
3. Types and Objects
All the data stored in a Python program is built around the concept of an object. Objects include fundamental data types such as numbers, strings, lists, and dictionaries. However, it’s also possible to create user-defined objects in the form of classes. In addition, most objects related to program structure and the internal operation of the interpreter are also exposed. This chapter describes the inner workings of the Python object model and provides an overview of the built-in data types. Chapter 4, “Operators and Expressions,” further describes operators and expressions. Chapter 7, “Classes and Object-Oriented Programming,” describes how to create user-defined objects.
Terminology
Every piece of data stored in a program is an object. Each object has an identity, a type (which is also known as its class), and a value. For example, when you write a = 42, an integer object is created with the value of 42. You can view the identity of an object as a pointer to its location in memory. a is a name that refers to this specific location.
The type of an object, also known as the object’s class, describes the internal representation of the object as well as the methods and operations that it supports. When an object of a particular type is created, that object is sometimes called an instance of that type. After an instance is created, its identity and type cannot be changed. If an object’s value can be modified, the object is said to be mutable. If the value cannot be modified, the object is said to be immutable. An object that contains references to other objects is said to be a container or collection.
Most objects are characterized by a number of data attributes and methods. An attribute is a value associated with an object. A method is a function that performs some sort of operation on an object when the method is invoked as a function. Attributes and methods are accessed using the dot (.) operator, as shown in the following example:

Object Identity and Type
The built-in function id() returns the identity of an object as an integer. This integer usually corresponds to the object’s location in memory, although this is specific to the Python implementation and no such interpretation of the identity should be made. The is operator compares the identity of two objects. The built-in function type() returns the type of an object. Here’s an example of different ways you might compare two objects:

The type of an object is itself an object known as the object’s class. This object is uniquely defined and is always the same for all instances of a given type. Therefore, the type can be compared using the is operator. All type objects are assigned names that can be used to perform type checking. Most of these names are built-ins, such as list, dict, and file. Here’s an example:

Because types can be specialized by defining classes, a better way to check types is to use the built-in isinstance(object, type) function. Here’s an example:

Because the isinstance() function is aware of inheritance, it is the preferred way to check the type of any Python object.
Although type checks can be added to a program, type checking is often not as useful as you might imagine. For one, excessive checking severely affects performance. Second, programs don’t always define objects that neatly fit into an inheritance hierarchy. For instance, if the purpose of the preceding isinstance(s,list) statement is to test whether s is “list-like,” it wouldn’t work with objects that had the same programming interface as a list but didn’t directly inherit from the built-in list type. Another option for adding type-checking to a program is to define abstract base classes. This is described in Chapter 7.
Reference Counting and Garbage Collection
All objects are reference-counted. An object’s reference count is increased whenever it’s assigned to a new name or placed in a container such as a list, tuple, or dictionary, as shown here:

This example creates a single object containing the value 37. a is merely a name that refers to the newly created object. When b is assigned a, b becomes a new name for the same object and the object’s reference count increases. Likewise, when you place b into a list, the object’s reference count increases again. Throughout the example, only one object contains 37. All other operations are simply creating new references to the object.
An object’s reference count is decreased by the del statement or whenever a reference goes out of scope (or is reassigned). Here’s an example:
![]()
The current reference count of an object can be obtained using the sys.getrefcount() function. For example:

In many cases, the reference count is much higher than you might guess. For immutable data such as numbers and strings, the interpreter aggressively shares objects between different parts of the program in order to conserve memory.
When an object’s reference count reaches zero, it is garbage-collected. However, in some cases a circular dependency may exist among a collection of objects that are no longer in use. Here’s an example:

In this example, the del statements decrease the reference count of a and b and destroy the names used to refer to the underlying objects. However, because each object contains a reference to the other, the reference count doesn’t drop to zero and the objects remain allocated (resulting in a memory leak). To address this problem, the interpreter periodically executes a cycle detector that searches for cycles of inaccessible objects and deletes them. The cycle-detection algorithm runs periodically as the interpreter allocates more and more memory during execution. The exact behavior can be fine-tuned and controlled using functions in the gc module (see Chapter 13, “Python Runtime Services”).
References and Copies
When a program makes an assignment such as a = b, a new reference to b is created. For immutable objects such as numbers and strings, this assignment effectively creates a copy of b. However, the behavior is quite different for mutable objects such as lists and dictionaries. Here’s an example:

Because a and b refer to the same object in this example, a change made to one of the variables is reflected in the other. To avoid this, you have to create a copy of an object rather than a new reference.
Two types of copy operations are applied to container objects such as lists and dictionaries: a shallow copy and a deep copy. A shallow copy creates a new object but populates it with references to the items contained in the original object. Here’s an example:

In this case, a and b are separate list objects, but the elements they contain are shared. Therefore, a modification to one of the elements of a also modifies an element of b, as shown.
A deep copy creates a new object and recursively copies all the objects it contains. There is no built-in operation to create deep copies of objects. However, the copy.deepcopy() function in the standard library can be used, as shown in the following example:

First-Class Objects
All objects in Python are said to be “first class.” This means that all objects that can be named by an identifier have equal status. It also means that all objects that can be named can be treated as data. For example, here is a simple dictionary containing two values:

The first-class nature of objects can be seen by adding some more unusual items to this dictionary. Here are some examples:

In this example, the items dictionary contains a function, a module, an exception, and a method of another object. If you want, you can use dictionary lookups on items in place of the original names and the code will still work. For example:

The fact that everything in Python is first-class is often not fully appreciated by new programmers. However, it can be used to write very compact and flexible code. For example, suppose you had a line of text such as "GOOG,100,490.10" and you wanted to convert it into a list of fields with appropriate type-conversion. Here’s a clever way that you might do it by creating a list of types (which are first-class objects) and executing a few simple list processing operations:

Built-in Types for Representing Data
There are approximately a dozen built-in data types that are used to represent most of the data used in programs. These are grouped into a few major categories as shown in Table 3.1. The Type Name column in the table lists the name or expression that you can use to check for that type using isinstance() and other type-related functions. Certain types are only available in Python 2 and have been indicated as such (in Python 3, they have been deprecated or merged into one of the other types).
Table 3.1 Built-In Types for Data Representation
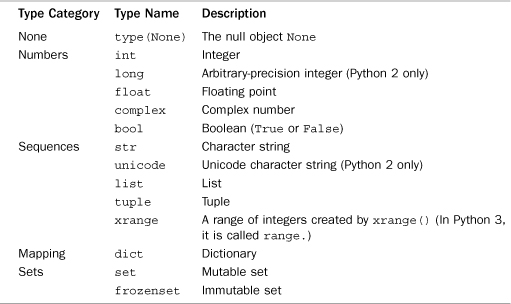
The None Type
The None type denotes a null object (an object with no value). Python provides exactly one null object, which is written as None in a program. This object is returned by functions that don’t explicitly return a value. None is frequently used as the default value of optional arguments, so that the function can detect whether the caller has actually passed a value for that argument. None has no attributes and evaluates to False in Boolean expressions.
Numeric Types
Python uses five numeric types: Booleans, integers, long integers, floating-point numbers, and complex numbers. Except for Booleans, all numeric objects are signed. All numeric types are immutable.
Booleans are represented by two values: True and False. The names True and False are respectively mapped to the numerical values of 1 and 0.
Integers represent whole numbers in the range of –2147483648 to 2147483647 (the range may be larger on some machines). Long integers represent whole numbers of unlimited range (limited only by available memory). Although there are two integer types, Python tries to make the distinction seamless (in fact, in Python 3, the two types have been unified into a single integer type). Thus, although you will sometimes see references to long integers in existing Python code, this is mostly an implementation detail that can be ignored—just use the integer type for all integer operations. The one exception is in code that performs explicit type checking for integer values. In Python 2, the expression isinstance(x, int) will return False if x is an integer that has been promoted to a long.
Floating-point numbers are represented using the native double-precision (64-bit) representation of floating-point numbers on the machine. Normally this is IEEE 754, which provides approximately 17 digits of precision and an exponent in the range of –308 to 308. This is the same as the double type in C. Python doesn’t support 32-bit single-precision floating-point numbers. If precise control over the space and precision of numbers is an issue in your program, consider using the numpy extension (which can be found at http://numpy.sourceforge.net).
Complex numbers are represented as a pair of floating-point numbers. The real and imaginary parts of a complex number z are available in z.real and z.imag. The method z.conjugate() calculates the complex conjugate of z (the conjugate of a+bj is a-bj).
Numeric types have a number of properties and methods that are meant to simplify operations involving mixed arithmetic. For simplified compatibility with rational numbers (found in the fractions module), integers have the properties x.numerator and x.denominator. An integer or floating-point number y has the properties y.real and y.imag as well as the method y.conjugate() for compatibility with complex numbers. A floating-point number y can be converted into a pair of integers representing a fraction using y.as_integer_ratio(). The method y.is_integer() tests if a floating-point number y represents an integer value. Methods y.hex() and y.fromhex() can be used to work with floating-point numbers using their low-level binary representation.
Several additional numeric types are defined in library modules. The decimal module provides support for generalized base-10 decimal arithmetic. The fractions module adds a rational number type. These modules are covered in Chapter 14, “Mathematics.”
Sequence Types
Sequences represent ordered sets of objects indexed by non-negative integers and include strings, lists, and tuples. Strings are sequences of characters, and lists and tuples are sequences of arbitrary Python objects. Strings and tuples are immutable; lists allow insertion, deletion, and substitution of elements. All sequences support iteration.
Operations Common to All Sequences
Table 3.2 shows the operators and methods that you can apply to all sequence types. Element i of sequence s is selected using the indexing operator s[i], and subsequences are selected using the slicing operator s[i:j] or extended slicing operator s[i:j:stride] (these operations are described in Chapter 4). The length of any sequence is returned using the built-in len(s) function. You can find the minimum and maximum values of a sequence by using the built-in min(s) and max(s) functions. However, these functions only work for sequences in which the elements can be ordered (typically numbers and strings). sum(s) sums items in s but only works for numeric data.
Table 3.2 Operations and Methods Applicable to All Sequences

