
So far we have trained our model based on 100 thousand samples and did not go beyond it. Otherwise, memory will be overloaded as it holds data that is too heavy, and the program will crash. In this section, we will be presenting how to train on a large-scale dataset with online learning.
Stochastic gradient descent grows from gradient descent by sequentially updating the model with individual training samples at a time, instead of the complete training set at once. We can further scale up stochastic gradient descent with online learning techniques. In online learning, new data for training is available in a sequential order or in real time, as opposed to all at once in an offline learning environment. A relatively small chunk of data is loaded and preprocessed for training at a time, which releases the memory used to hold the entire large dataset. Besides better computational feasibility, online learning is also used because of its adaptability to cases where new data is generated in real time and needed in modernizing the model. For instance, stock price prediction models are updated in an online learning manner with timely market data; click-through prediction models need to include the most recent data reflecting users' latest behaviors and tastes; spam email detectors have to be reactive to the ever-changing spammers by considering new features dynamically generated. The existing model trained by previous datasets is now updated based on the latest available dataset only, instead of rebuilding from scratch based on previous and recent datasets together as in offline learning.
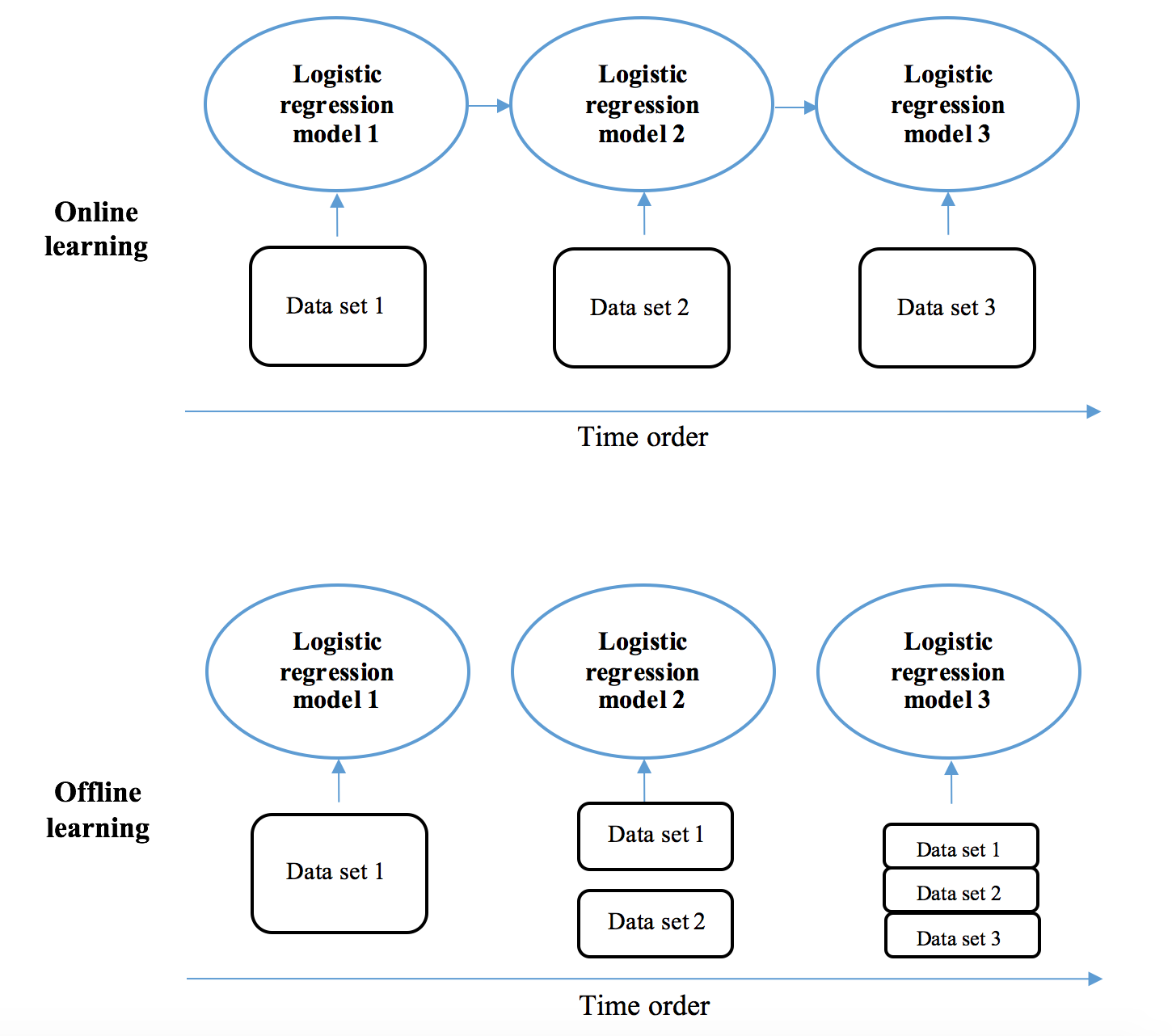
The SGDClassifier in scikit-learn implements online learning with the partial_fit method (while with the fit method in offline learning as we have seen). We train a model with the first ten 100 thousand (that is 1 million) samples with online learning:
>>> sgd_lr = SGDClassifier(loss='log', penalty=None,
fit_intercept=True, n_iter=1,
learning_rate='constant', eta0=0.01)
>>> start_time = timeit.default_timer()
>>> for i in range(10):
... X_dict_train, y_train_every_100k =
read_ad_click_data(100000, i * 100000)
... X_train_every_100k =
dict_one_hot_encoder.transform(X_dict_train)
... sgd_lr.partial_fit(X_train_every_100k, y_train_every_100k,
classes=[0, 1])
Then the next 10 thousand samples for testing:
>>> X_dict_test, y_test_next10k =
read_ad_click_data(10000, (i + 1) * 100000)
>>> X_test_next10k = dict_one_hot_encoder.transform(X_dict_test)
>>> predictions = sgd_lr.predict_proba(X_test_next10k)[:, 1]
>>> print('The ROC AUC on testing set is:
{0:.3f}'.format(roc_auc_score(y_test_next10k, predictions)))
The ROC AUC on testing set is: 0.756
>>> print("--- %0.3fs seconds ---" %
(timeit.default_timer() - start_time))
--- 107.030s seconds ---
With online learning, training based on, in total, 1 million samples becomes computationally effective.