
4
The Data Layer
The modeling of data when interacting with the application code is as important as how that data is stored in storage. The data layer is the layer that developers will interact with most often, so creating a good interface is critical to create a productive environment.
In this chapter, we will describe how to create a software data layer that interacts with storage to abstract the specifics of storing data. We will see what Domain-Driven Design is, how to use an Object-Relational Mapping framework, and more advanced patterns, like Command Query Responsibility Segregation.
We will also talk about how to make changes to the database as the application evolves and, finally, techniques to deal with legacy databases when the structure has already been defined before our involvement.
In this chapter, we will look at the following topics:
- The Model layer
- Database migrations
- Dealing with legacy databases
Let's start by giving the context of the data design as part of the Model part of the Model-View-Controller (MVC) pattern.
The Model layer
As we saw when we presented the Model-View-Controller architecture in Chapter 2, API Design, the Model layer is the part that's intimately related with the data and storing and retrieving it.
The Model abstracts all the data handling. This not only includes database access but also the related business logic. This creates a two-layer structure:
- The internal data modeling layer, handling the storage and retrieval of data from the database. This layer needs to understand the way the data is stored in the database and handles it accordingly.
- The next layer creates business logic and uses the internal data modeling layer to support it. This layer is in charge of ensuring that the data to be stored is consistent and enforces any relationships or constraints.
It's very common to deal with the data layer as a pure extension of the database design, removing the business level or storing it as code in the Controller part. While this is doable, it's better to think about whether it's good to explicitly add the business layer on top and ensure there's separation between the entity models, which makes good business sense, and the database models, which contain the details on how to access the database.
Domain-Driven Design
This way of operating has become common as part of Domain-Driven Design. When DDD was first introduced, it was aimed mainly at bridging the gap between the specific application and the technology implementing it to try to use proper nomenclature and ensure that the code was in sync with the real operations that the users of the code would use. For example, banking software will use methods for lodging and withdrawing funds, instead of adding and subtracting from an account.
DDD is not only naming methods and attributes in a way that's consistent with the proper jargon of the domain, but also replicating the uses and flows.
When paired with Object-Oriented Programming (OOP), DDD techniques will replicate the concepts required by the specific domain as objects. In our previous example, we would have an Account object that accepts the methods lodge() and withdraw(). These would probably accept a Transfer object that would keep the proper balance in the source of the funds.
These days, DDD is understood as the creation of this business-oriented interface in the Model layer, so we can abstract the internals on how that's being mapped into accesses to the database and present a consistent interface that replicates the business flows.
DDD requires an intimate knowledge of the specific domain at hand to create an interface that makes sense and properly models the business actions. It requires close communication and collaboration with business experts to be sure that all possible gaps are covered.
For a lot of different concepts, the Model works purely as a replication of the schema of the database. This way, if there's a table, it gets translated into a Model that accesses that table, replicates the fields, etc. An example of this is storing the user in a table with username, full name, subscription, and password fields.
But remember that it is not a hard requirement. A Model can use multiple tables or combine multiple fields in a way that makes more business sense, even not exposing some fields as they should remain internal.
We will use a relational database using SQL as our default example, as it is the most common kind of database. But everything that we are discussing is highly applicable to other kinds of databases, especially to document-based databases.
For example, the example of the user above has the following fields in the database as columns in a SQL table:
|
Field |
Type |
Description |
|
|
|
Unique username |
|
|
|
String describing the hashed password |
|
|
|
Name of the user |
|
|
|
Time when the subscription ends |
|
|
|
Kind of subscription |
But the Model may expose the following:
|
Attribute/Method |
Type |
Description |
|
|
String attribute |
Directly translates the username column |
|
|
String attribute |
Directly translates the full_name column |
|
|
Read-only property |
Returns the subscription type column. If the subscription has ended (as indicated in the subscription end column), it returns |
|
|
Method |
Internally checks whether the |
Note that this hides the password itself, as its internal details are not relevant outside the database. It also hides the internal subscription fields, presenting instead a single attribute that performs all the relevant checks.
This Model transforms the actions from the raw database access to a fully defined object that abstracts the access to the database. This way of operating, when mapping an object to a table or collection, is called Object-Relational Mapping (ORM).
Using ORM
As we've seen above, in essence, ORM is performing mapping between the collections or tables in a database, and generating objects in an OOP environment.
While ORM itself refers to the technique, the way it is usually understood is as a tool. There are multiple ORM tools available that do the conversion from SQL tables to Python objects. This means that, instead of composing SQL statements, we will set up properties defined in classes and objects that will then be translated automatically by the ORM tool and will connect to the database.
For example, a low-level access for a query in the "pens" table could look like this:
>>> cur = con.cursor()
>>> cur.execute('''CREATE TABLE pens (id INTEGER PRIMARY KEY DESC, name, color)''')
<sqlite3.Cursor object at 0x10c484c70>
>>> con.commit()
>>> cur.execute('''INSERT INTO pens VALUES (1, 'Waldorf', 'blue')''')
<sqlite3.Cursor object at 0x10c484c70>
>>> con.commit()
>>> cur.execute('SELECT * FROM pens');
<sqlite3.Cursor object at 0x10c484c70>
>>> cur.fetchall()
[(1, 'Waldorf', 'blue')]
Note that we are using the DB-API 2.0 standard Python interface, which abstracts away the differences between different databases, and allows us to retrieve the information using the standard fetchall() method.
To connect Python and an SQL database, the most common ORMs are the ones included in the Django framework (https://www.djangoproject.com/) and SQLAlchemy (https://www.sqlalchemy.org/). There are other less-used options, such as Pony (https://ponyorm.org/) or Peewee (https://github.com/coleifer/peewee), that aim to have a simpler approach.
