
Real-time applications vary in ubiquity, cost, size, and performance-sensitivity—from wristwatches and microwave ovens to factory automation and nuclear power plant control systems. Applying a general development methodology to the development of real-time systems requires that such a process must scale from small 4-bit and 8-bit controller-based systems up to networked arrays of powerful processors coordinating their activities to achieve a common purpose.
Real-time systems are ones in which timeliness, performance, and schedulability are essential to correctness. Model-driven approaches are a natural fit because they allow different aspects of the system—structural, behavioral, functional, and quality of service—to be specified, analyzed, designed, simulated, and/or executed.
Notation and Concepts Discussed: | ||
|---|---|---|
What Is Special about Real-Time Systems | ROPES Process | Working with Models |
Systems Engineering | Time, Performance, and Quality of Service | |
Organizing Models | Model-Based Development | |
If you read the popular computer press, you would come away with the impression that most computers sit on a desktop (or lap) and run Windows. In terms of the numbers of deployed systems, embedded real-time systems are orders of magnitude more common than their more visible desktop cousins. A tour of the average affluent American home might find one or even two standard desktop computers but literally dozens of smart consumer devices, each containing one or more processors. From the washing machine and microwave oven to the telephone, stereo, television, and automobile, embedded computers are everywhere. They help us evenly toast our muffins and identify mothers-in-law calling on the phone. Embedded computers are even more prevalent in industry. Trains, switching systems, aircraft, chemical process control, and nuclear power plants all use computers to safely and conveniently improve our productivity and quality of life.[1]
The software for these embedded computers is more difficult to construct than software for the desktop. Real-time systems have all the problems of desktop applications plus many more. Systems that are not real-time do not concern themselves with timelines, robustness, or safety—at least not to nearly the same extent as real-time systems. Real-time systems often do not have a conventional computer display or keyboard, but lie at the heart of some apparently noncomputerized device. The user of these devices may never be aware of the CPU embedded within, making decisions about how and when the system should act. The user is not intimately involved with such a device as a computer per se, but rather as an electrical or mechanical appliance that provides services. Such systems must often operate for days or even years without stopping, in the most hostile environments. The services and controls provided must be autonomous and timely. Frequently, these devices have the potential to do great harm if they fail.
Real-time systems encompass all devices with performance constraints. Hard deadlines are performance requirements that absolutely must be met. A missed deadline constitutes an erroneous computation and a system failure. In these systems, late data is bad data. Soft real-time systems are characterized by time constraints which can (a) be missed occasionally, (b) be missed by small time deviations, or (c) occasionally skipped altogether. Normally, these permissible variations are stochastically characterized. Another common definition for soft real-time systems is that they are constrained only by average time constraints (examples include on-line databases and flight reservation systems), although such constraints actually refer to throughput requirements rather than the timeliness of specific actions. In soft real-time systems, late data may still be good data, depending on some measure of the severity of the lateness. The methods presented in this text may be applied to the development of all performance-constrained systems, hard and soft alike. When we use the term real-time alone, we are specifically referring to hard real-time systems. In actuality, most real-time systems are a mixture of hard and soft real-time constraints, together with some requirements that have no timeliness requirements whatsoever. It is common to treat these different aspects separately, although when present, the hard real-time constraints tend to dominate the design.
An embedded system contains a computer as part of a larger system and does not exist primarily to provide standard computing services to a user. A desktop PC is not an embedded system, unless it is within a tomographical imaging scanner or some other device. A computerized microwave oven or VCR is an embedded system because it does no standard computing. In both cases, the embedded computer is part of a larger system that provides some noncomputing feature to the user, such as popping corn or showing Schwarzenegger ripping telephone booths from the floor.[2]
Most real-time systems interact directly with electrical devices and indirectly with mechanical ones. Frequently, custom software, written specifically for the application, must control or access the device. This is why real-time programmers have the reputation of being “bare metal code pounders.” You cannot buy a standard device driver or Windows VxD to talk to custom hardware components. Programming these device drivers requires very low-level manipulation. This kind of programming requires intimate knowledge of the electrical properties and timing characteristics of the actual devices.
Virtually all real-time systems either monitor or control hardware, or both. Sensors provide information to the system about the state of its external environment. Medical monitoring devices, such as electrocardiography (ECG) machines, use sensors to monitor patient and machine status. Air speed, engine thrust, attitude, and altitude sensors provide aircraft information for proper execution of flight control plans. Linear and angular position sensors sense a robot's arm position and adjust it via DC or stepper motors.
Many real-time systems use actuators to control their external environment or to guide some external processes. Flight control computers command engine thrust and wing and tail control surface orientation so that the aircraft follows the intended flight path. Chemical process control systems control when, what kind, and the amounts of different reagents are added to mixing vats. Pacemakers make the heart beat at appropriate intervals with electrical leads attached to the walls inside the (right-side) heart chambers.
Naturally, most systems containing actuators also contain sensors. While there are some open loop control systems,[3] the majority of control systems use environmental feedback to ensure that control loop is acting properly.
Standard computing systems react almost entirely to users and little else.[4] Real-time systems, on the other hand, may interact with the user, but have more concern for interactions with their sensors and actuators.
One of the problems that arise with environmental interaction is that the universe has an annoying habit of disregarding our opinions of how and when it ought to behave. The order and arrival times of external events are frequently unpredictable. The system must react to events when they occur rather than when it might be convenient. An ECG monitor must alarm quickly following the cessation of cardiac activity if it is to be of value. The system cannot delay alarm processing until later that evening when the processor load is lower. Many hard real-time systems are reactive in nature, and their responses to external events must be tightly bounded in time. Control loops, as we shall see later, are very sensitive to time delays. Delayed actuations destabilize control loops.
Most real-time systems do one or a small set of high-level tasks. The actual execution of those high-level tasks requires many simultaneous lower-level activities. This is called concurrency. Since single processor systems can only do a single thing at a time, they implement a scheduling policy that controls when tasks execute. In multiple processor systems, true concurrency is achievable since the processors execute asynchronously. Individual processors within such systems schedule many threads pseudoconcurrently (executing a single thread at a time, but switching among them according to some scheduling policy) as well.
Embedded systems are usually constructed with the least expensive (and therefore less powerful) computers able to meet the functional and performance requirements. Real-time systems ship the hardware along with the software as part of a complete system package. Because many products are extremely cost sensitive, marketing and sales concerns push for using smaller processors and less memory. Providing smaller CPUs with less memory lowers the manufacturing cost. This per-shipped-item cost is called recurring cost, because it recurs with each manufactured device. Software has no significant recurring cost—all the costs are bound up in development, maintenance, and support activities, making it appear to be free.[5] This means that most often choices are made that decrease hardware costs while increasing software development costs.
Under UNIX, a developer needing a big array might just allocate space for 1 million floats with little thought for the consequences. If the program doesn't use all that space—who cares? The workstation has hundreds of megabytes of RAM and gigabytes of virtual memory in the form of hard disk storage. The embedded systems developer cannot make these simplifying assumptions. He or she must do more with less, resulting in convoluted algorithms and extensive performance optimization. Naturally, this makes the real-time software more complex and expensive to develop and maintain.
Real-time developers often use tools hosted on PCs and workstations, but targeted to smaller, less capable computer platforms. This means that they must use cross-compiler tools, which are often more temperamental (i.e., buggy) than the more widely used desktop tools. Additionally, the hardware facilities available on the target platform—such as timers, A/D converters, and sensors—cannot be easily simulated accurately on a workstation. The discrepancy between the development and the target environments adds time and effort for the developer wanting to execute and test his or her code. The lack of sophisticated debugging tools on most small targets complicates testing as well. Small embedded targets often do not even have a display on which to view error and diagnostic messages.
Frequently, real-time developers must design and write software for hardware that does not yet exist. This creates very real challenges since developers cannot validate their understanding of how the hardware functions, even though, according to my experience, the hardware never functions exactly as specified. Integration and validation testing become more difficult and time consuming.
Embedded real-time systems must often run continuously for long periods of time. It would be awkward to have to reset your flight control computer because of a GPF[6] while in the air above Newark. The same applies to cardiac pacemakers, which last up to 10 years after implantation. Unmanned space probes must function properly for years on nuclear or solar power supplies. This is different from desktop computers that may be frequently reset at least daily. It may be acceptable to have to reboot your desktop PC when an application crashes the operating system, but it is much less acceptable to have to reboot a life support ventilator or the control avionics of a commercial passenger jet.
Embedded system environments are often adverse and computer-hostile. In surgical operating rooms, electrosurgical units create intense electrical arcs to cauterize incisions. These produce extremely high EMI (electromagnetic interference) and can physically damage unprotected computer electronics. Even if the damage is not permanent, it is possible to corrupt memory storage, degrading performance or inducing a systems failure.
Apart from increased reliability concerns, software is finding its way ever more frequently into safety systems. Medical devices are perhaps the most obvious safety related computing devices, but computers control many kinds of vehicles such as aircraft, spacecraft, trains, and even automobiles. Software controls weapons systems and ensures the safety of nuclear power and chemical plants. There is compelling evidence that the scope of industrial and transportation accidents is increasing [1,2].[7]
For all these reasons, developing real-time software is generally much more difficult than developing other software. The development environments traditionally have had fewer tools, and the ones that exist are often less capable than those for desktop environments or for “Big Iron” mainframes. Embedded targets are slower and have less memory, yet must still perform within tight timing and performance constraints. These additional concerns translate into more complexity for the developer, which means more time, more effort, and (unless we're careful indeed) more defects than standard desktop software of the same size. Fortunately, advances have been made in the development tools, approaches, and processes, which is what this book is all about.
In 2002, the Object Management Group (OMG) adopted the Unified Modeling Language™ (UML) profile that provided a standardized means for specifying timeliness, performance, and schedulability aspects of systems and parts of systems, the so-called Real-Time Profile (RTP) [7]. In the same year, an initial submission was made for a UML profile that detailed a generalized framework for Quality of Service (QoS) aspects—of which timeliness, performance, and schedulability are common examples—as well as a specific profile for fault tolerance mechanisms [8]. To be sure, these profiles are clearly not necessary for modeling the QoS aspects—developers have been doing this for as long as UML has been around (OK, even longer!); however, codifying what the best developers were already doing and defining specific names for the aspects, allows models to be easily exchanged among different kinds of tools, such as UML design and schedulability analysis tools.
These profiles provide a minutely specialized form of UML dealing with the issues important to some domain of concern. In this case, of course, the domain of concern is real-time, high-reliability, and safety-critical systems. These specializations take the form of representation of domain concepts as stereotypes of standard UML elements, with additional tag values for the QoS aspects, whose values can be specified in constraints. The details of the profiles will be discussed later. For now, let's limit our concern to the domain concepts themselves and not to how they are presented in the profiles.
Two critical aspects of real-time systems are how time is handled and the execution of actions with respect to time. The design of a real-time system must identify the timing requirements of the system and ensure that the system performance is both logically correct and timely.
Most developers concerned with timeliness of behavior express it in terms of actual execution time relative to a fixed budget called a time constraint. Often, the constraint is specified as a deadline, a single time value (specified from the onset of an initiating stimulus) by which the resulting action must complete. The two types of time constraints commonly used are hard and soft:
| The correctness of an action includes a description of timeliness. A late completion of an action is incorrect and constitutes a system failure. For example, a cardiac pacemaker must pace outside specific periods of time following a contraction or fibrillation.[8] |
| For the most part, software requirements are placed on a set of instance executions rather than on each specific execution. Average deadline and average throughput are common terms in soft real-time systems. Sometimes, missing an entire action execution may be acceptable. Soft real-time requirements are most often specified in probabilistic or stochastic terms so that they apply to a population of executions rather than to a single instance of an action execution. It is common to specify but not validate soft real-time requirements. An example of a soft real-time specification might be that the system must process 1200 events per second on average, or that the average processing time of an incoming event is 0.8 ms. |
[8] Uncoordinated contraction of random myocardial cells. This is a bad thing. | |
Usually a timing constraint is specified as a deadline, a milestone in time that somehow constrains the action execution.
