
If unfortunately, we have very little domain knowledge, how can we generate features? Don't panic. There are several generic approaches:
- Binarization: a process of converting a numerical feature to a binary one with a preset threshold. For example, in spam email detection, for the feature (or term) prize, we can generate a new feature whether prize occurs: any term frequency value greater than 1 becomes 1, otherwise 0. Feature number of visits per week can be used to produce a new feature is frequent visitor by judging whether the value is greater than or equal to 3. We implement such binarization as follows using scikit-learn:
>>> from sklearn.preprocessing import Binarizer
>>> X = [[4], [1], [3], [0]]
>>> binarizer = Binarizer(threshold=2.9)
>>> X_new = binarizer.fit_transform(X)
>>> print(X_new)
[[1]
[0]
[1]
[0]]
- Discretization: a process of converting a numerical feature to a categorical feature with limited possible values. Binarization can be viewed as a special case of discretization. For example, we can generate an age group feature from age: 18-24 for age from 18 to 24, 25-34 for age from 25 to 34, 34-54 and 55+.
- Interaction: includes sum, multiplication, or any operations of two numerical features, joint condition check of two categorical features. For example, number of visits per week and number of products purchased per week can be used to generate number of products purchased per visit feature; interest and occupation, such as sports and engineer, can form occupation and interest, such as engineer interested in sports.
- Polynomial transformation: a process of generating polynomial and interaction features. For two features
 and
and 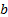 , the two degree of polynomial features generated are
, the two degree of polynomial features generated are 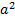 ,
, 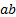 and
and 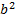 . In scikit-learn, we can use the PolynomialFeatures class to perform polynomial transformation:
. In scikit-learn, we can use the PolynomialFeatures class to perform polynomial transformation:
>>> from sklearn.preprocessing import PolynomialFeatures
>>> X = [[2, 4],
... [1, 3],
... [3, 2],
... [0, 3]]
>>> poly = PolynomialFeatures(degree=2)
>>> X_new = poly.fit_transform(X)
>>> print(X_new)
[[ 1. 2. 4. 4. 8. 16.]
[ 1. 1. 3. 1. 3. 9.]
[ 1. 3. 2. 9. 6. 4.]
[ 1. 0. 3. 0. 0. 9.]]
Note that the resulting new features consist of 1 (bias, intercept), ![]() ,
, ![]() ,
, ![]() ,
, ![]() and
and ![]() .
.