Using an ORM, like the one available in the Django framework, instead of creating a CREATE TABLE statement, we describe the table in code as a class:
from django.db import models
class Pens(models.Model):
name = models.CharField(max_length=140)
color = models.CharField(max_length=30)
This class allows us to retrieve and add elements using the class.
>>> new_pen = Pens(name='Waldorf', color='blue')
>>> new_pen.save()
>>> all_pens = Pens.objects.all()
>>> all_pens[0].name
'Waldorf'
The operation that in raw SQL is an INSERT is to create a new object and then use the .save() method to persist the data into the database. In the same way, instead of composing a SELECT query, the search API can be called. For example, this code:
>>> red_pens = Pens.objects.filter(color='red')
Is equivalent to this code:
SELECT * FROM Pens WHERE color = 'red;
Using an ORM, compared with composing SQL directly, has some advantages:
- Using an ORM detaches the database from the code
- It removes the need for using SQL (or learning it)
- It removes some problems with composing SQL queries, like security issues
Let's take a closer look at these advantages and see their limits.
Independence from the database
First of all, using an ORM detaches the database usage from the code. This means that a specific database can be changed, and the code will run unchanged. This can be useful sometimes to run code in different environments or to quickly change to use a different database.
A very common use case for this is to run tests in SQLite and use another database like MySQL or PostgreSQL once the code is deployed in production.
This approach is not problem-free, as some options may be available in one database and not in another. It may be a viable tactic for new projects, but the best approach is to run tests and production in the same technologies to avoid unexpected compatibility problems.
Independence from SQL and the Repository pattern
Another advantage is that you don't need to learn SQL (or whatever language is used in the database backend) to work with the data. Instead, the ORM uses its own API, which can be intuitive and closer to OOP. This can reduce the barrier to entry to work with the code, as developers that are not familiar with SQL can understand the ORM code faster.
Using classes to abstract the access to the persistent layer from the database usage is called the Repository pattern. Using an ORM will make use of this pattern automatically, as it will use programmatic actions without requiring any internal knowledge of the database.
This advantage also has the counterpart that the translation of some actions can be clunky and produce highly inefficient SQL statements. This is especially true for complicated queries that require you to JOIN multiple tables.
A typical example of this is the following example code. The Books objects have a reference to their author that's stored in a different table and stored as a foreign key reference.
for book in Books.objects.find(publisher='packt'):
author = book.author
do_something(author)
This code is interpreted in the following way:
Produce a query to retrieve all the books from publisher 'packt'
For each book, make a query to retrieve the author
Perform the action with the author
When the number of books is high, all those extra queries can be very costly. What we really want to do is
Produce a query to retrieve all the books from publisher 'packt', joining with their authors
For each book, perform the action with the author
This way, only a single query is generated, which is much more efficient than the first case.
This join has to be manually indicated to the API, in the following way.
for book in Books.objects.find(publisher='packt').select_related('author'):
author = book.author
do_something(author)
The need to require the addition of extra information is actually a good example of leaking abstractions, as discussed in Chapter 2. You are still required to understand the details of the database to be able to create efficient code.
This balance for ORM frameworks, between being intuitive to work with and sometimes requiring an understanding of the underlying implementation details, is a balance that needs to be defined. The framework itself will take a more or less flexible approach depending on how the specific SQL statements used are abstracted over a convenient API.
No problems related to composing SQL
Even if the developer knows how to deal with SQL, there's a lot of gotchas when working with it. A pretty important advantage is that using an ORM avoids some of the problems of dealing with the direct manipulation of SQL statements. When directly composing SQL, it ends up becoming a pure string manipulation to generate the desired query. This can create a lot of problems.
The most obvious ones are the requirement to compose the proper SQL statement, and not to generate a syntactically invalid SQL statement. For example, consider the following code:
>>> color_list = ','.join(colors)
>>> query = 'SELECT * FROM Pens WHERE color IN (' + color_list + ')'
This code works for values of colors that contain values but will produce an error if colors is empty.
Even worse, if the query is composed using input parameters directly, it can produce security problems. There's a kind of attack called an SQL injection attack that is aimed at precisely this kind of behavior.
For example, let's say that the query presented above is produced when the user is calling a search that can be filtered by different colors. The user is directly asked for the colors. A malicious user may ask for the color 'red'; DROP TABLE users;. This will take advantage of the fact that the query is composed as a pure string to generate a malicious string that contains a hidden, non-expected operation.
To avoid this problem, any input that may be used as part of a SQL query (or any other language) needs to be sanitized. This means removing or escaping characters that may affect the behavior of the expected query.
Escaping characters means that they are properly encoded to be understood as a regular string, and not part of the syntax. For example, in Python, to escape the character " to be included in a string instead of ending the string definition, it needs to be preceded by the character. Of course, the character needs to be escaped if it needs to be used in a string, in this case doubling it, using \.
For example:
"This string contains the double quote character " and the backslash character \."
While there are specific techniques to manually compose SQL statements and sanitize the inputs, any ORM will sanitize them automatically, greatly reducing the risk of SQL injection by default. This is a great win in terms of security and it's probably the biggest advantage for ORM frameworks. Manually composing SQL statements is generally understood as a bad idea, relying instead on an indirect way that guarantees that any input is safe.
The counterpart is that, even when having a good understanding of the ORM API, there are limits to the way elements are read for certain queries or results, which may lead to operations that are much more complicated or inefficient using an ORM framework than creating a bespoke SQL query.
This typically happens when creating complex joins. The queries created from the ORM are good for straightforward queries but can struggle to create queries when there are too many relationships, as it will overcomplicate them.