In the RTP, actions may have the time-related properties shown in Table 1-1.
As Table 1-1 suggests, the basic concepts of timeliness in real-time systems are straightforward even if their analysis is not. Most time requirements come from bounds on the performance of reactive systems. The system must react in a timely way to external events. The reaction may be a simple digital actuation, such as turning on a light, or a complicated loop controlling dozens of actuators simultaneously. Typically, many subroutines or tasks must execute between the causative event and the resulting system action. External requirements bound the overall performance of the control path. Each of the processing activities in the control path is assigned a portion of the overall time budget. The sum[9] of the time budgets for any path must be less than or equal to the overall performance constraint.
Because of the ease of analysis of hard deadlines, most timeliness analysis is done assuming hard deadlines and worst-case completion times. However, this can lead to overdesign of the hardware at a potentially much greater recurring cost than if a more detailed analysis were done.
Table 1-1. Timeliness Properties of Actions
Attribute | Description |
|---|---|
Priority | The priority of the action from a scheduling perspective. It may be set as a result of static analysis or by dynamic scheduling software. |
Blocking Time | The length of time that the action is blocked waiting for resources. |
Ready Time | The effective Release Time expressed as the length of time since the beginning of a period; in effect a delay between the time an entity is eligible for execution and the actual beginning of execution. |
Delay Time | The length of time an action that is eligible for execution waits while acquiring and releasing resources. |
Release Time | The instant of time at which a scheduling job becomes eligible for execution. |
Preempted Time | The length of time the action is preempted, when runable, to make way for a higher-priority action. |
Worst-Case Completion Time | The overall time taken to execute the action, including overheads. |
Laxity | Specifies the type of deadline, hard or soft. |
Absolute Deadline | Specifies the final instant by which the action must be complete. This may be either a hard or a soft deadline. |
Relative Deadline | For soft deadlines, specifies the desired time by which the action should be complete. |
start | The start time of the action. |
end | The completion time of the action. |
duration | The total duration of the action (not used if start and end times are defined). |
isAtomic | Identifies whether the action can be pre-empted or not. |
In the design of real-time systems several time-related concepts must be identified and tracked. An action may be initiated by an external event. Real-time actions identify a concept of timely—usually in terms of a deadline specified in terms of a completion time following the initiating event. An action that completes prior to that deadline is said to be timely; one completing after that deadline is said to be late.
Actions are ultimately initiated by events associated with the reception of messages arising from objects outside the scope of the system. These messages have various arrival patterns that govern how the various instances of the messages arrive over time. The two most common classifications of arrival patterns are periodic and aperiodic (i.e., episodic). Periodic messages may vary from their defined pattern in a (small) random way. This is known as jitter.
Aperiodic arrivals are further classified into bounded, bursty, irregular, and stochastic (unbounded). In bounded arrival times a subsequent arrival is bounded between a minimum interarrival time and a maximum interarrival time. A bursty message arrival pattern indicates that the messages tend to clump together in time (statistically speaking, there is a positive correlation in time between the arrival of one message and the near arrival of the next).[10] Bursty arrival patterns are characterized by a maximum burst length occurring within a specified burst interval. For example, a bouncy button might be characterized as giving up to 10 events within a 20ms burst interval. The maximum burst length is also sometimes specified with a probability density function (PDF) giving a likely distribution or frequency within the burst interval. Lastly, if the events arrivals are truly uncorrelated with each other, they may be modeled as arising randomly from a probability density function (PDF). This is the stochastic arrival pattern.
Knowing the arrival pattern of the messages leading to the execution of system actions is not enough to calculate schedulability, however. It is also important to know how long the action takes to execute. Here, too, a number of different measures are used in practice. It is very common to use a worst-case execution time in the analysis. This approach allows us to make very strong statements about absolute schedulability, but has disadvantages for the analysis of systems in which occasional lateness is either rare or tolerable. In the analysis of so-called soft real-time systems, it is more common to use average execution time to determine a statistic called mean lateness.
Actions often execute at the same time as other actions. We call this concurrency. Due to the complexity of systems, objects executing actions must send messages to communicate with objects executing other actions. In object terminology, a message is an abstraction of the communication between two objects. This may be realized in a variety of different ways. Synchronization patterns describe how different concurrent actions rendezvous and exchange messages. It is common to identify means for synchronizing an action initiated by a message sent between objects.
In modern real-time systems it cannot be assumed that the sender of a message and the receiver of that message are located in the same address space. They may be executing on the same processor, in the same thread, on the same processor but different threads, or on separate processors. This has implications for the ways in which the sender and receiver can exchange messages. The transmission of a message m may be thought of as having two events of interest—a send event followed by a receive event. Each of these events may be processed in either a synchronous or an asynchronous fashion, leading to four fundamental synchronization patterns, as shown in Figure 1-1. The sending of an event is synchronous if the sender waits until the message is sent before continuing and asynchronous if not.[11] The reception of an event is synchronous if the receiver immediately processes it and asynchronous if that processing is delayed. An example of synch-synch pattern (synchronous send–synchronous receive) is a standard function or operation call. A message sent and received through a TCP/IP protocol stack is an example of an asynch-asynch transfer, because the message is typically queued to send and then queued during reception as well. A remote procedure call (RPC) is an example of a synch-asynch pattern; the sender waits until the receiver is ready and processes the message (and returns a result), but the receiver may not be ready when the message is sent.

In addition to these basic types, a balking rendezvous is a synch-synch rendezvous that aborts the message transfer if the receiver is not immediately ready to receive it, while a timed wait rendezvous is a balking rendezvous in which the sender waits for a specified duration for the receiver to receive and process the message before aborting. A blocking rendezvous is a synch-synch rendezvous in which the sender will wait (forever if need be) until the receiver accepts and processes the message.
In lay terms, concurrency is doing more than one thing at once. When concurrent actions are independent, life is easy. Life is, however, hard when the actions must share information or rendezvous with other concurrent actions. This is where concurrency modeling becomes complex.
Programmers and models typically think of the units of concurrency as threads, tasks, or processes. These are OS concepts, and as such available as primitive services in the operating system. It is interesting that the RTP does not discuss these concepts directly. Instead, the RTP talks about an active resource (a resource that is capable of generating its own stimuli asynchronously from other activities). A concurrent Unit is a kind of active resource that associates with a scenario (a sequenced set of actions that it executes) and owns at least one queue for holding incoming stimuli that are waiting to be accepted and processed. Sounds like a thread to me ;-)
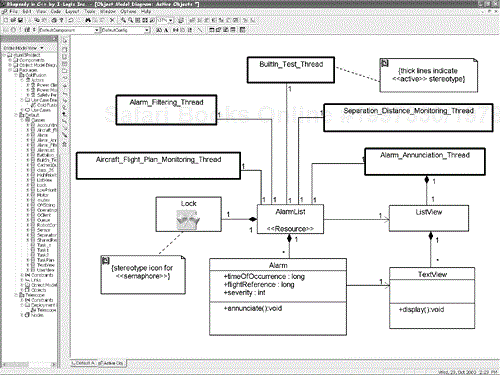
As a practical matter, «active» objects contain such concurrentUnits, have the responsibility to start and stop their execution, and, just as important, delegate incoming stimuli to objects contained within the «active» objects via the composition relationship. What this means is that we will create an «active» object for each thread we want to run, and we will add passive (nonactive) objects to it via composition when we want them to execute in the context of that thread. Figure 1-2 shows a typical task diagram in UML.[12] The boxes with thick borders are the «active» objects. The resource is shown with the annotation «resource», called a stereotype. In the figure, an icon is used to indicate the semaphore rather than the alternative «stereotype» annotation. We will discuss the UML notions of objects and relations in much more detail in the next chapter.
A simple analysis of execution times is usually inadequate to determine schedulability (the ability of an action to always meet its timing constraints). Most timeliness analysis is based, explicitly or implicitly, on a client-resource model in which a client requires a specified QoS from a resource and a resource offers a QoS. Assuming the offered and required values are correct, schedulability analysis is primarily a job of ensuring that offered QoS is always at least as good as required. See Figure 1-3.
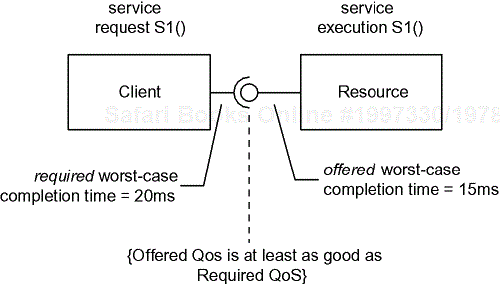
A resource from [7] is defined to be “an element whose service capacity is limited, directly or indirectly, by the finite capacities of the underlying physical computing environment.” Resource is a fundamental concept, one that appears many times in real-time systems. Much of the design of a real-time system is devoted to ensuring that resources act in accordance with their preconditional invariant assumptions about exclusivity of access and quality of service.
The execution times used in the analysis must take into account the blocking time, that is, the length of time an action of a specific priority is blocked from completion by a lower-priority action owning a required resource.
At the best of, uh, times, time itself is an elusive concept. While we lay folks talk about it passing, with concepts like past, present, and future, most philosophers reject the notion. There seem to be two schools of thought on the issue. The first holds that time is a landscape with a fixed past and future. Others feel it is a relationship between system (world) states as causal rules play out. Whatever it may be,[13] with respect to real-time systems, we are concerned with capturing the passage of time using milestones (usually deadlines) and measuring time. So we will treat time as if it flowed and we could measure it.
The RTP treats time as an ordered series of time instants. A timeValue corresponds to such a physical instant of time and may be either dense (meaning that a timeValue exists between any two timeValues) or discrete (meaning there exist timeValue pairs that do not have another timeValue between them). A timeValue measures one or more physical instants. A duration is the interval between two physical instants; that is, it has both starting and ending physical instants. A timeInterval may be either absolute (same as a duration) or relative. So what's the difference between a duration and a timeInterval? A duration has a start and end physical instant, while a timeInterval has a start and end timeValue. Confusing? You bet!
Fortunately, the concepts are not as difficult to use in practice as they are to define precisely. In models, you'll always refer to timeValues because that's what you measure, so timeIntervals will be used more than durations.
Speaking of measuring time....We use two mechanisms to measure time: clocks and timers. All time is with reference to some clock that has a starting origin. It might be the standard calendar clock, or it might be time since reboot. If there are multiple clocks, they will be slightly different, so in distributed systems we have to worry about synchronizing them. Clocks can differ in a couple of ways. They can have a different reference point and be out of synch for that reason—this is called clock offset. They may also progress at different rates, which is known as skew. Skew, of course can change over time, and that is known as clock drift. Offset, skew, and drift of a timing mechanism are all with respect to a reference clock. Clocks can be read, set, or reset (to an initial state), but mostly they must march merrily along. Timers, on the other hand, have an origin (as do clocks) but they also generate timeout events. The current time of a timer is the amount of time that must elapse before a timeout occurs. A timer is always associated with a particular clock. A retriggerable timer resets after a timeout event and starts again from its nominal timeout value, while a nonretriggerable timer generates a single timeout event and then stops.
There are two kinds of time events: a timeout event and a clock interrupt. A clock interrupt is a periodic event generated by the clock representing the fundamental timing frequency. A timeout event is the result of achieving a specified time from the start of the timer.
It might seem odd at first, but the concepts of concurrency are not the same as the concepts of scheduling. Scheduling is a more detailed view with the responsibility of executing the mechanisms necessary to make concurrency happen. A scheduling context includes an execution engine (scheduler) that executes a scheduling policy, such as round robin, cyclic executive, or preemptive. In addition, the execution engine owns a number of resources, some of which are scheduled in accordance with the policy in force. These resources have actions, and the actions execute at some priority with respect to other actions in the same or other resources.
