
21. Network Programming and Sockets
This chapter describes the modules used to implement low-level network servers and clients. Python provides extensive network support, ranging from programming directly with sockets to working with high-level application protocols such as HTTP. To begin, a very brief (and admittedly terse) introduction to network programming is presented. Readers are advised to consult a book such as UNIX Network Programming, Volume 1: Networking APIs: Sockets and XTI by W. Richard Stevens (Prentice Hall, 1997, ISBN 0-13-490012-X) for many of the advanced details. Chapter 22, “Internet Application Programming,” describes modules related to application-level protocols.
Network Programming Basics
Python’s network programming modules primarily support two Internet protocols: TCP and UDP. The TCP protocol is a reliable connection-oriented protocol used to establish a two-way communications stream between machines. UDP is a lower-level packet-based protocol (connectionless) in which machines send and receive discrete packets of information without formally establishing a connection. Unlike TCP, UDP communication is unreliable and thus inherently more complicated to manage in applications that require reliable communications. Consequently, most Internet applications utilize TCP connections.
Both network protocols are handled through a programming abstraction known as a socket. A socket is an object similar to a file that allows a program to accept incoming connections, make outgoing connections, and send and receive data. Before two machines can communicate, both must create a socket object.
The machine receiving the connection (the server) must bind its socket object to a known port number. A port is a 16-bit number in the range 0–65535 that’s managed by the operating system and used by clients to uniquely identify servers. Ports 0–1023 are reserved by the system and used by common network protocols. The following table shows the port assignments for a couple of common protocols (a more complete list can be found at http://www.iana.org/assignments/port-numbers):

The process of establishing a TCP connection involves a precise sequence of steps on both the server and client, as shown in Figure 21.1.
Figure 21.1 TCP connection protocol.
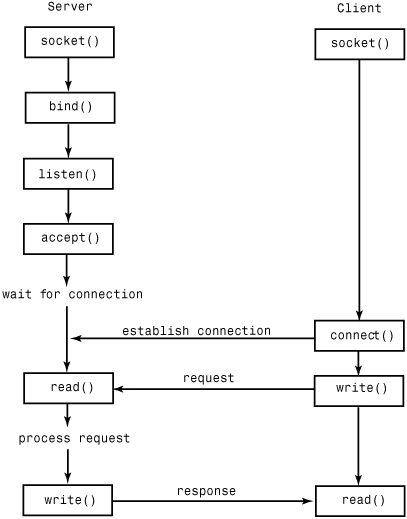
For TCP servers, the socket object used to receive connections is not the same socket used to perform subsequent communication with the client. In particular, the accept() system call returns a new socket object that’s actually used for the connection. This allows a server to manage connections from a large number of clients simultaneously.
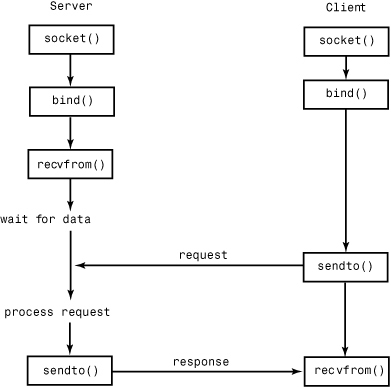
UDP communication is performed in a similar manner, except that clients and servers don’t establish a “connection” with each other, as shown in Figure 21.2.
Figure 21.2 UDP connection protocol.
The following example illustrates the TCP protocol with a client and server written using the socket module. In this case, the server simply returns the current time to the client as a string.

Here’s the client program:

An example of establishing a UDP connection appears in the socket module section later in this chapter.
It is common for network protocols to exchange data in the form of text. However, great attention needs to be given to text encoding. In Python 3, all strings are Unicode. Therefore, if any kind of text string is to be sent across the network, it needs to be encoded. This is why the server is using the encode('ascii') method on the data it transmits. Likewise, when a client receives network data, that data is first received as raw unencoded bytes. If you print it out or try to process it as text, you’re unlikely to get what you expected. Instead, you need to decode it first. This is why the client code is using decode('ascii') on the result.
The remainder of this chapter describes modules that are related to socket programming. Chapter 22 describes higher-level modules that provide support for various Internet applications such as email and the Web.
asynchat
The asynchat module simplifies the implementation of applications that implement asynchronous networking using the asyncore module. It does this by wrapping the low-level I/O functionality of asyncore with a higher-level programming interface that is designed for network protocols based on simple request/response mechanisms (for example, HTTP).
To use this module, you must define a class that inherits from async_chat. Within this class, you must define two methods: collect_incoming_data() and found_terminator(). The first method is invoked whenever data is received on the network connection. Typically, it would simply take the data and store it someplace. The found_terminator() method is called when the end of a request has been detected. For example, in HTTP, requests are terminated by a blank line.
For data output, async_chat maintains a producer FIFO queue. If you need to output data, it is simply added to this queue. Then, whenever writes are possible on the network connection, data is transparently taken from this queue.
async_chat([sock])
Base class used to define new handlers. async_chat inherits from asyncore.dispatcher and provides the same methods. sock is a socket object that’s used for communication.
An instance, a, of async_chat has the following methods in addition to those already provided by the asyncore.dispatcher base class:
a.close_when_done()
Signals an end-of-file on the outgoing data stream by pushing None onto the producer FIFO queue. When this is reached by the writer, the channel will be closed.
a.collect_incoming_data(data)
Called whenever data is received on the channel. data is the received data and is typically stored for later processing. This method must be implemented by the user.
a.discard_buffers()
Discards all data held in input/output buffers and the producer FIFO queue.
Called when the termination condition set by set_terminator() holds. This method must be implemented by the user. Typically, it would process data previously collected by the collect_incoming_data() method.
a.get_terminator()
Returns the terminator for the channel.
a.push(data)
Pushes data onto the channel’s outgoing producer FIFO queue. data is a string containing the data to be sent.
a.push_with_producer(producer)
Pushes a producer object, producer, onto the producer FIFO queue. producer may be any object that has a simple method, more(). The more() method should produce a string each time it is invoked. An empty string is returned to signal the end of data. Internally, the async_chat class repeatedly calls more() to obtain data to write on the outgoing channel. More than one producer object can be pushed onto the FIFO by calling push_with_producer() repeatedly.
s.set_terminator(term)
Sets the termination condition on the channel. term may either be a string, an integer, or None. If term is a string, the method found_terminator() is called whenever that string appears in the input stream. If term is an integer, it specifies a byte count. After many bytes have been read, found_terminator() will be called. If term is None, data is collected forever.
The module defines one class that can produce data for the a.push_with_producer() method.
simple_producer(data [, buffer_size])
Creates a simple producer object that produces chunks from a byte string data. buffer_size specifies the chunk size and is 512 by default.
The asynchat module is always used in conjunction with the asyncore module. For instance, asyncore is used to set up the high-level server, which accepts incoming connections. asynchat is then used to implement handlers for each connection. The following example shows how this works by implementing a minimalistic web server that handles GET requests. The example omits a lot of error checking and details but should be enough to get you started. Readers should compare this example to the example in the asyncore module, which is covered next.
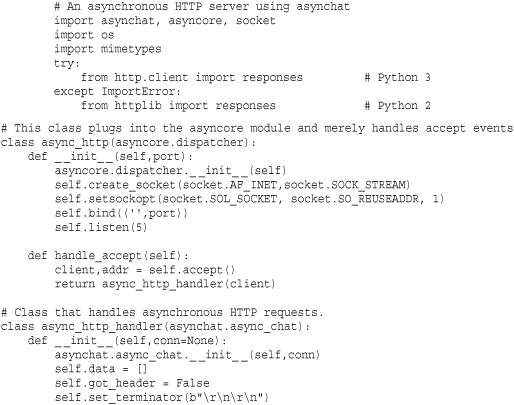
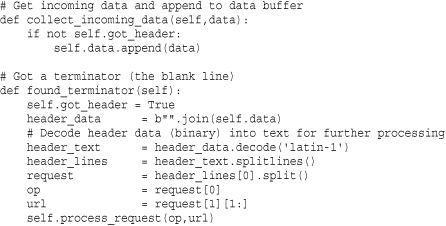
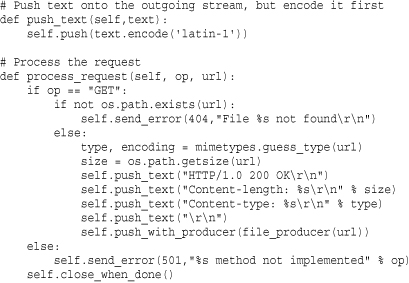

