
19. Operating System Services
The modules in this chapter provide access to a wide variety of operating system services with an emphasis on low-level I/O, process management, and the operating environment. Modules that are commonly used in conjunction with writing systems programs are also included—for example, modules to read configuration files, write log files, and so forth. Chapter 18, “File and Directory Handling,” covers high-level modules related to file and filesystem manipulation—the material presented here tends be at a lower level than that.
Most of Python’s operating system modules are based on POSIX interfaces. POSIX is a standard that defines a core set of operating system interfaces. Most UNIX systems support POSIX, and other platforms such as Windows support large portions of the interface. Throughout this chapter, functions and modules that only apply to a specific platform are noted as such. UNIX systems include both Linux and Mac OS X. Windows systems include all versions of Windows unless otherwise noted.
Readers may want to supplement the material presented here with additional references. The C Programming Language, Second Edition by Brian W. Kernighan and Dennis M. Ritchie (Prentice Hall, 1989) provides a good overview of files, file descriptors, and the low-level interfaces on which many of the modules in this section are based. More advanced readers may want to consult a book such as Advanced Programming in the UNIX Environment, 2nd Edition by W. Richard Stevens and Stephen Rago (Addison Wesley, 2005). For an overview of general concepts, you may want to locate a college textbook on operating systems. However, given the high cost and limited day-to-day practical utility of these books, you’re probably better off asking a nearby computer science student to loan you their copy for a weekend.
commands
The commands module is used to execute simple system commands specified as a string and return their output as a string. It only works on UNIX systems. The functionality provided by this module is somewhat similar to using backquotes (`) in a UNIX shell script. For example, typing x = commands.getoutput('ls –l') is similar to saying x=`ls –l`.
getoutput(cmd)
Executes cmd in a shell and returns a string containing both the standard output and standard error streams of the command.
Like getoutput(), except that a 2-tuple (status, output) is returned, where status is the exit code, as returned by the os.wait() function, and output is the string returned by getoutput().
Notes
• This module is only available in Python 2. In Python 3, both of the previous functions are found in the subprocess module.
• Although this module can be used for simple shell operations, you are almost always better off using the subprocess module for launching subprocesses and collecting their output.
See Also:
subprocess (p. 402)
ConfigParser, configparser
The ConfigParser module (called configparser in Python 3) is used to read .ini format configuration files based on the Windows INI format. These files consist of named sections, each with its own variable assignments such as the following:

The ConfigParser Class
The following class is used to manage configuration variables:
ConfigParser([defaults [, dict_type]])
Creates a new ConfigParser instance. defaults is an optional dictionary of values that can be referenced in configuration variables by including string format specifiers such as '%(key)s’ where key is a key of defaults. dict_type specifies the type of dictionary that is used internally for storing configuration variables. By default, it is dict (the built-in dictionary).
An instance c of ConfigParser has the following operations:
c.add_section(section)
Adds a new section to the stored configuration parameters. section is a string with the section name.
Returns the dictionary of default values.
c.get(section, option [, raw [, vars]])
Returns the value of option option from section section as a string. By default, the returned string is processed through an interpolation step where format strings such as '%(option)s' are expanded. In this case, option may the name of another configuration option in the same section or one of the default values supplied in the defaults parameter to ConfigParser. raw is a Boolean flag that disables this interpolation feature, returning the option unmodified. vars is an optional dictionary containing more values for use in '%' expansions.
c.getboolean(section, option)
Returns the value of option from section section converted to Boolean value. Values such as "0", "true", "yes", "no", "on", and "off" are all understood and checked in a case-insensitive manner. Variable interpolation is always performed by this method (see c.get()).
c.getfloat(section, option)
Returns the value of option from section section converted to a float with variable interpolation.
c.getint(section, option)
Returns the value of option from section section converted to an integer with variable interpolation.
c.has_option(section, option)
Returns True if section section has an option named option.
c.has_section(section)
Returns True if there is a section named section.
c.items(section [, raw [, vars]])
Returns a list of (option, value) pairs from section section. raw is a Boolean flag that disables the interpolation feature if set to True. vars is a dictionary of additional values that can be used in '%’ expansions.
c.options(section)
Returns a list of all options in section section.
c.optionxform(option)
Transforms the option name option to the string that’s used to refer to the option. By default, this is a lowercase conversion.
c.read(filenames)
Reads configuration options from a list of filenames and stores them. filenames is either a single string, in which case that is the filename that is read, or a list of filenames. If any of the given filenames can’t be found, they are ignored. This is useful if you want to read configuration files from many possible locations, but where such files may or may not be defined. A list of the successfully parsed filenames is returned.
Reads configuration options from a file-like object that has already been opened in fp. filename specifies the filename associated with fp (if any). By default, the filename is taken from fp.name or is set to '<???>' if no such attribute is defined.
c.remove_option(section, option)
Removes option from section section.
c.remove_section(section)
Removes section section.
c.sections()
Returns a list of all section names.
c.set(section, option, value)
Sets a configuration option option to value in section section. value should be a string.
c.write(file)
Writes all of the currently held configuration data to file. file is a file-like object that has already been opened.
Example
The ConfigParser module is often overlooked, but it is an extremely useful tool for controlling programs that have an extremely complicated user configuration or runtime environment. For example, if you’re writing a component that has to run inside of a large framework, a configuration file is often an elegant way to supply runtime parameters. Similarly, a configuration file may be a more elegant approach than having a program read large numbers of command-line options using the optparse module. There are also subtle, but important, differences between using configuration files and simply reading configuration data from a Python source script.
The following few examples illustrate some of the more interesting features of the ConfigParser module. First, consider a sample .ini file:
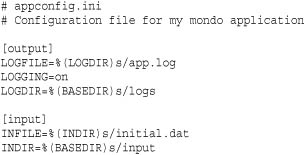
The following code illustrates how you read a configuration file and supply default values to some of the variables:

After you have read a configuration file, you use the get() method to retrieve option values. For example:

Here, you immediately see some interesting features. First, configuration parameters are case insensitive. Thus, if your program is reading a parameter 'logfile', it does not matter if the configuration file uses 'logfile', 'LOGFILE', or 'LogFile'. Second, configuration parameters can include variable substitutions such as '%(BASEDIR)s' and '%(LOGDIR)s' as seen in the file. These substitutions are also case insensitive. Moreover, the definition order of configuration parameters does not matter in these substitutions. For example, in appconfig.ini, the LOGFILE parameter makes a reference to the LOGDIR parameter, which is defined later in the file. Finally, values in configuration files are often interpreted correctly even if they don’t exactly match Python syntax or datatypes. For example, the 'on' value of the LOGGING parameter is interpreted as True by the cfg.getboolean() method.
Configuration files also have the ability to be merged together. For example, suppose the user had their own configuration file with custom settings:
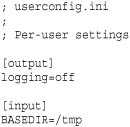
You can merge the contents of this file in with already loaded configuration parameters. For example:

Here, you will notice that the newly loaded configuration selectively replaces the parameters that were already defined. Moreover, if you change one of the configuration parameters that’s used in variable substitutions of other configuration parameters, the changes correctly propagate. For example, the new setting of BASEDIR in the input section affects previously defined configuration parameters in that section such as INFILE. This behavior is an important but subtle difference between using a config file and simply defining a set of program parameters in a Python script.
Notes
Two other classes can be used in place of ConfigParser. The class RawConfigParser provides all of the functionality of ConfigParser but doesn’t perform any variable interpolation. The SafeConfigParser class provides the same functionality as ConfigParser, but it addresses some subtle problems that arise if configuration values themselves literally include special formatting characters used by the interpolation feature (e.g., '%').
datetime
The datetime module provides a variety of classes for representing and manipulating dates and times. Large parts of this module are simply related to different ways of creating and outputting date and time information. Other major features include mathematical operations such as comparisons and calculations of time deltas. Date manipulation is a complex subject, and readers would be strongly advised to consult Python’s online documentation for an introductory background concerning the design of this module.
date Objects
A date object represents a simple date consisting of a year, month, and day. The following four functions are used to create dates:
date(year, month, day)
Creates a new date object. year is an integer in the range datetime.MINYEAR to datetime.MAXYEAR. month is an integer in the range 1 to 12, and day is an integer in the range 1 to the number of days in the given month. The returned date object is immutable and has the attributes year, month, and day corresponding to the values of the supplied arguments.
date.today()
A class method that returns a date object corresponding to the current date.
date.fromtimestamp(timestamp)
A class method that returns a date object corresponding to the timestamp timestamp. timestamp is a value returned by the time.time() function.
date.fromordinal(ordinal)
A class method that returns a date object corresponding to an ordinal number of days from the minimum allowable date (January 1 of year 1 has ordinal value 1 and January 1, 2006 has ordinal value 732312).
The following class attributes describe the maximum rate and resolution of date instances.
date.min
Class attribute representing the earliest date that can be represented (datetime.date(1,1,1)).
date.max
Class attribute representing the latest possible date (datetime.date(9999,12,31)).
date.resolution
Smallest resolvable difference between non-equal date objects (datetime.timedelta(1)).
An instance, d, of date has read-only attributes d.year, d.month, and d.day and additionally provides the following methods:
d.ctime()
Returns a string representing the date in the same format as normally used by the time.ctime() function.
d.isocalendar()
Returns the date as a tuple (iso_year, iso_week, iso_weekday), where iso_week is in the range 1 to 53 and iso_weekday is the range 1 (Monday) to 7 (Sunday). The first iso_week is the first week of the year that contains a Thursday. The range of values for the three tuple components are determined by the ISO 8601 standard.
d.isoformat()
Returns an ISO 8601–formatted string of the form ' representing the date.YYYY-MM-DD'
d.isoweekday()
Returns the day of the week in the range 1 (Monday) to 7 (Sunday).
d.replace([year [, month [, day ]]])
Returns a new date object with one or more of the supplied components replaced by a new value. For example, d.replace(month=4) returns a new date where the month has been replaced by 4.
d.strftime(format)
Returns a string representing the date formatted according to the same rules as the time.strftime() function. This function only works for dates later than the year 1900. Moreover, format codes for components missing from date objects (such as hours, minutes, and so on) should not be used.
d.timetuple()
Returns a time.struct_time object suitable for use by functions in the time module. Values related to the time of day (hours, minutes, seconds) will be set to 0.
d.toordinal()
Converts d to an ordinal value. January 1 of year 1 has ordinal value 1.
Returns the day of the week in the range 0 (Monday) to 6 (Sunday).
time Objects
time objects are used to represent a time in hours, minutes, seconds, and microseconds. Times are created using the following class constructor:
time(hour [, minute [, second [, microsecond [, tzinfo]]]])
Creates a time object representing a time where 0 <= hour < 24, 0 <= minute < 60, 0 <= second < 60, and 0 <= microsecond < 1000000. tzinfo provides time zone information and is an instance of the tzinfo class described later in this section. The returned time object has the attributes hour, minute, second, microsecond, and tzinfo, which hold the corresponding values supplied as arguments.
The following class attributes of time describe the range of allowed values and resolution of time instances:
time.min
Class attribute representing the minimum representable time (datetime.time(0,0)).
time.max
Class attribute representing the maximum representable time (datetime.time(23,59, 59, 999999)).
time.resolution
Smallest resolvable difference between non-equal time objects (datetime.timedelta(0,0,1)).
An instance, t, of a time object has attributes t.hour, t.minute, t.second, t.microsecond, and t.tzinfo in addition to the following methods:
t.dst()
Returns the value of t.tzinfo.dst(None). The returned object is a timedelta object. If no time zone is set, None is returned.
t.isoformat()
Returns a string representing the time as 'HH:MM:SS.mmmmmm'. If the microseconds are 0, that part of the string is omitted. If time zone information has been supplied, the time may have an offset added to it (for example, 'HH:MM:SS.mmmmmm+HH:MM').
t.replace([hour [, minute [, second [, microsecond [, tzinfo ]]]]])
Returns a new time object, where one or more components have been replaced by the supplied values. For example, t.replace(second=30) changes the seconds field to 30 and returns a new time object. The arguments have the same meaning as those supplied to the time() function shown earlier.
t.strftime(format)
Returns a string formatted according to the same rules as the time.strftime() function in the time module. Because date information is unavailable, only the formatting codes for time-related information should be used.
Returns the value of t.tzinfo.tzname(). If no time zone is set, None is returned.
t.utcoffset()
Returns the value of t.tzinfo.utcoffset(None). The returned object is a timedelta object. If no time zone has been set, None is returned.
datetime objects
datetime objects are used to represent dates and times together. There are many possible ways to create a datetime instance:
datetime(year, month, day [, hour [, minute [, second [, microsecond [, tzinfo]]]]])
Creates a new datetime object that combines all the features of date and time objects. The arguments have the same meaning as arguments provided to date() and time().
datetime.combine(date,time)
A class method that creates a datetime object by combining the contents of a date object, date, and a time object, time.
datetime.fromordinal(ordinal)
A class method that creates a datetime object given an ordinal day (integer number of days since datetime.min). The time components are all set to 0, and tzinfo is set to None.
datetime.fromtimestamp(timestamp [, tz])
A class method that creates a datetime object from a timestamp returned by the time.time() function. tz provides optional time zone information and is a tzinfo instance.
datetime.now([tz])
A class method that creates a datetime object from the current local date and time. tz provides optional time zone information and is an instance of tzinfo.
datetime.strptime(datestring, format)
A class method that creates a datetime object by parsing the date string in datestring according to the date format in format. The parsing is performed using the strptime() function in the time module.
datetime.utcfromtimestamp(timestamp)
A class method that creates a datetime object from a timestamp typically returned by time.gmtime().
datetime.utcnow()
A class method that creates a datetime object from the current UTC date and time.
The following class attributes describe the range of allowed dates and resolution:
datetime.min
Earliest representable date and time (datetime.datetime(1,1,1,0,0)).
datetime.max
Latest representable date and time (datetime.datetime(9999,12,31,23,59,59,999999)).
datetime.resolution
Smallest resolvable difference between non-equal datetime objects (datetime.timedelta(0,0,1)).
An instance, d, of a datetime object has the same methods as date and time objects combined. In additional, the following methods are available:
d.astimezone(tz)
Returns a new datetime object but in a different time zone, tz. The members of the new object will be adjusted to represent the same UTC time but in the time zone tz.
d.date()
Returns a date object with the same date.
d.replace([year [, month [, day [, hour [, minute [, second [, microsecond [, tzinfo]]]]]]])
Returns a new datetime object with one or more of the listed parameters replaced by new values. Use keyword arguments to replace an individual value.
d.time()
Returns a time object with the same time. The resulting time object has no time zone information set.
d.timetz()
Returns a time object with the same time and time zone information.
d.utctimetuple()
Returns a time.struct_time object containing date and time information normalized to UTC time.
timedelta objects
timedelta objects represent the difference between two dates or times. These objects are normally created as the result of computing a difference between two datetime instances using the - operator. However, they can be manually constructed using the following class:
timedelta([days [, seconds [, microseconds [, milliseconds [, minutes [, hours [, weeks ]]]]]]])
Creates a timedelta object that represents the difference between two dates and times. The only significant parameters are days, seconds, and microseconds, which are used internally to represent a difference. The other parameters, if supplied, are converted into days, seconds, and microseconds. The attributes days, seconds, and microseconds of the returned timedelta object contain these values.
The following class attributes describe the maximum range and resolution of timedelta instances:
timedelta.min
The most negative timedelta object that can be represented (timedelta(-999999999))
timedelta.max
The most positive timedelta object that can be represented (timedelta(days=999999999, hours=23, minutes=59, seconds=59, microseconds=999999)).
timedelta.resolution
A timedelta object representing the smallest resolvable difference between non-equal timedelta objects (timedelta(microseconds=1)).
Mathematical Operations Involving Dates
A significant feature of the datetime module is that it supports mathematical operations involving dates. Both date and datetime objects support the following operations:

When comparing dates, you must use care when time zone information has been supplied. If a date includes tzinfo information, that date can only be compared with other dates that include tzinfo; otherwise, a TypeError is generated. When two dates in different time zones are compared, they are first adjusted to UTC before being compared.
timedelta objects also support a variety of mathematical operations:
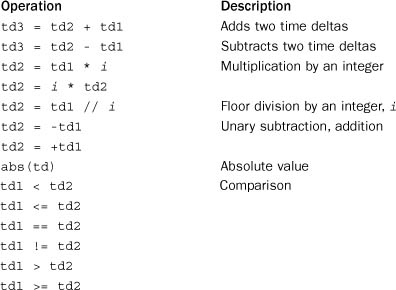
In addition to these operations, all date, datetime, time, and timedelta objects are immutable. This means that they can be used as dictionary keys, placed in sets, and used in a variety of other operations.
tzinfo Objects
Many of the methods in the datetime module manipulate special tzinfo objects that represent information about a time zone. tzinfo is merely a base class. Individual time zones are created by inheriting from tzinfo and implementing the following methods:
tz.dst(dt)
Returns a timedelta object representing daylight savings time adjustments, if applicable. Returns None if no information is known about DST. The argument dt is either a datetime object or None.
tz.fromutc(dt)
Converts a datetime object, dt, from UTC time to the local time zone and returns a new datetime object. This method is called by the astimezone() method on datetime objects. A default implementation is already provided by tzinfo, so it’s usually not necessary to redefine this method.
tz.tzname(dt)
Returns a string with the name of the time zone (for example, "US/Central"). dt is either a datetime object or None.
tz.utcoffset(dt)
Returns a timedelta object representing the offset of local time from UTC in minutes east of UTC. The offset incorporates all elements that make up the local time, including daylight savings time, if applicable. The argument dt is either a datetime object or None.
The following example shows a basic prototype of how one would define a time zone:
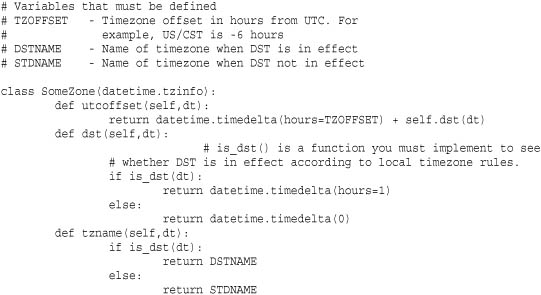
A number of examples of defining time zones can also be found in the online documentation for datetime.
Date and Time Parsing
A common question that arises with date handling is how to parse different kinds of time and date strings into an appropriate datetime object. The only parsing function that is really provided by the datetime module is datetime.strptime(). However, in order to use this, you need to specify the precise date format using various combinations of format codes (see time.strptime()). For example, to parse the date string s="Aug 23, 2008", you would have to use d = datetime.datetime.strptime(s, "%b %d, %Y").
For “fuzzy” date parsing that automatically understands a number of common date formats, you must turn to third-party modules. Go to the Python Package Index (http://pypi.python.org) and do a search for “datetime” to find a wide variety of utility modules that expand the feature set of the datetime module.
See also:
time (p. 405)
errno
The errno module defines symbolic names for the integer error codes returned by various operating system calls, especially those found in the os and socket modules. These codes are typically found in the errno attribute of an OSError or IOError exception. The os.strerror() function can be used to translate an error code into a string error message. The following dictionary can also be used to translate an integer error code into its symbolic name:
This dictionary maps errno integers to symbolic names (such as 'EPERM').
POSIX Error Codes
The following table shows the POSIX symbolic names for common system error codes. The error codes listed here are supported on almost every version of UNIX, Macintosh OS-X, and Windows. Different UNIX systems may provide additional error codes that are less common and not listed here. If such errors occur, you can consult the errorcode dictionary to find the appropriate symbolic name to use in your program.



Windows Error Codes
The error codes in the following table are only available on Windows.


fcntl
The fcntl module performs file and I/O control on UNIX file descriptors. File descriptors can be obtained using the fileno() method of a file or socket object.
fcntl(fd, cmd [, arg])
Performs a command, cmd, on an open file descriptor, fd. cmd is an integer command code. arg is an optional argument that’s either an integer or a string. If arg is passed as an integer, the return value of this function is an integer. If arg is a string, it’s interpreted as a binary data structure, and the return value of the call is the contents of the buffer converted back into a string object. In this case, the supplied argument and return value should be less than 1,024 bytes to avoid possible data corruption. The following commands are available:

An IOError exception is raised if the fcntl() function fails. The F_GETLK and F_SETLK commands are supported through the lockf() function.
ioctl(fd, op, arg [, mutate_flag])
This function is like the fcntl() function, except that the operations supplied in op are generally defined in the library module termios. The extra mutate_flag controls the behavior of this function when a mutable buffer object is passed as an argument. Further details about this can be found in the online documentation. Because the primary use of ioctl() is to interact with device-drivers and other low-level components of the operating system, its use depends highly on the underlying platform. It should not be used in code that aims to be portable.
flock(fd, op)
Performs a lock operation, op, on the file descriptor fd. op is the bitwise OR of the following constants, which are found in fnctl:

In nonblocking mode, an IOError exception is raised if the lock cannot be acquired. On some systems, the process of opening and locking a file can be performed in a single operation by adding special flags to the os.open() operation. Consult the os module for more details.
lockf(fd, op [, len [, start [, whence]]])
Performs record or range locking on part of a file. op is the same as for the flock() function. len is the number of bytes to lock. start is the starting position of the lock relative to the value of whence. whence is 0 for the beginning of the file, 1 for the current position, and 2 for the end of the file.
Example

Notes
• The set of available fcntl() commands and options is system-dependent. The fcntl module may contain more than 100 constants on some platforms.
• Although locking operations defined in other modules often make use of the context-manager protocol, this is not the case for file locking. If you acquire a file lock, make sure your code is written to properly release the lock.
• Many of the functions in this module can also be applied to the file descriptors of sockets.
io
The io module implements classes for various forms of I/O as well as the built-in open() function that is used in Python 3. The module is also available for use in Python 2.6.
The central problem addressed by the io module is the seamless handling of different forms of basic I/O. For example, working with text is slightly different than working with binary data because of issues related to newlines and character encodings. To handle these differences, the module is built as a series of layers, each of which adds more functionality to the last.
Base I/O Interface
The io module defines a basic I/O programming interface that all file-like objects implement. This interface is defined by a base class IOBase. An instance f of IOBase supports these basic operations:

Raw I/O
The lowest level of the I/O system is related to direct I/O involving raw bytes. The core object for this is FileIO, which provides a fairly direct interface to low-level system calls such as read() and write().
FileIO(name [, mode [, closefd]])
A class for performing raw low-level I/O on a file or system file descriptor. name is either a filename or an integer file descriptor such as that returned by the os.open() function or the fileno() method of other file objects. mode is one of 'r' (the default); 'w'; or 'a' for reading, writing, or appending. A '+’ can be added to the mode for update mode in which both reading and writing is supported. closefd is a flag that determines if the close() method actually closes the underlying file. By default, this is True, but it can be set False if you’re using FileIO to put a wrapper around a file that was already opened elsewhere. If a filename was given, the resulting file object is opened directly using the operating system’s open() call. There is no internal buffering, and all data is processed as raw byte strings. An instance f of FileIO has all of the basic I/O operations described earlier plus the following attributes and methods:

It is important to emphasize that FileIO objects are extremely low-level, providing a rather thin layer over operating system calls such as read() and write(). Specifically, users of this object will need to diligently check return codes as there is no guarantee that the f.read() or f.write() operations will read or write all of the requested data. The fcntl module can be used to change low-level aspects of files such as file locking, blocking behavior, and so forth.
FileIO objects should not be used for line-oriented data such as text. Although methods such as f.readline() and f.readlines() are defined, these come from the IOBase base class where they are both implemented entirely in Python and work by issuing f.read() operations for a single byte at a time. Needless to say, the resulting performance is horrible. For example, using f.readline() on a FileIO object f is more than 750 times slower than using f.readline() on a standard file object created by the open() function in Python 2.6.
Buffered Binary I/O
The buffered I/O layer contains a collection of file objects that read and write raw binary data, but with in-memory buffering. As input, these objects all require a file object that implements raw I/O such as the FileIO object in the previous section. All of the classes in this section inherit from BufferedIOBase.
BufferedReader(raw [, buffer_size])
A class for buffered binary reading on a raw file specified in raw. buffer_size specifies the buffer size to use in bytes. If omitted, the value of DEFAULT_BUFFER_SIZE is used (8,192 bytes as of this writing). An instance f of BufferedReader supports all of the operations provided on IOBase in addition to these operations:

BufferedWriter(raw [, buffer_size [, max_buffer_size]])
A class for buffered binary writing on a raw file specified in raw. buffer_size specifies the number of bytes that can be saved in the buffer before data is flushed to the underlying I/O stream. The default value is DEFAULT_BUFFER_SIZE. max_buffer_size specifies the maximum buffer size to use for storing output data that is being written to a non-blocking stream and defaults to twice the value of buffer_size. This value is larger to allow for continued writing while the previous buffer contents are written to the I/O stream by the operating system. An instance f of BufferedWriter supports the following operations:

BufferedRWPair(reader, writer [, buffer_size [, max_buffer_size]])
A class for buffered binary reading and writing on a pair of raw I/O streams. reader is a raw file that supports reading, and writing is a raw file that supports writing. These files may be different, which may be useful for certain kinds of communication involving pipes and sockets. The buffer size parameters have the same meaning as for BufferedWriter. An instance f of BufferedRWPair supports all of the operations for BufferedReader and BufferedWriter.
BufferedRandom(raw [, buffer_size [, max_buffer_size]])
A class for buffered binary reading and writing on a raw I/O stream that supports random access (e.g., seeking). raw must be a raw file that supports both read, write, and seek operations. The buffer size parameters have the same meaning as for BufferedWriter. An instance f of BufferedRandom supports all of the operations for BufferedReader and BufferedWriter.
BytesIO([bytes])
An in-memory file that implements the functionality of a buffered I/O stream. bytes is a byte string that specifies the initial contents of the file. An instance b of BytesIO supports all of the operations of BufferedReader and BufferedWriter objects. In addition, a method b.getvalue() can be used to return the current contents of the file as a byte string.
As with FileIO objects, all the file objects in this section should not be used with line-oriented data such as text. Although it’s not quite as bad due to buffering, the resulting performance is still quite poor (e.g., more than 50 times slower than reading lines with files created using the Python 2.6 built-in open() function). Also, because of internal buffering, you need to take care to manage flush() operations when writing. For example, if you use f.seek() to move the file pointer to a new location, you should first use f.flush() to flush any previously written data (if any).
Also, be aware that the buffer size parameters only specify a limit at which writes occur and do not necessarily set a limit on internal resource use. For example, when you do a f.write(data) on a buffered file f, all of the bytes in data are first copied into the internal buffers. If data represents a very large byte array, this copying will substantially increase the memory use of your program. Thus, it is better to write large amounts of data in reasonably sized chunks, not all at once with a single write() operation. It should be noted that because the io module is relatively new, this behavior might be different in future versions.
Text I/O
The text I/O layer is used to process line-oriented character data. The classes defined in this section build upon buffered I/O streams and add line-oriented processing as well as Unicode character encoding and decoding. All of the classes here inherit from TextIOBase.
TextIOWrapper(buffered [, encoding [, errors [, newline [, line_buffering]]]])
A class for a buffered text stream. buffered is a buffered I/O as described in the previous section. encoding is a string such as 'ascii' or 'utf-8' that specifies the text encoding. errors specifies the Unicode error-handling policy and is 'strict' by default (see Chapter 9, “Input and Output,” for a description). newline is the character sequence representing a newline and may be None, '', '
', '
', or '
'. If None is given, then universal newline mode is enabled in which any of the other line endings are translated into '
' when reading and os.linesep is used as the newline on output. If newline is one of the other values, then all '
' characters are translated into the specified newline on output. line_buffering is a flag that controls whether or not a flush() operation is performed when any write operation contains the newline character. By default, this is False. An instance f of TextIOWrapper supports all of the operations defined on IOBase as well as the following:

StringIO([initial [, encoding [, errors [, newline]]]])
An in-memory file object with the same behavior as a TextIOWrapper. initial is a string that specifies the initial contents of the file. The other parameters have the same meaning as with TextIOWrapper. An instance s of StringIO supports all of the usual file operations, in addition to a method s.getvalue() that returns the current contents of the memory buffer.
The open() Function
The io module defines the following open() function, which is the same as the built-in open() function in Python 3.
open(file [, mode [, buffering [, encoding [, errors [, newline [, closefd]]]]]])
Opens file and returns an appropriate I/O object. file is either a string specifying the name of a file or an integer file descriptor for an I/O stream that has already been opened. The result of this function is one of the I/O classes defined in the io module depending on the settings of mode and buffering. If mode is any of the text modes such as 'r', 'w', 'a', or 'U', then an instance of TextIOWrapper is returned. If mode is a binary mode such as 'rb' or 'wb', then the result depends on the setting of buffering. If buffering is 0, then an instance of FileIO is returned for performing raw unbuffered I/O. If buffering is any other value, then an instance of BufferReader, BufferedWriter, or BufferedRandom is returned depending on the file mode. The encoding, errors, and errors parameters are only applicable to files opened in text mode and passed to the TextIOWrapper constructor. The closefd is only applicable if file is an integer descriptor and is passed to the FileIO constructor.
Abstract Base Classes
The io module defines the following abstract base classes that can be used for type checking and defining new I/O classes:

It is rare for most programmers to work with these classes directly. You should refer to the online documentation for details concerning their use and definition.
Note
The io module is a new addition to Python, first appearing in Python 3 and backported to Python 2.6. As of this writing, the module is immature and has extremely poor runtime performance—especially for any application that involves heavy amounts of text I/O. If you are using Python 2, you will be better served by the built-in open() function than using the I/O classes defined in the io module. If you are using Python 3, there seems to be no other alternative. Although performance improvements are likely in future releases, this layered approach to I/O coupled with Unicode decoding is unlikely to match the raw I/O performance found in the C standard library, which is the basis for I/O in Python 2.
logging
The logging module provides a flexible facility for applications to log events, errors, warnings, and debugging information. This information can be collected, filtered, written to files, sent to the system log, and even sent over the network to remote machines. This section covers the essential details of using this module for most common cases.
Logging Levels
The main focus of the logging module concerns the issuing and handling of log messages. Each message consists of some text along with an associated level that indicates its severity. Levels have both a symbolic name and numerical value as follows:
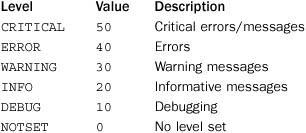
These different levels are the basis for various functions and methods throughout the logging module. For example, there are methods to issue log messages at each level as well as filters that work by blocking messages that don’t meet a certain threshold value.
Basic Configuration
Before using any other functions in the logging module, you should first perform some basic configuration of a special object known as the root logger. The root logger is responsible for managing the default behavior of log messages including the logging level, output destination, message format, and other basic details. The following function is used for configuration:
basicConfig([**kwargs])
Performs basic configuration of the root logger. This function should be called before any other logging calls are made. The function accepts a number of keyword arguments:

Most of these parameters are self-explanatory. The format argument is used to specify the format of log messages along with optional contextual information such as filenames, levels, line numbers, and so forth. datefmt is a date format string compatible with the time.strftime() function. If omitted, the date format is set to the ISO8601 format.
The following expansions are recognized in format:

Here is an example that illustrates a single configuration where log messages with a level of INFO or higher are appended to a file:

With this configuration, a CRITICAL log message of 'Hello World' will appear as follows in the log file 'app.log'.
CRITICAL 2005-10-25 20:46:57,126 Hello World
Logger Objects
In order to issue log messages, you have to obtain a Logger object. This section describes the process of creating, configuring, and using these objects.
Creating a Logger
To create a new Logger object, you use the following function:
getLogger([logname])
Returns a Logger instance associated with the name logname. If no such object exists, a new Logger instance is created and returned. logname is a string that specifies a name or series of names separated by periods (for example 'app' or 'app.net'). If you omit logname, you will get the Logger object associated with the root logger.
The creation of Logger instances is different than what you find in most other library modules. When you create a Logger, you always give it a name which is passed to getLogger() as the logname parameter. Internally, getLogger() keeps a cache of the Logger instances along with their associated names. If another part of the program requests a logger with the same name, the previously created instance is returned. This arrangement greatly simplifies the handling of log messages in large applications because you don’t have to figure out how to pass Logger instances around between different program modules. Instead, in each module where you want logging, you just use getLogger() to get a reference to the appropriate Logger object.
Picking Names
For reasons that will become clear later, you should always pick meaningful names when using getLogger(). For example, if your application is called 'app', then you should minimally use getLogger('app') at the top of every program module that makes up the application. For example:
![]()
You might also consider adding the module name to the logger such as getLogger('app.net') or getLogger('app.user') in order to more clearly indicate the source of log messages. This can be done using statements such as this:
![]()
Adding the module name makes it easier to selectively turn off or reconfigure the logging for specific program modules as will be described later.
Issuing Log Messages
If log is an instance of a Logger object (created using the getLogger() function in the previous section), the following methods are used to issue log messages at the different logging levels:

The fmt argument is a format string that specifies the format of the log message. Any remaining arguments in args serve as arguments for format specifiers in the format string. The string formatting operator % is used to form the resulting message from these arguments. If multiple arguments are provided, they are placed into a tuple for formatting. If a single argument is provided, it is placed directly after the % when formatting.
Thus, if you pass a single dictionary as an argument, the format string can include dictionary key names. Here are a few examples that illustrate how this works:
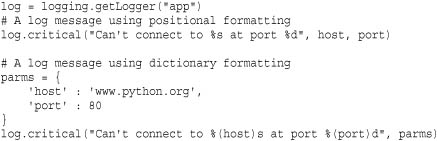
The keyword argument exc_info, if set to True, adds exception information from sys.exc_info() to the log message. If exc_info is set to an exception tuple such as that returned by sys.exc_info(), then that information is used. The extra keyword argument is a dictionary that supplies additional values for use in log message format strings (described later). Both exc_info and extra must be specified as keyword arguments.
When issuing log messages, you should avoid code that carries out string formatting at the time the message is issued (that is, formatting a message and then passing the result into the logging module). For example,
log.critical("Can't connect to %s at port %d" % (host, port))
In this example, the string formatting operation always occurs before the call to log.critical() because the arguments to a function or method have to be fully evaluated. However, in the example at the top of the page, the parameters used for string formatting operation are merely passed to the logging module and used only if the log message is actually going to be handled. This is a very subtle distinction, but because many applications choose to filter log messages or only emit logs during debugging, the first approach performs less work and runs faster when logging is disabled.
In addition to the methods shown, there are a few additional methods for issuing log messages on a Logger instance log.
log.exception(fmt [, *args ])
Issues a message at the ERROR level but adds exception information from the current exception being handled. This can only be used inside except blocks.
log.log(level, fmt [, *args [, exc_info [, extra]]])
Issues a logging message at the level specified by level. This can be used if the logging level is determined by a variable or if you want to have additional logging levels not covered by the five basic levels.
log.findCaller()
Returns a tuple (filename, lineno, funcname) corresponding to the caller’s source filename, line number, and function name. This information is sometimes useful when issuing log messages—for example, if you want to add information about the location of the logging call to a message.
Filtering Log Messages
Each Logger object log has an internal level and filtering mechanism that determines which log messages get handled. The following two methods are used to perform simple filtering based on the numeric level of log messages:
log.setLevel(level)
Sets the level of log. Only logging messages with a level greater than or equal to level will be handled. All other messages are simply ignored. By default, the level is logging.NOTSET which processes all log messages.
log.isEnabledFor(level)
Returns True if a logging message at level level would be processed.
Logging messages can also be filtered based on information associated with the message itself—for example, the filename, the line number, and other details. The following methods are used for this:
log.addFilter(filt)
Adds a filter object, filt, to the logger.
log.removeFilter(filt)
Removes a filter object, filt, from the logger.
In both methods, filt is an instance of a Filter object.
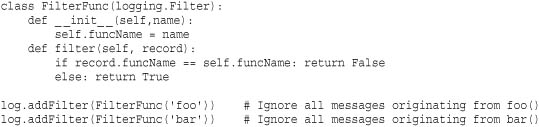
Filter(logname)
Creates a filter that only allows log messages from logname or its children to pass through. For example, if logname is 'app', then messages from loggers such as 'app', 'app.net', or 'app.user' will pass, but messages from a logger such as 'spam' will not.
Custom filters can be created by subclassing Filter and implementing the method filter(record) that receives as input a record containing information about a logging message. As output, True or False is returned depending on whether or not the message should be handled. The record object passed to this method typically has the following attributes:

The following example illustrates how you create a custom filter:
Message Propagation and Hierarchical Loggers
In advanced logging applications, Logger objects can be organized into a hierarchy. This is done by giving a logger object a name such as 'app.net.client'. Here, there are actually three different Logger objects called 'app', 'app.net', and 'app.net.client'. When a message is issued on any of the loggers and it successfully passes that logger’s filter, it propagates to and is handled by all of the parents. For example, a message successfully issued on 'app.net.client' also propagates to 'app.net', 'app' and the root logger.
The following attributes and methods of a Logger object log control this propagation.
log.propagate
A Boolean flag that indicates whether or not messages propagate to the parent logger. By default, this is set to True.
log.getEffectiveLevel()
Returns the effective level of the logger. If a level has been set using setLevel(), that level is returned. If no level has been explicitly set (the level is logging.NOTSET in this case), this function returns the effective level of the parent logger instead. If none of the parent loggers have a level set, the effective level of the root logger will be returned.
The primary purpose of hierarchical logging is to be able to more easily filter log messages originating from different parts of a large application. For example, if you wanted to shut down log messages from the 'app.net.client' part of an application, you might add configuration code such as the following:
![]()
Or, in this code, we’re ignoring all but the most severe messages from a program module:
![]()
A subtle aspect of hierarchical loggers is that the decision to handle a log message is made entirely by the level and filters on the Logger object on which the message was issued, not by the filters on any of the parents. Thus, if a message passes the first set of filters, it is propagated to and handled by all the parent loggers regardless of their own filter and level settings—even if these filters would have rejected the message. At first glance, the behavior is counterintuitive and might even seem like a bug. However, setting the level of a child logger to a value that is lower than its parent is one way to override the settings on the parent, achieving a kind of level promotion. Here is an example:

When using hierarchical loggers, you only have to configure the logging objects where you want to change the filtering or propagation behavior. Because messages naturally propagate to the root logger, it will ultimately be responsible for producing the output and any configuration that you made using basicConfig() will apply.
Message Handling
Normally, messages are handled by the root logger. However, any Logger object can have special handlers added to it that receive and process log messages. This is done using these methods of a Logger instance log.
log.addHandler(handler)
Adds a Handler object to the logger.
log.removeHandler(handler)
Removes the Handler object handler from the logger.
The logging module has a variety of pre-built handlers for writing log messages to files, streams, system logs, and so forth. These are described in further detail in the next section. However, the following example shows how loggers and handlers are hooked together using these methods.

