
22. Internet Application Programming
This chapter describes modules related to Internet application protocols including HTTP, XML-RPC, FTP, and SMTP. Web programming topics such as CGI scripting are covered in Chapter 23, “Web Programming.” Modules related to dealing with common Internet-related data formats are covered in Chapter 24, “Internet Data Handling and Encoding.”
The organization of network-related library modules is one area where there are significant differences between Python 2 and 3. In the interest of looking forward, this chapter assumes the Python 3 library organization because it is more logical. However, the functionality provided by the library modules is virtually identical between Python versions as of this writing. When applicable, Python 2 module names are noted in each section.
ftplib
The ftplib module implements the client side of the FTP protocol. It’s rarely necessary to use this module directly because the urllib package provides a higher-level interface. However, this module may still be useful if you want to have more control over the low-level details of an FTP connection. In order to use this module, it may be helpful to know some of the details of the FTP protocol which is described in Internet RFC 959.
A single class is defined for establishing an FTP connection:
FTP([host [, user [, passwd [, acct [, timeout]]]]])
Creates an object representing an FTP connection. host is a string specifying a host name. user, passwd, and acct optionally specify a username, password, and account. If no arguments are given, the connect() and login() methods must be called explicitly to initiate the actual connection. If host is given, connect() is automatically invoked. If user, passwd, and acct are given, login() is invoked. timeout is a timeout period in seconds.
An instance f of FTP has the following methods:
f.abort()
Attempts to abort a file transfer that is in progress. This may or may not work depending the remote server.
Closes the FTP connection. After this has been invoked, no further operations can be performed on the FTP object f.
f.connect(host [, port [, timeout]])
Opens an FTP connection to a given host and port. host is a string specifying the host name. port is the integer port number of the FTP server and defaults to port 21. timeout is the timeout period in seconds. It is not necessary to call this if a host name was already given to FTP().
f.cwd(pathname)
Changes the current working directory on the server to pathname.
f.delete(filename)
Removes the file filename from the server.
f.dir([dirname [, ... [, callback]]])
Generates a directory listing as produced by the 'LIST' command. dirname optionally supplies the name of a directory to list. In addition, if any additional arguments are supplied, they are simply passed as additional arguments to 'LIST’. If the last argument callback is a function, it is used as a callback function to process the returned directory listing data. This callback function works in the same way as the callback used by the retrlines() method. By default, this method prints the directory list to sys.stdout.
f.login([user, [passwd [, acct]]])
Logs in to the server using the specified username, password, and account. user is a string giving the username and defaults to 'anonymous'. passwd is a string containing the password and defaults to the empty string ''. acct is a string and defaults to the empty string. It is not necessary to call this method if this information was already given to FTP().
f.mkd(pathname)
Creates a new directory on the server.
f.ntransfercmd(command [, rest])
The same as transfercmd() except that a tuple (sock, size) is returned where sock is a socket object corresponding to the data connection and size is the expected size of the data in bytes, or None if the size could not be determined.
f.pwd()
Returns a string containing the current working directory on the server.
f.quit()
Closes the FTP connection by sending the 'QUIT' command to the server.
f.rename(oldname,newname)
Renames a file on the server.
f.retrbinary(command, callback [, blocksize [, rest]])
Returns the results of executing a command on the server using binary transfer mode. command is a string that specifies the appropriate file retrieval command and is almost always 'RETR filename'. callback is a callback function that is invoked each time a block of data is received. This callback function is invoked with a single argument which is the received data in the form of a string. blocksize is the maximum block size to use and defaults to 8192 bytes. rest is an optional offset into the file. If supplied, this specifies the position in the file where you want to start the transfer. However, this is not supported by all FTP servers so this may result in an error_reply exception.
f.retrlines(command [, callback])
Returns the results of executing a command on the server using text transfer mode. command is a string that specifies the command and is usually something like 'RETR filename'. callback is a callback function that is invoked each time a line of data is received. This callback function is called with a single argument which is a string containing the received data. If callback is omitted, the returned data is printed to sys.stdout.
f.rmd(pathname)
Removes a directory from the server.
f.sendcmd(command)
Sends a simple command to the server and returns the server response. command is a string containing the command. This method should only be used for commands that don’t involve the transfer of data.
f.set_pasv(pasv)
Sets passive mode. pasv is a Boolean flag that turns passive mode on if True or off if False. By default, passive mode is on.
f.size(filename)
Returns the size of filename in bytes. Returns None if the size can’t be determined for some reason.
f.storbinary(command, file [, blocksize])
Executes a command on the server and transmits data using binary transfer mode. command is a string that specifies the low-level command. It is almost always set to 'STOR filename', where filename is the name of a file you want to place on the server. file is an open file-object from which data will be read using file.read(blocksize) and transferred to the server. blocksize is the blocksize to use in the transfer. By default, it is 8192 bytes.
f.storlines(command, file)
Executes a command on the server and transfers data using text transfer mode. command is a string which specifies the low-level command. It is usually 'STOR filename'. file is an open file-object from which data will be read using file.readline() and sent to the server.
f.transfercmd(command [, rest])
Initiates a transfer over the FTP data connection. If active mode is being used, this sends a 'PORT' or 'EPRT' command and accepts the resulting connection from the server. If passive mode is being used, this sends a 'EPSV' or 'PASV' command followed by a connection to the server. In either case, once the data connection has been established, the FTP command in command is then issued. This function returns a socket object corresponding to the open data connection. The optional rest parameter specifies a starting byte offset into files requested on the server. However, this is not supported on all servers and could result in an error_reply exception.
Example
The following example shows how to use this module to upload a file to a FTP server:
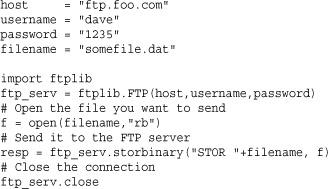
To fetch documents from an FTP server, use the urllib package. For example:

http Package
The http package consists of modules for writing HTTP clients and servers as well as support for state management (cookies). The Hypertext Transfer Protocol (HTTP) is a simple text-based protocol that works as follows:
1. A client makes a connection to an HTTP server and sends a request header of the following form:

The first line defines the request type, document (the selector), and protocol version. Following the request line is a series of header lines containing various information about the client, such as passwords, cookies, cache preferences, and client software. Following the header lines, a single blank line indicates the end of the header lines. After the header, data may appear in the event that the request is sending information from a form or uploading a file. Each of the lines in the header should be terminated by a carriage return and a newline ('
').
2. The server sends a response of the following form:
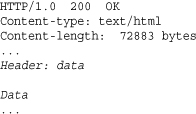
The first line of the server response indicates the HTTP protocol version, a success code, and a return message. Following the response line is a series of header fields that contain information about the type of the returned document, the document size, web server software, cookies, and so forth. The header is terminated by a single blank line followed by the raw data of the requested document.
The following request methods are the most common:

The response codes detailed in Table 22.1 are most commonly returned by servers. The Symbolic Constant column is the name of a predefined variable in http.client that holds the integer response code value and which can be used in code to improve readability.
Table 22.1 Response Codes Commonly Returned by Servers

The headers that appear in both requests and responses are encoded in a format widely known as RFC-822. Then general form of each header is Headername: data, although further details can be found in the RFC. It is almost never necessary to parse these headers as Python usually does it for you when applicable.
http.client (httplib)
The http.client module provides low-level support for the client side of HTTP. In Python 2, this module is called httplib. Use functions in the urllib package instead. The module supports both HTTP/1.0 and HTTP/1.1 and additionally allows connections via SSL if Python is built with OpenSSL support. Normally, you do not use this package directly; instead, you should consider using the urllib package. However, because HTTP is such an important protocol, you may encounter situations where you need to work with the low-level details in a way that urllib cannot easily address—for example, if you wanted to send requests with commands other than GET or POST. For more details about HTTP, consult RFC 2616 (HTTP/1.1) and RFC 1945 (HTTP/1.0).
The following classes can be used to establish an HTTP connection with a server:
HTTPConnection(host [,port])
Creates an HTTP connection. host is the host name, and port is the remote port number. The default port is 80. Returns an HTTPConnection instance.
HTTPSConnection(host [, port [, key_file=kfile [, cert_file=cfile ]]])
Creates an HTTP connection but uses a secure socket. The default port is 443. key_file and cert_file are optional keyword arguments that specify client PEM-formatted private-key and certificate chain files, should they be needed for client authentication. However, no validation of server certificates is performed. Returns an HTTPSConnection instance.
An instance, h, of HTTPConnection or HTTPSConnection supports the following methods:
h.connect()
Initializes the connection to the host and port given to HTTPConnection() or HTTPSConnection(). Other methods call this automatically if a connection hasn’t been made yet.
h.close()
Closes the connection.
h.send(bytes)
Sends a byte string, bytes, to the server. Direct use of this function is discouraged because it may break the underlying response/request protocol. It’s most commonly used to send data to the server after h.endheaders() has been called.
h.putrequest(method, selector [, skip_host [, skip_accept_encoding]])
Sends a request to the server. method is the HTTP method, such as 'GET' or 'POST'. selector specifies the object to be returned, such as '/index.html'. The skip_host and skip_accept_encoding parameters are flags that disable the sending of Host: and Accept-Encoding: headers in the HTTP request. By default, both of these arguments are False. Because the HTTP/1.1 protocol allows multiple requests to be sent over a single connection, a CannotSendRequest exception may be raised if the connection is in a state that prohibits new requests from being issued.
h.putheader(header, value, ...)
Sends an RFC-822–style header to the server. It sends a line to the server, consisting of the header, a colon and a space, and the value. Additional arguments are encoded as continuation lines in the header. Raises a CannotSendHeader exception if h is not in a state that allows headers to be sent.
h.endheaders()
Sends a blank line to the server, indicating the end of the header lines.
h.request(method, url [, body [, headers]])
Sends a complete HTTP request to the server. method and url have the same meaning as for h.putrequest(). body is an optional string containing data to upload to the server after the request has been sent. If body is supplied, the Context-length: header will automatically be set to an appropriate value. headers is a dictionary containing header:value pairs to be given to the h.putheader() method.
h.getresponse()
Gets a response from the server and returns an HTTPResponse instance that can be used to read data. Raises a ResponseNotReady exception if h is not in a state where a response would be received.
An HTTPResponse instance, r, as returned by the getresponse() method, supports the following methods:
Reads up to size bytes from the server. If size is omitted, all the data for this request is returned.
r.getheader(name [,default])
Gets a response header. name is the name of the header. default is the default value to return if the header is not found.
r.getheaders()
Returns a list of (header, value) tuples.
An HTTPResponse instance r also has the following attributes:
r.version
HTTP version used by the server.
r.status
HTTP status code returned by the server.
r.reason
HTTP error message returned by the server.
r.length
Number of bytes left in the response.
Exceptions
The following exceptions may be raised in the course of handling HTTP connections:

The following exceptions are related to the state of HTTP/1.1 connections. Because HTTP/1.1 allows multiple requests/responses to be sent over a single connection, extra rules are imposed as to when requests can be sent and responses received. Performing operations in the wrong order will generate an exception.

Example
The following example shows how the HTTPConnection class can be used to perform a memory-efficient file upload to a server using a POST request—something that is not easily accomplished within the urllib framework.
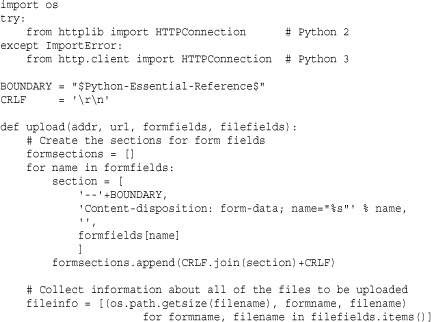
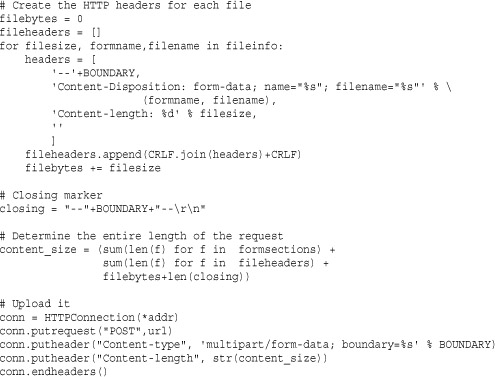