Operating systems, of course, provide the execution engine and the policies from which we select the one(s) we want to execute. The developer provides the schedulable resources in the forms of tasks («active» objects) and resources that may or may not be protected from simultaneous access via mechanisms such as monitors or semaphores. Such systems are fairly easy to put together, but there is (or should be!) concern about the schedulability of the system, that is, whether or not the system can be guaranteed to meet its timeliness requirements.
Determining a scheduling strategy is crucial for efficient scheduling of real-time systems. Systems no more loaded than 30% have failed because of poorly chosen scheduling policies.[14] Scheduling policies may be stable, optimal, responsive, and/or robust. A stable policy is one in which, in an overload situation, it is possible to a priori predict which task(s) will miss their timeliness requirements. Policies may also be optimal.[15] A responsive policy is one in which incoming events are handled in a timely way. Lastly, by robust, we mean that the timeliness of one task is not affected by the misbehavior of another. For example, in a round robin scheduling policy, a single misbehaving task can prevent any other task in the system from running.
Many different kinds of scheduling policies are used. Scheduling policies can be divided into two categories: fair policies and priority policies. The first category schedules things in such a way that all tasks progress more or less evenly. Examples of fair policies are shown in Table 1-2.
Table 1-2. Fair Scheduling Policies
Scheduling Policy | Description | Pros | Cons |
|---|---|---|---|
Cyclic Executive | The scheduler runs a set of tasks (each to completion) in a never-ending cycle. Task set is fixed at startup. |
|
|
Time-Triggered Cyclic Executive | Same as cyclic executive except that the start of a cyclic is begun in response to a time event so that the system pauses between cycles. |
|
|
Round Robin | A task, once started, runs until it voluntarily relinquishes control to the scheduler. Tasks may be spawned or killed during the run. |
|
|
Time-Division Round Robin | A round robin in which each task, if it does not relinquish control voluntarily, is interrupted within a specified time period, called a time slice. |
|
|
[16] By short tasks we mean that for the policy to be fair, each task must execute for a relatively short period of time. Often a task that takes a long time to run must be divided by the developer into shorter blocks to achieve fairness. This places an additional burden on the developer. | |||
In contrast, priority-driven policies are unfair because some tasks (those of higher priority) are scheduled preferentially to others. In a priority schedule, the priority is used to select which task will run when more than one task is ready to run. In a preemptive priority schedule, when a ready task has a priority higher than that of the running task, the scheduler preempts the running task (and places it in a queue of tasks ready to run, commonly known as the “ready queue”) and runs the highest-priority ready task. Priority schedulers are responsive to incoming events as long as the priority of the task triggered by the event is a higher priority than the currently running tasks. In such systems, interrupts are usually given the highest priority.
Two competing concepts are importance and urgency. Importance refers to the value of a specific action's completion to correct system performance. Certainly, correctly adjusting the control surface of an aircraft in a timely manner is of greater importance than providing flicker-free video on a cabin DVD display. The urgency of an action refers to the nearness of its deadline for that action without regard to its importance. The urgency of displaying the next video frame might be much higher than the moment-by-moment actuation control of the control surfaces, for example. It is possible to have highly important, yet not urgent actions, and highly urgent but not important ones mixed freely within a single system. Most scheduling executives, however, provide only a single means for scheduling actions—priority. Priority is an implementation-level solution offered to manage both importance and urgency.
All of the priority-based scheduling schemes in Table 1-3 are based on urgency. It is possible to also weight them by importance by multiplying them by an importance factor wj and then set the task priority equal to the product of the unweighted priority and the importance factor. For example, in RMS scheduling the task priority would be set to
Table 1-3. Priority Scheduling Policies
Scheduling Policy | Description | Pros | Cons |
|---|---|---|---|
Rate Monotonic Scheduling (RMS) | All tasks are assumed periodic, with their deadline at the end of the period. Priorities are assigned as design time so that tasks with the shortest periods have the highest priority. |
|
|
Deadline Monotonic Scheduling (DMS) | Same as RMS except it is not assumed that the deadline is at the end of the period, and priorities are assigned at design time, based on the shortness of the task's deadline. |
|
|
Maximum Urgency First (MUF) | Priorities are assigned at runtime when the task becomes ready to run, based on the nearness of the task deadlines—the nearer the deadline, the higher the priority. |
|
|
Earliest Deadline Scheduling (EDS) | Laxity is defined to be the time-to-deadline minus the remaining task-execution-time. LL scheduling assigns higher priorities to lower laxity values. |
|
|
Least Laxity (LL) | MUF is a hybrid of LL and RMS. A critical task set is run using the highest set of priorities under an RMS schedule, and the remaining (less critical) tasks run at lower priorities, scheduled using LL. |
|
|
Where pj is the priority of task j, wj is some measure of the importance of the completion of the task, and Cj is the period of task j. [10] provides a reasonably rigorous treatment of weighted scheduling policies for generalized scheduling algorithms. Note that some operating systems use ascending priority values to indicate higher priority while others use descending priorities to indicate higher priority.
Since essentially all real-time systems running multiple tasks must coordinate those tasks and share resources, the manner in which those resources are managed is crucial not only to the correct operation of the system but also to its schedulability. The fundamental issue is the protection of the resource from corruption due to interleaved writing of the values or from a reader getting an incorrect value because it read partway through an update from another task. Of course, for physical resources, there may be other integrity concerns as well, due to the nature of the physical process being managed. The most common basic solution is to serialize the access to the resource and prevent simultaneous access. There are a number of technical means to accomplish this. For example, access can be made atomic—that is, no other task is allowed to run when one task owns a resource. Such accesses are made during what is called a critical section. This approach completely prevents simultaneous access but is best suited when the access times for the resource are very short relative to the action completion and deadline times [11]. Atomic access also breaks the priority-based scheduling assumption of infinite preemptibility (that is, when a task will run as soon as it is ready to run and the highest priority ready task in the system). However, if the critical section isn't too long, then a mild violation of the assumption won't affect schedulability appreciably. When a resource must be used for longer periods of time, the use of critical sections is not recommended.
Another common approach to access serialization is to queue the requests. That is useful when the running task doesn't have to precisely synchronize with the resource, but wants to send it a message. Queuing a message is a “send-and-forget” kind of rendezvous that works well for some problems and not for others, depending on whether the resource (typically running in its own thread in this case) and the client must be tightly coupled with respect to time. For example, sending a time-stamped log entry to a logging database via a queue allows the sending task to send the message and go on about its business, knowing that eventually the database will handle the log entry. This would not be appropriate in a real-time control algorithm in which a sensor value is being used to control a medical laser, however.
A third common approach to access serialization is protect the resource with a mutual exclusion (mutex) semaphore. The semaphore is an OS object that protects a resource. When access is made to an unlocked resource, the semaphore allows the access and locks it. Should another task come along and attempt to access the resource, the semaphore detects it and blocks the second task from accessing the resource—the OS suspends the task allowing the original resource client to complete. Once complete, the resource is unlocked, and the OS then allows the highest-priority task waiting on that resource to access it, while preventing other tasks from accessing that resource. When a task is allowed to run (because it owns a needed resource) even though a higher-priority task is ready to run, the higher-priority task is said to be blocked.
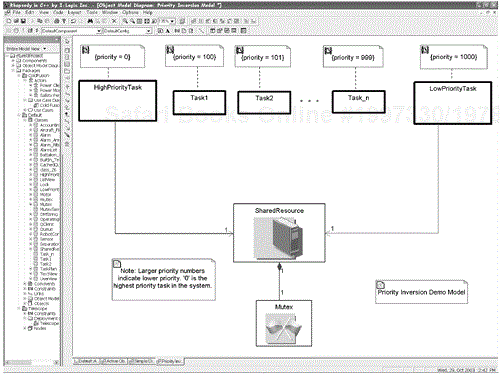
While this approach works very well, it presents a problem for schedulability called unbounded priority inversion. When a task is blocked, the system is said to be in a condition of priority inversion because a lower-priority task is running even though a higher-priority task is ready to run. In Figure 1-4, we see two tasks sharing a resource,[17] HighPriorityTask and the LowPriorityTask. In the model presented here, a low-priority value means the task is a high priority. Note that there is a set of tasks on intermediate priority, Task1 through Task_n, and that these tasks do not require the resource. Therefore, if LowPriorityTask runs and locks the resource, and then HighPriorityTask wants to run, it must block to allow LowPriorityTask to complete its use of the resource and release it. However, the other tasks in the system are of higher priority than LowPriorityTask and then can (and will) preempt LowPriority Task when they become ready to run. This, in effect, means that the highest priority task in the system is blocked not only by the LowPriority Task, but potentially by every other task in the system. Because there is no bound on the number of these intermediate priority tasks, this is called unbounded priority inversion. There are strategies for bounding the priority inversion and most of these are based on the temporary elevation of the priority of the blocking task (in this case, LowPriority Task). Figure 1-5 illustrates the problem in the simple implementation of semaphore-based blocking.
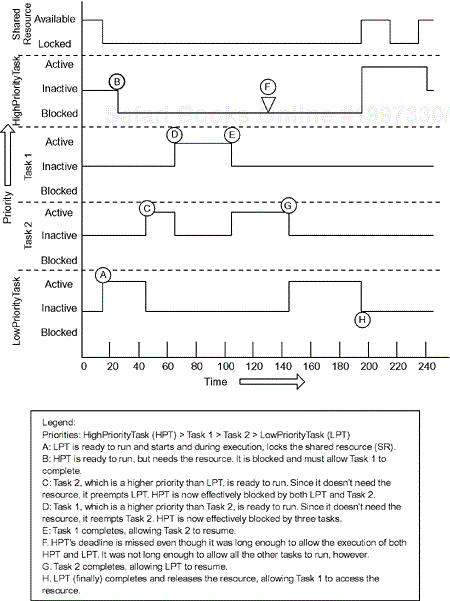
As mentioned, there are a number of solutions to the unbounded priority inversion problem. In one of them, the Highest Locker Pattern of [11] (see also [9,12]), each resource has an additional attribute—its priority ceiling. This is the priority just above that of the highest-priority task that can ever access the resource. The priority ceiling for each resource is determined at design time. When the resource is locked, the priority of the locking task is temporarily elevated to the priority ceiling of the resource. This prevents intermediate priority tasks from preempting the locking task as long as it owns the resource. When the resource is released, the locking task's priority is reduced to either its nominal priority or to the highest priority ceiling of any resources that remain locked by that task. There are other solutions with different pros and cons that the interested reader can review.
An important aspect of schedulability is determining whether or not a particular task set can be scheduled, that is, can it be guaranteed to always meet its timeliness requirements? Because timeliness requirements are usually expressed as deadlines, that is the case we will consider here.
When a task set is scheduled using RMS, then certain assumptions are made. First, the tasks are time-driven (i.e., periodic). If the tasks are not periodic, it is common to model the aperiodic tasks using the minimum interarrival time as the period. While this works, it is often an overly strong condition—that is, systems that fail this test may none theless be schedulable and always meet their deadlines, depending on the frequency with which the minimum arrival time actually occurs. The other assumptions include infinite preemptibility (meaning that a task will run immediately if it is now the highest-priority task ready to run) and the deadline occurs at the end of the period. In addition, the tasks are independent—that is, there is no blocking. When these things are true, then Equation 1-2 provides a strong condition for schedulability. By strong, we mean that if the inequality is true, then the system is schedulable; however, just because it's not true does not imply necessarily that the system is not schedulable. More detailed analysis might be warranted for those cases.
In Equation 1-2, Cj is the execution time for the task. In a worst-case analysis, this must be the worst-case execution time (i.e., worst-case completion time). Tj is the period of the task, and n is the number of tasks. The ratio Cj/Tj is called the utilization of the task. The expression on the right side of the inequality is called the utilization bound for the task set (note that 2 is raised to the power of (1/n)). The utilization bound converges to about 0.69 as the number of tasks grows. It is less than 1.0 because in the worst case, the periods of the tasks are prime with respect to each other. If the task periods are all multiples of each other (for example, periods of 10, 100, 500), then a utilization bound of 100% can be used for this special case (also for the case of dynamic priority policies, such as EDS). As an example, consider the case in which we have four tasks, as described in Table 1-4.