To test this example, you will need to supply a URL corresponding to a file in the same directory as where you are running the server.
asyncore
The asyncore module is used to build network applications in which network activity is handled asynchronously as a series of events dispatched by an event loop, built using the select() system call. Such an approach is useful in network programs that want to provide concurrency, but without the use of threads or processes. This method can also provide high performance for short transactions. All the functionality of this module is provided by the dispatcher class, which is a thin wrapper around an ordinary socket object.
dispatcher([sock])
Base class defining an event-driven nonblocking socket object. sock is an existing socket object. If omitted, a socket must be created using the create_socket() method (described shortly). Once it’s created, network events are handled by special handler methods. In addition, all open dispatcher objects are saved in an internal list that’s used by a number of polling functions.
The following methods of the dispatcher class are called to handle network events. They should be defined in classes derived from dispatcher.
d.handle_accept()
Called on listening sockets when a new connection arrives.
d.handle_close()
Called when the socket is closed.
d.handle_connect()
Called when a connection is made.
d.handle_error()
Called when an uncaught Python exception occurs.
Called when out-of-band data for a socket is received.
d.handle_read()
Called when new data is available to be read from a socket.
d.handle_write()
Called when an attempt to write data is made.
d.readable()
This function is used by the select() loop to see whether the object is willing to read data. Returns True if so, False if not. This method is called to see if the handle_read() method should be called with new data.
d.writable()
Called by the select() loop to see if the object wants to write data. Returns True if so, False otherwise. This method is always called to see whether the handle_write() method should be called to produce output.
In addition to the preceding methods, the following methods are used to perform low-level socket operations. They’re similar to those available on a socket object.
d.accept()
Accepts a connection. Returns a pair (client, addr) where client is a socket object used to send and receive data on the connection and addr is the address of the client.
d.bind(address)
Binds the socket to address. address is typically a tuple (host, port), but this depends the address family being used.
d.close()
Closes the socket.
d.connect(address)
Makes a connection. address is a tuple (host, port).
d.create_socket(family, type)
Creates a new socket. Arguments are the same as for socket.socket().
d.listen([backlog])
Listens for incoming connections. backlog is an integer that is passed to the underlying socket.listen() function.
d.recv(size)
Receives at most size bytes. An empty string indicates the client has closed the channel.
d.send(data)
Sends data. data is a byte string.
The following function is used to start the event loop and process events:
loop([timeout [, use_poll [, map [, count]]]])
Polls for events indefinitely. The select() function is used for polling unless the use_poll parameter is True, in which case poll() is used instead. timeout is the timeout period and is set to 30 seconds by default. map is a dictionary containing all the channels to monitor. count specifies how many polling operations to perform before returning. If count is None (the default), loop() polls forever until all channels are closed. If count is 1, the function will execute a single poll for events and return.
Example
The following example implements a minimalistic web server using asyncore. It implements two classes—asynhttp for accepting connections and asynclient for processing client requests. This should be compared with the example in the asynchat module. The main difference is that this example is somewhat lower-level—requiring us to worry about breaking the input stream into lines, buffering excess data, and identifying the blank line that terminates the request header.
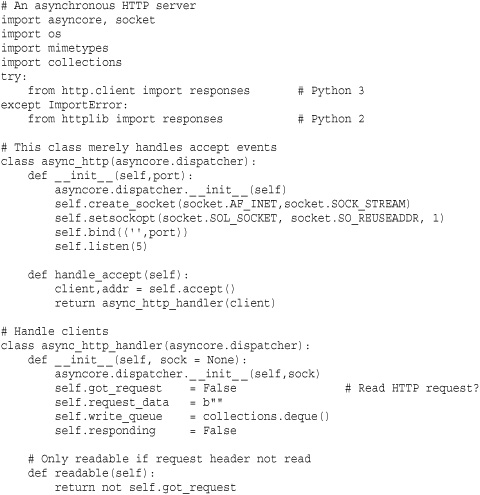
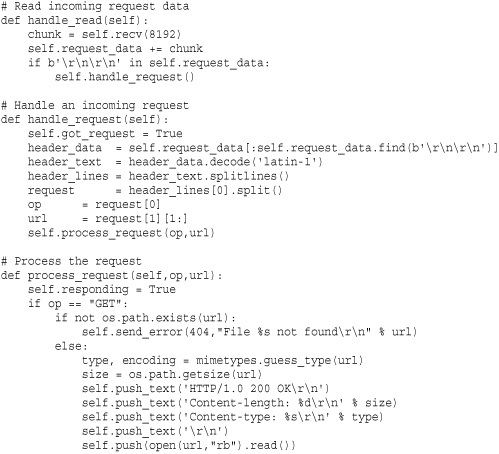

select
The select module provides access to the select() and poll() system calls. select() is typically used to implement polling or to multiplex processing across multiple input/output streams without using threads or subprocesses. On UNIX, it works for files, sockets, pipes, and most other file types. On Windows, it only works for sockets.
select(iwtd, owtd, ewtd [, timeout])
Queries the input, output, and exceptional status of a group of file descriptors. The first three arguments are lists containing either integer file descriptors or objects with a method, fileno(), that can be used to return a file descriptor. The iwtd parameter specifies objects waiting for input, owtd specifies objects waiting for output, and ewtd specifies objects waiting for an exceptional condition. Each list may be empty. timeout is a floating-point number specifying a timeout period in seconds. If timeout is omitted, the function waits until at least one file descriptor is ready. If it’s 0, the function merely performs a poll and returns immediately. The return value is a tuple of lists containing the objects that are ready. These are subsets of the first three arguments. If none of the objects is ready before the timeout occurs, three empty lists are returned. If an error occurs, a select.error exception raised. Its value is the same as that returned by IOError and OSError.
poll()
Creates a polling object that utilizes the poll() system call. This is only available on systems that support poll().
A polling object, p, returned by poll() supports the following methods:
p.register(fd [, eventmask])
Registers a new file descriptor, fd. fd is either an integer file descriptor or an object that provides the fileno() method from which the descriptor can be obtained. eventmask is the bitwise OR of the following flags, which indicate events of interest:

If eventmask is omitted, the POLLIN, POLLPRI, and POLLOUT events are checked.
p.unregister(fd)
Removes the file descriptor fd from the polling object. Raises KeyError if the file is not registered.
p.poll([timeout])
Polls for events on all the registered file descriptors. timeout is an optional timeout specified in milliseconds. Returns a list of tuples (fd, event), where fd is a file descriptor and event is a bitmask indicating events. The fields of this bitmask correspond to the constants POLLIN, POLLOUT, and so on. For example, to check for the POLLIN event, simply test the value using event & POLLIN. If an empty list is returned, it means a timeout occurred and no events occurred.
Advanced Module Features
The select() and poll() functions are the most generally portable functions defined by this module. On Linux systems, the select module also provides an interface to the edge and level trigger polling (epoll) interface which can offer significantly better performance. On BSD systems, access to kernel queue and event objects is provided. These programming interfaces are described in the online documentation for select at http://docs.python.org/library/select.
Advanced Asynchronous I/O Example
The select module is sometimes used to implement servers based on tasklets or coroutines—a technique that can be used to provide concurrent execution without threads or processes. The following advanced example illustrates this concept by implementing an I/O-based task scheduler for coroutines. Be forewarned—this is the most advanced example in the book and it will require some study for it to make sense. You might also want to consult my PyCON’09 tutorial “A Curious Course on Coroutines and Concurrency” (http://www.dabeaz.com/coroutines) for additional reference material.
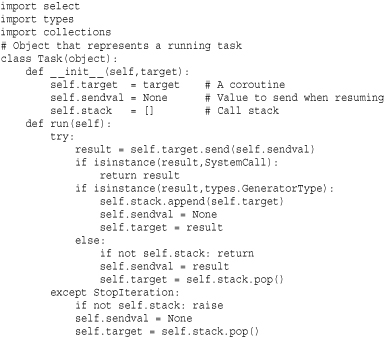


The code in this example implements a very tiny “operating system.” Here are some details concerning its operation:
• All work is carried out by coroutine functions. Recall that a coroutine uses the yield statement like a generator except that instead of iterating on it, you send it values using a send(value) method.
• The Task class represents a running task and is just a thin layer on top of a coroutine. A Task object task has only one operation, task.run(). This resumes the task and runs it until it hits the next yield statement, at which point the task suspends. When running a task, the task.sendval attribute contains the value that is to be sent into the task’s corresponding yield expression. Tasks run until they encounter the next yield statement. The value produced by this yield controls what happens next in the task:
• If the value is another coroutine (type.GeneratorType), it means that the task wants to temporarily transfer control to that coroutine. The stack attribute of Task objects represents a call-stack of coroutines that is built up when this happens. The next time the task runs, control will be transferred into this new coroutine.
• If the value is a SystemCall instance, it means that the task wants the scheduler to do something on its behalf (such as launch a new task, wait for I/O, and so on). The purpose of this object is described shortly.
• If the value is any other value, one of two things happens. If the currently executing coroutine was running as a subroutine, it is popped from the task call stack and the value saved so that it can be sent to the caller. The caller will receive this value the next time the task executes. If the coroutine is the only executing coroutine, the return value is simply discarded.
• The handling of StopIteration is to deal with coroutines that have terminated. When this happens, control is returned to the previous coroutine (if there was one) or the exception is propagated to the scheduler so that it knows that the task terminated.
• The SystemCall class represents a system call in the scheduler. When a running task wants the scheduler to carry out an operation on its behalf, it yields a SystemCall instance. This object is called a “system call” because it mimics the behavior of how programs request the services of a real multitasking operating system such as UNIX or Windows. In particular, if a program wants the services of the operating system, it yields control and provides some information back to the system so that it knows what to do. In this respect, yielding a SystemCall is similar to executing a kind of system “trap.”
• The Scheduler class represents a collection of Task objects that are being managed. At its core, the scheduler is built around a task queue (the task_queue attribute) that keeps track of tasks that are ready to run. There are four basic operations concerning the task queue. new() takes a new coroutine, wraps it with a Task object, and places it on the work queue. schedule() takes an existing Task and puts it back on the work queue. mainloop() runs the scheduler in a loop, processing tasks one by one until there are no more tasks. The readwait() and writewait() methods put a Task object into temporary staging areas where it will wait for I/O events. In this case, the Task isn’t running, but it’s not dead either—it’s just sitting around biding its time.
• The mainloop() method is the heart of the scheduler. This method first checks to see if any tasks are waiting for I/O events. If so, it arranges a call to select() in order to poll for I/O activity. If there are any events of interest, the associated tasks are placed back onto the task queue so that they can run. Next, the mainloop() method pops tasks off of the task queue and calls their run() method. If any task exits (StopIteration), it is discarded. If a task merely yields, it is just placed back onto the task queue so that it can run again. This continues until there are either no more tasks or all tasks are blocked, waiting for more I/O events. As an option, the mainloop() function accepts a count parameter that can be used to make it return after a specified number of I/O polling operations. This might be useful if the scheduler is to be integrated into another event loop.
• Perhaps the most subtle aspect of the scheduler is the handling of SystemCall instances in the mainloop() method. If a task yields a SystemCall instance, the scheduler invokes its handle() method, passing in the associated Scheduler and Task objects as parameters. The purpose of a system call is to carry out some kind of internal operation concerning tasks or the scheduler itself. The ReadWait(), WriteWait(), and NewTask() classes are examples of system calls that suspend a task for I/O or create a new task. For example, ReadWait() takes a task and invokes the readwait() method on the scheduler. The scheduler then takes the task and places it into an appropriate holding area. Again, there is a critical decoupling of objects going on here. Tasks yield SystemCall objects to request service, but do not directly interact with the scheduler. SystemCall objects, in turn, can perform operations on tasks and schedulers but are not tied to any specific scheduler or task implementation. So, in theory, you could write a completely different scheduler implementation (maybe using threads) that could just be plugged into this whole framework and it would still work.
Here is an example of a simple network time server implemented using this I/O task scheduler. It will illuminate many of the concepts described in the previous list:

In this example, two different servers are running concurrently—each listening on a different port number (use telnet to connect and test). The yield ReadWait() and yield WriteWait() statements cause the coroutine running each server to suspend until I/O is possible on the associated socket. When these statements return, the code immediately proceeds with an I/O operation such as accept() or send().
The use of ReadWait and WriteWait might look rather low-level. Fortunately, our design allows these operations to be hidden behind library functions and methods—provided that they are also coroutines. Consider the following object that wraps a socket object and mimics its interface:

Here is a reimplementation of the time server using the CoSocket class:
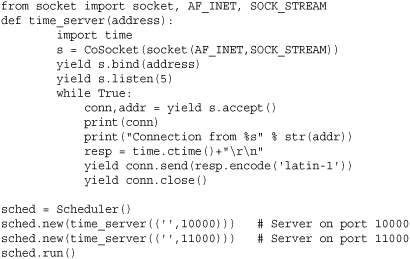
In this example, the programming interface of a CoSocket object looks a lot like a normal socket. The only difference is that every operation must be prefaced with yield (since every method is defined as a coroutine). At first, it looks crazy so you might ask what does all of this madness buy you? If you run the above server, you will find that it is able to run concurrently without using threads or subprocesses. Not only that, it has “normal” looking control flow as long as you ignore all of the yield keywords.
Here is an asynchronous web server that concurrently handles multiple client connections, but which does not use callback functions, threads, or processes. This should be compared to examples in the asynchat and asyncore modules.