ORM frameworks will also have an impact in terms of performance, as they require time to compose the proper SQL query, encode and decode data, and do other checkups. While for most queries this time will be negligible, for specific ones perhaps this will greatly increase the time taken to retrieve the data. Unfortunately, there's a good chance that, at some point, a specific, tailored SQL query will need to be created for some action. When dealing with ORM frameworks, there's always a balance between convenience and being able to create exactly the right query for the task at hand.
Another limit of ORM frameworks is that SQL access may allow operations that are not possible in the ORM interface. This may be a product of specific plugins or capabilities that are unique to the database in use.
If using SQL is the way to go, a common approach is to use prepared statements, which are immutable queries with parameters, so they are replaced as part of the execution in the DB API. For example, the following code will work in a similar way to a print statement.
db.execute('SELECT * FROM Pens WHERE color={color}', color=color_input)
This code will safely replace the color with the proper input, encoded in a safe way. If there's a list of elements that need to be replaced, that could be done in two steps: first, preparing the proper template, with one parameter per input, and second, making the replacement. For example:
# Input list
>>> color_list = ['red', 'green', 'blue']
# Create a dictionary with a unique name per parameter (color_X) and the value
>>> parameters = {f'color_{index}': value for index, value in enumerate(color_list)}
>>> parameters
{'color_0': 'red', 'color_1': 'green', 'color_2': 'blue'}
# Create a clausule with the name of the parameters to be replaced
# by string substitution
# Note that {{ will be replaced by a single {
>>> query_params = ','.join(f'{{{param}}}' for param in parameters.keys())
>>> query_params
'{color_0},{color_1},{color_2}'
# Compose the full query, replacing the prepared string
>>> query = f'SELECT * FROM Pens WHERE color IN ({query_params})'
>>> query
'SELECT * FROM Pens WHERE color IN ({color_0},{color_1},{color_2})'
# To execute, using ** on front of a dictionary will put all its keys as
# input parameters
>>> query.format(**parameters)
'SELECT * FROM Pens WHERE color IN (red,green,blue)'
# Execute the query in a similar way, it will handle all
# required encoding and escaping from the string input
>>> db.execute(query, **query_params)
In our examples, we are using a SELECT * statement that will return all the columns in the table for simplicity, but this is not the correct way of addressing them and should be avoided. The problem is that returning all columns may not be stable.
New columns can be added to a table, so retrieving all columns may change the retrieved data, increasing the chance of producing a formatting error. For example:
>>> cur.execute('SELECT * FROM pens');
<sqlite3.Cursor object at 0x10e640810>
# This returns a row
>>> cur.fetchone()
(1, 'Waldorf', 'blue')
>>> cur.execute('ALTER TABLE pens ADD brand')
<sqlite3.Cursor object at 0x10e640810>
>>> cur.execute('SELECT * FROM pens');
<sqlite3.Cursor object at 0x10e640810>
# This is the same row as above, but now it returns an extra element
>>> cur.fetchone()
(1, 'Waldorf', 'blue', None)
An ORM will handle this case automatically, but using raw SQL requires you to take this effect into account and always include explicitly the columns to retrieve to avoid problems when making changes in the schema later on.
>>> cur.execute('SELECT name, color FROM pens');
<sqlite3.Cursor object at 0x10e640810>
>>> cur.fetchone()
('Waldorf', 'blue')
Backward compatibility is critical when dealing with stored data. We will talk more about that later in the chapter.
Queries generated programmatically by composing them are called dynamic queries. While the default strategy should be to avoid them, preferring prepared statements, in certain cases dynamic queries are still very useful. There's a level of customization that can be impossible to produce unless there's a dynamic query involved.
Exactly what is considered a dynamic query may depend on the environment. In some cases, any query that's not a stored query (a query stored in the database itself beforehand and called with some parameters) may be considered dynamic. From our point of view, we will consider dynamic queries any queries that require string manipulation to produce the query.
Even if the selected way to access the database is raw SQL statements, it's good to create an abstraction layer that deals with all the specific details of the access. This layer should be responsible for storing data, in the proper format in the database, without business logic on that.
ORM frameworks will typically work a bit against this, as they are capable of handling a lot of complexity and will invite you to overload each of the defined objects with business logic. When the translation between the business concept and the database table is direct, for example, a user object, this is fine. But it's definitely possible to create an extra intermediate layer between the storage and the meaningful business object.
The Unit of Work pattern and encapsulating the data
As we've seen before, ORM frameworks directly translate between tables in the database and objects. This creates a representation of the data itself, in the way it's stored in the database.
In most situations, the design of the database will be tightly related to the business entities that we've introduced in the DDD philosophy. But that design may require an extra step, as some entities may be detached from the internal representation of the data, as it's stored inside the database.
The creation of methods representing actions that are unique entities is called the Unit of Work pattern. This means that everything that happens in this high-level action is performed as a single unit, even if internally it is implemented with multiple database operations. The operation acts atomically for the caller.
If the database allows for it, all the operations in a unit of work should be produced inside a transaction to ensure that the whole operation is done in one go. The name Unit of Work is very tightly associated with transactions and relational databases and normally is not used in databases that are not capable of creating transactions, though the pattern can still be used conceptually.
For example, we saw earlier the example of an Account class that accepts .lodge() and .withdraw() methods. While it is possible to directly implement an Account table that contains an integer representing the funds, we can also automatically create with any change a double-entry accountability system that keeps track of the system.
Account can be called a Domain Model to indicate that it's independent of the database representation.
To do so, each Account should have debit and credit internal values that change accordingly. If we also add an extra Log entry, in a different table, for keeping track of movements, it may be implemented as three different classes. The Account class will be the one to be used to encapsulate the log, while InternalAccount and Log will correspond to tables in the database. Note that a single .lodge() or .withdraw() call will generate multiple accesses to the database, as we'll see later.
