. An advanced example showing this technique is found in the select module section of Chapter 21, “Network Programming and Sockets.”