Table 1-4. Sample Task Set
Task | Execution Time (ms) | Period (ms) | Cj/Tj |
|---|---|---|---|
Task 1 | 10 | 100 | 0.1 |
Task 2 | 30 | 150 | 0.2 |
Task 3 | 50 | 250 | 0.2 |
Task 4 | 100 | 500 | 0.2 |
The sum of the utilizations from the table is 0.7. The utilization bound for four tasks is 0.757; therefore, we can guarantee that this set of tasks will always meet its deadlines.
The most common serious violation of the assumptions for Equation 1-2 is the independence of tasks. When one task can block another (resource sharing being the most common reason for that), then blocking must be incorporated into the calculation, as shown in Equation 1-3.
In this equation, Bj is the worst-case blocking for task j. Note that there is no blocking term for the lowest-priority task (task n). This is because the lowest-priority task can never be blocked (since it is normally preempted by every other task in the system).
As mentioned above, it is necessary to take into account any chained blocking in the blocking term. That is, if one task can preempt a blocking task then the blocking term for the blocking task must take this into account. For example, in the model shown in Figure 1-5, the blocking term for HighPriorityTask must include the time that Low PriorityTask locks the resource plus the sum of the worst-case execution time for all the intermediate-priority tasks (because they can preempt LowPriorityTask while it owns the resource), unless some special measure is used to bound the priority inversion.
Detailed treatment of the analysis of schedulability is beyond the scope of this book. The interested reader is referred to [5,9,12], for a more detailed discussion of timeliness and schedulability analysis.
Performance modeling is similar to modeling schedulability. However, our concerns are not meeting specific timeliness requirements but capturing performance requirements and ensuring that performance is adequate. Performance modeling is important for specifying performance requirements, such as bandwidth, throughput, or resource utilization, as well as estimating performance of design solutions. The measures of performance commonly employed are resource utilization, waiting times, execution demands on the hardware infrastructure, response times, and average or burst throughput—often expressed as statistical or stochastic parameters. Performance modeling is often done by examining scenarios (system responses in specific circumstances such as a specific load with specified arrival times) and estimating or calculating the system response properties. Performance analysis is done either by application of queuing models to compute average utilization and throughput or via simulation. This often requires modeling the underlying computational hardware and communications media as well.
One key concept for performance modeling is workload. The workload is a measure of the demand for the execution of a particular scenario on available resources, including computational resources (including properties such as context switch time, some measure of processing rate, and whether the resource is preemptible). The priority, importance, and response times of each scenario are required for this kind of analysis. The properties of the resources used by the scenarios that must be modeled are capacity, utilization (percentage of usage of total available capacity), access time, response time, throughput, and how the resources are scheduled or arbitrated. Chapter 4 discusses the UML Profile for Schedulability, Performance, and Time, and its application for modeling performance aspects.
In many, if not most, real-time and embedded systems development, it is crucial to consider not only the software aspects, but also the system aspects. By systems aspects, we mean those aspects that affect the system as a whole, independent of the implementation technologies (e.g., software, electronic, mechanical, or chemical), as well as how these different design aspects collaborate. By systems engineering we mean the definition, specification, and high-level architecture of a system that is to be realized with multiple disciplines, typically including electrical, mechanical, software, and possibly chemical engineering. The primary activities encompassed by systems engineering include
Capturing, specifying and validating the requirements of the system as a whole
Specification of the high-level subsystem architecture
Definition of the subsystem interfaces and functionality
Mapping the system requirements onto the various subsystems
Decomposing the subsystems into the various disciplines—electronic, mechanical, software, and chemical—and defining the abstract interfaces between those aspects
In all these activities, systems engineers are not concerned with the design of the discipline-specific aspects of the software or the electronics, but are concerned with the specification of what those design aspects must achieve and how they will collaborate.
The use of UML in systems engineering is increasing. A number of papers have been written on the topic (for examples, see [13,14]). The OMG has recently released a request for proposal (RFP) called “UML for Systems Engineering: Request for Proposal” [15]. At the time of this writing, work is underway creating a UML variant for this purpose.[18] The current schedule calls for adoption of this language variant in mid-2004.
In the ROPES process (described later in this chapter) architecture is defined as the set of strategic design decisions that affect the structure, behavior, or functionality of the system as a whole. The ROPES process goes on to discuss five primary aspects of architecture:
Subsystem/Component Architecture—. The large-scale pieces of the system that can be done prior to the decomposition of the system into hardware and software aspects, or may refer to the large-scale software pieces, as appropriate for the project.
Resource and Concurrency Architecture—. The identification of the concurrent tasks, how the primitive semantic objects map into those threads, the scheduling policies, and policies for synchronization and resource management. Note that in the UML, the primary unit of concurrency is the «active» object, which creates and owns the thread in which it executes. Note also that this is primarily a software architecture concern and has a relatively minor impact on system engineering and hardware architectures. However, it does impact the selection of processors and connection media such as networks and busses.
Distribution Architecture—. The identification of how objects map into different address spaces, and how they will communicate across those address space boundaries, including distribution patterns (such as Publish/Subscribe, Broker, etc.) and communication protocols.
Safety and Reliability Architecture—. The specification of how faults will be identified, isolated, and managed during runtime. This typically includes the redundant architectural substructures and their management in the event of faults.
Deployment Architecture—. The specification of how the different architectural aspects relate to each other, specifically the software, mechanical, electronic, and chemical aspects. This can be done asymmetrically, where each piece of software is assigned at design time to run on a particular hardware target, or symmetrically where runtime locale decisions are made dynamically at runtime to permit load-balancing.
We call these architectural aspects because there is a single system that in fact contains all of these. Therefore the system model must likewise have an architecture that contains all of these different aspects in a coherent and consistent way. Systems engineers are responsible for the subsystem and component architecture, the safety and reliability architecture, and the deployment architecture. They also may heavily influence, although not completely design, the other architectural aspects—distribution and concurrency and resource architectures. Software engineers may be responsible for the subsystem and component architectures for the software, most of the concurrency and resource management architecture, and parts of the distribution, deployment, and safety and reliability architectures. In the next chapter, we'll talk about how to represent these different architectural views using the UML.
The Rapid Object-Oriented Process for Embedded Systems (ROPES) Process[19]
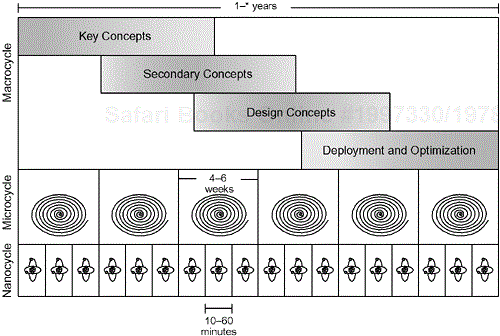
The ROPES process exists on three time scales simultaneously:
Macro—. The entire length of the project, typically one to several years
Micro—. The time required to produce a single increment or version of the system that achieves some targeted functionality—typically four to six weeks
Nano—. The time needed to produce, compile, execute, and/or test some very small portion of the system—typically 30 minutes to an hour
You can see that the macrocycle is divided up into four overlapping macrophases:
Key concepts
Secondary concepts
Design concepts
Optimization and deployment concepts
In each macrophase, there are usually several incremental prototypes produced. For example, if the macrocycle is 18 months long, you would expect the key concept macrophase to be on the order of four to five months long. This would encompass anywhere from three to five microcycles. Each microcycle results in a single prototype, so in this example, there would be three to five versions of the system incrementally produced that primarily focused on identification, specification, and elaboration of key concepts, whether these concepts are requirements, architecture, or technological concepts. Later prototypes would spend less effort on these key concepts but add more concern on the secondary and tertiary concepts. Still later prototypes would focus more on design and implementation issues, while the last set would tend to focus on optimization and deployment issues. Each prototype has a testable mission—its purpose—which tends evolve over time.
The ROPES process defines an alternative lifecycle used when there is significant codesign and some of the hardware components have a long lead time—the SemiSpiral lifecycle shown in Figure 1-7. This macrocycle at first proceeds like a waterfall—a complete requirements capture phase is followed by a complete systems engineering phase. This allows the specification of all the requirements and all the high-level architecture. Thus the long-lead-time hardware devices can be designed with a complete knowledge of all the requirements, with the downside being that if there are strategic defects in either the requirements or the high-level architecture, they will be costly to correct (similar to the waterfall lifecycle). Nevertheless, the design continues in a multidisciplinary spiral, so that early and frequent testing still results in a higher-quality product than a waterfall lifecycle.
The nanocycle[20] is the constant design-execution-debug cycle that is most successful designers' preferred style of working. The idea is that you should constantly ask and answer the question “Is this right?” never being more than minutes away from being able to demonstrate that it is right. The use of executable UML tools, such as Rhapsody®, allows you do accomplish this easily and with less effort, because Rhapsody can execute your UML models almost immediately.
The current state-of-the-art in software development process relies on a small number of important principles:
Iterative Development—. Iterative development is based on the concept of incremental construction; that is, building a large-scale product by constructing it as a series of smaller products of increasing completeness. Because the prerelease versions of the system are smaller, they are easier to “get right” by testing, and this testing can come much earlier than in a waterfall lifecycle. To be effective, the rapid prototypes must be production-quality software, be small focused pieces of the overall application, and address identified or perceived risks.
Use of Models—. Large, complex systems can't be effectively constructed using only source-code-level constructs. Abstract models permit the developers to capture the important characteristics of the application and how they interrelate. Models provide us with a way of thinking about the application domain by representing domain concepts as model elements. This enables us to structure the application around the concepts and properties of the application domain, which is much easier to prove correct because domain experts are available in our domain areas.
Model-Code Bidirectional Associativity—. For model-based systems, it is absolutely crucial that the code and the diagrams are different views of the very same underlying model. If the code is allowed to deviate from the design model, then the separate maintenance of the code and model becomes burdensome, and the system ultimately becomes code-based. As such, system complexity can no longer be effectively managed.
Executable Models—. You can only test things that execute—therefore, build primarily executable things, both early and often. The key to this is model-based translation of designs so that transforming a design into something that executes takes on the order of seconds to minutes, rather than weeks to months using traditional hand-implementation approaches.
Debug and Test at the Design Level of Abstraction—. Because today's applications are extremely complex, we use abstract design models to help us understand and create them. We also need to debug and test them at the same level. We need to be able to ask “Should I put the control rod into the reactor core?” rather than merely “Should I be jumping on C or NZ?”
Test What You Fly and Fly What You Test—. Simulation has its place, but the purpose of building and testing executable models is to quickly develop defect-free applications that meet all of their functional and performance requirements. Using appropriate technology, you can get all the benefits of rapid iterative development and deployment, model-level debugging, and executable models using generated production-level software so that the formal testing only needs to be done once.
Using these six principles, even the most demanding and complex real-time and embedded system can be effectively developed. Most development methodologies in practice today utilize these principles—some more effectively than others, mind you—and the approach I recommend is no different.
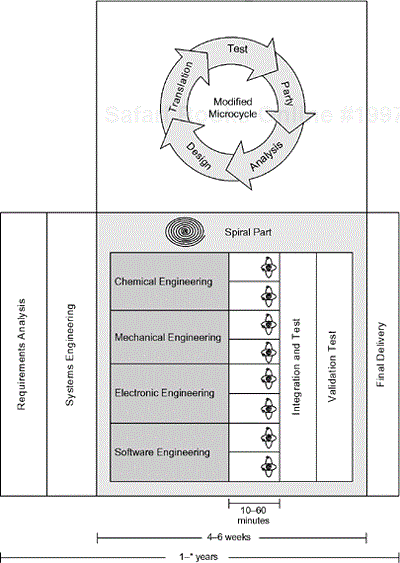
The microcycle is the “spiral” portion of the process, lasting usually four to six weeks (although if it's somewhat shorter or longer than this, it really doesn't matter) and resulting in a single incremental version of the system (called a prototype) that meets a specific mission. The prototype mission is usually a combination of some set of use cases (capabilities or coherent sets of requirements), reduction of some specific risks, and/or the addition of some set of technologies.