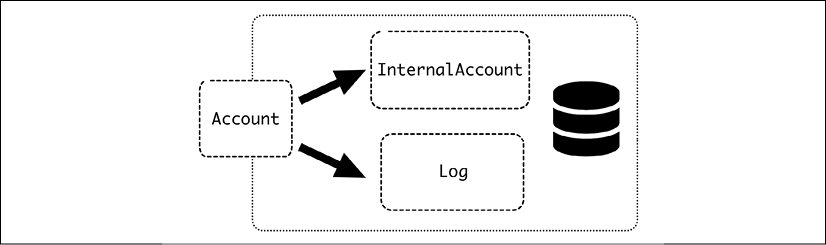
Figure 4.1: Design of the Account class
The code could be something like this:
class InternalAccount(models.Model):
''' This is the model related to a DB table '''
account_number = models.IntegerField(unique=True)
initial_amount = models.IntegerField(default=0)
amount = models.IntegerField(default=0)
class Log(models.Model):
''' This models stores the operations '''
source = models.ForeignKey('InternalAccount',
related_name='debit')
destination = models.ForeignKey('InternalAccount',
related_name='credit')
amount = models.IntegerField()
timestamp = models.DateTimeField(auto_now=True)
def commit():
''' this produces the operation '''
with transaction.atomic():
# Update the amounts
self.source.amount -= self.amount
self.destination.amount += self.amount
# save everything
self.source.save()
self.destination.save()
self.save()
class Account(object):
''' This is the exposed object that handled the operations '''
def __init__(self, account_number, amount=0):
# Retrieve or create the account
self.internal, _ = InternalAccount.objects.get_or_create(
account_number=account_number,
initial_amount=amount,
amount=amount)
@property
def amount(self):
return self.internal.amount
def lodge(source_account, amount):
'''
This operation adds funds from the source
'''
log = Log(source=source_account, destination=self,
amount=amount)
log.commit()
def withdraw(dest_account, amount):
'''
This operation transfer funds to the destination
'''
log = Log(source=self, destination=dest_account,
amount=amount)
log.commit()
The Account class is the expected interface. It is not related directly to anything in the database but keeps a relation to the InternalAccount using the unique reference of the account_number.
The logic to store the different elements is presented in a different class than the ORM models. This can be understood in the way that the ORM model classes are the Repositories classes and the Account model is the Unit of Work class.
In some manuals, they use Unit of Work classes, leaving them without much context, just as a container to perform the action to store the multiple elements. Nevertheless, it's more useful to assign a clear concept behind the Account class to give context and meaning. And there could be several actions that are appropriate for the business entity.
Whenever there's an operation, it requires another account, and then a new Log is created. The Log references the source, destination, and amount of the funds, and, in a single transaction, performs the operation. This is done in the commit method.
def commit():
''' this produces the operation '''
with transaction.atomic():
# Update the amounts
self.source.amount -= self.amount
self.destination.amount += self.amount
# save everything
self.source.save()
self.destination.save()
self.save()
In a single transaction, indicated by the usage of the with transaction.atomic() context manager, it adds and subtracts funds from the accounts, and then saves the three related rows, the source, the destination, and the log itself.
The Django ORM requires you to set this atomic decorator, but other ORMs can work differently. For example, SQLAlchemy tends to work more by adding operations to a queue and requiring you to explicitly apply all of them in a batch operation. Please check the documentation of the specific software you are using for each case.
A missing detail due to simplicity is the validation that there are enough funds to perform the operation. In cases where there aren't enough funds, an exception should be produced that will abort the transaction.
Note how this format allows for each InternalAccount to retrieve every Log associated to the transactions, both debits and credits. That means it can be checked that the current amount is correct. This code will calculate the amount in an account, based on the logs, and that can be used to check the amount is correct.
class InternalAccount(models.Model):
...
def recalculate(self):
'''
Recalculate the amount, based on the logs
'''
total_credit = sum(log.amount for log in self.credit.all())
total_debit = sum(log.amount for log in self.debit.all())
return self.initial_amount + total_credit - total_debit
The initial amount is required. The debit and credit fields are back-references to the Log, as defined in the Log class.
From the point of view of a user only interested in operating with Account objects, all these details are irrelevant. This extra layer allows us to cleanly abstract from the database implementation and store any relevant business logic there. This can be the exposed business Model layer (of the Domain Model) that handles relevant business operations with the proper logic and nomenclature.
CQRS, using different models for read and write
Sometimes a simple CRUD model for the database is not descriptive of how the data flows in the system. In some complex settings, it may be necessary to use different ways to read the data and to write or interact with the data.
A possibility is that sending data and reading it happen at different ends of a pipeline. For example, this is something that happens in event-driven systems, where the data is recorded in a queue, and then later processed. In most cases, this data is processed or aggregated in a different database.
Let's see a more specific example. We store sales for different products. These sales contain the SKU (a unique identifier of the product sold) and the price. But we don't know, at the time of the sale, what the profit from the sale is, as the buying of the product depends on fluctuations of the market. The storing of a sale goes to a queue to start the process to reconcile it with the price paid. Finally, a relational database stores the final sale entry, which includes the purchase price and profit.
The flow of information goes from the Domain Model to the queue, then by some external process to the relational database, where it is then represented with a relational model in an ORM way, and then back to the Domain Model.
This structure is called Command Query Responsibility Segregation (CQRS), meaning that the Command (write operations) and Query (read operations) are separated. The pattern is not unique to event-driven structures; they are typically seen in these systems because their nature is to detach the input data from the output data.