http.server (BaseHTTPServer, CGIHTTPServer, SimpleHTTPServer)
The http.server module provides various classes for implementing HTTP servers. In Python 2, the contents of this module are split across three library modules: BaseHTTPServer, CGIHTTPServer, and SimpleHTTPServer.
HTTPServer
The following class implements a basic HTTP server. In Python 2, it is located in the BaseHTTPServer module.
HTTPServer(server_address, request_handler)
Creates a new HTTPServer object. server_address is a tuple of the form (host, port) on which the server will listen. request_handler is a handler class derived from BaseHTTPRequestHandler, which is described later.
HTTPServer inherits directly from TCPServer defined in the socketserver module. Thus, if you want to customize the operation of the HTTP server in any way, you inherit from HTTPServer and extend it. Here is how you would define a multithreaded HTTP server that only accepts connections from a specific subnet:
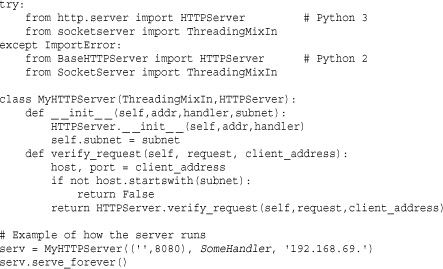
The HTTPServer class only deals with the low-level HTTP protocol. To get the server to actually do anything, you have to supply a handler class. There are two built-in handlers and a base class that can be used for defining your own custom handling. These are described next.
SimpleHTTPRequestHandler and CGIHTTPRequestHandler
Two prebuilt web server handler classes can be used if you want to quickly set up a simple stand-alone web server. These classes operate independently of any third-party web server such as Apache.
CGIHTTPRequestHandler(request, client_address, server)
Serves files from the current directory and all its subdirectories. In addition, the handler will run a file as a CGI script if it’s located in a special CGI directory (defined by the cgi_directories class variable which is set to ['/cgi-bin', '/htbin'] by default). The handler supports GET, HEAD, and POST methods. However, it does not support HTTP redirects (HTTP code 302), which limits its use to only more simple CGI applications. For security purposes, CGI scripts are executed with a UID of nobody. In Python 2, this class is defined in the CGIHTTPServer module.
SimpleHTTPRequestHandler(request, client_address, server)
Serves files from the current directory and all its subdirectories. The class provides support for HEAD and GET requests, respectively. All IOError exceptions result in a "404 File not found" error. Attempts to access a directory result in a "403 Directory listing not supported" error. In Python 2, this class is defined in the SimpleHTTPServer module.
Both of these handlers define the following class variables that can be changed via inheritance if desired:
handler.server_version
Server version string returned to clients. By default, this is set to a string such as 'SimpleHTTP/0.6'.
A dictionary mapping suffixes to MIME types. Unrecognized file types are considered to be of type 'application/octet-stream'.
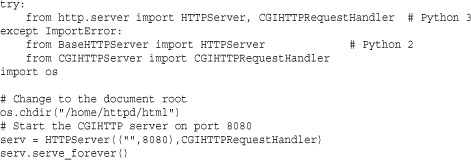
Here is an example of using these handler classes to run a stand-alone web server capable of running CGI scripts:
BaseHTTPRequestHandler
The BaseHTTPRequestHandler class is a base class that’s used if you want to define your own custom HTTP server handling. The prebuilt handlers such as SimpleHTTPRequestHandler and CGIHTTPRequestHandler inherit from this. In Python 2, this class is defined in the BaseHTTPServer module.
BaseHTTPRequestHandler(request, client_address, server)
Base handler class used to handle HTTP requests. When a connection is received, the request and HTTP headers are parsed. An attempt is then made to execute a method of the form do_REQUEST based on the request type. For example, a 'GET' method invokes do_GET() and a 'POST' method invokes do_POST. By default, this class does nothing, so these methods are expected to be defined in subclasses.
The following class variables are defined for BaseHTTPRequestHandler and can be redefined in subclasses.
BaseHTTPRequestHandler.server_version
Specifies the server software version string that the server reports to clients—for example, 'ServerName/1.2'.
BaseHTTPRequestHandler.sys_version
Python system version, such as 'Python/2.6'.
BaseHTTPRequestHandler.error_message_format
Format string used to build error messages sent to the client. The format string is applied to a dictionary containing the attributes code, message, and explain. For example:

BaseHTTPRequestHandler.protocol_version
HTTP protocol version used in responses. The default is 'HTTP/1.0'.
BaseHTTPRequestHandler.responses
Mapping of integer HTTP error codes to two-element tuples (message, explain) that describe the problem. For example, the integer code 404 is mapped to ("Not Found", "Nothing matches the given URI"). The integer code and strings in this mapping are use when creating error messages as defined in the error_message_format attribute shown previously.
When created to handle a connection, an instance, b, of BaseHTTPRequestHandler has the following attributes:

The following methods are commonly used or redefined in subclasses:
b.send_error(code [, message])
Sends a response for an unsuccessful request. code is the numeric HTTP response code. message is an optional error message. log_error() is called to record the error. This method creates a complete error response using the error_message_format class variable, sends it to the client, and closes the connection. No further operations should be performed after calling this.
b.send_response(code [, message])
Sends a response for a successful request. The HTTP response line is sent, followed by Server and Date headers. code is an HTTP response code, and message is an optional message. log_request() is called to record the request.
b.send_header(keyword, value)
Writes a MIME header entry to the output stream. keyword is the header keyword, and value is its value. This should only be called after send_response().
b.end_headers()
Sends a blank line to signal the end of the MIME headers.
b.log_request([code [, size]])
Logs a successful request. code is the HTTP code, and size is the size of the response in bytes (if available). By default, log_message() is called for logging.
b.log_error(format, ...)
Logs an error message. By default, log_message() is called for logging.
b.log_message(format, ...)
Logs an arbitrary message to sys.stderr. format is a format string applied to any additional arguments passed. The client address and current time are prefixed to every message.
Here is an example of creating a custom HTTP server that runs in a separate thread and lets you monitor the contents of a dictionary, interpreting the request path as a key.

To test this example, run the server and then enter a URL such as http://localhost:9000/name or http://localhost:9000/values into a browser. If it works, you’ll see the contents of the dictionary being displayed.
This example also shows a technique for how to get servers to instantiate handler classes with extra parameters. Normally, servers create handlers using a predefined set of arguments that are passed to _ _init_ _(). If you want to add additional parameters, use the functools.partial() function as shown. This creates a callable object that includes your extra parameter but preserves the calling signature expected by the server.
http.cookies (Cookie)
The http.cookies module provides server-side support for working with HTTP cookies. In Python 2, the module is called Cookie.
Cookies are used to provide state management in servers that implement sessions, user logins, and related features. To drop a cookie on a user’s browser, an HTTP server typically adds an HTTP header similar to the following to an HTTP response:
![]()
Alternatively, a cookie can be set by embedding JavaScript in the <head> section of an HTML document:

The http.cookies module simplifies the task of generating cookie values by providing a special dictionary-like object which stores and manages collections of cookie values known as morsels. Each morsel has a name, a value, and a set of optional attributes containing metadata to be supplied to the browser {expires, path, comment, domain, max-age, secure, version, httponly}. The name is usually a simple identifier such as "name" and must not be the same as one of the metadata names such as "expires" or "path". The value is usually a short string. To create a cookie, simply create a cookie object like this:
c = SimpleCookie()
Next, cookie values (morsels) can be set using ordinary dictionary assignment:
![]()
Additional attributes of a specific morsel are set as follows:
![]()
To create output representing the cookie data as a set of HTTP headers, use the c.output() method. For example:

When a browser sends a cookie back to an HTTP server, it is encoded as a string of key=value pairs, such as "session=8273612; user=beazley". Optional attributes such as expires, path, and domain are not returned. The cookie string can usually be found in the HTTP_COOKIE environment variable, which can be read by CGI applications. To recover cookie values, use code similar to the following:
![]()
The following documentation describes the SimpleCookie object in more detail.
Defines a cookie object in which cookie values are stored as simple strings.
A cookie instance, c, provides the following methods:
c.output([attrs [,header [,sep]]])
Generates a string suitable for use in setting cookie values in HTTP headers. attrs is an optional list of the optional attributes to include ("expires", "path", "domain", and so on). By default, all cookie attributes are included. header is the HTTP header to use ('Set-Cookie:' by default). sep is the character used to join the headers together and is a newline by default.
c.js_output([attrs])
Generates a string containing JavaScript code that will set the cookie if executed on a browser supporting JavaScript. attrs is an optional list of the attributes to include.
c.load(rawdata)
Loads the cookie c with data found in rawdata. If rawdata is a string, it’s assumed to be in the same format as the HTTP_COOKIE environment variable in a CGI program. If rawdata is a dictionary, each key-value pair is interpreted by setting c[key]=value.
Internally, the key/value pairs used to store a cookie value are instances of a Morsel class. An instance, m, of Morsel behaves like a dictionary and allows the optional "expires", "path", "comment", "domain", "max-age", "secure", "version", and "httponly" keys to be set. In addition, the morsel m has the following methods and attributes:
m.value
A string containing the raw value of the cookie.
m.coded_value
A string containing the encoded value of the cookie that would be sent to or received from the browser.
m.key
The cookie name.
m.set(key,value,coded_value)
Sets the values of m.key, m.value, and m.coded_value shown previously.
m.isReservedKey(k)
Tests whether k is a reserved keyword, such as "expires", "path", "domain", and so on.
m.output([attrs [,header]])
Produces the HTTP header string for this morsel. attrs is an optional list of the additional attributes to include ("expires", "path", and so on). header is the header string to use ('Set-Cookie:' by default).
m.js_output([attrs])
Outputs JavaScript code that sets the cookie when executed.
Returns the cookie string without any HTTP headers or JavaScript code.
Exceptions
If an error occurs during the parsing or generation of cookie values, a CookieError exception is raised.
http.cookiejar (cookielib)
The http.cookiejar module provides client-side support for storing and managing HTTP cookies. In Python 2, the module is called cookielib.
The primary role of this module is to provide objects in which HTTP cookies can be stored so that they can be used in conjunction with the urllib package, which is used to access documents on the Internet. For instance, the http.cookiejar module can be used to capture cookies and to retransmit them on subsequent connection requests. It can also be used to work with files containing cookie data such as files created by various browsers.
The following objects are defined by the module:
CookieJar()
An object that manages HTTP cookie values, storing cookies received as a result of HTTP requests, and adding cookies to outgoing HTTP requests. Cookies are stored entirely in memory and lost when the CookieJar instance is garbage-collected.
FileCookieJar(filename [, delayload ])
Creates a FileCookieJar instance that retrieves and stores cookie information to a file. filename is the name of the file. delayload, if True, enables lazy access to the file. That is, the file won’t be read or stored except by demand.
MozillaCookieJar(filename [, delayload ])
Creates a FileCookieJar instance that is compatible with the Mozilla cookies.txt file.
LWPCookieJar(filename [, delayload ])
Creates a FileCookieJar instance that is compatible with the libwww-perl Set-Cookie3 file format.
It is somewhat rare to work with the methods and attributes of these objects directly. If you need to know their low-level programming interface, consult the online documentation. Instead, it is more common to simply instantiate one of the cookie jar objects and plug it into something else that wants to work with cookies. An example of this is shown in the urllib.request section of this chapter.
smtplib
The smtplib module provides a low-level SMTP client interface that can be used to send mail using the SMTP protocol described in RFC 821 and RFC 1869. This module contains a number of low-level functions and methods that are described in detail in the online documentation. However, the following covers the most useful parts of this module:
Creates an object representing a connection to an SMTP server. If host is given, it specifies the name of the SMTP server. port is an optional port number. The default port is 25. If host is supplied, the connect() method is called automatically. Otherwise, you will need to manually call connect() on the returned object to establish the connection.
An instance s of SMTP has the following methods:
s.connect([host [, port]])
Connects to the SMTP server on host. If host is omitted, a connection is made to the local host ('127.0.0.1'). port is an optional port number that defaults to 25 if omitted. It is not necessary to call connect() if a host name was given to SMTP().
s.login(user, password)
Logs into the server if authentication is required. user is a username, and password is a password.
s.quit()
Terminates the session by sending a 'QUIT' command to the server.
s.sendmail(fromaddr, toaddrs, message)
Sends a mail message to the server. fromaddr is a string containing the email address of the sender. toaddrs is a list of strings containing the email addresses of recipients. message is a string containing a completely formatted RFC-822 compliant message. The email package is commonly used to create such messages. It is important to note that although message can be given as a text string, it should only contain valid ASCII characters with values in the range 0 to 127. Otherwise, you will get an encoding error. If you need to send a message in a different encoding such as UTF-8, encode it into a byte string first and supply the byte string as message.
Example
The following example shows how the module can be used to send a message:

urllib Package
The urllib package provides a high-level interface for writing clients that need to interact with HTTP servers, FTP servers, and local files. Typical applications include scraping data from web pages, automation, proxies, web crawlers, and so forth. This is one of the most highly configurable library modules, so every last detail is not presented here. Instead, the most common uses of the package are described.
In Python 2, the urllib functionality is spread across several different library modules including urllib, urllib2, urlparse, and robotparser. In Python 3, all of this functionality has been consolidated and reorganized under the urllib package.
urllib.request (urllib2)
The urllib.request module provides functions and classes to open and fetch data from URLs. In Python 2, this functionality is found in a module urllib2.
The most common use of this module is to fetch data from web servers using HTTP. For example, this code shows the easiest way to simply fetch a web page:

Of course, many complexities arise when interacting with servers in the real world. For example, you might have to worry about proxy servers, authentication, cookies, user agents, and other matters. All of these are supported, but the code is more complicated (keep reading).
urlopen() and Requests
The most straightforward way to make a request is to use the urlopen() function.
urlopen(url [, data [, timeout]])
Opens the URL url and returns a file-like object that can be used to read the returned data. url may either be a string containing a URL or an instance of the Request class, described shortly. data is a URL-encoded string containing form data to be uploaded to the server. When supplied, the HTTP 'POST' method is used instead of 'GET' (the default). Data is generally created using a function such as urllib.parse.urlencode(). timeout is an optional timeout in seconds for all blocking operations used internally.
The file-like object u returned by urlopen() supports the following methods:

It is important to emphasize that the file-like object u operates in binary mode. If you need to process the response data as text, you will need to decode it using the codecs module or some other means.
If an error occurs during download, an URLError exception is raised. This includes errors related to the HTTP protocol itself such as forbidden access or requests for authentication. For these kinds of errors, a server typically returns content that gives more descriptive information. To get this content, the exception instance itself operates as a file-like object that can be read. For example:

A very common error that arises with urlopen() is accessing web pages through a proxy server. For example, if your organization routes all web traffic through a proxy, requests may fail. If the proxy server doesn’t require any kind of authentication, you may be able to fix this by merely setting the HTTP_PROXY environment variable in the os.environ dictionary. For example, os.environ['HTTP_PROXY'] = 'http://example.com:12345'.
For simple requests, the url parameter to urlopen() is a string such as 'http://www.python.org'. If you need to do anything more complicated such as make modifications to HTTP request headers, create a Request instance and use that as the url parameter.
Request(url [, data [, headers [, origin_req_host [, unverifiable]]]])
Creates a new Request instance. url specifies the URL (for example, 'http://www.foo.bar/spam.html'). data is URL-encoded data to be uploaded to the server in HTTP requests. When this is supplied, it changes the HTTP request type from 'GET' to 'POST'. headers is a dictionary containing key-value mappings representing the contents of the HTTP headers. origin_req_host is set to the request-host of the transaction—typically it’s the host name from which the request is originating. unverifiable is set to True if the request is for an unverifiable URL. An unverifiable URL is informally defined as a URL not directly entered by the user—for instance, a URL embedded within a page that loads an image. The default value of unverifiable is False.
An instance r of Request has the following methods:
r.add_data(data)
Adds data to a request. If the request is an HTTP request, the method is changed to 'POST'. data is URL-encoded data as described for Request(). This does not append data to any previously set data; it simply replaces the old data with data.
r.add_header(key, val)
Adds header information to the request. key is the header name, and val is the header value. Both arguments are strings.
r.add_unredirected_header(key, val)
Adds header information to a request that will not be added to redirected requests. key and val have the same meaning as for add_header().
r.get_data()
Returns the request data (if any).
r.get_full_url()
Returns the full URL of a request.
r.get_host()
Returns the host to which the request will be sent.
r.get_method()
Returns the HTTP method, which is either 'GET' or 'POST'.
r.get_origin_req_host()
Returns the request-host of the originating transaction.
r.get_selector()
Returns the selector part of the URL (for example, '/index.html').
r.get_type()
Returns the URL type (for example, 'http').
r.has_data()
Returns True if data is part of the request.
r.is_unverifiable()
Returns True if the request is unverifiable.
r.has_header(header)
Returns True if the request has header header.
r.set_proxy(host, type)
Prepares the request for connecting to a proxy server. This replaces the original host with host and the original type of the request with type. The selector part of the URL is set to the original URL.
Here is an example that uses a Request object to change the 'User-Agent' header used by urlopen(). You might use this if you wanted a server to think you were making a connection from Internet Explorer, Firefox, or some other browser.

Custom Openers
The basic urlopen() function does not provide support for authentication, cookies, or other advanced features of HTTP. To add support, you must create your own custom opener object using the build_opener() function:
build_opener([handler1 [, handler2, ... ]])
Builds a custom opener object for opening URLs. The arguments handler1, handler2, and so on are all instances of special handler objects. The purpose of these handlers is to add various capabilities to the resulting opener object. The following lists all the available handler objects:

By default, an opener is always created with the handlers ProxyHandler, UnknownHandler, HTTPHandler, HTTPSHandler, HTTPDefaultErrorHandler, HTTPRedirectHandler, FTPHandler, FileHandler, and HTTPErrorProcessor. These handlers provide a basic level of functionality. Extra handlers supplied as arguments are added to this list. However, if any of the extra handlers are of the same type as the defaults, they take precedence. For example, if you added an instance of HTTPHandler or some class that derived from HTTPHandler, it would be used instead of the default.
The object returned by build_opener() has a method, open(url [, data [, timeout]]), that is used to open URLs according to all the rules provided by the various handlers. The arguments to open() are the same as what are passed to the urlopen() function.
install_opener(opener)
Installs a different opener object for use as the global URL opener used by urlopen(). opener is usually of an opener object created by build_opener().
The next few sections show how to create custom openers for some of the more common scenarios that arise when using urlib.request module.
Password Authentication
To handle requests involving password authentication, you create an opener with some combination of HTTPBasicAuthHandler, HTTPDigestAuthHandler, ProxyBasicAuthHandler, or ProxyDigestAuthHandler handlers added to it. Each of these handlers has the following method which can be used to set password:
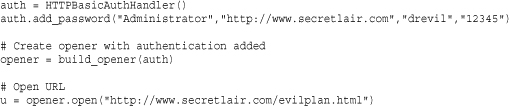
h.add_password(realm, uri, user, passwd)
Adds user and password information for a given realm and URI. All parameters are strings. uri can optionally be a sequence of URIs, in which case the user and password information is applied to all the URIs in the sequence. The realm is a name or description associated with the authentication. Its value depends on the remote server. However, it’s usually a common name associated with a collection of related web pages. uri is a base URL associated with the authentication. Typical values for realm and uri might be something like ('Administrator', 'http://www.somesite.com'). user and password specify a username and password, respectively.
Here is an example of how to set up an opener with basic authentication:
HTTP Cookies
To manage HTTP cookies, create an opener object with an HTTPCookieProcessor handler added to it. For example:
![]()
By default, the HTTPCookieProcessor uses the CookieJar object found in the http.cookiejar module. Different types of cookie processing can be supported by supplying a different CookieJar object as an argument to HTTPCookieProcessor. For example:

Proxies
If requests need to be redirected through a proxy, create an instance of ProxyHandler.
ProxyHandler([proxies])
Creates a proxy handler that routes requests through a proxy. The argument proxies is a dictionary that maps protocol names (for example, 'http', 'ftp', and so on) to the URLs of the corresponding proxy server.
The following example shows how to use this:

urllib.response
This is an internal module that implements the file-like objects returned by functions in the urllib.request module. There is no public API.
urllib.parse
The urllib.parse module is used to manipulate URL strings such as "http://www.python.org".
URL Parsing (urlparse Module in Python 2)
The general form of a URL is "scheme://netloc/path;parameters?query#fragment". In addition, the netloc part of a URL may include a port number such as "hostname:port" or user authentication information such as "user:pass@hostname". The following function is used to parse a URL:
urlparse(urlstring [, default_scheme [, allow_fragments]])
Parses the URL in urlstring and returns a ParseResult instance. default_scheme specifies the scheme ("http", "ftp", and so on) to be used if none is present in the URL. If allow_fragments is zero, fragment identifiers are not allowed. A ParseResult instance r is a named tuple the form (scheme, netloc, path, parameters, query, fragment). However, the following read-only attributes are also defined:

A ParseResult instance can be turned back into a URL string using r.geturl().
Constructs a URL string from a tuple-representation of a URL as returned by urlparse(). parts must be a tuple or iterable with six components.
urlsplit(url [, default_scheme [, allow_fragments]])
The same as urlparse() except that the parameters portion of a URL is left unmodified in the path. This allows for parsing of URLs where parameters might be attached to individual path components such as 'scheme://netloc/path1;param1/path2;param2/path3?query#fragment'. The result is an instance of SplitResult, which is a named tuple containing (scheme, netloc, path, query, fragment). The following read-only attributes are also defined:

A SplitResult instance can be turned back into a URL string using r.geturl().
urlunsplit(parts)
Constructs a URL from the tuple-representation created by urlsplit(). parts is a tuple or iterable with the five URL components.
urldefrag(url)
Returns a tuple (newurl, fragment) where newurl is url stripped of fragments and fragment is a string containing the fragment part (if any). If there are no fragments in url, then newurl is the same as url and fragment is an empty string.
urljoin(base, url [, allow_fragments])
Constructs an absolute URL by combining a base URL, base, with a relative URL. url. allow_fragments has the same meaning as for urlparse(). If the last component of the base URL is not a directory, it’s stripped.
parse_qs(qs [, keep_blank_values [, strict_parsing]])
Parses a URL-encoded (MIME type application/x-www-form-urlencoded) query string qs and returns a dictionary where the keys are the query variable names and the values are lists of values defined for each name. keep_blank_values is a Boolean flag that controls how blank values are handled. If True, they are included in the dictionary with a value set to the empty string. If False (the default), they are discarded. strict_parsing is a Boolean flag that if True, turns parsing errors into a ValueError exception. By default, errors are silently ignored.
parse_qsl(qs [, keep_blank_values [, strict_parsing]])
The same as parse_qs() except that the result is a list of pairs (name, value) where name is the name of a query variable and value is the value.
URL Encoding (urllib Module in Python 2)
The following functions are used to encode and decode data that make up URLs.
quote(string [, safe [, encoding [, errors]]])
Replaces special characters in string with escape sequences suitable for including in a URL. Letters, digits, and the underscore ( _ ), comma (,), period (.), and hyphen ( - ) characters are unchanged. All other characters are converted into escape sequences of the form '%xx'. safe provides a string of additional characters that should not be quoted and is '/' by default. encoding specifies the encoding to use for non-ASCII characters. By default, it is 'utf-8'. errors specifies what to do when encoding errors are encountered and is 'strict' by default. The encoding and errors parameters are only available in Python 3.
quote_plus(string [, safe [, encoding [, errors]]])
Calls quote() and additionally replaces all spaces with plus signs. string and safe are the same as in quote(). encoding and errors are the same as with quote().
quote_from_bytes(bytes [, safe])
The same as quote() but accepts a byte-string and performs no encoding. The return result is a text string. Python 3 only.
unquote(string [, encoding [, errors]])
Replaces escape sequences of the form '%xx' with their single-character equivalent. encoding and errors specify the encoding and error handling for decoding data in '%xx' escapes. The default encoding is 'utf-8', and the default errors policy is 'replace'. encoding and errors are Python 3 only.
unquote_plus(string [, encoding [, errors]])
Like unquote() but also replaces plus signs with spaces.
unquote_to_bytes(string)
The same as unquote() but performs no decoding and returns a byte string.
urlencode(query [, doseq])
Converts query values in query to a URL-encoded string suitable for inclusion as the query parameter of a URL or for uploading as part of a POST request. query is either a dictionary or a sequence of (key, value) pairs. The resulting string is a series of 'key=value' pairs separated by '&' characters, where both key and value are quoted using quote_plus(). The doseq parameter is a Boolean flag that should be set to True if any value in query is a sequence, representing multiple values for the same key. In this case, a separate 'key=v' string is created for each v in value.
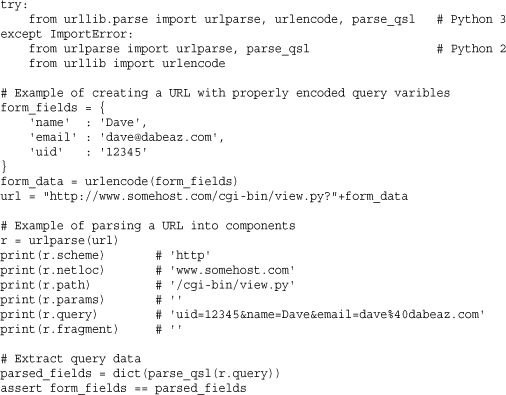
Examples
The following examples show how to turn a dictionary of query variables into a URL suitable for use in an HTTP GET request and how you can parse a URL:
urllib.error
The urllib.error module defines exceptions used by the urllib package.
ContentTooShort
Raised when the amount of downloaded data is less than the expected amount (as defined by the 'Content-Length' header). Defined in the urllib module in Python 2.
HTTPError
Raised to indicate problems with the HTTP protocol. This error may be used to signal events such as authentication required. This exception can also be used as a file object to read the data returned by the server that’s associated with the error. This is a subclass of URLError. It is defined in the urllib2 module in Python 2.
URLError
Error raised by handlers when a problem is detected. This is a subclass of IOError. The reason attribute of the exception instance has more information about the problem. This is defined in the urllib2 module in Python 2.
urllib.robotparser (robotparser)
The urllib.robotparser module (robotparser in Python 2) is used to fetch and parse the contents of 'robots.txt' files used to instruct web crawlers. Consult the online documentation for further usage information.
Notes
• Advanced users of the urllib package can customize its behavior in almost every way imaginable. This includes creating new kinds of openers, handlers, requests, protocols, etc. This topic is beyond the scope of what can be covered here, but the online documentation has some further details.
• Users of Python 2 should take note that the urllib.urlopen() function, which is in widespread use, is officially deprecated in Python 2.6 and eliminated in Python 3. Instead of using urllib.urlopen(), you should use urllib2.urlopen(), which provides the same functionality as urllib.request.urlopen() described here.
xmlrpc Package
The xmlrpc package contains modules for implement XML-RPC servers and clients. XML-RPC is a remote procedure call mechanism that uses XML for data encoding and HTTP as a transport mechanism. The underlying protocol is not specific to Python so programs using these modules can potentially interact with programs written in other languages. More information about XML-RPC can be obtained at http://www.xmlrpc.com.
xmlrpc.client (xmlrpclib)
The xmlrpc.client module is used to write XML-RPC clients. In Python 2, this module is called xmlrpclib. To operate as a client, you create an instance of ServerProxy:
![]()
uri is the location of the remote XML-RPC server—for example, "http://www.foo.com/RPC2". If necessary, basic authentication information can be added to the URI using the format "http://user:pass@host:port/path", where user:pass is the username and password. This information is base-64 encoded and put in an 'Authorization:' header on transport. If Python is configured with OpenSSL support, HTTPS can also be used. transport specifies a factory function for creating an internal transport object used for low-level communication. This argument is only used if XML-RPC is being used over some kind of connection other than HTTP or HTTPS. It is almost never necessary to supply this argument in normal use (consult the online documentation for details). encoding specifies the encoding, which is UTF-8 by default. verbose displays some debugging information if True. allow_none, if True, allows the value None to be sent to remote servers. By default, this is disabled because it’s not universally supported. use_datetime is a Boolean flag that if set to True, uses the datetime module to represent dates and times. By default, this is False.
An instance, s, of ServerProxy transparently exposes all the methods on the remote server. The methods are accessed as attributes of s. For example, this code gets the current time from a remote server providing that service:

For the most part, RPC calls work just like ordinary Python functions. However, only a limited number of argument types and return values are supported by the XML-RPC protocol:

When dates are received, they are stored in an xmlrpc.client.DateTime instance d. The d.value attribute contains the date as an ISO 8601 time/date string. To convert it into a time tuple compatible with the time module, use d.timetuple(). When binary data is received, it is stored in an xmlrpc.client.Binary instance b. The b.data attribute contains the data as a byte string. Be aware that strings are assumed to be Unicode and that you will have to worry about using proper encodings. Sending raw Python 2 byte strings will work if they contain ASCII but will break otherwise. To deal with this, convert to a Unicode string first.
If you make an RPC call with arguments involving invalid types, you may get a TypeError or an xmlrpclib.Fault exception.
If the remote XML-RPC server supports introspection, the following methods may be available:
s.system.listMethods()
Returns a list of strings listing all the methods provided by the XML-RPC server.
s.methodSignatures(name)
Given the name of a method, name, returns a list of possible calling signatures for the method. Each signature is a list of types in the form of a comma-separated string (for example, 'string, int, int'), where the first item is the return type and the remaining items are argument types. Multiple signatures may be returned due to overloading. In XML-RPC servers implemented in Python, signatures are typically empty because functions and methods are dynamically typed.
s.methodHelp(name)
Given the name of a method, name, returns a documentation string describing the use of that method. Documentation strings may contain HTML markup. An empty string is returned if no documentation is available.
The following utility functions are available in the xmlrpclib module:
boolean(value)
Creates an XML-RPC Boolean object from value. This function predates the existence of the Python Boolean type, so you may see it used in older code.
Creates an XML-RPC object containing binary data. data is a string containing the raw data. Returns a Binary instance. The returned Binary instance is transparently encoded/decoded using base 64 during transmission. To extract binary from Binary instance b, use b.data.
DateTime(daytime)
Creates an XML-RPC object containing a date. daytime is either an ISO 8601 format date string, a time tuple or struct as returned by time.localtime(), or a datetime instance from the datetime module.
![]()
Converts params into an XML-RPC request or response, where params is either a tuple of arguments or an instance of the Fault exception. methodname is the name of the method as a string. methodresponse is a Boolean flag. If True, then the result is an XML-RPC response. In this case, only one value can be supplied in params. encoding specifies the text encoding in the generated XML and defaults to UTF-8. allow_none is a flag that specifies whether or not None is supported as a parameter type. None is not explicitly mentioned by the XML-RPC specification, but many servers support it. By default, allow_none is False.
loads(data)
Converts data containing an XML-RPC request or response into a tuple (params, methodname) where params is a tuple of parameters and methodname is a string containing the method name. If the request represents a fault condition instead of an actual value, then the Fault exception is raised.
MultiCall(server)
Creates a MultiCall object that allows multiple XML-RPC requests to be packaged together and sent as a single request. This can be a useful performance optimization if many different RPC requests need to be made on the same server. server is an instance of ServerProxy, representing a connection to a remote server. The returned MultiCall object is used in exactly the same way as ServerProxy. However, instead of immediately executing the remote methods, the method calls as queued until the MultiCall object is called as a function. Once this occurs, the RPC requests are transmitted. The return value of this operation is a generator that yields the return result of each RPC operation in sequence. Note that MultiCall() only works if the remote server provides a system.multicall() method.
Here is an example that illustrates the use of MultiCall:

Exceptions
The following exceptions are defined in xmlrpc.client:
Fault
Indicates an XML-RPC fault. The faultCode attribute contains a string with the fault type. The faultString attribute contains a descriptive message related to the fault.
ProtocolError
Indicates a problem with the underlying networking—for example, a bad URL or a connection problem of some kind. The url attribute contains the URI that triggered the error. The errcode attribute contains an error code. The errmsg attribute contains a descriptive string. The headers attribute contains all the HTTP headers of the request that triggered the error.
xmlrpc.server (SimpleXMLRPCServer, DocXMLRPCServer)
The xmlrpc.server module contains classes for implementing different variants of XML-RPC servers. In Python 2, this functionality is found in two separate modules: SimpleXMLRPCServer and DocXMLRPCServer.
SimpleXMLRPCServer(addr [, requestHandler [, logRequests]])
Creates an XML-RPC server listening on the socket address addr (for example, ('localhost',8080)). requestHandler is factory function that creates handler request objects when connections are received. By default, it is set to SimpleXMLRPCRequestHandler, which is currently the only available handler. logRequests is a Boolean flag that indicates whether or not to log incoming requests. The default value is True.
DocXMLRPCServer(addr [, requestHandler [, logRequest])
Creates a documenting XML-RPC that additionally responds to HTTP GET requests (normally sent by a browser). If received, the server generates documentation from the documentation strings found in all of the registered methods and objects. The arguments have the same meaning as for SimpleXMLRPCServer.
An instance, s, of SimpleXMLRPCServer or DocXMLRPCServer has the following methods:
s.register_function(func [, name])
Registers a new function, func, with the XML-RPC server. name is an optional name to use for the function. If name is supplied, it’s the name clients will use to access the function. This name may contain characters that are not part of valid Python identifiers, including periods (.). If name is not supplied, then the actual function name of func is used instead.
s.register_instance(instance [, allow_dotted_names])
Registers an object that’s used to resolve method names not registered with the register_function() method. If the instance instance defines the method _dispatch(self, methodname, params), it is called to process requests. methodname is the name of the method, and params is a tuple containing arguments. The return value of _dispatch() is returned to clients. If no _dispatch() method is defined, the instance is checked to see if the method name matches the names of any methods defined for instance. If so, the method is called directly. The allow_dotted_names parameter is a flag that indicates whether a hierarchical search should be performed when checking for method names. For example, if a request for method 'foo.bar.spam' is received, this determines whether or not a search for instance.foo.bar.spam is made. By default, this is False. It should not be set to True unless the client has been verified. Otherwise, it opens up a security hole that can allow intruders to execute arbitrary Python code. Note that, at most, only one instance can be registered at a time.
s.register_introspection_functions()
Adds XML-RPC introspection functions system.listMethods(), system.methodHelp(), and system.methodSignature() to the XML-RPC server. system.methodHelp() returns the documentation string for a method (if any). The system.methodSignature() function simply returns a message indicating that the operation is unsupported (because Python is dynamically typed, type information is available).
s.register_multicall_functions()
Adds XML-RPC multicall function support by adding the system.multicall() function to the server.
An instance of DocXMLRPCServer additionally provides these methods:
s.set_server_title(server_title)
Sets the title of the server in HTML documentation. The string is placed in the HTML <title> tag.
s.set_server_name(server_name)
Sets the name of the server in HTML documentation. The string appears at the top of the page in an <h1> tag.
s.set_server_documentation(server_documentation)
Adds a descriptive paragraph to the generated HTML output. This string is added right after the server name, but before a description of the XML-RPC functions.
Although it is common for an XML-RPC server to operate as a stand-alone process, it can also run inside a CGI script. The following classes are used for this:
CGIXMLRPCRequestHandler([allow_none [, encoding]])
A CGI Request handler that operates in the same manner as SimpleXMLRPCServer. The arguments have the same meaning as described for SimpleXMLRPCServer.
DocCGIXMLRPCRequestHandler()
A CGI Request handler that operates in the same manner as DocXMLRPCServer. Please note that as of this writing, the calling arguments are different than CGIXMLRPCRequestHandler(). This might be a Python bug so you should consult the online documentation in future releases.
An instance, c, of either CGI handler has the same methods as a normal XML-RPC server for registering functions and instances. However, they additionally define the following method:
c.handle_request([request_text])
Processes an XML-RPC request. By default, the request is read from standard input. If request_text is supplied, it contains the request data in the form received by an HTTP POST request.
Examples
Here is a very simple example of writing a standalone server. It adds a single function, add. In addition, it adds the entire contents of the math module as an instance, exposing all the functions it contains.
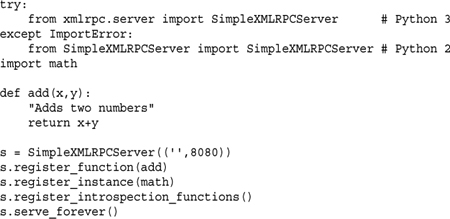
Here is the same functionality implemented as CGI-script:
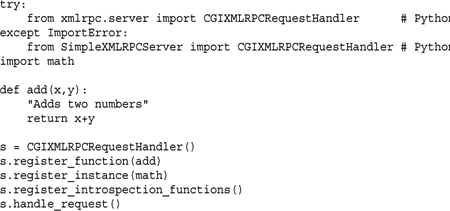
To access XML-RPC functions from other Python programs, use the xmlrpc.client or xmlrpclib module. Here is a short interactive session that shows how it works:
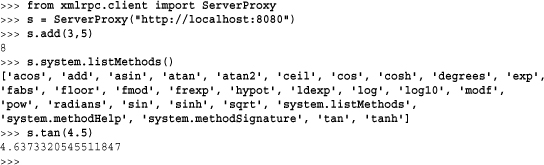
Advanced Server Customization
The XML-RPC server modules are easy to use for basic kinds of distributed computing. For example, XML-RPC could be used as a protocol for high-level control of other systems on the network, provided they were all running a suitable XML-RPC server. More interesting objects can also be passed between systems if you additionally use the pickle module.
One concern with XML-RPC is that of security. By default, an XML-RPC server runs as an open service on the network, so anyone who knows the address and port of the server can connect to it (unless it’s shielded by a firewall). In addition, XML-RPC servers place no limit on the amount of data that can be sent in a request. An attacker could potentially crash the server by sending an HTTP POST request with a payload so large as to exhaust memory.
If you want to address any of these issues, you will need to customize the XML-RPC server classes or request handlers. All of the server classes inherit from TCPServer in the socketserver module. Thus, the servers can be customized in the same manner as other socket server classes (for example, adding threading, forking, or validating client addresses). A validation wrapper can be placed around the request handlers by inheriting from SimpleXMLRPCRequestHandler or DocXMLRPCRequestHandler and extending the do_POST() method. Here is an example that limits the size of incoming requests:
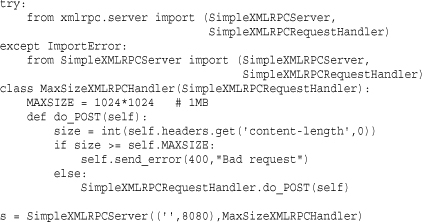
If you wanted to add any kind of HTTP-based authentication, it could also be implemented in a similar manner.