The microcycle, or spiral, shown in Figure 1-8, is divided into five primary microphases:
Party—. devoted to project planning, project assessment, and process improvement
Analysis—. devoted to identifying the essential properties required of the prototype, that is, properties without which the system would be considered “wrong”
Design—. devoted to identifying a specific optimal solution consistent with the analysis model
Translation—. devoted to the production of high-quality, defect-free components of the prototype, completely unit-tested and inspected
Testing—. devoted to ensuring that the architecture is properly met (integration) and that the prototype meets its mission (validation), including required performance

We can see that there is a systems engineering subphase in the analysis microphase. This does not mean or imply that it is only during this period that system engineers are doing useful work. Rather, it defines a particular set of activities resulting in a particular set of artifacts released at the end of the subphase. The workflow of the systems engineer is discussed in more detail later in this book.
The spiral approach is a depth-first approach of system development. Although in the first party phase, the expected use cases are named and roughly scoped, they are not detailed until the project matures to that point in the schedule. Thus, development proceeds without a detailed understanding of all of the requirements; instead, the focus is on the higher-risk issues and requirements, so that they are completely understood before those of lesser risk and significance are detailed. The early testing of the high-risk and high-importance aspects of the system reduces risk optimally, and the early and frequent testing ensures that the system produced is of high quality.
The major activities in the ROPES spiral are:
Analysis—. defines the essential application properties that must be true of all possible, acceptable solutions, leaving all other characteristics free to vary. Analysis consists of three parts:
Requirements analysis—. Requirements analysis identifies in detail the black-box[21] requirements, both functional and performance, of the system without revealing the internal structure (design).
Systems engineering—. In multidisciplinary systems development—that is, those that include software, electronic, mechanics, and possible chemical aspects—the system architecture is constructed early and system-level requirements are mapped down onto the various aspects of the architecture.
Object (domain) analysis—. In object analysis, the various concepts inherent in the various domains of concern are identified, along with their relations to each other. This is normally done one use case at a time. There are two primary aspects of object analysis: structural and behavioral.
Object structural analysis—. identifies the key abstractions of the application that are required for correctness, as well as the relation that links them together. The black box functional pieces are realized by collaborations of objects working together.
Object behavioral analysis—. identifies how the key abstractions behave in response to environmental and internal stimuli, and how they dynamically collaborate together to achieve system-level functionality.
Design—. Design defines a particular solution that optimizes the application in accordance with the project objectives while remaining consistent with the analysis model. Design is always about optimization. Design also consists of three parts:
Architectural design—. Architectural design identifies the strategic design decisions that affect most or all of the application, including the mapping to the physical deployment model, the identification of runtime artifacts, and the concurrency model. This is typically accomplished through the application of architectural design patterns.
Mechanistic design—. Mechanistic design adds to the collaborations to optimize their behavior according to some system optimization criteria. This is typically done through the application of mechanistic design patterns.
Detailed design—. Detailed design adds low-level information necessary to optimize the final system.
Translation—. Translation creates an executable application from a design model. Translation normally includes not only the development of executable code but also the unit-level (i.e., individual object) testing of that translation.
Testing—. Testing applies correctness criteria against the executable application to either identify defects or to show a minimal level of conformance to the requirements and/or design. Testing includes, at minimum, integration and validation testing.
These activities may be arranged in many different ways. Such an arrangement defines the development process used for the project. The iterative development process looks like Figure 1-8.
The iterative development process model shown in Figure 1-8 is known as ROPES, for rapid object-oriented process for embedded systems (see [5] for a more complete description). Each iteration produces work products, known as artifacts. A single iteration pass, along with the generated artifacts, is shown in Figure 1-9. This model is somewhat simplified in that it doesn't show the subphases of analysis and design, but does capture the important project artifacts, how they are created and used.
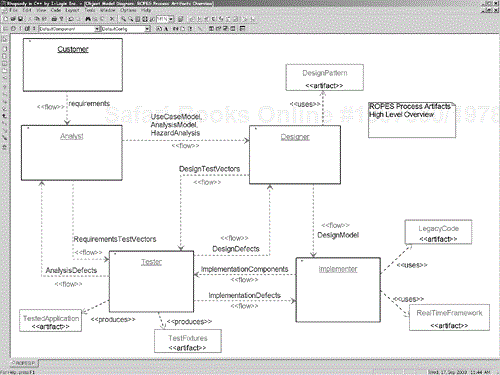
Rhapsody from I-Logix[22] is an advanced model creation tool with integrated product-quality code generation and design-level testing capabilities built in. Rhapsody was developed specifically to aid in the development of real-time and embedded systems, and integrates smoothly into the ROPES process model. Fully constructive tools, such as Rhapsody assist by providing support for all of the precepts mentioned at the beginning of this section. Although the UML in general and the ROPES process in particular can be applied using manual means for translation of models into code and debugging and testing that code, the use of such powerful automated tools greatly enhances their effectiveness. shows how a fully constructive tool can aid in the generation of development phase artifacts. Table 1-5 shows which artifacts are created in the various phases of the ROPES process.
Table 1-5. Phased Artifacts in the ROPES Process
Activity | Process Step | Generated Artifacts | Tool Generated Artifacts |
|---|---|---|---|
Analysis | Requirements Analysis | Use case model Use case scenarios | Use case diagrams Use case descriptions Message sequence diagrams Use case statecharts and/or activity diagrams Report generation |
Object Structural Analysis | Structural object model | Class diagrams Object diagrams Reverse engineering creates models from legacy source code Report generation | |
Object Behavioral Analysis | Behavioral object model | Message sequence diagrams Statecharts Activity diagrams Report generation | |
Design | Architectural Design | Subsystem model Concurrency model Distribution model Safety/reliability model Deployment model | Architectural class and object diagrams Architectural design patterns Active objects Component model (file mapping) Framework provides OS-tasking model Use of existing legacy code and components |
Mechanistic Design | Collaboration model | Class diagrams Message sequence diagrams Framework provides design patterns Framework provides state execution model | |
Detailed Design | Class details | Browser access to
Round-trip engineering updates model from modified source code | |
Translation | Executable application | Fully-executable code generated from structural and behavioral models including
| |
Testing | Unit Testing Integration Testing Validation Testing | Design defects Analysis defects | Design level debugging and testing on either host or remote target, including
Simultaneous debugging with other design-level tools (such as Rhapsody from I-Logix) and source-level debuggers |
A model is an integrated set of abstractions and their internal relations. Models are expressed in a modeling language that consists of two parts: a set of abstract elements (called metaclasses), which is a syntax for representing and viewing these elements and their relations, and a semantic framework that specifies the precise meaning of these abstract elements.
A model may support any number of different views. A UML class diagram may show a number of classes interacting together to realize a use case, for example. Another class diagram may show the same class in a generalization taxonomy. Still another class diagram may show how the class fits within its domain of interest. The behavioral constraints of a class may be represented as a statechart that shows how it responds to different events in different circumstances. Source code representing the implementation of the class can be viewed as text.
None of these views is, by itself, the model. Each is a narrow, restricted view of the model, using a particular graphical syntax to represent a particular point of view. The model is, in fact, the logical conjugation of the information shown in all views of the model. A class diagram is no more (or less) a model of a system than the source code. Both are important views of the model that concentrate on different aspects. This distinction between model and view is very important, as it turns out, in system development and maintenance, as we shall explore.
An executable model is a model that is defined with a rich enough set of semantics that its execution behavior is predictable. One can argue that any model that can be represented ultimately as executable machine code is, in fact, an executable model. At least two distinct views of an executable model must be constructed. The first is the structural view. What is the information manipulated by the model and how is it logically represented? What are the relationships among these structural elements? In the UML, for example, the structural view is represented by class diagrams (for logical elements) and object, deployment, and component diagrams (for physical elements). Secondly, what are the operations permitted to be done on that information and what constraints apply to the execution of those operations? The UML provides sequence, communication, and timing diagrams to show how model elements collaborate together and statecharts and activity diagrams to show how the behavior individually. Given these two views of a model, it is possible, in every important sense, to execute the model.
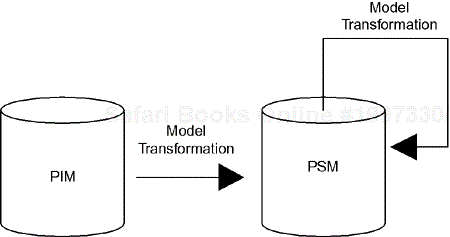
MDA is an approach that separates aspects of a model that are independent of underlying technologies from those that are dependent upon those aspects. The platform-independent model (PIM) is constructed to be independent of the processor(s) on which it runs, the communication infrastructure (such as Ethernet and TCP/IP), middleware (such as COM or CORBA), and even the implementation language (such as C or Ada). From the PIM, the platform-specific model (PSM) is constructed, either by translation or by elaboration (although the literature focuses primarily on the former). The PSM incorporates these aspects of the physical realization of the system. Of course, this can be done in stages, resulting in a succession of increasingly detailed PSMs until all the physical details of the system have been completely specified. Figure 1-10 shows this process schematically.
What does this mean in practice? Different tools support MDA to different degrees. Most tools are completely nonconstructive and nongenerative, and do not execute in any way. In such tools, the user must maintain two different models, performing the translation from the PIM to the PSM manually. Constructive tools handle more or less of this translation for you. Figure 1-11 shows how the Rhapsody® tool from I-Logix approaches MDA.

The Rhapsody tool can be thought of as consisting of several parts. The most visible to the user are the graphic editors used to perform model entry and manipulation and the report generator. Behind the scenes, however, there is an elaborate system that compiles your model and can control and monitor the execution of the model. The model compiler takes the model semantics entered by the user via the diagrams and compiles it into source code that can be fed into a standard compiler for language such as C, C++, Java, and Ada. The model-code association component maintains the model and the code “in sync,” whether the user modifies the model or the source code directly, eliminating the very pervasive problem of what to do when the model and the code disagree.
The model execution aspects of Rhapsody allow you to insert events, set breakpoints, and step and run the application. The model monitoring aspects of the tool allows the user to see the execution of the system at the model level—that is, see sequence diagrams drawn dynamically as the system runs, view the execution of the state machines and activity diagrams of the various objects of the system, examine the attributes, and so on. These tools allow the user to control and monitor the application execution on the user's desktop or on the actual target hardware. The Rhapsody Test Conductor® is a scenario-based test environment built on top of that debugging infrastructure that constructs (and applies) test vectors from the requirements scenarios. Of course, all of this uses the underlying model semantics stored in the model repository.
The compiler and linker work together to compile the output of the model compiler and compile in legacy source-code components. Precompiled components, such as third-party libraries, are linked in with the compiled application to create the PSM. The PSM consists of the PIM with bindings (links) into platform-specific aspects, including the PIM, the platform-independent framework (PIF), and the RTOS Adaptor, and any linked components. This PSM sits on top of any middleware, such as COM or CORBA, the RTOS, and, of course, the target hardware.
While this is not intended to be a book on project management and scheduling, I think it is an important enough topic to share what the ROPES process has to say on the subject. In my experience, lack of good scheduling is a leading cause of project failure, so while it might be a bit tangential, I will offer a few thoughts on the topic.
There are two primary reasons projects are estimated and scheduled. These two reasons are incompatible and mutually exclusive. Nevertheless, they are often combined—with disastrous results.
The primary reason for estimating and scheduling projects is to plan—and this requires the understanding of the cost and resource and time-based properties of the project. For example:
When will the project be done?
How much will it cost?
Is this project likely to provide a good return on investment (ROI)?
Should I invest in this project or another project?
How many resources must I apply to it?
Do I need to hire people and if so, with what skills?