The Domain Model may require different methods to deal with the information. The input and output data has a different internal representation, and sometimes it may be easier to clearly distinguish them. It's anyway a good idea to use an explicit Domain Model layer for CQRS to group the functionality and treat it as a whole. In certain cases, the models and data may be quite different for read and write. For example, if there's a step where aggregated results are generated, that may create extra data in the read part that's never written.
A description of the process of how the read and write parts connect is out of scope in our examples. In our example, that process would be how the data is stored in the database, including the amount paid.
The following diagram depicts the flow of information in a CQRS structure:
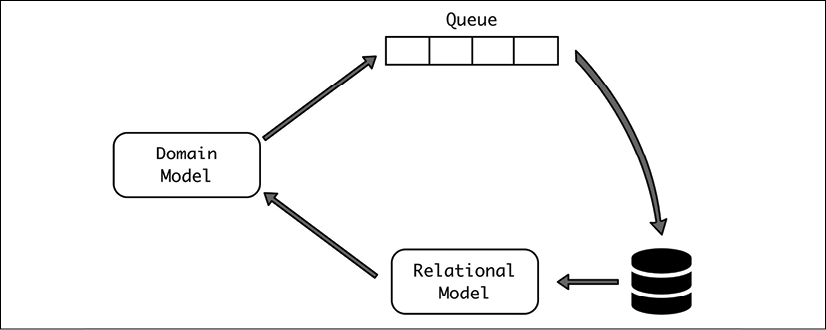
Figure 4.2: The flow of information in a CQRS structure
Our model's definition could be like this:
Class SaleModel(models.Model):
''' This is the usual ORM model '''
Sale_id = models.IntegerField(unique=True)
sku = models.IntegerField()
amount = models.IntegerField()
price = models.IntegerField()
class Sale(object):
'''
This is the exposed Domain Model that handled the operations
In a domain meaningful way, without exposing internal info
'''
def __init__(self, sale_id, sku, amount):
self.sale_id = sale_id
self.sku = sku
self.amount = amount
# These elements are won't be filled when creating a new element
self._price = None
self._profit = None
@property
def price(self):
if self._price is None:
raise Exception('No price yet for this sale')
return self._price
@property
def profit(self):
if self._profit is None:
raise Exception('No price yet for this sale')
return self._profit
def save(self):
# This sends the sale to the queue
event = {
'sale_id': self.sale_id,
'sku': self.sku,
'amount': self.amount,
}
# This sends the event to the external queue
Queue.send(event)
@classmethod
def get(cls, sale_id):
# if the sale is still not available it will raise an
# Exception
sale = SaleModel.objects.get(sale_id=sale_id)
full_sale = Sale(sale_id=sale_id, sku=sale.sku,
amount=sale.amount)
# fill the private attributes
full_sale._price = sale.price
full_sale._profit = sale.amount - full_sale._price
return full_sale
Note how the flow is different for save and retrieve:
# Create a new sale
sale = Sale(sale_id=sale_id, sku=sale.sku, amount=sale.amount)
sale.save()
# Wait some time until totally processed
full_sale = Sale.get(sale_id=sale_id)
# retrieve the profit
full_sale.profit
CQRS systems are complex, as the data in and the data out is different. They also normally incur some delay in being able to retrieve the information back, which can be inconvenient.
Another important problem in CQRS systems is the fact that the different pieces need to be in sync. This includes both the read and write models, but also any transformation that happens within the pipeline. Over time, this creates a maintenance requirement, especially when backward compatibility needs to be maintained.
All these problems make CQRS systems complicated. They should be used with care only when strictly necessary.
Database migrations
An unavoidable fact of development is that software systems are always changing. While the pace of changes in the database is typically not as fast as other areas, there are still changes and they need to be treated carefully.
Data changes are roughly categorized into two different kinds:
- Format or schema changes: New elements, like fields or tables, to be added or removed; or changes in the format of some fields.
- Data changes: Requiring changing the data itself, without modifying the format. For example, normalizing an address field including the zip code, or making a string field uppercase.
Backward compatibility
The basic principle related to changes in the database is backward compatibility. This means that any single change in the database needs to work without any change in the code.
This allows you to make changes without interrupting the service. If the changes in the database require a change in the code to understand it, the service will have to be interrupted. This is because you can't apply both changes at the same time, and if there is more than one server executing the code, it can't be applied simultaneously.
Of course, there's another option, which is to stop the service, perform all the changes, and restart again. While this is not great, it could be an option for small services or if scheduled downtime is acceptable.
Depending on the database, there are different approaches to data changes.
For relational databases, given that they require a fixed structure to be defined, any change in the schema needs to be applied to the whole database as a single operation.
For other databases that don't force defining a schema, there are ways of updating the database in a more iterative way.
Let's take a look at the different approaches.
Relational schema changes
In relational databases, each individual schema change is applied as a SQL statement that operates like a transaction. The schema change, called a migration, can happen at the same time that some transformation of the data (for example, transforming integers to strings) takes place.
Migrations are SQL commands that perform changes in an atomic way. They can involve changing the format of tables in the database, but also more operations like changing the data or multiple changes in one go. This can be achieved by creating a single transaction that groups these changes. Most ORM frameworks include support to create migrations and perform these operations natively.
For example, Django will automatically create a migration file by running the command makemigrations. This command needs to be run manually, but it will detect any change in the models and make the proper changes.
For example, if we add an extra value branch_id in the class introduced before
class InternalAccount(models.Model):
''' This is the model related to a DB table '''
account_number = models.IntegerField(unique=True)
initial_amount = models.IntegerField(default=0)
amount = models.IntegerField(default=0)
branch_id = models.IntegerField()
Running the command makemigrations will generate the proper file that describes the migration.