Careful study of this example will yield tremendous insight into coroutines and concurrent programming techniques used by some very advanced third-party modules. However, excessive usage of these techniques might get you fired after your next code review.
When to Consider Asynchronous Networking
Use of asynchronous I/O (asyncore and asynchat), polling, and coroutines as shown in previous examples remains one of the most mysterious aspects of Python development. Yet, these techniques are used more often than you might think. An often-cited reason for using asynchronous I/O is to minimize the perceived overhead of programming with a large number of threads, especially when managing a large number of clients and in light of restrictions related to the global interpreter lock (refer to Chapter 20, “Threads and Concurrency”).
Historically, the asyncore module was one of the first library modules to support asynchronous I/O. The asynchat module followed some time later with the aim of simplifying much of the coding. However, both of these modules take the approach of processing I/O as events. For example, when an I/O event occurs, a callback function is triggered. The callback then reacts in response to the I/O event and carries out some processing. If you build a large application in this style, you will find that event handling infects almost every part of the application (e.g., I/O events trigger callbacks, which trigger more callbacks, which trigger other callbacks, ad nauseum). One of the more popular networking packages, Twisted (http://twistedmatrix.com), takes this approach and significantly builds upon it.
Coroutines are more modern but less commonly understood and used since they were only first introduced in Python 2.5. An important feature of coroutines is that you can write programs that look more like threaded programs in their overall control flow. For instance, the web server in the example does not use any callback functions and looks almost identical to what you would write if you were using threads—you just have to become comfortable with the use of the yield statement. Stackless Python (http://www.stackless.com) takes this idea even further.
As a general rule, you probably should resist the urge to use asynchronous I/O techniques for most network applications. For instance, if you need to write a server that constantly transmits data over hundreds or even thousands of simultaneous network connections, threads will tend to have superior performance. This is because the performance of select() degrades significantly as the number of connections it must monitor increases. On Linux, this penalty can be reduced using special functions such as epoll(), but this limits the portability of your code. Perhaps the main benefit of asynchronous I/O is in applications where networking needs to be integrated with other event loops (e.g., GUIs) or in applications where networking is added into code that also performs a significant amount of CPU processing. In these cases, the use of asynchronous networking may result in quicker response time.
Just to illustrate, consider the following program that carries out the task described in the song “10 million bottles of beer on the wall”:

Now, suppose you wanted to add a remote monitoring capability to this code that allows clients to connect and see how many bottles are remaining. One approach is to launch a server in its own thread and have it run alongside the main application like this:

The other approach is to write a server based on I/O polling and embed a polling operation directly into the main computation loop. Here is an example that uses the coroutine scheduler developed earlier:
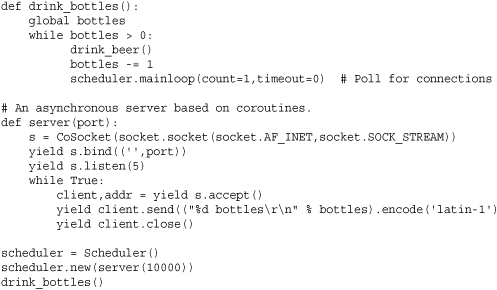
If you write a separate program that periodically connects to the bottles of beer program and measures the response time required to receive a status message, the results are surprising. On the author’s machine (a dual-core 2 GHZ MacBook), the average response time (measured over 1,000 requests) for the coroutine-based server is about 1ms versus 5ms for threads. This difference is explained by the fact that the coroutine-based code is able to respond as soon as it detects a connection whereas the threaded server doesn’t get to run until it is scheduled by the operating system. In the presence of a CPU-bound thread and the Python global interpreter lock, the server may be delayed until the CPU-bound thread exceeds its allotted time slice. On many systems, the time slice is about 10ms so the above rough measurement of thread response time is exactly the average time you might expect to wait for a CPU-bound task to be preempted by the operating system.
The downside to polling is that it introduces significant overhead if it occurs too often. For instance, even though the response time is lower in this example, the program instrumented with polling takes more than 50% longer to run to completion. If you change the code to only poll after every six-pack of beer, the response time increases slightly to 1.2ms whereas the run time of the program is only 3% greater than the program without any polling. Unfortunately, there is often no clear-cut way to know how often to poll other than to make measurements of your application.
Even though this improved response time might look like a win, there are still horrible problems associated with trying to implement your own concurrency. For example, tasks need to be especially careful when performing any kind of blocking operation. In the web server example, there is a fragment of code that opens and reads data from a file. When this operation occurs, the entire program will be frozen—potentially for a long period of time if the file access involves a disk seek. The only way to fix this would be to additionally implement asynchronous file access and add it as a feature to the scheduler. For more complicated operations such as performing a database query, figuring out how to carry out the work in an asynchronous manner becomes rather complex. One way to do it would be to carry out the work in a separate thread and to communicate the results back to the task scheduler when available—something that could be carried out with careful use of message queues. On some systems, there are low-level system calls for asynchronous I/O (such as the aio_* family of functions on UNIX). As of this writing, the Python library provides no access to those functions, although you can probably find bindings through third-party modules. In the author’s experience, using such functionality is a lot trickier than it looks and is not really worth the added complexity that gets introduced into your program—you’re often better off letting the thread library deal with such matters.
socket
The socket module provides access to the standard BSD socket interface. Although it’s based on UNIX, this module is available on all platforms. The socket interface is designed to be generic and is capable of supporting a wide variety of networking protocols (Internet, TIPC, Bluetooth, and so on). However, the most common protocol is the Internet Protocol (IP), which includes both TCP and UDP. Python supports both IPv4 and IPv6, although IPv4 is far more common.
It should be noted that this module is relatively low-level, providing direct access to the network functions provided by the operating system. If you are writing a network application, it may be easier to use the modules described in Chapter 22 or the SocketServer module described at the end of this chapter.
Address Families
Some of the socket functions require the specification of an address family. The family specifies the network protocol being used. The following constants are defined for this purpose:

Of these, AF_INET and AF_INET6 are the most commonly used because they represent standard Internet connections. AF_BLUETOOTH is only available on systems that support it (typically embedded systems). AF_NETLINK, AF_PACKET, and AF_TIPC are only supported on Linux. AF_NETLINK is used for fast interprocess communication between user applications and the Linux kernel. AF_PACKET is used for working directly at the data-link layer (e.g., raw ethernet packets). AF_TIPC is a protocol used for high-performance IPC on Linux clusters (http://tipc.sourceforge.net/).
Socket Types
Some socket functions also require the specification of a socket type. The socket type specifies the type of communications (streams or packets) to be used within a given protocol family. The following constants are used for this purpose:

The most common socket types are SOCK_STREAM and SOCK_DGRAM because they correspond to TCP and UDP in the Internet Protocol suite. SOCK_RDM is a reliable form of UDP that guarantees the delivery of a datagram but doesn’t preserve ordering (datagrams might be received in a different order than sent). SOCK_SEQPACKET is used to send packets through a stream-oriented connection in a manner that preserves their order and packet boundaries. Neither SOCK_RDM or SOCK_SEQPACKET are widely supported, so it’s best not to use them if you care about portability. SOCK_RAW is used to provide low-level access to the raw protocol and is used if you want to carry out special-purpose operations such as sending control messages (e.g., ICMP messages). Use of SOCK_RAW is usually restricted to programs running with superuser or administrator access.
Not every socket type is supported by every protocol family. For example, if you’re using AF_PACKET to sniff ethernet packets on Linux, you can’t establish a stream-oriented connection using SOCK_STREAM. Instead, you have to use SOCK_DGRAM or SOCK_RAW. For AF_NETLINK sockets, SOCK_RAW is the only supported type.
Addressing
In order to perform any communication on a socket, you have to specify a destination address. The form of the address depends on the address family of the socket.
AF_INET (IPv4)
For Internet applications using IPv4, addresses are specified as a tuple (host, port). Here are two examples:
![]()
If host is the empty string, it has the same meaning as INADDR_ANY, which means any address. This is typically used by servers when creating sockets that any client can connect to. If host is set to '<broadcast>', it has the same meaning as the INADDR_BROADCAST constant in the socket API.
Be aware that when host names such as 'www.python.org' are used, Python uses DNS to resolve the host name into an IP address. Depending on how DNS has been configured, you may get a different IP address each time. Use a raw IP address such as '66.113.130.182' to avoid this behavior, if needed.
AF_INET6 (IPv6)
For IPv6, addresses are specified as a 4-tuple (host, port, flowinfo, scopeid). With IPv6, the host and port components work in the same way as IPv4, except that the numerical form of an IPv6 host address is typically specified by a string of eight colon-separated hexadecimal numbers, such as 'FEDC:BA98:7654:3210:FEDC:BA98:7654:3210' or '080A::4:1' (in this case, the double colon fills in a range of address components with 0s).
The flowinfo parameter is a 32-bit number consisting of a 24-bit flow label (the low 24 bits), a 4-bit priority (the next 4 bits), and four reserved bits (the high 4 bits). A flow label is typically only used when a sender wants to enable special handling by routers. Otherwise, flowinfo is set to 0.
The scopeid parameter is a 32-bit number that’s only needed when working with link-local and site-local addresses. A link-local address always starts with the prefix 'FE80:...' and is used between machines on the same LAN (routers will not forward link-local packets). In this case, scopeid an interface index that identifies a specific network interface on the host. This information can be viewed using a command such as 'ifconfig' on UNIX or 'ipv6 if' on Windows. A site-local address always starts with the prefix 'FEC0:...' and is used between machines within the same site (for example, all machines on a given subnet). In this case, scopeid is a site-identifier number.
If no data is given for flowinfo or scopeid, an IPv6 address can be given as the tuple (host, port), as with IPv4.
AF_UNIX
For UNIX domain sockets, the address is a string containing a path name—for example, '/tmp/myserver'.
AF_PACKET
For the Linux packet protocol, the address is a tuple (device, protonum [, pkttype [, hatype [, addr]]]) where device is a string specifying the device name such as "eth0" and protonum is an integer specifying the ethernet protocol number as defined in the <linux/if_ether.h> header file (e.g., 0x0800 for an IP packet). packet_type is an integer specifying the packet type and is one of the following constants:

hatype is an integer specifying the hardware address type as used in the ARP protocol and defined in the <linux/if_arp.h> header file. addr is a byte string containing a hardware address, the structure of which depends on the value of hatype. For ethernet, addr will be a 6-byte string holding the hardware address.
AF_NETLINK
For the Linux Netlink protocol, the address is a tuple (pid, groups) where pid and groups are both unsigned integers. pid is the unicast address of the socket and is usually the same as the process ID of the process that created the socket or 0 for the kernel. groups is a bit mask used to specify multicast groups to join. Refer to the Netlink documentation for more information.
AF_BLUETOOTH
Bluetooth addresses depend on the protocol being used. For L2CAP, the address is a tuple (addr, psm) where addr is a string such as '01:23:45:67:89:ab' and psm is an unsigned integer. For RFCOMM, the address is a tuple (addr, channel) where addr is an address string and channel is an integer. For HCI, the address is a 1-tuple (deviceno,) where deviceno is an integer device number. For SCO, the address is a string host.
The constant BDADDR_ANY represents any address and is a string '00:00:00:00:00:00'. The constant BDADDR_LOCAL is a string '00:00:00:ff:ff:ff'.
AF_TIPC
For TIPC sockets, the address is a tuple (addr_type, v1, v2, v3 [, scope]) where all fields are unsigned integers. addr_type is one of the following values, which also determines the values of v1, v2, and v3:

The optional scope field is one of TIPC_ZONE_SCOPE, TIPC_CLUSTER_SCOPE, or TIPC_NODE_SCOPE.
Functions
The socket module defines the following functions:
create_connection(address [, timeout])
Establishes a SOCK_STREAM connection to address and returns an already connected socket object. address is tuple of the form (host, port), and timeout specifies an optional timeout. This function works by first calling getaddrinfo() and then trying to connect to each of the tuples that gets returned.
fromfd(fd, family, socktype [, proto])
Creates a socket object from an integer file descriptor, fd. The address family, socket type, and protocol number are the same as for socket(). The file descriptor must refer to a previously created socket. It returns an instance of SocketType.
getaddrinfo(host, port [,family [, socktype [, proto [, flags]]]])
Given host and port information about a host, this function returns a list of tuples containing information needed to open up a socket connection. host is a string containing a host name or numerical IP address. port is a number or a string representing a service name (for example, "http", "ftp", "smtp"). Each returned tuple consists of five elements (family, socktype, proto, canonname, sockaddr). The family, socktype, and proto items have the same values as would be passed to the socket() function. canonname is a string representing the canonical name of the host. sockaddr is a tuple containing a socket address as described in the earlier section on Internet addresses. Here’s an example:
![]()
In this example, getaddrinfo() has returned information about two possible socket connections. The first one (proto=17) is a UDP connection, and the second one (proto=6) is a TCP connection. The additional parameters to getaddrinfo() can be used to narrow the selection. For instance, this example returns information about establishing an IPv4 TCP connection:
![]()
The special constant AF_UNSPEC can be used for the address family to look for any kind of connection. For example, this code gets information about any TCP-like connection and may return information for either IPv4 or IPv6:
![]()
getaddrinfo() is intended for a very generic purpose and is applicable to all supported network protocols (IPv4, IPv6, and so on). Use it if you are concerned about compatibility and supporting future protocols, especially if you intend to support IPv6.
getdefaulttimeout()
Returns the default socket timeout in seconds. A value of None indicates that no timeout has been set.
getfqdn([name])
Returns the fully qualified domain name of name. If name is omitted, the local machine is assumed. For example, getfqdn("foo") might return "foo.quasievil.org".
gethostbyname(hostname)
Translates a host name such as 'www.python.org' to an IPv4 address. The IP address is returned as a string, such as '132.151.1.90'. It does not support IPv6.
gethostbyname_ex(hostname)
Translates a host name to an IPv4 address but returns a tuple (hostname, aliaslist, ipaddrlist) in which hostname is the primary host name, aliaslist is a list of alternative host names for the same address, and ipaddrlist is a list of IPv4 addresses for the same interface on the same host. For example, gethostbyname_ex('www.python.org') returns something like ('fang.python.org', ['www.python.org'], ['194.109.137.226']). This function does not support IPv6.
gethostname()
Returns the host name of the local machine.
gethostbyaddr(ip_address)
Returns the same information as gethostbyname_ex(), given an IP address such as '132.151.1.90'. If ip_address is an IPv6 address such as 'FEDC:BA98:7654:3210:FEDC:BA98:7654:3210', information regarding IPv6 will be returned.
getnameinfo(address, flags)
Given a socket address, address, this function translates the address into a 2-tuple (host, port), depending on the value of flags. The address parameter is a tuple specifying an address—for example, ('www.python.org',80). flags is the bitwise OR of the following constants:

The main purpose of this function is to get additional information about an address. Here’s an example:

getprotobyname(protocolname)
Translates an Internet protocol name (such as 'icmp') to a protocol number (such as the value of IPPROTO_ICMP) that can be passed to the third argument of the socket() function. Raises socket.error if the protocol name isn’t recognized. Normally, this is only used with raw sockets.
getservbyname(servicename [, protocolname])
Translates an Internet service name and protocol name to a port number for that service. For example, getservbyname('ftp', 'tcp') returns 21. The protocol name, if supplied, should be 'tcp' or 'udp’. Raises socket.error if servicename doesn’t match any known service.
getservbyport(port [, protocolname])
This is the opposite of getservbyname(). Given a numeric port number, port, this function returns a string giving the service name, if any. For example, getservbyport(21, 'tcp') returns 'ftp'. The protocol name, if supplied, should be 'tcp' or 'udp'. Raises socket.error if no service name is available for port.
has_ipv6
Boolean constant that is True if IPv6 support is available.
htonl(x)
Converts 32-bit integers from host to network byte order (big-endian).
htons(x)
Converts 16-bit integers from host to network byte order (big-endian).
inet_aton(ip_string)
Converts an IPv4 address provided as a string (for example, '135.128.11.209') to a 32-bit packed binary format for use as the raw-encoding of the address. The returned value is a four-character string containing the binary encoding. This may be useful if passing the address to C or if the address must be packed into a data structure passed to other programs. Does not support IPv6.
inet_ntoa(packedip)
Converts a binary-packaged IPv4 address into a string that uses the standard dotted representation (for example, '135.128.11.209'). packedip is a four-character string containing the raw 32-bit encoding of an IP address. The function may be useful if an address has been received from C or is being unpacked from a data structure. It does not support IPv6.
inet_ntop(address_family, packed_ip)
Converts a packed binary string packed_ip representing an IP network address into a string such as '123.45.67.89'. address_family is the address family and is usually AF_INET or AF_INET6. This can be used to obtain a network address string from a buffer of raw bytes (for instance, from the contents of a low-level network packet).
inet_pton(address_family, ip_string)
Converts an IP address such as '123.45.67.89' into a packed byte string. address_family is the address family and is usually AF_INET or AF_INET6. This can be used if you’re trying to encode a network address into a raw binary data packet.
ntohl(x)
Converts 32-bit integers from network (big-endian) to host byte order.
ntohs(x)
Converts 16-bit integers from network (big-endian) to host byte order.
setdefaulttimeout(timeout)
Sets the default timeout for newly created socket objects. timeout is a floating-point number specified in seconds. A value of None may be supplied to indicate no timeout (this is the default).
socket(family, type [, proto])
Creates a new socket using the given address family, socket type, and protocol number. family is the address family and type is the socket type as discussed in the first part of this section. To open a TCP connection, use socket(AF_INET, SOCK_STREAM). To open a UDP connection, use socket(AF_INET, SOCK_DGRAM). The function returns an instance of SocketType (described shortly).
The protocol number is usually omitted (and defaults to 0). This is typically only used with raw sockets (SOCK_RAW) and is set to a constant that depends on the address family being used. The following list shows all of the protocol numbers that Python may define for AF_INET and AF_INET6, depending on their availability on the host system:

The following protocol numbers are used with AF_BLUETOOTH:

socketpair([family [, type [, proto ]]])
Creates a pair of connected socket objects using the given family, type, and proto options, which have the same meaning as for the socket() function. This function only applies to UNIX domain sockets (family=AF_UNIX). type may be either SOCK_DGRAM or SOCK_STREAM. If type is SOCK_STREAM, an object known as a stream pipe is created. proto is usually 0 (the default). The primary use of this function would be to set up interprocess communication between processes created by os.fork(). For example, the parent process would call socketpair() to create a pair of sockets and call os.fork(). The parent and child processes would then communicate with each other using these sockets.
Sockets are represented by an instance of type SocketType. The following methods are available on a socket, s:
s.accept()
Accepts a connection and returns a pair (conn, address), where conn is a new socket object that can be used to send and receive data on the connection and address is the address of the socket on the other end of the connection.
s.bind(address)
Binds the socket to an address. The format of address depends on the address family. In most cases, it’s a tuple of the form (hostname, port). For IP addresses, the empty string represents INADDR_ANY and the string '<broadcast>' represents INADDR_BROADCAST. The INADDR_ANY host name (the empty string) is used to indicate that the server allows connections on any Internet interface on the system. This is often used when a server is multihomed. The INADDR_BROADCAST host name ('<broadcast>') is used when a socket is being used to send a broadcast message.
s.close()
Closes the socket. Sockets are also closed when they’re garbage-collected.
s.connect(address)
Connects to a remote socket at address. The format of address depends on the address family, but it’s normally a tuple (hostname, port). It raises socket.error if an error occurs. If you’re connecting to a server on the same computer, you can use the name 'localhost' as hostname.
s.connect_ex(address)
Like connect(address), but returns 0 on success or the value of errno on failure.
s.fileno()
Returns the socket’s file descriptor.
s.getpeername()
Returns the remote address to which the socket is connected. Usually the return value is a tuple (ipaddr, port), but this depends on the address family being used. This is not supported on all systems.
s.getsockname()
Returns the socket’s own address. Usually this is a tuple (ipaddr, port).
s.getsockopt(level, optname [, buflen])
Returns the value of a socket option. level defines the level of the option and is SOL_SOCKET for socket-level options or a protocol number such as IPPROTO_IP for protocol-related options. optname selects a specific option. If buflen is omitted, an integer option is assumed and its integer value is returned. If buflen is given, it specifies the maximum length of the buffer used to receive the option. This buffer is returned as a byte string, where it’s up to the caller to decode its contents using the struct module or other means.
The following tables list the socket options defined by Python. Most of these options are considered part of the Advanced Sockets API and control low-level details of the network. You will need to consult other documentation to find more detailed descriptions. When type names are listed in the value column, that name is same as the standard C data structure associated with the value and used in the standard socket programming interface. Not all options are available on all machines.
The following are commonly used option names for level SOL_SOCKET:

The following options are available for level IPPROTO_IP:

The following options are available for level IPPROTO_IPV6:



The following options are available for level SOL_TCP:

s.gettimeout()
Returns the current timeout value if any. Returns a floating-point number in seconds or None if no timeout is set.
s.ioctl(control, option)
Provides limited access to the WSAIoctl interface on Windows. The only supported value for control is SIO_RCVALL which is used to capture all received IP packets on the network. This requires Administrator access. The following values can be used for options:

Starts listening for incoming connections. backlog specifies the maximum number of pending connections the operating system should queue before connections are refused. The value should be at least 1, with 5 being sufficient for most applications.
s.makefile([mode [, bufsize]])
Creates a file object associated with the socket. mode and bufsize have the same meaning as with the built-in open() function. The file object uses a duplicated version of the socket file descriptor, created using os.dup(), so the file object and socket object can be closed or garbage-collected independently. The socket s should not have a timeout and should not be configured in nonblocking mode.
s.recv(bufsize [, flags])
Receives data from the socket. The data is returned as a string. The maximum amount of data to be received is specified by bufsize. flags provides additional information about the message and is usually omitted (in which case it defaults to zero). If used, it’s usually set to one of the following constants (system-dependent):