When should I begin ancillary activities, such as gearing up manufacturing, starting the marketing campaign, beginning the next project?
These are legitimate business questions and can only be answered with accurate schedules constructed from reasonable estimates.
The other primary use for schedules is motivation. Motivational (i.e., optimistic) schedules are used to inspire workers to apply their lazy selves to the project at hand and not goof off. Also to donate their nonwork time (i.e., professional time) to the project. To accomplish this motivation, the project requires a sense of urgency, and this is instilled by constructing a schedule that is unachievable without Herculean efforts, if at all. An accurate schedule is actually an impediment to this motivational goal, so that the two primary uses for schedules are in fact at odds with each other.
The real difficulty arises when a schedule is used for both purposes. The schedule is constructed to be optimistic but then used as if it were an accurate planning tool. The first step to estimating and scheduling projects is to select for which of these purposes the schedule is to be used. If it is to be used to plan, then the goal should be an accurate schedule. If it is to motivate, then an urgent schedule should be created. If both are needed, then you need to create two different schedules.
In reality, the only really appropriate use for schedules is for planning. In my experience, the vast majority of engineers are highly motivated, hardworking professionals[23] who respond best to being treated as if they were. For this reason, we will assume that our goal is the first purpose—the creation of schedules that are accurate and reasonable so that they are useful tools for planning. We will relegate the use of motivational schedules to the Dilbertesque business environments where they belong.
As a group, we engineers fail miserably at accurately estimating how long things will take. Studies of just how bad we are at this abound in the literature. In one 1995 study, 53% of all projects were almost 200% over budget and 31% were cancelled after being started. Other and more recent studies confirm these results. In a more recent study, 87% of the projects missed functionality expectations, 73% were delivered late, and a full 18% of the projects were so off the mark that they were cancelled after development had completed.
There are many reasons why this is true. The primary reason for such incredibly poor estimation success, in my experience, is because engineers are actively encouraged not to be accurate. For example, one manager told me, in response to my estimate for a project, “That's the wrong number. Go do it again.” Of course, this anti-accuracy bias is based in the desire for motivational, rather than accurate, schedules. While the desire itself may be well meant (such as maximizing fourth-quarter revenue), one cannot ignore the facts without consequence.
Even if being done with the best of intentions, estimation is hard! Estimation is inherently more inaccurate than observation for obvious reasons. Good estimation is possible, but it will never be as accurate as hindsight in principle. A good estimate must come to embrace uncertainty as a way of life but understand that the more you know the more accurate your estimates will be. The further along you are in the project, the more accurate your estimates will be. Schedule management must in principle include refinement of estimates and the schedule over time, resulting in ever-increasing accurate forecasts. In practice, few engineers are trained in estimation or even rewarded for accuracy; in fact, far too often, engineers are actively encouraged to give inaccurately low estimates.
The ROPES process provides means for both constructing estimates and for improving one's ability to estimate. These (sub)processes are known as BERT and ERNIE.
Bruce's Evaluation and Review Technique (BERT) is the ROPES way of constructing estimates. Estimates are always applied to estimable work units (EWUs). EWUs are small, atomic tasks typically no more than 80 hours in duration.[24] The engineer estimating the work provides three estimates:
The mean (50%) estimate
The optimistic (20%) estimate
The pessimistic (80%) estimate
Of these, the most important is the 50% estimate. This estimate is the one that the engineer will beat half of the time. The central limit theorem of statistics states that if all of the estimates are truly 50% estimates, then overall the project will come in on time. However, this estimate alone does not provide all necessary information. You would also like a measure of the perceived risk associated with the estimate. This is provided by the 20% and 80% estimates. The former is the time that the engineer will beat only 20% of the time, while the latter will be beat 80% of the time. The difference between these two estimates is a measure of the confidence the engineer has in the estimate. The more the engineer knows, the smaller that difference will be.
These estimates are then combined to come up with the estimate actually used in the schedule using equation 1-4.
The estimate confidence (EC) factor is based on the particular engineer's accuracy history. An ideal estimator would have an EC value of 1.00. Typical EC values range from 1.5 to 5.0. As an estimator's ability to estimate improves, that number gets smaller over time, (hopefully) approaching 1.00.
We also want engineers to improve their ability to estimate. As Tom DeMarco notes, “If you don't track it, you can't control it.” The approach in the ROPES process for estimation improvement is called Effect Review for Nanocycle Iteration Estimation (ERNIE). It consists of tracking estimated versus actual and recording these. From this, the EC factor used in Equation 1-4 is computed.
A sample from an estimation tracking spreadsheet is shown in Table 1-6.
To construct a new EC value, use the formula
ECn + 1 = ∑(deviations using ECn)/(# of estimates) + 1.00
For example, to construct a new EC value from Table 1-6, you would compute
EC2 = (0.425 + 0.56 + 0.842 + 0.1)/4 + 1.00 = 1.48
In this example, the engineer went from an EC factor of 1.75 to and EC factor of 1.48 (a significant improvement). This EC value will be used to adjust the “unadjusted used” computed estimate for insertion in the schedule. It is important to track estimation success in order to improve it. In order to improve a thing, it is necessary to track it.
A schedule is a sequenced arrangement of EWUs taking into account which can be run in parallel and which must be serialized. Further, the schedule must take into account inherent dependencies, level of risk, and the availability of personnel.
The waterfall lifecycle scheduling is often considered more accurate by naïve managers because schedules are constructed early and may be tracked against for the remainder of the project. However, this ignores the fundamental rule of scheduling: The more you know, the more accurate you can be. Early schedules are inherently inaccurate because you know less than you do one third, one half, or even seven eights of the way through a project than you do at the end. So it is ridiculous in principle to state at the outset of a project that it will be done in 18 months, 3 days, 6 hours, 42 minutes, and 13 seconds. Nevertheless, managers often act as if they can dictate the passage of time and the invention of software.
The BERT and ERNIE approach can be applied to waterfall or spiral projects. In either approach, though, early estimates will be less accurate than later refinements, when later refinements take into account information gleaned from observing the progress of the project. In principle, I believe the following accuracies for a waterfall lifecycle are achievable:[25]
Concept ± 50%
Requirements ± 25%
Systems analysis ± 20%
Design ± 15%
Implementation ± 10%
Validation testing ± 5%
When schedules are first constructed, in the concept phase, “10 person-years” means, in fact, anywhere from 5 to 15 person-years. If you need a hard number, then go with 15, but if your estimation process is fairly good, then 10 will be the most accurate single number you can provide.
In the spiral approach, the milestones are not the end of these waterfall phases, but instead planned prototypes. If you plan for 10 prototypes, then your first working schedule will have 10 primary milestones, one for each prototype. On average, these will usually be four to six weeks apart, but some may be longer or shorter, depending on their scope. If you want to construct larger-scale milestones, similar to preliminary design review (PDR) and critical design review (CDR) called out by some development methodologies, then you (somewhat arbitrarily) say that one prototype (say 3) will form the basis of the PDR and a later one (say 6) will form the basis of the CDR.
The ROPES scheduling approach uses the Central Limit Theorem from statistics, which states that if you take enough samples from a population, your accumulated samples will form a Gaussian distribution. What that means is that if you have enough estimates of the pieces and they are in fact 50% estimates, then half of them will be early, half of them will be late, and overall, your project will be on time.
That having been said, schedules must be not only tracked against, but also managed and maintained. Assessment and realignment of the schedule is one of the primary activities done in the so-called party phase of the ROPES microcycle.
Figure 1-12 shows a constructed schedule using prototypes as the primary scheduling points on a Gantt chart. Each prototype has a mission, defined to be a set of requirements (normally one to a small number of use cases) to be developed and a set of risks to be reduced. In the figure, the first such prototype, called “Hello World,” is subdivided into the microcycle phases, each with some time attached to it. We see that in this particular example, PDR, CDR, and customer review activities are specifically scheduled. This schedule is tracked against on a daily, or at least weekly, basis, and modified to incorporate new information as it becomes available. The net result is a self-correcting schedule that improves over time.

Other scheduling views are important as well—especially the resource view that shows how your people are mapped against the schedule. Special care must be taken to ensure that they are neither over- nor underutilized in your schedule.
Figure 1-13 is a resource histogram showing the loading of a resource over time.[26] In the example, you want to be sure to neither over- nor underutilize the resource. This means that for a typical eight-hour workday, you should not assume more than four to six hours of productive work effort per day, the actual value of which varies according to the business environment. You should also not assume that a work year is more than 45 weeks, to account for sick and vacation time,[27] training, and other business activities that may be not directly related to your project.
Figure 1-12 shows a highly serial set of prototypes. It is possible to run some prototypes in parallel and merge them together in a future prototype. This makes the schedule a bit more complex, but it may be more optimal. The important thing is to come up with a plan that you actually intend to follow. This allows you to be more accurate and to effectively track against the plan to see how you're doing.
Tracking against the schedule is crucial. In virtually all things, the earlier you try to correct something, the cheaper and easier it is. This is especially true with schedules. This means that you must schedule what actually is supposed to happen and must identify deviations from that plan. If you have a schedule but it does not reflect how the work is being done, you cannot track against it. The work against the EWUs (such as the “Design Phase of Prototype 3”) must be tracked if you want to be able to make adjustments, either to take advantage of the fact that it is coming in early or to adjust for the fact that it appears to be coming in late. The earlier you have this information, the easier that adjustment process will be.
Adjusting the schedule may involve
Adding or removing manpower to an activity
Outsourcing a component
Dropping a feature
Replanning subsequent scheduled items
Schedules are dynamic entities that change over time. They are never completely accurate, except perhaps in hindsight, but a good scheduler can take advantage of the elasticity of a schedule and use it to guide the management of the project to a successful conclusion.
In simple-enough systems, you can pretty much do anything you like and still succeed. Once you have a system complex enough to require more than one person, then it begins to matter what you do and how you do it. Once there are teams of people in place, it matters a great deal how the work is organized for the teams to effectively work together.
The reasons for worrying about model organization are to
Allow team members to contribute to the model without losing changes made by those or other team members, or in some other way corrupting your model
Allow team members to use parts of the model they are not responsible for developing
Provide for an efficient build process so that it is easy to construct the system
Be able to locate and work on various model elements
Allow the pieces of the system to be effectively reused in other models and systems
At first blush, it might appear that the first two issues—contributing and using aspects of a common model—are dealt with by configuration management (CM). This is only partially true. CM does provide locks and checks such that only one worker can own the “write token” to a particular model element and other users can only have a “read token.” However, this is a little like saying that C solves all your programming problems because it provides basic programmatic elements such as assignment, branching, looping, and so on. CM does not say anything about what model elements ought to be configuration items (CIs), only that if a model element is a CI, then certain policies of usage apply. Effective model organization uses the CM infrastructure but provides a higher-level set of principles that allow the model to be used effectively.
For example, it would be awkward in the extreme if the entire model were the only CI. Then only a single worker could update the model at a time. This is clearly unacceptable in a team environment. The other extreme would be to make every model element at CI—for example, every class and use case would be a separate CI. Again, in simple systems, this can work because there are only a few dozen total model elements, so it is not too onerous to explicitly check out each element on which you need to work. However, this does not work well on even medium-scale systems. You would hate to have to individually list 30 or 40 classes when you wanted to work on a large collaboration realizing a use case.
The UML provides an obvious organizational unit for a CI—the package. A UML package is a model element that contains other model elements. It is essentially a bag into which we can throw elements that have some real semantic meaning in our model, such as use cases, classes, objects, diagrams, and so on. However, UML does not provide any criteria for what should go into one package versus another. So while we might want to make packages CIs in our CM system, this begs the question as to what policies and criteria we should use to decide how to organize our packages—what model elements should go into one package versus another.
A simple solution would be to assign one package per worker. Everything that Sam works on is in SamPackage, everything that Julie works on is in JuliePackage, and so on. For very small project teams, this is in fact a viable policy. But again, this begs the question of what Sam should work on versus Julie. It can also be problematic if Susan wants to update a few classes of Sam's while Sam is working on some others in SamPackage. Further, this adds artificial dependencies of the model structure on the project team organization. This will make it more difficult to make changes to the project team (say to add or remove workers) and will really limit the reusability of the model.