$ python3 manage.py makemigrations
Migrations for 'example':
example/migrations/0002_auto_20210501_1843.py
- Add field branch_id to internalaccount
Note that Django keeps track of the state in the models and automatically adjusts the changes creating the proper migration files. The pending migrations can be applied automatically with the command migrate.
$ python3 manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, example, sessions
Running migrations:
Applying example.0002_auto_20210501_1843... OK
Django will store in the database the status of the applied migrations, to be sure that each one is applied exactly once.
Keep in mind that, to properly use migrations through Django no alterations outside of this method should be made, as this can confuse and create conflicts. If you need to apply changes that can't be replicated automatically with a change in the model, like a data migration, you can create an empty migration and fill it with your custom SQL statements. This can create complex, custom migrations, but that will be applied and kept in track with the rest of the automatically created Django migrations. Models can also be explicitly marked as not-handled by Django to manage them manually.
For more details about Django migrations, check the documentation at https://docs.djangoproject.com/en/3.2/topics/migrations/.
Changing the database without interruption
The process to migrate the data, then, needs to happen in the following order:
- The old code and the old database schema are in place. This is the starting point.
- The database applies a migration that's backward compatible with the old code. As the database can apply this change while in operation, the service is not interrupted.
- The new code taking advantage of the new schema is deployed. This deployment won't require any special downtime and can be performed without interrupting the process.
The critical element of this process is step 2, to ensure that the migration is backward compatible with the previous code.
Most of the usual changes are relatively simple, like adding a new table or column to a table, and you'll have no problem with that. The old code won't make use of the column or table, and that will be totally fine. But other migrations can be more complex.
For example, let's imagine that a field Field1 that has so far been an integer needs to be translated into a string. There'll be numbers stored, but also some special values like NaN or Inf that are not supported by the database. The new code will decode them and deal with them correctly.
But obviously, a change that migrates the code from an integer to a string is going to produce an error if this is not taken into account in the old code.
To solve this problem, it needs to be approached as a series of steps instead:
- The old code and the old database schema are in place. This is the starting point.
- The database applies a migration adding a new column,
Field2. In this migration, the value fromField1is translated into a string and copied. - A new version of the code, intermediate code, is deployed. This version understands there may be one (
Field2) or two columns (Field1andField2). It uses the value inField2, not the one inField1, but if there's a write, it should overwrite both.To avoid having a problem with possible updates between the application of the migration and the new code, the code will need to check if the column
Field1exists, and if it does and has a different value thanField2, update the latter before performing any operation. - A new migration removing
Field1, now unused, can be applied.In the same migration, the same caveat as above should be applied – if the value in
Field1is different from the one inField2, overwrite it withField1. Note how the only case where this may happen is if it has been updated with the old code. - The new code that is only aware of
Field2can now be deployed safely.
Depending on whether Field2 is an acceptable name or not, it may be possible that a further migration is deployed changing the name from Field2 to Field1. In that case, the new code needs to be prepared in advance to use Field2 or, if not present, Field1.
A new deployment could be done after that to use only Field1 again:
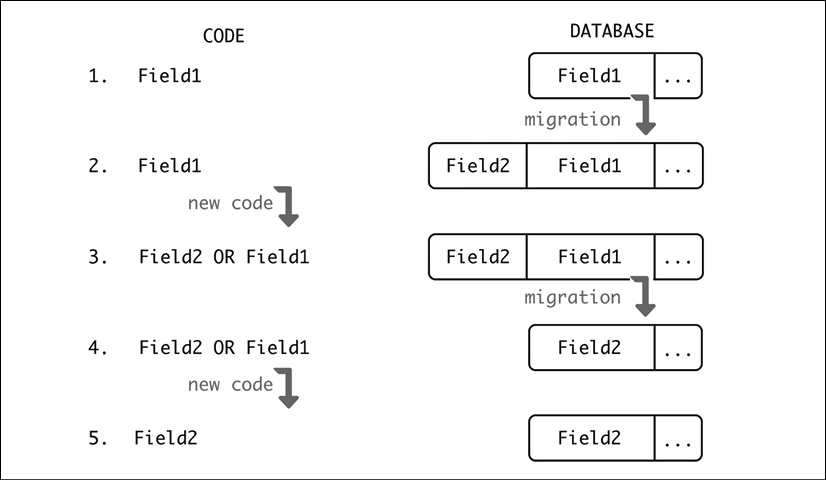
Figure 4.3: Migrating from Field1 to Field2
If this seems like a lot of work, well, it is. All these steps are required to enforce smooth operation and achieve no downtime. The alternative is to stop the old code, perform the migration with the format change in Field1, and then start the new code. But this can cause several problems.
The most obvious is the downtime. While the impact can be minimized by trying to set up a proper maintenance window, most modern applications are expected to work 24x7 and any downtime is considered a problem. If the application has a global audience, it may be difficult to justify a stop just for avoidable maintenance.
The downtime also may last a while, depending on the migration side. A common problem is testing the migration in a database much smaller than the production one. This can create an unexpected problem when running in production, taking much longer than anticipated. Depending on the size of the data, a complex migration may take hours to complete. And, given that it will run as part of a transaction, it needs to be totally completed before proceeding or it will be rolled back.
If possible, try to test the migrations of the system with a big enough test database that's representative. Some operations can be quite costly. It's possible that some migrations may need to be tweaked to run faster or even divided into smaller steps so each one can run in its own transaction to run in a reasonable time. It's even possible in some cases that the database will require more memory to allow the migration to run in a reasonable amount of time.