s.recv_into(buffer [, nbytes [, flags]])
The same as recv() except that data is written into a an object buffer supporting the buffer interface. nbytes is the maximum number of bytes to receive. If omitted, the maximum size is taken from the buffer size. flags has the same meaning as for recv().
s.recvfrom(bufsize [, flags])
Like the recv() method except that the return value is a pair (data, address) in which data is a string containing the data received and address is the address of the socket sending the data. The optional flags argument has the same meaning as for recv(). This function is primarily used in conjunction with the UDP protocol.
s.recvfrom_info(buffer [, nbytes [, flags]])
The same as recvfrom() but the received data is stored in the buffer object buffer. nbytes specifies the maximum number of bytes of receive. If omitted, the maximum size is taken from the size of buffer. flags has the same meaning as for recv().
Sends data in string to a connected socket. The optional flags argument has the same meaning as for recv(), described earlier. Returns the number of bytes sent, which may be fewer than the number of bytes in string. Raises an exception if an error occurs.
s.sendall(string [, flags])
Sends data in string to a connected socket, except that an attempt is made to send all of the data before returning. Returns None on success; raises an exception on failure. flags has the same meaning as for send().
s.sendto(string [, flags], address)
Sends data to the socket. flags has the same meaning as for recv(). address is a tuple of the form (host, port), which specifies the remote address. The socket should not already be connected. Returns the number of bytes sent. This function is primarily used in conjunction with the UDP protocol.
s.setblocking(flag)
If flag is zero, the socket is set to nonblocking mode. Otherwise, the socket is set to blocking mode (the default). In nonblocking mode, if a recv() call doesn’t find any data or if a send() call cannot immediately send the data, the socket.error exception is raised. In blocking mode, these calls block until they can proceed.
s.setsockopt(level, optname, value)
Sets the value of the given socket option. level and optname have the same meaning as for getsockopt(). The value can be an integer or a string representing the contents of a buffer. In the latter case, it’s up to the caller to ensure that the string contains the proper data. See getsockopt() for socket option names, values, and descriptions.
s.settimeout(timeout)
Sets a timeout on socket operations. timeout is a floating-point number in seconds. A value of None means no timeout. If a timeout occurs, a socket.timeout exception is raised. As a general rule, timeouts should be set as soon as a socket is created because they can be applied to operations involved in establishing a connection (such as connect()).
s.shutdown(how)
Shuts down one or both halves of the connection. If how is 0, further receives are disallowed. If how is 1, further sends are disallowed. If how is 2, further sends and receives are disallowed.
In addition to these methods, a socket instance s also has the following read-only properties which correspond to the arguments passed to the socket() function.

Exceptions
The following exceptions are defined by the socket module.
error
This exception is raised for socket- or address-related errors. It returns a pair (errno, mesg) with the error returned by the underlying system call. Inherits from IOError.
herror
Error raised for address-related errors. Returns a tuple (herrno, hmesg) containing an error number and error message. Inherits from error.
gaierror
Error raised for address-related errors in the getaddrinfo() and getnameinfo() functions. The error value is a tuple (errno, mesg), where errno is an error number and mesg is a string containing a message. errno is set to one of the following constants defined in the socket module:

timeout
Exception raised when a socket operation times out. This only occurs if a timeout has been set using the setdefaulttimeout() function or settimeout() method of a socket object. Exception value is a string, 'timeout'. Inherits from error.
Example
A simple example of a TCP connection is shown in the introduction to this chapter. The following example illustrates a simple UDP echo server:

Here a client that sends messages to the previous server:

Notes
• Not all constants and socket options are available on all platforms. If portability is your goal, you should only rely upon options that are documented in major sources such as the W. Richard Stevens UNIX Network Programming book cited at the beginning of this section.
• Notable omissions from the socket module are recvmsg() and sendmsg() system calls, commonly used to work with ancillary data and advanced network options related to packet headers, routing, and other details. For this functionality, you must install a third-party module such as PyXAPI (http://pypi.python.org/pypi/PyXAPI).
• There is a subtle difference between nonblocking socket operations and operations involving a timeout. When a socket function is used in nonblocking mode, it will return immediately with an error if the operation would have blocked. When a timeout is set, a function returns an error only if the operation doesn’t complete within a specified timeout.
ssl
The ssl module is used to wrap socket objects with the Secure Sockets Layer (SSL), which provides data encryption and peer authentication. Python uses the OpenSSL library (http://www.openssl.org) to implement this module. A full discussion concerning the theory and operation of SSL is beyond the scope of what can be covered here. So, just the essential elements of using this module are covered here with the assumption that you know what you’re doing when it comes to SSL configuration, keys, certificates, and other related matters:
wrap_socket(sock [, **opts])
Wraps an existing socket sock (created by the socket module) with SSL support and returns an instance of SSLSocket. This function should be used before subsequent connect() or accept() operations are made. opts represents a number of keyword arguments that are used to specify additional configuration data.

An instance s of SSLSocket inherits from socket.socket and additionally supports the following operations:
s.cipher()
Returns a tuple (name, version, secretbits) where name is the cipher name being used, version is the SSL protocol, and secretbits is the number of secret bits being used.
s.do_handshake()
Performs the SSL handshake. Normally this is done automatically unless the do_handshake_on_connect option was set to False in the wrap_socket() function. If the underlying socket s is nonblocking, an SSLError exception will be raised if the operation couldn’t be completed. The e.args[0] attribute of an SSLError exception e will have the value SSL_ERROR_WANT_READ or SSL_ERROR_WANT_WRITE depending on the operation that needs to be performed. To continue the handshake process once reading or writing can continue, simply call s.do_handshake() again.
Returns the certificate from the other end of the connection, if any. If there is no certificate None is returned. If there was a certificate but it wasn’t validated, an empty dictionary is returned. If a validated certificate is received, a dictionary with the keys 'subject' and 'notAfter' is returned. If binary_form is set True, the certificate is returned as a DER-encoded byte sequence.
s.read([nbytes])
Reads up to nbytes of data and returns it. If nbytes is omitted, up to 1,024 bytes are returned.
s.write(data)
Writes the byte string data. Returns the number of bytes written.
s.unwrap()
Shuts down the SSL connection and returns the underlying socket object on which further unencrypted communication can be carried out.
The following utility functions are also defined by the module:
cert_time_to_seconds(timestring)
Converts a string timestring from the format used in certificates to a floating-point number as compatible with the time.time() function.
DER_cert_to_PEM_cert(derbytes)
Given a byte string derbytes containing a DER-encoded certificate, returns a PEM-encoded string version of the certificate.
PEM_cert_to_DER_cert(pemstring)
Given a string pemstring containing a PEM-encoded string version of a certificate, returns a DER-encoded byte string version of the certificate.
get_server_certificate(addr [, ssl_version [, ca_certs]])
Retrieves the certificate of an SSL server and returns it as a PEM-encoded string. addr is an address of the form (hostname, port). ssl_version is the SSL version number, and ca_certs is the name of a file containing certificate authority certificates as described for the wrap_socket() function.
RAND_status()
Returns True or False if the SSL layer thinks that the pseudorandom number generator has been seeded with enough randomness.
RAND_egd(path)
Reads 256 bytes of randomness from an entropy-gathering daemon and adds it to the pseudorandom number generator. path is the name of a UNIX-domain socket for the daemon.
RAND_add(bytes, entropy)
Adds the bytes in byte string bytes into the pseudorandom number generator. entropy is a nonnegative floating-point number giving the lower bound on the entropy.
Examples
The following example shows how to use this module to open an SSL-client connection:
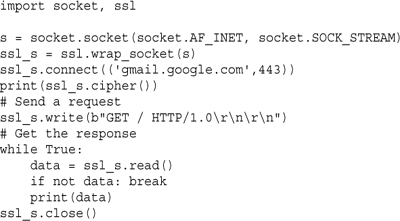
Here is an example of an SSL-secured time server:
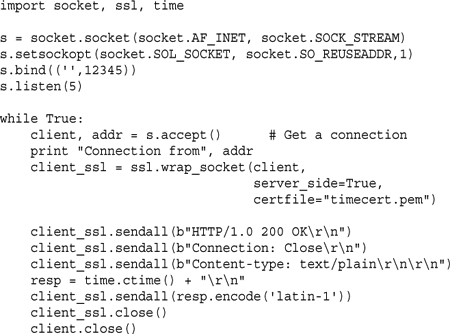
In order to run this server, you will need to have a signed server certificate in the file timecert.pem. For the purposes of testing, you can create one using this UNIX command:
% openssl req –new –x509 –days 30 –nodes –out timecert.pem –keyout timecert.pem
To test this server, try connecting with a browser using a URL such as 'https://localhost:1234'. If it works, the browser will issue a warning message about you using a self-signed certificate. If you agree, you should see the output of the server.
SocketServer
This module is called socketserver in Python 3. The SocketServer module provides classes that simplify the implementation of TCP, UDP, and UNIX domain socket servers.
Handlers
To use the module, you define a handler class that inherits from the base class BaseRequestHandler. An instance h of BaseRequestHandler implements one or more of the following methods:
h.finish()
Called to perform cleanup actions after the handle() method has completed. By default, it does nothing. It’s not called if either the setup() or handle() method generates an exception.
h.handle()
This method is called to perform the actual work of a request. It’s called with no arguments, but several instance variables contain useful values. h.request contains the request, h.client_address contains the client address, and h.server contains an instance of the server that called the handler. For stream services such as TCP, the h.request attribute is a socket object. For datagram services, it’s a byte string containing the received data.
h.setup()
This method is called before the handle() method to perform initialization actions. By default, it does nothing. If you wanted a server to implement further connection setup such as establishing a SSL connection, you could implement it here.
Here is an example of a handler class that implements a simple time server that operates with streams or datagrams:

If you know that a handler is only going to operate on stream-oriented connections such as TCP, have it inherit from StreamRequestHandler instead of BaseRequestHandler. This class sets two attributes: h.wfile is a file-like object that writes data to the client, and h.rfile is a file-like object that reads data from the client. Here is an example:

If you are writing a handler that only operates with packets and always sends a response back to the sender, have it inherit from DatagramRequestHandler instead of BaseRequestHandler. It provides the same file-like interface as StreamRequestHandler. For example:

In this case, all of the data written to self.wfile is collected into a single packet that is returned after the handle() method returns.
Servers
To use a handler, it has to be plugged into a server object. There are four basic server classes defined:
TCPServer(address, handler)
A server supporting the TCP protocol using IPv4. address is a tuple of the form (host, port). handler is an instance of a subclass of the BaseRequestHandler class described later.
UDPServer(address, handler)
A server supporting the Internet UDP protocol using IPv4. address and handler are the same as for TCPServer().
UnixStreamServer(address, handler)
A server implementing a stream-oriented protocol using UNIX domain sockets. Inherits from TCPServer.
UnixDatagramServer(address, handler)
A server implementing a datagram protocol using UNIX domain sockets. This inherits from UDPServer.
Instances of all four server classes have the following basic methods:
s.fileno()
Returns the integer file descriptor for the server socket. The presence of this method makes it legal to use server instances with polling operations such as the select() function.
s.serve_forever()
Handles an infinite number of requests.
Stops the serve_forever() loop.
The following attributes give some basic information about the configuration of a running server:
s.RequestHandlerClass
The user-provided request handler class that was passed to the server constructor.
s.server_address
The address on which the server is listening, such as the tuple ('127.0.0.1', 80).
s.socket
The socket object being used for incoming requests.
Here is an example of running the TimeHandler as a TCP server:

Here is an example of running the handler as a UDP server:

A key aspect of the SocketServer module is that handlers are decoupled from servers. That is, once you have written a handler, you can plug it into many different kinds of servers without having to change its implementation.
Defining Customized Servers
Servers often need special configuration to account for different network address families, timeouts, concurrency, and other features. This customization is carried out by inheriting from one of the four basic servers described in the previous section. The following class attributes can be defined to customize basic settings of the underlying network socket:
Server.address_family
The address family used by the server socket. The default value is socket.AF_INET. Use socket.AF_INET6 if you want to use IPv6.
Server.allow_reuse_address
A Boolean flag that indicates whether or not a socket should reuse an address. This is useful when you want to immediately restart a server on the same port after a program has terminated (otherwise, you have to wait a few minutes). The default value is False.
Server.request_queue_size
The size of the request queue that’s passed to the socket’s listen() method. The default value is 5.
The socket type used by the server, such as socket.SOCK_STREAM or socket.SOCK_DGRAM.
Server.timeout
Timeout period in seconds that the server waits for a new request. On timeout, the server calls the handle_timeout() method (described below) and goes back to waiting. This timeout is not used to set a socket timeout. However, if a socket timeout has been set, its value is used instead of this value.
Here is an example of how to create a server that allows the port number to be reused:

If desired, the following methods are most useful to extend in classes that inherit from one of the servers. If you define any of these methods in your own server, make sure you call the same method in the superclass.
Server.activate()
Method that carries out the listen() operation on the server. The server socket is referenced as self.socket.
Server.bind()
Method that carries out the bind() operation on the server.
Server.handle_error(request, client_address)
Method that handles uncaught exceptions that occur in handling. To get information about the last exception, use sys.exc_info() or functions in the traceback module.
Server.handle_timeout()
Method that is called when the server timeout occurs. By redefining this method and adjusting the timeout setting, you can integrate other processing into the server event loop.
Server.verify_request(request, client_address)
Redefine this method if you want to verify the connection before any further processing. This is what you define if you wanted to implement a firewall or perform some other kind of a validation.
Finally, addition server features are available through the use of mixin classes. This is how concurrency via threads or processing forking is added. The following classes are defined for this purpose:
ForkingMixIn
A mixin class that adds UNIX process forking to a server, allowing it to serve multiple clients. The class variable max_children controls the maximum number of child processes, and the timeout variable determines how much time elapses between attempts to collect zombie processes. An instance variable active_children keeps track of how many active processes are running.
ThreadingMixIn
A mixin class that modifies a server so that it can serve multiple clients with threads. There is no limit placed on the number of threads that can be created. By default, threads are non-daemonic unless the class variable daemon_threads is set to True.
To add these features to a server, you use multiple inheritance where the mixin class is listed first. For example, here is a forking time server:
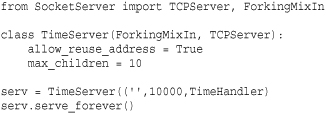
Since concurrent servers are relatively common, the SocketServer predefines the following server classes for this purpose.
• ForkingUDPServer(address, handler)
• ForkingTCPServer(address, handler)
• ThreadingUDPServer(address, handler)
• ThreadingTCPServer(address, handler)
These classes are actually just defined in terms of the mixins and server classes. For example, here is the definition of ForkingTCPServer:
class ForkingTCPServer(ForkingMixIn, TCPServer): pass
Customization of Application Servers
Other library modules often use the SocketServer class to implement servers for application-level protocols such as HTTP and XML-RPC. Those servers can also be customized via inheritance and extending the methods defined for basic server operation. For example, here is a forking XML-RPC server that only accepts connections originating on the loopback interface:
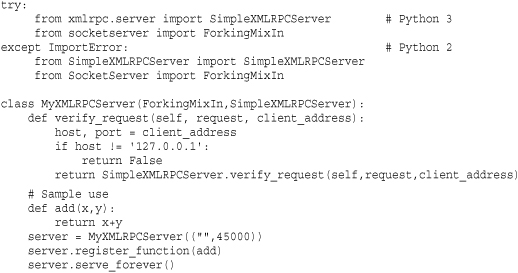
To test this, you will need to use the xmlrpclib module. Run the previous server and then start a separate Python process:

To test the rejection of connections, try the same code, but from a different machine on the network. For this, you will need to replace “localhost” with the hostname of the machine that’s running the server.