It makes sense to examine the user workflow when modeling or manipulating model elements in order to decide how best to organize the model. After all, we would like to optimize the workflow of the users as much as possible, decoupling the model organization from irrelevant concerns. The specific set of workflows depends, of course, on the development process used, but there are a number of common workflows:
Requirements
Working on related requirements and use cases
Detailing a use case
Create set of scenarios
Create specification of a use case via statechart or activity diagram
Mapping requirements (e.g., use cases) to realizing model elements (e.g., classes)
Realizing requirements with analysis and design elements
Elaborating a collaboration realizing a use case
Refining collaborations in design
Detailing an individual class
Designing the architecture
Logical architecture—. working on a set of related concepts (classes) from a single domain
Physical architecture—. working on a set of objects in a single runtime subsystem or component
Construction and testing
Translation of requirements into tests against design elements
Execution of tests
Constructing the iterative prototypes from model elements at various stages in the project development
Planning
Project scheduling, including work products from the model
When working on related requirements and use cases, the worker typically needs to work on one or more related use cases and actors. When detailing a use case, a worker will work on a single use case and detailed views—a set of scenarios and often either an activity diagram or a statechart (or some other formal specification language). When elaborating a collaboration, the user will need to create a set of classes related to a single use case, as well as refining the scenarios bound to that use case. These workflows suggest that one way to organize the requirements and analysis model is around the use cases. Use packages to divide up the use cases into coherent sets (such as those related by generalization, «includes», or «extends» relations, or by associating with a common set of actors). In this case, a package would contain a use case and the detailing model elements—actors, activity diagrams, statecharts, and sequence diagrams.
The next set of workflows (realizing requirements) focus on classes, which may be used in either analysis or design. A domain, in the ROPES process, is a subject area with a common vocabulary, such as User Interface, Device I/O, or Alarm Management. Each domain contains many classes, and system-level use case collaborations will contain classes from several different domains. Many domains require rather specialized expertise, such as low-level device drivers, aircraft navigation and guidance, or communication protocols. It makes sense from a workflow standpoint (as well as a logical standpoint) to group such elements together because a single worker or set of workers will develop and manipulate them. Grouping classes by domains and making the domains CIs may make sense for many projects.
Architectural workflows also require effective access to the model. Here, the architecture is broken up into the logical architecture (organization of types, classes, and other design-time model elements) and physical architecture (organization of instances, objects, subsystems, and other runtime elements). It is common for the logical architecture to be organized by domains and the physical architecture to be organized around components or subsystems. If the model is structured this way, then a domain, subsystem, or component is made a CI and assigned to a single worker or team. If the element is large enough, then it may be further subdivided into subpackages of finer granularity based on subtopic within a domain, subcomponents, or some other criterion such as team organization.
Testing workflows are often neglected in the model organization, usually to the detriment of the project. Testing teams need only read-only access to the model elements under test, but nevertheless they do need to manage test plans, test procedures, test results, test scripts, and test fixtures, often at multiple levels of abstraction. Testing is often done at many different levels of abstraction but can be categorized into three primary levels: unit testing (often done by the worker responsible for the model element under test), integration (internal interface testing), and validation (black-box system level testing). Unit-level testing is usually accomplished by the owner of the model element under test or a “testing buddy” (a peer in the development organization). The tests are primarily white-box, design, or code-level tests and often use additional model elements constructed as test fixtures. It is important to retain these testing fixture model elements so that as the system evolves, we can continue to test the model elements. Since these elements are white box and tightly coupled with the implementation of the model elements, it makes the most sense to colocate them with the model elements they test. So, if a class myClass has some testing support classes, such as myClass_tester and myClass_stub, they should be located close together. If the same worker is responsible for all, then perhaps they should be located within the same package (or another package in the same scope). If a testing buddy is responsible, then it is better to have it in another package but make sure that it is in the same CI as the model elements under test.
Integration and validation tests are not so tightly coupled as at the unit level, but clearly the testing team may construct model elements and other artifacts to assist in the execution of those tests. These tests are typically performed by different workers than the creators of the model elements they test. Thus, independent access is required and they should be in different CIs.
It is important to be able to efficiently construct and test prototypes during the development process. This involves both tests against the architecture (the integration and testing activities) and against the entire prototype's requirements (validation testing activities). There may be any number of model elements specifically constructed for a particular prototype that need not be used anywhere else. It makes sense to include these in a locale specific to that build or prototype. Other artifacts, such as test fixtures that are going to be reused or evolved and apply to many or all prototypes should be stored in a locale that allows them to be accessed independently from a specific prototype. Tools such as I-Logix iNotion™ provide company-wide repositories, access, and control over the complete sets of management, development, marketing, and manufacturing artifacts.
In the preceding discussion, we see that a number of factors influence how we organize our models: the project team organization, system size, architecture, how we test our software, and our project lifecycle. Let us now consider some common ways to organize models and see where they fit well and where they fit poorly.
The model organization shown in Figure 1-14 is the simplest organization we will consider. The system is broken down by use cases, of which there are only three in the example. The model is organized into four high-level packages: one for the system level and one per use case. For a simple system with three to 10 use cases, and perhaps one to six developers, this model can be used with little difficulty. The advantages of this organization are its simplicity and the ease with which requirements can be traced from the high level through the realizing elements. The primary disadvantages of this approach are that it doesn't scale up to medium- or large-scale systems. Other disadvantages include difficulty in reuse of model elements and that there is no place to put elements common to multiple use case collaborations, hence a tendency to reinvent similar objects. Finally, there is no place to put larger-scale architectural organizations in the model, and this further limits its scalability to large systems.

The model organization shown in Figure 1-15 is meant to address some of the limitations of the use case-based approach. It is still targeted toward small systems, but adds a Framework package for shared and common elements. The Framework package has subpackages for usage points (classes that will be used to provide services for the targeted application environment) and extension points (classes that will be subclassed by classes in the use case packages). It should be noted that there are other ways to organize the Framework area that work well too. For example, Frameworks often consist of sets of coherent patterns—the subpackaging of the Framework can be organized around those patterns. This organization is particularly apt when constructing small applications against a common Framework. This organization does have some of the same problems with respect to reuse as the use case-based model organization.

As mentioned early on, if the system is simple enough, virtually any organization can be made to work. Workflow and collaboration issues can be worked out ad hoc and everybody can get their work done without serious difficulty. A small application might be 10 to 100 classes realizing 3 to 10 use cases. Using another measure, it might be on the order of 10,000 or so lines of code.
One of the characteristics of successful large systems (more than, say, 300 classes) is that they are architecture-centric. That is, architectural schemes and principles play an important role in organizing and managing the application. In the ROPES process, there are two primary subdivisions of architecture—logical and physical.[28] The logical model organizes types and classes (things that exist at design time), while the physical model organizes objects, components, tasks, and subsystems (things that exist at runtime). When reusability of design classes is an important goal of the system development, it is extremely helpful to maintain this distinction in the model organization.
The next model organization, shown in Figure 1-16, is suitable for large-scale systems. The major packages for the model are
System
Logical model
Subsystem model
Builds

The system package contains elements common to the overall system—system level use cases, subsystem organization (shown as an object diagram), and system-level actors. The logical model is organized into subpackages called domains. Each domain contains classes and types organized around a single subject matter, such as User Interface, Alarms, Hardware Interfaces, Bus Communication, and so on. Domains have domain owners—those workers responsible for the content of a specific domain. Every class in the system ends up in a single domain. Class generalization hierarchies almost always remain within a single domain, although they may cross package boundaries within a domain.
The physical model is organized around the largest-scale pieces of the system—the subsystems. In large systems, subsystems are usually developed by independent teams, thus it makes sense to maintain this distinction in the model. Subsystems are constructed primarily of instances of classes from multiple domains. Put another way, each subsystem contains (by composition) objects instantiated from different domains in the system.
The last major package is builds. This area is decomposed into subpackages, one per prototype. This allows easy management of the different incremental prototypes. Also included in this area are the test fixtures, test plans, procedures, and other things used to test each specific build for both the integration and validation testing of that prototype.
The primary advantage of this model organization is that it scales up to very large systems very nicely because it can be used recursively to as many levels of abstraction as necessary. The separation of the logical and physical models means that the classes in the domains may be reused in many different deployments, while the use of the physical model area allows the decomposition of system use cases to smaller subsystem-level use cases and interface specifications.
The primary disadvantage that I have seen in the application of this model organization is that the difference between the logical and physical models seems tenuous for some developers. The model organization may be overly complex when reuse is not a major concern for the system. It also often happens that many of the subsystems depend very heavily (although never entirely) on a single domain, and this model organization requires the subsystem team to own two different pieces of the model. For example, guidance and navigation is a domain rich with classes, but it is usually also one or more subsystems.
The last model organization to be presented, shown in Figure 1-17, is similar to the previous one, except that it blurs the distinction between the logical and physical models. This can be appropriate when most or all subsystems are each dominated by a single domain. In this case, the domain package is decomposed into one package for each domain, and each of these is further decomposed into the subsystems that it dominates. For common classes, such as bus communication and other infrastructure classes, a separate shared Framework package is provided to organize them, similar to the Framework-based model organization shown in Figure 1-15.
Given that your team has selected and implemented a reasonable model organizational structure, the question remains as to how to do the daily work of analysis, design, translation, and testing. These questions should be answered by your company's (or project's) software development plan (SDP). The SDP documents how the team is to work together effectively, what standards of work must be met, and other process details. In Section 1.5.2, we introduced the ROPES process. This can be used, as it has in many real-time and embedded projects, or your own favorite process may be used instead. However, for the teams to work together, it is crucial that all the team members understand their roles and expectation on their deliverable products [16].
One of the key activities in the daily workings of a project is configuration management. In a model-based project, the primary artifact being configured with the CM system is the model. If you are using a full-generative tool, such as Rhapsody, then you might be able to get away with CMing the model and not the generated code because you can always produce the code from the model automatically. Nevertheless, many projects, especially those with high safety requirements, CM both the mode and the generated code.
Ideally the CM tool will interface directly with the modeling tool and most UML modeling tools do exactly that. Most also allow a great deal of configurability as to the level and number of configuration items (CIs). The default behavior should be that a package and all its contents, form a single CI, so there will be approximately the same number of CIs from the model as there are packages. However, for large-scale systems, packages may contain other packages, so the default should probably be the number of bottom-level packages. Packages, in the UML, may contain any model element, and will, of course, reflect your model organization. It may be desirable to have finer-level control over CIs, in which case you may want to go as far down as the individual class or function, but in large-scale systems, that level of control can be very tedious to manipulate. For the purpose of this discussion, we will assume you use the package as the primary CI for manipulation.
You will mostly likely want to use a locking mechanism on your CIs—that is, when one developer checks out a CI for updating, no one else can check it out except for reference. Because classes must collaborate across package boundaries, it is important that clients of a CIs can be referenced. However, this does create a problem. As we will see when we discuss classes in the next chapter, associations are normally bi-directional. When you add such an association, you must have write access to both classes in order to add the association. If one of these classes is checked out read-only, then you don't have write privileges to it and cannot add the bi-directional association. One possible solution for is to add unidirectional associations to classes for which you have only read access. As long as you're sending messages to objects of such a class, you don't need write access to create the association. Another solution is to get write access for that small change.
Still another option is to allow multiple developers to work on the same CIs and merge the changes when they are finished. This is often done with code using text-based diff and merge tools. Some tools (such as Rhapsody) can perform these functions on models and identify when changes are in conflict, allowing the developers to decide what to do should the changes made to the CIs be mutually incompatible.
A generative tool is one that can take the structural and behavioral semantics specified in the model diagrams and use them to generate executable code. As mentioned, it is common to CM the code in addition to the models, but in many cases, this may not be necessary.