Table 3.3 shows the additional operators that can be applied to mutable sequences such as lists.
Table 3.3 Operations Applicable to Mutable Sequences
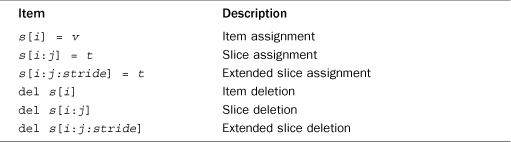
Lists
Lists support the methods shown in Table 3.4. The built-in function list(s) converts any iterable type to a list. If s is already a list, this function constructs a new list that’s a shallow copy of s. The s.append(x) method appends a new element, x, to the end of the list. The s.index(x) method searches the list for the first occurrence of x. If no such element is found, a ValueError exception is raised. Similarly, the s.remove(x) method removes the first occurrence of x from the list or raises ValueError if no such item exists. The s.extend(t) method extends the list s by appending the elements in sequence t.

The s.sort() method sorts the elements of a list and optionally accepts a key function and reverse flag, both of which must be specified as keyword arguments. The key function is a function that is applied to each element prior to comparison during sorting. If given, this function should take a single item as input and return the value that will be used to perform the comparison while sorting. Specifying a key function is useful if you want to perform special kinds of sorting operations such as sorting a list of strings, but with case insensitivity. The s.reverse() method reverses the order of the items in the list. Both the sort() and reverse() methods operate on the list elements in place and return None.
Strings
Python 2 provides two string object types. Byte strings are sequences of bytes containing 8-bit data. They may contain binary data and embedded NULL bytes. Unicode strings are sequences of unencoded Unicode characters, which are internally represented by 16-bit integers. This allows for 65,536 unique character values. Although the Unicode standard supports up to 1 million unique character values, these extra characters are not supported by Python by default. Instead, they are encoded as a special two-character (4-byte) sequence known as a surrogate pair—the interpretation of which is up to the application. As an optional feature, Python may be built to store Unicode characters using 32-bit integers. When enabled, this allows Python to represent the entire range of Unicode values from U+000000 to U+110000. All Unicode-related functions are adjusted accordingly.
Strings support the methods shown in Table 3.5. Although these methods operate on string instances, none of these methods actually modifies the underlying string data. Thus, methods such as s.capitalize(), s.center(), and s.expandtabs() always return a new string as opposed to modifying the string s. Character tests such as s.isalnum() and s.isupper() return True or False if all the characters in the string s satisfy the test. Furthermore, these tests always return False if the length of the string is zero.