When you add your own handlers to process messages, it is often your intent to override the behavior of the root logger. This is why message propagation is disabled in the previous example (i.e., the 'app' logger is simply going to handle all of the messages).
Handler Objects
The logging module provides a collection of pre-built handlers that can process log messages in various in ways. These handlers are added to Logger objects using their addHandler() method. In addition, each handler can be configured with its own filtering and levels.
Built-In Handlers
The following handler objects are built-in. Some of these handlers are defined in a sub-module logging.handlers, which must be imported specifically if necessary.
handlers.DatagramHandler(host,port)
Sends log messages to a UDP server located on the given host and port. Log messages are encoded by taking the dictionary of the corresponding LogRecord object and encoding it using the pickle module. The transmitted network message consists of a 4-byte network order (big-endian) length followed by the pickled record data. To reconstruct the message, the receiver must strip the length header, read the entire message, unpickle the contents, and call logging.makeLogRecord(). Because UDP is unreliable, network errors may result in lost log messages.
FileHandler(filename [, mode [, encoding [, delay]]])
Writes log messages to the file filename. mode is the file mode to use when opening the file and defaults to 'a'. encoding is the file encoding. delay is a Boolean flag that, if set True, defers the opening of the log file until the first log message is issued. By default, it is False.
handlers.HTTPHandler(host, url [, method])
Uploads log messages to an HTTP server using HTTP GET or POST methods. host specifies the host machine, url is the URL to use, and method is either 'GET' (the default) or 'POST'. The log message is encoded by taking the dictionary of the corresponding LogRecord object and encoding it as a set of URL query-string variables using the urllib.urlencode() function.
handlers.MemoryHandler(capacity [, flushLevel [, target]])
This handler is used to collect log messages in memory and to flush them to another handler, target, periodically. capacity is the size of the memory buffer in bytes. flushLevel is a numeric logging level that forces a memory flush should a logging message of that level or higher appear. The default value is ERROR. target is another Handler object that receives the messages. If target is omitted, you will need to set a target using the setTarget() method of the resulting handler object in order for this handler to do anything.
handlers.NTEventLogHandler(appname [, dllname [, logtype]])
Sends messages to the event log on Windows NT, Windows 2000, or Windows XP. appname is the name of the application name to use in the event log. dllname is a full path name to a .DLL or .EXE file that provides message definitions to hold in the log. If omitted, dllname is set to 'win32service.pyd'. logtype is either 'Application', 'System', or 'Security'. The default value is 'Application'. This handler is only available if Win32 extensions for Python have been installed.
handlers.RotatingFileHandler(filename [, mode [, maxBytes [, backupCount [, encoding [, delay]]]]])
Writes log messages to the file filename. However, if the file exceeds the size specified by maxBytes, the file is rotated to filename.1 and a new log file, filename, is opened. backupCount specifies the maximum number of backup files to create. By default, the value of backupCount is 0. However, when specified, backup files are rotated through the sequence filename.1, filename.2, ... ,filename.N, where filename.1 is always the most recent backup and filename.N is always the oldest backup. mode specifies the file mode to use when opening the log file. The default mode is 'a'. If maxBytes is 0 (the default), the log file is never rolled over and is allowed to grow indefinitely. encoding and delay have the same meaning as with FileHandler.
handlers.SMTPHandler(mailhost, fromaddr, toaddrs, subject [, credentials])
Sends log messages to a remote host using email. mailhost is the address of an SMTP server that can receive the message. The address can be a simple host name specified as a string or a tuple (host, port). fromaddr is the from address, toaddrs is the destination address, and subject is the subject to use in the message. credentials is a tuple (username, password) with the username and password.
handlers.SocketHandler(host, port)
Sends log messages to a remote host using a TCP socket connection. host and port specify the destination. Messages are sent in the same format as described for DatagramHandler. Unlike DatagramHandler, this handler reliably delivers log messages.
StreamHandler([fileobj])
Writes log messages to an already open file-like object, fileobj. If no argument is provided, messages are written to sys.stderr.
handlers.SysLogHandler([address [, facility]])
Sends log messages to a UNIX system logging daemon. address specifies the destination as a (host, port) tuple. If omitted, a destination of ('localhost', 514) is used. facility is an integer facility code and is set to SysLogHandler.LOG_USER by default. A full list of facility codes can be found in the definition of SysLogHandler.
handlers.TimedRotatingFileHandler(filename [, when [, interval [, backupCount [, encoding [, delay [, utc]]]]]])
The same as RotatingFileHandler, but the rotation of files is controlled by time instead of file size. interval is a number, and when is a string that specifies units. Possible values for when are 'S' (seconds), 'M' (minutes), 'H' (hours), 'D' (days), 'W' (weeks), and 'midnight' (roll over at midnight). For example, setting interval to 3 and when to 'D' rolls the log every three days. backupCount specifies the maximum number of backup files to keep. utc is a Boolean flag that determines whether or not to use local time (the default) or UTC time.
handlers.WatchedFileHandler(filename [, mode [, encoding [, delay]]])
The same as FileHandler, but the inode and device of the opened log file is monitored. If it changes since the last log message was issued, the file is closed and reopened again using the same filename. These changes might occur if a log file has been deleted or moved as a result of a log rotation operation carried out externally to the running program. This handler only works on UNIX systems.
Handler Configuration
Each Handler object h can be configured with its own level and filtering. The following methods are used to do this:
h.setLevel(level)
Sets the threshold of messages to be handled. level is a numeric code such as ERROR or CRITICAL.
h.addFilter(filt)
Adds a Filter object, filt, to the handler. See the addFilter() method of Logger objects for more information.
h.removeFilter(filt)
Removes a Filter object, filt, from the handler.
It is important to stress that levels and filters can be set on handlers independently from any settings used on the Logger objects to which handlers are attached. Here is an example that illustrates this:

In this example, there is a single logger called 'app’ with a level of INFO. Two handlers are attached to it, but one of the handlers (crit_handler) has its own level setting of CRITICAL. Although this handler will receive log messages with a level of INFO or higher, it selectively discards those that are not CRITICAL.
Handler Cleanup
The following methods are used on handlers to perform cleanup.
h.flush()
Flushes all logging output.
h.close()
Closes the handler.
Message Formatting
By default, Handler objects emit log messages exactly as they are formatted in logging calls. However, sometimes you want to add additional contextual information to the messages such as timestamps, filenames, line numbers, and so forth. This section describes how this extra information can be automatically added to log messages.
Formatter Objects
To change the log message format, you must first create a Formatter object:
Formatter([fmt [, datefmt]])
Creates a new Formatter object. fmt provides a format string for messages. Within fmt, you can place various expansions as previously described for the basicConfig() function. datefmt is a date format string compatible with the time.strftime() function. If omitted, the date format is set to the ISO8601 format.
To take effect, Formatter objects must be attached to handler objects. This is done using the h.setFormatter() method of a Handler instance h.
h.setFormatter(format)
Sets the message formatter object used to create log messages on the Handler instance h. format must be an instance of Formatter.
Here is an example that illustrates how to customize the log message format on a handler:

In this example, a custom Formatter is set on the crit_hand handler. If a logging message such as "Creeping death detected." is processed by this handler, the following log message is produced:
CRITICAL 2005-10-25 20:46:57,126 Creeping death detected.
Adding Extra Context to Messages
In certain applications, it is useful to add additional context information to log messages. This extra information can be provided in one of two ways. First, all of the basic logging operations (e.g., log.critical(), log.warning(), etc.) have a keyword parameter extra that is used to supply a dictionary of additional fields for use in message format strings. These fields are merged in with the context data previously described for Formatter objects. Here is an example:

The downside of this approach is that you have to make sure every logging operation includes the extra information or else the program will crash. An alternative approach is to use the LogAdapter class as a wrapper for an existing logger.
LogAdapter(log [, extra])
Creates a wrapper around a Logger object log. extra is a dictionary of extra context information to be supplied to message formatters. An instance of LogAdapter has the same interface as a Logger object. However, operations that issue log messages will automatically add the extra information supplied in extra.
Here is an example of using a LogAdapter object:

Miscellaneous Utility Functions
The following functions in logging control a few other aspects of logging:
disable(level)
Globally disables all logging messages below the level specified in level. This can be used to turn off logging on a applicationwide basis—for instance, if you want to temporarily disable or reduce the amount of logging output.
addLevelName(level, levelName)
Creates an entirely new logging level and name. level is a number and levelName is a string. This can be used to change the names of the built-in levels or to add more levels than are supported by default.
getLevelName(level)
Returns the name of the level corresponding to the numeric value level.
shutdown()
Shuts down all logging objects, flushing output if necessary.
Logging Configuration
Setting an application to use the logging module typically involves the following basic steps:
1. Use getLogger() to create various Logger objects. Set parameters such as the level, as appropriate.
2. Create Handler objects by instantiating one of the various types of handlers (FileHandler, StreamHandler, SocketHandler, and so on) and set an appropriate level.
3. Create message Formatter objects and attach them to the Handler objects using the setFormatter() method.
4. Attach the Handler objects to the Logger objects using the addHandler() method.
Because the configuration of each step can be somewhat involved, your best bet is to put all the logging configuration into a single well-documented location. For example, you might create a file applogconfig.py that is imported by the main program of your application:

If changes need to be made to any part of the logging configuration, having everything in one location makes things easier to maintain. Keep in mind that this special file only needs to be imported once and in only one location in the program. In other parts of the code where you want to issue log messages, you simply include code like this:

The logging.config Submodule
As an alternative to hard-coding the logging configuration in Python code, it is also possible to configure the logging module through the use of an INI-format configuration file. To do this, use the following functions found in logging.config.
fileConfig(filename [, defaults [, disable_existing_loggers]])
Reads the logging configuration from the configuration file filename. defaults is a dictionary of default configuration parameters for use in the config file. The specified filename is read using the ConfigParser module. disable_existing_loggers is a Boolean flag that specifies whether or not any existing loggers are disabled when new configuration data is read. By default, this is True.
The online documentation for the logging module goes into some detail on the expected format of configuration files. However, experienced programmers can probably extrapolate from the following example, which is a configuration file version of applogconfig.py shown in the previous section.
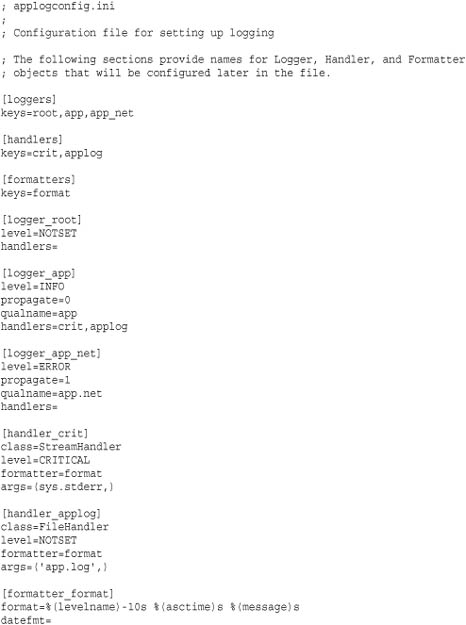
To read this configuration file and set up logging, you would use this code:
![]()
As before, modules that want to issue log messages do not need to worry about the details of loading the logging configuration. They merely import the logging module and get a reference to the appropriate Logger object. For example:

Performance Considerations
Adding logging to an application can severely degrade its performance if you aren’t careful. However, there are some techniques that can be used to reduce the overhead.
First, Python’s optimized mode (-O) removes all code that is conditionally executed using statements such as if _ _debug_ _: statements. If the sole purpose of logging is debugging, you could conditionally execute all of the logging calls and have the calls removed in optimized mode.
A second technique would be to use a Null object in place of a Logger object when logging is to be completely disabled. This is different than using None. Instead, you want to use an instance of an object that silently swallows all operations that get performed on it. For example:

Depending on your cleverness, logging can also be managed through the use of decorators and metaclasses. Because these features of Python operate at the time that functions, methods, and classes are defined, they can be used to selectively add or remove logging features from parts of a program in a way that does not impact performance when logging is disabled. Please refer to Chapter 6, “Functions and Functional Programming,” and Chapter 7, “Classes and Object-Oriented Programming,” for further details.
Notes
• The logging module provides a large number of customization options not discussed here. Readers should consult online documentation for further details.
• It is safe to use the logging module with programs that use threads. In particular, it is not necessary to add locking operations around code that is issuing log messages.
mmap
The mmap module provides support for a memory-mapped file object. This object behaves both like a file and a byte string and can be used in most places where an ordinary file or byte string is expected. Furthermore, the contents of a memory-mapped file are mutable. This means that modifications can be made using index-assignment and slice-assignment operators. Unless a private mapping of the file has been made, such changes directly alter the contents of the underlying file.
A memory-mapping file is created by the mmap() function, which is slightly different on UNIX and Windows.
mmap(fileno, length [, flags, [prot [,access [, offset]]]])
(UNIX). Returns an mmap object that maps length bytes from the file with an integer file descriptor, fileno. If fileno is -1, anonymous memory is mapped. flags specifies the nature of the mapping and is one of the following:

The default flags setting is MAP_SHARED. prot specifies the memory protections of the object and is the bitwise OR of the following:

The default value of prot is PROT_READ | PROT_WRITE. The modes specified in prot must match the access permissions used to open the underlying file descriptor fileno. In most cases, this means that the file should be opened in read/write mode (for example, os.open(name, os.O_RDWR)).
The optional access parameter may be used as an alternative to flags and prot. If given, it has one of the following values:

When access is supplied, it is typically given as a keyword argument—for example, mmap(fileno, length, access=ACCESS_READ). It is an error to supply values for both access and flags. The offset parameter specifies the number of bytes from the start of the file and defaults to 0. It must be a multiple of mmap.ALLOCATIONGRANULARITY.
mmap(fileno, length[, tagname [,access [, offset]]])
(Windows) Returns an mmap object that maps length bytes from the file specified by the integer file descriptor fileno. Use a fileno of -1 for anonymous memory. If length is larger than the current size of the file, the file is extended to length bytes. If length is 0, the current length of the file is used as the length as long as the file is non-empty (otherwise, an exception will be raised). tagname is an optional string that can be used to name the mapping. If tagname refers to an existing mapping, that mapping is opened. Otherwise, a new mapping is created. If tagname is None, an unnamed mapping is created. access is an optional parameter that specifies the access mode. It takes the same values for access as described for the UNIX version of mmap() shown earlier. By default, access is ACCESS_WRITE. offset is the number of bytes from the beginning of the file and defaults to 0. It must be a multiple of mmap.ALLOCATIONGRANULARITY.
A memory-mapped file object, m, supports the following methods.
m.close()
Closes the file. Subsequent operations will result in an exception.
m.find(string[, start])
Returns the index of the first occurrence of string. start specifies an optional starting position. Returns -1 if no match is found.
m.flush([offset, size])
Flushes modifications of the in-memory copy back to the file system. offset and size specify an optional range of bytes to flush. Otherwise, the entire mapping is flushed.
m.move(dst,src,count)
Copies count bytes starting at index src to the destination index dst. This copy is performed using the C memmove() function, which is guaranteed to work correctly when the source and destination regions happen to overlap.
m.read(n)
Reads up to n bytes from the current file position and returns the data as a string.
m.read_byte()
Reads a single byte from the current file position and returns as a string of length 1.
m.readline()
Returns a line of input starting at the current file position.
m.resize(newsize)
Resizes the memory-mapped object to contain newsize bytes.
m.seek(pos[, whence])
Sets the file position to a new value. pos and whence have the same meaning as for the seek() method on file objects.
m.size()
Returns the length of the file. This value may be larger than the size of the memory-mapped region.
m.tell()
Returns the value of the file pointer.
Writes a string of bytes to the file at the current file pointer.
m.write_byte(byte)
Writes a single byte into memory at the current file pointer.
Notes
• Although UNIX and Windows supply slightly different mmap() functions, this module can be used in a portable manner by relying on the optional access parameter that is common to both functions. For example, mmap(fileno,length,access=ACCESS_WRITE) will work on both UNIX and Windows.
• Certain memory mapping may only work with a length that’s a multiple of the system page size, which is contained in the constant mmap.PAGESIZE.
• On UNIX SVR4 systems, anonymous mapped memory can be obtained by calling mmap() on the file /dev/zero, opened with appropriate permissions.
• On UNIX BSD systems, anonymous mapped memory can be obtained by calling mmap() with a negative file descriptor and the flag mmap.MAP_ANON.
msvcrt
The msvcrt module provides access to a number of useful functions in the Microsoft Visual C runtime library. This module is available only on Windows.
getch()
Reads a keypress and returns the resulting character. This call blocks if a keypress is not available. If the pressed key was a special function key, the call returns '�00' or 'xe0' and the next call returns the keycode. This function doesn’t echo characters to the console, nor can the function be used to read Ctrl+C.
getwch()
The same as getch() except that a Unicode character is returned.
getche()
Like getch() except that characters are echoed (if printable).
getwche()
The same as getche() except that a Unicode character is returned.
get_osfhandle(fd)
Returns the file handle for file descriptor fd. Raises IOError if fd is not recognized.
heapmin()
Forces the internal Python memory manager to return unused blocks to the operating system. This works only on Windows NT and raises IOError on failure.
Returns True if a keypress is waiting to be read.
locking(fd, mode, nbytes)
Locks part of a file, given a file descriptor from the C runtime. nbytes is the number of bytes to lock relative to the current file pointer. mode is one of the following integers:

Attempts to acquire a lock that takes more than approximately 10 seconds results in an IOError exception.
open_osfhandle(handle, flags)
Creates a C runtime file descriptor from the file handle handle. flags is the bitwise OR of os.O_APPEND, os.O_RDONLY, and os.O_TEXT. Returns an integer file descriptor that can be used as a parameter to os.fdopen() to create a file object.
putch(char)
Prints the character char to the console without buffering.
putwch(char)
The same as putch() except that char is a Unicode character.
setmode(fd, flags)
Sets the line-end translation mode for file descriptor fd. flags is os.O_TEXT for text mode and os.O_BINARY for binary mode.
ungetch(char)
Causes the character char to be “pushed back” into the console buffer. It will be the next character read by getch() or getche().
ungetwch(char)
The same as ungetch() except that char is a Unicode character.
Note
A wide variety of Win32 extensions are available that provide access to the Microsoft Foundation Classes, COM components, graphical user interfaces, and so forth. These topics are far beyond the scope of this book, but detailed information about many of these topics is available in Python Programming on Win32 by Mark Hammond and Andy Robinson (O’Reilly & Associates, 2000). Also, http://www.python.org maintains an extensive list of contributed modules for use under Windows.
See Also:
winreg (p. 408)
optparse
The optparse module provides high-level support for processing UNIX-style command-line options supplied in sys.argv. A simple example of using the module is found in Chapter 9. Use of optparse primarily focuses on the OptionParser class.
OptionParser([**args])
Creates a new command option parser and returns an OptionParser instance. A variety of optional keyword arguments can be supplied to control configuration. These keyword arguments are described in the following list:

Unless you really need to customize option processing in some way, an OptionParser will usually be created with no arguments. For example:
p = optparse.OptionParser()
An instance, p, of OptionParser supports the following methods:
p.add_option(name1, ..., nameN [, **parms])
Adds a new option to p. The arguments name1, name2, and so on are all of the various names for the option. For example, you might include short and long option names such as '-f' and '--file’. Following the option names, an optional set of keyword arguments is supplied that specifies how the option will be processed when parsed. These keyword arguments are described in the following list:


p.disable_interspersed_args()
Disallows the mixing of simple options with positional arguments. For example, if '-x’ and '-y' are options that take no parameters, the options must appear before any arguments (for example, 'prog -x -y arg1 arg2 arg3').
p.enable_interspersed_args()
Allows the mixing of options with positional arguments. For example, if '-x’ and '-y' are simple options that take no parameters, they may be mixed with the arguments, such as in 'prog -x arg1 arg2 -y arg3'. This is the default behavior.
p.parse_args([arglist])
Parses command-line options and returns a tuple (options, args) where options is an object containing the values of all the options and args is a list of all the remaining positional arguments left over. The options object stores all the option data in attributes with names that match the option name. For example, the option '--output' would have its value stored in options.output. If the option does not appear, the value will be None. The name of the attribute can be set using the dest keyword argument to add_option(), described previously. By default, arguments are taken from sys.argv[1:]. However, a different source of arguments can be supplied as an optional argument, arglist.
p.set_defaults(dest=value, ... dest=value)
Sets the default values of particular option destinations. You simply supply keyword arguments that specify the destinations you wish to set. The name of the keyword arguments should match the names specified using the dest parameter in add_option(), described earlier.
p.set_usage(usage)
Changes the usage string displayed in text produced by the --help option.
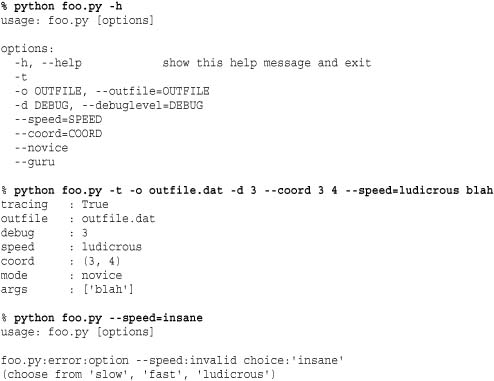
Example

Here is a short interactive UNIX session that shows how the previous code works:
Notes
• When specifying option names, use a single dash to specify a short name such as '-x' and a double-dash to specify a long name such as '--exclude'. An OptionError exception will be raised if you attempt to define an option that is a mix of the two styles, such as '-exclude'.
• Python also includes a module getopt that provides support for command-line parsing in a style similar to a C library of the same name. For all practical purposes, there is no benefit to using that module over optparse (which is much higher level and requires far less coding).
• The optparse module contains a considerable number of advanced features related to customization and specialized handling of certain kinds of command-line options. However, none of these features are required for the most common types of command-line option parsing. Readers should consult the online library documentation for more details and additional examples.
os
The os module provides a portable interface to common operating-system services. It does this by searching for an OS-dependent built-in module such as nt or posix and exporting the functions and data as found there. Unless otherwise noted, functions are available on Windows and UNIX. UNIX systems include both Linux and Mac OS X.
The following general-purpose variables are defined:
environ
A mapping object representing the current environment variables. Changes to the mapping are reflected in the current environment. If the putenv() function is also available, then changes are also reflected in subprocesses.
linesep
The string used to separate lines on the current platform. May be a single character such as '
' for POSIX or multiple characters such as '
' for Windows.
name
The name of the OS-dependent module imported: 'posix', 'nt', 'dos', 'mac', 'ce', 'java', 'os2', or 'riscos'.
path
The OS-dependent standard module for pathname operations. This module can also be loaded using import os.path.
Process Environment
The following functions are used to access and modify various parameters related to the environment in which a process runs. Process, group, process group, and session IDs are integers unless otherwise noted.
chdir(path)
Changes the current working directory to path.
chroot(path)
Changes the root directory of the current process (UNIX).
ctermid()
Returns a string with the filename of the control terminal for the process (UNIX).
fchdir(fd)
Changes the current working directory. fd is a file descriptor to an opened directory (UNIX).
getcwd()
Returns a string with the current working directory.
getcwdu()
Returns a Unicode string with the current working directory.
getegid()
Returns the effective group ID (UNIX).
geteuid()
Returns the effective user ID (UNIX).
Returns the real group ID of the process (UNIX).
getgroups()
Returns a list of integer group IDs to which the process owner belongs (UNIX).
getlogin()
Returns the user name associated with the effective user ID (UNIX).
getpgid(pid)
Returns the process group ID of the process with process ID pid. If pid is 0, the process group of the calling process is returned (UNIX).
getpgrp()
Returns the ID of the current process group. Process groups are typically used in conjunction with job control. The process group is not necessarily the same as the group ID of the process (UNIX).
getpid()
Returns the real process ID of the current process (UNIX and Windows).
getppid()
Returns the process ID of the parent process (UNIX).
getsid(pid)
Returns the process session identifier of process pid. If pid is 0, the identifier of the current process is returned (UNIX).
getuid()
Returns the real user ID of the current process (UNIX).
putenv(varname, value)
Sets environment variable varname to value. Changes affect subprocesses started with os.system(), popen(), fork(), and execv(). Assignments to items in os.environ automatically call putenv(). However, calls to putenv() don’t update os.environ (UNIX and Windows).
setegid(egid)
Sets the effective group id (UNIX).
seteuid(euid)
Sets the effective user ID (UNIX).
setgid(gid)
Sets the group ID of the current process (UNIX).
setgroups(groups)
Sets the group access list of the current process. groups is a sequence of integers specifying group identifiers. Can only be called by root (UNIX).
Creates a new process group by calling the system call setpgrp() or setpgrp(0, 0), depending on which version is implemented (if any). Returns the ID of the new process group (UNIX).
setpgid(pid, pgrp)
Assigns process pid to process group pgrp. If pid is equal to pgrp, the process becomes a new process group leader. If pid is not equal to pgrp, the process joins an existing group. If pid is 0, the process ID of the calling process is used. If pgrp is 0, the process specified by pid becomes a process group leader (UNIX).
setreuid(ruid,euid)
Sets the real and effective user ID of the calling process (UNIX).
setregid(rgid,egid)
Sets the real and effective group ID of the calling process (UNIX).
setsid()
Creates a new session and returns the newly created session ID. Sessions are typically associated with terminal devices and the job control of processes that are started within them (UNIX).
setuid(uid)
Sets the real user ID of the current process. This function is privileged and often can be performed only by processes running as root (UNIX).
strerror(code)
Returns the error message corresponding to the integer error code (UNIX and Windows). The errno module defines symbolic names for these error codes.
umask(mask)
Sets the current numeric umask and returns the previous umask. The umask is used to clear permissions bits on files that are created by the process (UNIX and Windows).
uname()
Returns a tuple of strings (sysname, nodename, release, version, machine) identifying the system type (UNIX).
unsetenv(name)
Unsets the environment variable name.
File Creation and File Descriptors
The following functions provide a low-level interface for manipulating files and pipes. In these functions, files are manipulated in terms of an integer file descriptor, fd. The file descriptor can be extracted from a file object by invoking its fileno() method.
close(fd)
Closes the file descriptor fd previously returned by open() or pipe().
Closes all file descriptors fd in the range low<= fd < high. Errors are ignored.
dup(fd)
Duplicates file descriptor fd. Returns a new file descriptor that’s the lowest-numbered unused file descriptor for the process. The new and old file descriptors can be used interchangeably. Furthermore, they share state, such as the current file pointer and locks (UNIX and Windows).
dup2(oldfd, newfd)
Duplicates file descriptor oldfd to newfd. If newfd already corresponds to a valid file descriptor, it’s closed first (UNIX and Windows).
fchmod(fd, mode)
Changes the mode of the file associated with fd to mode. See the description of os.open() for a description of mode (UNIX).
fchown(fd, uid, gid)
Changes the owner and group ID of the file associated with fd to uid and gid. Use a valid of -1 for uid or gid to keep the value unchanged (UNIX).
fdatasync(fd)
Forces all cached data written to fd to be flushed to disk (UNIX).
fdopen(fd [, mode [, bufsize]])
Creates an open file object connected to file descriptor fd. The mode and bufsize arguments have the same meaning as in the built-in open() function. mode should be a string such as 'r', 'w', or 'a'. On Python 3, this function accepts any additional parameters that work with the built-in open() function such as specifications for the encoding and line ending. However, if portability with Python 2 is a concern, you should only use the mode and bufsize arguments described here.
fpathconf(fd, name)
Returns configurable pathname variables associated with the open file with descriptor fd. name is a string that specifies the name of the value to retrieve. The values are usually taken from parameters contained in system header files such as <limits.h> and <unistd.h>. POSIX defines the following constants for name:

Not all names are available on all platforms, and some systems may define additional configuration parameters. However, a list of the names known to the operating system can be found in the dictionary os.pathconf_names. If a known configuration name is not included in os.pathconf_names, its integer value can also be passed as name. Even if a name is recognized by Python, this function may still raise an OSError if the host operating system doesn’t recognize the parameter or associate it with the file fd. This function is only available on some versions of UNIX.
fstat(fd)
Returns the status for file descriptor fd. Returns the same values as the os.stat() function (UNIX and Windows).
fstatvfs(fd)
Returns information about the file system containing the file associated with file descriptor fd. Returns the same values as the os.statvfs() function (UNIX).
fsync(fd)
Forces any unwritten data on fd to be written to disk. Note that if you are using an object with buffered I/O (for example, a Python file object), you should first flush the data before calling fsync(). Available on UNIX and Windows.
ftruncate(fd, length)
Truncates the file corresponding to file descriptor fd so that it’s at most length bytes in size (UNIX).
isatty(fd)
Returns True if fd is associated with a TTY-like device such as a terminal (UNIX).
lseek(fd, pos, how)
Sets the current position of file descriptor fd to position pos. Values of how are as follows: SEEK_SET sets the position relative to the beginning of the file, SEEK_CUR sets it relative to the current position, and SEEK_END sets it relative to the end of the file. In older Python code, it is common to see these constants replaced with their numeric values of 0, 1, or 2, respectively.
Opens the file file. flags is the bitwise OR of the following constant values:

Synchronous I/O modes (O_SYNC, O_DSYNC, O_RSYNC) force I/O operations to block until they’ve been completed at the hardware level (for example, a write will block until the bytes have been physically written to disk). The mode parameter contains the file permissions represented as the bitwise OR of the following octal values (which are defined as constants in the stat module as indicated):

The default mode of a file is (0777 & ~umask), where the umask setting is used to remove selected permissions. For example, a umask of 0022 removes the write permission for groups and others. The umask can be changed using the os.umask() function. The umask setting has no effect on Windows.
openpty()
Opens a psuedo-terminal and returns a pair of file descriptors (master,slave) for the PTY and TTY. Available on some versions of UNIX.
pipe()
Creates a pipe that can be used to establish unidirectional communication with another process. Returns a pair of file descriptors (r, w) usable for reading and writing, respectively. This function is usually called prior to executing a fork() function. After the fork(), the sending process closes the read end of the pipe and the receiving process closes the write end of the pipe. At this point, the pipe is activated and data can be sent from one process to another using read() and write() functions (UNIX).
read(fd, n)
Reads at most n bytes from file descriptor fd. Returns a byte string containing the bytes read.
tcgetpgrp(fd)
Returns the process group associated with the control terminal given by fd (UNIX).
tcsetpgrp(fd, pg)
Sets the process group associated with the control terminal given by fd (UNIX).
ttyname(fd)
Returns a string that specifies the terminal device associated with file descriptor fd. If fd is not associated with a terminal device, an OSError exception is raised (UNIX).
write(fd, str)
Writes the byte string str to file descriptor fd. Returns the number of bytes actually written.
Files and Directories
The following functions and variables are used to manipulate files and directories on the file system. To handle variances in filenaming schemes, the following variables contain information about the construction of path names:

The following functions are used to manipulate files:
access(path, accessmode)
Checks read/write/execute permissions for this process to access the file path. accessmode is R_OK, W_OK, X_OK, or F_OK for read, write, execute, or existence, respectively. Returns 1 if access is granted, 0 if not.
chflags(path, flags)
Changes the file flags on path. flags is the bitwise-or of the constants listed next. Flags starting with UF_ can be set by any user, whereas SF_ flags can only be changed by the superuser (UNIX).

Changes the mode of path. mode has the same values as described for the open() function (UNIX and Windows).
chown(path, uid, gid)
Changes the owner and group ID of path to the numeric uid and gid. Setting uid or gid to -1 causes that parameter to remain unmodified (UNIX).
lchflags(path, flags)
The same as chflags(), but doesn’t follow symbolic links (UNIX).
lchmod(path, mode)
The same as chmod() except that if path is a symbolic link, it modifies the link itself, not the file the link refers to.
lchown(path, uid, gid)
The same as chown() but doesn’t follow symbolic links (UNIX).
link(src, dst)
Creates a hard link named dst that points to src (UNIX).
listdir(path)
Returns a list containing the names of the entries in the directory path. The list is returned in arbitrary order and doesn’t include the special entries of '.' and '..'. If path is Unicode, the resulting list will only contain Unicode strings. Be aware that if any filenames in the directory can’t be properly encoded into Unicode, they are silently skipped. If path is given as a byte string, then all filenames are returned as a list of byte strings.
lstat(path)
Like stat() but doesn’t follow symbolic links (UNIX).
makedev(major, minor)
Creates a raw device number given major and minor device numbers (UNIX).
major(devicenum)
Returns the major device number from a raw device number devicenum created by makedev().
minor(devicenum)
Returns the minor device number from a raw device number devicenum created by makedev().
makedirs(path [, mode])
Recursive directory-creation function. Like mkdir() but makes all the intermediate-level directories needed to contain the leaf directory. Raises an OSError exception if the leaf directory already exists or cannot be created.
Creates a directory named path with numeric mode mode. The default mode is 0777. On non-UNIX systems, the mode setting may have no effect or be ignored.
mkfifo(path [, mode])
Creates a FIFO (a named pipe) named path with numeric mode mode. The default mode is 0666 (UNIX).
mknod(path [, mode, device])
Creates a device-special file. path is the name of the file, mode specifies the permissions and type of file, and device is the raw device number created using os.makedev(). The mode parameter accepts the same parameters as open() when setting the file’s access permissions. In addition, the flags stat.S_IFREG, stat.S_IFCHR, stat.S_IFBLK, and stat.S_IFIFO are added to mode to indicate a file type (UNIX).
pathconf(path, name)
Returns configurable system parameters related to the path name path. name is a string that specifies the name of the parameter and is the same as described for the fpathconf() function (UNIX).
readlink(path)
Returns a string representing the path to which a symbolic link, path, points (UNIX).
remove(path)
Removes the file path. This is identical to the unlink() function.
removedirs(path)
Recursive directory-removal function. Works like rmdir() except that, if the leaf directory is successfully removed, directories corresponding to the rightmost path segments will be pruned away until either the whole path is consumed or an error is raised (which is ignored because it generally means that a parent directory isn’t empty). Raises an OSError exception if the leaf directory could not be removed successfully.
rename(src, dst)
Renames the file or directory src to dst.
renames(old, new)
Recursive directory-renaming or file-renaming function. Works like rename() except it first attempts to create any intermediate directories needed to make the new path name. After the rename, directories corresponding to the rightmost path segments of the old name will be pruned away using removedirs().
rmdir(path)
Removes the directory path.
stat(path)
Performs a stat() system call on the given path to extract information about a file. The return value is an object whose attributes contain file information. Common attributes include:

However, additional attributes may be available depending on the system. The object returned by stat() also looks like a 10-tuple containing the parameters (st_mode, st_ino, st_dev, st_nlink, st_uid, st_gid, st_size, st_atime, st_mtime, st_ctime). This latter form is provided for backward compatibility. The stat module defines constants that are used to extract fields from this tuple.
stat_float_times([newvalue])
Returns True if the times returned by stat() are floating-point numbers instead of integers. The behavior can be changed by supplying a Boolean value for newvalue.
statvfs(path)
Performs a statvfs() system call on the given path to get information about the file system. The return value is an object whose attributes describe the file system. Common attributes include:

The returned object also behaves like a tuple containing these attributes in the order listed. The standard module statvfs defines constants that can be used to extract information from the returned statvfs data (UNIX).
symlink(src, dst)
Creates a symbolic link named dst that points to src.
Removes the file path. Same as remove().
utime(path, (atime, mtime))
Sets the access and modified time of the file to the given values. (The second argument is a tuple of two items.) The time arguments are specified in terms of the numbers returned by the time.time() function.
walk(top [, topdown [, onerror [,followlinks]]])
Creates a generator object that walks through a directory tree. top specifies the top of the directory, and topdown is a Boolean that indicates whether to traverse directories in a top-down (the default) or bottom-up order. The returned generator produces tuples (dirpath, dirnames, filenames) where dirpath is a string containing the path to the directory, dirnames is a list of all subdirectories in dirpath, and filenames is a list of the files in dirpath, not including directories. The onerror parameter is a function accepting a single argument. If any errors occur during processing, this function will be called with an instance of os.error. The default behavior is to ignore errors. If a directory is walked in a top-down manner, modifications to dirnames will affect the walking process. For example, if directories are removed from dirnames, those directories will be skipped. By default, symbolic links are not followed unless the followlinks argument is set to True.
Process Management
The following functions and variables are used to create, destroy, and manage processes:
abort()
Generates a SIGABRT signal that’s sent to the calling process. Unless the signal is caught with a signal handler, the default is for the process to terminate with an error.
defpath
This variable contains the default search path used by the exec*p*() functions if the environment doesn’t have a 'PATH' variable.
execl(path, arg0, arg1, ...)
Equivalent to execv(path, (arg0, arg1, ...)).
execle(path, arg0, arg1, ..., env)
Equivalent to execve(path, (arg0, arg1, ...), env).
execlp(path, arg0, arg1, ...)
Equivalent to execvp(path, (arg0, arg1, ...)).
execv(path, args)
Executes the program path with the argument list args, replacing the current process (that is, the Python interpreter). The argument list may be a tuple or list of strings.
Executes a new program like execv() but additionally accepts a dictionary, env, that defines the environment in which the program runs. env must be a dictionary mapping strings to strings.
execvp(path, args)
Like execv(path, args) but duplicates the shell’s actions in searching for an executable file in a list of directories. The directory list is obtained from environ['PATH'].
execvpe(path, args, env)
Like execvp() but with an additional environment variable as in the execve() function.
_exit(n)
Exits immediately to the system with status n, without performing any cleanup actions. This is typically only done in child processes created by fork(). This is also different than calling sys.exit(), which performs a graceful shutdown of the interpreter. The exit code n is application-dependent, but a value of 0 usually indicates success, whereas a nonzero value indicates an error of some kind. Depending on the system, a number of standard exit code values may be defined:
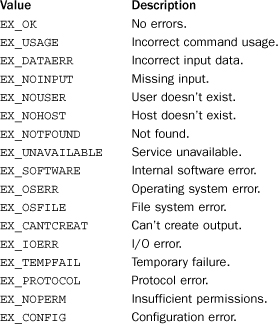
fork()
Creates a child process. Returns 0 in the newly created child process and the child’s process ID in the original process. The child process is a clone of the original process and shares many resources such as open files (UNIX).
Creates a child process using a new pseudo-terminal as the child’s controlling terminal. Returns a pair (pid, fd), in which pid is 0 in the child and fd is a file descriptor of the master end of the pseudo-terminal. This function is available only in certain versions of UNIX.
kill(pid, sig)
Sends the process pid the signal sig. A list of signal names can be found in the signal module (UNIX).
killpg(pgid, sig)
Sends the process group pgid the signal sig. A list of signal names can be found in the signal module (UNIX).
nice(increment)
Adds an increment to the scheduling priority (the “niceness”) of the process. Returns the new niceness. Typically, users can only decrease the priority of a process because increasing the priority requires root access. The effect of changing the priority is system-dependent, but decreasing the priority is commonly done to make a process run in the background in a way such that it doesn’t noticeably impact the performance of other processes (UNIX).
plock(op)
Locks program segments into memory, preventing them from being swapped. The value of op is an integer that determines which segments are locked. The value of op is platform-specific but is typically one of UNLOCK, PROCLOCK, TXTLOCK, or DATLOCK. These constants are not defined by Python but might be found in the <sys/lock.h> header file. This function is not available on all platforms and often can be performed only by a process with an effective user ID of 0 (root) (UNIX).
popen(command [, mode [, bufsize]])
Opens a pipe to or from a command. The return value is an open file object connected to the pipe, which can be read or written depending on whether mode is 'r' (the default) or 'w'. bufsize has the same meaning as in the built-in open() function. The exit status of the command is returned by the close() method of the returned file object, except that when the exit status is zero, None is returned.
spawnv(mode, path, args)
Executes the program path in a new process, passing the arguments specified in args as command-line parameters. args can be a list or a tuple. The first element of args should be the name of the program. mode is one of the following constants:

spawnv() is available on Windows and some versions of UNIX.
spawnve(mode, path, args, env)
Executes the program path in a new process, passing the arguments specified in args as command-line parameters and the contents of the mapping env as the environment. args can be a list or a tuple. mode has the same meaning as described for spawnv().
spawnl(mode, path, arg1, ..., argn)
The same as spawnv() except that all the arguments are supplied as extra parameters.
spawnle(mode, path, arg1, ... , argn, env)
The same as spawnve() except that the arguments are supplied as parameters. The last parameter is a mapping containing the environment variables.
spawnlp(mode, file, arg1, ... , argn)
The same as spawnl() but looks for file using the settings of the PATH environment variable (UNIX).
spawnlpe(mode, file, arg1, ... , argn, env)
The same as spawnle() but looks for file using the settings of the PATH environment variable (UNIX).
spawnvp(mode, file, args)
The same as spawnv() but looks for file using the settings of the PATH environment variable (UNIX).
spawnvpe(mode, file, args, env)
The same as spawnve() but looks for file using the settings of the PATH environment variable (UNIX).
startfile(path [, operation])
Launches the application associated with the file path. This performs the same action as would occur if you double-clicked the file in Windows Explorer. The function returns as soon as the application is launched. Furthermore, there is no way to wait for completion or to obtain exit codes from the application. path is a relative to the current directory. operation is an optional string that specifies the action to perform when opening path. By default, it is set to 'open’, but it may be set to 'print', 'edit', 'explore', or 'find' (the exact list depends on the type of path (Windows)).
system(command)
Executes command (a string) in a subshell. On UNIX, the return value is the exit status of the process as returned by wait(). On Windows, the exit code is always 0. The subprocess module provides considerably more power and is the preferred way to launch subprocesses.
Returns a 5-tuple of floating-point numbers indicating accumulated times in seconds. On UNIX, the tuple contains the user time, system time, children’s user time, children’s system time, and elapsed real time in that order. On Windows, the tuple contains the user time, system time, and zeros for the other three values.
wait([pid])
Waits for completion of a child process and returns a tuple containing its process ID and exit status. The exit status is a 16-bit number whose low byte is the signal number that killed the process and whose high byte is the exit status (if the signal number is zero). The high bit of the low byte is set if a core file was produced. pid, if given, specifies the process to wait for. If it’s omitted, wait() returns when any child process exits (UNIX).
waitpid(pid, options)
Waits for a change in the state of a child process given by process ID pid and returns a tuple containing its process ID and exit status indication, encoded as for wait(). options should be 0 for normal operation or WNOHANG to avoid hanging if no child process status is available immediately. This function can also be used to gather information about child processes that have only stopped executing for some reason. Setting options to WCONTINUED gathers information from a child when it resumes operation after being stopped via job control. Setting options to WUNTRACED gathers information from a child that has been stopped, but from which no status information has been reported yet.
wait3([options])
The same as waitpid() except that the function waits for a change in any child process. Returns a 3-tuple (pid, status, rusage), where pid is the child process ID, status is the exit status code, and rusage contains resource usage information as returned by resource.getrusage(). The options parameter has the same meaning as for waitpid().
wait4(pid, options)
The same as waitpid() except that the return result is the same tuple as returned by wait3().
The following functions take a process status code as returned by waitpid(), wait3(), or wait4() and are used to examine the state of the process (UNIX).
WCOREDUMP(status)
Returns True if the process dumped core.
WIFEXITED(status)
Returns True if the process exited using the exit() system call.
WEXITSTATUS(status)
If WIFEXITED(status) is true, the integer parameter to the exit() system call is returned. Otherwise, the return value is meaningless.
Returns True if the process has resumed from a job-control stop.
WIFSIGNALED(status)
Returns True if the process exited due to a signal.
WIFSTOPPED(status)
Returns True if the process has been stopped.
WSTOPSIG(status)
Returns the signal that caused the process to stop.
WTERMSIG(status)
Returns the signal that caused the process to exit.
System Configuration
The following functions are used to obtain system configuration information:
confstr(name)
Returns a string-valued system configuration variable. name is a string specifying the name of the variable. The acceptable names are platform-specific, but a dictionary of known names for the host system is found in os.confstr_names. If a configuration value for a specified name is not defined, the empty string is returned. If name is unknown, ValueError is raised. An OSError may also be raised if the host system doesn’t support the configuration name. The parameters returned by this function mostly pertain to the build environment on the host machine and include paths of system utilities, compiler options for various program configurations (for example, 32-bit, 64-bit, and large-file support), and linker options (UNIX).
getloadavg()
Returns a 3-tuple containing the average number of items in the system run-queue over the last 1, 5, and 15 minutes (UNIX).
sysconf(name)
Returns an integer-valued system-configuration variable. name is a string specifying the name of the variable. The names defined on the host system can be found in the dictionary os.sysconf_names. Returns -1 if the configuration name is known but the value is not defined. Otherwise, a ValueError or OSError may be raised. Some systems may define more than 100 different system parameters. However, the following list details the parameters defined by POSIX.1 that should be available on most UNIX systems:

Returns a string containing n random bytes generated by the system (for example, /dev/urandom on UNIX). The returned bytes are suitable for cryptography.
Exceptions
The os module defines a single exception to indicate errors.
error
Exception raised when a function returns a system-related error. This is the same as the built-in exception OSError. The exception carries two values: errno and strerr. The first contains the integer error value as described for the errno module. The latter contains a string error message. For exceptions involving the file system, the exception also contains a third attribute, filename, which is the filename passed to the function.
os.path
The os.path module is used to manipulate pathnames in a portable manner. It’s imported by the os module.
abspath(path)
Returns an absolute version of the path name path, taking the current working directory into account. For example, abspath('../Python/foo') might return '/home/beazley/Python/foo'.
basename(path)
Returns the base name of path name path. For example, basename('/usr/local/python') returns 'python'.
commonprefix(list)
Returns the longest string that’s a prefix of all strings in list. If list is empty, the empty string is returned.
dirname(path)
Returns the directory name of path name path. For example, dirname('/usr/local/ python') returns '/usr/local'.
exists(path)
Returns True if path refers to an existing path. Returns False if path refers to a broken symbolic link.
Replaces path names of the form '~user' with a user’s home directory. If the expansion fails or path does not begin with '~', the path is returned unmodified.
expandvars(path)
Expands environment variables of the form '$name' or '${name}' in path. Malformed or nonexistent variable names are left unchanged.
getatime(path)
Returns the time of last access as the number of seconds since the epoch (see the time module). The return value may be a floating-point number if os.stat_float_times() returns True.
getctime(path)
Returns the time of last modification on UNIX and the time of creation on Windows. The time is returned as the number of seconds since the epoch (see the time module). The return value may be a floating-point number in certain cases (see getatime()).
getmtime(path)
Returns the time of last modification as the number of seconds since the epoch (see the time module). The return value may be a floating-point number in certain cases (see getatime()).
getsize(path)
Returns the file size in bytes.
isabs(path)
Returns True if path is an absolute path name (begins with a slash).
isfile(path)
Returns True if path is a regular file. This function follows symbolic links, so both islink() and isfile() can be true for the same path.
isdir(path)
Returns True if path is a directory. Follows symbolic links.
islink(path)
Returns True if path refers to a symbolic link. Returns False if symbolic links are unsupported.
ismount(path)
Returns True if path is a mount point.
join(path1 [, path2 [, ...]])
Intelligently joins one or more path components into a pathname. For example, join('home', 'beazley', 'Python') returns 'home/beazley/Python'.
lexists(path)
Returns True if path exists. Returns True for all symbolic links, even if the link is broken.
Normalizes the case of a path name. On non-case-sensitive file systems, this converts path to lowercase. On Windows, forward slashes are also converted to backslashes.
normpath(path)
Normalizes a path name. This collapses redundant separators and up-level references so that 'A//B', 'A/./B', and 'A/foo/../B' all become 'A/B'. On Windows, forward slashes are converted to backslashes.
realpath(path)
Returns the real path of path, eliminating symbolic links if any (UNIX).
relpath(path [, start])
Returns a relative path to path from the current working directory. start can be supplied to specify a different starting directory.
samefile(path1, path2)
Returns True if path1 and path2 refer to the same file or directory (UNIX).
sameopenfile(fp1, fp2)
Returns True if the open file objects fp1 and fp2 refer to the same file (UNIX).
samestat(stat1, stat2)
Returns True if the stat tuples stat1 and stat2 as returned by fstat(), lstat(), or stat() refer to the same file (UNIX).
split(path)
Splits path into a pair (head, tail), where tail is the last pathname component and head is everything leading up to that. For example, '/home/user/foo' gets split into ('/home/ user', 'foo'). This tuple is the same as would be returned by (dirname(), basename()).
splitdrive(path)
Splits path into a pair (drive, filename) where drive is either a drive specification or the empty string. drive is always the empty string on machines without drive specifications.
splitext(path)
Splits a path name into a base filename and suffix. For example, splitext('foo.txt') returns ('foo', '.txt').
splitunc(path)
Splits a path name into a pair (unc,rest) where unc is a UNC (Universal Naming Convention) mount point and rest the remainder of the path (Windows).
supports_unicode_filenames
Variable set to True if the file system allows Unicode filenames.
Note
On Windows, some care is required when working with filenames that include a drive letter (for example, 'C:spam.txt'). In most cases, filenames are interpreted as being relative to the current working directory. For example, if the current directory is 'C:Foo', then the file 'C:spam.txt' is interpreted as the file 'C:FooC:spam.txt', not the file 'C:spam.txt'.
signal
The signal module is used to write signal handlers in Python. Signals usually correspond to asynchronous events that are sent to a program due to the expiration of a timer, arrival of incoming data, or some action performed by a user. The signal interface emulates that of UNIX, although parts of the module are supported on other platforms.
alarm(time)
If time is nonzero, a SIGALRM signal is scheduled to be sent to the program in time seconds. Any previously scheduled alarm is canceled. If time is zero, no alarm is scheduled and any previously set alarm is canceled. Returns the number of seconds remaining before any previously scheduled alarm or zero if no alarm was scheduled (UNIX).
getsignal(signalnum)
Returns the signal handler for signal signalnum. The returned object is a callable Python object. The function may also return SIG_IGN for an ignored signal, SIG_DFL for the default signal handler, or None if the signal handler was not installed from the Python interpreter.
getitimer(which)
Returns the current value of an internal timer identified by which.
pause()
Goes to sleep until the next signal is received (UNIX).
set_wakeup_fd(fd)
Sets a file descriptor fd on which a '�' byte will be written when a signal is received. This, in turn, can be used to handle signals in programs that are polling file descriptors using functions such as those found in the select module. The file described by fd must be opened in non-blocking mode for this to work.
setitimer(which, seconds [, interval])
Sets an internal timer to generate a signal after seconds seconds and repeatedly thereafter every interval seconds. Both of these parameters are specified as floating-point numbers. The which parameter is one of ITIMER_REAL, ITIMER_VIRTUAL, or ITIMER_PROF. The choice of which determines what signal is generated after the timer has expired. SIGALRM is generated for ITIMER_REAL, SIGVTALRM is generated for ITIMER_VIRTUAL, and SIGPROF is generated for ITIMER_PROF. Set seconds to 0 to clear a timer. Returns a tuple (seconds, interval) with the previous settings of the timer.
siginterrupt(signalnum, flag)
Sets the system call restart behavior for a given signal number. If flag is False, system calls interrupted by signal signalnum will be automatically restarted. If set True, the system call will be interrupted. An interrupted system call will typically result in an OSError or IOError exception where the associated error number is set to errno.EINTR or errno.EAGAIN.
signal(signalnum, handler)
Sets a signal handler for signal signalnum to the function handler. handler must be a callable Python object taking two arguments: the signal number and frame object. SIG_IGN or SIG_DFL can also be given to ignore a signal or use the default signal handler, respectively. The return value is the previous signal handler, SIG_IGN, or SIG_DFL. When threads are enabled, this function can only be called from the main thread. Otherwise, a ValueError exception is raised.
Individual signals are identified using symbolic constants of the form SIG*. These names correspond to integer values that are machine-specific. Typical values are as follows:

In addition, the module defines the following variables:

Example
The following example illustrates a timeout on establishing a network connection (the socket module already provides a timeout option so this example is merely meant to illustrate the basic concept of using the signal module).
Notes
• Signal handlers remain installed until explicitly reset, with the exception of SIGCHLD (whose behavior is implementation-specific).
• It’s not possible to temporarily disable signals.
• Signals are only handled between the atomic instructions of the Python interpreter. The delivery of a signal can be delayed by long-running calculations written in C (as might be performed in an extension module).
• If a signal occurs during an I/O operation, the I/O operation may fail with an exception. In this case, the errno value is set to errno.EINTR to indicate an interrupted system call.
• Certain signals such as SIGSEGV cannot be handled from Python.
• Python installs a small number of signal handlers by default. SIGPIPE is ignored, SIGINT is translated into a KeyboardInterrupt exception, and SIGTERM is caught in order to perform cleanup and invoke sys.exitfunc.
• Extreme care is needed if signals and threads are used in the same program. Currently, only the main thread of execution can set new signal handlers or receive signals.
• Signal handling on Windows is of only limited functionality. The number of supported signals is extremely limited on this platform.
subprocess
The subprocess module contains functions and objects that generalize the task of creating new processes, controlling input and output streams, and handling return codes. The module centralizes functionality contained in a variety of other modules such as os, popen2, and commands.
Popen(args, **parms)
Executes a new command as a subprocess and returns a Popen object representing the new process. The command is specified in args as either a string, such as 'ls -l', or as a list of strings, such as ['ls', '-l']. parms represents a collection of keyword arguments that can be set to control various properties of the subprocess. The following keyword parameters are understood:


call(args, **parms)
This function is exactly the same as Popen(), except that it simply executes the command and returns its status code instead (that is, it does not return a Popen object). This function is useful if you just want to execute a command but are not concerned with capturing its output or controlling it in other ways. The parameters have the same meaning as with Popen().
check_call(args, **parms)
The same as call() except that if the exit code is non-zero, the CalledProcessError exception is raised. This exception has the exit code stored in its returncode attribute.
The Popen object p returned by Popen() has a variety of methods and attributes that can be used for interacting with the subprocess.
p.communicate([input])
Communicates with the child process by sending the data supplied in input to the standard input of the process. Once data is sent, the method waits for the process to terminate while collecting output received on standard output and standard error. Returns a tuple (stdout, stderr) where stdout and stderr are strings. If no data is sent to the child process, input is set to None (the default).
p.kill()
Kills the subprocess by sending it a SIGKILL signal on UNIX or calling the p.terminate() method on Windows.
p.poll()
Checks to see if p has terminated. If so, the return code of the subprocess is returned. Otherwise, None is returned.
p.send_signal(signal)
Sends a signal to the subprocess. signal is a signal number as defined in the signal module. On Windows, the only supported signal is SIGTERM.
Terminates the subprocess by sending it a SIGTERM signal on UNIX or calling the Win32 API TerminateProcess function on Windows.
p.wait()
Waits for p to terminate and returns the return code.
p.pid
Process ID of the child process.
p.returncode
Numeric return code of the process. If None, the process has not terminated yet. If negative, it indicates the process was terminated by a signal (UNIX).
p.stdin, p.stdout, p.stderr
These three attributes are set to open file objects whenever the corresponding I/O stream is opened as a pipe (for example, setting the stdout argument in Popen() to PIPE). These file objects are provided so that the pipe can be connected to other subprocesses. These attributes are set to None if pipes are not in use.
Examples

Notes
• As a general rule, it is better to supply the command line as a list of strings instead of a single string with a shell command (for example, ['wc','filename'] instead of 'wc filename'). On many systems, it is common for filenames to include funny characters and spaces (for example, the “Documents and Settings” folder on Windows). If you stick to supplying command arguments as a list, everything will work normally. If you try to form a shell command, you will have to take additional steps to make sure special characters and spaces are properly escaped.
• On Windows, pipes are opened in binary file mode. Thus, if you are reading text output from a subprocess, line endings will include the extra carriage return character ('
' instead of '
'). If this is a concern, supply the universal_newlines option to Popen().
• The subprocess module can not be used to control processes that expect to be running in a terminal or TTY. The most common example is any program that expects a user to enter a password (such as ssh, ftp, svn, and so on). To control these programs, look for third-party modules based on the popular “Expect” UNIX utility.
time
The time module provides various time-related functions. In Python, time is measured as the number of seconds since the epoch. The epoch is the beginning of time (the point at which time = 0 seconds). The epoch is January 1, 1970, on UNIX and can be determined by calling time.gmtime(0) on other systems.
The following variables are defined:
accept2dyear
A Boolean value that indicates whether two-digit years are accepted. Normally this is True, but it’s set to False if the environment variable $PYTHONY2K is set to a non-empty string. The value can be changed manually as well.
altzone
The time zone used during daylight saving time (DST), if applicable.
daylight
Is set to a nonzero value if a DST time zone has been defined.
timezone
The local (non-DST) time zone.
tzname
A tuple containing the name of the local time zone and the name of the local daylight saving time zone (if defined).
The following functions can be used:
asctime([tuple])
Converts a tuple representing a time as returned by gmtime() or localtime() to a string of the form 'Mon Jul 12 14:45:23 1999'. If no arguments are supplied, the current time is used.
clock()
Returns the current CPU time in seconds as a floating-point number.
ctime([secs])
Converts a time expressed in seconds since the epoch to a string representing local time. ctime(secs) is the same as asctime(localtime(. If secs))secs is omitted or None, the current time is used.
Converts a time expressed in seconds since the epoch to a time in UTC Coordinated Universal Time (a.k.a. Greenwich Mean Time). This function returns a struct_time object with the following attributes:
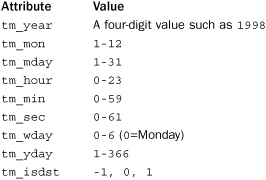
The tm_isdst attribute is 1 if DST is in effect, 0 if not, and -1 if no information is available. If secs is omitted or None, the current time is used. For backward compatibility, the returned struct_time object also behaves like a 9-tuple containing the preceding attribute values in the same order as listed.
localtime([secs])
Returns a struct_time object as with gmtime(), but corresponding to the local time zone. If secs is omitted or None, the current time is used.
mktime(tuple)
This function takes a struct_time object or tuple representing a time in the local time zone (in the same format as returned by localtime()) and returns a floating-point number representing the number of seconds since the epoch. An OverflowError exception is raised if the input value is not a valid time.
sleep(secs)
Puts the current process to sleep for secs seconds. secs is a floating-point number.
strftime(format [, tm])
Converts a struct_time object tm representing a time as returned by gmtime() or localtime() to a string (for backwards compatibility, tm may also be a tuple representing a time value). format is a format string in which the following format codes can be embedded:
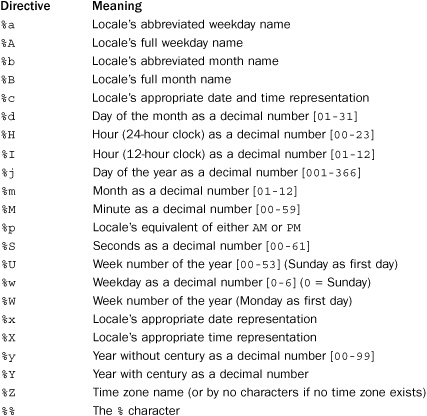
The format codes can include a width and precision in the same manner as used with the % operator on strings. ValueError is raised if any of the tuple fields are out of range. If tuple is omitted, the time tuple corresponding to the current time is used.
strptime(string [, format])
Parses a string representing a time and returns a struct_time object as returned by localtime() or gmtime(). The format parameter uses the same specifiers as used by strftime() and defaults to '%a %b %d %H:%M:%S %Y'. This is the same format as produced by the ctime() function. If the string cannot be parsed, a ValueError exception is raised.
time()
Returns the current time as the number of seconds since the epoch in UTC (Coordinated Universal Time).
tzset()
Resets the time zone setting based on the value of the TZ environment variable on UNIX. For example:

Notes
• When two-digit years are accepted, they’re converted to four-digit years according to the POSIX X/Open standard, where the values 69-99 are mapped to 1969-1999 and the values 0-68 are mapped to 2000-2068.
• The accuracy of the time functions is often much less than what might be suggested by the units in which time is represented. For example, the operating system might only update the time 50–100 times a second.
See Also:
datetime (p. 336)
winreg
The winreg module (_winreg in Python 2) provides a low-level interface to the Windows registry. The registry is a large hierarchical tree in which each node is called a key. The children of a particular key are known as subkeys and may contain additional subkeys or values. For example, the setting of the Python sys.path variable is typically contained in the registry as follows:
HKEY_LOCAL_MACHINESoftwarePythonPythonCore2.6PythonPath
In this case, Software is a subkey of HKEY_LOCAL_MACHINE, Python is a subkey of Software, and so forth. The value of the PythonPath key contains the actual path setting.
Keys are accessed through open and close operations. Open keys are represented by special handles (which are wrappers around the integer handle identifiers normally used by Windows).
CloseKey(key)
Closes a previously opened registry key with handle key.
ConnectRegistry(computer_name, key)
Returns a handle to a predefined registry key on another computer. computer_name is the name of the remote machine as a string of the \computername. If computer_name is None, the local registry is used. key is a predefined handle such as HKEY_CURRENT_USER or HKEY_ USERS. Raises EnvironmentError on failure. The following list shows all HKEY_* values defined in the _winreg module:
• HKEY_CLASSES_ROOT
• HKEY_CURRENT_CONFIG
• HKEY_CURRENT_USER
• HKEY_DYN_DATA
• HKEY_LOCAL_MACHINE
• HKEY_PERFORMANCE_DATA
• HKEY_USERS
CreateKey(key, sub_key)
Creates or opens a key and returns a handle. key is a previously opened key or a predefined key defined by the HKEY_* constants. sub_key is the name of the key that will be opened or created. If key is a predefined key, sub_key may be None, in which case key is returned.
Deletes sub_key. key is an open key or one of the predefined HKEY_* constants. sub_key is a string that identifies the key to delete. sub_key must not have any subkeys; otherwise, EnvironmentError is raised.
DeleteValue(key, value)
Deletes a named value from a registry key. key is an open key or one of the predefined HKEY_* constants. value is a string containing the name of the value to remove.
EnumKey(key, index)
Returns the name of a subkey by index. key is an open key or one of the predefined HKEY_* constants. index is an integer that specifies the key to retrieve. If index is out of range, an EnvironmentError is raised.
EnumValue(key, index)
Returns a value of an open key. key is an open key or a predefined HKEY_* constant. index is an integer specifying the value to retrieve. The function returns a tuple (name, data, type) in which name is the value name, data is an object holding the value data, and type is an integer that specifies the type of the value data. The following type codes are currently defined:

ExpandEnvironmentStrings(s)
Expands environment strings of the form % in Unicode string name%s.
FlushKey(key)
Writes the attributes of key to the registry, forcing changes to disk. This function should only be called if an application requires absolute certainty that registry data is stored on disk. It does not return until data is written. It is not necessary to use this function under normal circumstances.
RegLoadKey(key, sub_key, filename)
Creates a subkey and stores registration information from a file into it. key is an open key or a predefined HKEY_* constant. sub_key is a string identifying the subkey to load. filename is the name of the file from which to load data. The contents of this file must be created with the SaveKey() function, and the calling process must have SE_RESTORE_PRIVILEGE for this to work. If key was returned by ConnectRegistry(), filename should be a path that’s relative to the remote computer.
OpenKey(key, sub_key[, res [, sam]])
Opens a key. key is an open key or an HKEY_* constant. sub_key is a string identifying the subkey to open. res is a reserved integer that must be zero (the default). sam is an integer defining the security access mask for the key. The default is KEY_READ. Here are the other possible values for sam:
• KEY_ALL_ACCESS
• KEY_CREATE_LINK
• KEY_CREATE_SUB_KEY
• KEY_ENUMERATE_SUB_KEYS
• KEY_EXECUTE
• KEY_NOTIFY
• KEY_QUERY_VALUE
• KEY_READ
• KEY_SET_VALUE
• KEY_WRITE
OpenKeyEx()
Same as OpenKey().
QueryInfoKey(key)
Returns information about a key as a tuple (num_subkeys, num_values, last_modified) in which num_subkeys is the number of subkeys, num_values is the number of values, and last_modified is a long integer containing the time of last modification. Time is measured from January 1, 1601, in units of 100 nanoseconds.
QueryValue(key,sub_key)
Returns the unnamed value for a key as a string. key is an open key or an HKEY_* constant. sub_key is the name of the subkey to use, if any. If omitted, the function returns the value associated with key instead. This function returns the data for the first value with a null name. However, the type is returned (use QueryValueEx instead).
QueryValueEx(key, value_name)
Returns a tuple (value, type) containing the data value and type for a key. key is an open key or HKEY_* constant. value_name is the name of the value to return. The returned type is one of the integer codes as described for the EnumValue() function.
SaveKey(key, filename)
Saves key and all its subkeys to a file. key is an open key or a predefined HKEY_* constant. filename must not already exist and should not include a filename extension. Furthermore, the caller must have backup privileges for the operation to succeed.
SetValue(key, sub_key, type, value)
Sets the value of a key. key is an open key or HKEY_* constant. sub_key is the name of the subkey with which to associate the value. type is an integer type code, currently limited to REG_SZ. value is a string containing the value data. If sub_key does not exist, it is created. key must have been opened with KEY_SET_VALUE access for this function to succeed.
SetValueEx(key, value_name, reserved, type, value)
Sets the value field of a key. key is an open key or an HKEY_* constant. value_name is the name of the value. type is an integer type code as described for the EnumValue() function. value is a string containing the new value. When the values of numeric types (for example, REG_DWORD) are being set, value is still a string containing the raw data. This string can be created using the struct module. reserved is currently ignored and can be set to anything (the value is not used).
Notes
• Functions that return a Windows HKEY object return a special registry handle object described by the class PyHKEY. This object can be converted into a Windows handle value using int(). This object can also be used with the context-management protocol to automatically close the underlying handle—for example:
with winreg.OpenKey(winreg.HKEY_LOCAL_MACHINE, "spam") as key:
statements