But another problem is the risk of introducing a step, at the start of the new code, that can have problems and bugs, either related to the migration, or unrelated. With this process, after the migration is applied, there's no possibility of using the old code. If there's a bug in the new code, it needs to be fixed and a newer version deployed. This can create big trouble.
While it's true that, as migrations are not reversible, applying a migration is always a risk, the fact that the code stays stable helps mitigate problems. Changing a single piece of code is less risky than changing two without being able to revert either of them.
Migrations may be reversible, as there could be steps that perform the reverse operation. While this is theoretically true, it is extremely difficult to enforce in real operations. It's possible that a migration like removing a column is effectively not reversible, as data gets lost.
This way migrations need to be applied very carefully and by ensuring that each step is small and deliberate.
Keep in mind how migrations inter-operate with the techniques that we talked about related to distributed databases. For example, a sharded database will need to apply each migration independently to each of the shards, which may be a time-consuming operation.
Data migrations
Data migrations are changes in the database that don't change the format but change the values of some fields.
These migrations are produced normally either to correct some error in the data, like a bug that stores a value with some encoding error, or to move old records to a more up-to-date format. For example, including zip codes in all addresses, if not already present, or to change the scale of a measurement from inches to centimeters.
In either case, these actions may need to be performed for all rows or only for a selection of them. Applying them only to the relevant subset, if possible, can greatly speed up the process, especially for big databases.
In cases like the scale change described above, the process may require more steps to ensure that the code can handle both scales and differentiate between them. For example, with an extra field describing the scale. In this case, the process will be as follows:
- Create a migration to set a new column,
scale, to all rows, with a default value ofinches. Any new row introduced by the old code will automatically set up the values correctly, by using a default value. - Deploy a new version of the code able to work with both inches and centimeters reading the value in
scale. - Set up another migration to change the value of measurement. Each row will change both the
scaleand themeasurementaccordingly. Set the default value forscaletocentimeters. - Now all the values in the database are in centimeters.
- Optionally, clean up by deploying a new version of the code that doesn't access the
scalefield and understands only centimeters, as both scales are not used. After that, a new migration removing the column can also be run.
Step 5 is optional and normally there's not a great appetite for this kind of cleanup, as it's not strictly necessary and the versatility of having the extra column may be worth keeping for future usage.
As we discussed before, the key element is to deploy code that's able to work with both database values, the old and the new, and understand them. This allows for a smooth transition between the values.
Changes without enforcing a schema
One of the flexible aspects of non-relational databases is the fact that there's typically not an enforced schema. Instead, the stored documents accept different formats.
This means that, instead of an all-or-nothing change as for relational databases, a more continuous change and dealing with multiple formats is preferred.
Instead of the application of migrations, which is a concept not really applicable here, the code will have to perform the changes over time. In this case, the steps are like this:
- The old code and the old database schema are in place. This is the starting point.
- Each of the documents in the database has a
versionfield. - The new code contains a Model layer with the migration instructions from the previous version to the new one – in our example above, to translate
Field1from integer to string. - Every time that a particular document is accessed, the
versionis checked. If it's not the latest,Field1is transformed into a string, and the version is updated. This action happens before performing any operation. After the update, the operation is performed normally.This operation runs alongside the normal operation of the system. Given enough time, it will migrate, document by document, the whole database.
The
versionfield may not be strictly necessary, as the type ofField1may be easy to infer and change. But it presents the advantage that it makes the process explicit, and can be concatenated, migrating an old document from different versions in a single access.If the
versionfield is not present, it may be understood asversion 0and be migrated toversion 1, now including the field.

Figure 4.4: Changes over time
This process is very clean, but sometimes leaving data in the old format for a long time, even if it's not accessed, may not be advisable. It may cause that code to migrate from version 1 to 2, version 2 to 3, etc, if still present in the code. If this is the case, an extra process running alongside may be covering every document, updating and saving it until the whole database is migrated.
This process is similar to the one described for data migration, though databases enforcing schemas need to perform migrations to change the format. In a schema-less database, the format can be changed at the same time as the value.
In the same way, a pure data change, like the example seen before where it was changing the scale, can be performed without the need for a migration, slowly changing the database as we described here. Doing it with a migration ensures a cleaner change, though, and may allow a simultaneous change in format.
Also note that, if this functionality is encapsulated in the internal database access layer, the logic above this one may use the newer functionality without caring about old formats, as they'll be translated on the fly.
While there's still data in the database with the old version, the code needs to be able to interpret it. This can cause some accumulation of old tech, so it's also possible to migrate all the data in the background, as it can be done document to document, filtering by the old version, while everything is in operation. Once this background migration is done, the code can be refactored and cleaned to remove the handling of obsolete versions.
Dealing with legacy databases
ORM frameworks can generate the proper SQL commands to create the database schema. When designing and implementing a database from scratch, that means that we can create the ORM Model in code and the ORM framework will make the proper adjustments.
But sometimes, we need to work with an existing database that was created previously by manually running SQL commands. There are two possible use cases:
- The schema will never be under the control of the ORM framework. In this case, we need a way to detect the existing schema and use it.
- We want to use the ORM framework from this situation to control the fields and any new changes. In this scenario, we need to create a Model that reflects the current situation and move from there to a declarative situation.
Let's take a look at how to approach these situations.
Detecting a schema from a database
For certain applications, if the database is stable or it's simple enough, it can be used as-is, and you can try to minimize the code to deal with it. SQLAlchemy allows you to automatically detect the schema of the database and work with it.
SQLAlchemy is a very powerful ORM-capable library and arguably the best solution to perform complex and tailored accesses to a relational database. It allows complex definitions on how exactly tables relate to each other and allows you to tweak queries and create precise mappings. It's also more complex and potentially more difficult to use than other ORM frameworks such as the Django ORM.