The s.find(), s.index(), s.rfind(), and s.rindex() methods are used to search s for a substring. All these functions return an integer index to the substring in s. In addition, the find() method returns -1 if the substring isn’t found, whereas the index() method raises a ValueError exception. The s.replace() method is used to replace a substring with replacement text. It is important to emphasize that all of these methods only work with simple substrings. Regular expression pattern matching and searching is handled by functions in the re library module.
The s.split() and s.rsplit() methods split a string into a list of fields separated by a delimiter. The s.partition() and s.rpartition() methods search for a separator substring and partition s into three parts corresponding to text before the separator, the separator itself, and text after the separator.
Many of the string methods accept optional start and end parameters, which are integer values specifying the starting and ending indices in s. In most cases, these values may be given negative values, in which case the index is taken from the end of the string.
The s.translate() method is used to perform advanced character substitutions such as quickly stripping all control characters out of a string. As an argument, it accepts a translation table containing a one-to-one mapping of characters in the original string to characters in the result. For 8-bit strings, the translation table is a 256-character string. For Unicode, the translation table can be any sequence object s where s[n] returns an integer character code or Unicode character corresponding to the Unicode character with integer value n.
The s.encode() and s.decode() methods are used to transform string data to and from a specified character encoding. As input, these accept an encoding name such as 'ascii', 'utf-8', or 'utf-16'. These methods are most commonly used to convert Unicode strings into a data encoding suitable for I/O operations and are described further in Chapter 9, “Input and Output.” Be aware that in Python 3, the encode() method is only available on strings, and the decode() method is only available on the bytes datatype.
The s.format() method is used to perform string formatting. As arguments, it accepts any combination of positional and keyword arguments. Placeholders in s denoted by {item} are replaced by the appropriate argument. Positional arguments can be referenced using placeholders such as {0} and {1}. Keyword arguments are referenced using a placeholder with a name such as {name}. Here is an example:
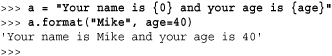
Within the special format strings, the {item} placeholders can also include simple index and attribute lookup. A placeholder of {item[n]} where n is a number performs a sequence lookup on item. A placeholder of {item[key]} where key is a nonnumeric string performs a dictionary lookup of item["key"]. A placeholder of {item.attr} refers to attribute attr of item. Further details on the format() method can be found in the “String Formatting” section of Chapter 4.
xrange() Objects
The built-in function xrange([i,]j [,stride]) creates an object that represents a range of integers k such that i <= k < j. The first index, i, and the stride are optional and have default values of 0 and 1, respectively. An xrange object calculates its values whenever it’s accessed and although an xrange object looks like a sequence, it is actually somewhat limited. For example, none of the standard slicing operations are supported. This limits the utility of xrange to only a few applications such as iterating in simple loops.
It should be noted that in Python 3, xrange() has been renamed to range(). However, it operates in exactly the same manner as described here.
Mapping Types
A mapping object represents an arbitrary collection of objects that are indexed by another collection of nearly arbitrary key values. Unlike a sequence, a mapping object is unordered and can be indexed by numbers, strings, and other objects. Mappings are mutable.
Dictionaries are the only built-in mapping type and are Python’s version of a hash table or associative array. You can use any immutable object as a dictionary key value (strings, numbers, tuples, and so on). Lists, dictionaries, and tuples containing mutable objects cannot be used as keys (the dictionary type requires key values to remain constant).
To select an item in a mapping object, use the key index operator m[k], where k is a key value. If the key is not found, a KeyError exception is raised. The len(m) function returns the number of items contained in a mapping object. Table 3.6 lists the methods and operations.
Table 3.6 Methods and Operations for Dictionaries

Most of the methods in Table 3.6 are used to manipulate or retrieve the contents of a dictionary. The m.clear() method removes all items. The m.update(b) method updates the current mapping object by inserting all the (key,value) pairs found in the mapping object b. The m.get(k [,v]) method retrieves an object but allows for an optional default value, v, that’s returned if no such key exists. The m.setdefault(k [,v]) method is similar to m.get(), except that in addition to returning v if no object exists, it sets m[k] = v. If v is omitted, it defaults to None. The m.pop() method returns an item from a dictionary and removes it at the same time. The m.popitem() method is used to iteratively destroy the contents of a dictionary.
The m.copy() method makes a shallow copy of the items contained in a mapping object and places them in a new mapping object. The m.fromkeys(s [,value]) method creates a new mapping with keys all taken from a sequence s. The type of the resulting mapping will be the same as m. The value associated with all of these keys is set to None unless an alternative value is given with the optional value parameter. The fromkeys() method is defined as a class method, so an alternative way to invoke it would be to use the class name such as dict.fromkeys().
The m.items() method returns a sequence containing (key,value) pairs. The m.keys() method returns a sequence with all the key values, and the m.values() method returns a sequence with all the values. For these methods, you should assume that the only safe operation that can be performed on the result is iteration. In Python 2 the result is a list, but in Python 3 the result is an iterator that iterates over the current contents of the mapping. If you write code that simply assumes it is an iterator, it will be generally compatible with both versions of Python. If you need to store the result of these methods as data, make a copy by storing it in a list. For example, items = list(m.items()). If you simply want a list of all keys, use keys = list(m).
Set Types
A set is an unordered collection of unique items. Unlike sequences, sets provide no indexing or slicing operations. They are also unlike dictionaries in that there are no key values associated with the objects. The items placed into a set must be immutable. Two different set types are available: set is a mutable set, and frozenset is an immutable set. Both kinds of sets are created using a pair of built-in functions:
![]()
Both set() and frozenset() populate the set by iterating over the supplied argument. Both kinds of sets provide the methods outlined in Table 3.7.
Table 3.7 Methods and Operations for Set Types

The s.difference(t), s.intersection(t), s.symmetric_difference(t), and s.union(t) methods provide the standard mathematical operations on sets. The returned value has the same type as s (set or frozenset). The parameter t can be any Python object that supports iteration. This includes sets, lists, tuples, and strings. These set operations are also available as mathematical operators, as described further in Chapter 4.
Mutable sets (set) additionally provide the methods outlined in Table 3.8.
Table 3.8 Methods for Mutable Set Types