Normal work in the presence of a CM infrastructure proceeds as the engineer checks out the model CIs on which he or she wishes to work, as well as getting read-only locks on the CIs containing elements they wish to reference. They make the design changes, additions, or updates and check the CIs back in. In some cases, a two-tiered CM system is used—local CM for the individual worker at the desktop and project CM for the entire team. This approach allows the team member to work with CIs without breaking anyone else's work. Once the CIs are in a stable configuration, they may be checked back in to the project CM. The ROPES process recommends that before any CI can be used in a team build, the CI be unit-tested and reviewed. In my experience, this eliminates many work stoppages due to simple and easily correctable (and all too frequent) errors.
Another important aspect is requirements management (RM). This is particularly important in high-reliability (hi-rel) systems development in which the cost of system failure is high. The concept of requirements management is a simple one, very similar to that of configuration management. Requirements are identified in an RM system and then their design, implementation, and testing are tracked to the individual requirement. Forward RM allows the developer to track from the specific requirement to where the requirement is met in the design and code, and to its test status. This allows for queries such as “Where is this requirement met,” “How many requirements have been implemented,” and “How many requirements have been successfully tested?” Backward tracability allows the developer to look at some portion of the design or some set of tests and identify which requirements they meet. RM is best accomplished with tools design for that specific purpose and there are several available that interface with modeling tools.
The executability of a model is, in my opinion, very important. Whenever you do some portion of a model, you must be able to answer the question “Is this right?” Experience has shown that asking—and answering—this question throughout the development lifecycle has enormous impact on the quality of the system at the end. Indeed, the spiral development lifecycle is an attempt to ensure that the system is constructed using relatively small increments (called prototypes) that are each tested to be correct before moving on and adding more functionality. This is done not only at the level of the microcycle (four to six weeks is a typical timeframe) but also at the level of the nanocycle (every few minutes to hours). So if you are designing a collaboration of 50 classes to realize a use case, rather than create all 50 classes, generate them, and hope that they're right, you might create three classes and execute and test that portion of the collaboration. Once you're convinced that much is right, you might add one or two more and get that to work. Then add another class and some more behavior to two of the existing classes. And so on. This is a highly effective way in which to create complex systems. This approach is made even more productive when the modeling tool used is executable—that is, it can execute and debug portions of or the entire model. There exist UML tools that do this, Rhapsody being a prime example.
Executable tools come in two flavors: simulation tools and generative tools. Simulators pretend they are the real system and allow the system to execute in a simulated environment. Simulators have a good deal of merit, particular for proving logical correctness, but they suffer from a few flaws as well. First, because you're not testing the real system or the real code, you must test twice, once on the simulated version and once on the final code. Second, the simulation cannot easily run on the actual target environment nor in anything close to real time, so they are once removed from the true execution environment.
The other approach to executability is to use a generative tool. By generative tool, I mean that the tool can take the semantics of your model, by far most commonly entered using structural and behavioral diagrams, and generate code in the desired target source code language, such as C++, C, Java, or Ada. Since the code generated is the same as that which will be ultimately deployed, it is usually only necessary to test it once, saving valuable time and effort. Also, because true source code is generated, it can be run on the desktop debugging environment or, with nothing more than a recompile, also on the target hardware environment. For this reason, generative tools are considered by most to be “stronger” in terms of their executability.
In either case, the execution and debugging of models should be done at the model level rather than the level of the source code. If the developer is using class diagrams to show structure, and statecharts and sequence diagrams to specify behavior, then those are, in fact, the very views that should be used to examine the executing system.
Of course, standard debugging concepts should be supported at this model level—single step, step-over, step-into, set breakpoints, and so on—but they should be using design-level concepts, such as setting a breakpoint when a state is entered or an operation is invoked. Most of the system debugging should be done at this level of abstraction, although it may be necessary sometimes to drill down to the source-code level (and use a source-code-level debugger) or even to the assembly or logic analyzer level. Nevertheless, most of the debugging of a model should be done at the level of abstraction at which the model was created.
Debugging may be thought of as testing by roaming around. It is usually highly informal and unstructured. Debugging at the model level allows us to much more easily ensure that the system is behaving as expected than if we were limited to debugging the code resulting from the models. Beyond debugging, there is testing. By testing, I mean a structured and repeatable execution of the system or some portion thereof, with well-defined test conditions and a set of expected results with clear and unambiguous pass/fail criteria. Testing should also be done primarily at the model level as well.
In the ROPES process, there are three identified levels of testing:
Unit testing
Integration testing
Validation testing
Unit-level testing is done primarily white box and at the class or component level. Such testing ensures the detailed design of the primitive building blocks of the system is correct, that preconditional invariants (such as “pointers are valid” and “enumerated values are ensured to be in range”) are checked. The consistent application of good unit-level testing is, in my experience, where the biggest improvements in overall system quality may be made.
Integration testing is a test of the architecture. Specifically it tests that the large-scale pieces of the system—typically components or subsystems—fit together properly and collaborate as expected. Failure to adhere to interface requirements, especially those that are more subtle than simple operation parameter list types, is a leading cause of large-system failure. Interfaces are more than simple collections of operations that may be called from other architectural components. They have many assumptions about value ranges, the order in which operations may be invoked, and so on, that may not be caught by simple visual inspection. By putting together these architectural pieces and demonstrating that they do all the right things and catch violations of the preconditional invariants, we can alleviate many of the failures we see.
The last level of testing is validation testing. This is done primarily black box. Validation testing means that a system (or prototype of a system) properly executes its requirements in the real or simulated target environment. In an iterative development lifecycle, the primary artifacts produced at the end of each spiral constitute a version of the system that realizes some coherent set of requirements. Each prototype in the ROPES spiral is tested against that set of requirements, normally represented as a small set of use cases. In subsequent spirals, old requirements are validated using a set of regression tests to ensure that the new functionality hasn't broken the old.
As stated, the primary artifact of each spiral is the prototype—a tested, working version of the system, which may be incomplete. Another artifact is a defect report, identifying the defects that weren't fixed in the previous spiral. The next spiral typically adds new requirements as well as fixing previously identified minor defects (major defects must be repaired before the spiral may end). Often, as new functionality is added and known defects are removed, the model must be internally reorganized in minor ways. This is called refactoring. Refactoring is a normal outcome of the iterative lifecycle and is not to be feared. In the spiral approach, early design decisions are made with incomplete knowledge, after all, and even though an attempt is made to ensure that future additional functionality won't radically affect the architecture, sometimes it will. Usually these are small changes that must be made. But working with a spiral model means that you expect some refactoring to be necessary. It is only a concern if you find major architectural changes are necessary in a number of prototypes. Should this occur, then it would be useful to step back and consider the architectural selection with a greater scrutiny.
The last aspect of model-based development I would like to consider is that of reviews or inspections, as they are sometimes called. Inspections serve two primary purposes: to improve the quality of the portion of the model being inspected and to disseminate knowledge of some portion of the model to various team members.
The ROPES process has particular notions of what constitutes good models. One of the common problems made by neophyte modelers is that of too much information in one place. While in books, problems are simplified to make concrete points (and this book is no exception), in the real world, problems are complex. It simply isn't possible to put every aspect of a system in a single diagram. What is needed is a good rule for how to break up a model into the diagrams so that they aid in model creation and understanding. The ROPES rule for diagrams revolves around the notion of a “mission.” Each diagram should have a single mission and include only those elements necessary to perform that mission, but should include all of those elements. So rather than create a class diagram that has every class in the system (requiring “E” size plotter paper and a 2-point font), a class only appears on diagrams when it is relevant to its mission. Likewise, given that a class is relevant to the diagram's mission, only the aspects of the class that are relevant are shown—operations, attributes, associations, and so on that are not relevant to the particular diagram are not shown on this diagram, although they may very well appear on a different one. This means that it is common for a class to appear on more than one diagram.
Common diagrammatic missions include
A single collaboration (set of classes working together for a common purpose, such as realizing a use case)
A class taxonomy (i.e., generalization)
An architectural view
Subsystem and/or component architecture
Distribution of elements across multiple address spaces
Safety and/or reliability management
Concurrency and/or resource management (e.g., task diagram)
Deployment of elements on processors
Organization of processors and buses
The organization of the model (package diagram)
A scenario of a collaboration
A coherent set of requirements
Behavior of a structural element (e.g., statechart or activity diagram)
And these missions may occur at multiple levels of abstraction.
So far, we have only touched on the defining characteristics of real-time systems and the very basic aspects of the model-based development. In the subsequent chapters of this book, we'll examine the basic concepts of the UML (Chapters 2 and 3) and apply these ideas to the process of creating real-time embedded applications. The process is broken into the overall analysis and design steps, as called out in Section 1.5.1. Analysis is subdivided into specification of external requirements and the identification of inherent classes and objects. Design is divided into three parts—architectural, mechanistic, and detailed levels of abstraction. Architectural design specifies the strategic decisions for the overall organization of the system, such as the design of the processor and concurrency models. Mechanistic design is concerned with the medium level of organization—the collaboration of objects to achieve common goals. Detailed design defines the internal algorithms and primitive data structures within classes. All the process steps are required to create efficient, correct designs that meet the system requirements. In the next chapter, we'll focus on using the UML to capture the structural aspects of systems.
[1] Not to mention that they also keep a significant number of us gainfully employed.
[2] Commando, a heart-warming tale if ever there was one.
[3] An open loop system is one in which feedback about the success of the performed action is not used to control the action. A closed loop system is one in which the action is monitored and that sensory data is used to modify future actions.
[4] It is true that behind the scenes even desktop computers must interface with printers, mice, keyboards, and networks. The point is that they do this only to facilitate the user's whim.
[5] Unfortunately, many companies opt for decreasing (primarily hardware) recurring costs without considering all of the development cost ramifications, but that's fodder for another book.
[6] General Protection Fault, a term that was introduced to tens of millions of people with Microsoft's release of Windows 3.1.
[7] It is not a question of whether or not developers of safety-critical software are paranoid. The real question is “Are they paranoid enough?”
[9] Although due to blocking and preemption, it is not generally just a simple arithmetic sum.
[10] Bursty message arrival patterns are characterized by a Poisson distribution and so do not have a standard deviation but do have an average interarrival time.
[11] Note that some people consider an invocation synchronous if the caller waits until the receiver returns a response. This is what we would call the blocking kind of synch-synch rendezvous.
[12] A task diagram is just a class diagram (see Chapter 2) whose mission is to show the classes related to the concurrency of the system.
[13] And I, for one, feel like St. Augustine of Hippo who said he knew what time was until someone asked him to explain it.
[14] Doug Locke, Chief Scientist for TimeSys, private communication.
[15] An optimal policy is one that can schedule a task set if it is possible for any other policy to do so.
[17] The notations will be covered in the next chapter. For now, the boxes represent “things” such as tasks, resources, and semaphores, and the lines mean that connected things can exchange messages. The notes in curly braces, called constraints, provide additional information or annotations.
[18] The author is a member of the SysML consortium working on this submission at the time of this writing.
[20] The nanocycle workflow is very similar to the workflow in the XP (extreme programming) or Agile methods processes. That is, constant execution and constant test throughput development.
[21] By black box I mean that the requirements are visible to objects interacting with the system not requiring knowledge of the systems internal structure.
[22] See www.ilogix.com for more information about the Rhapsody tool. Several white papers on the development of real-time systems are also available on the I-Logix Web site.
[23] The only exception that comes to mind was an individual who quit to go into marketing.
[24] Although it can be used for larger units early before the decomposition to smaller units has been made.
[25] The astute reader will note that these far exceed the accuracies of most project schedules.
[26] You never ever want to schedule overtime. If you are in the position of scheduling overtime, you will never meet your plan. At that point, you should take some corrective measures on your schedule to adjust it rather than schedule overtime.
[27] Yes, in some environments, engineers actually get vacation time!
[28] “Components: Logical and Physical Models” by Bruce Douglass, Software Development Magazine, December 1999.