To automatically detect a database, you can automatically detect the tables and columns:
>>> from sqlalchemy.ext.automap import automap_base
>>> from sqlalchemy.sql import select
>>> from sqlalchemy import create_engine
# Read the database and detect it
>>> engine = create_engine("sqlite:///database.db")
>>> Base = automap_base()
>>> Base.prepare(engine, reflect=True)
# The Pens class maps the table called "pens" in the DB
>>> Pens = Base.classes.pens
# Create a session to query
>>> session = Session(engine)
# Create a select query
>>> query = select(Pens).where(Pens.color=='blue')
# Execute the query
>>> result = session.execute(query)
>>> for row, in result:
... print(row.id, row.name, row.color)
...
1 Waldorf blue
Note how the described names for the table pens and columns id, name, and color are detected automatically. The format of the query is also very similar to what a SQL construction will be.
SQLAlchemy allows more complex usages and the creation of classes. For more information, refer to its documentation: https://docs.sqlalchemy.org/.
The Django ORM also has a command that allows you to dump a definition of the defined tables and relationships, using inspectdb.
$ python3 manage.py inspectdb > models.py
This creates a models.py file that contains the interpretation of the database based on the discovery that Django can do. This file may require adjustments.
These methods of operation work perfectly for simple situations, where the most important part is to not spend too much effort having to replicate a schema in code. Other situations, where the schema gets mutated and requires better handling and control over the code, require a different approach.
Check the Django documentation for more information: https://docs.djangoproject.com/en/3.2/howto/legacy-databases/.
Syncing the existing schema to the ORM definition
In other situations, there's a legacy database that was created by a method that cannot be replicated. Perhaps it was done through manual commands. The current code may use the database, but we want to migrate the code so we are up-to-date with it so we can, on one hand, understand exactly what the different relations and formats are, and on another, allow the ORM to make controlled changes to the schema in a compatible way. We will see the latter as migrations.
The challenge in this case is to create a bunch of Models in the ORM framework that are up-to-date with the definition of the database. This is easier said than done, for several reasons:
- There can be database features that are not exactly translated by the ORM. For example, ORM frameworks don't deal with stored procedures natively. If the database has stored procedures, they need to be either removed or replicated as part of the software operation.
Stored procedures are code functions inside the database that modify it. They can be manually called by using a SQL query, but normally they are triggered by certain operations, like inserting a new row or changing a column. Stored procedures are not very common these days, as they can be confusing to operate, and instead, in most cases, system designs tend to see databases as storage-only facilities, without the capacity to change the data that is stored. Managing stored procedures is complicated, as they can be difficult to debug and keep in sync with external code.
Stored procedures can be replicated by code that handles that complexity as part of a single Unit of Work action when the action will be triggered. This is the most common approach these days. But, of course, migrating already-existing stored procedures into external code is a process that may not be easy and requires care and planning.
- ORM frameworks can have their quirks in how to set up certain elements, which may not be compatible with the already-existing database. For example, how certain elements are named. The Django ORM doesn't allow you to set custom names for the indices and constraints. For a while, the constraint can remain only in the database, but "hidden" in the ORM, but in the long run that can create problems. This means that at some point, the index name needs to be changed externally to the compatible name.
- Another example of this is the lack of support for composite primary keys in the Django ORM, which may require you to create a new numeric column to create a surrogate key.
These limitations require that the creation of Models is done carefully and there are checks needed to ensure that they work as expected with the current schema. The created schema based on the code Models in the ORM framework can be produced and compared with the actual schema until there's parity or they are close enough.
For example, for Django, the following general procedure can be used:
- Create a dump of the database schema. This will be used as a reference.
- Create the proper Model files. The starting point could be the output from the
inspectdbcommand described above.Note that the
inspectdbcreates the Models with their metadata set to not track changes in the database. That means that Django labels the Models as not tracked for changes as migrations. Once verified, this will need to be changed. - Create a single migration with all the required changes for the database. This migration is created normally, with
makemigrations. - Use the command
sqlmigrateto produce a SQL dump of the SQL statements that will be applied by the migration. This generates a database schema that can be compared with the reference. - Adjust the differences and repeat from step 2 onward. Remember to delete the migration file each time to generate it from scratch.
Once the migration is tweaked to produce exactly the results that are currently applied, this migration can be applied using the parameter
--fakeor–fake-initial, meaning that it will be registered as applied, but the SQL won't run.
This is a very simplified method. As we discussed above, there are some elements that can be difficult to replicate. Changes to the external database to solve incompatibility problems may be required.
On the other hand, sometimes it can be okay to live with small differences that are not creating any problems. For example, a different name in the primary key index may be something that can be acceptable and fixed later. Normally, these kinds of operations require a long time to be totally completed from a complex schema. Plan accordingly and do it in small increments.
After that, changes can be applied normally by changing the Models and then autogenerating migrations.
Summary
In this chapter, we described what the principles behind Domain-Driven Design are, to orient the abstraction of storing data and use rich objects that follow business principles. We also described ORM frameworks and how they can be useful to remove the need to deal with low-level interaction with specific libraries to work with the storage layer. We described different useful techniques for the code to interact with the database, like the Unit of Work pattern, which is related to the concept of a transaction, and CQRS for advanced cases where the write and read are addressed to different backends.
We also discussed how to deal with database changes, both with explicit migrations that change the schema and with more soft changes that migrate the data as the application is running.
Finally, we described different methods to deal with legacy databases, and how to create models to create a proper software abstraction when there's no control over the current schema of the data.
Join our book’s Discord space
Join the book’s Discord workspace for a monthly Ask me Anything session with the authors:
https://packt.link/PythonArchitechture