All these operations modify the set s in place. The parameter t can be any object that supports iteration.
Built-in Types for Representing Program Structure
In Python, functions, classes, and modules are all objects that can be manipulated as data. Table 3.9 shows types that are used to represent various elements of a program itself.
Table 3.9 Built-in Python Types for Program Structure
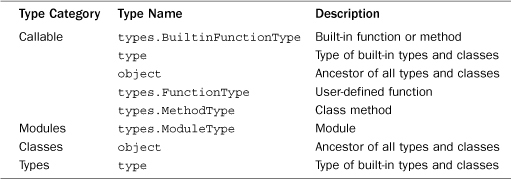
Note that object and type appear twice in Table 3.9 because classes and types are both callable as a function.
Callable Types
Callable types represent objects that support the function call operation. There are several flavors of objects with this property, including user-defined functions, built-in functions, instance methods, and classes.
User-Defined Functions
User-defined functions are callable objects created at the module level by using the def statement or with the lambda operator. Here’s an example:
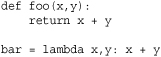
A user-defined function f has the following attributes:

In older versions of Python 2, many of the preceding attributes had names such as func_code, func_defaults, and so on. The attribute names listed are compatible with Python 2.6 and Python 3.
Methods
Methods are functions that are defined inside a class definition. There are three common types of methods—instance methods, class methods, and static methods:

An instance method is a method that operates on an instance belonging to a given class. The instance is passed to the method as the first argument, which is called self by convention. A class method operates on the class itself as an object. The class object is passed to a class method in the first argument, cls. A static method is a just a function that happens to be packaged inside a class. It does not receive an instance or a class object as a first argument.
Both instance and class methods are represented by a special object of type types.MethodType. However, understanding this special type requires a careful understanding of how object attribute lookup (.) works. The process of looking something up on an object (.) is always a separate operation from that of making a function call. When you invoke a method, both operations occur, but as distinct steps. This example illustrates the process of invoking f.instance_method(arg) on an instance of Foo in the preceding listing:
![]()
In this example, meth is known as a bound method. A bound method is a callable object that wraps both a function (the method) and an associated instance. When you call a bound method, the instance is passed to the method as the first parameter (self). Thus, meth in the example can be viewed as a method call that is primed and ready to go but which has not been invoked using the function call operator ().
Method lookup can also occur on the class itself. For example:
![]()
In this example, umeth is known as an unbound method. An unbound method is a callable object that wraps the method function, but which expects an instance of the proper type to be passed as the first argument. In the example, we have passed f, a an instance of Foo, as the first argument. If you pass the wrong kind of object, you get a TypeError. For example:

For user-defined classes, bound and unbound methods are both represented as an object of type types.MethodType, which is nothing more than a thin wrapper around an ordinary function object. The following attributes are defined for method objects:

One subtle feature of Python 3 is that unbound methods are no longer wrapped by a types.MethodType object. If you access Foo.instance_method as shown in earlier examples, you simply obtain the raw function object that implements the method. Moreover, you’ll find that there is no longer any type checking on the self parameter.
Built-in Functions and Methods
The object types.BuiltinFunctionType is used to represent functions and methods implemented in C and C++. The following attributes are available for built-in methods:

For built-in functions such as len(), _ _self_ _ is set to None, indicating that the function isn’t bound to any specific object. For built-in methods such as x.append, where x is a list object, _ _self_ _ is set to x.
Classes and Instances as Callables
Class objects and instances also operate as callable objects. A class object is created by the class statement and is called as a function in order to create new instances. In this case, the arguments to the function are passed to the _ _init_ _() method of the class in order to initialize the newly created instance. An instance can emulate a function if it defines a special method, _ _call_ _(). If this method is defined for an instance, x, then x(args) invokes the method x._ _call_ _(args).
Classes, Types, and Instances
When you define a class, the class definition normally produces an object of type type. Here’s an example:

The following table shows commonly used attributes of a type object t:

When an object instance is created, the type of the instance is the class that defined it. Here’s an example:
![]()
The following table shows special attributes of an instance i:

The _ _dict_ _ attribute is normally where all of the data associated with an instance is stored. When you make assignments such as i.attr = value, the value is stored here. However, if a user-defined class uses _ _slots_ _, a more efficient internal representation is used and instances will not have a _ _dict_ _ attribute. More details on objects and the organization of the Python object system can be found in Chapter 7.
Modules
The module type is a container that holds objects loaded with the import statement. When the statement import foo appears in a program, for example, the name foo is assigned to the corresponding module object. Modules define a namespace that’s implemented using a dictionary accessible in the attribute _ _dict_ _. Whenever an attribute of a module is referenced (using the dot operator), it’s translated into a dictionary lookup. For example, m.x is equivalent to m._ _dict_ _["x"]. Likewise, assignment to an attribute such as m.x = y is equivalent to m._ _dict_ _["x"] = y. The following attributes are available:

Built-in Types for Interpreter Internals
A number of objects used by the internals of the interpreter are exposed to the user. These include traceback objects, code objects, frame objects, generator objects, slice objects, and the Ellipsis as shown in Table 3.10. It is relatively rare for programs to manipulate these objects directly, but they may be of practical use to tool-builders and framework designers.
Table 3.10 Built-in Python Types for Interpreter Internals

Code Objects
Code objects represent raw byte-compiled executable code, or bytecode, and are typically returned by the built-in compile() function. Code objects are similar to functions except that they don’t contain any context related to the namespace in which the code was defined, nor do code objects store information about default argument values. A code object, c, has the following read-only attributes:

Frame Objects
Frame objects are used to represent execution frames and most frequently occur in traceback objects (described next). A frame object, f, has the following read-only attributes:

The following attributes can be modified (and are used by debuggers and other tools):

Traceback Objects
Traceback objects are created when an exception occurs and contain stack trace information. When an exception handler is entered, the stack trace can be retrieved using the sys.exc_info() function. The following read-only attributes are available in traceback objects:

Generator Objects
Generator objects are created when a generator function is invoked (see Chapter 6, “Functions and Functional Programming”). A generator function is defined whenever a function makes use of the special yield keyword. The generator object serves as both an iterator and a container for information about the generator function itself. The following attributes and methods are available:

Slice Objects
Slice objects are used to represent slices given in extended slice syntax, such as a[i:j:stride], a[i:j, n:m], or a[..., i:j]. Slice objects are also created using the built-in slice([i,] j [,stride]) function. The following read-only attributes are available:

Slice objects also provide a single method, s.indices(length). This function takes a length and returns a tuple (start,stop,stride) that indicates how the slice would be applied to a sequence of that length. Here’s an example:
![]()
Ellipsis Object
The Ellipsis object is used to indicate the presence of an ellipsis (...) in an index lookup []. There is a single object of this type, accessed through the built-in name Ellipsis. It has no attributes and evaluates as True. None of Python’s built-in types make use of Ellipsis, but it may be useful if you are trying to build advanced functionality into the indexing operator [] on your own objects. The following code shows how an Ellipsis gets created and passed into the indexing operator:

Object Behavior and Special Methods
Objects in Python are generally classified according to their behaviors and the features that they implement. For example, all of the sequence types such as strings, lists, and tuples are grouped together merely because they all happen to support a common set of sequence operations such as s[n], len(s), etc. All basic interpreter operations are implemented through special object methods. The names of special methods are always preceded and followed by double underscores (_ _). These methods are automatically triggered by the interpreter as a program executes. For example, the operation x + y is mapped to an internal method, x._ _add_ _(y), and an indexing operation, x[k], is mapped to x._ _getitem_ _(k). The behavior of each data type depends entirely on the set of special methods that it implements.
User-defined classes can define new objects that behave like the built-in types simply by supplying an appropriate subset of the special methods described in this section. In addition, built-in types such as lists and dictionaries can be specialized (via inheritance) by redefining some of the special methods.
The next few sections describe the special methods associated with different categories of interpreter features.
Object Creation and Destruction
The methods in Table 3.11 create, initialize, and destroy instances. _ _new_ _() is a class method that is called to create an instance. The _ _init_ _() method initializes the attributes of an object and is called immediately after an object has been newly created. The _ _del_ _() method is invoked when an object is about to be destroyed. This method is invoked only when an object is no longer in use. It’s important to note that the statement del x only decrements an object’s reference count and doesn’t necessarily result in a call to this function. Further details about these methods can be found in Chapter 7.
Table 3.11 Special Methods for Object Creation and Destruction

The _ _new_ _() and _ _init_ _() methods are used together to create and initialize new instances. When an object is created by calling A(args), it is translated into the following steps:
![]()
In user-defined objects, it is rare to define _ _new_ _() or _ _del_ _(). _ _new_ _() is usually only defined in metaclasses or in user-defined objects that happen to inherit from one of the immutable types (integers, strings, tuples, and so on). _ _del_ _() is only defined in situations in which there is some kind of critical resource management issue, such as releasing a lock or shutting down a connection.
Object String Representation
The methods in Table 3.12 are used to create various string representations of an object.
Table 3.12 Special Methods for Object Representation

The _ _repr_ _() and _ _str_ _() methods create simple string representations of an object. The _ _repr_ _() method normally returns an expression string that can be evaluated to re-create the object. This is also the method responsible for creating the output of values you see when inspecting variables in the interactive interpreter. This method is invoked by the built-in repr() function. Here’s an example of using repr() and eval() together:
![]()
If a string expression cannot be created, the convention is for _ _repr_ _() to return a string of the form <...message...>, as shown here:
![]()
The _ _str_ _() method is called by the built-in str() function and by functions related to printing. It differs from _ _repr_ _() in that the string it returns can be more concise and informative to the user. If this method is undefined, the _ _repr_ _() method is invoked.
The _ _format_ _() method is called by the format() function or the format() method of strings. The format_spec argument is a string containing the format specification. This string is the same as the format_spec argument to format(). For example:
![]()
The syntax of the format specification is arbitrary and can be customized on an object-by-object basis. However, a standard syntax is described in Chapter 4.
Object Comparison and Ordering
Table 3.13 shows methods that can be used to perform simple tests on an object. The _ _bool_ _() method is used for truth-value testing and should return True or False. If undefined, the _ _len_ _() method is a fallback that is invoked to determine truth. The _ _hash_ _() method is defined on objects that want to work as keys in a dictionary. The value returned is an integer that should be identical for two objects that compare as equal. Furthermore, mutable objects should not define this method; any changes to an object will alter the hash value and make it impossible to locate an object on subsequent dictionary lookups.
Table 3.13 Special Methods for Object Testing and Hashing

Objects can implement one or more of the relational operators (<, >, <=, >=, ==, !=). Each of these methods takes two arguments and is allowed to return any kind of object, including a Boolean value, a list, or any other Python type. For instance, a numerical package might use this to perform an element-wise comparison of two matrices, returning a matrix with the results. If a comparison can’t be made, these functions may also raise an exception. Table 3.14 shows the special methods for comparison operators.
Table 3.14 Methods for Comparisons

It is not necessary for an object to implement all of the operations in Table 3.14. However, if you want to be able to compare objects using == or use an object as a dictionary key, the _ _eq_ _() method should be defined. If you want to be able to sort objects or use functions such as min() or max(), then _ _lt_ _() must be minimally defined.
Type Checking
The methods in Table 3.15 can be used to redefine the behavior of the type checking functions isinstance() and issubclass(). The most common application of these methods is in defining abstract base classes and interfaces, as described in Chapter 7.
Table 3.15 Methods for Type Checking

Attribute Access
The methods in Table 3.16 read, write, and delete the attributes of an object using the dot (.) operator and the del operator, respectively.
Table 3.16 Special Methods for Attribute Access

Whenever an attribute is accessed, the _ _getattribute_ _() method is always invoked. If the attribute is located, it is returned. Otherwise, the _ _getattr_ _() method is invoked. The default behavior of _ _getattr_ _() is to raise an AttributeError exception. The _ _setattr_ _() method is always invoked when setting an attribute, and the _ _delattr_ _() method is always invoked when deleting an attribute.
Attribute Wrapping and Descriptors
A subtle aspect of attribute manipulation is that sometimes the attributes of an object are wrapped with an extra layer of logic that interact with the get, set, and delete operations described in the previous section. This kind of wrapping is accomplished by creating a descriptor object that implements one or more of the methods in Table 3.17. Keep in mind that descriptions are optional and rarely need to be defined.
Table 3.17 Special Methods for Descriptor Object

The _ _get_ _(), _ _set_ _(), and _ _delete_ _() methods of a descriptor are meant to interact with the default implementation of _ _getattribute_ _(), _ _setattr_ _(), and _ _delattr_ _() methods on classes and types. This interaction occurs if you place an instance of a descriptor object in the body of a user-defined class. In this case, all access to the descriptor attribute will implicitly invoke the appropriate method on the descriptor object itself. Typically, descriptors are used to implement the low-level functionality of the object system including bound and unbound methods, class methods, static methods, and properties. Further examples appear in Chapter 7.
Sequence and Mapping Methods
The methods in Table 3.18 are used by objects that want to emulate sequence and mapping objects.
Table 3.18 Methods for Sequences and Mappings

Here’s an example:

The _ _len_ _ method is called by the built-in len() function to return a nonnegative length. This function also determines truth values unless the _ _bool_ _() method has also been defined.
For manipulating individual items, the _ _getitem_ _() method can return an item by key value. The key can be any Python object but is typically an integer for sequences. The _ _setitem_ _() method assigns a value to an element. The _ _delitem_ _() method is invoked whenever the del operation is applied to a single element. The _ _contains_ _() method is used to implement the in operator.
The slicing operations such as x = s[i:j] are also implemented using _ _getitem_ _(), _ _setitem_ _(), and _ _delitem_ _(). However, for slices, a special slice object is passed as the key. This object has attributes that describe the range of the slice being requested. For example:

The slicing features of Python are actually more powerful than many programmers realize. For example, the following variations of extended slicing are all supported and might be useful for working with multidimensional data structures such as matrices and arrays:

The general format for each dimension of an extended slice is i:j[:stride], where stride is optional. As with ordinary slices, you can omit the starting or ending values for each part of a slice. In addition, the ellipsis (written as ...) is available to denote any number of trailing or leading dimensions in an extended slice:
![]()
When using extended slices, the _ _getitem_ _(), _ _setitem_ _(), and _ _delitem_ _() methods implement access, modification, and deletion, respectively. However, instead of an integer, the value passed to these methods is a tuple containing a combination of slice or Ellipsis objects. For example,
a = m[0:10, 0:100:5, ...]
invokes _ _getitem_ _() as follows:
a = m._ _getitem_ _((slice(0,10,None), slice(0,100,5), Ellipsis))
Python strings, tuples, and lists currently provide some support for extended slices, which is described in Chapter 4. Special-purpose extensions to Python, especially those with a scientific flavor, may provide new types and objects with advanced support for extended slicing operations.
Iteration
If an object, obj, supports iteration, it must provide a method, obj._ _iter_ _(), that returns an iterator object. The iterator object iter, in turn, must implement a single method, iter.next() (or iter._ _next_ _() in Python 3), that returns the next object or raises StopIteration to signal the end of iteration. Both of these methods are used by the implementation of the for statement as well as other operations that implicitly perform iteration. For example, the statement for x in s is carried out by performing steps equivalent to the following:

Mathematical Operations
Table 3.19 lists special methods that objects must implement to emulate numbers. Mathematical operations are always evaluated from left to right according the precedence rules described in Chapter 4; when an expression such as x + y appears, the interpreter tries to invoke the method x._ _add_ _(y). The special methods beginning with r support operations with reversed operands. These are invoked only if the left operand doesn’t implement the specified operation. For example, if x in x + y doesn’t support the _ _add_ _() method, the interpreter tries to invoke the method y._ _radd_ _(x).
Table 3.19 Methods for Mathematical Operations


The methods _ _iadd_ _(), _ _isub_ _(), and so forth are used to support in-place arithmetic operators such as a+=b and a-=b (also known as augmented assignment). A distinction is made between these operators and the standard arithmetic methods because the implementation of the in-place operators might be able to provide certain customizations such as performance optimizations. For instance, if the self parameter is not shared, the value of an object could be modified in place without having to allocate a newly created object for the result.
The three flavors of division operators—_ _div_ _(), _ _truediv_ _(), and _ _floordiv_ _()—are used to implement true division (/) and truncating division (//) operations. The reasons why there are three operations deal with a change in the semantics of integer division that started in Python 2.2 but became the default behavior in Python 3. In Python 2, the default behavior of Python is to map the / operator to _ _div_ _(). For integers, this operation truncates the result to an integer. In Python 3, division is mapped to _ _truediv_ _() and for integers, a float is returned. This latter behavior can be enabled in Python 2 as an optional feature by including the statement from _ _future_ _ import division in a program.
The conversion methods _ _int_ _(), _ _long_ _(), _ _float_ _(), and _ _complex_ _() convert an object into one of the four built-in numerical types. These methods are invoked by explicit type conversions such as int() and float(). However, these methods are not used to implicitly coerce types in mathematical operations. For example, the expression 3 + x produces a TypeError even if x is a user-defined object that defines _ _int_ _() for integer conversion.
Callable Interface
An object can emulate a function by providing the _ _call_ _(self [,*args [, **kwargs]]) method. If an object, x, provides this method, it can be invoked like a function. That is, x(arg1, arg2, ...) invokes x._ _call_ _(self, arg1, arg2, ...). Objects that emulate functions can be useful for creating functors or proxies. Here is a simple example:

In this example, the DistanceFrom class creates instances that emulate a single-argument function. These can be used in place of a normal function—for instance, in the call to sort() in the example.
Context Management Protocol
The with statement allows a sequence of statements to execute under the control of another object known as a context manager. The general syntax is as follows:
![]()
The context object shown here is expected to implement the methods shown in Table 3.20. The _ _enter_ _() method is invoked when the with statement executes. The value returned by this method is placed into the variable specified with the optional as var specifier. The _ _exit_ _() method is called as soon as control-flow leaves from the block of statements associated with the with statement. As arguments, _ _exit_ _() receives the current exception type, value, and traceback if an exception has been raised. If no errors are being handled, all three values are set to None.
Table 3.20 Special Methods for Context Managers

Object Inspection and dir()
The dir() function is commonly used to inspect objects. An object can supply the list of names returned by dir() by implementing _ _dir_ _(self). Defining this makes it easier to hide the internal details of objects that you don’t want a user to directly access. However, keep in mind that a user can still inspect the underlying _ _dict_ _ attribute of instances and classes to see everything that is defined.